국내 최고의 안정성을 기반으로 사용 목적에 따라 최적의 컴퓨팅 자원을 편리하고 탄력적으로 제공합니다.
이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
Compute
- 1: Virtual Server
- 1.1: Overview
- 1.1.1: 서버 타입
- 1.1.2: 모니터링 지표
- 1.1.3: ServiceWatch 지표
- 1.2: How-to guides
- 1.2.1: Image
- 1.2.2: Keypair
- 1.2.3: Server Group
- 1.2.4: IP 변경하기
- 1.2.5: Linux NTP 설정하기
- 1.2.6: RHEL Repo 및 WKMS 설정하기
- 1.2.7: ServiceWatch Agent 설치하기
- 1.3: API Reference
- 1.4: CLI Reference
- 1.5: Release Note
- 2: Virtual Server Auto-Scaling
- 2.1: Overview
- 2.1.1: 모니터링 지표
- 2.2: How-to guides
- 2.2.1: Launch Configuration
- 2.2.2: 정책 관리하기
- 2.2.3: 스케줄 관리하기
- 2.2.4: 알림 관리하기
- 2.3: API Reference
- 2.4: CLI Reference
- 2.5: Release Note
- 3: GPU Server
- 3.1: Overview
- 3.1.1: 서버 타입
- 3.1.2: 모니터링 지표
- 3.1.3: ServiceWatch 지표
- 3.2: How-to guides
- 3.2.1: Image 관리하기
- 3.2.2: Keypair 관리하기
- 3.2.3: GPU Server에서 Multi-instance GPU 사용하기
- 3.2.4: GPU Server에서 NVSwitch 사용하기
- 3.2.5: ServiceWatch Agent 설치하기
- 3.3: API Reference
- 3.4: CLI Reference
- 3.5: Release Note
- 4: Bare Metal Server
- 4.1: Overview
- 4.2: How-to guides
- 4.2.1: ServiceWatch Agent 설치하기
- 4.3: API Reference
- 4.4: CLI Reference
- 4.5: Release Note
- 5: Multi-node GPU Cluster
- 5.1: Overview
- 5.2: How-to guides
- 5.2.1: Cluster Fabric 관리
- 5.2.2: ServiceWatch Agent 설치하기
- 5.2.3: Multi-node GPU Cluster 서비스 범위 및 점검 가이드
- 5.3: Release Note
- 6: Cloud Functions
- 6.1: Overview
- 6.2: How-to guides
- 6.2.1: 트리거 설정하기
- 6.2.2: AIOS 연계하기
- 6.2.3: Blueprint 상세 가이드
- 6.2.4: PrivateLink 서비스 연계하기
- 6.3: API Reference
- 6.4: CLI Reference
- 6.5: Release Note
- 7: Virtual Server DR
- 7.1: Overview
- 7.2: Release Note
- 8: Block Storage
- 8.1: Overview
- 8.1.1: 모니터링 지표
- 8.2: How-to guides
- 8.3: API Reference
- 8.4: CLI Reference
- 8.5: Release Note
1 - Virtual Server
1.1 - Overview
서비스 개요
Virtual Server는 CPU, Memory 등 서버에서 제공하는 인프라 자원을 개별 구매할 필요 없이, 필요한 시점에 필요한 만큼 자유롭게 할당 받아 사용할 수 있는 클라우드 컴퓨팅에 최적화된 가상 서버입니다. 클라우드 환경에서 개발, 테스트, 응용 프로그램 실행 등 사용자의 컴퓨팅 활용 목적에 따라 최적화된 성능의 자원을 이용할 수 있습니다.
특장점
쉽고 편리한 컴퓨팅 환경 구성: 웹 기반 Console을 통해 Virtual Server 프로비저닝부터 자원 관리, 비용 관리까지 사용자가 직접 Self Service로 손쉽게 사용 가능합니다. Virtual Server 사용 중 CPU나 Memory 등 주요 자원의 용량 변경이 필요할 경우 운영자의 개입 없이도 손쉽게 증설, 축소가 가능합니다.
다양한 유형의 서비스 제공: 사전 정의된 서버 타입(1~128 vCore)에 따라 가상화 된 vCore/Memory 자원을 제공합니다.
- 일반 Virtual Server: 일반적으로 사용되는 Computing Spec 제공 (최대 16vCore, 256GB)
- 대용량 Virtual Server: 일반 Virtual Server Spec 이상의 대용량 자원 필요 시 제공
강력한 보안 적용: Security Group 서비스를 통해 외부 인터넷이나 다른 VPC(Virtual Private Cloud)와 통신하는 Inbound/Outbound 트래픽을 제어하여 서버를 안전하게 보호합니다. 또한 실시간 모니터링을 통해 컴퓨팅 자원을 안정적으로 운영할 수 있습니다.
서비스 구성도
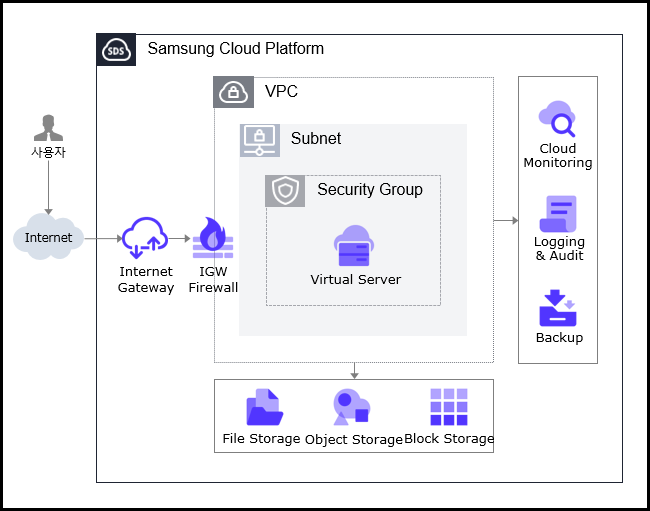
제공 기능
Virtual Server는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning) 및 관리: 웹 기반 Console을 통해 Virtual Server 프로비저닝부터 자원 관리, 비용 관리 기능을 제공합니다. Virtual Server 사용 중 CPU나 Memory 등 주요 자원의 용량 변경이 필요할 경우 서버 타입 수정 기능을 이용해 즉시 변경할 수 있습니다.
- 표준 서버 타입 및 Image 제공: 표준 서버 타입에 따라 가상화 된 vCore/Memory 자원을 제공하며, 표준 OS Image를 제공합니다.
- 스토리지 연결: OS 디스크 외 추가 연결 스토리지를 제공 합니다. Block Storage, File Storage, Object Storage 를 추가 연결하여 사용할 수 있습니다.
- 네트워크 연결: Virtual Server의 일반 서브넷/IP 설정 및 Public NAT IP를 연결할 수 있습니다. 서버 간 통신을 위한 로컬 서브넷 연결을 제공합니다. 해당 작업은 상세 페이지에서 수정할 수 있습니다.
- Security Group 적용: Security Group 서비스를 통해 외부 인터넷이나 다른 VPC와 통신하는 Inbound/Outbound 트래픽을 제어하여 서버를 안전하게 보호합니다.
- 모니터링: 컴퓨팅 자원에 해당하는 CPU, Memory, Disk 등의 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
- 백업 및 복구: Backup 서비스를 통해 Virtual Server Image를 백업 및 복구할 수 있습니다.
- 비용 관리: 필요에 따라 서버를 생성, 중지, 해지할 수 있으며, 실제 사용 시간에 따라 과금되므로 사용량에 따른 비용을 확인할 수 있습니다.
- ServiceWatch 서비스 연계 제공: ServiceWatch 서비스를 통해 데이터를 모니터링할 수 있습니다.
구성 요소
Virtual Server은 표준 서버 타입 및 표준 OS Image를 제공하고 있습니다. 사용자는 원하는 서비스 규모에 따라 이를 선택하여 사용할 수 있습니다.
Image
Image를 생성 및 관리할 수 있습니다. 주요 기능은 다음과 같습니다.
- Image 생성: 사용 중인 Virtual Server의 구성을 Image로 생성할 수 있으며, 사용자의 Image 파일을 Object Storage에 업로드하여 Image를 생성할 수 있습니다.
- 공유용 Image 생성: Visibility가 Private인 Image를 공유가 가능한 Shared Image로 생성할 수 있습니다.
- 다른 Account로 공유: Image를 다른 Account로 공유할 수 있습니다.
- Image 생성 및 활용 방법은 How-to guides > Image문서를 참고하세요.
Keypair
보다 안전한 OS 접속을 위해 ID/Password 입력 방식이 아닌, Key Pair 를 제공하여 보안을 강화합니다. 주요 기능은 다음과 같습니다.
- Keypair 생성: Virtual Server에 연결하기 위한 사용자 증명을 생성합니다.
- 공개 키 가져오기: 파일 불러오기 또는 공개 키를 직접 입력하여 공개 키를 가져올 수 있습니다.
- Keypair 생성 및 활용 방법은 How-to guides > Keypair문서를 참고하세요.
Server Group
Server Group 설정을 통해 Virtual Server 및 Virtual Server 생성 시 추가한 Block Storage를 랙(Rack) 및 호스트에 근접 또는 분산 배치 가능합니다. 주요 기능은 다음과 같습니다.
- Server Group 생성: 동일 Server Group에 소속된 Virtual Server를 Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치)로 설정할 수 있습니다.
- Server Group 생성 및 활용 방법은 How-to guides > Server Group문서를 참고하세요.
OS Image 제공 버전
Virtual Server에서 제공하는 OS Image는 다음과 같습니다
| OS Image 버전 | EoS Date |
|---|---|
| Alma Linux 8.10 | 2029-05-31 |
| Alma Linux 9.6 | 2025-11-17 |
| Oracle Linux 8.10 | 2029-07-31 |
| Oracle Linux 9.6 | 2025-11-25 |
| RHEL 8.10 | 2029-05-31 |
| RHEL 9.4 | 2026-04-30 |
| RHEL 9.6 | 2027-05-31 |
| Rocky Linux 8.10 | 2029-05-31 |
| Rocky Linux 9.6 | 2025-11-30 |
| Ubuntu 22.04 | 2027-06-30 |
| Ubuntu 24.04 | 2029-06-30 |
| Windows 2019 | 2029-01-09 |
| Windows 2022 | 2031-10-14 |
표. Virtual Server 제공 OS Image 버전
참고
- Alma Linux 및 Rocky Linux와 같은 Linux 운영체제는 Major 버전의 가장 마지막 릴리스 버전을 제외하고, 짝수 Minor 버전만 제공합니다. 이는 SCP 시스템의 안정성과 일관성을 보장하기 위한 정책입니다. 해당 운영체제의 EOS(End of Support) 및 EOL(End of Life) 날짜를 확인하시어, 필요 시 신규 또는 추가 개별 패키지를 적용하여 안정적인 환경을 유지하시길 권장드립니다.
서버 타입
Virtual Server에서 지원하는 서버 타입은 다음 형식과 같습니다. 서버 타입에 대한 자세한 내용은 Virtual Server 서버 타입을 참고하세요.
Standard s1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | s1 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | Memory 용량
|
표. Virtual Server 서버 타입
제약 사항
참고
- Rocky Linux, Oracle Linux로 Virtual Server를 생성한 경우 시간 동기화(NTP:Network Time Protocol)를 위해 추가 설정이 필요합니다. 다른 Image로 생성한 경우에는 자동 설정되어 별도 설정이 필요없습니다.
자세한 내용은 Linux NTP 설정하기를 참고하세요. - 2025년 8월 이전 RHEL 및 Windows Server를 생성한 경우 RHEL Repository 및 WKMS(Windows Key Management Service) 설정 수정이 필요합니다.
자세한 내용은 RHEL Repo 및 WKMS 설정하기를 참고하세요.
선행 서비스
해당 서비스를 생성하기 전에 미리 구성이 필요한 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
표. Virtual Server 선행 서비스
1.1.1 - 서버 타입
Virtual Server 서버 타입
Virtual Server는 사용 목적에 맞게 서버 타입을 제공합니다. 서버 타입은 CPU, Memory, Network Bandwidth 등 다양한 조합으로 구성됩니다. Virtual Server를 생성할 때 선택하는 서버 타입에 따라 Virtual Server에 사용되는 호스트 서버가 결정됩니다. Virtual Server에서 실행하려는 애플리케이션의 사양에 따라 서버 타입을 선택해주세요.
Virtual Server에서 지원하는 서버 타입은 다음 형식과 같습니다.
Standard s1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | s1 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Virtual Server 서버 타입 형식
s1 서버 타입
Virtual Server의 s1 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 애플리케이션에 적합합니다.
- Samsung Cloud Platform v2의 1세대: 최대 3.3Ghz의 Intel 3세대(Ice Lake) Xeon Gold 6342 Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | s1v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | s1v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | s1v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | s1v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | s1v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | s1v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | s1v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | s1v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | s1v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | s1v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | s1v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | s1v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | s1v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | s1v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | s1v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | s1v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | s1v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | s1v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | s1v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | s1v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | s1v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | s1v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | s1v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | s1v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | s1v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | s1v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | s1v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | s1v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | s1v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | s1v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | s1v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | s1v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | s1v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | s1v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | s1v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | s1v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | s1v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | s1v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | s1v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | s1v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | s1v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Virtual Server 서버 타입 사양 - s1 서버 타입
s2 서버 타입
Virtual Server s2 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 애플리케이션에 적합합니다.
- Samsung Cloud Platform v2의 2세대: 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | CPU vCore | Memory | Network Bandwidth(Gbps) |
|---|---|---|---|---|
| Standard | s2v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | s2v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | s2v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | s2v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | s2v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | s2v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | s2v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | s2v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | s2v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | s2v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | s2v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | s2v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | s2v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | s2v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | s2v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | s2v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | s2v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | s2v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | s2v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | s2v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | s2v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | s2v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | s2v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | s2v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | s2v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | s2v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | s2v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | s2v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | s2v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | s2v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | s2v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | s2v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | s2v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | s2v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | s2v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | s2v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | s2v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | s2v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | s2v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | s2v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | s2v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Virtual Server 서버 타입 사양 - s2 서버 타입
h2 서버 타입
Virtual Server의 h2 서버 타입은 대용량 서버 사양으로 제공하며, 대규모 데이터 처리를 위한 애플리케이션에 적합합니다.
- Samsung Cloud Platform v2의 2세대: 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 128개의 vCPU 및 1,536 GB의 메모리를 지원
- 최대 25Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | h2v24m48 | 24 vCore | 48 GB | 최대 25 Gbps |
| High Capacity | h2v24m96 | 24 vCore | 96 GB | 최대 25 Gbps |
| High Capacity | h2v24m192 | 24 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | h2v24m288 | 24 vCore | 288 GB | 최대 25 Gbps |
| High Capacity | h2v32m64 | 32 vCore | 64 GB | 최대 25 Gbps |
| High Capacity | h2v32m128 | 32 vCore | 128 GB | 최대 25 Gbps |
| High Capacity | h2v32m256 | 32 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | h2v32m384 | 32 vCore | 384 GB | 최대 25 Gbps |
| High Capacity | h2v48m96 | 48 vCore | 96 GB | 최대 25 Gbps |
| High Capacity | h2v48m192 | 48 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | h2v48m384 | 48 vCore | 384 GB | 최대 25 Gbps |
| High Capacity | h2v48m576 | 48 vCore | 576 GB | 최대 25 Gbps |
| High Capacity | h2v64m128 | 64 vCore | 128 GB | 최대 25 Gbps |
| High Capacity | h2v64m256 | 64 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | h2v64m512 | 64 vCore | 512 GB | 최대 25 Gbps |
| High Capacity | h2v64m768 | 64 vCore | 768 GB | 최대 25 Gbps |
| High Capacity | h2v72m144 | 72 vCore | 144 GB | 최대 25 Gbps |
| High Capacity | h2v72m288 | 72 vCore | 288 GB | 최대 25 Gbps |
| High Capacity | h2v72m576 | 72 vCore | 576 GB | 최대 25 Gbps |
| High Capacity | h2v72m864 | 72 vCore | 864 GB | 최대 25 Gbps |
| High Capacity | h2v96m192 | 96 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | h2v96m384 | 96 vCore | 384 GB | 최대 25 Gbps |
| High Capacity | h2v96m768 | 96 vCore | 768 GB | 최대 25 Gbps |
| High Capacity | h2v96m1152 | 96 vCore | 1152 GB | 최대 25 Gbps |
| High Capacity | h2v128m256 | 128 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | h2v128m512 | 128 vCore | 512 GB | 최대 25 Gbps |
| High Capacity | h2v128m1024 | 128 vCore | 1024 GB | 최대 25 Gbps |
| High Capacity | h2v128m1536 | 128 vCore | 1536 GB | 최대 25 Gbps |
표. Virtual Server 서버 타입 사양 - h2 서버 타입
1.1.2 - 모니터링 지표
Virtual Server 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Virtual Server의 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Agent를 설치하지 않아도 기본적인 모니터링 지표를 제공하며 아래 표. Virtual Server 모니터링 지표(기본 제공) 에서 확인해주세요. 추가로 Agent 설치를 통해 조회 가능한 지표는 아래 표. Virtual Server 추가 모니터링 지표 (Agent 설치 필요) 에서 참고하세요.
Windows OS의 경우 Memory 관련 지표는 Agent를 설치해야만 조회가 가능합니다.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Memory Total [Basic] | 사용할 수 있는 메모리의 bytes | bytes |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Memory Swap In [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Swap Out [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Free [Basic] | 사용하지 않은 메모리의 bytes | bytes |
| Disk Read Bytes [Basic] | 읽기 bytes | bytes |
| Disk Read Requests [Basic] | 읽기 요청 수 | cnt |
| Disk Write Bytes [Basic] | 쓰기bytes | bytes |
| Disk Write Requests [Basic] | 쓰기 요청 수 | cnt |
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Instance State [Basic] | Instance 상태 | state |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Dropped [Basic] | 수신 패킷 드롭 | cnt |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Dropped [Basic] | 송신 패킷 드롭 | cnt |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. Virtual Server 모니터링 지표(기본 제공)
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Core Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| Core Usage [System] | 커널 공간에서 소요된 CPU 시간의 비율 | % |
| Core Usage [User] | 사용자 공간에서 소요된 CPU 시간의 비율 | % |
| CPU Cores | 호스트에 있는 CPU 코어의 수 | cnt |
| CPU Usage [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage [User] | 사용자 영역에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage/Core [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage/Core [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage/Core [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage/Core [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage/Core [User] | 사용자 영역에서 사용한 CPU 시간의 백분율 | % |
| DiskCPU Usage [IO Request] | 장치에 대한 입출력 요청이 실행된 CPU 시간의 비율 | % |
| Disk Queue Size [Avg] | 장치에 대해 실행된 요청의 평균 대기열 길이입니다. | num |
| Disk Read Bytes | 장치에서 읽는 초당 바이트 수입니다. | bytes |
| Disk Read Bytes [Delta Avg] | 개별 Disk들의 system.diskio.read.bytes_delta의 평균 | bytes |
| Disk Read Bytes [Delta Max] | 개별 Disk들의 system.diskio.read.bytes_delta의 최대 | bytes |
| Disk Read Bytes [Delta Min] | 개별 Disk들의 system.diskio.read.bytes_delta의 최소 | bytes |
| Disk Read Bytes [Delta Sum] | 개별 Disk들의 system.diskio.read.bytes_delta의 합 | bytes |
| Disk Read Bytes [Delta] | 개별 Disk의 system.diskio.read.bytes 값의 delta | bytes |
| Disk Read Bytes [Success] | 성공적으로 읽은 총 바이트 수 | bytes |
| Disk Read Requests | 1초동안 디스크 디바이스의 읽기 요청 수 | cnt |
| Disk Read Requests [Delta Avg] | 개별 Disk들의 system.diskio.read.count_delta의 평균 | cnt |
| Disk Read Requests [Delta Max] | 개별 Disk들의 system.diskio.read.count_delta의 최대 | cnt |
| Disk Read Requests [Delta Min] | 개별 Disk들의 system.diskio.read.count_delta의 최소 | cnt |
| Disk Read Requests [Delta Sum] | 개별 Disk들의 system.diskio.read.count_delta의 합 | cnt |
| Disk Read Requests [Success Delta] | 개별 Disk의 system.diskio.read.count 의 delta | cnt |
| Disk Read Requests [Success] | 성공적으로 완료된 총 읽기 수 | cnt |
| Disk Request Size [Avg] | 장치에 대해 실행된 요청의 평균 크기(단위: 섹터)입니다. | num |
| Disk Service Time [Avg] | 장치에 대해 실행된 입력 요청의 평균 서비스 시간(밀리초)입니다. | ms |
| Disk Wait Time [Avg] | 지원할 장치에 대해 실행된 요청에 소요된 평균 시간입니다. | ms |
| Disk Wait Time [Read] | 디스크 평균 대기 시간 | ms |
| Disk Wait Time [Write] | 디스크 평균 대기 시간 | ms |
| Disk Write Bytes [Delta Avg] | 개별 Disk들의 system.diskio.write.bytes_delta의 평균 | bytes |
| Disk Write Bytes [Delta Max] | 개별 Disk들의 system.diskio.write.bytes_delta의 최대 | bytes |
| Disk Write Bytes [Delta Min] | 개별 Disk들의 system.diskio.write.bytes_delta의 최소 | bytes |
| Disk Write Bytes [Delta Sum] | 개별 Disk들의 system.diskio.write.bytes_delta의 합 | bytes |
| Disk Write Bytes [Delta] | 개별 Disk의 system.diskio.write.bytes 값의 delta | bytes |
| Disk Write Bytes [Success] | 성공적으로 쓰여진 총 바이트 수 | bytes |
| Disk Write Requests | 1초동안 디스크 디바이스의 쓰기 요청 수 | cnt |
| Disk Write Requests [Delta Avg] | 개별 Disk들의 system.diskio.write.count_delta의 평균 | cnt |
| Disk Write Requests [Delta Max] | 개별 Disk들의 system.diskio.write.count_delta의 최대 | cnt |
| Disk Write Requests [Delta Min] | 개별 Disk들의 system.diskio.write.count_delta의 최소 | cnt |
| Disk Write Requests [Delta Sum] | 개별 Disk들의 system.diskio.write.count_delta의 합 | cnt |
| Disk Write Requests [Success Delta] | 개별 Disk의 system.diskio.write.count의 Delta | cnt |
| Disk Write Requests [Success] | 성공적으로 완료된 총 쓰기 수 | cnt |
| Disk Writes Bytes | 장치에 쓰는 초당 바이트 수 | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang 체크(정상:1, 비정상:0) | status |
| Filesystem Nodes | 파일 시스템의 총 파일 노드 수입니다. | cnt |
| Filesystem Nodes [Free] | 파일 시스템의 총 가용 파일 노드 수입니다. | cnt |
| Filesystem Size [Available] | 권한 없는 사용자가 사용할 수 있는 디스크 공간(바이트) | bytes |
| Filesystem Size [Free] | 사용 가능한 디스크 공간(bytes) | bytes |
| Filesystem Size [Total] | 총 디스크 공간(bytes) | bytes |
| Filesystem Usage | 사용한 디스크 공간 백분율 | % |
| Filesystem Usage [Avg] | 개별 filesystem.used.pct들의 평균 | % |
| Filesystem Usage [Inode] | iNode 사용률 | % |
| Filesystem Usage [Max] | 개별 filesystem.used.pct 중에 Max | % |
| Filesystem Usage [Min] | 개별 filesystem.used.pct 중에 Min | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | 사용한 디스크 공간(bytes) | bytes |
| Filesystem Used [Inode] | iNode 사용량 | bytes |
| Memory Free | 사용 가능한 총 메모리 양(bytes) | bytes |
| Memory Free [Actual] | 실제 사용가능한 Memory(bytes) | bytes |
| Memory Free [Swap] | 사용가능한 Swap memory | bytes |
| Memory Total | 총 Memory | bytes |
| Memory Total [Swap] | 총 Swap memory. | bytes |
| Memory Usage | 사용한 Memory의 백분율 | % |
| Memory Usage [Actual] | 실제 사용된 Memory의 백분율 | % |
| Memory Usage [Cache Swap] | cache 된 swap 사용률 | % |
| Memory Usage [Swap] | 사용한 Swap memory의 백분율 | % |
| Memory Used | 사용한 Memory | bytes |
| Memory Used [Actual] | 실제 사용된 Memory(bytes) | bytes |
| Memory Used [Swap] | 사용한 Swap memory | bytes |
| Collisions | 네트워크 충돌 | cnt |
| Network In Bytes | 수신된 byte 수 | bytes |
| Network In Bytes [Delta Avg] | 개별 Network들의 system.network.in.bytes_delta의 평균 | bytes |
| Network In Bytes [Delta Max] | 개별 Network들의 system.network.in.bytes_delta의 최대 | bytes |
| Network In Bytes [Delta Min] | 개별 Network들의 system.network.in.bytes_delta의 최소 | bytes |
| Network In Bytes [Delta Sum] | 개별 network 들의 system.network.in.bytes_delta의 합 | bytes |
| Network In Bytes [Delta] | 수신된 byte 수의 delta | bytes |
| Network In Dropped | 들어온 packet 중 삭제된 패킷의 수 | cnt |
| Network In Errors | 수신 중의 error 수 | cnt |
| Network In Packets | 수신된 packet 수 | cnt |
| Network In Packets [Delta Avg] | 개별 Network들의 system.network.in.packets_delta의 평균 | cnt |
| Network In Packets [Delta Max] | 개별 Network들의 system.network.in.packets_delta의 최대 | cnt |
| Network In Packets [Delta Min] | 개별 Network들의 system.network.in.packets_delta의 최소 | cnt |
| Network In Packets [Delta Sum] | 개별 Network들의 system.network.in.packets_delta의 합 | cnt |
| Network In Packets [Delta] | 수신된 packet 수의 delta | cnt |
| Network Out Bytes | 송신된 byte 수 | bytes |
| Network Out Bytes [Delta Avg] | 개별 Network들의 system.network.out.bytes_delta의 평균 | bytes |
| Network Out Bytes [Delta Max] | 개별 Network들의 system.network.out.bytes_delta의 최대 | bytes |
| Network Out Bytes [Delta Min] | 개별 Network들의 system.network.out.bytes_delta의 최소 | bytes |
| Network Out Bytes [Delta Sum] | 개별 Network들의 system.network.out.bytes_delta의 합 | bytes |
| Network Out Bytes [Delta] | 송신된 byte 수의 delta | bytes |
| Network Out Dropped | 나가는 packet 중 삭제된 packet 수 | cnt |
| Network Out Errors | 송신 중의 error 수 | cnt |
| Network Out Packets | 송신된 packet 수 | cnt |
| Network Out Packets [Delta Avg] | 개별 Network들의 system.network.out.packets_delta의 평균 | cnt |
| Network Out Packets [Delta Max] | 개별 Network들의 system.network.out.packets_delta의 최대 | cnt |
| Network Out Packets [Delta Min] | 개별 Network들의 system.network.out.packets_delta의 최소 | cnt |
| Network Out Packets [Delta Sum] | 개별 Network들의 system.network.out.packets_delta의 합 | cnt |
| Network Out Packets [Delta] | 송신된 packet 수의 delta | cnt |
| Open Connections [TCP] | 열려 있는 모든 TCP 연결 | cnt |
| Open Connections [UDP] | 열려 있는 모든 UDP 연결 | cnt |
| Port Usage | 접속가능한 port 사용률 | % |
| SYN Sent Sockets | SYN_SENT 상태의 소켓 수 (로컬에서 원격 접속시) | cnt |
| Kernel PID Max | kernel.pid_max 값 | cnt |
| Kernel Thread Max | kernel.threads-max 값 | cnt |
| Process CPU Usage | 마지막 업데이트 후 프로세스에서 소비한 CPU 시간의 백분율 | % |
| Process CPU Usage/Core | 마지막 이벤트 이후 프로세스에서 사용한 CPU 시간의 백분율 | % |
| Process Memory Usage | main memory(RAM) 에서 프로세스가 차지하는 비율 | % |
| Process Memory Used | Resident Set 사이즈. 프로세스가 RAM 에서 차지한 메모리 양 | bytes |
| Process PID | 프로세스 pid | pid |
| Process PPID | 부모 프로세스의 pid | pid |
| Processes [Dead] | deadProcesses 수 | cnt |
| Processes [Idle] | idle Processes 수 | cnt |
| Processes [Running] | running Processes 수 | cnt |
| Processes [Sleeping] | sleeping processes 수 | cnt |
| Processes [Stopped] | stopped processes 수 | cnt |
| Processes [Total] | 총 processes 수 | cnt |
| Processes [Unknown] | 상태를 검색할 수 없거나 알 수 없는 processes 수 | cnt |
| Processes [Zombie] | 좀비 processes 수 | cnt |
| Running Process Usage | process 사용률 | % |
| Running Processes | running processes 수 | cnt |
| Running Thread Usage | thread 사용률 | % |
| Running Threads | running processes 에서 실행중인 thread 수 총합 | cnt |
| Context Switches | context switch 수 (초당) | cnt |
| Load/Core [1 min] | 마지막 1 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [15 min] | 마지막 15 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [5 min] | 마지막 5 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Multipaths [Active] | 외장 스토리지 연결 path status = active 카운트 | cnt |
| Multipaths [Failed] | 외장 스토리지 연결 path status = failed 카운트 | cnt |
| Multipaths [Faulty] | 외장 스토리지 연결 path status = faulty 카운트 | cnt |
| NTP Offset last | sample의 measured offset (NTP 서버와 로컬환경 간의 시간 차이) | num |
| Run Queue Length | 실행 대기열 길이 | num |
| Uptime | OS 가동시간(uptime) (milliseconds) | ms |
| Context Switchies CPU | context switch 수(초당) | cnt |
| Disk Read Bytes [Sec] | windows logical 디스크에서 1초동안 읽어들인 바이트 수
| cnt |
| Disk Read Time [Avg] | 데이터 읽기 평균 시간(초)
| sec |
| Disk Transfer Time [Avg] | 디스크 average wait time (초)
| sec |
| Disk Write Bytes [Sec] | windows logical 디스크에서 1초동안 쓰여진 바이트 수
| cnt |
| Disk Write Time [Avg] | 데이터 쓰기 평균 시간 (초)
| sec |
| Pagingfile Usage | paging file 사용률
| % |
| Pool Used [Non Paged] | 커널 메모리 중 Nonpaged Pool 사용량
| bytes |
| Pool Used [Paged] | 커널 메모리 중 Paged Pool 사용량
| bytes |
| Process [Running] | 현재 동작 중인 프로세스 수
| cnt |
| Threads [Running] | 현재 동작 중인 thread 수
| cnt |
| Threads [Waiting] | 프로세서 시간을 기다리는 thread 수
| cnt |
표. Virtual Server 추가 모니터링 지표 (Agent 설치 필요)
1.1.3 - ServiceWatch 지표
Virtual Server는 ServiceWatch로 지표를 전송합니다. 기본 모니터링으로 제공되는 지표는 5분 주기로 수집된 데이터입니다. 세부 모니터링을 활성화하면, 1분 주기로 수집된 데이터를 확인할 수 있습니다.
참고
ServiceWatch에서 지표를 확인하는 방법은 ServiceWatch 가이드를 참고하세요.
Virtual Server의 세부 모니터링 활성화하는 방법은 How-to guides > ServiceWatch 세부 모니터링 활성화하기를 참고하세요.
기본 지표
다음은 네임스페이스 Virtual Server에 대한 기본 지표입니다.
| 성능 항목 | 상세 설명 | 단위 | 의미있는 통계 |
|---|---|---|---|
| Instance State | 인스턴스 상태 표시 | - | - |
| CPU Usage | CPU 사용률 | Percent |
|
| Disk Read Bytes | 블록 장치에서 읽은 용량(바이트) | Bytes |
|
| Disk Read Requests | 블록 장치에서의 읽기 요청 수 | Count |
|
| Disk Write Bytes | 블록 장치에서 쓰기 용량(바이트) | Bytes |
|
| Disk Write Requests | 블록 장치에서의 쓰기 요청 수 | Count |
|
| Network In Bytes | 네트워크 인터페이스에서 수신된 용량(바이트) | Bytes |
|
| Network In Dropped | 네트워크 인터페이스에서 수신된 패킷 드롭 수 | Count |
|
| Network In Packets | 네트워크 인터페이스에서 수신된 패킷 수 | Count |
|
| Network Out Bytes | 네트워크 인터페이스에서 전송된 용량(바이트) | Bytes |
|
| Network Out Dropped | 네트워크 인터페이스에서 전송된 패킷 드롭 수 | Count |
|
| Network Out Packets | 네트워크 인터페이스에서 전송된 패킷 수 | Count |
|
표. Virtual Server 기본 지표
참고
ServiceWatch Agent를 사용하여 지표를 수집하는 방법은 ServiceWatch Agent 가이드를 참고하세요.
1.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Virtual Server의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Virtual Server 생성하기
Samsung Cloud Platform Console에서 Virtual Server 서비스를 생성하여 사용할 수 있습니다.
Virtual Server를 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 생성 버튼을 클릭하세요. Virtual Server 생성 페이지로 이동합니다.
- Virtual Server 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- Image 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 Image 필수 제공하는 Image 종류 선택 - 표준: Samsung Cloud Platform 표준 제공 Image
- Alma Linux, Oracle Linux, RHEL, Rocky Linux, Ubuntu, Windows
- Custom: 사용자 생성 Image
- Kubernetes: Kubernetes용 Image
- RHEL, Ubuntu
- Marketplace: Marketplace에서 구독한 Image
Image 버전 필수 선택한 Image의 버전 선택 - 제공하는 서버 Image의 버전 리스트 제공
표. Virtual Server Image 및 버전 선택 입력 항목 - 표준: Samsung Cloud Platform 표준 제공 Image
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버 수 필수 동시 생성할 서버 수 - 숫자만 입력 가능하며 1~100 사이의 값 입력
서비스 유형 > 서버 타입 필수 Virtual Server 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: Standard 이상의 대용량 서버 사양
- Virtual Server에서 제공하는 서버 타입에 대한 자세한 내용은 Virtual Server 서버 타입을 참고
서비스 유형 > Planned Compute 필수 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 생성 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기를 참고
Block Storage 필수 용도에 따라 서버가 사용하는 Block Storage 설정 - 기본 OS: OS가 설치되어 사용되는 영역
- 용량은 Units 단위로 입력하며, OS Image 종류에 따라 최소 용량이 다름
- Alma Linux: 2~1,536 사이의 값을 입력
- Oracle Linux: 7~1,536 사이의 값을 입력
- RHEL: 2~1,536 사이의 값을 입력
- Rocky Linux: 2~1,536 사이의 값을 입력
- Ubuntu: 2~1,536 사이의 값을 입력
- Windows: 4~1,536 사이의 값을 입력
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS(Key Management Service) 암호화키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 적용 가능하고, 생성 후 변경 불가
- SSD_KMS 디스크 유형을 사용하는 경우에는 성능 저하가 발생
- 용량은 Units 단위로 입력하며, OS Image 종류에 따라 최소 용량이 다름
- 추가: OS영역 외 사용자 추가 공간 필요 시 사용
- 사용을 선택한 후, 스토리지의 유형과 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭(최대 25개까지 추가)
- 용량은 Units 단위로 입력하며, 1~1,536 사이의 값을 입력
- 1 Unit은 8GB이므로 8 ~ 12,288GB가 생성됨
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS(Key Management Service) 암호화키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 적용 가능하고, 생성 후 변경 불가
- SSD_KMS 디스크 유형을 사용하는 경우에는 성능 저하가 발생할 수 있음
- SSD_MultiAttach: 2개 이상의 서버 연결이 가능한 볼륨
- Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고
- Delete on termination: Delete on Termination 선택 시, 서버를 해지하면 해당 Volume이 같이 해지
- Snapshot이 존재하는 볼륨은 Delete on termination이 사용 일 때도 삭제되지 않음
- Multi attach 볼륨은 삭제하려는 서버가 볼륨에 연결된 마지막 남은 서버일 때만 삭제
Server Group 선택 동일 Server Group에 소속된 서버를 Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치) 설정 - 사용을 선택한 후, Server Group을 선택
- 신규 생성을 선택하여 Server Group 생성
- 동일 Server Group에 소속된 서버를 선택한 정책에 따라 Best Effort 방식으로 배치
- 정책은 Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치) 중 선택
표. Virtual Server 서비스 정보 입력 항목
- Image 및 버전 선택 영역에서 필요한 정보를 선택하세요.
주의
- Server Group 정책 중 Partition(Virtual Server와 Block Storage 분산배치) 정책을 사용할 경우, Virtual Server 생성 이후 Block Storage Volume 추가 할당이 불가하오니, Virtual Server 생성 단계에서 필요한 Block Storage를 모두 생성하세요.
* **필수 정보 입력** 영역에서 필요한 정보를 입력 또는 선택하세요.
| 구분 | 필수 여부 | 상세 설명 |
|---|---|---|
| 서버명 | 필수 | 선택한 서버 수가 1인 경우에 서버 구별을 위한 이름 입력
|
| 네트워크설정 > 신규 네트워크 포트 생성 | 필수 | Virtual Server가 설치될 네트워크를 설정
|
| 네트워크설정 > 기존 네트워크 포트 지정 | 필수 | Virtual Server가 설치될 네트워크를 설정
|
| Keypair | 필수 | 서버에 연결할 때 사용할 사용자 증명 방법
|
표. Virtual Server 필수 정보 입력 항목
| 구분 | 필수 여부 | 상세 설명 |
|---|---|---|
| Lock | 선택 | Lock 사용 여부 설정
|
| Init script | 선택 | 서버 시작 시, 실행하는 스크립트
|
| 태그 | 선택 | 태그 추가
|
표. Virtual Server 추가 정보 입력 항목
안내
서버명 입력 시 공백과 특수문자 (_) 사용할 경우 OS의 hostname은 공백과 특수문자 (_)가 특수문자 (-)로 변경되어 설정됩니다. OS의 hostname 설정 시 참고하세요.
- 예시: 서버명이 ‘server name_01’ 인 경우 OS의 hostname은 ‘server-name-01’로 설정됩니다.
참고
- Rocky Linux, Oracle Linux로 Virtual Server를 생성한 경우 시간 동기화(NTP:Network Time Protocol)를 위해 추가 설정이 필요합니다. 자세한 내용은 Linux NTP 설정하기를 참고하세요.
- 2025년 7월 이전 RHEL 및 Windows Server를 생성한 경우 RHEL Repository 및 WKMS(Windows Key Management Service) 설정 수정이 필요합니다. 자세한 내용은 RHEL Repo 및 WKMS 설정하기를 참고하세요.
Virtual Server 상세 정보 확인하기
Virtual Server 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Virtual Server 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Virtual Server 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
- Virtual Server 부가 기능에 대한 자세한 내용은 Virtual Server 관리 부가 기능을 참고하세요.
구분 상세 설명 Virtual Server 상태 사용자가 생성한 Virtual Server의 상태 - Build: Build 명령이 전달된 상태
- Building: Build 진행중
- Networking: 서버 생성 진행중 프로세스
- Scheduling: 서버 생성 진행중 프로세스
- Block_Device_Mapping: 서버 생성시 Block Storage 연결중
- Spawning: 서버 생성 프로세스가 진행중인 상태
- Active: 사용 가능한 상태
- Powering_off: 중지 요청시 상태
- Deleting: 서버 삭제 진행중
- Reboot_Started: Reboot 진행중 상태
- Error: 에러 상태
- Migrating: 다른 호스트로 서버가 Migration 되는 상태
- Reboot: Reboot 명령이 전달된 상태
- Rebooting: 재시작 진행중
- Rebuild: Rebuild 명령이 전달된 상태
- Rebuilding: Rebuild 요청시 상태
- Rebuild_Spawning: Rebuild 프로세스가 진행중인 상태
- Resize: Resize 명령이 전달된 상태
- Resizing: Resize 진행중
- Resize_Prep: 서버 타입 수정 요청시 상태
- Resize_Migrating: 서버가 Resize 진행 동시에 다른 호스토로 이동중인 상태
- Resize_Migrated: 서버가 Resize 진행 동시에 다른 호스트로 이동 완료된 상태
- Resize_Finish: Resize가 완료됨
- Revert_Resize: 어떤 이유로 서버의 Resize 또는 마이그레이션 실패. 대상 서버가 정리되고 원래 원본 서버가 다시 시작됨
- Shutoff: Powering off 완료 시 상태
- Verity_ Resize: 서버 타입 수정 요청에 따라 Resize_Prep 진행 이후, 서버 타입 확정/서버 타입 원복 선택 가능 상태
- Resize_Reverting: 서버 타입 원복 요청 시 상태
- Resize_Confirming: 서버의 Resize 요청을 확인중인 상태
서버 제어 서버 상태를 변경할 수 있는 버튼 - 시작: 중지된 서버를 시작
- 중지: 가동 중인 서버를 중지
- 재시작: 가동 중인 서버를 재시작
Image 생성 현재 서버의 Image로 사용자 Image 생성 - 자세한 Image 생성 방법은 Image 생성하기를 참고
콘솔 로그 현재 서버의 콘솔 로그 조회 - 현재 서버에서 출력되는 콘솔 로그를 확인할 수 있음. 자세한 내용은 콘솔 로그 확인하기를 참고
Dump 생성 현재 서버의 Dump를 생성 - Dump 파일은 Virtual Server 안에 생성됨
- 자세한 Dump 생성 방법은 Dump 생성하기를 참고
Rebuild 기존 Virtual Server의 OS 영역 데이터와 설정이 삭제되고, 새로운 서버로 Rebuild하여 구성 - 자세한 내용은 Rebuild 수행하기를 참고
서비스 해지 서비스를 해지하는 버튼 표. Virtual Server 상태 정보 및 부가 기능
상세 정보
Virtual Server 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 서버명 | 서버 이름
|
| 서버 타입 | vCPU, 메모리 정보 표시
|
| Image명 | 서버의 OS Image 및 버전
|
| Lock | Lock 사용/미사용 여부 표시
|
| 서버 그룹 | 서버가 속한 서버 그룹명
|
| Keypair명 | 사용자가 설정한 서버 인증 정보
|
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| LLM Endpoint | LLM 이용을 위한 URL
|
| ServiceWatch 세부 모니터링 | ServiceWatch 세부 모니터링 활성화 여부 표시
|
| 네트워크 | Virtual Server의 네트워크 정보
|
| 로컬 Subnet | Virtual Server의 로컬 Subnet 정보
|
| Block Storage | 서버에 연결된 Block Storage 정보
|
표. Virtual Server 상세 정보 탭 항목
태그
Virtual Server 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Virtual Server 태그 탭 항목
작업 이력
Virtual Server 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Virtual Server 작업 이력 탭 상세 정보 항목
Virtual Server 가동 제어하기
생성된 Virtual Server 자원의 가동 제어가 필요한 경우, Virtual Server 목록 또는 Virtual Server 상세 페이지에서 작업을 수행할 수 있습니다. 가동 중인 서버의 시작, 중지, 재시작을 할 수 있습니다.
Virtual Server 시작하기
중지(Shutoff)된 Virtual Server를 시작할 수 있습니다. Virtual Server를 시작하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 중지(Shutoff)된 서버 중 시작할 자원을 클릭하여, Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 시작할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 시작 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- Virtual Server 상세 페이지에서 상단의 시작 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- Virtual Server 시작이 완료되면 서버 상태가 Shutoff에서 Active로 변경됩니다.
- Virtual Server 상태에 대한 자세한 내용은 Virtual Server 상세 정보 확인하기를 참고하세요.
Virtual Server 중지하기
가동(Active)중인 Virtual Server를 중지할 수 있습니다. Virtual Server를 중지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 가동(Active) 중인 서버 중 중지할 자원을 클릭하여, Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 중지할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 중지 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- Virtual Server 상세 페이지에서 상단의 중지 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- Virtual Server 중지가 완료되면 서버 상태가 Active에서 Shutoff로 변경됩니다.
- Virtual Server 상태에 대한 자세한 내용은 Virtual Server 상세 정보 확인하기를 참고하세요.
Virtual Server 재시작하기
생성된 Virtual Server를 재시작할 수 있습니다. Virtual Server를 재시작하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 재시작할 자원을 클릭하여, Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 재시작할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 재시작 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- Virtual Server 상세 페이지에서 상단의 재시작 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- Virtual Server 재시작 중에는 서버 상태가 Rebooting을 거쳐 최종 Active로 변경됩니다.
- Virtual Server 상태에 대한 자세한 내용은 Virtual Server 상세 정보 확인하기를 참고하세요.
Virtual Server 자원 관리하기
생성된 Virtual Server 자원의 서버 제어 및 관리 기능이 필요한 경우, Virtual Server 목록 또는 Virtual Server 상세 페이지에서 작업을 수행할 수 있습니다.
Image 생성하기
가동 중인 Virtual Server의 Image를 생성할 수 있습니다.
참고
해당 내용은 가동 중인 Virtual Server로 사용자 Image를 생성하는 방법을 안내하고 있습니다.
- Virtual Server 목록 또는 Virtual Server 상세 페이지에서 Image 생성 버튼을 클릭하여 사용자 Image를 생성합니다.
- 사용자의 보유한 Image 파일을 업로드하여 Image 생성하는 방식은 Image 상세 가이드 내 Image 생성하기를 참고하세요.
Virtual Server의 Image를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
Virtual Server 목록 페이지에서 Image 생성할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
Virtual Server 상세 페이지에서 Image 생성 버튼을 클릭하세요. Image 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
구분 필수 여부상세 설명 Image명 필수 생성할 Image의 이름 - 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 200자 이내로 입력
표. Image 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
입력 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, 모든 서비스 > Compute > Virtual Server > Image 목록 페이지에서 생성한 자원을 확인하세요.
안내
- Image를 생성하면 생성된 Image를 내부 저장소로 사용되는 Object Storage에 저장하게 됩니다. 따라서 Image 저장에 대한 사용 요금이 부과됩니다.
- Active 상태인 Virtual Server로부터 생성된 Image의 파일 시스템은 무결성을 보장할 수 없으므로 서버 정지 후 Image 생성을 권장합니다.
서버 타입 수정하기
Virtual Server 서버의 서버 타입을 수정할 수 있습니다.
참고
Virtual Server에서 제공하는 변경 가능한 서버 타입에 대해서는 Virtual Server 서버 타입을 참고하세요.
Virtual Server의 서버 타입 수정을 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 가동 제어할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 서버 상태를 확인하고, 서버 타입 수정 버튼을 클릭하세요. 서버 타입 수정 팝업창이 열립니다.
- 서버 타입 수정 팝업창에서 서버 타입을 변경한 뒤, 확인 버튼을 클릭하세요.
- Virtual Server 서버 타입을 수정하면, Virtual Server 상태가 Resize 수행 관련 상태로 변경됩니다.
- Virtual Server 상태에 대한 자세한 내용은 Virtual Server 상세 정보 확인하기를 참고하세요.
참고
Virtual Server 서버 타입을 변경하면, 모니터링 성능 지표 데이터가 잠시동안 정상적으로 수집되지 않을 수 있습니다. 다음 수집 주기(1분)에는 정상적인 성능 지표가 수집됩니다.
IP 변경하기
IP 변경하는 방법은 IP 변경하기를 참고하세요.
주의
- IP 변경을 진행하면 더 이상 해당 IP로 통신할 수 없으며, 진행 중에는 IP 변경을 취소할 수 없습니다.
- 변경된 IP를 적용하기 위해 서버가 재부팅 됩니다.
- Load Balancer 서비스 중인 서버일 경우, LB 서버 그룹에서 기존 IP를 삭제하고 변경된 IP를 LB 서버 그룹의 멤버로 직접 추가해야 합니다.
- Public NAT/Private NAT를 사용 중인 서버는 IP 변경 후, Public NAT/Private NAT의 사용을 해제하고 다시 설정해야 합니다.
- Public NAT/Private NAT를 사용 중인 경우에는 먼저 Public NAT/Private NAT의 사용을 해제하고 IP 변경을 완료한 후, 다시 설정하세요.
- Public NAT/Private NAT의 사용 여부는 Virtual Server 상세 페이지에서 Public NAT IP/Private NAT IP의 수정 버튼을 클릭하여 변경할 수 있습니다.
ServiceWatch 세부 모니터링 활성화하기
기본적으로 Virtual Server는 ServiceWatch와 기본 모니터링으로 연계되어 있습니다. 필요에 따라 세부 모니터링을 활성화하여 운영 문제를 보다 신속하게 식별하고 조치를 취할 수 있습니다. ServiceWatch에 대한 자세한 내용은 ServiceWatch 개요를 참조하세요.
주의
기본 모니터링은 무료로 제공되지만, 세부 모니터링을 활성화하면 추가 요금이 부과됩니다. 이용에 유의하세요.
Virtual Server의 ServiceWatch 세부 모니터링 활성화하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 ServiceWatch 세부 모니터링 활성화할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 ServiceWatch 세부 모니터링 수정 버튼을 클릭하세요. ServiceWatch 세부 모니터링 수정 팝업창으로 이동합니다.
- ServiceWatch 세부 모니터링 수정 팝업창에서 활성화 선택한 후, 안내 문구를 확인하고 확인 버튼을 클릭하세요.
- Virtual Server 상세 페이지에서 ServiceWatch 세부 모니터링 항목을 확인하세요.
ServiceWatch 세부 모니터링 비활성화 하기
주의
비용 효율화를 위해 세부 모니터링 비활성화가 필요합니다. 반드시 필요한 경우에만 세부 모니터링을 활성화를 유지하고, 나머지는 세부 모니터링을 비활성화하세요.
Virtual Server의 ServiceWatch 세부 모니터링 비활성화하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 ServiceWatch 세부 모니터링 비활성화할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 ServiceWatch 세부 모니터링 수정 버튼을 클릭하세요. ServiceWatch 세부 모니터링 수정 팝업창으로 이동합니다.
- ServiceWatch 세부 모니터링 수정 팝업창에서 활성화 선택 해제한 후, 안내 문구를 확인하고 확인 버튼을 클릭하세요.
- Virtual Server 상세 페이지에서 ServiceWatch 세부 모니터링 항목을 확인하세요.
Virtual Server 관리 부가 기능
Virtual Server 서버 관리를 위해 콘솔 로그 조회, Dump 생성, Rebuild를 할 수 있습니다. Virtual Server의 콘솔 로그 조회, Dump 생성, Rebuild를 하려면 다음 절차를 따르세요.
콘솔 로그 확인하기
Virtual Server의 현재 콘솔 로그를 확인할 수 있습니다.
Virtual Server의 콘솔 로그 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 콘솔 로그를 확인할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 콘솔 로그 버튼을 클릭하세요. 콘솔 로그 팝업창으로 이동합니다.
- 콘솔 로그 팝업창에서 출력된 콘솔 로그를 확인합니다.
Dump 생성하기
Virtual Server의 Dump 파일을 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 Dump 생성 버튼을 클릭하세요.
- Dump 파일은 Virtual Server 안에 생성됩니다.
Rebuild 수행하기
기존 Virtual Server 서버의 OS영역 데이터와 설정을 삭제하고, 새로운 서버로 Rebuild하여 구성할 수 있습니다.
Virtual Server의 Rebuild를 수행하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 Rebuild를 수행할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 Rebuild 버튼을 클릭하세요.
- Virtual Server Rebuild 중에는 서버 상태가 Rebuilding로 변경되었다가 Rebuild가 완료되면 Rebuild 수행 전 상태로 돌아옵니다.
- Virtual Server 상태에 대한 자세한 내용은 Virtual Server 상세 정보 확인하기를 참고하세요.
Virtual Server 해지하기
사용하지 않는 Virtual Server를 해지하면 운영 비용을 절감할 수 있습니다. 단, Virtual Server를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 해지 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Virtual Server를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 연결된 스토리지의 해지는 Delete on termination 설정에 따라 다르오니, 해지 제약 사항을 참고하세요.
- 해지가 완료되면, Virtual Server 목록 페이지에서 자원이 해지되었는지 확인하세요.
해지 제약 사항
Virtual Server 해지 요청 시 해지가 불가한 경우에는 팝업창으로 안내합니다. 아래 케이스를 참고하세요.
해지 불가
- File Storage가 연결된 경우: File Storage 연결을 먼저 해지하세요.
- LB 서버 그룹이 연결된 경우: LB 서버 그룹Pool 연결을 먼저 해제하세요.
- Lock이 설정된 경우: Lock 설정을 미사용으로 변경한 후, 다시 시도하세요.
- Backup이 연결된 경우: Backup 연결을 먼저 해제하세요.
- Virtual Server에 연결된 Auto-Scaling Group이 In Service 상태가 아닌 경우: 연결된 Auto-Scaling Group의 상태를 변경한 후, 다시 시도하세요.
연결된 스토리지의 해지는 Delete on termination 설정에 따라 다르니 참고하세요.
Delete on termination 설정 별 삭제
- Delete on termination 설정 여부에 따라 볼륨 삭제 여부도 달라집니다.
- Delete on termination 미설정 시: Virtual Server를 해지해도 해당 볼륨이 삭제되지 않습니다.
- Delete on termination 설정 시: Virtual Server를 해지하면 해당 볼륨이 삭제됩니다.
- Snapshot이 존재하는 볼륨은 Delete on termination이 설정되어도 삭제되지 않습니다.
- Multi attach 볼륨은 삭제하려는 서버가 볼륨에 연결된 마지막 남은 서버일 때만 삭제됩니다.
1.2.1 - Image
사용자는 Samsung Cloud Platform Console을 통해 Virtual Server 서비스 내 Image 서비스의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Image 생성하기
Samsung Cloud Platform Console에서 Virtual Server 서비스를 사용하면서 Image 서비스를 생성하여 사용할 수 있습니다.
Image를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
Image 목록 페이지에서 Image 생성 버튼을 클릭하세요. Image 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Image명 필수 생성할 Image의 이름 - 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 255자 이내로 입력
Image 파일 > URL 필수 Object Storage 에 Image 파일을 업로드 한 후 URL 입력 - Object Storage 상세 페이지에서 URL을 복사 가능
- Image 파일을 업로드한 Object Storage의 Bucket은 생성할 서버와 동일한 존(Zone) 존재
- Image 파일은 .qcow2 확장자만 가능
- 안전한 Image 파일을 업로드하여 보안 위험을 최소화해야 함.
OS 타입 필수 업로드한 Image 파일의 OS 타입 - Alma Linux, CentOS, Oracle Linux, RHEL, Rocky Linux, Ubuntu 중 선택
최소 디스크 필수 생성할 Image의 최소 디스크 용량(GB) 0~12,288GB 사이의 값을 입력
최소 RAM 필수 생성할 Image의 최소 RAM 용량(GB) 0~2,097,151GB 사이의 값을 입력
Visibility 필수 Image에 대한 접근 권한을 표시 - Private: Account 내에서만 사용이 가능
- Shared: Account 간 공유가 가능
Protected 선택 Image 삭제 불가 여부를 선택 - 사용을 체크하면 Image를 실수로 삭제하지 않도록 방지
- 해당 설정은 Image 생성 이후 변경
표. Image 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Image 추가 정보 입력 항목
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Image 목록 페이지에서 생성한 자원을 확인하세요.
Image 상세 정보 확인하기
Image 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Image 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Image 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Image 상세 페이지로 이동합니다.
- Image 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 Image 상태 사용자가 생성한 Image의 상태 - Active: 사용 가능한 상태
- Queued: Image 생성 요청 시, Image가 업로드 되어 처리 대기 중인 상태
- Importing: Image 생성 요청 시, Image가 업로드 되어 처리 중인 상태
공유용 Image 생성 다른 Account로 공유할 Image 생성 - Image의 Visibility가 private 상태이고 Image에 스냅샷 정보가 있는 경우에만 생성 가능
다른 Account로 공유 Image를 다른 Account로 공유 가능 - Image의 Visibility가 Shared 상태일 경우 다른 Account로 공유 가능
- 공유용 Image 생성 또는 qcow2 확장자 파일을 업로드하여 생성한 Image에만 표시
Image 삭제 Image를 삭제하는 버튼 - Image를 삭제하면 복구 불가
표. Image 상태 정보 및 부가 기능
- Image 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Image 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | Image 이름 |
| 자원 ID | Image의 고유 자원 ID |
| 생성자 | Image를 생성한 사용자 |
| 생성 일시 | Image를 생성한 일시 |
| 수정자 | Image 정보를 수정한 사용자 |
| 수정 일시 | Image 정보를 수정한 일시 |
| Image명 | Image 이름 |
| 최소 디스크 | Image의 최소 디스크 용량(GB)
|
| 최소 RAM | Image의 최소 RAM 용량(GB) |
| OS 타입 | Image의 OS 타입
|
| OS hash algorithm | OS hash algorithm 방식 |
| Visibility | Image에 대한 접근 권한을 표시
|
| Protected | Image 삭제 불가 여부를 선택
|
| Image 크기 | Image의 크기
|
| Image 유형 | Image 생성 방법에 따른 구분
|
| Image 파일 URL | Image 생성 시 Object Storage에 업로드 한 Image 파일 URL
|
| 공유 현황 | 다른 Account로 Image를 공유하고 있는 현황
|
표. Image 상세 정보 탭 항목
태그
Image 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Image 태그 탭 항목
작업 이력
Image 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Image 작업 이력 탭 상세 정보 항목
Image 자원 관리하기
생성된 Image 의 제어 및 관리 기능을 설명합니다.
공유용 Image 생성하기
다른 Account로 공유할 Image 생성합니다.
안내
- Image의 Visibility가 private 상태이고 Image에 스냅샷 정보가 있는 경우에만 공유용 Image를 생성할 수 있습니다.
- 공유용 Image는 OS영역 디스크 볼륨 1개만 이미지화 대상에 포함됩니다. 추가로 연결된 데이터 볼륨은 Image에 포함되지 않으므로, 필요한 경우 별도의 볼륨으로 데이터 복사 후 볼륨 이전 기능을 활용해주세요.
공유용 Image를 생성하려면 다음 절차를 따르세요.
- 공유할 Account에 접속하여 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 공유용 Image를 생성할 Image를 클릭하세요. Image 상세 페이지로 이동합니다.
- 공유용 Image 생성 버튼을 클릭하세요. 공유용 Image 생성을 알리는 팝업창이 열립니다.
- 알림 내용을 확인한 후, 완료 버튼을 클릭하세요.
다른 Account로 Image 공유하기
다른 Account로 공유할 Image 생성합니다.
안내
- .qcow2 확장자 파일을 업로드하여 생성하거나 Image 상세 페이지에서 공유용 Image 생성으로 생성한 Image만 다른 Account로 공유할 수 있습니다.
- 공유할 Image의 Visibility가 Shared이어야 합니다.
Image를 다른 Account로 공유하려면 다음 절차를 따르세요.
공유할 Account에 접속하여 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
Image 목록 페이지에서 다른 Account로 공유할 Image를 클릭하세요. Image 상세 페이지로 이동합니다.
다른 Account로 공유 버튼을 클릭하세요. Image 공유를 알리는 팝업창이 열립니다.
알림 내용을 확인한 후, 확인 버튼을 클릭하세요. 다른 Account로 Image 공유 페이지로 이동합니다.
다른 Account로 Image 공유 페이지에서 공유 Account ID를 입력하고 완료 버튼을 클릭하세요. Image 공유를 알리는 팝업창이 열립니다.
구분 필수 여부상세 설명 Image명 - 공유할 Image의 이름 - 입력 불가
Image ID - 공유할 Image ID - 입력 불가
공유 Account ID 필수 공유할 다른 Account ID 입력 - 영문, 숫자, 특수문자
-를 사용하여 64자 이내로 입력
표. 다른 Account로 Image 공유 항목알림 내용을 확인한 후, 확인 버튼을 클릭하세요. Image 상세 페이지의 공유 현황에서 정보를 확인할 수 있습니다.
- 최초 요청 시에는 상태가 Pending 이고, 공유 받을 Account에서 승인이 완료되면 Accepted, 승인이 거부되면 Rejected로 변경됩니다.
다른 Account에서 공유한 Image 공유받기
Image를 다른 Account로부터 공유 받으려면 다음 절차를 따르세요.
공유 받을 Account에 접속하여 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
Image 목록 페이지에서 더보기 > Image 공유 요청 목록 버튼을 클릭하세요. Image 공유 요청 목록 팝업창이 열립니다.
Image 공유 요청 목록 팝업창에서 공유 받을 Image의 승인 또는 거부 버튼을 클릭하세요.
구분 상세 설명 Image명 공유 Image의 이름 OS 타입 공유 Image의 OS 타입 Owner Account ID 공유 Image의 Owner Account ID 생성 일시 공유 Image의 생성 일시 승인 해당 공유 Image를 승인 처리 거부 해당 공유 Image를 거부 처리 표. Image 공유 요청 목록 항목알림 내용을 확인한 후, 확인 버튼을 클릭하세요. Image 목록에서 공유받은 Image를 확인할 수 있습니다.
Image 삭제하기
사용하지 않는 Image를 삭제할 수 있습니다. 단, Image를 삭제하면 복구할 수 없으므로 Image 삭제 시에는 발생하는 영향을 충분히 고려한 후 삭제 작업을 진행해야 합니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Image를 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 삭제할 자원을 선택하고, 삭제 버튼을 클릭하세요.
- Image 목록 페이지에서 다수의 Image 체크 박스를 선택하고, 자원 목록 상단의 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Image 목록 페이지에서 자원이 삭제되었는지 확인하세요.
1.2.2 - Keypair
사용자는 Samsung Cloud Platform Console을 통해 Virtual Server 서비스 내 Keypair의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Keypair 생성하기
Samsung Cloud Platform Console에서 Virtual Server 서비스를 사용하면서 Keypair 서비스를 생성하여 사용할 수 있습니다.
Keypair 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 Keypair 생성 버튼을 클릭하세요. Keypair 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
구분 필수 여부상세 설명 Keypair명 필수 생성할 Keypair의 이름 - 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 255자 이내로 입력
Keypair 유형 필수 ssh 표. Keypair 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Keypair 추가 정보 입력 항목주의- 생성 완료 후 최초 1회에 한해서 Key를 다운로드할 수 있습니다. 재발급이 불가능하므로, 다운로드 되었는지 확인하세요.
- 다운로드 받은 Private Key는 안전한 곳에 저장하세요.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
- 입력 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Keypair 목록 페이지에서 생성한 자원을 확인하세요.
Keypair 상세 정보 확인하기
Keypair 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Keypair 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Keypair 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Keypair 상세 페이지로 이동합니다.
- Keypair 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Keypair 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | Keypair 이름 |
| 자원 ID | Keypair의 고유 자원 ID |
| 생성자 | Keypair를 생성한 사용자 |
| 생성 일시 | Keypair를 생성한 일시 |
| 수정자 | Keypair 정보를 수정한 사용자 |
| 수정 일시 | Keypair정보를 수정한 일시 |
| Keypair명 | Keypair 이름 |
| Fingerprint | Key를 식별하기 위한 고유한 값 |
| 사용자 ID | Keypair 생성한 사용자 ID |
| 공개 키 | 공개 키 정보 |
표. Keypair 상세 정보 탭 항목
태그
Keypair 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Keypair 태그 탭 항목
작업 이력
Keypair 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Keypair 작업 이력 탭 상세 정보 항목
Keypair 자원 관리하기
Keypair의 제어 및 관리 기능을 설명합니다.
공개 키 가져오기
공개 키 가져오기를 하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
Keypair 목록 페이지에서 상단의 더보기 버튼을 클릭하여 공개 키 가져오기 버튼을 클릭하세요. 공개 키 가져오기 페이지로 이동합니다.
- 필수 정보 입력 영역에 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Keypair명 필수 생성할 Keypair 이름 Keypair 유형 필수 ssh 공개 키 필수 공개 키 입력 - 파일 불러오기: 파일 첨부 버튼을 선택하여 공개 키 파일을 첨부
- 첨부 파일은 다음의 확장자 파일(.pem)만 가능
- 공개 키 입력: 복사한 공개 키 값을 붙여넣기
- Keypair 상세 페이지에서 공개 키 값을 복사 가능
표. 공개 키 가져오기 필수 입력 항목 - 파일 불러오기: 파일 첨부 버튼을 선택하여 공개 키 파일을 첨부
- 필수 정보 입력 영역에 필요한 정보를 입력 또는 선택하세요.
입력한 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Keypair 목록 페이지에서 생성한 자원을 확인하세요.
Keypair 삭제하기
사용하지 않는 Keypair를 삭제할 수 있습니다. 단, Keypair를 삭제하면 복구할 수 없으므로 사전에 충분한 영향도 검토 후 삭제를 진행하시기 바랍니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Keypair를 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 삭제할 자원을 선택하고, 삭제 버튼을 클릭하세요.
- Keypair 목록 페이지에서 다수의 Keypair 체크 박스를 선택하고, 자원 목록 상단의 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Keypair 목록 페이지에서 자원이 삭제되었는지 확인하세요.
1.2.3 - Server Group
사용자는 Samsung Cloud Platform Console을 통해 Virtual Server 서비스 내 Server Group의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Server Group 생성하기
Samsung Cloud Platform Console에서 Virtual Server 서비스를 사용하면서 Server Group 서비스를 생성하여 사용할 수 있습니다.
Server Group 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Server Group 페이지에서 Server Group 메뉴를 클릭하세요. Server Group 목록 페이지로 이동합니다.
- Server Group 목록 페이지에서 Server Group 생성 버튼을 클릭하세요. Server Group 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Server Group 명 필수 생성할 Server Group의 이름 - 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 255자 이내로 입력
정책 필수 동일 Server Group 에 소속된 Virtual Server를 Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치) 설정 - Anti-Affinity(분산배치) 및 Affinity(근접배치) 정책은 동일 Server Group에 소속된 Virtual Server를 선택한 정책에 기반하여 Best Effort 방식으로 배치되나, 절대적으로 보장되지는 않음.
- Anti-Affinity(분산배치): 하나의 Server Group에 속한 서버들을 가급적 다른 랙 및 호스트에 배치시키는 정책
- Affinity(근접배치): 하나의 Server Group에 속한 서버들을 가급적 같은 랙 및 호스트 내에 근접하게 배치시키는 정책
- Partition(Virtual Server와 Block Storage 분산배치): 하나의 Server Group에 속한 Virtual Server와 해당 서버에 연결된 Block Storage를 서로 다른 분산 단위(Partition)에 배치시키는 정책
- Partition(Virtual Server와 Block Storage 분산배치) 정책은 각 Virtual Server와 해당 서버에 속한 Block Storage가 어느 Partition에 속해 있는지 명확히 확인할 수 있도록 Partition 번호를 함께 표시합니다.
- Partition 번호는 해당 Server Group에 설정된 Partition Size(최대 3)를 기준으로 부여됩니다.
표. Server Group 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Server Group 추가 정보 입력 항목
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
- 입력 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Server Group 목록 페이지에서 생성한 자원을 확인하세요.
Server Group 상세 정보 확인하기
Server Group 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Server Group 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Server Group 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Server Group 메뉴를 클릭하세요. Server Group 목록 페이지로 이동합니다.
- Server Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Server Group 상세 페이지로 이동합니다.
- Server Group 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Server Group 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | Server Group 이름 |
| 자원 ID | Server Group의 고유 자원 ID |
| 생성자 | Server Group을 생성한 사용자 |
| 생성 일시 | Server Group을 생성한 일시 |
| Server Group명 | Server Group 이름 |
| 정책 | Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치) |
| Server Group 멤버 | Server Group에 속한 Virtual Server 목록
|
표. Server Group 상세 정보 탭 항목
태그
Server Group 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Server Group 태그 탭 항목
작업 이력
Server Group 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Server Group 작업 이력 탭 상세 정보 항목
Server Group 삭제하기
사용하지 않는 Server Group을 삭제할 수 있습니다. 단, Server Group을 삭제하면 복구할 수 없으므로 사전에 충분한 영향도 검토 후 삭제를 진행하시기 바랍니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Server Group을 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Server Group 메뉴를 클릭하세요. Server Group 목록 페이지로 이동합니다.
- Server Group 목록 페이지에서 삭제할 자원을 선택하고, 삭제 버튼을 클릭하세요.
- Server Group 목록 페이지에서 다수의 Server Group 체크 박스를 선택하고, 자원 목록 상단의 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Server Group 목록 페이지에서 자원이 삭제되었는지 확인하세요.
1.2.4 - IP 변경하기
Virtual Server의 IP를 변경하고 Virtual Server의 네트워크 포트를 추가하여 IP 설정할 수 있습니다.
IP 변경하기
Virtual Server의 IP를 변경할 수 있습니다.
주의
- IP 변경을 진행하면 더 이상 해당 IP로 통신할 수 없으며, 진행 중에는 IP 변경을 취소할 수 없습니다.
- 변경된 IP를 적용하기 위해 서버가 재부팅 됩니다.
- Load Balancer 서비스 중인 서버일 경우, LB 서버 그룹에서 기존 IP를 삭제하고 변경된 IP를 LB 서버 그룹의 멤버로 직접 추가해야 합니다.
- Public NAT/Private NAT를 사용 중인 서버는 IP 변경 후, Public NAT/Private NAT의 사용을 해제하고 다시 설정해야 합니다.
- Public NAT/Private NAT를 사용 중인 경우에는 먼저 Public NAT/Private NAT의 사용을 해제하고 IP 변경을 완료한 후, 다시 설정하세요.
- Public NAT/Private NAT의 사용 여부는 Virtual Server 상세 페이지에서 Public NAT IP/Private NAT IP의 수정 버튼을 클릭하여 변경할 수 있습니다.
IP를 변경하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 IP를 변경할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 IP를 변경할 IP 항목의 수정 버튼을 클릭하세요. IP 수정 팝업창이 열립니다.
- IP 수정 팝업창에서 Subnet을 선택한 후, 변경할 IP를 설정하세요.
- 입력: 변경할 IP를 직접 입력합니다.
- 자동 생성: IP를 자동으로 생성하여 적용합니다.
- 설정이 완료되면 확인 버튼을 클릭하세요.
- IP 수정을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
네트워크 포트 추가 후 서버에서 IP 설정하기
Ubuntu Linux로 Virtual Server를 생성한 경우 Samsung Cloud Platform에서 네트워크 포트 추가 후 서버에서 IP 설정이 추가로 필요합니다.
Virtual Server의 OS의 root 사용자로 ip 명령어를 사용하여 할당된 네트워크 인터페이스명을 확인하세요.
배경색 변경ip aip a코드블록. ip 명령어 - 네트워크 인터페이스 확인 명령어 - 추가된 인터페이스가 있는 경우 다음과 같은 결과가 표시됩니다.
배경색 변경[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7코드블록. ip 명령어 - 네트워크 인터페이스 확인 결과 텍스트 편집기(예시:vim)을 사용하여 /etc/netplan/50-cloud-init.yaml 파일을 불러오세요.
/etc/netplan/50-cloud-init.yaml 파일에 아래 내용을 추가하고 저장하세요.
배경색 변경network: version: 2 ethernets: ens7: match: macaddress: "fa:16:3e:98:b6:64" dhcp4: true set-name: "ens7" mtu: 9000network: version: 2 ethernets: ens7: match: macaddress: "fa:16:3e:98:b6:64" dhcp4: true set-name: "ens7" mtu: 9000코드블록. YAML 파일 편집
참고
netplan 구성을 하는 YAML 파일은 들여쓰기가 중요합니다. YAML 파일 수정 시, 기존 설정된 내용을 참고하여 유의해주세요.
netplan 명령어를 사용하여 추가된 네트워크 DEVICE에 IP를 설정하세요.
배경색 변경netplan --debug applynetplan --debug apply코드블록. netplan 적용 ip 명령어를 사용하여 정상적으로 IP가 설정되었는지 확인하세요.
배경색 변경[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7 inet 10.10.10.10/24 metric 100 brd 10.10.10.255 scope global dynamic ens7 valid_lft 43197sec preferred_lft 43197sec inet6 fe80::f816:3eff:fe0a:96bf/64 scope link valid_lft forever preferred_lft forever[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7 inet 10.10.10.10/24 metric 100 brd 10.10.10.255 scope global dynamic ens7 valid_lft 43197sec preferred_lft 43197sec inet6 fe80::f816:3eff:fe0a:96bf/64 scope link valid_lft forever preferred_lft forever코드블록. IP 설정 확인
1.2.5 - Linux NTP 설정하기
사용자는 Samsung Cloud Platform Console을 통해 Rocky Linux, Oracle Linux로 Virtual Server를 생성한 경우 시간 동기화(NTP:Network Time Protocol)를 위해 추가적인 설정이 필요합니다. 그 외 OS 표준 Linux Image(RHEL, Alma Linux, Ubuntu) 는 NTP 설정이 되어 있어 추가 설정 불필요합니다.
NTP Daemon 설치하기
chrony daemon을 설치하여 NTP를 설정할 수 있습니다. chrony daemon을 설치하려면 다음 절차를 따르세요.
참고
chrony에 대한 자세한 내용은 chronyc 페이지를 참고하세요.
Virtual Server의 OS의 root 사용자로 dnf 명령어를 사용하여 chrony 패키지가 설치되었는지 확인합니다.
배경색 변경dnf list chronydnf list chrony코드블록. dnf 명령어 - chrony 패키지 설치 확인 명령어 - chrony 패키지가 설치되어 있는 경우 다음과 같은 결과가 표시됩니다.
배경색 변경[root@scp-test-vm-01 ~] # dnf list chrony Last metadata expiration check: 1:47:29 ago on Wed 19 Feb 2025 05:55:57 PM KST. Installed Packages chrony.x86_64 3.5-1.0.1.el8 @anaconda[root@scp-test-vm-01 ~] # dnf list chrony Last metadata expiration check: 1:47:29 ago on Wed 19 Feb 2025 05:55:57 PM KST. Installed Packages chrony.x86_64 3.5-1.0.1.el8 @anaconda코드블록. dnf 명령어 - chrony 패키지 설치 확인 결과 chrony 패키지가 설치되지 않은 경우 dnf 명령어를 사용하여 chrony 패키지를 설치합니다.
배경색 변경dnf install chrony -ydnf install chrony -y코드블록. dnf 명령 - chrony 패키지 설치 확인 명령어
NTP Daemon 설정하기
참고
chrony에 대한 자세한 내용은 chronyc 페이지를 참고하세요.
chrony daemon을 설정하려면 다음 절차를 따르세요.
텍스트 편집기(예시: vim)를 사용하여 /etc/chrony.conf 파일을 불러오세요.
/etc/chrony.conf 파일에 아래 내용을 추가하고 저장하세요.
배경색 변경server 198.19.0.54 iburstserver 198.19.0.54 iburst코드블록. /etc/chrony.conf 편집 systemctl 명령어를 사용하여 chrony daemon을 자동으로 시작하도록 설정하세요.
배경색 변경systemctl enable chronydsystemctl enable chronyd코드블록. systemctl 명령어 - chrony daemon 자동 시작 설정 systemctl 명령어를 사용하여 chrony daemon을 재시작하세요.
배경색 변경systemctl restart chronydsystemctl restart chronyd코드블록. systemctl 명령어 - chrony daemon 재시작 chronyc sources명령어를 “v” 옵션(상세 정보 표시)과 함께 실행하여 설정한 NTP 서버의 IP 주소를 확인하고 동기화가 진행 중인지 확인하세요.
배경색 변경chronyc sources -vchronyc sources -v코드블록. chronyc sources 명령어 - NTP 동기화 확인 - chronyc sources 명령어를 실행할 경우, 다음과 같은 결과가 표시됩니다.
배경색 변경[root@scp-test-vm-01 ~] # chronyc sources -v 210 Number of sources = 1 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample ========================================================================= ^* 198.19.0.54 2 6 377 52 -129us[ -128us] +/- 14ms[root@scp-test-vm-01 ~] # chronyc sources -v 210 Number of sources = 1 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample ========================================================================= ^* 198.19.0.54 2 6 377 52 -129us[ -128us] +/- 14ms코드블록. chronyc sources 명령어 - NTP 동기화 확인 chronyc tracking 명령어를 실행하여 동기화 지표를 확인하세요.
배경색 변경[root@scp-test-vm-01 ~] # chronyc tracking Reference ID : A9FEA9FE (198.19.0.54) Stratum : 3 Ref time (UTC) : Wed Feb 19 18:48:41 2025 System time : 0.000000039 seconds fast of NTP time Last offset : -0.000084246 seconds RMS offset : 0.000084246 seconds Frequency : 21.667 ppm slow Residual freq : +4.723 ppm Skew : 0.410 ppm Root delay : 0.000564836 seconds Root dispersion : 0.027399288 seconds Update interval : 2.0 seconds Leap status : Normal[root@scp-test-vm-01 ~] # chronyc tracking Reference ID : A9FEA9FE (198.19.0.54) Stratum : 3 Ref time (UTC) : Wed Feb 19 18:48:41 2025 System time : 0.000000039 seconds fast of NTP time Last offset : -0.000084246 seconds RMS offset : 0.000084246 seconds Frequency : 21.667 ppm slow Residual freq : +4.723 ppm Skew : 0.410 ppm Root delay : 0.000564836 seconds Root dispersion : 0.027399288 seconds Update interval : 2.0 seconds Leap status : Normal코드블록. chronyc tracking 명령어 - NTP 동기화 지표
1.2.6 - RHEL Repo 및 WKMS 설정하기
안내
- 사용자는 Samsung Cloud Platform Console을 통해 2025년 8월 이전 RHEL 및 Windows Server를 생성한 경우 RHEL Repository 및 WKMS(Windows Key Management Service) 설정 수정이 필요합니다.
- SCP RHEL Repository는 외부 접속이 제한되는 VPC Private Subnet 등 사용자 환경을 지원하기 위해 SCP에서 제공하는 리포지토리입니다.
SCP RHEL Repository는 내부 스케줄에 따라 각 Region Local Repository와 동기화되므로, 최신 패치를 빠르게 적용하려면 외부 Public Mirror 사이트로 변경하는 것을 권장합니다.
RHEL Repository 설정 가이드
Samsung Cloud Platform에서는 RHEL을 사용 시 SCP에서 제공하는 RHEL Repository를 활용하여 공식 RHEL Repository와 동일한 Package를 설치 및 Download 할 수 있습니다.
SCP에서는 기본적으로 해당 Major 버전의 가장 최신 버전 Repository를 제공합니다. RHEL Repository 설정을 하려면 다음 절차를 따르세요.
Virtual Server의 OS의 root 사용자로 cat 명령어를 사용하여
/etc/yum.repos.d/scp.rhel8.repo또는/etc/yum.repos.d/scp.rhel9.repo설정을 확인하세요.배경색 변경cat /etc/yum.repos.d/scp.rhel8.repocat /etc/yum.repos.d/scp.rhel8.repo코드블록. repo 설정 확인(RHEL8) 배경색 변경cat /etc/yum.repos.d/scp.rhel9.repocat /etc/yum.repos.d/scp.rhel9.repo코드블록. repo 설정 확인(RHEL9) - 설정 파일 확인 시 다음과 같은 결과가 표시됩니다.배경색 변경
[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstream[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstream코드블록. repo 설정 확인(RHEL8) 배경색 변경[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1코드블록. repo 설정 확인(RHEL9)
- 설정 파일 확인 시 다음과 같은 결과가 표시됩니다.
텍스트 편집기(예시: vim)를 사용하여
/etc/hosts파일을 불러오세요./etc/hosts파일에 아래 내용으로 수정하고 저장하세요.배경색 변경198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ip198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ip코드블록. /etc/hosts 파일 설정 변경 yum 명령어를 사용하여 서버에 설정된 RHEL Repository 연결을 확인하세요.
배경색 변경yum repolist –vyum repolist –v코드블록. repository 연결 설정 확인 - RHEL Repository가 성공적으로 연결 되었을 경우 Repository list를 확인할 수 있습니다.배경색 변경
Repo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repoRepo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo코드블록. Repository list 확인
- RHEL Repository가 성공적으로 연결 되었을 경우 Repository list를 확인할 수 있습니다.
Windows Key Management Service 설정 가이드
Samsung Cloud Platform에서는 Windows Server를 사용할 경우 SCP 에서 제공하는 Key Management Service를 활용하여 정품 인증할 수 있습니다. 다음 절차를 따르세요.
Windows 시작 아이콘을 우클릭한 후, Windows PowerShell(관리자) 혹은 Windows 실행 메뉴에서 cmd를 실행해주세요.
Windows PowerShell(관리자) 혹은 cmd에서 아래 명령어를 수행하여 KMS Server를 등록해주세요.
배경색 변경slmgr /skms 198.19.2.23:1688slmgr /skms 198.19.2.23:1688코드블록. WKMS 설정 KMS Server 등록 명령어를 수행한 후, 성공적으로 등록되었다는 알림 팝업을 확인한 후 OK를 클릭하세요.
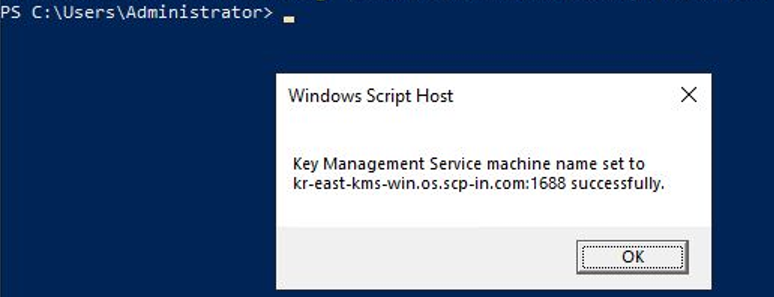
그림. WKMS 설정 확인 Windows PowerShell(관리자) 혹은 cmd에서 아래 명령어를 수행하여 정품 인증을 수행해주세요.
배경색 변경slmgr /atoslmgr /ato코드블록. Windows Server 정품인증 설정 정품 인증이 성공적으로 수행되었다는 알림 팝업을 확인한 후, OK를 클릭하세요.
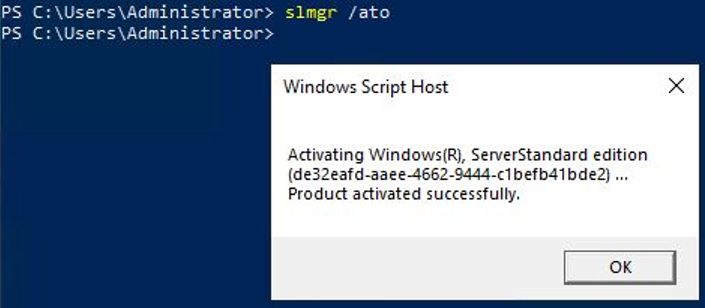
그림. Windows Server 정품 인증 수행 확인 Windows PowerShell(관리자) 혹은 cmd에서 아래 명령어를 수행하여 정품 인증이 되었는지 확인해주세요.
배경색 변경slmgr /dlvslmgr /dlv코드블록. Windows Server 정품 인증 확인 정품 인증이 성공적으로 수행되었다는 알림 팝업을 확인한 후, OK를 클릭하세요.
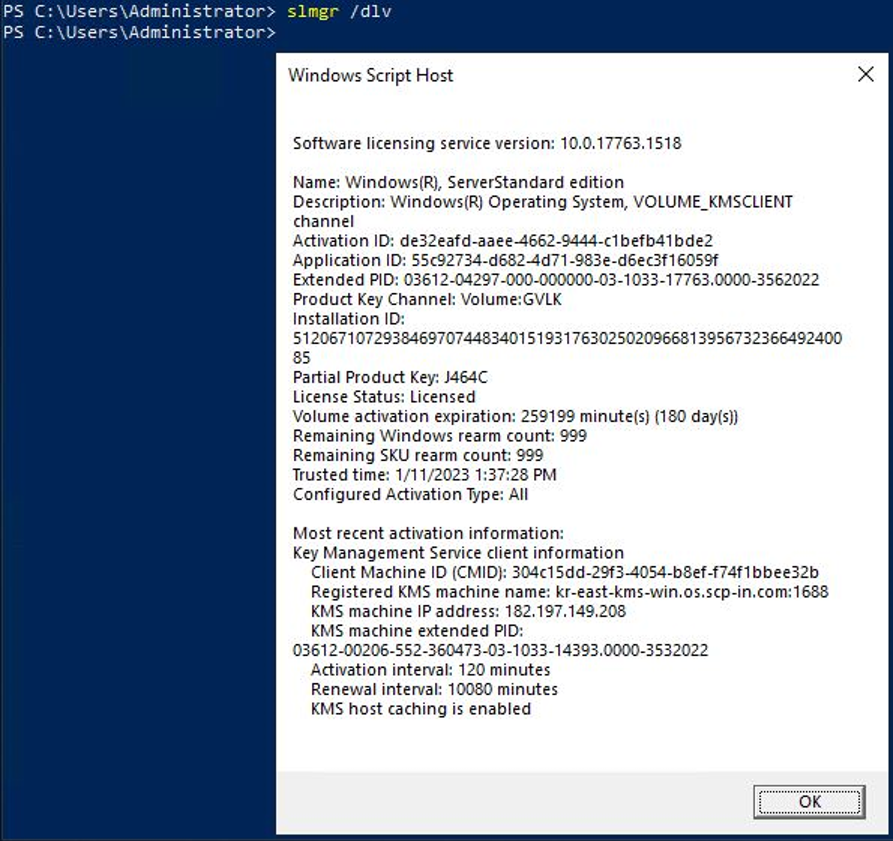
그림. Windows Server 정품 인증 확인
1.2.7 - ServiceWatch Agent 설치하기
사용자는 Virtual Server에 ServiceWatch Agent를 설치하여 사용자 정의 지표와 로그를 수집할 수 있습니다.
참고
ServiceWatch Agent를 통한 사용자 정의 지표/로그 수집은 현재 Samsung Cloud Platform For Enterprise에서만 사용 가능합니다. 이외 오퍼링에서도 향후 제공 예정입니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 각 서비스로부터 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집 설정은 제거하거나 비활성화하기를 권장합니다.
ServiceWatch Agent
Virtual Server에 ServiceWatch의 사용자 정의 지표 및 로그 수집을 위해 설치해야 하는 Agent는 크게 2가지로 나눌 수 있습니다. Prometheus Exporter와 Open Telemetry Collector 입니다.
| 구분 | 상세 설명 | |
|---|---|---|
| Prometheus Exporter | 특정 애플리케이션이나 서비스의 메트릭을 Prometheus가 스크랩(scrape)할 수 있는 형식으로 제공
| |
| Open Telemetry Collector | 분산 시스템의 메트릭, 로그와 같은 텔레메트리 데이터를 수집하고, 처리(필터링, 샘플링 등)한 후, 여러 백엔드(예: Prometheus, Jaeger, Elasticsearch 등)로 내보내는 중앙 집중식 수집기 역할
|
표. Prometheus Exporter와 Open Telemetry Collector 설명
Virtual Server를 위한 Prometheus Exporter 설치 (for Linux)
Linux 서버에서 사용하기 위해 Prometheus Exporter를 아래의 순서에 따라 설치합니다.
Node Exporter 설치
아래의 순서에 따라 Node Exporter를 설치합니다.
Node Exporter User 생성
Node Exporter 프로세스를 안전하게 격리하기 위한 전용 사용자를 생성합니다.
배경색 변경
sudo useradd --no-create-home --shell /bin/false node_exportersudo useradd --no-create-home --shell /bin/false node_exporterNode Exporter 설정
- Node Exporter 설치를 위해 다운로드합니다.
해당 가이드에서는 아래 버전으로 안내합니다.
- 다운로드 경로: /tmp
- 설치 버전: 1.7.0배경색 변경
cd /tmp wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gzcd /tmp wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz코드블록. Node Exporter 다운로드 명령어
참고
최신 버전 Node Exporter는 Node Exporter > Releases > Lastest에서 확인할 수 있고, 특정 버전의 Node Exporter는 Node Exporter > Releases 에서 확인할 수 있습니다.
다운로드 받은 Node Exporter 설치하고 실행 파일에 권한을 부여합니다.
배경색 변경cd /tmp sudo tar -xvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --strip-components=1 node_exporter-1.7.0.linux-amd64/node_exportercd /tmp sudo tar -xvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --strip-components=1 node_exporter-1.7.0.linux-amd64/node_exporter코드블록. Node Exporter 설치 명령어 배경색 변경sudo chown node_exporter:node_exporter /usr/local/bin/node_exportersudo chown node_exporter:node_exporter /usr/local/bin/node_exporter코드블록. Node Exporter 권한 설정 명령어 서비스 파일 생성 Node Exporter를 메모리 메트릭(meminfo) 또는 블록 스토리지 메트릭(filesystem) 수집하도록 설정합니다.
배경색 변경sudo vi /etc/systemd/system/node_exporter.servicesudo vi /etc/systemd/system/node_exporter.service코드블록. Node Exporter 서비스 파일 열기 명령어 배경색 변경[Unit] Description=Prometheus Node Exporter (meminfo only) Wants=network-online.target After=network-online.target [Service] User=node_exporter Group=node_exporter Type=simple ExecStart=/usr/local/bin/node_exporter \ --collector.disable-defaults \ # 기본 제공 메트릭 비활성화 --collector.meminfo \ # 메모리 메트릭 활성화 --collector.filesystem # Block Storage 파일 시스템 메트릭 활성화 Restart=on-failure [Install] WantedBy=multi-user.target[Unit] Description=Prometheus Node Exporter (meminfo only) Wants=network-online.target After=network-online.target [Service] User=node_exporter Group=node_exporter Type=simple ExecStart=/usr/local/bin/node_exporter \ --collector.disable-defaults \ # 기본 제공 메트릭 비활성화 --collector.meminfo \ # 메모리 메트릭 활성화 --collector.filesystem # Block Storage 파일 시스템 메트릭 활성화 Restart=on-failure [Install] WantedBy=multi-user.target코드블록. Node Exporter 서비스 파일 열기 결과
참고
collector는 플래그를 사용하여 활성화/비활성화 설정할 수 있습니다.
–collector.{name}: 특정 메트릭을 활성화할 때 사용합니다.–no-collector.{name}: 특정 메트릭을 비활성화할 수 있습니다.- 기본적으로 제공하는 메트릭을 모두 비활성화하고 특정 수집기만 활성화하려면
–collector.disable-defaults –collector.{name} …와 같이 사용할 수 있습니다.
아래는 주요 collector 설명입니다.
| Collector | 설명 | 라벨 |
|---|---|---|
| meminfo | 메모리 통계 제공 | - |
| filesystem | 사용된 디스크 공간과 같은 파일 시스템 통계 제공 |
|
표. Node Exporter 주요 Collector 설명
- Node Exporter 지표에서 Node Exporter에서 제공하는 주요 지표와 Node Exporter Collector 설정 방법을 확인할 수 있습니다.
참고
- 수집 가능한 메트릭과 설정 방법에 대한 자세한 내용은 Node Exporter > Collector에서 확인할 수 있습니다.
- 사용하는 Node Exporter의 버전에 따라 제공 가능한 메트릭이 상이할 수 있습니다. Node Exporter을 참고하세요.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집은 제거하거나 비활성화해야 과도한 요금이 부과되지 않습니다.
- 서비스 활성화 및 시작
Node Exporter 서비스를 등록하고 등록된 서비스와 설정한 메트릭을 확인합니다.배경색 변경
sudo systemctl daemon-reload sudo systemctl enable --now node_exportersudo systemctl daemon-reload sudo systemctl enable --now node_exporter코드블록. Node Exporter 서비스 활성화 및 시작 명령어 배경색 변경sudo systemctl status node_exportersudo systemctl status node_exporter코드블록. Node Exporter 서비스 확인 명령어 배경색 변경curl http://localhost:9100/metrics | grep node_memorycurl http://localhost:9100/metrics | grep node_memory코드블록. Node Exporter 메트릭 정보 확인 명령어
안내
Node Exporter 설정을 완료하였다면, ServiceWatch에서 제공하는 Open Telemetry Collector를 설치하여 SerivceWatch Agent 설정을 완료하셔야 합니다.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
Virtual Server를 위한 Prometheus Exporter 설치 (for Windows)
Windows 서버에서 Prometheus Exporter를 사용하기 위해 아래의 순서에 따라 설치합니다.
Windows Exporter 설치
아래의 순서에 따라 Windows Exporter를 설치합니다.
Windows Exporter 설정
- Windows Exporter 설치를 위해 설치 파일을 다운로드합니다.
- 다운로드 경로: C:\Temp
- 테스트 버전: 0.31.3배경색 변경
$ mkdir /Temp $ Invoke-WebRequest -Uri "https://github.com/prometheus-community/windows_exporter/releases/download/v0.31.3/windows_exporter-0.31.3-amd64.exe" -OutFile "C:\Temp\windows_exporter-0.31.3-amd64.exe"$ mkdir /Temp $ Invoke-WebRequest -Uri "https://github.com/prometheus-community/windows_exporter/releases/download/v0.31.3/windows_exporter-0.31.3-amd64.exe" -OutFile "C:\Temp\windows_exporter-0.31.3-amd64.exe"코드블록. Windows Exporter 다운로드
참고
Windows Exporter 버전 및 설치 파일은 Windows Exporter > Releases 에서 확인할 수 있습니다.
- Windows Exporter 실행 테스트
Windows Exporter는 기본적으로 모든 컬렉터를 활성화하지만, 원하는 메트릭만 수집하려면 다음 컬렉터를 활성화해야 합니다. 다음은 사용자가 지정한 컬렉터를 활성화하는 예제입니다.- 메모리 메트릭: memory
- 블록 스토리지 메트릭: local_disk
- Host name: os배경색 변경
$ cd C:\Temp $ .\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os$ cd C:\Temp $ .\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os코드블록. Windows Exporter 실행 테스트
참고
collector는 플래그를 사용하여 활성화 설정할 수 있습니다.
–collectors.enabled “[defaults]"기본적으로 제공하는 메트릭–collector.enabled {name},{name},{name}…: 특정 메트릭을 활성화할 때 사용합니다.
아래는 주요 collector 설명입니다.
| Collector | 설명 | 라벨 |
|---|---|---|
| memory | 메모리 통계 제공 | |
| logical_disk | 로컬 시스템의 논리적 디스크(예: C:, D: 드라이브) 성능 및 상태 메트릭을 수집 |
|
표. Windows Exporter 주요 Collector 설명
- Windows Exporter 지표에서 Windows Exporter에서 제공하는 주요 지표와 Windows Exporter Collector 설정 방법을 확인할 수 있습니다.
참고
수집 가능한 메트릭과 설정 방법에 대한 자세한 내용은 Windows Exporter > Collector에서 확인할 수 있습니다.
사용하는 Windoes Exporter의 버전에 따라 제공 가능한 메트릭이 상이할 수 있습니다. Windows Exporter을 참고하세요.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집은 제거하거나 비활성화해야 과도한 요금이 부과되지 않습니다.
서비스 등록 및 확인 Windows Exporter의 서비스를 등록하고 설정한 메트릭을 확인합니다.
배경색 변경$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter코드블록. Windows Exporter 서비스 등록 배경색 변경# 서비스 확인 $ Get-Service windows_exporter # 메트릭 확인 $ Invoke-WebRequest -Uri "http://localhost:9182/metrics" | Select-String memory# 서비스 확인 $ Get-Service windows_exporter # 메트릭 확인 $ Invoke-WebRequest -Uri "http://localhost:9182/metrics" | Select-String memory코드블록. Windows Exporter 서비스 확인 구성 파일 설정
–config.file옵션을 사용하여 YAML 구성 파일을 사용하도록 설정할 수 있습니다.배경색 변경$ .\windows_exporter.exe --config.file=config.yml $ .\windows_exporter.exe --config.file="C:\Program Files\windows_exporter\config.yml" # 절대 경로를 사용하는 경우 경로를 따옴표로 묶어야 합니다.$ .\windows_exporter.exe --config.file=config.yml $ .\windows_exporter.exe --config.file="C:\Program Files\windows_exporter\config.yml" # 절대 경로를 사용하는 경우 경로를 따옴표로 묶어야 합니다.코드블록. Windows Exporter 구성 파일 설정 배경색 변경collectors: enabled: cpu,net,service collector: service: include: windows_exporter log: level: warncollectors: enabled: cpu,net,service collector: service: include: windows_exporter log: level: warn코드블록. Windows Exporter 구성 파일 일부 예시 - Windows Exporter > 구성 파일 공식 예시 파일을 참고하세요.배경색 변경
--- # Note this is not an exhaustive list of all configuration values collectors: enabled: cpu,logical_disk,net,os,service,system collector: service: include: "windows_exporter" scheduled_task: include: /Microsoft/.+ log: level: debug scrape: timeout-margin: 0.5 telemetry: path: /metrics web: listen-address: ":9182"--- # Note this is not an exhaustive list of all configuration values collectors: enabled: cpu,logical_disk,net,os,service,system collector: service: include: "windows_exporter" scheduled_task: include: /Microsoft/.+ log: level: debug scrape: timeout-margin: 0.5 telemetry: path: /metrics web: listen-address: ":9182"코드블록. Windows Exporter 구성 파일 예시 - 구성 파일을 이용하여 서비스 등록하기 위해서 아래를 참고하세요.배경색 변경
$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter코드블록. Windows Exporter 구성 파일을 이용한 서비스 등록
참고
구성 파일과 명령줄 옵션을 함께 사용하는 경우, 명령줄 옵션에 포함된 값들이 우선 적용됩니다. 따라서 명령줄 옵션이 구성 파일 설정보다 우선 적용합니다.
안내
Node Exporter 설정을 완료하였다면, ServiceWatch에서 제공하는 Open Telemetry Collector를 설치하여 SerivceWatch Agent 설정을 완료하셔야 합니다.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
Node Exporter 지표
Node Exporter 주요 지표
아래는 Node Exporter를 통해 확인할 수 있는 Collector와 지표 정보입니다. Collector로 설정할 수도 있고, 특정 지표만 활성화할 수 있습니다.
| 구분 | Collector | Metric | Description |
|---|---|---|---|
| Memory | meminfo | node_memory_MemTotal_bytes | 전체 메모리 |
| Memory | meminfo | node_memory_MemAvailable_bytes | 사용 가능한 메모리(메모리 부족 여부를 판단하기 위해 사용) |
| Memory | meminfo | node_memory_MemFree_bytes | Free 메모리(비어 있는 메모리) |
| Memory | meminfo | node_memory_Buffers_bytes | IO 버퍼 |
| Memory | meminfo | node_memory_Cached_bytes | 페이지 캐시 |
| Memory | meminfo | node_memory_SwapTotal_bytes | 전체 스왑 |
| Memory | meminfo | node_memory_SwapFree_bytes | 남은 스왑 |
| Filesystem | filesystem | node_filesystem_size_bytes | 파일 시스템 전체 크기 |
| Filesystem | filesystem | node_filesystem_free_bytes | 전체 여유 공간(total free space) |
| Filesystem | filesystem | node_filesystem_avail_bytes | 사용자가 실제로 사용 가능한 공간(available space for unprivileged users) |
표. Node Exporter 주요 지표
Node Exporter Collector 및 지표 수집 설정
Node Exporter는 기본적으로 대부분의 collector가 활성화되지만, 원하는 collector만 활성화/비활성화 설정할할 수 있습니다.
특정 Collector만 활성화
- 메모리, 파일 시스템 Collector만 사용하고 싶을 때:배경색 변경
./node_exporter --collector.meminfo # 메모리 Collector 활성화 --collector.filesystem # 파일 시스템 Collector 활성화./node_exporter --collector.meminfo # 메모리 Collector 활성화 --collector.filesystem # 파일 시스템 Collector 활성화코드블록. Node Exporter 특정 Collector 활성화 - Default 설정은 모두 해제하고 메모리, 파일 시스템 Collector만 사용하고 싶을 때:배경색 변경
./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.meminfo # 메모리 Collector 활성화 --collector.filesystem # 파일 시스템 Collector 활성화./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.meminfo # 메모리 Collector 활성화 --collector.filesystem # 파일 시스템 Collector 활성화코드블록. Node Exporter 특정 Collector 활성화 - 특정 마운트 지점에 대한 파일 시스템 Collector 활성화배경색 변경
./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.filesystem.mount-points-include="/|/data" # /(Root)와 /data 마운트 지점에 대한 파일 시스템 Collector 활성화./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.filesystem.mount-points-include="/|/data" # /(Root)와 /data 마운트 지점에 대한 파일 시스템 Collector 활성화코드블록. Node Exporter 특정 Collector 활성화 - 특정 마운트 지점을 제외한 파일 시스템 Collector 활성화배경색 변경
./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.filesystem.mount-points-exclude="/boot|/var/log" # /boot와 /var/log 마운트 지점에 대한 파일 시스템 Collector 활성화./node_exporter --collector.disable-defaults # 기본 제공 메트릭 비활성화 --collector.filesystem.mount-points-exclude="/boot|/var/log" # /boot와 /var/log 마운트 지점에 대한 파일 시스템 Collector 활성화코드블록. Node Exporter 특정 Collector 활성화
특정 Collector 비활성화 (no-collector)
파일 시스템 collector를 사용하고 싶지 않을때:
배경색 변경
./node_exporter --no-collector.filesystem./node_exporter --no-collector.filesystemSystemd 서비스로 Collector 구성 (권장)
배경색 변경
[Unit]
Description=Node Exporter
After=network-online.target
[Service]
User=nodeexp
ExecStart=/usr/local/bin/node_exporter
--collector.disable-defaults # 기본 제공 메트릭 collector 모두 비활성화
--collector.meminfo
--collector.filesystem
[Install]
WantedBy=multi-user.target[Unit]
Description=Node Exporter
After=network-online.target
[Service]
User=nodeexp
ExecStart=/usr/local/bin/node_exporter
--collector.disable-defaults # 기본 제공 메트릭 collector 모두 비활성화
--collector.meminfo
--collector.filesystem
[Install]
WantedBy=multi-user.target특정 지표만 필터링하는 방법
Open Telemetry Collector 설정을 통해서 Node Exporter로부터 수집한 지표 중 필요한 것만 선택해서 수집하도록 설정할 수 있습니다. Node Exporter의 특정 Collector에서 제공하는 지표 중에 특정 지표만 수집하고자 할 때, ServiceWatch를 위한 Open Telemetry Collector 사전 설정을 참고할 수 있습니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 각 서비스로부터 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 반드시 필요한 지표에 대해 설정하는 것을 권장합니다.
Windows Exporter 지표
Windows Exporter 주요 지표
아래는 Windows Exporter를 통해 확인할 수 있는 Collector와 지표 정보입니다. Collector로 설정할 수도 있고, 특정 지표만 활성화할 수 있습니다.
| 구분 | Collector | 지표명 | 설명 |
|---|---|---|---|
| Memory | memory | windows_memory_available_bytes | 사용 가능한 메모리 |
| Memory | memory | windows_memory_cache_bytes | 캐시 메모리 |
| Memory | memory | windows_memory_committed_bytes | 커밋된 메모리 |
| Memory | memory | windows_memory_commit_limit | 커밋 한도 |
| Memory | memory | windows_memory_pool_paged_bytes | paged pool |
| Memory | memory | windows_memory_pool_nonpaged_bytes | non-paged pool |
| 디스크 정보 | logical_disk | windows_logical_disk_free_bytes | 남은 용량 |
| 디스크 정보 | logical_disk | windows_logical_disk_size_bytes | 전체 용량 |
| 디스크 정보 | logical_disk | windows_logical_disk_read_bytes_total | 읽기 바이트 수 |
| 디스크 정보 | logical_disk | windows_logical_disk_write_bytes_total | 쓰기 바이트 수 |
| 디스크 정보 | logical_disk | windows_logical_disk_read_seconds_total | 읽기 latency |
| 디스크 정보 | logical_disk | windows_logical_disk_write_seconds_total | 쓰기 latency |
| 디스크 정보 | logical_disk | windows_logical_disk_idle_seconds_total | idle 시간 |
표. Windows Exporter 주요 지표
Windows Exporter Collector 및 지표 수집 설정
Windows Exporter는 기본적으로 대부분의 collector가 활성화되지만, 원하는 collector만 설정할할 수 있습니다.
특정 Collector만 활성화
CPU, 메모리, 논리 디스크만 사용하고 싶을 때:
배경색 변경
# --collector.enabled 옵션은 기본값을 비활성화하고, 표기한 Collector만 활성화
.\windows_exporter.exe --collectors.enabled="memory,logical_disk" # --collector.enabled 옵션은 기본값을 비활성화하고, 표기한 Collector만 활성화
.\windows_exporter.exe --collectors.enabled="memory,logical_disk" 참고
Windows Exporter는 사용하지 않는 collector를 비활성화하지 않아도
–collector.enabled를 사용하면 해당 옵션에 기재된 collector에 대해서만 수집됩니다.서비스로 Collector 구성 (권장)
배경색 변경
# windows_exporter 를 서비스로 등록
sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto
# 서비스 시작
Start-Service windows_exporter# windows_exporter 를 서비스로 등록
sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto
# 서비스 시작
Start-Service windows_exporter배경색 변경
# Note this is not an exhaustive list of all configuration values
collectors:
enabled: logical_disk,memory # 활성화할 collector 설정
collector:
service:
include: "windows_exporter"
scheduled_task:
include: /Microsoft/.+
log:
level: debug
scrape:
timeout-margin: 0.5
telemetry:
path: /metrics
web:
listen-address: ":9182"# Note this is not an exhaustive list of all configuration values
collectors:
enabled: logical_disk,memory # 활성화할 collector 설정
collector:
service:
include: "windows_exporter"
scheduled_task:
include: /Microsoft/.+
log:
level: debug
scrape:
timeout-margin: 0.5
telemetry:
path: /metrics
web:
listen-address: ":9182"특정 지표만 필터링하는 방법
Open Telemetry Collector 설정을 통해서 Windows Exporter로부터 수집한 지표 중 필요한 것만 선택해서 수집하도록 설정할 수 있습니다. Windows Exporter의 특정 Collector에서 제공하는 지표 중에 특정 지표만 수집하고자 할 때, ServiceWatch를 위한 Open Telemetry Collector 사전 설정을 참고할 수 있습니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 각 서비스로부터 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 반드시 필요한 지표에 대해 설정하는 것을 권장합니다.
1.3 - API Reference
API Reference
1.4 - CLI Reference
CLI Reference
1.5 - Release Note
Virtual Server
2025.12.16
FEATURE
Virtual Server 기능 추가- OS Image 추가 제공
- 표준 Image가 추가되었습니다. (Alma Linux 9.6, Oracle Linux 9.6, RHEL 9.6, Rocky Linux 9.6)
- Server Group 신규 정책 추가
- Partition(Virtual Server와 Block Storage 분산 배치) 정책이 추가되었습니다.
- Virtual Server ServiceWatch Agent를 설치하여 사용자 정의 지표와 로그를 수집할 수 있습니다.
2025.10.23
FEATURE
서버명 변경 기능 추가 및 ServiceWatch 서비스 연계 제공- Samsung Cloud Platform Console의 Virtual Server 상세페이지에서 서버명을 변경할 수 있습니다.
- 서버명 변경 시 OS의 Hostname은 변경되지 않고, Samsung Cloud Platform Console 내 정보만 변경됩니다.
- ServiceWatch 서비스 연계 제공
- ServiceWatch 서비스를 통해 데이터를 모니터링할 수 있습니다.
2025.07.01
FEATURE
Virtual Server 기능 추가 및 Image 공유 방법 변경- Virtual Server 기능 추가
- IP, Public NAT IP, Private NAT IP 설정 기능이 추가되었습니다.
- LLM 이용을 위한 LLM Endpoint가 제공됩니다.
- Virtual Server 생성 시 Marketplace에서 구독한 OS Image를 선택할 수 있습니다.
- 2세대 서버 타입 추가되었습니다.
- Intel 4세대(Sapphire Rapids) Processor 기반의 2세대(s2) 서버타입 추가. 자세한 내용은 Virtual Server 서버 타입 를 참고
- Account 간 Image 공유 방법이 변경되었습니다.
- qcow2 Image 또는 공유용 Image를 새로 생성하여 공유할 수 있습니다.
2025.02.27
FEATURE
NAT 설정 기능 및 OS Image, 서버 타입 추가- Virtual Server 기능 추가
- Virtual Server에서 NAT 설정 기능이 추가되었습니다.
- OS Image 추가 제공
- 표준 Image가 추가되었습니다. (Alma Linux 8.10, Alma Linux 9.4, Oracle Linux 8.10, Oracle Linux 9.4, RHEL 8.10, RHEL 9.4, Rocky Linux 8.10, Rocky Linux 9.4, Ubuntu 24.04)
- Kubernetes용 Image가 추가되었습니다. Kubernetes용 Image를 사용하여 Kubernetes Engine을 생성할 수 있습니다.
- 2세대 서버 타입 추가
- Intel 4세대(Sapphire Rapids) Processor 기반의 2세대(h2) 서버타입 추가. 자세한 내용은 Virtual Server 서버 타입 를 참고
- Samsung Cloud Platform 공통 기능 변경
- Account, IAM 및 Service Home, 태그 등 공통 CX 변경 사항을 반영하였습니다.
2024.10.01
NEW
Virtual Server 서비스 정식 버전 출시- Virtual Server 서비스 정식 출시하였습니다.
- 인프라 자원을 개별 구매할 필요 없이, 필요한 시점에 필요한 만큼 자유롭게 할당 받아 사용할 수 있는 가상화 서버를 출시하였습니다.
2024.07.02
NEW
Beta 버전 출시- 인프라 자원을 개별 구매할 필요 없이, 필요한 시점에 필요한 만큼 자유롭게 할당 받아 사용할 수 있는 가상화 서버를 출시하였습니다.
2 - Virtual Server Auto-Scaling
2.1 - Overview
서비스 개요
Virtual Server Auto-Scaling은 수요에 따라 자원을 자동으로 확장, 축소하는 서비스입니다.애플리케이션을 실행하는 서버 수를 사전에 정의한 조건 또는 일정에 맞게 추가하거나 해지할 수 있습니다.
Auto-Scaling Group은 사전에 생성한 Launch Configuration을 사전 Configuration 템플릿으로 사용하여 서버를 생성하고, 서버 수를 조정하고 관리할 수 있습니다. 지정한 최소 서버 수보다 적어지거나, 최대 서버 수를 초과하지 않도록 조정합니다.
Auto-Scaling Group에 스케줄을 등록하면, 정해진 일정에 맞게 서버 수를 설정할 수 있습니다. 정책을 등록하면, 사전 정의된 조건에 따라 서버 수를 늘리거나 줄일 수 있습니다.
특장점
쉽고 편리한 컴퓨팅 환경 구성: 웹 기반 Console을 통해 Launch Configuration 생성부터 Auto-Scaling Group 생성/변경/삭제까지 사용자가 직접 Self Service로 손쉽게 필요한 컴퓨팅 환경을 구성할 수 있습니다.
탄력적 자원 사용: 서비스의 부하량과 사용량에 맞게 탄력적으로 컴퓨팅 자원을 사용할 수 있습니다. 사용자는 예측 가능한 특정 시간대의 자원 사용량 스케줄링이 가능하며, 불특정 다수 사용자의 일시적 접속을 대비해 자원 사용량을 조절할 수 있습니다.
가용성 향상: Virtual Server Auto-Scaling은 사용자가 요구하는 트래픽이 항시 처리될 수 있도록 가변적인 수요에 맞게 자원을 조절하는 기능을 합니다. 이를 통해 사용자는 애플리케이션 성능과 가용성을 향상시키는 효과를 얻을 수 있습니다.
비용 절감 효과 극대화: 수요 변동에 따라서 필요한 만큼만 자원을 사용하여 불필요한 비용을 줄일 수 있습니다. 야간, 주말, 월말 등 특정 시간대 트래픽 증감에 따른 유연한 자원 사용을 통해 비용 절감 효과를 극대화 할 수 있습니다.
서비스 구성도
제공 기능
Virtual Server Auto-Scaling은 다음과 같은 기능을 제공하고 있습니다.
- Launch Configuration: Auto-Scaling Group에서 Virtual Server를 생성하는 데 사용하는 Configuration 템플릿입니다. Launch Configuration을 만들 때 이미지, 서버 유형, Key Pair, Block Storage 등 Virtual Server에 대한 정보를 설정합니다.
- 서버 수 조정: 서버 수를 조정할 수 있는 여러 가지 방법을 제공합니다. 정책을 사용하면 임계치 이상의 부하가 있을 경우 처리할 수 있는 Virtual Server를 추가하고 수요가 낮을 때는 Virtual Server을 해제하여 애플리케이션 가용성을 유지하고 비용을 절감할 수 있습니다. 스케줄을 이용하여 정해진 일정에 따라 Virtual Server를 추가하고 해제할 수 있고, 필요에 따라 Auto-Scaling Group의 서버 수를 수동으로 조정할 수도 있습니다.
- Load Balancer 연계: Load Balancer를 사용하여 애플리케이션 트래픽이 Virtual Server에 고르게 분배되도록 할 수 있습니다. Virtual Server가 추가되거나 해지될 때마다 Load Balancer에 자동으로 등록 및 해제합니다.
- 네트워크 연결: Auto-Scaling Group의 일반 서브넷, IP 자동 할당 및 Public NAT IP를 연결할 수 있습니다. 서버 간 통신을 위한 로컬 서브넷 연결을 제공합니다.
- Security Group 적용: Security Group은 Virtual Server에서 발생하는 Inbound/Outbound 트래픽을 제어하는 가상의 논리적 방화벽입니다. Inbound 규칙은 Virtual Server로 들어오는 수신 트래픽을 제어하고 Outbound 규칙은 Virtual Server에서 나가는 발신 트래픽을 제어합니다.
- 모니터링: Auto-Scaling Group에서 생성된 Virtual Server의 CPU, Memory, Disk 등의 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다. Monitoring 정보를 기반으로 Auto-Scaling 정책을 사용하여 부하에 대한 임계치를 설정하고 임계치가 넘어서면 서버를 추가 또는 해제하도록 할 수 있습니다.
구성 요소
Virtual Server Auto-Scaling은 Launch Configuration을 통해 Auto-Scaling Group을 생성하고 서버를 확인하고 관리합니다.
Launch Configuration
Auto-Scaling Group에서 Virtual Server를 생성하는 데 사용하는 Configuration 템플릿입니다. 주요 기능은 다음과 같습니다.
- 이미지: OS 표준 이미지와 사용자가 생성한 Custom 이미지를 제공합니다. 사용자는 구성하고자 하는 서비스에 따라 선택하여 사용 가능합니다.
- Keypair: 안전한 OS 접속 방식을 위해 Keypair 방식을 제공합니다.
- Init script: Virtual Server 시작 시 실행할 스크립트를 사용자가 정의할 수 있습니다.
- 자세한 내용은 Launch Configuration 생성하기를 참고하세요.
참고
Launch Configuration에서 선택 가능한 이미지와 서버 타입은 Virtual Server OS 이미지 제공 버전과 Virtual Server 서버 타입을 참고하세요.
Auto-Scaling Group
Launch Configuration을 서버 생성을 위한 사전 Configuration 템플릿으로 사용합니다. Auto-Scaling Group을 생성하여 서버 수 조정 및 관리할 수 있습니다. 주요 기능은 다음과 같습니다.
- Launch Configuration: Auto-Scaling Group에서 Virtual Server를 생성하는 데 사용하는 Configuration 템플릿입니다.
- 서버 수 설정: Virtual Server Auto-Scaling은 Auto-Scaling Group의 서버 수를 조정할 수 있는 여러 가지 방법을 제공합니다.
- 서버 수 고정 방식: Auto-Scaling Group 생성 시, 설정한 서버 수로 추가된 스케줄이나 정책 없이 기본 설정값을 유지하도록 하는 방식입니다. Auto-Scaling Group 생성하기를 참고하여 Min, Desired, Max 서버 수를 설정하세요.
- 서버 수 수동 조정 방식: Auto-Scaling Group에서 서버 수 수정을 통해 원하는 서버 수 만큼 늘리거나 줄이는 방식입니다. Desired 서버 수 수동 설정 여부를 선택할 수 있습니다. 서버 수 수정하기를 참고하세요.
- 스케줄 예약 방식: 매일, 매주, 매달 또는 한번 스케줄 예약을 할 수 있으며, 정해진 시간에 원하는 서버 수를 설정할 수 있습니다. 이는 어떨 때 서버 수를 줄이거나 늘려야 할지 예측이 가능한 경우에 유용하게 사용할 수 있습니다. 스케줄 방식을 사용하고 한다면, 스케줄 관리하기를 참고하여 스케줄을 추가 및 관리해주세요.
- 정책 방식: 동적으로 서버를 조정하는 방법으로 정책을 사용할 수 있습니다. 모니터링 지표 기반으로 설정한 임계치를 벗어나는 경우, 서버 수를 조정하는 방식입니다. 이때 서버 수를 조정하는 방식을 3가지 중에 선택 할 수 있습니다. 지정 대수만큼 서버 수 증감, 지정한 비율로 서버 수 증감, 입력한 값으로 서버 수 고정입니다. 정책으로 인한 서버가 시작되고 해지될 때, 일시적으로 모니터링 지표인 CPU 사용률 정책에 등록한 임계치를 벗어날 수 있습니다. 하지만 이는 일시적인 순간이기 때문에 비정상 상황으로 판단하지 않기 위해 쿨다운 시간을 설정합니다. 정책 방식을 사용하고 싶다면, 정책 관리하기을 참고하세요.
- Load Balancer: Virtual Server가 추가되거나 해지될 때마다 Auto-Scaling Group에 등록되어 있는 Load Balancer에 자동으로 연결 및 분리합니다.
- Auto-Scaling Group의 Load Balancer 관련된 자세한 내용은 Auto-Scaling Group 상세 정보 확인하기를 참고하세요.
참고
Auo-Scaling Group의 Load Balancer는 2025년 2월부터 Load Balancer와 연계하여 동작합니다.
제약 사항
Virtual Server Auto-Scaling의 제약 사항은 다음과 같습니다.
| 구분 | 설명 |
|---|---|
| Auto-Scaling Group당 Virtual Server 수 | 50개 이하 |
| Auto-Scaling Group당 정책 개수 | 12개 이하 |
| Auto-Scaling Group당 스케줄 개수 | 20개 이하 |
| Auto-Scaling Group당 LB 서버 그룹 및 포트 개수 | 3개 이하 |
표. Virtual Server Auto-Scaling Group 제약 사항
주의
- 사용 중인 Image가 제공 종료된 표준 Image 라면, Scale-out 이 동작하지 않습니다.
사용 중인 Image가 Custom Image 라면, 해당 버전 제공 종료 이후에도 Scale out 이 정상적으로 동작합니다. - 사용 중인 Image의 제공 종료 전에, 최신 버전의 Image 또는 Custom Image로 Launch Configuration를 교체 권고드립니다.
- Virtual Server에서 제공 중인 OS Image에 대한 자세한 내용은 OS Image 제공 버전을 참고하세요.
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
표. Virtual Server Auto-Scaling 선행 서비스
2.1.1 - 모니터링 지표
Virtual Server Auto-Scaling은 Virtual Server 대상으로 제공하는 서비스로 개별 Virtual Server 모니터링 지표와 Cloud Monitoring 기반 정책에서 제공하는 모니터링 지표를 제공합니다.
Virtual Server 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Virtual Server의 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Windows OS의 경우 Memory 관련 지표는 제공되지 않습니다.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Memory Total [Basic] | 사용할 수 있는 메모리의 bytes | bytes |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Memory Swap In [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Swap Out [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Free [Basic] | 사용하지 않은 메모리의 bytes | bytes |
| Disk Read Bytes [Basic] | 읽기 bytes | bytes |
| Disk Read Requests [Basic] | 읽기 요청 수 | cnt |
| Disk Write Bytes [Basic] | 쓰기bytes | bytes |
| Disk Write Requests [Basic] | 쓰기 요청 수 | cnt |
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Instance State [Basic] | Instance 상태 | state |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Dropped [Basic] | 수신 패킷 드롭 | cnt |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Dropped [Basic] | 송신 패킷 드롭 | cnt |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. Virtual Server 모니터링 지표(기본 제공)
Cloud Monitoring 기반 정책에서 제공하는 모니터링 지표
아래 표는 Cloud Monitoring 기반 Auto-Scaling Group의 정책에서 제공하는 모니터링 지표를 나타냅니다. Cloud Monitoring 기반은 정책 설정에 대한 자세한 내용은 정책 관리하기를 참고하세요.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. Cloud Monitoring 기반 정책에서 제공하는 모니터링 지표
2.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Auto-Scaling Group의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Auto-Scaling Group 생성하기
Samsung Cloud Platform Console에서 Auto-Scaling Group 서비스를 생성하여 사용할 수 있습니다.
참고
Auto-Scaling Group 생성하기 위해서는 사전에 Launch Configuration 생성이 필요합니다.
Launch Configuration 생성하기을 참고하세요.
Auto-Scaling Group 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
Auto-Scaling Group 목록 페이지에서 Auto-Scaling Group 생성 버튼을 클릭하세요. Auto-Scaling Group 생성 페이지로 이동합니다.
Auto-Scaling Group 생성 페이지에서 서비스 생성에 필요한 정보를 입력하세요.
- Launch Configuration 영역에서 Launch Configuration을 선택하세요.
- Launch Configuration 생성 버튼을 클릭하여 새로운 Launch Configuration를 생성할 수 있습니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Auto-Scaling Group 명 필수 Auto-Scaling Group 이름 - 동일한 유형과 목적으로 사용하는 서버들을 그룹으로 관리
서버명 필수 Auto-Scaling Group 내의 생성할 서버명 - Auto-Scaling Group 내 생성된 서버를 구분하기 위한 식별자로 입력한 서버명과 Sequence의 조합으로 서버명이 자동 부여됩니다.
서버 수 필수 Auto-Scaling Group에 생성할 서버 개수 - 0~20 사이의 값을 입력 (Min≤Desired≤Max)
- Min: Auto-Scailg Group이 최소한으로 유지할 서버 수를 설정
- Desired: Auto-Scailg Group 내 목표 서버 수를 설정 또한, Auto-Scailg Group 생성 시, 최초 생성되는 서버 수를 의미
- Max: Auto-Scailg Group이 최대로 유지할 수 있는 서버 수를 설정
- Auto-Scaling Group 생성 후에도 수정 버튼을 통해서 설정. 자세한 내용은 서버 수 수정하기를 참고
Desired 서버 수 수동 설정 선택 Desired 서버 수를 수동으로 변경할 지 여부를 선택 - Auto-Scaling Group 생성 후에도 수정 버튼을 통해서 설정. 자세한 내용은 Desired 서버 수 수동 설정 수정하기를 참고
네트워크 설정 > 네트워크 설정 필수 Auto-Scaling Group을 위한 네트워크 설정 - 원하는 VPC와 일반 Subnet를 선택
- IP는 자동 생성만 가능합니다.
- 로컬 Subnet을 선택하면 원하는 로컬 Subnet을 선택할 수 있고, IP는 자동 생성만 가능
네트워크 설정 > Security Group 선택 필요한 접속을 허용하기 위해서 Security Group을 설정 필요 - Security Group을 설정하지 않으면 기본 규칙(Any/Deny)에 따라 Inbound/Outbound 모든 트래픽을 차단
- Linux 서버의 경우 SSH 트래픽을 허용
- Windows 서버의 경우 RDP 트래픽을 허용
- Auto-Scaling Group 생성 후에도 수정 버튼을 통해 설정. 자세한 내용은 Security Group 설정하기를 참고
Load Balancer 선택 Auto-Scaling Group을 Load Balancer에 연결 - Auto-Scaling Group의 서버를 LB 서버 그룹의 Member로 등록
- LB 서버 그룹: 선택한 VPC에 생성되어 있는 LB 서버 그룹을 선택
- 포트: 1 ~ 65,534 사이의 값을 입력
- + 버튼을 눌러서 LB 서버 그룹을 추가가능(LB 서버 그룹 및 포트는 총 3개까지 가능)
- Weighted Round Robin 또는 Weighted Least Connection 부하 분산을 사용하는 LB 서버 그룹은 선택 불가
- Draining Timeout값: Draining Timeout을 사용으로 체크한 후, Draining Timeout값을 설정 가능
- Draining Timeout: 서버를 Load Balancer에서 분리하기 전에 대기하는 시간
- 해당 서버로 연결된 세션이 남아있을 수 있으므로, Draining Timeout을 설정하여 대기할 경우, 안전하게 세션 정리 가능
- Load Balancer가 미사용일 경우, Draining Timeout 설정 불가
- 기본값은 300초, 최소 1초 ~ 최대 3,600초까지 입력 가능합니다.
- Draining Timeout: 서버를 Load Balancer에서 분리하기 전에 대기하는 시간
- Auto-Scaling Group 생성 후에도 변경이 가능하며, 자세한 내용은 Auto-Scaling Group Load Balancer 사용하기를 참고
표. Auto-Scaling Group 서비스 정보 입력 항목 - Scaling 정책 설정 영역에서 Scaling 정책을 설정하세요.
- 정책 설정에 대한 자세한 내용은 정책 추가하기를 참고하세요.
구분 필수 여부상세 설명 지금 설정 선택 Scaling 정책을 지금 설정 - 정책 추가 버튼을 클릭하면 정책 정보 입력 항목 표시
나중에 설정 선택 Auto-Scaling Group 생성 후, 상세 정보 페이지에서 정책 설정 표. Auto-Scaling Group Scaling 정책 설정 항목
- 정책 설정에 대한 자세한 내용은 정책 추가하기를 참고하세요.
- 알림 설정 영역에서 알림 수신자와 알림 방식을 설정하세요.
- 알림 설정에 대한 자세한 내용은 알림 추가하기를 참고하세요.
구분 필수 여부상세 설명 지금 설정 선택 알림 수신자와 알림 방식을 지금 설정 - 알림 추가 버튼을 클릭하면 알림 추가 팝업창이 열림
- 알림 설정에 대한 자세한 내용은 상세정보 내 참고
- 알림 수신인 목록에서 수정 버튼을 클릭하여 알림 정보 변경 가능
나중에 설정 선택 Auto-Scaling Group 생성 후, 상세 정보 페이지에서 알림 수신자와 알림 방식을 설정 표. Auto-Scaling Group 알림 설정 항목
- 알림 설정에 대한 자세한 내용은 알림 추가하기를 참고하세요.
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Auto-Scaling Group 추가 정보 입력 항목
- Launch Configuration 영역에서 Launch Configuration을 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Auto-Scaling Group 목록 페이지에서 생성한 Auto-Scaling Group을 확인하세요.
Auto-Scaling Group 상세 정보 확인하기
Auto-Scaling Group 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Auto-Scaling Group 상세 페이지에서는 상세 정보, 정책, 스케줄, Virtual Server, Load Balancer, 태그, 작업 이력 탭으로 구성되어 있습니다.
Auto-Scaling Group 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- Auto-Scaling Group 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 정책, 스케줄, Virtual Server, Load Balancer, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 Auto-Scaling Group 상태 사용자가 생성한 Auto-Scaling Group의 상태 - Creating: Auto-Scaling Group 생성 중
- In Service: 서비스 가능한 상태
- Scale In: Scale In 진행 중
- Scale Out: Scale Out 진행 중
- Cool Down: 쿨 다운 대기 중
- Terminating: Auto-Scaling Group 삭제 중
- Attach to LB: Load Balancer에 연결하는 중
- Detach from LB: Load Balancer로부터 분리하는 중
Auto-Scaling Group 삭제 Auto-Scaling Group 삭제하는 버튼 표. Auto-Scaling Group 상태 정보 및 부가 기능
- Auto-Scaling Group 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 정책, 스케줄, Virtual Server, Load Balancer, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Auto-Scaling Group 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Auto-Scaling Group명 | Auto-Scaling Group 이름 |
| Launch Configuration명 | Auto-Scaling Group을 생성할 때, 선택한 Launch Configuration 이름
|
| 서버 수 | 현재 Auto-Scaling Group의 생성되어 있는 서버 수와 설정한 Min, Desired, Max 서버 수
|
| Desired 서버 수 수동 설정 | Desired 서버 수 수동 설정 사용/미사용
|
| VPC | Auto-Scaling Group의 VPC 정보 |
| 일반 Subnet | Auto-Scaling Group의 일반 Subnet, NAT IP 사용 정보 |
| 로컬 Subnet | Auto-Scaling Group의 로컬 Subnet |
| Security Group | Auto-Scaling Group의 Security Group
|
표. Auto-Scaling Group 상세 - 상세 정보 탭 항목
정책
Auto-Scaling Group 목록 페이지에서 선택한 자원의 정책 목록를 확인하고, 필요한 경우 정책을 추가하거나 관리할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 구분 | 정책 구분
|
| 정책명 | 정책 별 구분할 이름 |
| 실행 조건 | 정책을 실행할 조건
|
| 실행 단위 | 정책을 실행하는 방식
|
| 쿨다운 | 정책으로 인한 서버가 시작 또는 해지될 때, 대기하는 시간(초)
|
| 더보기 > 수정 | 해당 정책 정보를 수정
|
| 더보기 > 활성화 | 해당 정책을 활성화
|
| 더보기 > 비활성화 | 해당 정책을 비활성화
|
표. Auto-Scaling Group 상세 - 정책 탭 항목
정책 관리 및 정책 예시 설명에 대해서는 정책 관리하기를 참고하세요.
스케줄
Auto-Scaling Group 목록 페이지에서 선택한 자원의 스케줄 목록를 확인하고, 필요한 경우 스케줄을 추가하거나 관리할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 이름 | 스케줄 이름 |
| Min | 스케줄에서 설정한 최소 서버 수 |
| Desired | 스케줄에서 설정한 목표 서버 수 |
| Max | 스케줄에서 설정한 최대 서버 수 |
| 주기 | 스케줄이 수행 주기
|
| 날짜/요일 | 스케줄 수행 날짜 또는 요일
|
| 수행 시간 | 스케줄 수행 시간 |
| 시간대 | 스케줄 수행 시간대 |
| 상태 | 스케줄 상태 |
| 더보기 > 수정 | 해당 스케줄 정보를 수정
|
| 더보기 > 활성화 | 해당 스케줄을 활성화
|
| 더보기 > 비활성화 | 해당 스케줄을 비활성화
|
표. Auto-Scaling Group 상세 - 스케줄 탭 항목
스케줄 관리에 대해서는 스케줄 추가하기와 스케줄 삭제하기를 참고하세요.
Virtual Server
Auto-Scaling Group 목록 페이지에서 선택한 자원의 Virtual Server 목록를 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서버명 | Auto-Scaling Group에 생성된 서버 이름
|
| IP | 서버에 할당된 IP |
| 생성 일시 | 서버가 생성된 날짜와 시간 |
| 상태 | 서버의 상태
|
| LB 연결 상태 | Load Balancer를 설정한 경우, Load Balancer와의 연결 상태
|
표. Auto-Scaling Group 상세 - Virtual Server 탭 항목
Load Balancer
Auto-Scaling Group 목록 페이지에서 선택한 자원의 Load Balancer 목록를 확인하고, 필요한 경우 Load Balancer를 추가하거나 관리할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| Draining Timeout | Draining Timeout 사용 여부
|
| Load Balancer | Load Balancer 사용 여부
|
| Load Balancer > Load Balancer명 | Auto-Scaling Group에 연결할 Load Balancer 이름 |
| Load Balancer > LB 서버 그룹 | Load Balancer의 LB 서버 그룹
|
| Load Balancer > 포트 | LB 서버 그룹에 Member로 등록한 포트 |
표. Auto-Scaling Group 상세 - Load Balancer 탭 항목
참고
- Auto-Scaling Group에서 설정한 LB 서버 그룹 Member 정보는 LB 서버 그룹 연결된 자원에서도 확인 가능합니다.
- 또한 서버-Load Balancer간 수동으로 연결/분리가 필요할 경우 LB 서버 그룹 Member 추기하기를 참고하세요.
알림
Auto-Scaling Group 목록 페이지에서 선택한 자원의 알림 수신인 정보와 알림 방식을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 알림 수신자 | 알림 수신자의 이름 |
| 이메일 | 알림 수신자의 이메일 |
| 서버 생성 | 서버 생성 관련 알림 발생 시 알림 발송 여부
|
| 서버 해지 | 서버 해지 관련 알림 발생 시 알림 발송 여부
|
| 정책 실행 조건 만족 시 | 정책 실행 조건 만족 시 알림 발생 여부 |
| 상태 | 알림 활성화 상태
|
| 더보기 > 수정 | 해당 알림 정보를 수정 |
| 더보기 > 활성화 | 해당 알림 정보를 활성화
|
| 더보기 > 비활성화 | 해당 알림 정보를 비활성화
|
표. Auto-Scaling Group 상세 - 알림 탭 항목
알림 설정에 대한 자세한 내용은 알림 관리하기를 참고하세요.
태그
Auto-Scaling Group 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Auto-Scaling Group 상세 - 태그 탭 항목
작업 이력
Auto-Scaling Group 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Auto-Scaling Group 상세 - 작업 이력 탭 항목
Auto-Scaling Group 자원 관리하기
생성된 Auto-Scaling Group의 관리 기능이 필요한 경우, Auto-Scaling Group 상세 페이지에서 작업을 수행할 수 있습니다.
Launch Configuration 수정하기
Auto-Scaling Group의 Launch Configuration을 수정할 수 있습니다.
참고
Launch Configuration을 수정해도 이미 생성된 Auto-Scaling Group의 서버에는 적용되지 않고, 이후 새로 생성되는 서버부터 적용됩니다. 수정된 Launch Configuation으로 Auto-Scaling Group의 모든 서버에 적용하고자 한다면, 서버 수(Desired)를 0으로 조정하여 기존 서버를 모두 삭제한 뒤, 다시 서버 수(Desired)를 원하는 수량으로 수정해주세요.
Auto-Scaling Group의 Launch Configuration 수정하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
Auto-Scaling Group 목록 페이지에서 Launch Configuration 수정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
Launch Configuration명 수정 버튼을 클릭하세요. Launch Configuration 수정 팝업창이 열립니다. 선택 가능한 Launch Configuration 목록을 확인할 수 있습니다.
구분상세 설명 Launch Configuration 명 Launch Configuration 이름 이미지 Launch Configuration OS 이미지 서버 타입 Launch Configuration 서버 타입 Block Storage Launch Configuration Block Storage 설정 Auto-Scaling Group 수 Launch Configuration이 적용된 Auto-Scailg Group 개수 상세 보기 Launch Configuration 상세 조회할 수 있는 버튼 표. Launch Configuration 목록 항목Launch Configuration 수정 팝업창에서 변경할 Launch Configuration을 선택한 후, 확인 버튼을 클릭하세요. Launch Configuration 수정 알림 팝업창이 열립니다. Launch Configuration 수정 알림 팝업창의 메시지를 확인하고 확인 버튼을 클릭 하세요.
서버 수 수정하기
Auto-Scaling Group의 서버 수를 수정할 수 있습니다.
참고
최대 설정 가능한 서버 수는 50대 입니다. 단, Load Balancer가 있는 경우, Load Balancer에 연결되지 않은 서버 수는 제외합니다.
Auto-Scaling Group의 서버 수를 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 서버 수 수정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 서버 수 수정 버튼을 클릭하세요. 서버 수 수정 팝업창이 열립니다.
- 서버 수 수정 팝업창에서 필수 항목 입력 후, 확인 버튼 클릭하세요.
구분 필수 여부상세 설명 서버 수 > Min 필수 수정할 최소 서버 수 - Auto-Scaling Group이 최소한으로 유지할 서버 수를 설정
서버 수 > Desired 필수 수정할 목표 서버 수 - Auto-Scaling Group내 목표 서버 수를 설정
- Desired 서버 수 수동 설정이 미사용으로 설정된 경우에는 Desired 서버 수를 수정할 수 없습니다. Desired 서버 수를 수정하려면 Desired 서버 수 수동 설정 수정하기를 참고
서버 수 > Max 필수 수정할 목표 서버 수 - Auto-Scailg Group이 최대로 유지할 수 있는 서버 수를 설정
표. Auto-Scailg Group 서버 수 수정 항목
Auto-Scaling Group에서 생성한 Virtual Server 해지하기
Auto-Scaling Group에서 생성한 Virtual Server는 해당 Virtual Server의 상세 페이지에서 해지 버튼을 클릭하거나 서버 수를 수정하여 해지할 수 있습니다.
주의
- 서비스 해지 후에는 데이터를 복구할 수 없으므로 주의하세요.
- 서비스를 해지하려면 먼저 File Storage 연결 및 Lock 사용을 해제하세요. File Storage가 연결되어 있거나 Lock이 설정된 경우에는 Virtual Server를 해지할 수 없습니다.
참고
- Auto-Scaling Group에서 생성한 Virtual Server를 해지하면 연결된 Load Balancer가 자동으로 분리됩니다.
- Virtual Server 해지 시 연결된 Storage 상태는 다음과 같습니다.
- Delete on termination을 설정하지 않은 경우: Virtual Server를 해지해도 볼륨이 삭제되지 않습니다.
- Delete on termination을 설정한 경우: Virtual Server를 해지하면 해당 볼륨이 삭제됩니다. 단, Snapshot이 존재할 경우에는 Delete on termination이 설정되어 있어도 삭제되지 않습니다.
- Multi attach 볼륨: 삭제하려는 서버가 볼륨에 연결된 마지막 남은 서버일 때만 삭제됩니다.
Virtual Server 상세 페이지에서 해지하기
Virtual Server 상세 페이지에서 Virtual Server를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 Auto-Scaling Group에서 생성한 Virtual Server를 선택하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 서비스 해지 버튼을 클릭하세요. 서버 해지를 알리는 팝업창이 열립니다.
- 확인 버튼을 클릭하세요. 서버 해지가 완료됩니다.
서버 수를 수정하여 해지하기
서버 수를 수정하여 Virtual Server를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 Virtual Server를 해지할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 서버 수 항목의 수정 버튼을 클릭하세요. 서버 수 수정 팝업창이 열립니다.
- 서버 수 수정 팝업창에서 Desired 수를 줄인 후, 확인 버튼 클릭하세요. Desired 서버 수가 조정되면서 Virtual Server가 해지됩니다.
안내
- Desired 서버 수 수동 설정이 미사용으로 설정된 경우에는 Desired 서버 수를 수정할 수 없습니다. Desired 서버 수를 수정하려면 Desired 서버 수 수동 설정 수정하기를 참고하세요.
- Virtual Server 해지 시 Desired 서버 수는 그대로 유지되며, Desired 체크 배치에 따라 scale-out을 진행합니다.
Desired 서버 수 수동 설정 수정하기
Auto-Scaling Group의 Desired 서버 수 수동 설정을 변경할 수 있습니다.
참고
Desired 서버 수 수동 설정 사용을 선택하지 않을 경우, 상세 정보의 서버 수 수정에서 Desired 서버 수를 수정할 수 없습니다. Desired 서버 수는 Virtual Server 상태를 10분 단위로 체크하여 자동으로 맞춥니다.
Auto-Scaling Group의 Desired 서버 수 수동 설정을 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 Desired 서버 수 수동 설정을 변경할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 서버 수 수정 버튼을 클릭하세요. Desired 서버 수 수동 설정 팝업창이 열립니다.
- Desired 서버 수 수동 설정 팝업창에서 사용 여부를 선택한 후, 확인 버튼 클릭하세요.
Security Group 설정하기
Auto-Scaling Group의 Security Group을 설정할 수 있습니다.
참고
Security Group을 수정해도 이미 생성된 Auto-Scaling Group의 서버에는 적용되지 않고, 이후 새로 생성되는 서버부터 적용됩니다. 수정된 Security Group으로 Auto-Scaling Group의 모든 서버에 적용하고자 한다면, 서버 수(Desired)를 0으로 조정하여 기존 서버를 모두 삭제한 뒤, 다시 서버 수(Desired)를 원하는 수량으로 수정해주세요.
Auto-Scaling Group의 Security Group을 설정하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
Auto-Scaling Group 목록 페이지에서 Security Group 설정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
Security Group 수정 버튼을 클릭하세요. Security Group 수정 팝업창이 열립니다. 선택 가능한 Security Group 목록을 확인할 수 있습니다.
구분 상세 설명 Security Group 명 Security Group 이름 표. Security Group 목록 항목Security Group 수정 팝업창에서 Security Group을 선택한 후, 확인 버튼을 클릭하세요. Security Group 수정 알림 팝업창이 열립니다. Security Group 수정 알림 팝업창의 메시지를 확인하고 확인 버튼을 클릭 하세요.
Auto-Scaling Group 추가 정보 관리하기
Auto-Scaling Group의 Load Balancer를 사용으로 설정하고 LB 서버그룹을 선택할 수 있습니다. Load Balancer를 사용중인 Auto-Scaling Group의 경우 미사용으로 변경할 수 있습니다.
Load Balancer Draining Timeout 수정하기
Auto-Scaling Group의 Load Balancer Draining Timeout을 설정할 수 있습니다.
참고
Draining Timeout은 서버를 Load Balancer에서 분리하기 전에 대기하는 시간입니다.
- 해당 서버로 연결된 세션이 남아있을 수 있기 때문에 Draining Timeout을 설정하여 대기하면 더욱 안전하게 세션을 정리할 수 있습니다.
- Load Balancer가 미사용이면 Draining Timeout은 설정이 불가능합니다.
- 기본값은 300초, 최소 1초 ~ 최대 3,600초까지 설정할 수 있습니다.
Auto-Scaling Group의 Load Balancer Draining Timeout을 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 Load Balancer Draining Timeout 설정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- Load Balancer 탭을 클릭하세요. Load Balancer 목록 페이지로 이동합니다.
- Draining Timeout 의 수정 버튼을 클릭하세요. Draining Timeout 수정 팝업창이 열립니다.
- Draining Timeout 수정 팝업창에서 Draining Timeout 사용 여부를 선택하고, Draining Timeout 시간(초)을 입력하세요.
- Draining Timeout 수정 팝업창에서 입력값을 확인한 후, 확인 버튼을 클릭하세요. Draining Timeout 수정 알림 팝업창이 열립니다. 알림 팝업창의 메시지를 확인하고 확인 버튼을 클릭 하세요.-
Load Balancer 사용하기
Auto-Scaling Group의 Load Balancer을 수정할 수 있습니다. Auto-Scaling Group의 Load Balancer을 설정하려면 다음 절차를 따르세요.
참고
- Auto-Scaling Group의 서버가 생성되면 선택한 Load Balancer의 LB 서버 그룹의 Member로 자동으로 연결되고, 서버가 해지되면 LB 서버 그룹의 Member에서 분리됩니다.
- Draining Timeout이 사용중이라면, Draining Timeout(초) 만큼 대기한 후 서버가 LB 서버 그룹의 Member에서 분리됩니다.
- Load Balancer 수정에 의한 Member 분리의 경우 Detach from LB 상태로 대기하고, Scale In에 의한 Member 분리의 경우 Scale In 상태로 대기합니다.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 Load Balancer 설정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- Load Balancer 탭을 클릭하세요. Load Balancer 목록 페이지로 이동합니다.
- Load Balancer 의 수정 버튼을 클릭하세요. Load Balancer 수정 팝업창이 열립니다.
- Load Balancer 수정 팝업창에서 사용 여부를 선택합니다. 사용으로 선택하면 Load Balancer를 선택할 수 있습니다.
구분 상세 설명 LB 서버 그룹 LB 서버 그룹 이름 - 선택한 VPC에 생성되어 있는 LB 서버 그룹을 선택
- Weighted Round Robin 또는 Weighted Least Connection 부하 분산을 사용하는 LB 서버 그룹은 선택 불가
포트 LB 서버 그룹의 포트 정보 - LB 서버 그룹 Member로 등록할 때, 등록정보로 필요한 포트 정보를 입력합니다.
- 1~65,534 사이의 값을 입력
표. Load Balancer 목록 항목- + 버튼을 클릭하여 LB 서버 그룹을 추가할 수 있습니다. 총 3개까지 가능합니다. X 버튼을 클릭하여 추가한 Load Balancer를 제거할 수 있습니다.
- Load Balancer 목록을 확인하고 확인 버튼을 클릭하세요. Load Balancer 수정 알림 팝업창이 열립니다. 알림 팝업창의 메시지를 확인하고 확인 버튼을 클릭 하세요.
주의
- Load Balancer로부터 서버를 분리/연결하는 시점에 서비스 영향이 있을 수 있으니 주의해주세요.
- Draining Timeout이 사용중이라면, Load Balancer를 미사용으로 설정하거나 연결된 Load Balancer 중 일부를 X 버튼으로 제거하여도 바로 분리되지 않습니다. Draining Timeout(초) 만큼 대기한 후 Load Balancer로부터 서버가 분리됩니다. 이때 Auto-Scaling Group은 Detach from LB 상태로 대기합니다.
참고
- Auto-Scaling Group에서 설정한 LB 서버 그룹 Member 정보는 LB 서버 그룹 연결된 자원에서도 확인 가능합니다.
- 또한 서버-Load Balancer간 수동으로 연결/분리가 필요할 경우 LB 서버 그룹 Member 등록하기를 참고하세요.
Load Balancer 미사용하기
Auto-Scaling Group의 Load Balancer을 미사용으로 수정할 수 있습니다. Auto-Scaling Group의 Load Balancer 미사용 설정을 하려면 다음 절차를 따르세요.
주의
- Load Balancer로부터 서버를 분리/연결하는 시점에 서비스 영향이 있을 수 있으니 주의해주세요.
- Draining Timeout이 사용중이라면, Load Balancer를 미사용으로 설정하거나 연결된 Load Balancer 중 일부를 X 버튼으로 제거하여도 바로 분리되지 않습니다. Draining Timeout(초) 만큼 대기한 후 Load Balancer로부터 서버가 분리됩니다. 이때 Auto-Scaling Group은 Detach from LB 상태로 대기합니다.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 Load Balancer 설정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- Load Balancer 탭을 클릭하세요. Load Balancer 목록 페이지로 이동합니다.
- Load Balancer 의 수정 버튼을 클릭하세요. Load Balancer 수정 팝업창이 열립니다.
- Load Balancer 수정 팝업창에서 사용 여부를 선택합니다. 사용을 선택 해제하면 더 이상 Load Balancer를 사용하지 않게 됩니다.
- 사용 선택 해제 확인하고, 확인 버튼을 클릭하세요. Load Balancer 수정 알림 팝업창이 열립니다. 알림 팝업창의 메시지를 확인하고 확인 버튼을 클릭 하세요.
Auto-Scaling Group 삭제하기
사용하지 않는 Auto-Scaling Group을 삭제하면 운영 비용을 절감할 수 있습니다. 단, Auto-Scaling Group을 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Auto-Scaling Group을 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 해지할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- Auto-Scaling Group 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Auto-Scaling Group 목록 페이지에서 자원이 삭제되었는지 확인하세요.
2.2.1 - Launch Configuration
Auto-Scaling Group 생성하기 위해서는 사전에 Launch Configuration이 생성이 필요합니다.
Launch Configuration 생성하기
Samsung Cloud Platform Console에서 Launch Configuration 서비스를 생성하여 사용할 수 있습니다.
Launch Configuration 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Launch Configuration 메뉴를 클릭하세요. Launch Configuration 목록 페이지로 이동합니다.
Launch Configuration 목록 페이지에서 Launch Configuration 생성 버튼을 클릭하세요. Launch Configurationp 생성 페이지로 이동합니다.
Launch Configurationp 생성 페이지의 이미지 및 버전 선택 영역에서 필요한 정보를 선택하고 다음 버튼을 클릭하세요.
참고Launch Configuration에서 선택 가능한 이미지는 서버 타입은 Virtual Server OS 이미지 제공 버전을 참고하세요.Launch Configurationp 생성 페이지의 서비스 정보 입력 영역에 필요한 정보를 입력하세요.
구분 필수 여부상세 설명 Launch Configuration 명 필수 Launch Configuration 이름 - Launch Configuration을 구별하기 위한 명칭
서비스 유형 > 서버 타입 필수 Launch Configuration의 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: Standard 이상의 대용량 서버 사양
- 선택 가능한 서버 타입은 Virtual Server 서버 타입을 참고
Block Storage 필수 Launch Configuration의 용도에 따라 Block Storage 설정 - 기본 OS: OS가 설치되어 사용되는 영역
- 용량은 Units 단위로 입력하며, OS이미지 종류에 따라 최소 용량이 다름
- Alma Linux: 2~1,536 사이의 값을 입력
- Oracle Linux: 5~1,536 사이의 값을 입력
- RHEL: 2~1,536 사이의 값을 입력
- Rocky Linux: 2~1,536 사이의 값을 입력
- Ubuntu: 1~1,536 사이의 값을 입력
- Windows: 4~1,536 사이의 값을 입력
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 적용 가능하고, 생성 후 변경 불가
- SSD_KMS 디스크 유형을 사용하는 경우에는 성능 저하가 발생
- 용량은 Units 단위로 입력하며, OS이미지 종류에 따라 최소 용량이 다름
- 추가: OS영역 외 사용자 추가 공간 필요 시 사용
- 사용을 선택한 후, 스토리지의 유형과 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭(최대 25개까지 추가)
- 용량은 Units 단위로 입력하며, 1~1,536 사이의 값을 입력
- 1 Unit은 8GB이므로 8 ~ 12,288GB가 생성됨
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 적용 가능하고, 생성 후 변경 불가
- SSD_KMS 디스크 유형을 사용하는 경우에는 성능 저하가 발생
- SSD_MultiAttach: 2개 이상의 서버 연결이 가능한 볼륨
- Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고
Keypair 필수 Launch Configuration의 사용자 증명 방법을 선택 - Launch Configuration으로 Auto-Scaling Group을 생성하여 만들어진 서버에 접속하기 위한 서버 인증 정보
- 신규 생성: 새로운 Keypair가 필요한 경우 신규 생성
- 신규 Keypair 생성 방법은 Keypair 생성하기 를 참고
- OS별 기본 접속 계정 리스트
- Alma Linux: almalinux
- RHEL: cloud-user
- Rocky Linux: rocky
- Ubuntu: ubuntu
- Windows: sysadmin
표. Launch Configuration 서비스 정보 입력 항목Launch Configuration 생성 페이지에서 추가 정보 입력 영역에 정보를 입력한 후, 다음 버튼을 클릭하세요.
구분 필수 여부상세 설명 Init Script 선택 Launch Configuration을 사용할 Auto-Scaling Group의 서버 시작 시, 실행되는 스크립트 - 45,000 bytes 이내로 입력
- Init Script는 선택 이미지에 따라 Windows의 경우 배치 스크립트, 리눅스의 경우 쉘 스크립트 또는 cloud-init여야 합니다.
태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Launch Configuration 추가 정보 입력 항목생성 정보 확인 페이지에서 입력한 정보와 예상 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Launch Configuration 목록 페이지에서 생성한 Launch Configuration을 확인하세요.
Launch Configuration 상세 정보 확인하기
Launch Configuration 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Launch Configuration 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Launch Configuration 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Launch Configuration 메뉴를 클릭하세요. Launch Configuration 목록 페이지로 이동합니다.
- Launch Configuration 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Launch Configuration 상세 페이지로 이동합니다.
- Launch Configuration 상세 페이지 상단에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 Launch Configuration 상태 사용자가 생성한 Launch Configuration의 상태 - Active: 사용 가능한 상태
Launch Configuration 삭제 Launch Configuration 삭제하는 버튼 표. Launch Configuration 상태 정보 및 부가 기능
- Launch Configuration 상세 페이지 상단에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Launch Configuration 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Launch Configuration명 | Launch Configuration 이름 |
| 이미지 | Launch Configuration을 생성할 때, 선택한 이미지 이름
|
| Auto-Scaling Group 수 | Launch Configuration을 사용하고 있는 Auto-Scaling Group의 개수 |
| 서버 타입 | Launch Configuration에 설정한 서버 타입 |
| Block Storage | Launch Configuration에 설정한 서버 당 Block Storage 정보
|
| Keypair | Launch Configuration에 설정한 서버 인증 정보
|
| Init Script | Launch Configuration에 설정한 Init Script
|
표. Launch Configuration 상세 정보 탭 항목
태그
Launch Configuration 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Launch Configuration 태그 탭 항목
작업 이력
Launch Configuration 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Launch Configuration 작업 이력 탭 상세 정보 항목
Launch Configuration 삭제하기
사용하지 않는 Launch Configuration을 삭제하면 운영 비용을 절감할 수 있습니다. 단, Launch Configuration을 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
데이터 삭제 후에는 복구할 수 없으므로 주의해주세요.
Launch Configuration을 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Launch Configuration 메뉴를 클릭하세요. Launch Configuration 목록 페이지로 이동합니다.
- Launch Configuration 목록 페이지에서 해지할 자원을 클릭하세요. Launch Configuration 상세 페이지로 이동합니다.
- Launch Configuration 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Launch Configuration 목록 페이지에서 자원이 삭제되었는지 확인하세요.
주의
Auto-Scaling Group에 적용되어 있는 Launch Configuration은 삭제할 수 없습니다.
Auto-Scaling Group을 먼저 삭제한 후, Launch Configuration 삭제해주세요.
2.2.2 - 정책 관리하기
Auto-Scaling Group의 서버 수를 모니터링 지표를 기반으로 동적으로 조정할 수 있습니다. 모니터링 지표 기반으로 설정한 임계치를 벗어나는 경우, 서버 수를 조정하는 방식입니다. 이때 서버 수를 조정하는 방식을 3가지 중에 선택 할 수 있습니다. 지정 대수만큼 서버 수 증감, 지정한 비율로 서버 수 증감, 입력한 값으로 서버 수 고정입니다. 정책으로 인한 서버가 시작되고 해지될 때, 일시적으로 모니터링 지표인 CPU 사용률이 정책에 등록한 임계치를 벗어날 수 있습니다. 하지만 이는 일시적인 순간이기 때문에 비정상 상황으로 판단하지 않기 위해 쿨다운 시간을 설정합니다. Samsung Cloud Platform Console에서 생성한 Auto-Scaling Group에 정책을 추가하고 관리할 수 있습니다.
정책 추가하기
Auto-Scaling Group의 정책을 추가할 수 있습니다. Auto-Scaling Group의 정책을 추가하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
정책 탭을 클릭하세요. 정책 탭 페이지로 이동합니다.
정책 추가 버튼을 클릭하세요. 정책 추가 팝업창이 열립니다.
구분 필수상세 설명 구분 필수 정책 구분 - Scale In: 서버 수 반납
- Scale Out: 서버 수 증가
정책명 필수 정책 별 구분할 이름 실행 조건 필수 정책을 실행할 조건 - Statistic: Metric Type을 계산하는 방법
- Average: Auto-Scaling Group 내 서버들의 평균
- Min: Auto-Scaling Group 내 서버들 중 최소 값
- Max: Auto-Scaling Group 내 서버들 중 최대 값
- Metric Type: CPU Usage, Memory Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- 단, Memory usage 정책은 Windows 서버에서 설정 불가
- Operator:
>=><=<
- Threshold: Metric Type에 해당하는 임계치
- Period: 실행 조건을 발생 시킬 연속 시간(N분간 지속적으로 실행 조건을 만족해야 정책이 실행)
실행 단위 필수 정책을 실행하는 방식 - Policy Type: 정책을 실행할 유형을 선택합니다.
- 지정 대수만큼 서버 수 증감: 서버 수 Target Value 증가 또는 반납
- 지정한 비율로 서버 수 증감: Target Value 비율로 증가 또는 반납
- 입력한 값으로 서버 수 고정: 서버 수 Target Value 대로 고정
- Target Value: 선택한 Policy Type을 실행할 개수 또는 비율
쿨다운 필수 정책으로 인한 서버가 시작 또는 해지될 때, 대기하는 시간(초) - 기본값은 300초이며, 최소 60초~최대 3,600초로 설정 가능합니다.
표. 정책 추가 팝업 항목참고정책 > 쿨다운 설정
- 정책으로 인한 서버가 시작되고 해지될 때, 쿨다운으로 설정한 시간만큼 대기합니다. 일시적으로 모니터링 지표인 CPU 사용률이 정책에 등록한 임계치를 벗어날 수 있습니다. 하지만 이는 서버 수를 조정하기 위한 조건이 아닌 일시적인 순간이기 때문에 비정상 상황으로 판단하지 않고 쿨다운 시간을 설정하여 대기합니다.
안내정책 실행은 설정한 Min/Max 서버 수 범위 내에서 동작합니다.
- 서버 수 증가 및 반납, 서버 수 고정 등 Min/Max 서버 수 범위 밖으로 입력하더라도 설정되어 있는 Min/Max 서버 수 안에서 동작합니다.
- 예시: Min 서버 수가 3일때, 서버 수 고정을 1로 하여도 서버 수가 1로 줄어들지 않고 최소 서버 수인 3을 유지합니다.
정책 추가 팝업창에서 필수값을 입력한 후, 확인 버튼을 클릭하세요. 추가한 정책은 정책 목록에서 확인하세요.
정책 생성 예시
아래는 정책 예시에 대한 설명입니다. 정책 생성 시, 참고하세요.
정책 예시 설명 1
| 구분 | 실행 조건 | 실행 단위 | 쿨다운 |
|---|---|---|---|
| Scale Out | Average CPU Usage >= 60% 1분동안 발생 | 지정 대수만큼 서버 수 증감 1대수로 증가 | 300초 |
표. Auto-Scaling Group 정책 예시1
- Auto-Scaling Group 내 서버들 평균 CPU Usage가 60% 이상 1분 동안 지속되는 경우, 1대씩 서버가 추가로 생성됩니다.
- 서버가 추가로 생성될 때 쿨다운 시간은 300초로, 쿨다운 시간 동안은 정책으로 인한 서버 추가 또는 반납이 발생하지 않습니다.
- 쿨다운 시간이 종료된 후에 다시 정책 실행 조건을 확인합니다.
정책 예시 설명 2
| 구분 | 실행 조건 | 실행 단위 | 쿨다운 |
|---|---|---|---|
| Scale In | Min CPU Usage <= 5% 1분동안 발생 | 지정한 비율로 서버 수 증감 50% 반납 | 300초 |
표. Auto-Scaling Group 정책 예시2
- Auto-Scaling Group 내 서버들 중 최소 CPU Usage가 5% 이하 1분 동안 지속되는 경우, 현재 서버 수의 50%가 해지됩니다.
- 서버가 해지될 때 쿨다운 시간은 300초로, 쿨다운 시간 동안은 정책으로 인한 서버 추가 또는 반납이 발생하지 않습니다.
- 쿨다운 시간이 종료된 후에 다시 정책 실행 조건을 확인합니다.
정책 예시 설명 3
| 구분 | 실행 조건 | 실행 단위 | 쿨다운 |
|---|---|---|---|
| Scale Out | Max CPU Usage >= 90% 1분동안 발생 | 입력한 값으로 서버 수 고정 5대로 고정 | 300초 |
표. Auto-Scaling Group 정책 예시3
- Auto-Scaling Group 내 서버들 중 최대 CPU Usage가 90% 이상 1분 동안 지속되는 경우, 현재 서버 수가 5대보다 적은 경우 서버가 5개까지 생성됩니다.
- 서버가 생성되는 동안 쿨다운 시간은 300초로, 쿨다운 시간 동안은 정책으로 인한 서버 추가 또는 반납이 발생하지 않습니다.
- 쿨다운 시간이 종료된 후에 다시 정책 실행 조건을 확인합니다.
정책 수정하기
Auto-Scaling Group의 정책을 수정할 수 있습니다. Auto-Scaling Group의 정책을 수정하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
정책 탭을 클릭하세요. 정책 탭 페이지로 이동합니다.
수정할 정책의 더보기 > 수정 버튼을 클릭하세요. 정책 수정 팝업 열립니다.
구분 필수상세 설명 구분 필수 정책 구분 - Scale In: 서버 수 반납
- Scale Out: 서버 수 증가
정책명 필수 정책 별 구분할 이름 실행 조건 필수 정책을 실행할 조건 - Statistic: Metric Type을 계산하는 방법
- Average: Auto-Scaling Group 내 서버들의 평균
- Min: Auto-Scaling Group 내 서버들 중 최소 값
- Max: Auto-Scaling Group 내 서버들 중 최대 값
- Metric Type: CPU Usage, Memory Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- 단, Memory usage 정책은 Windows 서버에서 설정 불가
- Operator:
>=><=<
- Threshold: Metric Type에 해당하는 임계치
- Period: 실행 조건을 발생 시킬 연속 시간(N분 발생)
실행 단위 필수 정책을 실행하는 방식 - Policy Type: 정책을 실행할 유형을 선택합니다.
- 지정 대수만큼 서버 수 증감: 서버 수 Target Value 증가 또는 반납
- 지정한 비율로 서버 수 증감: Target Value 비율로 증가 또는 반납
- 입력한 값으로 서버 수 고정: 서버 수 Target Value 대로 고정
- Target Value: 선택한 Policy Type을 실행할 개수 또는 비율
쿨다운 필수 정책으로 인한 서버가 시작 또는 해지될 때, 대기하는 시간(초) - 기본값은 300초, 최소 1초 ~ 최대 3,600초까지 설정
표. 정책 수정 팝업 항목정책 수정 팝업창에서 필수값을 입력한 후, 확인 버튼을 클릭하세요.
정책 추가 및 수정 제약 사항
정책 추가할때나 정책 수정할때 정책 구분, 실행 조건, 실행 조건 범위에 따라 제약 사항이 존재합니다. 아래는 정책에 대한 제약 사항에 대한 예시입니다. 제약 사항 예시를 참고하여 정책을 추가하거나 수정하세요.
예시 1 - 정책 구분/실행 조건 중복 등록 확인 필요
정책 구분(Scale Out 또는 Scale In)과 실행 조건(Metric type)이 동일하게 중복 등록이 불가합니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
표. 정책 제약 사항 예시 1 - 선행 등록 정책
위와 같이 정책이 등록되어 있는 경우, 구분(Scale Out) 실행 조건(Metric type=CPU Usage)로 정책 추가하거나 해당 조건으로 수정 불가합니다.
예시 2 - 정책 구분에 따른 실행 조건(Metric type)과 실행 조건(Statistic)에 대해 실행 조건 범위 확인 필요
정책 구분(Scale Out 또는 Scale In)이 다를 때, 동일한 실행 조건(Metric type)과 실행 조건(Statistic)에 대해서 실행 조건 범위(Comparison operator + Threshold)는 중복 등록이 불가합니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
표. 정책 제약 사항 예시 2 - 선행 등록 정책
위와 같이 정책이 등록되어 있는 경우, 아래와 같이 정책 추가하거나 아래 조건으로 수정 불가합니다.
CPU Usage이 평균 60% 이상일 경우, Scale Out 정책이 이미 등록되어 있기 때문에, CPU Usage 평균 60% 이하일 경우 Scale In 정책을 등록하면 60%인 경우가 동일 실행 조건으로 중복되어 등록할 수 없습니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale In | AddUpdatePolicy | Average | CPU Usage | <= 60% |
표. 정책 제약 사항 예시 2 - 추가 불가 정책
예시 3 - 정책 구분에 따른 실행 조건(Metric type)과 실행 조건(Statistic)에 대해 실행 조건 범위 확인 필요
정책 구분(Scale Out 또는 Scale In)이 다를 때, 동일한 실행 조건(Metric type)과 실행 조건(Statistic)에 대해서 실행 조건 범위(Comparison operator + Threshold)는 중복 등록이 불가합니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale In | ScaleInPolicy | Average | CPU Usage | <= 10% |
표. 정책 제약 사항 예시 3 - 선행 등록 정책
위와 같이 정책이 등록되어 있는 경우, 아래와 같이 정책 추가하거나 아래 조건으로 수정 불가합니다.
CPU Usage이 평균 10% 이하일 경우, Scale In 정책이 이미 등록되어 있기 때문에, CPU Usage 평균 60% 미만/60% 이하/10% 이상/9% 초과인 경우, Scale Out 정책을 등록하면 실행 조건 범위가 중복되어 등록할 수 없습니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale Out | AddUpdatePolicy1 | Average | CPU Usage | < 60% |
Scale Out | AddUpdatePolicy2 | Average | CPU Usage | <= 60% |
Scale Out | AddUpdatePolicy3 | Average | CPU Usage | >= 10% |
Scale Out | AddUpdatePolicy4 | Average | CPU Usage | > 9% |
표. 정책 제약 사항 예시 3 - 추가 불가 정책
예시 4 - 정책 구분에 따른 실행 조건(Metric type)과 실행 조건(Statistic)에 대해 실행 조건 범위에 따라 등록 가능
정책 구분(Scale Out 또는 Scale In)이 다를 때, 동일한 실행 조건(Metric type)에 대해 실행 조건(Statistic)이 다르거나 실행 조건 범위(Comparison operator + Threshold)가 겹치지 않으면 등록 가능합니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
표. 정책 제약 사항 예시 4 - 선행 등록 정책
위와 같이 정책이 등록되어 있는 경우, 아래와 같이 정책 추가하거나 아래 조건으로 수정 가능합니다. 실행 조건 범위가 겹치지않거나, 실행 조건(Statistic)이 다르면 등록이 가능합니다.
| 정책 구분 | 정책명 | 실행 조건(Statistic) | 실행 조건(Metric type) | 실행 조건 범위 |
|---|---|---|---|---|
Scale In | AddUpdatePolicy1 | Average | CPU Usage | <= 10% |
Scale In | AddUpdatePolicy2 | Min | CPU Usage | <= 60% |
표. 정책 제약 사항 예시 4 - 추가 가능 정책
정책 삭제하기
Auto-Scaling Group의 정책을 삭제할 수 있습니다. Auto-Scaling Group의 정책을 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 정책 탭을 클릭하세요. 정책 탭 페이지로 이동합니다.
- 삭제할 정책을 선택하고 삭제 버튼을 클릭하세요. 정책 삭제 확인 팝업창이 열립니다.
- 정책 삭제 확인 팝업창을 확인하고 확인 버튼을 클릭하세요.
2.2.3 - 스케줄 관리하기
매일, 매주, 매달 또는 한번 스케줄 예약을 할 수 있으며, 정해진 시간에 원하는 서버 수를 설정할 수 있습니다. 이는 어떨 때 서버 수를 줄이거나 늘려야 할지 예측이 가능한 경우에 유용하게 사용할 수 있습니다.
스케줄 추가하기
Auto-Scaling Group의 스케줄을 추가할 수 있습니다. Auto-Scaling Group의 스케줄을 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 스케줄 탭을 클릭하세요. 스케줄 탭 페이지로 이동합니다.
- 스케줄 추가 버튼을 클릭하세요. 스케줄 추가 팝업창이 열립니다.
구분 필수상세 설명 스케줄명 필수 스케줄 별 구분할 이름 서버 수 선택 필수 스케줄 수행 시, 조정할 서버 수를 선택 - Min: Auto-Scailg Group이 최소한으로 유지할 서버 수
- Desired: Auto-Scailg Group 내 목표 서버 수
- Max: Auto-Scailg Group이 최대로 유지할 수 있는 서버 수
서버 수 입력 필수 선택한 서버 수의 값을 입력 - Min 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
- Desired 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
- Max 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
주기 필수 스케줄 수행 주기 - 매일: 매일 스케줄이 수행될 시작일과 종료일, 영구 설정을 할 수 있습니다. 또한 시간과 시간대를 설정
- 매주: 시작일과 종료일, 영구 설정 및 시간과 시간대를 설정을 할 수 있습니다. 또한 매주 스케줄이 수행될 요일을 선택할 수 있습니다.
- 매달: 시작일과 종료일, 영구 설정 및 시간과 시간대를 설정을 할 수 있습니다. 또한 매달 스케줄이 수행될 Date를 입력 가능
- 한 번: 시간과 시간대를 설정을 할 수 있습니다. 또한 한 번 스케줄이 수행될 Date를 설정
시작일 선택 스케줄 시작 날짜 설정 - 현재 날짜 이전으로 설정할 수 없습니다. 기본값은 현재 날짜입니다.
종료일 선택 스케줄 종료 날짜 설정 - 현재 날짜 이전으로 설정할 수 없습니다. 기본값은 현재 날짜 + 7입니다.
영구 선택 영구 설정 시, 스케줄 종료일을 9999-12-31로 설정 시간 필수 스케줄 수행 시간 설정 - 30분 단위로 설정 가능합니다. 현재 날짜, 현재 시간보다 빠른 시간은 설정 불가
시간대 필수 스케줄 수행 시간에 해당하는 시간대 (예시: Asia/Seoul (GMT +09:00)) 요일 필수 주기를 매주 선택한 경우, 스케줄 수행할 요일을 선택 Date 필수 - 주기를 매달 선택한 경우, 스케줄 수행할 날짜인 Date를 입력
- 0을 제외한 -31~31까지 한 개이상 입력하세요. (예시: 3,4,5)
- 주기를 한 번 선택한 경우, 스케줄 수행할 날짜인 Date를 설정
- 현재 날짜 이전으로 설정 불가합니다. 기본값은 현재 날짜입니다.
표. 스케줄 추가 팝업 항목 - 스케줄 추가 팝업창에서 필수값을 입력한 후, 확인 버튼을 클릭하세요.
- 스케줄 추가 확인 팝업창의 메시지 확인 후, 확인 버튼을 클릭하세요.
참고
스케줄 주기를 매달 선택한 경우, 스케줄 수행 날짜인 Date를 입력해야합니다. 아래 내용을 참고하여 스케줄을 등록하세요.
- 0보다 큰 숫자를 입력하면 매달 날짜를 의미합니다.
- 예시: 1을 입력하면, 8월 1일, 9월 1일, …, 12월 1일
- 0보다 작은 숫자를 입력하면 매달 말일로부터 계산합니다.
- -1을 입력하면 매달 말일을 의미합니다.
- 예시: 8월 31일, 9월 30일, …, 12월 31일
- -2를 입력하면 매달 말일 전날을 의미합니다.
- 예시: 8월 30일, 9월 29일, …, 12월 30일
- 매달 말일은 31일, 30일, 29일, 28일과 같이 매달 다르기 때문에 매달 말일에 스케줄이 수행되어야 하는 경우를 위해, 위와 같이 0보다 작은 숫자를 이용하여 말일로부터 계산할 수 있도록 하였습니다.
- -1을 입력하면 매달 말일을 의미합니다.
안내
- 스케줄이 수행될 때 스케줄에 설정한 Min 서버 수가 Desired 서버 수보다 크거나, Max 서버 수가 Desired 서버 수보다 작은 경우, Desired 서버 수도 함께 수정됩니다.
- 수행 시간이 중복된 스케줄이 있는 경우, 정상 수행되지 않을 수 있습니다. 가급적 수행 시간이 중복되지 않도록 해주세요.
스케줄 수정하기
Auto-Scaling Group의 스케줄을 수정할 수 있습니다. Auto-Scaling Group의 스케줄을 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 스케줄 탭을 클릭하세요. 스케줄 탭 페이지로 이동합니다.
- 수정할 스케줄의 더보기 > 수정 버튼을 클릭하세요. 스케줄 수정 팝업창이 열립니다.
구분 필수상세 설명 스케줄명 필수 스케줄 별 구분할 이름 서버 수 선택 필수 스케줄 수행 시, 조정할 서버 수를 선택 - Min: Auto-Scailg Group이 최소한으로 유지할 서버 수
- Desired: Auto-Scailg Group 내 목표 서버 수
- Max: Auto-Scailg Group이 최대로 유지할 수 있는 서버 수
서버 수 입력 필수 선택한 서버 수의 값을 입력 - Min 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
- Desired 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
- Max 값: 0~50 사이의 값을 입력하세요. (Min≤Desired≤Max)
주기 필수 스케줄 수행 주기 - 매일: 매일 스케줄이 수행될 시작일과 종료일, 영구 설정을 할 수 있습니다. 또한 시간과 시간대를 설정
- 매주: 시작일과 종료일, 영구 설정 및 시간과 시간대를 설정을 할 수 있습니다. 또한 매주 스케줄이 수행될 요일을 선택할 수 있습니다.
- 매달: 시작일과 종료일, 영구 설정 및 시간과 시간대를 설정을 할 수 있습니다. 또한 매달 스케줄이 수행될 Date를 입력 가능
- 한 번: 시간과 시간대를 설정을 할 수 있습니다. 또한 한 번 스케줄이 수행될 Date를 설정
시작일 선택 스케줄 시작 날짜 설정 - 현재 날짜 이전으로 설정할 수 없습니다. 기본값은 현재 날짜입니다.
종료일 선택 스케줄 종료 날짜 설정 - 현재 날짜 이전으로 설정할 수 없습니다. 기본값은 현재 날짜 + 7입니다.
영구 선택 영구 설정 시, 스케줄 종료일을 9999-12-31로 설정 시간 필수 스케줄 수행 시간 설정 - 30분 단위로 설정 가능합니다. 현재 날짜, 현재 시간보다 빠른 시간은 설정 불가
시간대 필수 스케줄 수행 시간에 해당하는 시간대 (예시: Asia/Seoul (GMT +09:00)) 요일 필수 주기를 매주 선택한 경우, 스케줄 수행할 요일을 선택 Date 필수 - 주기를 매달 선택한 경우, 스케줄 수행할 날짜인 Date를 입력
- 0을 제외한 -31~31까지 한 개이상 입력하세요. (예시: 3,4,5)
- 주기를 한 번 선택한 경우, 스케줄 수행할 날짜인 Date를 설정
- 현재 날짜 이전으로 설정 불가합니다. 기본값은 현재 날짜입니다.
표. 스케줄 수정 팝업 항목 - 스케줄 수정 팝업창에서 필수값을 입력한 후, 확인 버튼을 클릭하세요.
- 스케줄 수정 확인 팝업창의 메시지 확인 후, 확인 버튼을 클릭하세요.
스케줄 삭제하기
Auto-Scaling Group의 스케줄을 삭제할 수 있습니다. Auto-Scaling Group의 스케줄을 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 스케줄 탭을 클릭하세요. 스케줄 탭 페이지로 이동합니다.
- 삭제할 스케줄을 선택하고 삭제 버튼을 클릭하세요. 스케줄 삭제 확인 팝업창이 열립니다.
- 스케줄 삭제 확인 팝업창을 확인하고 확인 버튼을 클릭하세요.
2.2.4 - 알림 관리하기
알림 수신인을 지정하여 E-mail 또는 SMS로 특정 상황에 대한 알림 메시지를 발송할 수 있습니다.
참고
- 알림 방식(E-mail 또는 SMS)은 알림 설정 페이지에서 알림 대상을 서비스 > Virtual Server Auto-Scaling로 선택하여 설정할 수 있습니다.
- 알림 설정 수정에 대한 자세한 내용은 알림 설정 수정하기를 참고하세요.
알림 추가하기
Auto-Scaling Group의 알림을 추가할 수 있습니다. Auto-Scaling Group의 알림을 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 알림 정보를 추가할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 알림 탭을 클릭하세요. 알림 탭 페이지로 이동합니다.
- 알림 추가 버튼을 클릭하세요. 알림 추가 팝업창이 열립니다.
- 알림 추가 팝업창에서 필수값을 입력한 후, 확인 버튼을 클릭하세요.
구분 상세 설명 통보시점 Auto-Scaling Group 알림 발생 시 통보 시점 - 서버 생성, 서버 해지, 서버 생성 실패, 서버 해지 실패, 정책 실행 조건 만족 시
- 다중 선택 가능
알림 수신인 알림 발생 시 알림을 수신할 사용자 - 알림 수신자 추가 버튼을 클릭하여 사용자 선택 가능
- Samsung Cloud Platform 사용자만 수신인으로 선택 가능
표. 알림 항목
주의
알림 수신인 추가 시 이메일 주소가 있는지 확인하고 추가하세요. 로그인 이력이 있는 사용자(이메일, 휴대전화 번호 등록 사용자)만 알림을 받을 수 있습니다.
- 알림 추가 확인 팝업창의 메시지 확인 후, 확인 버튼을 클릭하세요.
알림 수정하기
Auto-Scaling Group의 알림 정보를 수정할 수 있습니다. Auto-Scaling Group의 알림 정보를 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 알림 정보를 수정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 알림 탭을 클릭하세요. 알림 탭 페이지로 이동합니다.
- 알림 목록에서 수정할 알림 정보의 더보기 > 수정 버튼을 클릭하세요. 알림 수정 팝업창이 열립니다.
- 알림 수정 팝업창에서 알림 정보를 수정한 후, 확인 버튼을 클릭하세요.
구분 상세 설명 통보시점 Auto-Scaling Group 알림 발생 시 통보 시점 - 서버 생성, 서버 해지, 서버 생성 실패, 서버 해지 실패, 정책 실행 조건 만족 시
- 다중 선택 가능
표. 알림 수정 항목 - 알림 수정 확인 팝업창의 메시지 확인 후, 확인 버튼을 클릭하세요.
알림 삭제하기
Auto-Scaling Group의 알림을 삭제할 수 있습니다. Auto-Scaling Group의 알림을 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Auto-Scaling Group 메뉴를 클릭하세요. Auto-Scaling Group 목록 페이지로 이동합니다.
- Auto-Scaling Group 목록 페이지에서 알림 정보를 수정할 자원을 클릭하세요. Auto-Scaling Group 상세 페이지로 이동합니다.
- 알림 탭을 클릭하세요. 알림 탭 페이지로 이동합니다.
- 알림 목록에서 삭제할 알림을 선택한 후, 삭제 버튼을 클릭하세요. 알림 삭제 확인 팝업창이 열립니다.
- 알림 삭제 확인 팝업창을 확인하고 확인 버튼을 클릭하세요.
2.3 - API Reference
API Reference
2.4 - CLI Reference
CLI Reference
2.5 - Release Note
Virtual Server Auto-Scaling
2025.10.23
FEATURE
Virtual Server 해지 기능 개선- Auto-Scaling Group에서 만든 Virtual Server의 해지 기능이 개선되었습니다.
- Virtual Server 해지 시 Load Balancer를 자동으로 분리됩니다.
- Desired 서버 수는 그대로 유지되며 Desired 체크 배치에 따라 scale-out을 진행합니다.
2025.07.01
FEATURE
신규 기능 추가- Virtual Server Auto-Scaling에 알림 기능을 추가하였습니다.
- Auto-Scaling Group 생성 또는 상세 화면에서 알림 설정을 추가할 수 있습니다.
- Auto-Scaling Group 생성 시 Scaling 정책을 설정할 수 있습니다.
- Auto-Scaling Group 정책의 Metric Type을 추가하였습니다.
- 추가 : Memory Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- Load Balancer 연결 시 Draining Timeout을 설정할 수 있습니다.
- Auto-Scaling Group에 Virtual Server는 최대 50개, LB 서버 그룹 및 포트는 최대 3개까지 연결할 수 있습니다.
2025.02.27
FEATURE
Virtual Server Auto Scaling-Load Balancer 서비스 연계 출시 및 NAT 설정 기능 추가- Virtual Server Auto-Scaling 기능 변경
- 2025년 2월에 출시하는 Load Balancer 서비스와 연계 출시합니다.
- Auto-Scaling Group에서 NAT 설정 기능이 추가되었습니다.
- Samsung Cloud Platform 공통 기능 변경
- Account, IAM 및 Service Home, 태그 등 공통 CX 변경 사항을 반영하였습니다.
2024.11.19
NEW
Virtual Server Auto Scaling 서비스 정식 버전 출시- Virtual Server Auto-Scaling은 Launch Configuration을 통해 Auto-Scaling Group을 생성하고 서버를 확인하고 관리합니다.
- 정해진 시간에 원하는 서버 수를 설정할 수 있는 스케줄 방식과 CPU 사용률 기반으로 서버 수를 조정하는 방법의 정책 방식을 제공합니다.
3 - GPU Server
3.1 - Overview
서비스 개요
GPU Server는 CPU, GPU, 메모리 등 서버에서 제공하는 인프라 자원을 개별 구매할 필요 없이, 필요한 시점에 필요한 만큼 자유롭게 할당 받아 사용할 수 있는 가상화 컴퓨팅 서비스 입니다. 클라우드 환경에서 AI모델 실험, 예측, 추론 등 빠른 연산 속도를 필요로 하는 업무에 적합하며, 업무 유형 및 규모에 따라 최적화 된 성능의 자원을 유연하게 선택하여 이용할 수 있습니다. GPU Server는 다음과 같은 기능을 제공하고 있습니다.
제공 기능
- GPU Server 관리: 웹 기반 Console을 통해 GPU Server 프로비저닝부터 모니터링, 빌링까지 사용자가 직접 Self Service로 생성, 삭제 및 변경을 관리할 수 있습니다.
- GPU 수량별 상품 제공: 프로젝트 용도 및 규모 등에 따라 H100/A100 GPU의 수량을 자유롭게 선택하여 가상 서버를 구성할 수 있습니다.
- 고성능 GPU 제공: Pass-through 방식을 사용하여 물리서버 수준의 고성능 GPU 서버를 제공합니다.
- 스토리지 연결: OS 디스크 외 추가 연결 스토리지를 제공 합니다. Block Storage, File Storage, Object Storage 를 연결하여 사용할 수 있습니다.
- 강력한 보안적용: Security Group 서비스를 통해 외부 인터넷이나 다른 VPC(Virtual Private Cloud)와 주고받는 Inbound/Outbound 트래픽을 제어하여 서버를 안전하게 보호합니다.
- 모니터링: 컴퓨텅 자원에 해당하는 CPU, Memory, Disk 및 GPU의 현황 등의 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
- 네트워크 설정 관리: 서버의 서브넷/IP는 최초 생성시 설정된 값을 간편하게 변경 가능합니다. NAT IP는 필요에 따라 사용/해지를 설정할 수 있는 관리기능을 제공하고 있습니다.
- Key Pair 방식: 안전한 OS접속 방식을 위해 ID/PW의 접속이 아니라 Key Pair 방식을 제공합니다.
- Image 관리: Custom Image를 생성 및 관리할 수 있고, 프로젝트간 공유 기능을 제공합니다.
- ServiceWatch 서비스 연계 제공: ServiceWatch 서비스를 통해 데이터를 모니터링할 수 있습니다.
구성 요소
GPU Server는 가상화 컴퓨팅 자원 위에 GPU와 NVSwitch 및 NVLink가 제공됩니다.
주의
- NVSwitch는 단일 GPU Server에 8개의 GPU를 할당한 인스턴스 타입의 경우에만 활성화하여 사용 가능합니다.
GPU(A100/H100)
GPU(Graphic Processing Unit)는 컴퓨터 화면을 구성 이미지를 만들기 위해 필요한 계산을 수행하는 역할로 병렬 처리에 특화되어있어 많은 양의 데이터를 빠르게 처리할 수 있어 인공지능(AI), 데이터 분석 등 대규모 병렬 연산을 처리합니다. 다음은 GPU Server 서비스에서 제공하는 GPU Type의 사양입니다.
| 구분 | A100 Type | H100 Type |
|---|---|---|
| 서비스 제공 방식 | Pass-through | Pass-through |
| GPU Architecture | NVIDIA Ampere | NVIDIA Hopper |
| GPU Memory | 80GB | 80GB |
| GPU Transistors | 54 billion 7N TSMC | 80 billion 4N TSMC |
| GPU Tensor Performance (FP16 기준, *: With Sparsity) | 312 TFLOPs, 624* TFLOPs | 989.4 TFLOPs, 1,978.9* TFLOPs |
| GPU Memory Bandwidth | 2,039 GB/sec HBM2e | 3,352 GB/sec HBM3 |
| GPU CUDA Cores | 6,912 Cores | 16,896 Cores |
| GPU Tensor Cores | 432 (3rd Generation) | 528 (4th Generation) |
| NVLink 성능 | NVLink 3 | NVLink 4 |
| 총 NVLink 대역폭 | 600 GB/s | 900 GB/s |
| NVLink Signaling Rate (단방향) | 25 GB/s (x12) | 25 GB/s (x18) |
| NVSwitch 성능 | NVSwitch 2 | NVSwitch 3 |
| NVSwitch GPU간 대역폭 | 600 GB/s | 900 GB/s |
| 총 NVSwitch 집계 대역폭 | 4.8 TB/s | 7.2 TB/s |
| 연계 스토리지 | Block Storage - SSD | Block Storage - SSD |
표. GPU Type 사양
서버 타입
GPU Server에서 제공하는 서버 타입은 다음과 같습니다. GPU Server에서 제공하는 서버 타입에 대한 자세한 설명은 GPU Server 서버 타입을 참고하세요.
| 구분 | 서버 타입 | CPU vCore | Memory(GB) | GPU수량 |
|---|---|---|---|---|
| GPU-A100-1 | g1v16a1 | 16 | 234 | 1 |
| GPU-A100-1 | g1v32a2 | 32 | 468 | 2 |
| GPU-A100-1 | g1v64a4 | 64 | 936 | 4 |
| GPU-A100-1 | g1v128a8 | 128 | 1872 | 8 |
| GPU-H100-2 | g2v12h1 | 12 | 234 | 1 |
| GPU-H100-2 | g2v24h2 | 24 | 468 | 2 |
| GPU-H100-2 | g2v48h4 | 48 | 936 | 4 |
| GPU-H100-2 | g2v96h8 | 96 | 1872 | 8 |
표. GPU Server 서버 타입
OS 및 GPU 드라이버 버전
GPU Server에서 지원하는 운영체제(OS)는 다음과 같습니다.
| OS | OS 버전 | GPU 드라이버버전 |
|---|---|---|
| Ubuntu | 22.04 | 535.183.06 |
| RHEL | 8.10 | +ND 535.183.06 |
표. GPU Server OS 및 GPU 드라이버 버전
선행 서비스
본 서비스를 생성하기 전에 미리 설치가 되어야 하는 서비스입니다. 사전에 안내된 사용자 가이드를 참고하여 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
표. GPU Server 선행 서비스
3.1.1 - 서버 타입
GPU Server 서버 타입
GPU Server는 제공하는 GPU Type에 따라 구분되며, GPU Server를 생성할 때 선택하는 서버 타입에 따라 GPU Server에 사용되는 GPU가 결정됩니다. GPU Server에서 실행하려는 애플리케이션의 사양에 따라 서버 타입을 선택해주세요.
GPU Server에서 지원하는 서버 타입은 다음 형식과 같습니다.
GPU-H100-2 g2v12h1
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | GPU-H100-2 | 제공되는 서버 타입 구분
|
| 서버 사양 | g2 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v12 | vCore 개수
|
| 서버 사양 | h1 | GPU 종류와 수량
|
표. GPU Server 서버 타입 형식
g1 서버 타입
g1 서버 타입은 NVIDIA A100 Tensor Core GPU를 사용하는 GPU Server로 고성능 애플리케이션에 적합합니다.
- 최대 8개의 NVIDIA A100 Tensor Core GPU 제공
- GPU 당 6,912개의 CUDA 코어와 432 Tensor 코어 탑재
- 최대 128개의 vCPU 및 1,920 GB의 메모리를 지원
- 최대 40 Gbps의 네트워킹 속도
- 600GB/s GPU와 NVIDIA NVSwitch P2P 통신
| 구분 | 서버 타입 | GPU | CPU | Memory | GPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| GPU-A100-1 | g1v16a1 | 1 | 16 vCore | 234 GB | 80 GB | 최대 20 Gbps |
| GPU-A100-1 | g1v32a2 | 2 | 32 vCore | 468 GB | 160 GB | 최대 20 Gbps |
| GPU-A100-1 | g1v64a4 | 4 | 64 vCore | 936 GB | 320 GB | 최대 40 Gbps |
| GPU-A100-1 | g1v128a8 | 8 | 128 vCore | 1872 GB | 640 GB | 최대 40 Gbps |
표. GPU Server 서버 타입 > GPU-A100-1 서버 타입
g2 서버 타입
g2 서버 타입은 NVIDIA H100 Tensor Core GPU를 사용하는 GPU Server로 고성능 애플리케이션에 적합합니다.
- 최대 8개의 NVIDIA H100 Tensor Core GPU 제공
- GPU 당 16,896개의 CUDA 코어와 528 Tensor 코어 탑재
- 최대 96개의 vCPU 및 1,920 GB의 메모리를 지원
- 최대 40Gbps의 네트워킹 속도
- 900GB/s GPU와 NVIDIA NVSwitch P2P 통신
| 구분 | 서버 타입 | GPU | CPU | Memory | GPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| GPU-H100-2 | g2v12h1 | 1 | 12 vCore | 234 GB | 80 GB | 최대 20 Gbps |
| GPU-H100-2 | g2v24h2 | 2 | 24 vCore | 468 GB | 160 GB | 최대 20 Gbps |
| GPU-H100-2 | g2v48h4 | 4 | 48 vCore | 936 GB | 320 GB | 최대 40 Gbps |
| GPU-H100-2 | g2v96h8 | 8 | 96 vCore | 1872 GB | 640 GB | 최대 40 Gbps |
표. GPU Server 서버 타입 > GPU-H100-2 서버 타입
3.1.2 - 모니터링 지표
GPU Server 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 GPU Server의 모니터링 지표를 나타냅니다.
Agent를 설치하지 않아도 기본적인 모니터링 지표를 제공하며 아래 표. GPU Server 모니터링 지표(기본 제공) 에서 확인해주세요. 추가로 Agent 설치를 통해 조회 가능한 지표는 아래 표. GPU Server 추가 모니터링 지표 (Agent 설치 필요) 에서 참고하세요.
자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
| 성능 항목명 | 설명 | 단위 |
|---|---|---|
| Memory Total [Basic] | 사용할 수 있는 메모리의 bytes | bytes |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Memory Swap In [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Swap Out [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Free [Basic] | 사용하지 않은 메모리의 bytes | bytes |
| Disk Read Bytes [Basic] | 읽기 bytes | bytes |
| Disk Read Requests [Basic] | 읽기 요청 수 | cnt |
| Disk Write Bytes [Basic] | 쓰기bytes | bytes |
| Disk Write Requests [Basic] | 쓰기 요청 수 | cnt |
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Instance State [Basic] | Instance 상태 | state |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Dropped [Basic] | 수신 패킷 드롭 | cnt |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Dropped [Basic] | 송신 패킷 드롭 | cnt |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. GPU Server 기본 모니터링 지표 (기본 제공)
| 성능항목명 | 설명 | 단위 |
|---|---|---|
| GPU Count | gpu 개수 | cnt |
| GPU Memory Usage | 메모리 사용율 | % |
| GPU Memory Used | 메모리 사용량 | MB |
| GPU Temperature | gpu 온도 | ℃ |
| GPU Usage | utilization | % |
| GPU Usage [Avg] | GPU 전체 평균 사용율(%) | % |
| GPU Power Cap | GPU의 최대 전력 용량 | W |
| GPU Power Usage | GPU의 현재 전력 사용량 | W |
| GPU Memory Usage [Avg] | GPU Memory Uti. AVG | % |
| GPU Count in use | Node 내 Job이 수행중인 GPU 수 | cnt |
| Execution Status for nvidia-smi | nvidia-smi 명령어 실행결과 | status |
| Core Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| Core Usage [System] | 커널 공간에서 소요된 CPU 시간의 비율 | % |
| Core Usage [User] | 사용자 공간에서 소요된 CPU 시간의 비율 | % |
| CPU Cores | 호스트에 있는 CPU 코어의 수 | cnt |
| CPU Usage [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage [User] | 사용자 영역에서 사용한 CPU 시간의 백분율. | % |
| CPU Usage/Core [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage/Core [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage/Core [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage/Core [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage/Core [User] | 사용자 영역에서 사용한 CPU 시간의 백분율. | % |
| Disk CPU Usage [IO Request] | 장치에 대한 입출력 요청이 실행된 CPU 시간의 비율 | % |
| Disk Queue Size [Avg] | 장치에 대해 실행된 요청의 평균 대기열 길이입니다. | num |
| Disk Read Bytes | 장치에서 읽는 초당 바이트 수입니다. | bytes |
| Disk Read Bytes [Delta Avg] | 개별 disk들의 system.diskio.read.bytes_delta의 평균 | bytes |
| Disk Read Bytes [Delta Max] | 개별 disk들의 system.diskio.read.bytes_delta의 최대 | bytes |
| Disk Read Bytes [Delta Min] | 개별 disk들의 system.diskio.read.bytes_delta의 최소 | bytes |
| Disk Read Bytes [Delta Sum] | 개별 disk들의 system.diskio.read.bytes_delta의 합 | bytes |
| Disk Read Bytes [Delta] | 개별 disk의 system.diskio.read.bytes 값의 delta | bytes |
| Disk Read Bytes [Success] | 성공적으로 읽은 총 바이트 수. | bytes |
| Disk Read Requests | 1초동안 디스크 디바이스의 읽기 요청 수 | cnt |
| Disk Read Requests [Delta Avg] | 개별 disk들의 system.diskio.read.count_delta의 평균 | cnt |
| Disk Read Requests [Delta Max] | 개별 disk들의 system.diskio.read.count_delta의 최대 | cnt |
| Disk Read Requests [Delta Min] | 개별 disk들의 system.diskio.read.count_delta의 최소 | cnt |
| Disk Read Requests [Delta Sum] | 개별 disk들의 system.diskio.read.count_delta의 합 | cnt |
| Disk Read Requests [Success Delta] | 개별 disk의 system.diskio.read.count 의 delta | cnt |
| Disk Read Requests [Success] | 성공적으로 완료된 총 읽기 수 | cnt |
| Disk Request Size [Avg] | 장치에 대해 실행된 요청의 평균 크기(단위: 섹터)입니다. | num |
| Disk Service Time [Avg] | 장치에 대해 실행된 입력 요청의 평균 서비스 시간(밀리초)입니다. | ms |
| Disk Wait Time [Avg] | 지원할 장치에 대해 실행된 요청에 소요된 평균 시간입니다. | ms |
| Disk Wait Time [Read] | 디스크 평균 대기 시간 | ms |
| Disk Wait Time [Write] | 디스크 평균 대기 시간 | ms |
| Disk Write Bytes [Delta Avg] | 개별 disk들의 system.diskio.write.bytes_delta의 평균 | bytes |
| Disk Write Bytes [Delta Max] | 개별 disk들의 system.diskio.write.bytes_delta의 최대 | bytes |
| Disk Write Bytes [Delta Min] | 개별 disk들의 system.diskio.write.bytes_delta의 최소 | bytes |
| Disk Write Bytes [Delta Sum] | 개별 disk들의 system.diskio.write.bytes_delta의 합 | bytes |
| Disk Write Bytes [Delta] | 개별 disk의 system.diskio.write.bytes 값의 delta | bytes |
| Disk Write Bytes [Success] | 성공적으로 쓰여진 총 바이트 수. | bytes |
| Disk Write Requests | 1초동안 디스크 디바이스의 쓰기 요청 수 | cnt |
| Disk Write Requests [Delta Avg] | 개별 disk들의 system.diskio.write.count_delta의 평균 | cnt |
| Disk Write Requests [Delta Max] | 개별 disk들의 system.diskio.write.count_delta의 최대 | cnt |
| Disk Write Requests [Delta Min] | 개별 disk들의 system.diskio.write.count_delta의 최소 | cnt |
| Disk Write Requests [Delta Sum] | 개별 disk들의 system.diskio.write.count_delta의 합 | cnt |
| Disk Write Requests [Success Delta] | 개별 disk의 system.diskio.write.count 의 delta | cnt |
| Disk Write Requests [Success] | 성공적으로 완료된 총 쓰기 수 | cnt |
| Disk Writes Bytes | 장치에 쓰는 초당 바이트 수입니다. | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang 체크 (정상:1, 비정상:0) | status |
| Filesystem Nodes | 파일 시스템의 총 파일 노드 수입니다. | cnt |
| Filesystem Nodes [Free] | 파일 시스템의 총 가용 파일 노드 수입니다. | cnt |
| Filesystem Size [Available] | 권한 없는 사용자가 사용할 수 있는 디스크 공간(바이트) | bytes |
| Filesystem Size [Free] | 사용 가능한 디스크 공간 (bytes) | bytes |
| Filesystem Size [Total] | 총 디스크 공간 (bytes) | bytes |
| Filesystem Usage | 사용한 디스크 공간 백분율 | % |
| Filesystem Usage [Avg] | 개별 filesystem.used.pct들의 평균 | % |
| Filesystem Usage [Inode] | inode 사용률 | % |
| Filesystem Usage [Max] | 개별 filesystem.used.pct 중에 max | % |
| Filesystem Usage [Min] | 개별 filesystem.used.pct 중에 min | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | 사용한 디스크 공간 (bytes) | bytes |
| Filesystem Used [Inode] | inode 사용량 | bytes |
| Memory Free | 사용 가능한 총 메모리 양 (bytes). | bytes |
| Memory Free [Actual] | 실제 사용가능한 memory (bytes). | bytes |
| Memory Free [Swap] | 사용가능한 swap memory. | bytes |
| Memory Total | 총 memory | bytes |
| Memory Total [Swap] | 총 swap memory. | bytes |
| Memory Usage | 사용한 memory의 백분율 | % |
| Memory Usage [Actual] | 실제 사용된 memory의 백분율 | % |
| Memory Usage [Cache Swap] | cache 된 swap 사용률 | % |
| Memory Usage [Swap] | 사용한 swap memory의 백분율 | % |
| Memory Used | 사용한 memory | bytes |
| Memory Used [Actual] | 실제 사용된 memory (bytes). | bytes |
| Memory Used [Swap] | 사용한 swap memory. | bytes |
| Collisions | 네트워크 충돌 | cnt |
| Network In Bytes | 수신된 byte 수 | bytes |
| Network In Bytes [Delta Avg] | 개별 network들의 system.network.in.bytes_delta의 평균 | bytes |
| Network In Bytes [Delta Max] | 개별 network들의 system.network.in.bytes_delta의 최대 | bytes |
| Network In Bytes [Delta Min] | 개별 network들의 system.network.in.bytes_delta의 최소 | bytes |
| Network In Bytes [Delta Sum] | 개별 network 들의 system.network.in.bytes_delta의 합 | bytes |
| Network In Bytes [Delta] | 수신된 byte 수의 delta | bytes |
| Network In Dropped | 들어온 packet 중 삭제된 패킷의 수 | cnt |
| Network In Errors | 수신 중의 error 수 | cnt |
| Network In Packets | 수신된 packet 수 | cnt |
| Network In Packets [Delta Avg] | 개별 network들의 system.network.in.packets_delta의 평균 | cnt |
| Network In Packets [Delta Max] | 개별 network들의 system.network.in.packets_delta의 최대 | cnt |
| Network In Packets [Delta Min] | 개별 network들의 system.network.in.packets_delta의 최소 | cnt |
| Network In Packets [Delta Sum] | 개별 network들의 system.network.in.packets_delta의 합 | cnt |
| Network In Packets [Delta] | 수신된 packet 수의 delta | cnt |
| Network Out Bytes | 송신된 byte 수 | bytes |
| Network Out Bytes [Delta Avg] | 개별 network들의 system.network.out.bytes_delta의 평균 | bytes |
| Network Out Bytes [Delta Max] | 개별 network들의 system.network.out.bytes_delta의 최대 | bytes |
| Network Out Bytes [Delta Min] | 개별 network들의 system.network.out.bytes_delta의 최소 | bytes |
| Network Out Bytes [Delta Sum] | 개별 network들의 system.network.out.bytes_delta의 합 | bytes |
| Network Out Bytes [Delta] | 송신된 byte 수의 delta | bytes |
| Network Out Dropped | 나가는 packet 중 삭제된 packet 수. | cnt |
| Network Out Errors | 송신 중의 error 수 | cnt |
| Network Out Packets | 송신된 packet 수 | cnt |
| Network Out Packets [Delta Avg] | 개별 network들의 system.network.out.packets_delta의 평균 | cnt |
| Network Out Packets [Delta Max] | 개별 network들의 system.network.out.packets_delta의 최대 | cnt |
| Network Out Packets [Delta Min] | 개별 network들의 system.network.out.packets_delta의 최소 | cnt |
| Network Out Packets [Delta Sum] | 개별 network들의 system.network.out.packets_delta의 합 | cnt |
| Network Out Packets [Delta] | 송신된 packet 수의 delta | cnt |
| Open Connections [TCP] | 열려 있는 모든 TCP 연결 | cnt |
| Open Connections [UDP] | 열려 있는 모든 UDP 연결 | cnt |
| Port Usage | 접속가능한 port 사용률 | % |
| SYN Sent Sockets | SYN_SENT 상태의 소켓 수 (로컬에서 원격 접속시) | cnt |
| Kernel PID Max | kernel.pid_max 값 | cnt |
| Kernel Thread Max | kernel.threads-max 값 | cnt |
| Process CPU Usage | 마지막 업데이트 후 프로세스에서 소비한 CPU 시간의 백분율. | % |
| Process CPU Usage/Core | 마지막 이벤트 이후 프로세스에서 사용한 CPU 시간의 백분율. | % |
| Process Memory Usage | main memory (RAM) 에서 프로세스가 차지하는 비율 | % |
| Process Memory Used | Resident Set 사이즈. 프로세스가 RAM 에서 차지한 메모리 양. | bytes |
| Process PID | 프로세스 pid | PID |
| Process PPID | 부모 프로세스의 pid | PID |
| Processes [Dead] | dead processes 수 | cnt |
| Processes [Idle] | idle processes 수 | cnt |
| Processes [Running] | running processes 수 | cnt |
| Processes [Sleeping] | sleeping processes 수 | cnt |
| Processes [Stopped] | stopped processes 수 | cnt |
| Processes [Total] | 총 processes 수 | cnt |
| Processes [Unknown] | 상태를 검색할 수 없거나 알 수 없는 processes 수 | cnt |
| Processes [Zombie] | 좀비 processes 수 | cnt |
| Running Process Usage | process 사용률 | % |
| Running Processes | running processes 수 | cnt |
| Running Thread Usage | thread 사용률 | % |
| Running Threads | running processes 에서 실행중인 thread 수 총합 | cnt |
| Context Switches | context switch 수 (초당) | cnt |
| Load/Core [1 min] | 마지막 1 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [15 min] | 마지막 15 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [5 min] | 마지막 5 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Multipaths [Active] | 외장 스토리지 연결 path status = active 카운트 | cnt |
| Multipaths [Failed] | 외장 스토리지 연결 path status = failed 카운트 | cnt |
| Multipaths [Faulty] | 외장 스토리지 연결 path status = faulty 카운트 | cnt |
| NTP Offset | last sample의 measured offset (NTP 서버와 로컬환경 간의 시간 차이) | num |
| Run Queue Length | 실행 대기열 길이 | num |
| Uptime | OS 가동시간(uptime). (milliseconds) | ms |
| Context Switchies | CPU context switch 수 (초당) | cnt |
| Disk Read Bytes [Sec] | windows logical 디스크에서 1초동안 읽어들인 바이트 수 | cnt |
| Disk Read Time [Avg] | 데이터 읽기 평균 시간 (초) | sec |
| Disk Transfer Time [Avg] | 디스크 average wait time | sec |
| Disk Usage | 디스크 사용률 | % |
| Disk Write Bytes [Sec] | windows logical 디스크에서 1초동안 쓰여진 바이트 수 | cnt |
| Disk Write Time [Avg] | 데이터 쓰기 평균 시간 (초) | sec |
| Pagingfile Usage | paging file 사용률 | % |
| Pool Used [Non Paged] | 커널 메모리 중 Nonpaged Pool 사용량 | bytes |
| Pool Used [Paged] | 커널 메모리 중 Paged Pool 사용량 | bytes |
| Process [Running] | 현재 동작 중인 프로세스 수 | cnt |
| Threads [Running] | 현재 동작 중인 thread 수 | cnt |
| Threads [Waiting] | 프로세서 시간을 기다리는 thread 수 | cnt |
표. GPU Server 추가 모니터링 지표 (Agent 설치 필요)
3.1.3 - ServiceWatch 지표
GPU Server는 ServiceWatch로 지표를 전송합니다. 기본 모니터링으로 제공되는 지표는 5분 주기로 수집된 데이터입니다. 세부 모니터링을 활성화하면, 1분 주기로 수집된 데이터를 확인할 수 있습니다.
안내
- GPU Server의 기본 모니터링과 세부 모니터링은 Virtual Server와 동일한 지표로 제공되며, 네임스페이스도 Virtual Server로 제공됩니다.
- GPU 관련 지표는 ServiceWatch Agent를 통해 제공되며, ServiceWatch Agent를 사용하여 지표를 수집하는 방법은 ServiceWatch Agent 가이드를 참고하세요.
참고
ServiceWatch에서 지표를 확인하는 방법은 ServiceWatch 가이드를 참고하세요.
GPU Server의 세부 모니터링 활성화하는 방법은 How-to guides > ServiceWatch 세부 모니터링 활성화하기를 참고하세요.
기본 지표
다음은 네임스페이스 Virtual Server에 대한 기본 지표입니다.
| 성능 항목 | 상세 설명 | 단위 | 의미있는 통계 |
|---|---|---|---|
| Instance State | 인스턴스 상태 표시 | - | - |
| CPU Usage | CPU 사용률 | % |
|
| Disk Read Bytes | 블록 장치에서 읽은 용량(바이트) | Bytes |
|
| Disk Read Requests | 블록 장치에서의 읽기 요청 수 | Count |
|
| Disk Write Bytes | 블록 장치에서 쓰기 용량(바이트) | Bytes |
|
| Disk Write Requests | 블록 장치에서의 쓰기 요청 수 | Count |
|
| Network In Bytes | 네트워크 인터페이스에서 수신된 용량(바이트) | Bytes |
|
| Network In Dropped | 네트워크 인터페이스에서 수신된 패킷 드롭 수 | Count |
|
| Network In Packets | 네트워크 인터페이스에서 수신된 패킷 수 | Count |
|
| Network Out Bytes | 네트워크 인터페이스에서 전송된 용량(바이트) | Bytes |
|
| Network Out Dropped | 네트워크 인터페이스에서 전송된 패킷 드롭 수 | Count |
|
| Network Out Packets | 네트워크 인터페이스에서 전송된 패킷 수 | Count |
|
표. Virtual Server 기본 지표
3.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 GPU Server의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
GPU Server 생성하기
Samsung Cloud Platform Console에서 GPU Server 서비스를 생성하여 사용할 수 있습니다.
GPU Server 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 생성 버튼을 클릭하세요. GPU Server 생성 페이지로 이동합니다.
- GPU Server 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 필수 제공하는 이미지 종류 선택 - RHEL, Ubuntu
이미지 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
- 제공 서버 이미지에 대한 자세한 정보는 OS 및 GPU 드라이버 버전 참고
표. GPU Server 이미지 및 버전 선택 입력 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버 수 필수 동시 생성할 GPU Server 서버 수 - 숫자만 입력 가능하며 1~100 사이의 값을 입력
서비스 유형 > 서버 타입 필수 GPU Server 서버 타입 - GPU 타입의 서버 사양을 나타내며 GPU 1장, 2장, 4장, 8장을 포함한 서버를 선택
- GPU Server에서 제공하는 서버 타입에 대한 자세한 내용은 GPU Server 서버 타입을 참고
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기를 참고
Block Storage 필수 용도에 따라 GPU Server가 사용하는 Block Storage를 설정 - 기본: OS가 설치되어 사용되는 영역
- 용량은 Unit 단위로 입력 가능(OS 이미지의 종류에 따라 최소 용량이 다름)
- RHEL: 3 ~ 1,536 사이의 값 입력 가능
- Ubuntu: 3 ~ 1,536 사이의 값 입력 가능
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS (Key Management System) 암호화 키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 가능(생성 후, 변경 불가)
- SSD_KMS 디스크 유형 사용 시 성능 저하 발생
- 용량은 Unit 단위로 입력 가능(OS 이미지의 종류에 따라 최소 용량이 다름)
- 추가: OS 영역 외 사용자 추가 공간 필요 시 사용
- 사용을 선택한 후, Storage의 유형과 용량 입력
- Storage를 추가하려면 + 버튼을 클릭(최대 25개까지 추가 가능), 삭제하려면 x 버튼 클릭
- 용량은 Unit 단위로 1 ~ 1,536 사이의 값을 입력 가능
- 1 Unit이 8 GB이므로 8 ~ 12,288 GB가 생성
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD/HDD_KMS: Samsung Cloud Platform KMS (Key Management System) 암호화 키를 사용하는 추가 암호화 볼륨
- 암호화 적용은 최초 생성 시에만 가능(생성 후, 변경 불가)
- SSD_KMS 디스크 유형 사용 시 성능 저하가 발생할 있음
- Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고
- Delete on termination: Delete on Termination을 사용으로 선택한 경우, 서버를 해지할 때 해당 볼륨을 함께 해지
- 스냅샷이 존재하는 볼륨은 Delete on termination을 사용으로 선택한 경우에도 삭제되지 않음
- Multi attach 볼륨은 삭제하려는 서버가 볼륨에 연결된 마지막 남은 서버일 때만 삭제
표. GPU Server 서비스 구성 항목 - 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버명 필수 선택한 서버 수가 1인 경우에 서버 구별을 위한 이름 입력 - 입력한 서버 이름으로 hostname을 설정
- 영문,숫자,공백과 특수문자(
-_)를 사용하여 63자 이내로 입력
서버명 Prefix 필수 선택한 서버 수가 2이상인 경우에 생성되는 각각의 서버 구별을 위한 Prefix 입력 - 사용자 입력값(prefix) + ‘
-#’ 형태로 자동 생성
- 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 59자 이내로 입력
네트워크 설정 > 신규 네트워크 포트 생성 필수 GPU Server가 설치될 네트워크를 설정 - 미리 생성한 VPC를 선택합니다.
- 일반 Subnet: 미리 생성한 일반 Subnet을 선택
- IP는 자동 생성과 사용자 입력을 선택할 수 있으며, 입력을 선택하면 사용자가 IP를 직접 입력
- NAT: 서버 수가 1대이고 VPC에 Internet Gateway가 연결되어 있어야 사용 가능. 사용을 체크하면 NAT IP를 선택 가능
- NAT IP: NAT IP를 선택
- 선택할 NAT IP가 없는 경우, 신규 생성 버튼을 클릭하여 Public IP를 생성해야 함
- 새로고침 버튼을 클릭하여, 생성한 Public IP를 확인하고 선택
- Public IP를 생성하면 Public IP 요금 기준에 따라 요금이 부과
- 로컬 Subnet(선택): 로컬 Subnet 사용을 선택
- 서비스를 생성하는데 필수 요소는 아님
- 미리 생성한 로컬 Subnet을 선택해야 함
- IP는 자동 생성과 사용자 입력을 선택할 수 있으며, 입력을 선택하면 사용자가 IP를 직접 입력 가능
- Security Group: 서버에 접속하기 위해 필요한 설정
- 선택: 미리 생성한 Security Group을 선택
- 신규 생성: 적용할 Security Group이 없는 경우 Security Group 서비스에서 별도로 생성 가능
- 최대 5개까지 선택 가능
- Security Group을 설정하지 않으면 기본적으로 모든 접속을 차단함
- 필요한 접속을 허용하기 위해서 Security Group을 설정해야 함
네트워크 설정 > 기존 네트워크 포트 지정 필수 GPU Server가 설치될 네트워크를 설정 - 미리 생성한 VPC를 선택
- 일반 Subnet: 미리 생성한 일반 Subnet과 Port를 선택
- NAT: 서버 수가 1대이고 VPC에 Internet Gateway가 연결되어 있어야 사용 가능 사용을 체크하면 NAT IP를 선택할 수 있습니다.
- NAT IP: NAT IP를 선택
- 선택할 NAT IP가 없는 경우, 신규 생성 버튼을 클릭하여 Public IP를 생성
- 새로고침 버튼을 클릭하여, 생성한 Public IP를 확인하고 선택
- 로컬 Subnet(선택): 로컬 Subnet의 사용 을 선택
- 미리 생성한 로컬 Subnet과 Port를 선택
Keypair 필수 서버에 연결할 때 사용할 사용자 증명 방법 - 신규 생성: 새로운 Keypair가 필요한 경우 신규 생성
- 신규 Keypair 생성 방법은 Keypair 생성하기 를 참고
- OS별 기본 접속 계정 리스트
- RHEL: cloud-user
- Ubuntu: ubuntu
표. GPU Server 필수 정보 입력 항목 - 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Lock 선택 Lock 사용 여부 설정 - Lock을 사용하면 서버 해지, 시작, 중지 등의 동작을 실행할 수 없도록 하여 실수로 인한 오동작을 방지
Init script 선택 서버 시작 시, 실행하는 스크립트 - Init script는 이미지 종류에 따라 Windows의 경우 Batch script, Linux의 경우 Shell script 또는 cloud-init로 작성되어야 함.
- 최대 45,000 bytes까지 입력 가능
태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. GPU Server 추가 정보 입력 항목
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
- 요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, GPU Server 목록 페이지에서 생성한 자원을 확인하세요.
GPU Server 상세 정보 확인하기
GPU Server 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. GPU Server 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
GPU Server 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
- GPU Server 부가 기능에 대한 자세한 내용은 GPU Server 관리 부가 기능을 참고하세요.
구분 상세 설명 GPU Server 상태 사용자가 생성한 GPU Server의 상태 - Build: Build 명령이 전달된 상태
- Building: Build 진행중
- Networking: 서버 생성 진행중 프로세스
- Scheduling: 서버 생성 진행중 프로세스
- Block_Device_Mapping: 서버 생성시 Block Storage 연결 중
- Spawning: 서버 생성 프로세스가 진행 중인 상태
- Active: 사용 가능한 상태
- Powering_off: 중지 요청시 상태
- Deleting: 서버 삭제 진행 중
- Reboot_Started: Reboot 진행중 상태
- Error: 에러 상태
- Migrating: 다른 호스트로 서버 Migration 되는 상태
- Reboot: Reboot 명령이 전달된 상태
- Rebooting: 재시작 진행 중
- Rebuild: Rebuild 명령이 전달된 상태
- Rebuilding: Rebuild 요청 시 상태
- Rebuild_Spawning: Rebuild 프로세스가 진행중인 상태
- Resize: Resize 명령이 전달된 상태
- Resizing: Resize 진행 중
- Resize_Prep: 서버 타입 수정 요청 시 상태
- Resize_Migrating: 서버가 Resize 진행 동시에 다른 호스토로 이동 중인 상태
- Resize_Migrated: 서버가 Resize 진행 동시에 다른 호스트로 이동 완료된 상태
- Resize_Finish: Resize가 완료
- Revert_Resize: 어떤 이유로 서버의 Resize 또는 마이그레이션 실패. 대상 서버가 정리되고 원래 원본 서버가 다시 시작
- Shutoff: Powering off 완료 시 상태
- Verity_Resize: 서버 타입 수정 요청에 따라 Resize_Prep 진행 이후, 서버 타입 확정/서버 타입 원복 선택 가능 상태
- Resize_Reverting: 서버 타입 원복 요청 시 상태
- Resize_Confirming: 서버의 Resize 요청을 확인 중인 상태
서버 제어 서버 상태를 변경할 수 있는 버튼 - 시작: 중지된 서버를 시작
- 중지: 가동 중인 서버를 중지
- 재시작: 가동 중인 서버를 재시작
이미지 생성 현재 서버의 이미지로 사용자 Custom 이미지 생성 콘솔 로그 현재 서버의 콘솔 로그 조회 - 현재 서버에서 출력되는 콘솔 로그를 확인할 수 있음. 자세한 내용은 콘솔 로그 확인하기를 참고하세요.
Dump 생성 현재 서버의 Dump를 생성 - Dump 파일은 GPU Server 안에 생성됨
- 자세한 Dump 생성 방법은 Dump 생성하기를 참고
Rebuild 기존 서버의 모든 데이터와 설정이 삭제되고, 새로운 서버를 구성 - 자세한 내용은 Rebuild 수행하기를 참고하세요.
서비스 해지 서비스를 해지하는 버튼 표. GPU Server 상태 정보 및 부가 기능
안내
mig 기능을 사용하는 경우, GPU Server의 Rebooting 상태가 끝난 후, mig 설정을 다시 확인해야 합니다.
상세 정보
GPU Server 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 서버명 | 서버 이름 |
| 서버 타입 | vCPU, 메모리, GPU정보 표시
|
| 이미지명 | 서비스의 OS 이미지 및 버전 |
| Lock | Lock 사용/미사용 여부 표시
|
| Keypair명 | 사용자가 설정한 서버 인증 정보 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| LLM Endpoint | LLM 이용을 위한 URL
|
| ServiceWatch 세부 모니터링 | 활성화 시 ServiceWatch 서비스에서 데이터 모니터링 가능
|
| 네트워크 | GPU Server의 네트워크 정보
|
| 로컬 Subnet | GPU Server의 로컬 Subnet 정보
|
| Block Storage | 서버에 연결된 Block Storage의 정보
|
표. GPU Server 상세 정보 탭 항목
주의
ServiceWatch 세부 모니터링을 사용할 경우, 추가 요금이 부과됩니다.
태그
GPU Server 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. GPU Server 태그 탭 항목
작업 이력
GPU Server 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. 작업 이력 탭 상세 정보 항목
GPU Server 가동 제어하기
생성된 GPU Server 자원의 가동 제어가 필요한 경우, GPU Server 목록 또는 GPU Server 상세 페이지에서 작업을 수행할 수 있습니다. 가동 중인 서버의 시작, 중지, 재시작을 할 수 있습니다.
GPU Server 시작하기
중지(Shutoff)된 GPU Server를 시작할 수 있습니다. GPU Server를 시작하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 중지(Shutoff)된 서버 중 시작할 자원을 클릭하여, GPU Server 상세 페이지로 이동합니다.
- GPU Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 시작할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 시작 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- GPU Server 상세 페이지에서 상단의 시작 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- GPU Server 시작이 완료되면 서버 상태가 Shutoff에서 Active로 변경됩니다.
- GPU Server 상태에 대한 자세한 내용은 GPU Server 상세 정보 확인하기를 참고하세요.
GPU Server 중지하기
가동(Active)중인 GPU Server를 중지할 수 있습니다. GPU Server를 중지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 가동(Active) 중인 서버 중 중지할 자원을 클릭하여, GPU Server 상세 페이지로 이동합니다.
- GPU Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 중지할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 중지 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- GPU Server 상세 페이지에서 상단의 중지 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- GPU Server 중지가 완료되면 서버 상태가 Active에서 Shutoff로 변경됩니다.
- GPU Server 상태에 대한 자세한 내용은 GPU Server 상세 정보 확인하기를 참고하세요.
GPU Server 재시작하기
생성된 GPU Server를 재시작할 수 있습니다. GPU Server를 재시작하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 재시작할 자원을 클릭하여, GPU Server 상세 페이지로 이동합니다.
- GPU Server 목록 페이지에서 각 자원 별로 오른쪽 더보기 버튼을 통해 재시작할 수 있습니다.
- 여러 대 서버를 체크 박스 선택한 후, 상단의 재시작 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- GPU Server 상세 페이지에서 상단의 재시작 버튼을 클릭하여, 서버를 시작합니다. 상태 표시 항목에서 변경된 서버의 상태를 확인하세요.
- GPU Server 재시작 중에는 서버 상태가 Rebooting을 거쳐 최종 Active로 변경됩니다.
- GPU Server 상태에 대한 자세한 내용은 GPU Server 상세 정보 확인하기를 참고하세요.
GPU Server 자원 관리하기
생성된 GPU Server 자원의 서버 제어 및 관리 기능이 필요한 경우, GPU Server 자원목록 또는 GPU Server 상세 페이지에서 작업을 수행할 수 있습니다.
Image 생성하기
가동 중인 GPU Server의 Image를 생성할 수 있습니다.
참고
해당 내용은 가동 중인 GPU Server의 Image로 사용자 Custom Image를 생성하는 방법을 안내하고 있습니다.
- GPU Server 목록 또는 GPU Server 상세 페이지에서 이미지 생성 버튼을 클릭하여 사용자 Custom Image를 생성합니다.
GPU Server의 Image를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
GPU Server 목록 페이지에서 Image 생성할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
GPU Server 상세 페이지에서 이미지 생성 버튼을 클릭하세요. Image 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
구분 필수 여부상세 설명 이미지명 필수 생성할 이미지의 이름 - 영문, 숫자, 공백과 특수문자(
-_)를 사용하여 200자 이내로 입력
표. Image 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
입력 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, 모든 서비스 > Compute > GPU Server > Image 목록 페이지에서 생성한 자원을 확인하세요.
안내
- Image를 생성하면 생성된 Image를 내부 저장소로 사용되는 Object Storage에 저장하게됩니다. 따라서 Image 저장에 대한 Object Storage 사용 요금이 부과 됩니다.
- Active 상태인 GPU Server로부터 생성된 이미지의 파일 시스템은 무결성을 보장할 수 없으므로 서버 정지 후 이미지 생성을 권장합니다.
ServiceWatch 세부 모니터링 활성화하기
기본적으로 GPU Server는 ServiceWatch와 Virtual Server 네임스페이스의 기본 모니터링으로 연계되어 있습니다. 필요에 따라 세부 모니터링을 활성화하여 운영 문제를 보다 신속하게 식별하고 조치를 취할 수 있습니다. ServiceWatch에 대한 자세한 내용은 ServiceWatch 개요를 참조하세요.
참고
GPU Server는 Virtual Server와 동일한 네임스페이스의 기본 모니터링과 세부 모니터링을 제공됩니다.
GPU Server의 GPU 지표는 ServiceWatch Agent로 제공될 예정입니다. (25년 12월 예정)
주의
기본 모니터링은 무료로 제공되지만, 세부 모니터링을 활성화하면 추가 요금이 부과됩니다. 이용에 유의하세요.
GPU Server의 ServiceWatch 세부 모니터링 활성화하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 ServiceWatch 세부 모니터링 활성화할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 ServiceWatch 세부 모니터링 수정 버튼을 클릭하세요. ServiceWatch 세부 모니터링 수정 팝업창으로 이동합니다.
- ServiceWatch 세부 모니터링 수정 팝업창에서 활성화 선택한 후, 안내 문구를 확인하고 확인 버튼을 클릭하세요.
- GPU Server 상세 페이지에서 ServiceWatch 세부 모니터링 항목을 확인하세요.
ServiceWatch 세부 모니터링 비활성화 하기
주의
비용 효율화를 위해 세부 모니터링 비활성화가 필요합니다. 반드시 필요한 경우에만 세부 모니터링을 활성화를 유지하고, 나머지는 세부 모니터링을 비활성화하세요.
GPU Server의 ServiceWatch 세부 모니터링 비활성화하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 ServiceWatch 세부 모니터링 비활성화할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 ServiceWatch 세부 모니터링 수정 버튼을 클릭하세요. ServiceWatch 세부 모니터링 수정 팝업창으로 이동합니다.
- ServiceWatch 세부 모니터링 수정 팝업창에서 활성화 선택 해제한 후, 안내 문구를 확인하고 확인 버튼을 클릭하세요.
- GPU Server 상세 페이지에서 ServiceWatch 세부 모니터링 항목을 확인하세요.
GPU Server 관리 부가 기능
GPU Server 서버 관리를 위해 Console 로그 조회, Dump 생성, Rebuild를 할 수 있습니다. GPU Server의 Console 로그 조회, Dump 생성, Rebuild를 하려면 다음 절차를 따르세요.
콘솔 로그 확인하기
GPU Server의 현재 콘솔 로그를 확인할 수 있습니다.
GPU Server의 콘솔 로그 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 콘솔 로그를 확인할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 콘솔 로그 버튼을 클릭하세요. 콘솔 로그 팝업창으로 이동합니다.
- 콘솔 로그 팝업창에서 출력된 콘솔 로그를 확인합니다.
Dump 생성하기
GPU Server의 Dump 파일을 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 Dump 생성 버튼을 클릭하세요.
- Dump 파일은 GPU Server 안에 생성됩니다.
Rebuild 수행하기
기존 GPU Server 서버의 모든 데이터와 설정을 삭제하고, 새로운 서버로 Rebuild하여 구성할 수 있습니다.
GPU Server의 Rebuild를 수행하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 Rebuild를 수행할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 Rebuild 버튼을 클릭하세요.
- GPU Server Rebuild 중에는 서버 상태가 Rebuilding로 변경되었다가 Rebuild가 완료되면 Rebuild 수행 전 상태로 돌아옵니다.
- GPU Server 상태에 대한 자세한 내용은 GPU Server 상세 정보 확인하기를 참고하세요.
GPU Server 해지하기
사용하지 않는 GPU Server를 해지하면 운영 비용을 절감할 수 있습니다. 단, GPU Server를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 해지 후에는 데이터를 복구할 수 없으므로 주의해주세요.
GPU Server를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 연결된 스토리지의 해지는 Delete on termination 설정에 따라 다르오니, 해지 제약 사항을 참고하세요.
- 해지가 완료되면, GPU Server 목록 페이지에서 자원이 해지되었는지 확인하세요.
해지 제약 사항
GPU Server 해지 요청 시 해지가 불가한 경우에는 팝업창으로 안내합니다. 아래 케이스를 참고하세요.
해지 불가
- File Storage가 연결된 경우는 File Storage 연결을 먼저 해지해주세요.
- LB Pool이 연결된 경우는 LB Pool 연결을 먼저 해지해 주세요.
- Lock이 설정된 경우는 Lock 설정을 미사용으로 변경 후 재시도 해주세요.
연결된 스토리지의 해지는 Delete on termination 설정에 따라 달라집니다.
Delete on termination 설정 별 삭제
- Delete on termination 설정 여부에 따라 볼륨 삭제 여부도 달라집니다.
- Delete on termination 미설정 시: GPU Server를 해지해도 해당 볼륨이 삭제되지 않습니다.
- Delete on termination 설정 시: GPU Server를 해지하면 해당 볼륨이 삭제됩니다.
- Snapshot이 존재하는 볼륨은 Delete on termination이 설정되어도 삭제되지 않습니다.
- Multi attach 볼륨은 삭제하려는 서버가 볼륨에 연결된 마지막 남은 서버일 때만 삭제됩니다.
3.2.1 - Image 관리하기
사용자는 Samsung Cloud Platform Console을 통해 GPU Server 서비스 내 Image 서비스의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 해당 서비스를 생성할 수 있습니다.
Image 생성하기
가동 중인 GPU Server 서버의 Image를 생성할 수 있습니다. GPU Server의 Image를 생성하려면 Image 생성하기를 참고해주세요.
Image 상세 정보 확인하기
Image 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Image 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Image 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Image 상세 페이지로 이동합니다.
- Image 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 이미지 상태 사용자가 생성한 Image의 상태 - Active: 사용 가능한 상태
- Queued: Image 생성 생성 시, Image가 업로드 되어 처리 대기 중인 상태
- Importing: Image 생성 생성 시, Image가 업로드 되어 처리 중인 상태
다른 Account로 공유 Image를 다른 Account로 공유 가능 - Image의 Visibility가 Shared 상태이어야만 다른 Account로 공유 가능
이미지 삭제 Image를 삭제하는 버튼 - Image를 삭제하면 복구 불가
표. GPU Server Image 상태 정보 및 부가 기능
- Image 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Image 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | Image 이름 |
| 자원 ID | Image ID |
| 생성자 | Image를 생성한 사용자 |
| 생성 일시 | Image를 생성한 일시 |
| 수정자 | Image를 수정한 사용자 |
| 수정 일시 | Image를 수정한 일시 |
| 이미지명 | Image 이름 |
| 최소 디스크 | Image의 최소 디스크 용량(GB)
|
| 최소 RAM | Image의 최소 RAM 용량(GB) |
| OS 타입 | Image의 OS 타입 |
| OS hash algorithm | OS hash algorithm 방식 |
| Visibility | 이미지에 대한 접근 권한을 표시
|
| Protected | 이미지 삭제 불가 여부를 선택
|
| 이미지 파일 URL | 이미지 생성 시 업로드 한 이미지 파일 URL
|
| 공유 현황 | 다른 Account로 이미지를 공유하고 있는 현황
|
표. Image 상세 정보 탭 항목
태그
Image 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Image 태그 탭 항목
작업 이력
Image 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. GPU Server Image 작업 이력 탭 상세 정보 항목
Image 자원 관리하기
생성된 Image 의 제어 및 관리 기능을 설명합니다.
다른 Account로 공유하기
Image를 다른 Account로 공유하려면 다음 절차를 따르세요.
- 공유할 Account에 접속하여 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 제어할 Image를 클릭하세요. Image 상세 페이지로 이동합니다.
- 다른 Account로 공유 버튼을 클릭하세요. 다른 Account로 이미지 공유 페이지로 이동합니다.
- 다른 Account로 공유 기능을 통해 Image를 다른 Account로 공유할 수 있습니다. Image를 다른 Account로 공유하려면 Image의 Visibility가 Shared이어야 합니다.
- 다른 Account로 이미지 공유 페이지에서 필요한 정보를 입력하고 완료 버튼을 클릭하세요.
구분 필수 여부상세 설명 이미지명 - 공유할 이미지의 이름 - 입력 불가
이미지 ID - 공유할 이미지 ID - 입력 불가
공유 Account ID 필수 공유할 다른 Account ID 입력 - 영문, 숫자, 특수문자
-를 사용하여 64자 이내로 입력
표. 다른 Account로 이미지 공유 필수 입력 항목 - Image 상세 페이지의 공유 현황에서 정보를 확인할 수 있습니다.
- 최초 요청 시에는 상태가 Pending 이고, 공유 받을 Account에서 승인이 완료되면 Accepted로 변경됩니다.
안내
현재 사용자의 Image 파일 업로드를 통해 생성한 Image만 다른 Account로 공유가 가능합니다. 가동 중인 GPU Server의 Image로 Custom Image를 생성한 경우 다른 Account로 공유가 되지 않으며 해당 기능은 제공 예정이니 참고하세요.
다른 Account로부터 공유받기
Image를 다른 Account로부터 공유받으려면 다음 절차를 따르세요.
- 공유 받을 Account에 접속하여 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 이미지 공유 받기 버튼을 클릭하세요. 이미지 공유 받기 팝업창으로 이동합니다.
- 이미지 공유 받기 팝업창에서 공유 받고자 하는 Image의 자원 ID를 입력하고, 확인 버튼을 클릭하세요.
- 이미지 공유 받기가 완료되면 Image 목록에서 공유받은 Image를 확인할 수 있습니다.
Image 삭제하기
사용하지 않는 Image를 삭제할 수 있습니다. 단, Image를 삭제하면 복구할 수 없으므로 Image 삭제 시에는 발생하는 영향을 충분히 고려한 후 삭제 작업을 진행해야 합니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Image를 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Image 메뉴를 클릭하세요. Image 목록 페이지로 이동합니다.
- Image 목록 페이지에서 삭제할 자원을 선택하고, 삭제 버튼을 클릭하세요.
- Image 목록 페이지에서 다수의 Image 체크 박스를 선택하고, 자원 목록 상단의 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Image 목록 페이지에서 자원이 삭제되었는지 확인하세요.
3.2.2 - Keypair 관리하기
사용자는 Samsung Cloud Platform Console을 통해 GPU Server 서비스 내 Keypair의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Keypair 생성하기
Samsung Cloud Platform Console에서 GPU Server 서비스를 사용하면서 Keypair 서비스를 생성하여 사용할 수 있습니다.
Keypair 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 Keypair 생성 버튼을 클릭하세요. Keypair 생성 페이지로 이동합니다.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
구분 필수 여부상세 설명 Keypair명 필수 생성할 Keypair의 이름 - 영문, 숫자, 공백과 특수문자(
-,_)를 사용하여 255자 이내로 입력
Keypair 유형 필수 ssh 표. Keypair 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Keypair 추가 정보 입력 항목주의- 생성 완료 후 최초 1회에 한해서 Key를 다운로드할 수 있습니다. 재발급이 불가능하므로, 다운로드 되었는지 확인하세요.
- 다운로드 받은 Private Key는 안전한 곳에 저장하세요.
- 서비스 정보 입력 영역에서 필요한 정보를 입력하세요.
- 입력 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Keypair 목록 페이지에서 생성한 자원을 확인하세요.
Keypair 상세 정보 확인하기
Keypair 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Keypair 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Keypair 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Keypair 상세 페이지로 이동합니다.
- Keypair 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Keypair 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | Keypair 이름 |
| 자원 ID | Keypair의 고유 자원 ID |
| 생성자 | Keypair를 생성한 사용자 |
| 생성 일시 | Keypair를 생성한 일시 |
| 수정자 | Keypair 정보를 수정한 사용자 |
| 수정 일시 | Keypair정보를 수정한 일시 |
| Keypair명 | Keypair 이름 |
| Fingerprint | Key를 식별하기 위한 고유한 값 |
| 사용자 ID | Keypair 생성한 사용자 ID |
| 공개 키 | 공개 키 정보 |
표. Keypair 상세 정보 탭 항목
태그
Keypair 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Keypair 태그 탭 항목
작업 이력
Keypair 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Keypair 작업 이력 탭 상세 정보 항목
Keypair 자원 관리하기
Keypair의 제어 및 관리 기능을 설명합니다.
공개 키 가져오기
공개 키 가져오기를 하려면 다음 절차를 따르세요.
모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
Keypair 목록 페이지에서 상단의 더보기 버튼을 클릭하여 공개 키 가져오기 버튼을 클릭하세요. 공개 키 가져오기 페이지로 이동합니다.
- 필수 정보 입력 영역에 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Keypair명 필수 생성할 Keypair 이름 Keypair 유형 필수 ssh 공개 키 필수 공개 키 입력 - 파일 불러오기: 파일 첨부 버튼을 선택하여 공개 키 파일을 첨부
- 첨부 파일은 다음의 확장자 파일(.pem)만 가능
- 공개 키 입력: 복사한 공개 키 값을 붙여넣기
- Keypair 상세 페이지에서 공개 키 값을 복사 가능
표. 공개 키 가져오기 필수 입력 항목 - 파일 불러오기: 파일 첨부 버튼을 선택하여 공개 키 파일을 첨부
- 필수 정보 입력 영역에 필요한 정보를 입력 또는 선택하세요.
입력한 정보를 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Keypair 목록 페이지에서 생성한 자원을 확인하세요.
Keypair 삭제하기
사용하지 않는 Keypair를 삭제할 수 있습니다. 단, Keypair를 삭제하면 복구할 수 없으므로 사전에 충분한 영향도 검토 후 삭제를 진행하시기 바랍니다.
주의
서비스 삭제 후에는 데이터를 복구할 수 없으므로 주의해주세요.
Keypair를 삭제하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Keypair 메뉴를 클릭하세요. Keypair 목록 페이지로 이동합니다.
- Keypair 목록 페이지에서 삭제할 자원을 선택하고, 삭제 버튼을 클릭하세요.
- Keypair 목록 페이지에서 다수의 Keypair 체크 박스를 선택하고, 자원 목록 상단의 삭제 버튼을 클릭하세요.
- 삭제가 완료되면 Keypair 목록 페이지에서 자원이 삭제되었는지 확인하세요.
3.2.3 - GPU Server에서 Multi-instance GPU 사용하기
GPU Server를 생성한 후 GPU Server의 VM(Guest OS)에서 MIG (Multi-instance GPU) 기능을 활성화하고 Instance를 생성해 사용할 수 있습니다.
Multi-instance GPU (NVIDIA A100) 살펴보기
NVIDIA A100은 NVIDIA 암페어(Ampere) 아키텍처를 기반으로 하는 Multi-instance GPU(MIG)로, 최대 7개의 독립된 GPU Instance로 안전하게 분할되어 CUDA (Compute Unified Device Architecture, 연산통합 장치설계) Application을 운용할 수 있습니다. NVIDIA A100은 고대역폭 메모리(HBM: high bandwidth memory)와 캐시를 활용하는 동시에 GPU 사용에 최적화된 방식으로 컴퓨팅 자원을 할당함으로써 다수의 사용자들에게 독립적인 GPU 자원을 제공할 수 있습니다. 사용자는 각 워크로드의 병렬 실행을 통해 GPU 최대 연산 용량에 도달하지 않은 워크로드를 활용할 수 있으므로, GPU 사용율을 극대화할 수 있습니다.
Multi-instance GPU 기능 사용하기
Multi-instance GPU 기능을 사용하려면 Samsung Cloud Platform에서 GPU Server 서비스를 생성한 후 A100 GPU가 할당된 VM Instance(GuestOS)를 생성해야 합니다. GPU Server 생성 완료 후, 아래의 MIG 적용 순서와 MIG 해제 순서를 따라 적용해볼 수 있습니다.
MIG 적용 순서
MIG 활성화 → GPU Instance 생성 → Compute Instance 생성 → MIG 사용
MIG 해제 순서
Compute Instance 삭제 → GPU Instance 삭제 → MIG 기능 해제(비활성화)
참고
- MIG 기능을 사용하기 위한 시스템 요구사항은 다음과 같습니다(NVIDIA - Supported GPUs 참고).
- CUDA toolkit 11, NVIDIA driver 450.80.02 또는 이후 버전
- CUDA toolkit 11을 지원하는 리눅스 배포 운영체제
- 컨테이너 또는 쿠버네티스 서비스 운용 시 MIG 기능을 사용하기 위한 요구사항은 다음과 같습니다.
- NVIDIA Container Toolkit(nvidia-docker2) v 2.5.0 또는 이후 버전
- NVIDIA K8s Device Plugin v 0.7.0 또는 이후 버전
- NVIDIA gpu-feature-discovery v 0.2.0 또는 이후 버전
MIG 적용 및 사용하기
MIG를 활성화하고 Instance를 생성해 작업을 할당하려면 다음 절차를 따르세요.
MIG 적용 순서
MIG 활성화 → GPU Instance 생성 → Compute Instance 생성 → MIG 사용
MIG 활성화
MIG를 적용하기 전 VM Instance(GuestOS)에서 GPU 상태를 확인하세요.
- MIG mode가 Disabled 상태인지 확인하세요.배경색 변경
$ nvidia-smi Mon Sep 27 08:37:08 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 08:37:08 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU 비활성화 상태 확인 (1) 배경색 변경$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)코드블록. nvidia-smi 명령어 - GPU 비활성화 상태 확인 (2)
- MIG mode가 Disabled 상태인지 확인하세요.
VM Instance(GuestOS)에서 GPU별로 MIG를 활성화(Enable)하고 VM Instance를 재부팅하세요.
배경색 변경$ nvidia-smi –I 0 –mig 1 Enabled MIG mode for GPU 00000000:05:00.0 All done. # reboot$ nvidia-smi –I 0 –mig 1 Enabled MIG mode for GPU 00000000:05:00.0 All done. # reboot코드블록. nvidia-smi 명령어 - MIG 활성화
참고
GPU 모니터링 에이전트가 다음과 같은 경고 메시지를 표시하는 경우, MIG를 활성화하기 전에 nvsm 및 dcgm 서비스를 중단하세요.
Warning: MIG mode is in pending enable state for GPU 00000000:05:00.0: In use by another client. 00000000:05:00.0 is currently being used by one or more other processes (e.g. CUDA application or a monitoring application such as another instance of nvidia-smi).
# systemctl stop nvsm
# systemctl stop dcgm
- MIG 작업을 마친 후 nvsm 및 dcgm 서비스를 다시 시작하세요.
- VM Instance(GuestOS)에서 MIG를 적용한 후 GPU 상태를 확인하세요.
- MIG mode가 Enabled 상태인지 확인하세요.배경색 변경
$ nvidia-smi Mon Sep 27 09:44:33 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 09:44:33 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU 활성화 상태 확인 (1) 배경색 변경$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)코드블록. nvidia-smi 명령어 - GPU 활성화 상태 확인 (2)
- MIG mode가 Enabled 상태인지 확인하세요.
GPU Instance 생성
MIG 활성화하고 상태를 확인하였다면, GPU Instance를 생성할 수 있습니다.
생성할 수 있는 MIG GPU Instance 프로파일 목록을 확인하세요.
배경색 변경$ nvidia-smi mig -i [GPU ID] -lgip$ nvidia-smi mig -i [GPU ID] -lgip코드블록. nvidia-smi 명령어 - MIG GPU Instance 프로파일 목록 확인 배경색 변경$ nvidia-smi mig -i 0 -lgip +-----------------------------------------------------------------------------+ | GPU instance profiles: | | GPU Name ID Instances Memory P2P SM DEC ENC | | Free/Total GiB CE JPEG OFA | |=============================================================================| | 0 MIG 1g.10gb 19 7/7 9.50 No 14 0 0 | | 1 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 1g.10gb+me 20 1/1 9.50 No 14 0 0 | | 1 1 1 | +-----------------------------------------------------------------------------+ | 0 MIG 2g.20gb 14 3/3 19.50 No 28 1 0 | | 2 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 3g.40gb 9 2/2 39.50 No 42 2 0 | | 3 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 4g.40gb 5 1/1 39.50 No 56 2 0 | | 4 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 7g.80gb 0 1/1 79.25 No 98 0 0 | | 7 1 1 | +-----------------------------------------------------------------------------+$ nvidia-smi mig -i 0 -lgip +-----------------------------------------------------------------------------+ | GPU instance profiles: | | GPU Name ID Instances Memory P2P SM DEC ENC | | Free/Total GiB CE JPEG OFA | |=============================================================================| | 0 MIG 1g.10gb 19 7/7 9.50 No 14 0 0 | | 1 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 1g.10gb+me 20 1/1 9.50 No 14 0 0 | | 1 1 1 | +-----------------------------------------------------------------------------+ | 0 MIG 2g.20gb 14 3/3 19.50 No 28 1 0 | | 2 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 3g.40gb 9 2/2 39.50 No 42 2 0 | | 3 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 4g.40gb 5 1/1 39.50 No 56 2 0 | | 4 0 0 | +-----------------------------------------------------------------------------+ | 0 MIG 7g.80gb 0 1/1 79.25 No 98 0 0 | | 7 1 1 | +-----------------------------------------------------------------------------+코드블록. MIG GPU Instance 프로파일 목록
참고
A100 GPU Instance 프로파일은 NVIDIA A100 MIG Profile의 예시를 참고하세요.

| Profile Name | Fraction of Memory | Fraction of SMs | Hardware Units | L2 Cache Size | Number of Instances Available |
|---|---|---|---|---|---|
| MIG 1g.10gb | 1/8 | 1/7 | 0 NVDECs /0 JPEG /0 OFA | 1/8 | 7 |
| MIG 1g.10gb+me | 1/8 | 1/7 | 1 NVDEC /1 JPEG /1 OFA | 1/8 | 1 (A single 1g profile can include media extensions) |
| MIG 2g.20gb | 2/8 | 2/7 | 1 NVDECs /0 JPEG /0 OFA | 2/8 | 3 |
| MIG 3g.40gb | 4/8 | 3/7 | 2 NVDECs /0 JPEG /0 OFA | 4/8 | 2 |
| MIG 4g.40gb | 4/8 | 4/7 | 2 NVDECs /0 JPEG /0 OFA | 4/8 | 1 |
| MIG 7g.80gb | Full | 7/7 | 5 NVDECs /1 JPEG /1 OFA | Full | 1 |
표. NVIDIA A100 MIG Profile
참고
MIG 1g.10gb+me 프로파일은 R470 드라이버와 함께 시작하는 경우에만 사용할 수 있습니다.
- MIG GPU Instance를 생성한 후 확인하세요.
GPU Instance 생성
배경색 변경$ nvidia-smi mig -i [GPU ID] -cgi [Profile ID]$ nvidia-smi mig -i [GPU ID] -cgi [Profile ID]코드블록. nvidia-smi 명령어 - GPU Instance 생성 배경색 변경$ nvidia-smi mig -i 0 -cgi 0 Successfully created GPU instance ID 0 on GPU 0 using profile MIG 7g.80gb (ID 0)$ nvidia-smi mig -i 0 -cgi 0 Successfully created GPU instance ID 0 on GPU 0 using profile MIG 7g.80gb (ID 0)코드블록. nvidia-smi 명령어 - GPU Instance 생성 예시 GPU Instance 확인
배경색 변경$ nvidia-smi mig -i [GPU ID] -lgi$ nvidia-smi mig -i [GPU ID] -lgi코드블록. nvidia-smi 명령어 - GPU Instance 확인 배경색 변경$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |========================================================| | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |========================================================| | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU Instance 확인 예시
Compute Instance 생성
GPU Instance를 생성하였다면, Compute Instance를 생성할 수 있습니다.
생성할 수 있는 MIG Compute Instance 프로파일을 확인하세요.
배경색 변경$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip코드블록. nvidia-smi 명령어 - MIG Compute Instance 프로파일 확인 배경색 변경$ nvidia-smi mig -i 0 -gi 0 -lcip +---------------------------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Exclusive Shared | | GPU Instance ID Free/Total SM DEC ENC OFA | | ID CE JPEG | |=================================================================================| | 0 0 MIG 1c.7g.80gb 0 7/7 14 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 2c.7g.80gb 1 3/3 28 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 3c.7g.80gb 2 2/2 42 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 4c.7g.80gb 3 1/1 56 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 7g.80gb 4* 1/1 98 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 -lcip +---------------------------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Exclusive Shared | | GPU Instance ID Free/Total SM DEC ENC OFA | | ID CE JPEG | |=================================================================================| | 0 0 MIG 1c.7g.80gb 0 7/7 14 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 2c.7g.80gb 1 3/3 28 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 3c.7g.80gb 2 2/2 42 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 4c.7g.80gb 3 1/1 56 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 7g.80gb 4* 1/1 98 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+코드블록. MIG Compute Instance 프로파일 목록 예시 MIG Compute Instance를 생성하고 확인하세요.
- MIG Compute Instance 생성배경색 변경
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -cci [Compute Profile ID]$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -cci [Compute Profile ID]코드블록. nvidia-smi 명령어 - MIG Compute Instance 생성 배경색 변경$ nvidia-smi mig -i 0 -gi 0 -cci 4 Successfully created compute instance ID 0 on GPU instance ID 0 using profile MIG 7g.80gb(ID 4)$ nvidia-smi mig -i 0 -gi 0 -cci 4 Successfully created compute instance ID 0 on GPU instance ID 0 using profile MIG 7g.80gb(ID 4)코드블록. nvidia-smi 명령어 - MIG Compute Instance 생성 예시 - MIG Compute Instance 확인배경색 변경
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –lci$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –lci코드블록. nvidia-smi 명령어 - MIG Compute Instance 확인 배경색 변경$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | |=================================================================| | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | |=================================================================| | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+코드블록. MIG Compute Instance 확인 예시 배경색 변경$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0) MIG 7g.80gb Device 0: (UUID: MIG-53e20040-758b-5ecb-948e-c626d03a9a32)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0) MIG 7g.80gb Device 0: (UUID: MIG-53e20040-758b-5ecb-948e-c626d03a9a32)코드블록. nvidia-smi 명령어 - GPU 상태 확인 (1) 배경색 변경$ nvidia-smi Mon Sep 27 09:52:17 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 49W / 400W | 0MiB / 81251MiB | N/A Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | 0 0 0 0 | 0MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 1MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 09:52:17 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 49W / 400W | 0MiB / 81251MiB | N/A Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | 0 0 0 0 | 0MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 1MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU 상태 확인 (2)
- MIG Compute Instance 생성
MIG 사용
- MIG Instance를 사용해 Job을 수행하세요.
- 작업 수행 예시배경색 변경
$ docker run --gpus '"device=[GPU ID]:[MIG ID]"' -rm nvcr.io/nvidia/cuda nvidia-smi$ docker run --gpus '"device=[GPU ID]:[MIG ID]"' -rm nvcr.io/nvidia/cuda nvidia-smi코드블록. 작업 수행 예시 - 아래와 같이 작업을 수행한 예시를 확인해볼 수 있습니다.배경색 변경
$ docker run --gpus '"device=0:0"' -rm -it --network=host --shm-size=1g --ipc=host -v /root/.ssh/:/root/.ssh ================ == TensorFlow == ================ NVIDIA Release 21.08-tf1 (build 26012104) TensorFlow Version 1.15.5 Container image Copyright (c) 2021, NVIDIA CORPORATION. All right reserved. ... # Python 프로세스 실행 root@d622a93c9281:/workspace# python /workspace/nvidia-examples/cnn/resnet.py --num_iter 100 ... PY 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] TF 1.15.5 ...$ docker run --gpus '"device=0:0"' -rm -it --network=host --shm-size=1g --ipc=host -v /root/.ssh/:/root/.ssh ================ == TensorFlow == ================ NVIDIA Release 21.08-tf1 (build 26012104) TensorFlow Version 1.15.5 Container image Copyright (c) 2021, NVIDIA CORPORATION. All right reserved. ... # Python 프로세스 실행 root@d622a93c9281:/workspace# python /workspace/nvidia-examples/cnn/resnet.py --num_iter 100 ... PY 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] TF 1.15.5 ...코드블록. 작업 수행 결과
- 작업 수행 예시
- GPU 사용률을 확인하세요. (JOB 프로세스 생성)
- Job이 구동될 때 MIG 디바이스에 프로세스가 할당되고 사용률이 증가하는 것을 확인할 수 있습니다.배경색 변경
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip코드블록. nvidia-smi 명령어 - GPU 사용률 확인 - 아래와 같이 GPU 사용률을 확인할 수 있습니다.배경색 변경
+-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | 0 0 0 0 | 66562MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 5MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 0 0 17483 C python 66559MiB | +-----------------------------------------------------------------------------++-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | 0 0 0 0 | 66562MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 5MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 0 0 17483 C python 66559MiB | +-----------------------------------------------------------------------------+코드블록. GPU 사용률 확인 예시
- Job이 구동될 때 MIG 디바이스에 프로세스가 할당되고 사용률이 증가하는 것을 확인할 수 있습니다.
MIG Instance 삭제 및 해제하기
MIG Instance를 삭제하고 MIG를 해제하려면 다음 절차를 따르세요.
MIG 해제 순서
Compute Instance 삭제 → GPU Instance 삭제 → MIG 기능 해제(비활성화)
Compute Instance 삭제
- Compute Instance를 삭제하세요.배경색 변경
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dci $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -ci [Compute Instance] –dci$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dci $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -ci [Compute Instance] –dci코드블록. nvidia-smi 명령어 - Compute Instance 삭제 배경색 변경$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | |=================================================================| | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | |=================================================================| | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+코드블록. MIG Compute Instance 확인 예시 배경색 변경$ nvidia-smi mig -i 0 -gi 0 –dci Successfully destroyed compute instance ID 0 from GPU instance ID 0$ nvidia-smi mig -i 0 -gi 0 –dci Successfully destroyed compute instance ID 0 from GPU instance ID 0코드블록. Compute Instance 삭제 예시 배경색 변경$ nvidia-smi mig -i 0 -gi 0 –lci No compute instances found: Not found$ nvidia-smi mig -i 0 -gi 0 –lci No compute instances found: Not found코드블록. Compute Instance 삭제 확인
GPU Instance 삭제
- GPU Instance를 삭제하세요.배경색 변경
$ nvidia-smi mig -i [GPU ID] –dgi $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dgi$ nvidia-smi mig -i [GPU ID] –dgi $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dgi코드블록. nvidia-smi 명령어 - GPU Instance 삭제 배경색 변경$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |========================================================| | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |========================================================| | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU Instance 확인 예시 배경색 변경$ nvidia-smi mig -i 0 -dgi Successfully destroyed GPU instance ID 0 from GPU 0$ nvidia-smi mig -i 0 -dgi Successfully destroyed GPU instance ID 0 from GPU 0코드블록. nvidia-smi 명령어 - GPU Instance 삭제 예시 배경색 변경$ nvidia-smi mig -i 0 -lgi No GPU instances found: Not found$ nvidia-smi mig -i 0 -lgi No GPU instances found: Not found코드블록. nvidia-smi 명령어 - GPU Instance 삭제 예시
MIG 기능 해제(비활성화)
- MIG를 비활성화(Disable)한 후 재부팅하세요.배경색 변경
$ nvidia-smi -mig 0 Disabled MIG Mode for GPU 00000000:05:00.0 All done.$ nvidia-smi -mig 0 Disabled MIG Mode for GPU 00000000:05:00.0 All done.코드블록. nvidia-smi 명령어 - MIG 비활성화 배경색 변경$ nvidia-smi Mon Sep 30 05:18:28 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 33C P0 60W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 30 05:18:28 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------| | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 33C P0 60W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG| | | | ECC| | |=============================================================================| | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+코드블록. nvidia-smi 명령어 - GPU 상태 확인
3.2.4 - GPU Server에서 NVSwitch 사용하기
GPU Server를 생성한 후 GPU Server의 VM(Guest OS)에서 NVSwitch 기능을 활성화하고 GPU 간 P2P(GPU to GPU)통신을 빠르게 사용할 수 있습니다.
Multi GPU를 위한 NVIDIA NVSwitch 살펴보기
NVIDIA A100 GPU서버는 NVIDIA 암페어(Ampere) 아키텍처를 기반으로 하는 멀티 GPU로, 베이스보드에는 8개의 Ampere 80 GB GPU가 장착되어 있습니다. 베이스보드에 장착된 GPU들은 NVLink 포트를 통해 6개의 NVSwitch와 연결됩니다. 베이스보드에 있는 GPU 간 통신은 600 GBps 대역폭 전체를 활용해 이루어집니다. 이런 이유로 A100 GPU 서버에 장착된 8개의 GPU가 마치 하나처럼 연결되어 동작 할 수 있으므로, GPU to GPU 사용률을 극대화 할 수 있습니다.
- NVLink(25 GBps) 12개 Lane 8 GPU 구성도

- NVSwitch(600 GBps) 6개 8 GPU 구성도

GPU NVSwitch 생성하기
GPU NVSwitch 기능을 사용하려면 Samsung Cloud Platform에서 GPU Server 서비스를 생성한 후, A100 GPU 8개가 할당된 VM Instance(GuestOS)를 생성하고 Fabricmanager를 활성화합니다.
주의
- NVSwitch는 단일 GPU Server에 8개의 A100 GPU를 할당한 상품(g1v128a8 (vCPU 128 | Memory 1920G | A100(80GB)*8))의 경우에만 Fabricmanager를 활성화하여 사용할 수 있습니다.
- 현재 Windows OS로 생성된 GPU Server에서는 NVSwitch (Fabricmanager)를 지원하지 않습니다.
NVSwitch 설치 및 동작 확인하기(Fabricmanager 활성화)
NVSwitch를 구동하려면 GPU Instance에서 Fabricmanager를 설치하고 다음 절차를 따르세요.
GPU 서버에 NVIDIA GPU Driver (470.52.02 Version)를 설치하세요.
배경색 변경$ add-apt-repository ppa:graphics-drivers/ppa $ apt-get update $ apt-get install nvidia-driver-470-server$ add-apt-repository ppa:graphics-drivers/ppa $ apt-get update $ apt-get install nvidia-driver-470-server코드블록. NVIDIA GPU Driver 설치 GPU 서버에 NVIDIA Fabric Manager (470 Version)를 설치하고 구동하세요(For NVSwitch).
배경색 변경$ apt-get install cuda-drivers-fabricmanager-470 $ systemctl enable nvidia-fabricmanager $ systemctl start nvidia-fabricmanager$ apt-get install cuda-drivers-fabricmanager-470 $ systemctl enable nvidia-fabricmanager $ systemctl start nvidia-fabricmanager코드블록. NVIDIA Fabric Manager 설치 및 구동 GPU 서버에 NVIDIA Fabric Manager 구동 상태를 확인하세요.
- 정상 구동 시 active (running) 표시배경색 변경
$ systemctl status nvidia-fabricmanager$ systemctl status nvidia-fabricmanager코드블록. NVIDIA Fabric Manager 구동 상태 확인
- 정상 구동 시 active (running) 표시
- GPU 서버에 NVSwitch 구동 상태를 확인하세요.
- 정상 구동 시 NV12 표시배경색 변경
$ nvidia-smi topo --matrix$ nvidia-smi topo --matrix코드블록. NVSwitch 구동 상태 확인
- 정상 구동 시 NV12 표시
3.2.5 - ServiceWatch Agent 설치하기
사용자는 GPU Server에 ServiceWatch Agent를 설치하여 사용자 정의 지표와 로그를 수집할 수 있습니다.
참고
ServiceWatch Agent를 통한 사용자 정의 지표/로그 수집은 현재 Samsung Cloud Platform For Enterprise에서만 사용 가능합니다. 이외 오퍼링에서도 향후 제공 예정입니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 각 서비스로부터 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집 설정은 제거하거나 비활성화하기를 권장합니다.
ServiceWatch Agent
GPU Server에 ServiceWatch의 사용자 정의 지표 및 로그 수집을 위해 설치해야 하는 Agent는 크게 2가지로 나눌 수 있습니다. Prometheus Exporter와 Open Telemetry Collector 입니다.
| 구분 | 상세 설명 | |
|---|---|---|
| Prometheus Exporter | 특정 애플리케이션이나 서비스의 메트릭을 Prometheus가 스크랩(scrape)할 수 있는 형식으로 제공
| |
| Open Telemetry Collector | 분산 시스템의 메트릭, 로그와 같은 텔레메트리 데이터를 수집하고, 처리(필터링, 샘플링 등)한 후, 여러 백엔드(예: Prometheus, Jaeger, Elasticsearch 등)로 내보내는 중앙 집중식 수집기 역할
|
표. Prometheus Exporter와 Open Telemetry Collector 설명
주의
GPU Server에 Kubernetes Engine을 구성한 경우, Kubernetes Engine에서 제공되는 지표를 통해 GPU 지표를 확인하기 바랍니다.
- Kubernetes Engine이 구성되어 있는 GPU Server에 DCGM Exporter를 설치하게 되면 정상 동작하지 않을 수 있습니다.
GPU 지표를 위한 Prometheus Exporter 설치 (for Ubuntu)
GPU Server의 지표를 수집하기 위한 Prometheus Exporter를 아래의 순서에 따라 설치합니다.
NVDIA Driver 설치 확인
- 설치되어 있는 NVDIA Driver를 확인합니다.배경색 변경
nvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csv코드블록. NVDIA Driver 버전 확인 명령어 배경색 변경driver_version 535.183.06 ... 535.183.06driver_version 535.183.06 ... 535.183.06코드블록. NVDIA Driver 버전 확인 예시
NVSwitch Configuration and Query (NSCQ) Library 설치
참고
NVSwitch Configuration and Query (NSCQ) Library는 Hopper or earlier Generation GPUs 인 경우에 필요합니다.
안내
아래 설치 명령어는 인터넷이 사용 가능한 환경에서 가능합니다.
만약 인터넷이 안되는 환경이라면, https://developer.download.nvidia.com/compute/cuda/repos/ 에서 libnvdia-nscq를 다운로드받아 업로드해야 합니다.
cuda-keyring를 설치합니다.
배경색 변경wget https://developer.download.nvidia.com/compute/cuda/repos/<distro>/<arch>/cuda-keyring_1.1-1_all.debwget https://developer.download.nvidia.com/compute/cuda/repos/<distro>/<arch>/cuda-keyring_1.1-1_all.deb코드블록. NSCQ library 다운로드 명령어 배경색 변경sudo dpkg -i cuda-keyring_1.1-1_all.deb apt updatesudo dpkg -i cuda-keyring_1.1-1_all.deb apt update코드블록. NSCQ library 설치 명령어 배경색 변경nvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csv코드블록. NVDIA Driver 버전 확인 명령어 배경색 변경driver_version 535.183.06 ... 535.183.06driver_version 535.183.06 ... 535.183.06코드블록. NVDIA Driver 버전 확인 예시 libnvidia-nscq를 설치합니다.
배경색 변경apt-cache policy libnvidia-nscq-535apt-cache policy libnvidia-nscq-535코드블록. NSCQ library apt-cache 명령어 배경색 변경libnvidia-nscq-535: Installed: (none) Candidate: 535.247.01-1 Version table: 535.247.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.216.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.06-1 600 # Driver 와 일치 하는 버전으로 설치 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.01-1 600 ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.54.03-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvidia-nscq-535: Installed: (none) Candidate: 535.247.01-1 Version table: 535.247.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.216.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.06-1 600 # Driver 와 일치 하는 버전으로 설치 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.01-1 600 ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.54.03-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages코드블록. NSCQ library apt-cache 명령어 결과 배경색 변경apt install libnvidia-nscq-535=535.183.06-1apt install libnvidia-nscq-535=535.183.06-1코드블록. NSCQ library 설치 명령어
안내
NVDIA Driver의 버전과 같은 버전으로 설치해야 합니다.
- 예시) driver version: 535.183.06, libnvdia-nscq version: 535.183.06-1
NVSwitch Device Monitoring API(NVSDM) Library 설치
참고
Blackwell 이후 GPU Architecture 에서는 NVSDM Library 설치가 필요합니다. NVDIA Driver 버전 560 이하는 NVSDM Library가 제공되지 않습니다.
- NVSDM library 설치합니다.배경색 변경
apt-cache policy libnvsdmapt-cache policy libnvsdm코드블록. NVSDM library apt-cache 명령어 배경색 변경libnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages코드블록. NVSDM library apt-cache 명령어 결과 배경색 변경apt install libnvsdm=580.105.08-1apt install libnvsdm=580.105.08-1코드블록. NVSDM library 설치
NVIDIA DCGM 설치 (for Ubuntu)
아래의 순서에 따라 DCGM Exporter를 설치합니다.
DCGM(datacenter-gpu-manager) 설치
NVIDIA의 데이터센터 GPU Manager(DCGM) 도구의 특정 버전을 가리키며, 이는 NVIDIA 데이터센터 GPU를 관리하고 모니터링하기 위한 패키지입니다. 특히, cuda12는 이 관리 도구가 CUDA 12 버전에 맞춰 설치됨을 나타내며, datacenter-gpu-manager-4는 DCGM의 4.x 버전을 의미합니다. 이 도구는 GPU 상태 모니터링, 진단, 경고 시스템 및 전력/클럭 관리를 포함한 다양한 기능을 제공합니다.
- CUDA 버전을 확인합니다.배경색 변경
nvidia-smi | grep CUDAnvidia-smi | grep CUDA코드블록. CUDA 버전 확인 배경색 변경| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |코드블록. CUDA 버전 확인 결과 예시 배경색 변경CUDA_VERSION=12CUDA_VERSION=12코드블록. CUDA 버전 설정 명령어 - datacenter-gpu-manager-cuda를 설치합니다.배경색 변경
apt install datacenter-gpu-manager-4-cuda${CUDA_VERSION}apt install datacenter-gpu-manager-4-cuda${CUDA_VERSION}코드블록. datacenter-gpu-manager-cuda 설치 명령어
datacenter-gpu-manager-exporter 설치
NVIDIA Data Center GPU Manager(DCGM) 기반으로 GPU 사용량, 메모리 사용량, 온도, 전력 소비 등 다양한 GPU 메트릭을 수집하여 Prometheus와 같은 모니터링 시스템에서 사용할 수 있도록 노출하는 도구입니다.
- datacenter-gpu-manager-exporter를 설치합니다.배경색 변경
apt install datacenter-gpu-manager-exporterapt install datacenter-gpu-manager-exporter코드블록. datacenter-gpu-manager-exporter 설치 명령어 - DCGM Exporter 설정 파일을 확인합니다.배경색 변경
cat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartcat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStart코드블록. datacenter-gpu-manager-exporter 설정 파일 확인 명령어 배경색 변경ExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csv코드블록. datacenter-gpu-manager-exporter 설정 파일 확인 결과 예시 - DCGM Exporter 설치 시 제공되는 설정을 확인하고 필요한 메트릭은
#을 제거하고, 불필요한 메트릭은#을 추가합니다.배경색 변경vi /etc/dcgm-exporter/default-counters.csv ## Example ## ... DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active. ...vi /etc/dcgm-exporter/default-counters.csv ## Example ## ... DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active. ...코드블록. datacenter-gpu-manager-exporter metric 설정 예시
참고
GPU DCGM Exporter로 수집 가능한 지표와 설정 방법은 DCGM Exporter 지표를 참고하세요.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집은 제거하거나 비활성화해야 과도한 요금이 부과되지 않습니다.
DCGM 서비스 활성화 및 시작
nvdia-dcgm 서비스 활성화 및 시작작합니다.
배경색 변경systemctl enable --now nvidia-dcgmsystemctl enable --now nvidia-dcgm코드블록. nvdia-dcgm 서비스 활성화 및 시작작 명령어 nvdia-dcgm-exporter 서비스 활성화 및 시작합니다.
배경색 변경systemctl enable --now nvidia-dcgm-exportersystemctl enable --now nvidia-dcgm-exporter코드블록. nvdia-dcgm-exporter 서비스 활성화 및 시작 명령어
안내
DCGM Exporter 설정을 완료하였다면, ServiceWatch에서 제공하는 Open Telemetry Collector를 설치하여 SerivceWatch Agent 설정을 완료하셔야 합니다.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
GPU 지표를 위한 Prometheus Exporter 설치 (for RHEL)
ServiceWatch Agent를 GPU Server의 지표를 수집하기 위해 아래의 순서에 따라 설치합니다.
NVDIA Driver 설치 확인 (for RHEL)
- 설치되어 있는 NVDIA Driver를 확인합니다.배경색 변경
nvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csv코드블록. NVDIA Driver 버전 확인 명령어 배경색 변경driver_version 535.183.06 ... 535.183.06driver_version 535.183.06 ... 535.183.06코드블록. NVDIA Driver 버전 확인 예시
NVSwitch Configuration and Query (NSCQ) Library 설치 (for RHEL)
참고
NVSwitch Configuration and Query (NSCQ) Library는 Hopper or earlier Generation GPUs 인 경우에 필요합니다.
- RHEL의 경우 libnvdia-nscq가 설치되어 있는지 확인 후 설치합니다.
안내
아래 설치 명령어는 인터넷이 사용 가능한 환경에서 가능합니다.
만약 인터넷이 안되는 환경이라면, https://developer.download.nvidia.com/compute/cuda/repos/ 에서 libnvdia-nscq를 다운로드 받아 업로드해야 합니다.
libnvdia-nscq 패키지 확인합니다.
배경색 변경rpm -qa | grep libnvidia-nscq libnvidia-nscq-535-535.183.06-1.x86_64rpm -qa | grep libnvidia-nscq libnvidia-nscq-535-535.183.06-1.x86_64코드블록. NSCQ library 패키지 확인 DNF에 CUDA Repository를 추가합니다.
배경색 변경dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo코드블록. DNF Repository 추가 NVDIA Driver 상태 초기화
배경색 변경dnf module reset nvidia-driverdnf module reset nvidia-driver코드블록. NVIDIA Driver DNF 모듈의 상태 초기화 배경색 변경Updating Subscription Management repositories. Last metadata expiration check: 0:03:15 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Disabling module profiles: nvidia-driver/default nvidia-driver/fm Resetting modules: nvidia-driver Transaction Summary ============================================= Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:03:15 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Disabling module profiles: nvidia-driver/default nvidia-driver/fm Resetting modules: nvidia-driver Transaction Summary ============================================= Is this ok [y/N]: y코드블록. NVIDIA Driver DNF 모듈의 상태 초기화 결과 예시 NVDIA Driver 모듈을 활성화합니다.
배경색 변경dnf module enable nvidia-driver:535-opendnf module enable nvidia-driver:535-open코드블록. NVDIA Driver 모듈 활성화 배경색 변경Updating Subscription Management repositories. Last metadata expiration check: 0:04:22 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Enabling module streams: nvidia-driver 535-open Transaction Summary ============================================= Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:04:22 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Enabling module streams: nvidia-driver 535-open Transaction Summary ============================================= Is this ok [y/N]: y코드블록. NVDIA Driver 모듈 활성화 결과 예시 libnvdia-nscq 모듈 목록을 확인합니다.
배경색 변경dnf list libnvidia-nscq-535 --showduplicatesdnf list libnvidia-nscq-535 --showduplicates코드블록. libnvdia-nscq 모듈 목록 확인 libnvdia-nscq를 설치합니다.
배경색 변경dnf install libnvidia-nscq-535-535.183.06-1dnf install libnvidia-nscq-535-535.183.06-1코드블록. libnvdia-nscq 설치 명령어
NVSwitch Device Monitoring API(NVSDM) Library 설치 (for RHEL)
참고
Blackwell 이후 GPU Architecture 에서는 NVSDM Library 설치가 필요합니다. NVDIA Driver 버전 560 이하는 NVSDM Library가 제공되지 않습니다.
NVSDM library 모듈 목록을 확인합니다.
배경색 변경dnf list libnvsdm --showduplicatesdnf list libnvsdm --showduplicates코드블록. NVSDM library 모듈 목록 확인 배경색 변경libnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages코드블록. NVSDM library 모듈 목록 확인 결과 예시 libnvsdm 설치합니다.
배경색 변경dnf install libnvsdm-580.105.08-1dnf install libnvsdm-580.105.08-1코드블록. NVSDM library 설치 배경색 변경Updating Subscription Management repositories. Last metadata expiration check: 0:08:18 ago on Wed 19 Nov 2025 01:05:28 AM EST. Dependencies resolved. ========================================================================= Package Architecture Version Repository Size ========================================================================= Installing: libnvsdm x86_64 580.105.08-1 cuda-rhel8-x86_64 675 k Installing dependencies: infiniband-diags x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 323 k libibumad x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 34 k Transaction Summary ========================================================================= Install 3 Packages Total download size: 1.0 M Installed size: 3.2 M Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:08:18 ago on Wed 19 Nov 2025 01:05:28 AM EST. Dependencies resolved. ========================================================================= Package Architecture Version Repository Size ========================================================================= Installing: libnvsdm x86_64 580.105.08-1 cuda-rhel8-x86_64 675 k Installing dependencies: infiniband-diags x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 323 k libibumad x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 34 k Transaction Summary ========================================================================= Install 3 Packages Total download size: 1.0 M Installed size: 3.2 M Is this ok [y/N]: y코드블록. NVSDM library 설치 명령어 결과 예시
NVIDIA DCGM 설치 (for RHEL)
아래의 순서에 따라 Node Exporter를 설치합니다.
DCGM(datacenter-gpu-manager) 설치 (for RHEL)
NVIDIA의 데이터센터 GPU Manager(DCGM) 도구의 특정 버전을 가리키며, 이는 NVIDIA 데이터센터 GPU를 관리하고 모니터링하기 위한 패키지입니다. 특히, cuda12는 이 관리 도구가 CUDA 12 버전에 맞춰 설치됨을 나타내며, datacenter-gpu-manager-4는 DCGM의 4.x 버전을 의미합니다. 이 도구는 GPU 상태 모니터링, 진단, 경고 시스템 및 전력/클럭 관리를 포함한 다양한 기능을 제공합니다.
- DNF에 CUDA Repository를 추가합니다.배경색 변경
dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo코드블록. DNF Repository 추가 - CUDA 버전을 확인합니다.배경색 변경
nvidia-smi | grep CUDAnvidia-smi | grep CUDA코드블록. CUDA 버전 확인 배경색 변경| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |코드블록. CUDA 버전 확인 결과 예시 배경색 변경CUDA_VERSION=12CUDA_VERSION=12코드블록. CUDA 버전 설정 명령어 - datacenter-gpu-manager-cuda 모듈 목록을 확인합니다.배경색 변경
dnf list datacenter-gpu-manager-4-cuda${CUDA_VERSION} --showduplicatesdnf list datacenter-gpu-manager-4-cuda${CUDA_VERSION} --showduplicates코드블록. datacenter-gpu-manager-cuda 모듈 목록 확인 배경색 변경Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:00:34 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-4-cuda12.x86_64 1:4.0.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-2 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.2-1 cuda-rhel8-x86_64Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:00:34 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-4-cuda12.x86_64 1:4.0.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-2 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.2-1 cuda-rhel8-x86_64코드블록. datacenter-gpu-manager-cuda 모듈 목록 확인 결과 예시 - datacenter-gpu-manager-cuda 설치합니다.배경색 변경
dnf install datacenter-gpu-manager-4-cuda${CUDA_VERSION}dnf install datacenter-gpu-manager-4-cuda${CUDA_VERSION}코드블록. datacenter-gpu-manager-cuda 설치 배경색 변경Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. =================================================================================================== Package Architecture Version Repository Size =================================================================================================== Installing: datacenter-gpu-manager-4-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 554 M Installing dependencies: datacenter-gpu-manager-4-core x86_64 1:4.4.2-1 cuda-rhel8-x86_64 9.9 M Installing weak dependencies: datacenter-gpu-manager-4-proprietary x86_64 1:4.4.2-1 cuda-rhel8-x86_64 5.3 M datacenter-gpu-manager-4-proprietary-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 289 M Transaction Summary ==================================================================================================== Install 4 Packages ... Is this ok [y/N]: yUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. =================================================================================================== Package Architecture Version Repository Size =================================================================================================== Installing: datacenter-gpu-manager-4-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 554 M Installing dependencies: datacenter-gpu-manager-4-core x86_64 1:4.4.2-1 cuda-rhel8-x86_64 9.9 M Installing weak dependencies: datacenter-gpu-manager-4-proprietary x86_64 1:4.4.2-1 cuda-rhel8-x86_64 5.3 M datacenter-gpu-manager-4-proprietary-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 289 M Transaction Summary ==================================================================================================== Install 4 Packages ... Is this ok [y/N]: y코드블록. datacenter-gpu-manager-cuda 설치 결과 예시
datacenter-gpu-manager-exporter 설치 (for RHEL)
NVIDIA Data Center GPU Manager(DCGM) 기반으로 GPU 사용량, 메모리 사용량, 온도, 전력 소비 등 다양한 GPU 메트릭을 수집하여 Prometheus와 같은 모니터링 시스템에서 사용할 수 있도록 노출하는 도구입니다.
DNF에 CUDA Repository를 추가합니다. (해당 명령어를 이미 수행했다면, 다음 단계로 넘어갑니다.)
배경색 변경dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo코드블록. DNF Repository 추가 CUDA 버전을 확인합니다. (해당 명령어를 이미 수행했다면, 다음 단계로 넘어갑니다.)
배경색 변경nvidia-smi | grep CUDAnvidia-smi | grep CUDA코드블록. CUDA 버전 확인 배경색 변경| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |코드블록. CUDA 버전 확인 결과 예시 배경색 변경CUDA_VERSION=12CUDA_VERSION=12코드블록. CUDA 버전 설정 명령어 datacenter-gpu-manager-exporter 모듈 목록을 확인합니다.
배경색 변경dnf list datacenter-gpu-manager-exporter --showduplicatesdnf list datacenter-gpu-manager-exporter --showduplicates코드블록. datacenter-gpu-manager-exporter 모듈 목록 확인 배경색 변경Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:02:11 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-exporter.x86_64 4.0.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.6.0-1 cuda-rhel8-x86_64Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:02:11 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-exporter.x86_64 4.0.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.6.0-1 cuda-rhel8-x86_64코드블록. datacenter-gpu-manager-exporter 모듈 목록 확인 결과 예시 datacenter-gpu-manager-cuda 설치합니다. dcgm-exporter 4.5.X 는 glibc 2.34 이상을 요구하지만, RHEL9 에서 glibc 2.34는 제공하므로 버전을 4.1.3-1 로 지정하여 설치합니다.
배경색 변경dnf install datacenter-gpu-manager-exporter-4.1.3-1dnf install datacenter-gpu-manager-exporter-4.1.3-1코드블록. datacenter-gpu-manager-cuda 설치 배경색 변경Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. ==================================================================================================== Package Architecture Version Repository Size ==================================================================================================== Installing: datacenter-gpu-manager-exporter x86_64 4.1.3-1 cuda-rhel8-x86_64 26 M ... Is this ok [y/N]: yUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. ==================================================================================================== Package Architecture Version Repository Size ==================================================================================================== Installing: datacenter-gpu-manager-exporter x86_64 4.1.3-1 cuda-rhel8-x86_64 26 M ... Is this ok [y/N]: y코드블록. datacenter-gpu-manager-cuda 설치 결과 예시 배경색 변경cat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartcat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStart코드블록. datacenter-gpu-manager-exporter 설정 파일 배경색 변경ExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csv코드블록. datacenter-gpu-manager-exporter 설정 파일 확인 결과 예시 DCGM Exporter 설치 시 제공되는 설정을 확인하고 필요한 메트릭은
#을 제거하고, 불필요한 메트릭은#을 추가합니다.배경색 변경vi /etc/dcgm-exporter/default-counters.csv ## Example ## ... DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active. ...vi /etc/dcgm-exporter/default-counters.csv ## Example ## ... DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active. ...코드블록. datacenter-gpu-manager-exporter metric 설정 예시
참고
GPU DCGM Exporter로 수집 가능한 지표와 설정 방법은 DCGM Exporter 지표를 참고하세요.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집은 제거하거나 비활성화해야 과도한 요금이 부과되지 않습니다.
DCGM 서비스 활성화 및 시작 (for RHEL)
nvdia-dcgm 서비스 활성화 및 시작합니다.
배경색 변경systemctl enable --now nvidia-dcgmsystemctl enable --now nvidia-dcgm코드블록. nvdia-dcgm 서비스 활성화 및 시작 명령어 nvdia-dcgm-exporter 서비스 활성화 및 시작합니다.
배경색 변경systemctl enable --now nvidia-dcgm-exportersystemctl enable --now nvidia-dcgm-exporter코드블록. nvdia-dcgm-exporter 서비스 활성화 및 시작 명령어
안내
DCGM Exporter 설정을 완료하였다면, ServiceWatch에서 제공하는 Open Telemetry Collector를 설치하여 SerivceWatch Agent 설정을 완료하셔야 합니다.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
자세한 내용은 ServiceWatch > ServiceWatch Agent 사용하기 참고하세요.
DCGM Exporter 지표
DCGM Exporter 주요 지표
DCGM Exporter에서 제공하는 지표 중, 주요 GPU 지표는 아래와 같습니다.
| Category | DCGM Field | Prometheus Metric Type | Summary | |
|---|---|---|---|---|
| Clocks | DCGM_FI_DEV_SM_CLOCK | gauge | SM clock frequency (in MHz) | |
| Clocks | DCGM_FI_DEV_MEM_CLOCK | gauge | Memory clock frequency (in MHz) | |
| Temperature | DCGM_FI_DEV_GPU_TEMP | gauge | GPU temperature (in C) | |
| Power | DCGM_FI_DEV_POWER_USAGE | gauge | Power draw (in W) | |
| Utilization | DCGM_FI_DEV_GPU_UTIL | gauge | GPU utilization (in %) | |
| Utilization | DCGM_FI_DEV_MEM_COPY_UTIL | gauge | Memory utilization (in %) | |
| Memory Usage | DCGM_FI_DEV_FB_FREE | gauge | Frame buffer memory free (in MiB) | |
| Memory Usage | DCGM_FI_DEV_FB_USED | gauge | Frame buffer memory used (in MiB) | |
| Nvlink | DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL(8 GPU only) | counter | Total number of NVLink bandwidth counters for all lanes |
표. DCGM Exporter가 제공하는 GPU 주요 지표
DCGM Exporter 지표 수집 설정
DCGM Exporter의 기본 설정되어 있는 지표는 DCGM Exporter > 기본 지표를 참고하세요.
- 기본 설정 외에 추가로 설정할 지표는 default-counters.csv에서
#를 제거합니다. - 기본 설정된 지표 중 수집을 원하지 않는 지표는
#를 추가하거나 해당 항목을 삭제합니다.
배경색 변경
# Format
# If line starts with a '#' it is considered a comment
# DCGM FIELD, Prometheus metric type, help message
# Clocks
DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz).
DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz).
# Temperature
DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C).
DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C).
# Power
DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W).
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ).
# PCIE
# DCGM_FI_PROF_PCIE_TX_BYTES, counter, Total number of bytes transmitted through PCIe TX via NVML.
# DCGM_FI_PROF_PCIE_RX_BYTES, counter, Total number of bytes received through PCIe RX via NVML.
...# Format
# If line starts with a '#' it is considered a comment
# DCGM FIELD, Prometheus metric type, help message
# Clocks
DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz).
DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz).
# Temperature
DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C).
DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C).
# Power
DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W).
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ).
# PCIE
# DCGM_FI_PROF_PCIE_TX_BYTES, counter, Total number of bytes transmitted through PCIe TX via NVML.
# DCGM_FI_PROF_PCIE_RX_BYTES, counter, Total number of bytes received through PCIe RX via NVML.
...3.3 - API Reference
API Reference
3.4 - CLI Reference
CLI Reference
3.5 - Release Note
GPU Server
2025.10.23
FEATURE
신규 기능 추가 및 ServiceWatch 서비스 연계 기능 제공- ServiceWatch 서비스 연계 제공
- ServiceWatch 서비스를 통해 데이터를 모니터링할 수 있습니다.
- GPU Server 생성 시 RHEL 이미지를 선택할 수 있습니다.
- Keypair 관리 기능이 추가되었습니다.
- Keypair를 생성하여 사용하거나 공개 키를 가져와 적용할 수 있습니다.
2025.07.01
FEATURE
GPU Server 기능 추가, Image 공유 방법 변경 및 GPU Server 사용 가이드 추가- GPU Server 기능 추가
- IP, Public NAT IP, Private NAT IP 설정 기능이 추가되었습니다.
- LLM 이용을 위한 LLM Endpoint가 제공됩니다.
- Account 간 Image 공유 방법이 변경되었습니다.
- 공유용 Image를 새로 생성하여 공유할 수 있습니다.
- GPU Server 사용 가이드 추가
- GPU Server에서 Multi-instance GPU 사용하기와 GPU Server에서 NVSwitch 사용하기 가이드를 추가하였습니다.
2025.04.28
FEATURE
OS 이미지 추가- GPU Server RHEL OS 및 GPU 드라이버 버전이 추가되었습니다.
2025.02.27
FEATURE
공통 기능 변경- GPU Server 기능 추가
- GPU Server에서 NAT 설정 기능이 추가되었습니다.
- Samsung Cloud Platform 공통 기능 변경
- Account, IAM 및 Service Home, 태그 등 공통 CX 변경 사항을 반영하였습니다.
2024.10.01
NEW
GPU Server 서비스 정식 버전 출시- GPU Server 서비스를 정식 출시하였습니다.
- CPU, GPU, 메모리 등 서버에서 제공하는 인프라 자원을 개별 구매할 필요 없이 필요한 시점에 필요한 만큼 할당 받아 사용할 수 있는 가상화 컴퓨팅 서비스를 출시하였습니다.
4 - Bare Metal Server
4.1 - Overview
서비스 개요
Bare Metal Server는 가상화 기술을 사용하지 않고 물리적으로 분리된 CPU, 메모리 등의 컴퓨팅 자원을 단독으로 할당 받아 사용할 수 있는 고성능 클라우드 컴퓨팅 서비스입니다. 다른 클라우드 사용자의 영향을 받지 않아 성능에 민감한 서비스를 안정적으로 운영할 수 있습니다.
특장점
쉽고 편리한 컴퓨팅 환경 구성: 웹 기반 Console을 통해 Bare Metal Server 프로비저닝부터 자원 관리, 비용 관리까지 손쉽게 사용 가능합니다. 표준 스펙(CPU, Memory, Disk)의 서버를 단독으로 할당받아 즉시 활용할 수 있습니다.
고성능 컴퓨팅 환경 제공: 실시간(Real-Time) 시스템, HPC(High Performance Computing), 과도한 I/O 사용이 요구되는 서버 등 고용량, 고성능을 요구하는 워크로드에 적합한 서버를 물리적으로 분리된 환경으로 제공합니다.
효율적인 서비스 제공: 최적의 서버 선정 및 자체 테스트를 통해 성능과 안정성을 보장합니다. 고객은 Samsung Cloud Platform에서 제공하는 다양한 스펙의 Bare Metal Server를 통해 고객 서비스 환경에 맞는 최적의 자원을 선택할 수 있습니다.
서비스 구성도
제공 기능
Bare Metal Server는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning) 및 관리: 웹 기반 Console을 통해 Bare Metal Server 프로비저닝부터 자원 관리, 비용 관리까지 손쉽게 사용 가능합니다.
- 다양한 유형의 서버타입 및 OS 이미지 제공: 표준 서버 타입의 CPU/Memory/Disk 자원을 제공하며, 다양한 OS 표준 이미지를 제공합니다.
- 스토리지 연결: OS 디스크 외 추가 연결 스토리지를 제공 합니다. Block Storage, File Storage, Object Storage 를 연결하여 사용할 수 있습니다.
- 네트워크 연결: Bare Metal Server의 일반 서브넷/IP 설정 및 Public NAT IP를 연결할 수 있습니다. 서버 간 통신을 위한 로컬 서브넷 연결을 제공합니다. 해당 작업은 상세 페이지에서 수정할 수 있습니다.
- 모니터링: 컴퓨팅 자원에 해당하는 CPU, Memory, Disk 등의 모니터링 정보를 Cloud Monitoring 을 통해 확인할 수 있습니다. Bare Metal Server 의 Cloud Monitoring 서비스를 사용하기 위해 Agent 를 설치해야 합니다. 안정적인 Bare Metal Server 서비스 이용을 위해 Agent를 반드시 설치해주세요. 자세한 내용은 Bare Metal Server 모니터링 지표 를 참고하세요.
- 백업 및 복구: Bare Metal Server 의 Filesystem 백업 및 복구를 Backup 서비스를 통해 사용할 수 있습니다.
- 효율적 비용 관리: 필요에 따라 손쉽게 서버를 생성/해지 할 수 있고 실 사용 시간 기반으로 과금되기 때문에 예측할 수 없는 다양한 상황에서 비용 효율적으로 사용할 수 있습니다.
- Local disk partition 생성 Local disk partition을 최대 10개까지 생성하여 활용할 수 있습니다.
- Terraform 제공: Terraform을 통한 IaC 환경을 제공합니다.
구성 요소
Bare Metal Server은 다양한 OS 표준 이미지와 표준 서버 타입을 제공하고 있습니다. 사용자는 구성하고자 하는 서비스 규모에 따라 이를 선택하여 사용할 수 있습니다.
OS 이미지 제공 버전
Bare Metal Server에서 지원하는 OS 이미지는 다음과 같습니다
| OS 이미지 버전 | EoS Date |
|---|---|
| Oracle Linux 9.6 | 2032-06-30 |
| RHEL 8.10 | 2029-05-31 |
| RHEL 9.4 | 2026-04-30 |
| RHEL 9.6 | 2027-05-31 |
| Rocky Linux 8.10 | 2029-05-31 |
| Rocky Linux 9.6 | 2025-11-30 |
| Ubuntu 22.04 | 2027-06-30 |
| Ubuntu 24.04 | 2029-06-30 |
| Windows 2019 | 2029-01-09 |
| Windows 2022 | 2031-10-14 |
표. Bare Metal Server 제공 OS 이미지 버전
서버 타입
Bare Metal Server에서 지원하는 서버 타입은 다음 형식과 같습니다. Bare Metal Server에서 지원하는 서버 타입에 대한 자세한 내용은 Bare Metal Server 서버 타입을 참고하세요.
s3v16m64_metal
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 세대 | s3 | 제공하는 서버 구분과 세대
|
| CPU vCore | v16 | vCore 개수
|
| Memory | m64 | 메모리 용량
|
표. Bare Metal Server 서버 타입
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
표. Bare Metal Server 선행 서비스
4.1.1 - 서버 타입
Bare Metal Server 서버 타입
Bare Metal Server는 사용 목적에 맞게 서버 타입을 제공합니다. 서버 타입은 CPU, Memory 등 다양한 조합으로 구성됩니다. Bare Metal Server를 생성할 때 선택하는 서버 타입에 따라 Bare Metal Server에 사용되는 서버가 결정됩니다. Bare Metal Server에서 실행하려는 애플리케이션의 사양에 따라 서버 타입을 선택해주세요.
Bare Metal Server에서 지원하는 서버 타입은 다음 형식과 같습니다.
s3v16m64_metal
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 세대 | s3 | 제공하는 서버 구분과 세대
|
| CPU vCore | v16 | vCore 개수
|
| Memory | m64 | 메모리 용량
|
표. Bare Metal Server 서버 타입 형식
s3/h3 서버 타입
Bare Metal Server s3 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 물리적으로 분리된 자원을 할당받아 사용하기 때문에 고성능 애플리케이션에 적합합니다.
또한 Bare Metal Server h3 서버 타입은 대용량 서버 사양으로 제공하며 대규모 데이터 처리를 위한 고성능 애플리케이션에 적합합니다.
- 총 5종의 vCPU 지원 (16, 32, 64, 96, 128vCore)
- Intel 4세대(Sapphire Rapids) Processor
- 최대 64개의 물리 코어, 128개의 vCPU 및 2,048 GB의 메모리를 지원
- 최대 1.92 TB의 Internal Disk 2개 제공
| 서버 타입 | 물리 CPU | vCPU | Memory | CPU Type | Internal Disk | ||
|---|---|---|---|---|---|---|---|
| s3v16m64_metal | 8 Core | 16 vCore | 64 GB | 최대 4.1GHz의 Intel Xeon Gold 6434 | 480 GB * 2EA | ||
| s3v16m128_metal | 8 Core | 16 vCore | 128 GB | 최대 4.1GHz의 Intel Xeon Gold 6434 | 480 GB * 2EA | ||
| s3v16m256_metal | 8 Core | 16 vCore | 256 GB | 최대 4.1GHz의 Intel Xeon Gold 6434 | 480 GB * 2EA | ||
| h3v32m128_metal | 16 Core | 32 vCore | 128 GB | 최대 4.0GHz의 Intel Xeon Gold 6444Y | 960 GB * 2EA | ||
| h3v32m256_metal | 16 Core | 32 vCore | 256 GB | 최대 4.0GHz의 Intel Xeon Gold 6444Y | 960 GB * 2EA | ||
| h3v32m512_metal | 16 Core | 32 vCore | 512 GB | 최대 4.0GHz의 Intel Xeon Gold 6444Y | 960 GB * 2EA | ||
| h3v64m256_metal | 32 Core | 64 vCore | 256 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA | ||
| h3v64m512_metal | 32 Core | 64 vCore | 512 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA | ||
| h3v64m1024_metal | 32 Core | 64 vCore | 1024 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA | ||
| h3v96m384_metal | 48 Core | 96 vCore | 384 GB | 최대 3.3GHz의 Intel Xeon Gold 6442Y | 1.92 TB * 2EA | ||
| h3v96m768_metal | 48 Core | 96 vCore | 768 GB | 최대 3.3GHz의 Intel Xeon Gold 6442Y | 1.92 TB * 2EA | ||
| h3v96m1536_metal | 48 Core | 96 vCore | 1536 GB | 최대 3.3GHz의 Intel Xeon Gold 6442Y | 1.92 TB * 2EA | ||
| h3v128m512_metal | 64 Core | 128 vCore | 512 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA | ||
| h3v128m1024_metal | 64 Core | 128 vCore | 1024 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA | ||
| h3v128m2048_metal | 64 Core | 128 vCore | 2048 GB | 최대 3.2GHz의 Intel Xeon Gold 6448H | 1.92 TB * 2EA |
표. Bare Metal Server 서버 타입 사양 > s3/h3 서버 타입
s2/h2 서버 타입
안내
s2/h2 서버 타입은 신규 신청 서비스가 종료되었습니다. 기존에 사용하시는 서비스에는 영향이 없습니다.
Bare Metal Server s2 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 물리적으로 분리된 자원을 할당받아 사용하기 때문에 고성능 애플리케이션에 적합합니다.
또한 Bare Metal Server h2 서버 타입은 대용량 서버 사양으로 제공하며 대규모 데이터 처리를 위한 고성능 애플리케이션에 적합합니다.
- 총 5종의 vCPU 지원 (16, 24, 32, 72, 96vCore)
- Intel 3세대(Ice Lake) Processor
- 최대 48개의 물리 코어, 96개의 vCPU 및 1,024 GB의 메모리를 지원
- 최대 1.92TB의 Internal Disk 2개 제공
| 서버 타입 | 물리 CPU | vCPU | Memory | CPU Type | Internal Disk | |
|---|---|---|---|---|---|---|
| s2v16m64_metal | 8 Core | 16 vCore | 64 GB | 최대 3.6GHz의 Intel Xeon Gold 6334 | 480 GB * 2EA | |
| s2v16m128_metal | 8 Core | 16 vCore | 128 GB | 최대 3.6GHz의 Intel Xeon Gold 6334 | 480 GB * 2EA | |
| s2v16m256_metal | 8 Core | 16 vCore | 256 GB | 최대 3.6GHz의 Intel Xeon Gold 6334 | 480 GB * 2EA | |
| h2v24m96_metal | 12 Core | 24 vCore | 96 GB | 최대 3.4GHz의 Intel Xeon Gold 5317 | 960 GB * 2EA | |
| h2v24m192_metal | 12 Core | 24 vCore | 192 GB | 최대 3.4GHz의 Intel Xeon Gold 5317 | 960 GB * 2EA | |
| h2v24m384_metal | 12 Core | 24 vCore | 384 GB | 최대 3.4GHz의 Intel Xeon Gold 5317 | 960 GB * 2EA | |
| h2v32m128_metal | 16 Core | 32 vCore | 128 GB | 최대 3.6GHz의 Intel Xeon Gold 6346 | 960 GB * 2EA | |
| h2v32m256_metal | 16 Core | 32 vCore | 256 GB | 최대 3.6GHz의 Intel Xeon Gold 6346 | 960 GB * 2EA | |
| h2v32m512_metal | 16 Core | 32 vCore | 512 GB | 최대 3.6GHz의 Intel Xeon Gold 6346 | 960 GB * 2EA | |
| h2v72m256_metal | 36 Core | 72 vCore | 256 GB | 최대 3.6GHz의 Intel Xeon Gold 6354 | 1.92 TB * 2EA | |
| h2v72m512_metal | 36 Core | 72 vCore | 512 GB | 최대 3.6GHz의 Intel Xeon Gold 6354 | 1.92 TB * 2EA | |
| h2v72m1024_metal | 36 Core | 72 vCore | 1024 GB | 최대 3.6GHz의 Intel Xeon Gold 6354 | 1.92 TB * 2EA | |
| h2v96m384_metal | 48 Core | 96 vCore | 384 GB | 최대 3.3GHz의 Intel Xeon Gold 6342 | 1.92 TB * 2EA | |
| h2v96m768_metal | 48 Core | 96 vCore | 768 GB | 최대 3.3GHz의 Intel Xeon Gold 6342 | 1.92 TB * 2EA |
표. Bare Metal Server 서버 타입 사양 > s2/h2 서버 타입
4.1.2 - 모니터링 지표
Bare Metal Server 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Bare Metal Server의 모니터링 지표를 나타냅니다.
안내
Bare Metal Server 는 사용자가 직접 가이드를 통해 Agent를 설치해야 모니터링 지표를 조회할 수 있습니다. 안정적인 Bare Metal Server 서비스를 사용하기에 앞서 Agent 를 반드시 설치해주세요. Agent 설치 방법 및 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Core Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| Core Usage [System] | 커널 공간에서 소요된 CPU 시간의 비율 | % |
| Core Usage [User] | 사용자 공간에서 소요된 CPU 시간의 비율 | % |
| CPU Cores | 호스트에 있는 CPU 코어의 수 | cnt |
| CPU Usage [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| CPU Usage [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage [User] | 사용자 영역에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage/Core [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 | % |
| CPU Usage/Core [Idle] | 유휴 상태로 소요된 CPU 시간의 비율 | % |
| CPU Usage/Core [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| CPU Usage/Core [System] | 커널에서 사용한 CPU 시간의 백분율 | % |
| CPU Usage/Core [User] | 사용자 영역에서 사용한 CPU 시간의 백분율 | % |
| Disk CPU Usage [IO Request] | 장치에 대한 입출력 요청이 실행된 CPU 시간의 비율 | % |
| Disk Queue Size [Avg] | 장치에 대해 실행된 요청의 평균 대기열 길이 | num |
| Disk Read Bytes | 장치에서 읽는 초당 바이트 수 | bytes |
| Disk Read Bytes [Delta Avg] | 개별 Disk들의 system.diskio.read.bytes_delta의 평균 | bytes |
| Disk Read Bytes [Delta Max] | 개별 Disk들의 system.diskio.read.bytes_delta의 최대 | bytes |
| Disk Read Bytes [Delta Min] | 개별 Disk들의 system.diskio.read.bytes_delta의 최소 | bytes |
| Disk Read Bytes [Delta Sum] | 개별 Disk들의 system.diskio.read.bytes_delta의 합 | bytes |
| Disk Read Bytes [Delta] | 개별 Disk의 system.diskio.read.bytes 값의 delta | bytes |
| Disk Read Bytes [Success] | 성공적으로 읽은 총 바이트 수 | bytes |
| Disk Read Requests | 1초동안 디스크 디바이스의 읽기 요청 수 | cnt |
| Disk Read Requests [Delta Avg] | 개별 Disk들의 system.diskio.read.count_delta의 평균 | cnt |
| Disk Read Requests [Delta Max] | 개별 Disk들의 system.diskio.read.count_delta의 최대 | cnt |
| Disk Read Requests [Delta Min] | 개별 Disk들의 system.diskio.read.count_delta의 최소 | cnt |
| Disk Read Requests [Delta Sum] | 개별 Disk들의 system.diskio.read.count_delta의 합 | cnt |
| Disk Read Requests [Success Delta] | 개별 Disk의 system.diskio.read.count의 delta | cnt |
| Disk Read Requests [Success] | 성공적으로 완료된 총 읽기 수 | cnt |
| Disk Request Size [Avg] | 장치에 대해 실행된 요청의 평균 크기(단위: 섹터) | num |
| Disk Service Time [Avg] | 장치에 대해 실행된 입력 요청의 평균 서비스 시간(밀리초) | ms |
| Disk Wait Time [Avg] | 지원할 장치에 대해 실행된 요청에 소요된 평균 시간 | ms |
| Disk Wait Time [Read] | 디스크 평균 대기 시간 | ms |
| Disk Wait Time [Write] | 디스크 평균 대기 시간 | ms |
| Disk Write Bytes [Delta Avg] | 개별 Disk들의 system.diskio.write.bytes_delta의 평균 | bytes |
| Disk Write Bytes [Delta Max] | 개별 Disk들의 system.diskio.write.bytes_delta의 최대 | bytes |
| Disk Write Bytes [Delta Min] | 개별 Disk들의 system.diskio.write.bytes_delta의 최소 | bytes |
| Disk Write Bytes [Delta Sum] | 개별 Disk들의 system.diskio.write.bytes_delta의 합 | bytes |
| Disk Write Bytes [Delta] | 개별 Disk의 system.diskio.write.bytes 값의 delta | bytes |
| Disk Write Bytes [Success] | 성공적으로 쓰여진 총 바이트 수 | bytes |
| Disk Write Requests | 1초동안 디스크 디바이스의 쓰기 요청 수 | cnt |
| Disk Write Requests [Delta Avg] | 개별 Disk들의 system.diskio.write.count_delta의 평균 | cnt |
| Disk Write Requests [Delta Max] | 개별 Disk들의 system.diskio.write.count_delta의 최대 | cnt |
| Disk Write Requests [Delta Min] | 개별 Disk들의 system.diskio.write.count_delta의 최소 | cnt |
| Disk Write Requests [Delta Sum] | 개별 Disk들의 system.diskio.write.count_delta의 합 | cnt |
| Disk Write Requests [Success Delta] | 개별 Disk의 system.diskio.write.count의 delta | cnt |
| Disk Write Requests [Success] | 성공적으로 완료된 총 쓰기 수 | cnt |
| Disk Writes Bytes | 장치에 쓰는 초당 바이트 수 | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang 체크 (정상:1, 비정상:0) | status |
| Filesystem Nodes | 파일 시스템의 총 파일 노드 수 | cnt |
| Filesystem Nodes [Free] | 파일 시스템의 총 가용 파일 노드 수 | cnt |
| Filesystem Size [Available] | 권한 없는 사용자가 사용할 수 있는 디스크 공간(바이트) | bytes |
| Filesystem Size [Free] | 사용 가능한 디스크 공간 (bytes) | bytes |
| Filesystem Size [Total] | 총 디스크 공간 (bytes) | bytes |
| Filesystem Usage | 사용한 디스크 공간 백분율 | % |
| Filesystem Usage [Avg] | 개별 filesystem.used.pct들의 평균 | % |
| Filesystem Usage [Inode] | inode 사용률 | % |
| Filesystem Usage [Max] | 개별 filesystem.used.pct 중에 max | % |
| Filesystem Usage [Min] | 개별 filesystem.used.pct 중에 min | % |
| Filesystem Usage [Total] | filesystem 사용량 전체 | % |
| Filesystem Used | 사용한 디스크 공간 (bytes) | bytes |
| Filesystem Used [Inode] | inode 사용량 | bytes |
| Memory Free | 사용 가능한 총 메모리 양 (bytes). 시스템 캐시 및 버퍼에서 사용하는 메모리는 포함하지 않음 | bytes |
| Memory Free [Actual] | 실제 사용가능한 memory (bytes). | bytes |
| Memory Free [Swap] | 사용가능한 swap memory. | bytes |
| Memory Total | 총 memory | bytes |
| Memory Total [Swap] | 총 swap memory. | bytes |
| Memory Usage | 사용한 memory의 백분율 | % |
| Memory Usage [Actual] | 실제 사용된 memory의 백분율 | % |
| Memory Usage [Cache Swap] | cache 된 swap 사용률 | % |
| Memory Usage [Swap] | 사용한 swap memory의 백분율 | % |
| Memory Used | 사용한 memory | bytes |
| Memory Used [Actual] | 실제 사용된 memory (bytes). 총 memory 에서 사용된 memory 를 뺀 값. | bytes |
| Memory Used [Swap] | 사용한 swap memory | bytes |
| Collisions | 네트워크 충돌 | cnt |
| Network In Bytes | 수신된 byte 수 | bytes |
| Network In Bytes [Delta Avg] | 개별 network들의 system.network.in.bytes_delta의 평균 | bytes |
| Network In Bytes [Delta Max] | 개별 network들의 system.network.in.bytes_delta의 최대 | bytes |
| Network In Bytes [Delta Min] | 개별 network들의 system.network.in.bytes_delta의 최소 | bytes |
| Network In Bytes [Delta Sum] | 개별 network 들의 system.network.in.bytes_delta의 합 | bytes |
| Network In Bytes [Delta] | 수신된 byte 수의 delta | bytes |
| Network In Dropped | 들어온 packet 중 삭제된 패킷의 수 | cnt |
| Network In Errors | 수신 중의 error 수 | cnt |
| Network In Packets | 수신된 packet 수 | cnt |
| Network In Packets [Delta Avg] | 개별 network들의 system.network.in.packets_delta의 평균 | cnt |
| Network In Packets [Delta Max] | 개별 network들의 system.network.in.packets_delta의 최대 | cnt |
| Network In Packets [Delta Min] | 개별 network들의 system.network.in.packets_delta의 최소 | cnt |
| Network In Packets [Delta Sum] | 개별 network들의 system.network.in.packets_delta의 합 | cnt |
| Network In Packets [Delta] | 수신된 packet 수의 delta | cnt |
| Network Out Bytes | 송신된 byte 수 | bytes |
| Network Out Bytes [Delta Avg] | 개별 network들의 system.network.out.bytes_delta의 평균 | bytes |
| Network Out Bytes [Delta Max] | 개별 network들의 system.network.out.bytes_delta의 최대 | bytes |
| Network Out Bytes [Delta Min] | 개별 network들의 system.network.out.bytes_delta의 최소 | bytes |
| Network Out Bytes [Delta Sum] | 개별 network들의 system.network.out.bytes_delta의 합 | bytes |
| Network Out Bytes [Delta] | 송신된 byte 수의 delta | bytes |
| Network Out Dropped | 나가는 packet 중 삭제된 packet 수 | cnt |
| Network Out Errors | 송신 중의 error 수 | cnt |
| Network Out Packets | 송신된 packet 수 | cnt |
| Network Out Packets [Delta Avg] | 개별 network들의 system.network.out.packets_delta의 평균 | cnt |
| Network Out Packets [Delta Max] | 개별 network들의 system.network.out.packets_delta의 최대 | cnt |
| Network Out Packets [Delta Min] | 개별 network들의 system.network.out.packets_delta의 최소 | cnt |
| Network Out Packets [Delta Sum] | 개별 network들의 system.network.out.packets_delta의 합 | cnt |
| Network Out Packets [Delta] | 송신된 packet 수의 delta | cnt |
| Open Connections [TCP] | 열려 있는 모든 TCP 연결 | cnt |
| Open Connections [UDP] | 열려 있는 모든 UDP 연결 | cnt |
| Port Usage | 접속가능한 port 사용률 | % |
| SYN Sent Sockets | SYN_SENT 상태의 소켓 수 (로컬에서 원격 접속시) | cnt |
| Kernel PID Max | kernel.pid_max 값 | cnt |
| Kernel Thread Max | kernel.threads-max 값 | cnt |
| Process CPU Usage | 마지막 업데이트 후 프로세스에서 소비한 CPU 시간의 백분율 | % |
| Process CPU Usage/Core | 마지막 이벤트 이후 프로세스에서 사용한 CPU 시간의 백분율 | % |
| Process Memory Usage | main memory (RAM)에서 프로세스가 차지하는 비율 | % |
| Process Memory Used | Resident Set 사이즈. 프로세스가 RAM 에서 차지한 메모리 양 | bytes |
| Process PID | 프로세스 pid | pid |
| Process PPID | 부모 프로세스의 pid | pid |
| Processes [Dead] | dead processes 수 | cnt |
| Processes [Idle] | idle processes 수 | cnt |
| Processes [Running] | running processes 수 | cnt |
| Processes [Sleeping] | sleeping processes 수 | cnt |
| Processes [Stopped] | stopped processes 수 | cnt |
| Processes [Total] | 총 processes 수 | cnt |
| Processes [Unknown] | 상태를 검색할 수 없거나 알 수 없는 processes 수 | cnt |
| Processes [Zombie] | 좀비 processes 수 | cnt |
| Running Process Usage | process 사용률 | % |
| Running Processes | running processes 수 | cnt |
| Running Thread Usage | thread 사용률 | % |
| Running Threads | running processes 에서 실행중인 thread 수 총합 | cnt |
| Context Switches | context switch 수 (초당) | cnt |
| Load/Core [1 min] | 마지막 1 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [15 min] | 마지막 15 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [5 min] | 마지막 5 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Multipaths [Active] | 외장 스토리지 연결 path status = active 카운트 | cnt |
| Multipaths [Failed] | 외장 스토리지 연결 path status = failed 카운트 | cnt |
| Multipaths [Faulty] | 외장 스토리지 연결 path status = faulty 카운트 | cnt |
| NTP Offset | last sample의 measured offset (NTP 서버와 로컬환경 간의 시간 차이) | num |
| Run Queue Length | 실행 대기열 길이 | num |
| Uptime | OS 가동시간(uptime). (milliseconds) | ms |
| Context Switchies | CPU context switch 수 (초당) | cnt |
| Disk Read Bytes [Sec] | windows logical 디스크에서 1초동안 읽어들인 바이트 수 | cnt |
| Disk Read Time [Avg] | 데이터 읽기 평균 시간 (초) | sec |
| Disk Transfer Time [Avg] | 디스크 average wait time | sec |
| Disk Usage | 디스크 사용률 | % |
| Disk Write Bytes [Sec] | windows logical 디스크에서 1초동안 쓰여진 바이트 수 | cnt |
| Disk Write Time [Avg] | 데이터 쓰기 평균 시간 (초) | sec |
| Pagingfile Usage | paging file 사용률 | % |
| Pool Used [Non Paged] | 커널 메모리 중 Nonpaged Pool 사용량 | bytes |
| Pool Used [Paged] | 커널 메모리 중 Paged Pool 사용량 | bytes |
| Process [Running] | 현재 동작 중인 프로세스 수 | cnt |
| Threads [Running] | 현재 동작 중인 thread 수 | cnt |
| Threads [Waiting] | 프로세서 시간을 기다리는 thread 수 | cnt |
표. Bare Metal Server 모니터링 지표(Agent 설치 시 조회 가능)
4.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Bare Metal Server의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Bare Metal Server 생성하기
Samsung Cloud Platform Console에서 Bare Metal Server 서비스를 생성하여 사용할 수 있습니다.
Bare Metal Server 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Bare Metal Server 생성 버튼을 클릭하세요. Bare Metal Server 생성 페이지로 이동합니다.
- Bare Metal Server 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 필수 제공하는 이미지 종류 선택 - RHEL
- Rocky Linux
- Ubuntu
- Windows
이미지 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
표. Bare Metal Server 이미지 및 버전 입력 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버 수 필수 동시 생성할 Bare Metal Server 서버 개수 - 숫자만 입력 가능하며 1~5 사이로 입력
서비스 유형 > 서버 타입 필수 Bare Metal Server 서버 타입 - 원하는 vCPU, Memory, Disk 사양을 선택
- Bare Metal Server에서 제공하는 서버 타입에 대한 자세한 내용은 Bare Metal Server 서버 타입을 참고
서비스 유형 > Planned Compute 필수 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기를 참고
자동화 계정 필수 Bare Metal Server 생성 이후 자동화 기능 제공을 위한 계정을 자동으로 생성 - 해당 계정은 시스템간 인터페이스 용도로만 사용
- Password는 암호화되어 시스템 외 접근이 불가능
- 계정을 삭제할 경우 네트워크 변경 및 일부 자동화 기능에 제약 발생
표. Bare Metal Server 서비스 정보 입력 항목 - 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 관리자 계정 필수 서버 접속 시 사용할 관리자 계정과 암호를 설정 - RHEL, Ubuntu OS는 root로 고정하여 제공
- Windows OS는 영문 소문자, 숫자를 사용하여 5~20자로 입력
Administrator사용 불가
서버명 필수 선택한 서버 수가 1인 경우에 Bare Metal Server 구별을 위한 이름 입력 - 입력한 서버 이름으로 hostname을 설정
- 영문 소문자로 시작하며, 소문자, 숫자,특수문자(
-)를 사용하여 3~15자 이내로 입력
- 특수문자(
-)로 끝나지 않음
서버명 Prefix 필수 선택한 서버 수가 2이상인 경우에 생성되는 각각의 Bare Metal Server 구별을 위한 Prefix 입력 - 사용자 입력값(prefix) + ‘
-###’ 형태로 자동 생성됨
- 영문 소문자로 시작하며, 소문자, 숫자, 특수문자(
-)를 사용하여 3 ~ 15자 이내로 입력
- 특수문자(
-)로 끝나지 않음
네트워크 설정 필수 Bare Metal Server가 설치될 네트워크를 설정 - 미리 생성한 VPC를 선택
- 일반 Subnet: 미리 생성한 일반 Subnet을 선택
- IP는 자동 생성과 사용자 입력을 선택할 수 있으며, 입력을 선택하면 사용자가 IP를 직접 입력
- NAT: 서버 수가 1대이고 VPC에 Internet Gateway가 연결되어 있어야 사용 가능
- 사용을 체크하면 NAT IP를 선택 가능
- NAT IP: NAT IP를 선택
- 선택할 NAT IP가 없는 경우에는 신규 생성 버튼을 클릭하여 Public IP를 생성
- 새로고침 버튼을 클릭하여, 생성한 Public IP를 확인하고 선택
- Public IP를 생성하면 Public IP 요금 기준에 따라 요금이 부과됨
- 로컬 Subnet(선택): 로컬 Subnet 사용을 선택
- 서비스를 생성하는데 필수 요소는 아님
- 미리 생성한 로컬 Subnet을 선택
- IP는 자동 생성과 사용자 입력 을 선택할 수 있으며, 입력을 선택하면 사용자가 IP를 직접 입력
표. Bare Metal Server 필수 정보 입력 항목
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
주의
Bare Metal Server의 트래픽 접근 통제를 위해 Firewall 등을 사용해주세요. Security Group은 제공하지 않습니다.
Bare Metal Server의 Firewall는 Bare Metal Server와 Virtual Server 간의 트래픽 제어를 위해서만 사용 가능합니다. Bare Metal Server의 Firewall을 사용하려면 다음의 절차를 따르세요.
- Bare Metal Server의 VPC를 분리: Bare Metal Server와 Virtual Server가 같은 VPC를 사용하지 않도록 분리하세요.
- Transit Gateway 생성: Transit Gateway를 생성하세요.
- Virtual Server의 VPC와 Bare Metal Server의 VPC 간의 연동은 Transit Gateway를 사용합니다.
- Bare Metal Server의 VPC에서 Transit Gateway 연동 생성 시, Bare Metal Server의 Firewall을 같이 생성하여야 합니다.
- Firewall Rule 등록: Bare Metal Server의 Firewall에서 Rule을 등록하세요.
- Bare Metal Server 생성 페이지에서 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Local disk partition 선택 로컬 디스크 파티션의 사용 여부를 설정 - 루트 파티션을 포함하여 최대 10개까지 생성 가능
- 전체 용량의 90%까지 사용 가능
- 사용을 체크한 후, 파티션 정보 설정 가능
- 루트 파티션 정보 설정
- 파티션 유형: flat, lvm 선택 가능
- 파티션명: 파티션 이름 입력
- 파티션 유형이 lvm인 경우에만 입력 가능
- 영문으로 시작하고 영문, 숫자와 특수문자(
-)를 포함하여 15자 이내 입력
- 파티션 용량: 50 GB 이상 입력
- Filesystem 유형: 사용 이미지에 따라 선택
- RHEL, Rocky Linux 인 경우: xfs, ext4
- Ubuntu인 경우: ext4, xfs, btrfs
- SLES인 경우: btrfs, xfs, ext4
- 마운트 포인트: 특수문자
/로 시작하고 영문, 숫자와 특수문자(-)를 포함하여 15자 이내 입력- Filesystem 유형이 swap인 경우, 입력 불가
- 사용 가능한 용량: 서버 선택 시 제공되는 기본 디스크 용량의 90%
- 파티션 용량 설정 시 자동으로 남은 용량을 계산하여 표시
- 파티션 디스크의 총량은 사용 가능 용량 초과 불가
- 추가 파티션 정보 설정
- 파티션 유형: flat, lvm 선택 가능
- 파티션명: 파티션 이름 입력
- 파티션 유형이 lvm인 경우에만 입력 가능
- 영문으로 시작하고 영문, 숫자와 특수문자(
-)를 포함하여 15자 이내 입력
- 파티션 용량: 1 GB 이상 입력
- Filesystem 유형: 사용 이미지에 따라 선택>
- RHEL, Rocky Linux인 경우: xfs, ext4, swap
- Ubuntu인 경우: ext4, xfs, btrfs, swap
- SLES인 경우: btrfs, xfs, ext4, swap
- 마운트 포인트: 특수문자
/로 시작하고 영문, 숫자와 특수문자(-)를 포함하여 15자 이내 입력- Filesystem 유형이 swap인 경우, 입력 불가
- 사용 가능한 용량: 서버 선택 시 제공되는 기본 디스크 용량의 90%
- 파티션 용량 설정 시 자동으로 남은 용량을 계산하여 표시
- 파티션 디스크의 총량은 사용 가능 용량 초과 불가
Placement Group 선택 같은 Placement group 에 소속된 서버들은 서로 다른 랙에 분산 배치됨 - 같은 Placement group에 소속된 서버 2대까지 분산 배치를 제공
- 서버 3대 이상의 분산 배치는 Placement group을 추가하여 사용
- 최초 생성 시에만 적용 가능하며, 생성 후 수정 불가
- Placement group에 소속된 마지막 서버를 해지하시면 해당 Placement group은 자동 삭제됨
Lock 선택 Lock을 사용하면 서버 해지/시작/중지를 실행할 수 없도록 실수로 인한 동작을 방지 Hyper Threading 선택 물리 코어수의 2배로 논리 코어수가 동작하도록 설정 - Hyper Threading 기능을 Off하려면 체크박스를 해제
- 서버 생성 후에는 변경 불가
Init Script 선택 서버 시작 시 실행할 스크립트 - Init Script는 이미지 종류에 따라 다르게 선택해야 함
- Windows의 경우: Batch Script 선택
- Linux의 경우: Shell Script
표. Bare Metal Server 추가 정보 입력 항목 - 요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Bare Metal Server 목록 페이지에서 생성한 자원을 확인하세요.
Bare Metal Server 상세 정보 확인하기
Bare Metal Server 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Bare Metal Server 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Bare Metal Server 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server 목록 페이지로 이동합니다.
- Bare Metal Server 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Bare Metal Server 상세 페이지로 이동합니다.
- Bare Metal Server 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 Bare Metal Server 상태 사용자가 생성한 Bare Metal Server의 상태 - Creating: 서버 생성 중인 상태
- Running:: 생성 완료되어 사용 가능한 상태
- Editing:: IP 변경중인 상태
- Unknown: 오류 상태
- Starting: 서버 시작 중인 상태
- Stopping: 서버 중지 중인 상태
- Stopped: 서버 중지 완료 상태
- Terminating: 해지 중인 상태
- Terminated: 해지 완료 상태
서버 제어 서버 상태를 변경할 수 있는 버튼 - 시작: 중지된 서버를 시작
- 중지: 가동 중인 서버를 중지
서비스 해지 서비스를 해지하는 버튼 표. Bare Metal Server 상태 정보 및 부가 기능
- Bare Metal Server 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Bare Metal Server 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 서버명 | 서버 이름 |
| 이미지/버전 | 서버의 OS 이미지와 버전 |
| 서버 타입 | vCPU, 메모리 정보 표시 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| Lock | Lock 사용/미사용 여부 표시
|
| Hyper Threading | Hyper Threading 사용/미사용 여부 표시
|
| 네트워크 | Bare Metal Server의 네트워크 정보
|
| 로컬 Subnet | Bare Metal Server의 로컬 Subnet 정보
|
| Block Storage | 서버에 연결된 Block Storage 정보
|
| Init Script | 서버 생성 시 입력한 Init Script 내용을 조회 |
표. Bare Metal Server 상세 정보 탭 항목
태그
Bare Metal Server 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Bare Metal Server 태그 탭 항목
작업 이력
Bare Metal Server 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Bare Metal Server 작업 이력 탭 상세 정보 항목
Bare Metal Server 자원 관리하기
생성된 Bare Metal Server 자원의 서버 제어 및 관리 기능이 필요한 경우에는 Bare Metal Server 목록 또는 Bare Metal Server 상세 페이지에서 작업을 수행할 수 있습니다.
Bare Metal Server 가동 제어하기
가동 중인 Bare Metal Server 서버의 시작, 중지, 재시작을 할 수 있습니다.
Bare Metal Server의 가동 제어를 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server 목록 페이지로 이동합니다.
- Bare Metal Server 목록 페이지에서 여러 대 서버를 선택한 후 표 상단의 시작, 중지 버튼을 통해 여러 대 서버를 동시에 제어할 수 있습니다.
- Bare Metal Server 상세 페이지에서도 서버의 시작과 중지를 작동할 수 있습니다.
- Bare Metal Server 목록 페이지에서 가동 제어할 자원을 클릭하여 Bare Metal Server 상세 페이지로 이동합니다.
- 서버 상태를 확인하고, 각 서버 관리 버튼을 통해 변경을 완료하세요.
- 시작: 중지된 서버를 시작합니다.
- 중지: 가동 중인 서버를 중지합니다.
안내
Bare Metal Server 중지 시, Server의 전원이 Off됩니다.
- 사용 중인 애플리케이션이나 스토리지 등에 영향을 줄 수 있으므로, OS에서 전원 종료 후 중지를 실행하시기를 권장합니다.
- OS에서 전원 종료한 후에 반드시 Console에서도 중지를 실행하세요.
가동 제어 불가
- Bare Metal Server 시작 요청 시 시작이 불가능한 경우는 다음을 참고하세요.
- Lock이 설정된 경우: Lock 설정을 미사용으로 변경한 후, 다시 시도하세요.
- Bare Metal Server의 상태가 Stopped 상태가 아닌 경우: Bare Metal Server를 상태를 Stopped 상태로 변경한 후, 다시 시도하세요.
- Bare Metal Server 중지 요청 시 중지가 불가능한 경우는 다음을 참고하세요.
- Lock이 설정된 경우: Lock 설정을 미사용으로 변경한 후, 다시 시도하세요.
- Bare Metal Server의 상태가 Running 상태가 아닌 경우: Bare Metal Server를 상태를 Running 상태로 변경한 후, 다시 시도하세요.
Block Storage 추가하기
Bare Metal Server에 Block Storage를 추가할 수 있습니다.
Block Storage를 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server 목록 페이지로 이동합니다.
- Bare Metal Server 목록 페이지에서 Block Storage를 추가할 서버를 클릭하세요. Bare Metal Server 상세 페이지로 이동합니다.
- Bare Metal Server 상세 페이지에서 Block Storage 항목에 있는 추가 버튼을 클릭하세요.
- Block Storage 추가를 확인하는 팝업창이 열리면 확인 버튼을 클릭하세요. Block Storage (BM) 생성 페이지로 이동합니다.
- Block Storage(BM) 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하여 Block Storage를 생성하세요.
- Block Storage(BM) 생성에 대한 자세한 내용은 Block Storage(BM) 생성하기를 참고하세요.
- Block Storage를 추가한 Bare Metal Server 상세 페이지로 이동하여 Block Storage가 추가되었는지 확인하세요.
주의
Block Storage를 생성한 후에는 용량을 증설할 수 없습니다.
Bare Metal Server 해지하기
사용하지 않는 Bare Metal Server를 해지하면 운영 비용을 절감할 수 있습니다. 단, Bare Metal Server를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 해지 후에는 데이터를 복구할 수 없으므로 주의해주세요.
주의
Block Storage(BM)가 연결된 서버를 1대씩 해지하면 서버는 해지되지만 연결된 Block Storage(BM)는 해지되지 않으니 Block Storage(BM)에서 직접 해지하세요.
Bare Metal Server를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server 목록 페이지로 이동합니다.
- Bare Metal Server 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 여러 자원을 선택하여 동시에 삭제할 수 있습니다.
- 해지할 자원의 Bare metal Server 상세 페이지에서 서비스 해지 버튼을 클릭하여 삭제할 수도 있습니다.
- 해지가 완료되면, Bare Metal Server 목록 페이지에서 자원이 해지되었는지 확인하세요.
해지 제약 사항
Bare Metal Server 해지 요청 시 해지가 불가한 경우에는 팝업창으로 안내합니다. 아래 케이스를 참고하세요.
해지 불가
Block Storage(BM)가 연결된 경우(서버 2대 이상 동시 해지): Block Storage(BM) 연결을 먼저 해지하세요.
- 해지 방법에 대한 자세한 내용은 Block Storage(BM) 해지하기를 참고하세요.
File Storage가 연결된 경우: File Storage 연결을 먼저 해지하세요.
- 해지 방법에 대한 자세한 내용은 File Storage 해지하기를 참고하세요.
Lock이 설정된 경우: Lock 설정을 미사용으로 변경한 후, 다시 시도하세요.
Backup Agent나 Load Balancer 연결 자원이 있는 경우: 해당 연결 자원의 연결을 먼저 해지하세요.
동일 Account에서 Bare Metal Server 자원 관리 작업이 진행 중인 경우: Bare Metal Server 자원 관리 작업이 완료된 후, 다시 시도하세요.
Bare Metal Server의 상태가 Running 또는 Stopped 상태가 아닌 경우: Bare Metal Server를 상태를 Running 또는 Stopped 상태로 변경한 후, 다시 시도하세요.
동시에 해지할 수 없는 서버가 포함된 경우: 해지 가능한 자원만 선택한 후, 다시 시도하세요.
로컬 Subnet 설정하기
Bare Metal Server 생성을 완료한 후 Bare Metal Server 상세 페이지에서 로컬 Subnet을 추가하는 경우, 사용자가 직접 로컬 Subnet의 네트워크 구성을 설정해야 합니다
첫 번째 연결(kr-west)
기존에 Bare Metal Server에 연결된 로컬 Subnet이 없으며, 첫번째 연결을 추가한 경우에는 아래 가이드대로 진행하세요.
주의
해당 가이드는 kr-west(한국 서부) 에서 해당 서버에 첫번째 로컬 Subnet 연결을 추가하는 경우 에 해당되는 가이드입니다.
- kr-south(한국 남부) 에 해당되는 가이드는 첫 번째 연결(kr-south) 쳅터를 참고하세요.
Linux - Ubuntu에서 Subnet 설정하기
Ubuntu 운영 체제에서 로컬 Subnet을 추가하고, 네트워크 설정을 진행하려면 다음 절차를 따르세요.
Bare Metal Server 상세 페이지에서 Interface Name을 확인하세요.
네트워크 설정 정보를 조회하세요.
배경색 변경[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1코드블록. 네트워크 설정 파일 조회 신규 Vlan을 추가한 후, Bonding 구성을 위한 IP를 설정하세요.
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. - ens4f1 // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: // SCP Console에서 확인한 Vlan ID를 20 대신 입력하세요. addresses: - 192.168.0.10/24 // SCP Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 20 // SCP Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. - ens4f1 // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: // SCP Console에서 확인한 Vlan ID를 20 대신 입력하세요. addresses: - 192.168.0.10/24 // SCP Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 20 // SCP Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500코드블록. IP 설정
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.
수정 사항을 시스템에 반영하세요.
배경색 변경# netplan apply# netplan apply코드블록. 수정사항 반영 인터페이스 상태를 조회하세요.
배경색 변경# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Linux – CentOS/Red Hat에서 Subnet 설정하기
CentOS/Red Hat 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
주의
Interface name을 잘못 설정할 경우에는 사용 중인 IP 정보가 삭제될 수 있으므로 주의하세요.
Bare Metal Server 상세 페이지에서 Interface Name을 확인하세요.
다음 command를 수정하여 수행하세요.
배경색 변경#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" BOND_IF_name1="ens2f1" // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. BOND_IF_name2="ens4f0" // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. # Delete Connection nmcli con down "Bond ${BOND_NAME}" nmcli con del "Bond ${BOND_NAME}" nmcli con down "System ${BOND_IF_name1}" nmcli con down "System ${BOND_IF_name2}" nmcli con del "System ${BOND_IF_name1}" nmcli con del "System ${BOND_IF_name2}" # Create Bonding nmcli con add con-name ${BOND_NAME} type bond ifname ${BOND_NAME} nmcli conn mod ${BOND_NAME} con-name "Bond ${BOND_NAME}" nmcli conn mod "Bond ${BOND_NAME}" ipv4.method disabled nmcli conn mod "Bond ${BOND_NAME}" ipv6.method ignore nmcli conn mod "Bond ${BOND_NAME}" connect.autoconnect yes nmcli conn mod "Bond ${BOND_NAME}" +bond.options mode=active-backup \ +bond.options xmit_hash_policy=layer2 \ +bond.options miimon=100 \ +bond.options num_grat_arp=1 \ +bond.options downdelay=0 \ +bond.options updelay=0 # Assign bond-slave nmcli conn add type bond-slave ifname ${BOND_IF_name1} con-name "${BOND_IF_name1}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name1} con-name "System ${BOND_IF_name1}" nmcli conn add type bond-slave ifname ${BOND_IF_name2} con-name "${BOND_IF_name2}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name2} con-name "System ${BOND_IF_name2}" # Connection UP nmcli conn up "Bond ${BOND_NAME}" # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" BOND_IF_name1="ens2f1" // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. BOND_IF_name2="ens4f0" // **Bare Metal Server 상세** 페이지에서 확인한 Interface Name을 입력하세요. # Delete Connection nmcli con down "Bond ${BOND_NAME}" nmcli con del "Bond ${BOND_NAME}" nmcli con down "System ${BOND_IF_name1}" nmcli con down "System ${BOND_IF_name2}" nmcli con del "System ${BOND_IF_name1}" nmcli con del "System ${BOND_IF_name2}" # Create Bonding nmcli con add con-name ${BOND_NAME} type bond ifname ${BOND_NAME} nmcli conn mod ${BOND_NAME} con-name "Bond ${BOND_NAME}" nmcli conn mod "Bond ${BOND_NAME}" ipv4.method disabled nmcli conn mod "Bond ${BOND_NAME}" ipv6.method ignore nmcli conn mod "Bond ${BOND_NAME}" connect.autoconnect yes nmcli conn mod "Bond ${BOND_NAME}" +bond.options mode=active-backup \ +bond.options xmit_hash_policy=layer2 \ +bond.options miimon=100 \ +bond.options num_grat_arp=1 \ +bond.options downdelay=0 \ +bond.options updelay=0 # Assign bond-slave nmcli conn add type bond-slave ifname ${BOND_IF_name1} con-name "${BOND_IF_name1}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name1} con-name "System ${BOND_IF_name1}" nmcli conn add type bond-slave ifname ${BOND_IF_name2} con-name "${BOND_IF_name2}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name2} con-name "System ${BOND_IF_name2}" # Connection UP nmcli conn up "Bond ${BOND_NAME}" # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}코드블록. IP 설정 스크립트 인터페이스 상태를 조회하세요.
배경색 변경# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Windows에서 Subnet 설정하기
Windows 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
Windows 시작 아이콘을 우클릭한 후, Windows PowerShell(관리자) 프로그램을 실행하세요.
Bare Metal Server 상세 페이지에서 Interface Name을 확인하세요.
Windows 실행 메뉴에서 ncpa.cpl을 실행하세요.

인터페이스의 활성화 여부를 확인한 후, 필요한 경우 활성화하세요.
- Bare Metal Server 상세 페이지에서 확인한 Interface Name을 활성화합니다.

- Bare Metal Server 상세 페이지에서 확인한 Interface Name을 활성화합니다.
Teaming을 생성하세요.
배경색 변경PS C:\> New-NetLbfoTeam –Name “bond-mgt” –TeamMembers ens2f1,ens4f1 PS C:\> Set-NetLbfoTeam –Name “bond-mgt” –LoadBalancingAlgorithm DynamicPS C:\> New-NetLbfoTeam –Name “bond-mgt” –TeamMembers ens2f1,ens4f1 PS C:\> Set-NetLbfoTeam –Name “bond-mgt” –LoadBalancingAlgorithm Dynamic코드블록. Teaming 생성 
신규 VLAN을 추가한 후, IP를 설정하세요.
- Bare Metal Server 상세 페이지에서 확인한 VLAN ID와 로컬 Subnet IP를 입력합니다.배경색 변경
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”코드블록. Windows IP 설정
- Bare Metal Server 상세 페이지에서 확인한 VLAN ID와 로컬 Subnet IP를 입력합니다.
Windows 실행 메뉴에서 ncpa.cpl을 실행하여 인터페이스 상태를 확인하세요.
첫 번째 연결(kr-south)
기존에 Bare Metal Server에 연결된 로컬 Subnet이 없으며, 첫번째 연결을 추가한 경우에는 아래 가이드대로 진행하세요.
주의
해당 가이드는 kr-south(한국 님부) 에서 해당 서버에 첫번째 로컬 Subnet 연결을 추가하는 경우 에 해당되는 가이드입니다.
- kr-west(한국 서부) 에 해당되는 가이드는 첫 번째 연결(kr-west) 쳅터를 참고하세요.
Linux - Ubuntu에서 Subnet 설정하기
Ubuntu 운영 체제에서 로컬 Subnet을 추가하고, 네트워크 설정을 진행하려면 다음 절차를 따르세요.
신규 Vlan을 추가한 후, IP를 설정하세요.
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Console에서 확인한 Vlan ID를 21 대신 입력하세요. addresses: - 192.168.0.20/24 // Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 21 // Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Console에서 확인한 Vlan ID를 21 대신 입력하세요. addresses: - 192.168.0.20/24 // Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 21 // Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500코드블록. Vlan 추가 및 IP 설정
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.
수정 사항을 시스템에 반영하세요.
배경색 변경# netplan apply# netplan apply코드블록. 수정 사항 반영 인터페이스 상태를 조회하세요.
배경색 변경# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Linux – CentOS/Red Hat에서 Subnet 설정하기
CentOS/Red Hat 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
주의
로컬 Subnet 추가 및 네트워크 설정을 잘못할 경우, 사용 중인 IP 정보가 삭제될 수 있으므로 주의하세요.
- 로컬 Subnet용 Bond Name을 확인하세요.배경색 변경
# sh /usr/local/bin/ip.sh# sh /usr/local/bin/ip.sh코드블록. Bonding 확인 - 다음 command를 수정하여 수행하세요.배경색 변경
#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" // 1. 에서 확인한 Bond Name 설정하세요. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" // 1. 에서 확인한 Bond Name 설정하세요. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}코드블록. IP 설정 스크립트 - 인터페이스 상태를 조회하세요.배경색 변경
# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Windows에서 Subnet 설정하기
Windows 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
Windows 시작 아이콘을 우클릭한 후, Windows PowerShell(관리자) 프로그램을 실행하세요.
로컬 Subnet용 Teaming 이름 을 확인하세요.
배경색 변경PS C:\> Get-NetAdapterPS C:\> Get-NetAdapter코드블록. Windows 인터페이스 확인 신규 Vlan을 추가한 후, IP를 설정하세요.
- 2번에서 확인한 Teaming 이름과, Console에서 확인한 Vlan ID 와 로컬 Subnet IP 를 입력합니다.배경색 변경
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”코드블록. Teaming 생성
- 2번에서 확인한 Teaming 이름과, Console에서 확인한 Vlan ID 와 로컬 Subnet IP 를 입력합니다.
Windows 실행 메뉴에서 ncpa.cpl을 실행하여 인터페이스 상태를 확인하세요.
두 번째 연결 추가(kr-west, kr-south)
Bare Metal Server에 연결된 로컬 Subnet이 있다면, 두 번째 추가 연결을 위한 가이드는 아래와 같습니다.
첫 번째 로컬 Subnet 연결 시에 이미 Bonding을 생성하였기 때문에, 두 번째 로컬 Subnet을 연결할 때는 Bonding을 생성하는 절차가 없습니다.
자세한 내용은 아래 내용을 참고하세요.
안내
kr-west, kr-south 에 공통으로 적용 가능한 가이드 입니다.
Linux - Ubuntu에서 Subnet 설정하기
Ubuntu 운영 체제에서 로컬 Subnet을 추가하고, 네트워크 설정을 진행하려면 다음 절차를 따르세요.
신규 Vlan을 추가한 후, IP를 설정하세요.
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Console에서 확인한 Vlan ID를 21 대신 입력하세요. addresses: - 192.168.0.20/24 // Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 21 // Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Console에서 확인한 Vlan ID를 21 대신 입력하세요. addresses: - 192.168.0.20/24 // Console에서 확인한 로컬 Subnet IP로 설정하세요. id: 21 // Console에서 확인한 Vlan ID로 설정하세요. link: bond-mgt mtu: 1500코드블록. Vlan 추가 및 IP 설정
- 예시 코드의 ID와 IP를 할당 받은 ID와 IP로 변경하세요.
수정 사항을 시스템에 반영하세요.
배경색 변경# netplan apply# netplan apply코드블록. 수정 사항 반영 인터페이스 상태를 조회하세요.
배경색 변경# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Linux – CentOS/Red Hat에서 Subnet 설정하기
CentOS/Red Hat 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
주의
로컬 Subnet 추가 및 네트워크 설정을 잘못할 경우, 사용 중인 IP 정보가 삭제될 수 있으므로 주의하세요.
- 로컬 Subnet용 Bond Name을 확인하세요.배경색 변경
# sh /usr/local/bin/ip.sh# sh /usr/local/bin/ip.sh코드블록. Bonding 확인 - 다음 command를 수정하여 수행하세요.배경색 변경
#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" // 1. 에서 확인한 Bond Name 설정하세요. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Console에서 확인한 로컬 Subnet IP를 설정하세요. VLAN_ID="7" // Console에서 확인한 Vlan ID를 설정하세요. BOND_NAME="bond-mgt" // 1. 에서 확인한 Bond Name 설정하세요. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}코드블록. IP 설정 스크립트 - 인터페이스 상태를 조회하세요.배경색 변경
# ip a 또는 # bash /usr/local/bin/ip.sh# ip a 또는 # bash /usr/local/bin/ip.sh코드블록. 인터페이스 조회
Windows에서 Subnet 설정하기
Windows 운영 체제에서 로컬 Subnet을 추가한 후, 네트워크를 설정하려면 다음 절차를 따르세요.
Windows 시작 아이콘을 우클릭한 후, Windows PowerShell(관리자) 프로그램을 실행하세요.
로컬 Subnet용 Teaming 이름 을 확인하세요.
배경색 변경PS C:\> Get-NetAdapterPS C:\> Get-NetAdapter코드블록. Windows 인터페이스 확인 신규 Vlan을 추가한 후, IP를 설정하세요.
- 2번에서 확인한 Teaming 이름과 Console에서 확인한 Vlan ID 와 로컬 Subnet IP 를 입력합니다.배경색 변경
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”코드블록. Teaming 생성
- 2번에서 확인한 Teaming 이름과 Console에서 확인한 Vlan ID 와 로컬 Subnet IP 를 입력합니다.
Windows 실행 메뉴에서 ncpa.cpl을 실행하여 인터페이스 상태를 확인하세요.
IP 변경하기
마이그레이션, 서버 교체 등을 진행을 위하여 IP를 변경할 수 있습니다.
주의
- IP 변경을 진행하면 더 이상 해당 IP로 통신할 수 없으며, 진행 중에는 IP 변경을 취소할 수 없습니다.
- Load Balancer 서비스 중인 서버일 경우, LB 서버 그룹에서 기존 IP를 삭제하고 변경된 IP를 LB 서버 그룹의 멤버로 직접 추가해야 합니다.
- Public NAT, Privat NAT를 사용 중인 서버는 IP 변경 후, Public NAT, Privat NAT의 사용을 해제하고 다시 설정해야 합니다.
- Public NAT, Privat NAT를 사용 중인 경우에는 먼저 Public NAT, Privat NAT의 사용을 해제하고 IP 변경을 완료한 후, 다시 설정하세요.
- Public NAT, Privat NAT의 사용 여부는 Bare Metal Server 상세 페이지에서 Public NAT IP, Privat NAT의 수정 버튼을 클릭하여 변경할 수 있습니다.
IP를 변경하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Bare Metal Server 메뉴를 클릭하세요. Bare Metal Server 목록 페이지로 이동합니다.
Bare Metal Server 목록 페이지에서 IP를 변경할 서버를 클릭하세요.Bare Metal Server 상세 페이지로 이동합니다.
Bare Metal Server 상세 페이지에서 IP 항목 옆의 수정 버튼을 클릭하세요.
IP 수정을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요. IP 변경 팝업창이 열립니다.
IP 변경 팝업창의 Step 1, Step 2, Step 3작업을 순서대로 진행하세요.
안내- IP를 변경할 때 변경할 IP의 서브넷에 따라 IP 변경 Step의 상세 설정 방법이 달라집니다. 반드시 다음 예시를 참조하여 Step별 작업을 진행하세요.
- 동일한 서브넷을 사용하는 IP로 변경하는 경우: 동일 Subnet의 IP로 변경하기 참고
- 다른 서브넷을 사용하는 IP로 변경하는 경우: 다른 Subnet의 IP로 변경하기 참고
- 각 진행 단계가 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시되고 다음 단계를 진행할 수 있습니다.
- Step 3의 최종 점검을 할 때에는 서버를 재시작한 후, 점검을 진행하는 것을 권장합니다.
- IP를 변경할 때 변경할 IP의 서브넷에 따라 IP 변경 Step의 상세 설정 방법이 달라집니다. 반드시 다음 예시를 참조하여 Step별 작업을 진행하세요.
모든 작업이 정상적으로 완료되었는지 확인한 후, 확인 버튼을 클릭하세요.
동일 Subnet의 IP로 변경하기
변경할 IP가 동일한 Subnet을 사용할 때 운영체제별 IP 설정 방법을 설명합니다.
Linux – centos/redhat 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.Step 1에서 할당 받은 IP를 입력하여 변경할 IP를 서버에 설정하세요.
- 다음 예시에서
172.17.34.150대신 할당 받은 IP를 입력하세요. - 변경하고자 하는 Interface의 정보를 서버에서 확인한 후, 다음 예시의
bond-srv.9대신 입력하세요.배경색 변경# nmcli con mod "Vlan bond-srv.9" ipv4.addresses 172.17.34.150/24 # nmcli con mod "Vlan bond-srv.9" ipv4.method manual # nmcli device reapply bond-srv.9# nmcli con mod "Vlan bond-srv.9" ipv4.addresses 172.17.34.150/24 # nmcli con mod "Vlan bond-srv.9" ipv4.method manual # nmcli device reapply bond-srv.9코드블록. 변경할 IP 설정 안내- IP를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
- 다음 예시에서
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
# bash /usr/local/bin/ip.sh# bash /usr/local/bin/ip.sh코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
Linux – Ubuntu 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.Step 1에서 할당 받은 IP를 입력하여 변경할 IP를 서버에 설정하세요.
- 다음 예시에서
172.17.34.150/24대신 할당 받은 IP를 입력하세요. - 변경하고자 하는 Interface의 정보를 서버에서 확인한 후, 다음 예시의
bond-srv.9대신 입력하세요.배경색 변경[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 # Step1에서 할당 받은 IP를 입력합니다. gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 # Step1에서 할당 받은 IP를 입력합니다. gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv코드블록. 변경할 IP 설정
- 다음 예시에서
Netplan apply 명령어를 사용하여 수정한 사항을 시스템에 반영하세요.
배경색 변경[root@localhost ~]# netplan apply[root@localhost ~]# netplan apply코드블록. Netplan apply 실행 안내- IP를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
# bash /usr/local/bin/ip.sh# bash /usr/local/bin/ip.sh코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
Windows 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.Windows 시작 아이콘을 우클릭한 후, **Windows PowerShell(관리자)**을 실행하세요.
Step 1에서 할당 받은 IP를 입력하여 변경할 IP를 서버에 설정하세요.
- 다음 예시에서
172.17.34.150대신 할당 받은 IP를 입력하세요.배경색 변경PS C:\> netsh interface ip set address "bond-srv.20" static 172.17.34.150 255.255.255.0PS C:\> netsh interface ip set address "bond-srv.20" static 172.17.34.150 255.255.255.0코드블록. 변경할 IP 설정 안내- IP를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
- 다음 예시에서
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
PS C:\> Get-NetIPAddress | Format-TablePS C:\> Get-NetIPAddress | Format-Table코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
다른 Subnet의 IP로 변경하기
변경할 IP가 다른 Subnet을 사용할 때 운영체제별 IP 설정 방법을 설명합니다.
Linux – centos/redhat 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.변경할 IP를 서버에 추가하기 위해 신규 Vlan을 추가하고, IP를 설정하세요.
- VLAN 추가: Step 1에서 확인한 Vlan ID의 인터페이스를 생성합니다. 다음 예시에서
20대신 할당 받은 ID를 입력하세요. - IP 설정: Step 1에서 할당 받은 IP를 입력합니다. 다음 예시에서
192.168.0.10/24대신 할당 받은 IP를 입력하세요.배경색 변경# nmcli conn add type vlan ifname "bond-srv.20" con-name "bond-srv.20" id 20 dev bond-srv # nmcli con mod bond-srv.20 con-name "Vlan bond-srv.20" # nmcli con mod "Vlan bond-srv.20" ipv4.addresses 192.168.0.10/24 # nmcli con mod "Vlan bond-srv.20" ipv4.method manual # nmcli con mod "Vlan bond-srv.20" ipv6.method "ignore" # nmcli con up "Vlan bond-srv.20"# nmcli conn add type vlan ifname "bond-srv.20" con-name "bond-srv.20" id 20 dev bond-srv # nmcli con mod bond-srv.20 con-name "Vlan bond-srv.20" # nmcli con mod "Vlan bond-srv.20" ipv4.addresses 192.168.0.10/24 # nmcli con mod "Vlan bond-srv.20" ipv4.method manual # nmcli con mod "Vlan bond-srv.20" ipv6.method "ignore" # nmcli con up "Vlan bond-srv.20"코드블록. 변경할 IP 설정
- VLAN 추가: Step 1에서 확인한 Vlan ID의 인터페이스를 생성합니다. 다음 예시에서
신규 Vlan에 Default Gateway를 설정하세요.
- Default gateway 설정: Step 1에서 할당 받은 Default gateway IP를 입력합니다. 다음 예시에서
192.168.0.1대신 할당 받은 Default gateway IP를 입력하세요.배경색 변경# nmcli con mod "Vlan bond-srv.20" ipv4.gateway 192.168.0.1 # nmcli device reapply bond-srv.20# nmcli con mod "Vlan bond-srv.20" ipv4.gateway 192.168.0.1 # nmcli device reapply bond-srv.20코드블록. 변경할 IP 설정 안내- 신규 Vlan에 Default Gateway를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
- Default gateway 설정: Step 1에서 할당 받은 Default gateway IP를 입력합니다. 다음 예시에서
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하세요.
기존(변경 전) 인터페이스의 Default Gateway IP를 확인한 후, 삭제하세요.
- 다음 예시에서
192.168.10.1대신 확인한 IP를 입력하세요.배경색 변경# ip route del default via 192.168.10.1# ip route del default via 192.168.10.1코드블록. 기존 인터페이스의 Default Gateway IP 삭제
- 다음 예시에서
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
# netstat –nr # bash /usr/local/bin/ip.sh# netstat –nr # bash /usr/local/bin/ip.sh코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
기존 IP의 Vlan 정보를 확인 후 서버에서 삭제하세요.
- 다음 예시에서
30대신 확인한 ID를 입력하세요.배경색 변경# nmcli con delete "Vlan bond-srv.30"# nmcli con delete "Vlan bond-srv.30"코드블록. 기존 IP의 Vlan 정보 삭제
- 다음 예시에서
모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
Linux – Ubuntu 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.변경할 IP를 서버에 추가하기 위해 신규 Vlan을 추가하고, IP 와 Default Gateway를 설정하세요.
- 다음 예시에서 Step 1 작업 내용 하단의 내용이 추가되는 부분입니다.
- 다음 예시에서 ID와 IP 대신 할당 받은 ID와 IP를 입력하세요.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv # Step1에서 확인한 Vlan ID의 인터페이스를 생성합니다. # Step1에서 할당 받은 IP를 입력합니다. # Step1에서 할당 받은 Default gateway IP를 입력합니다. bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv # Step1에서 확인한 Vlan ID의 인터페이스를 생성합니다. # Step1에서 할당 받은 IP를 입력합니다. # Step1에서 할당 받은 Default gateway IP를 입력합니다. bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500코드블록. 변경할 IP 설정
Netplan apply 명령어를 사용하여 수정한 사항을 시스템에 반영하세요.
배경색 변경[root@localhost ~]# netplan apply[root@localhost ~]# netplan apply코드블록. Netplan apply 실행 안내- 신규 Default Gateway를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하세요.
기존(변경 전) 인터페이스의 Default Gateway IP를 확인한 후, 삭제하세요.
- 다음 예시에서 해당 라인 삭제 행이 삭제하는 부분입니다.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 #해당 라인 삭제 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 #해당 라인 삭제 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500코드블록. 기존 인터페이스의 Default Gateway IP 삭제
- 다음 예시에서 해당 라인 삭제 행이 삭제하는 부분입니다.
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
# netstat –nr # bash /usr/local/bin/ip.sh# netstat –nr # bash /usr/local/bin/ip.sh코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
기존 IP를 삭제하세요.
- 다음 예시에서 해당 라인 삭제 행이 삭제하는 부분입니다.배경색 변경
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: #해당 라인 삭제 addresses: #해당 라인 삭제 - 172.17.34.150/24 #해당 라인 삭제 gateway4: 172.17.34.2 #해당 라인 삭제 id: 9 #해당 라인 삭제 link: bond-srv #해당 라인 삭제 mtu: 1500 #해당 라인 삭제 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... 생략 ethernets: ...................... 생략 vlans: bond-srv.9: #해당 라인 삭제 addresses: #해당 라인 삭제 - 172.17.34.150/24 #해당 라인 삭제 gateway4: 172.17.34.2 #해당 라인 삭제 id: 9 #해당 라인 삭제 link: bond-srv #해당 라인 삭제 mtu: 1500 #해당 라인 삭제 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1코드블록. 기존 IP 삭제
- 다음 예시에서 해당 라인 삭제 행이 삭제하는 부분입니다.
수정한 사항을 시스템에 적용하세요.
배경색 변경[root@localhost ~]# netplan apply [root@localhost ~]# ip link delete bond-srv.9 # VLAN 삭제 시 추가 수행[root@localhost ~]# netplan apply [root@localhost ~]# ip link delete bond-srv.9 # VLAN 삭제 시 추가 수행코드블록. 수정 사항 적용 모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고
최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.
- 최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
Windows 운영체제
Step 1
다음 절차를 따라 Step 1 작업을 진행하세요.
- 변경할 Subnet을 선택하세요.
- 변경할 IP를 입력하세요.
- IP 할당 신청 버튼을 클릭하세요.
- IP 변경 확인을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.주의Step 1의 IP 할당 신청을 진행하면 IP 변경을 취소하거나 복구할 수 없습니다.
- 작업이 정상적으로 완료되면 Vlan ID 확인, Default Gateway 확인 정보가 표시되며, 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 2
다음 절차를 따라 Step 2 작업을 진행하세요.
IP 변경 작업을 위해 IP 변경 대상 서버에 NAT IP로 접속하세요.
안내작업 중 통신이 불가능한 상황을 방지하기 위하여 동일 서브넷에 생성된 다른 Virtual Server 또는 Bare Metal Server를 경유하여 접속하는 것을 권장합니다.Windows 시작 아이콘을 우클릭한 후, **Windows PowerShell(관리자)**을 실행하세요.
VLAN을 추가하고 IP와 Default gateway를 설정하세요.
- VLAN 추가: Step 1에서 확인한 Vlan ID의 인터페이스를 생성합니다. 다음 예시에서
20대신 할당 받은 ID를 입력하세요. - IP 설정: Step 1에서 할당 받은 IP를 입력합니다. 다음 예시에서
46대신 Get-NetAdapter로 확인한 ifindex, 192.168.0.10 대신 할당 받은 IP를 입력하세요. - Default gateway 설정: Step 1에서 할당 받은 Default gateway IP를 입력합니다. 다음 예시에서
192.168.0.1대신 할당 받은 Default gateway IP를 입력하세요.배경색 변경PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-srv -VlanID 20 -Name bond-srv.20 -Confirm:$false PS C:\> Get-NetAdapter PS C:\> New-NetIPAddress -InterfaceIndex 46 -IPAddress 192.168.0.10 -PrefixLength 24 –defaultgateway 192.168.0.1PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-srv -VlanID 20 -Name bond-srv.20 -Confirm:$false PS C:\> Get-NetAdapter PS C:\> New-NetIPAddress -InterfaceIndex 46 -IPAddress 192.168.0.10 -PrefixLength 24 –defaultgateway 192.168.0.1코드블록. 변경할 IP 설정 안내- 신규 Default Gateway를 설정하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
- VLAN 추가: Step 1에서 확인한 Vlan ID의 인터페이스를 생성합니다. 다음 예시에서
모든 작업이 완료되면 IP 변경 팝업창에서 Step 2의 작업 완료 체크박스를 선택하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.안내
- Step 2의 작업 상태가 Completed로 변경된 후에도 터미널 접속에 이상이 있는 경우, 모든 서비스 > Management > Support Center의 문의하기 메뉴로 이동하여 문의하세요.
- 작업이 정상적으로 완료되면 우측 상단의 작업 상태가 Completed로 표시됩니다.
Step 3
다음 절차를 따라 Step 3 작업을 진행하세요.
IP 변경 대상 서버에 NAT IP로 접속하세요.
기존 Default Gateway IP를 확인하기 위하여 interface index (ifindex)를 실행하세요.
배경색 변경PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략코드블록. Get-NetAdapter 실행 배경색 변경PS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.35.0/24 172.17.35.1 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStore 30 0.0.0.0/0 172.17.34.1 1 ActiveStorePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.35.0/24 172.17.35.1 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStore 30 0.0.0.0/0 172.17.34.1 1 ActiveStore코드블록. -ifindex 실행 기존 Default Gateway IP를 삭제하세요.
- 다음 예시에서
30대신 Get-NetAdapter로 확인한 ifindex,172.17.34.1대신 확인한 IP를 입력하세요.배경색 변경PS C:\> Remove-NetRoute -ifIndex 30 -DestinationPrefix 0.0.0.0/0 -NextHop 172.17.34.1 -Confirm:$falsePS C:\> Remove-NetRoute -ifIndex 30 -DestinationPrefix 0.0.0.0/0 -NextHop 172.17.34.1 -Confirm:$false코드블록. Default Gateway IP 삭제 배경색 변경PS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStorePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStore코드블록. -ifindex 실행 안내- 기존 Default Gateway를 삭제하면 터미널 세션이 끊어집니다.
- Step 2 작업을 완료한 후, 작업 상태가 Completed로 변경되면 다시 터미널에 접속할 수 있습니다.
- 다음 예시에서
IP 변경 대상 서버에 NAT IP로 접속하여 통신 상태를 점검하세요.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.배경색 변경
PS C:\> netstat –nr | findstr Default PS C:\> Get-NetIPAddress | Format-TablePS C:\> netstat –nr | findstr Default PS C:\> Get-NetIPAddress | Format-Table코드블록. 통신 상태 점검 참고NAT IP는 변경되지 않습니다.
- 다음 명령어를 이용하여 변경 전의 설정 정보가 남아있는지, 정상적으로 변경되었는지 다시 한번 확인하세요. IP 변경 대상 서버에 정상적으로 접속되면 변경된 IP가 정상 통신 상태입니다.
Team 정보에서 기존 IP의 Vlan 정보를 확인하세요.
배경색 변경PS C:\> Get-NetLbfoTeam Name : bond_bond-srv Members : {ens6f1, ens3f1} TeamNics : {bond-srv, bond-srv.9} TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-iscsi Members : {ens6f0, ens3f0} TeamNics : bond-iscsi TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-backup Members : {ens2f0, ens4f1} TeamNics : bond-backup TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략PS C:\> Get-NetLbfoTeam Name : bond_bond-srv Members : {ens6f1, ens3f1} TeamNics : {bond-srv, bond-srv.9} TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-iscsi Members : {ens6f0, ens3f0} TeamNics : bond-iscsi TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-backup Members : {ens2f0, ens4f1} TeamNics : bond-backup TeamingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략코드블록. Get-NetLbfoTeam 실행 기존 IP의 Vlan 정보를 서버에서 삭제하세요.
- 다음 예시에서
30대신 확인한 ID를 입력하세요.배경색 변경PS C:\> Remove-NetLbfoTeamNic -Team bond_bond-srv -VlanID 30 -Confirm:$false PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략PS C:\> Remove-NetLbfoTeamNic -Team bond_bond-srv -VlanID 30 -Confirm:$false PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. 생략코드블록. Get-NetLbfoTeam 실행
- 다음 예시에서
모든 작업이 완료되면 서버를 재시작한 후, 최종 점검을 진행하세요.
참고최종 점검은 서버를 재시작한 후에 진행하는 것을 권장합니다.최종 점검 결과에 이상이 없으면 IP 변경 팝업창에서 Step 3의 작업 완료 체크박스를 선택하세요.
4.2.1 - ServiceWatch Agent 설치하기
사용자는 Bare Metal Server에 ServiceWatch Agent를 설치하여 사용자 정의 지표와 로그를 수집할 수 있습니다.
참고
ServiceWatch Agent를 통한 사용자 정의 지표/로그 수집은 현재 Samsung Cloud Platform For Enterprise에서만 사용 가능합니다. 이외 오퍼링에서도 향후 제공 예정입니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집 설정은 제거하거나 비활성화하기를 권장합니다.
ServiceWatch Agent
Bare Metal Server에 ServiceWatch의 사용자 정의 지표 및 로그 수집을 위해 설치해야 하는 Agent는 크게 2가지로 나눌 수 있습니다. Prometheus Exporter와 Open Telemetry Collector 입니다.
| 구분 | 상세 설명 | |
|---|---|---|
| Prometheus Exporter | 특정 애플리케이션이나 서비스의 메트릭을 Prometheus가 스크랩(scrape)할 수 있는 형식으로 제공
| |
| Open Telemetry Collector | 분산 시스템의 메트릭, 로그와 같은 텔레메트리 데이터를 수집하고, 처리(필터링, 샘플링 등)한 후, 여러 백엔드(예: Prometheus, Jaeger, Elasticsearch 등)로 내보내는 중앙 집중식 수집기 역할
|
표. Prometheus Exporter와 Open Telemetry Collector 설명
참고
ServiceWatch Agent 가이드는 Virtual Server와 동일하게 사용할 수 있습니다.
자세한 내용은 Virtual Server > ServiceWatch Agent를 참고하세요.
4.3 - API Reference
API Reference
4.4 - CLI Reference
CLI Reference
4.5 - Release Note
Bare Metal Server
2025.10.23
FEATURE
Local disk partition 기능 추가- Local disk partition 기능 제공
- 이제 Local disk partition을 최대 10개까지 생성하여 활용할 수 있습니다.
2025.07.01
FEATURE
신규 기능 추가 및 OS Image 추가 제공- Bare Metal Server 목록에서 여러 자원을 동시에 해지할 수 있습니다.
- 일반 Subnet의 IP를 변경할 수 있습니다.
- OS Image가 추가되었습니다.
- RHEL 8.10, Ubuntu 24.04
2025.02.27
FEATURE
Placement Group 기능 및 OS Image, 서버 타입 추가- Bare Metal Server 기능 추가
- 같은 Placement group에 소속된 서버들을 서로 다른 랙에 분산 배치합니다.
- OS Image 추가 제공(RHEL 9.4, Rocky Linux 8.6, Rocky Linux 9.4)
- Intel 4세대(Sapphire Rapids) Processor 기반의 3세대(s3/h3) 서버 타입 추가. 자세한 내용은 Bare Metal Server 서버 타입을 참고하세요.
- Samsung Cloud Platform 공통 기능 변경
- Account, IAM 및 Service Home, 태그 등 공통 CX 변경 사항을 반영하였습니다.
2024.10.01
NEW
Bare Metal Server 서비스 정식 버전 출시- Bare Metal Server 서비스를 정식 출시하였습니다.
- 물리 서버를 가상화 하지 않고 고객 단독으로 사용할 수 있는 Bare Metal Server 서비스를 출시하였습니다.
5 - Multi-node GPU Cluster
5.1 - Overview
서비스 개요
Multi-node GPU Cluster는 대규모의 고성능 AI 연산을 위해 물리 GPU 서버를 가상화 없이 제공하는 서비스입니다. GPU가 장착된 Bare Metal Server 2대 이상을 사용하여 다수의 GPU를 클러스터링 할 수 있으며, Samsung Cloud Platform의 고성능 스토리지 및 네트워킹 서비스과 연계하여 편리하게 GPU 서버를 사용할 수 있습니다.
제공 기능
Multi-node GPU Cluster는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning) 및 관리: 웹 기반 Console을 통해 GPU 8장을 장착한 표준 GPU Bare Metal 모델의 서버를 프로비저닝부터 자원 및 비용 관리까지 손쉽게 사용 가능합니다.
- 네트워크 연결: Bare Metal Server 2대 이상을 고속 인터커넥트를 통해 다수의 GPU를 클러스터링 할 수 있으며 GPU Direct RDMA (Remote Direct Memory Access) 환경을 구성함으로써 GPU 메모리간 데이터 IO를 직접 처리하여 AI/Machine Learning 고속 연산이 가능합니다.
- 스토리지 연결: OS 디스크 외 다양한 추가 연결 스토리지를 제공합니다. 고속 네트워크와 직접 연동한 고성능 SSD NAS File Storage와 Block Storage 및 Object Storage도 연계하여 사용 가능합니다.
- 네트워크 설정 관리: 서버의 서브넷/IP는 최초 생성시 설정된 값을 간편하게 변경 가능합니다. NAT IP는 필요에 따라 사용/해지를 설정할 수 있는 관리기능을 제공하고 있습니다.
- 모니터링: 컴퓨팅 자원에 해당하는 CPU, GPU, Memory, Disk 등의 모니터링 정보를 Cloud Monitoring 을 통해 확인할 수 있습니다. Multi-node GPU Cluster의 Cloud Monitoring 서비스를 사용하기 위해 Agent 를 설치해야 합니다. 안정적인 서비스 이용을 위해 Agent를 반드시 설치해주세요. 자세한 내용은 Multi-node GPU Cluster 모니터링 지표 를 참고하세요.
구성 요소
Multi-node GPU Cluster는 GPU를 Bare Metal Sever 유형으로 표준 이미지와 서버 타입을 제공하고 있습니다. NVSwitch 및 NVLink가 제공됩니다.
GPU(H100)
GPU(Graphic Processing Unit)는 많은 양의 데이터를 빠르게 처리하는 병렬 연산에 특화되어 있어 인공지능(AI), 데이터 분석 등 분야에서 대규모 병렬 연산 처리를 가능하게 합니다.
다음은 Multi-node GPU Cluster 서비스에서 제공하는 GPU Type의 사양입니다.
| 구분 | H100 Type |
|---|---|
| 상품 제공 방식 | Bare Metal |
| GPU Architecture | NNVIDIA Hopper |
| GPU Memory | 80GB |
| GPU Transistors | 80 billion 4N TSMC |
| GPU Tensor Performance(FP16기준) | 989.4 TFLOPs, 1,978.9 TFLOPs* |
| GPU Memory Bandwidth | 3,352 GB/sec HBM3 |
| GPU CUDA Cores | 16,896 Cores |
| GPU Tensor Cores | 528(4th Generation) |
| NVLink 성능 | NVLink 4 |
| 총 NVLink 대역폭 | 900 GB/s |
| NVLink Signaling Rate | 25 Gbps (x18) |
| NVSwitch 성능 | NVSwitch 3 |
| NVSwitch GPU간 대역폭 | 900 GB/s |
| 총 NVSwitch 집계 대역폭 | 7.2TB/s |
- With Sparsity
표. GPU Type 사양
OS 및 GPU 드라이버 버전
Multi-node GPU Cluster에서 지원하는 운영체제(OS)는 다음과 같습니다.
| OS | OS 버전 | GPU 드라이버버전 |
|---|---|---|
| Ubuntu | 22.04 | 535.86.10, 535.183.06 |
표. Multi-node GPU Cluster OS 및 GPU 드라이버 버전
서버 타입
Multi-node GPU Cluster에서 제공하는 서버 타입은 다음과 같습니다. Multi-node GPU Cluster에서 제공하는 서버 타입에 대한 자세한 설명은 Multi-node GPU Cluster 서버 타입을 참고하세요.
g2c96h8_metal
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 세대 | g2 | 제공하는 서버 세대
|
| CPU | c96 | Core 개수
|
| GPU | h8 | GPU 종류 및 수량
|
표. Multi-node GPU Cluster 서버 타입 형식
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
표. Multi-node GPU Cluster 선행 서비스
5.1.1 - 서버 타입
Multi-node GPU Cluster 서버 타입
Multi-node GPU Cluster는 제공하는 GPU Type에 따라 구분되며, GPU Node를 생성할 때 선택하는 서버 타입에 따라 Multi-node GPU Cluster에 사용되는 GPU가 결정됩니다. Multi-node GPU Cluster에서 실행하려는 애플리케이션의 사양에 따라 서버 타입을 선택해주세요.
Multi-node GPU Cluster에서 지원하는 서버 타입은 다음 형식과 같습니다.
g2c96h8_metal
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 세대 | g2 | 제공하는 서버 세대
|
| CPU | c96 | Core 개수
|
| GPU | h8 | GPU 종류 및 수량
|
표. Multi-node GPU Cluster 서버 타입 형식
g2 서버 타입
g2 서버 타입은 NVIDIA H100 Tensor Core GPU를 사용하는 GPU Bare Metal Serve로 대규모 고성능 AI 연산에 적합합니다.
- 최대 8개의 NVIDIA H100 Tensor Core GPU 제공
- GPU 당 16,896개의 CUDA 코어와 528 Tensor 코어 탑재
- 최대 96개의 vCPU 및 1,920 GB의 메모리를 지원
- 최대 100 Gbps의 네트워킹 속도
- 900GB/s GPU와 NVIDIA NVSwitch P2P 통신
| 서버 타입 | GPU | GPU Memory | CPU(Core) | Memory | Disk | GPU P2P |
|---|---|---|---|---|---|---|
| g2c96h8_metal | H100 | 640 GB | 96 vCore | 2 TB | SSD(OS) 960 GB * 2, NVMeSSD 3.84 TB * 4 | 900GB/s NVSwitch |
표. Multi-node GPU Cluster 서버 타입 사양 > H100 서버 타입
5.1.2 - 모니터링 지표
Multi-node GPU Cluster 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Multi-node GPU Cluster의 모니터링 지표를 나타냅니다.
안내
Multi-node GPU Cluster 는 사용자가 직접 가이드를 통해 Agent를 설치해야 모니터링 지표를 조회할 수 있습니다. 안정적인 서비스를 사용하기에 앞서 Agent 를 반드시 설치해주세요. Agent 설치 방법 및 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Multi-node GPU Cluster [Cluster]
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Memory Total [Basic] | 사용할 수 있는 메모리의 bytes | bytes |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Memory Swap In [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Swap Out [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Free [Basic] | 사용하지 않은 메모리의 bytes | bytes |
| Disk Read Bytes [Basic] | 읽기 bytes | bytes |
| Disk Read Requests [Basic] | 읽기 요청 수 | cnt |
| Disk Write Bytes [Basic] | 쓰기bytes | bytes |
| Disk Write Requests [Basic] | 쓰기 요청 수 | cnt |
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Instance State [Basic] | Instance 상태 | state |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Dropped [Basic] | 수신 패킷 드롭 | cnt |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Dropped [Basic] | 송신 패킷 드롭 | cnt |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. Multi-node GPU Cluster [Cluster] 모니터링 지표(기본 제공)
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Cluster GPU Count | Cluster 내 GPU Count SUM
| cnt |
| Cluster GPU Count In Use | Cluster 내 Job이 수행중인 GPU 수
| cnt |
| Cluster GPU Usage | Cluster 내 GPU Utilization AVG
| % |
| Cluster GPU Memory Usage [Avg] | Cluster 내 GPU Memory Uti. AVG
| % |
표. Multi-node GPU Cluster [Cluster] 추가 모니터링 지표(Agent 설치 필요)
Multi-node GPU Cluster [Node]
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Memory Total [Basic] | 사용할 수 있는 메모리의 bytes | bytes |
| Memory Used [Basic] | 현재 사용되는 메모리의 bytes | bytes |
| Memory Swap In [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Swap Out [Basic] | 교체된 메모리의 bytes | bytes |
| Memory Free [Basic] | 사용하지 않은 메모리의 bytes | bytes |
| Disk Read Bytes [Basic] | 읽기 bytes | bytes |
| Disk Read Requests [Basic] | 읽기 요청 수 | cnt |
| Disk Write Bytes [Basic] | 쓰기bytes | bytes |
| Disk Write Requests [Basic] | 쓰기 요청 수 | cnt |
| CPU Usage [Basic] | 1분간 평균 시스템 CPU 사용률 | % |
| Instance State [Basic] | Instance 상태 | state |
| Network In Bytes [Basic] | 수신 bytes | bytes |
| Network In Dropped [Basic] | 수신 패킷 드롭 | cnt |
| Network In Packets [Basic] | 수신 패킷 수 | cnt |
| Network Out Bytes [Basic] | 송신 bytes | bytes |
| Network Out Dropped [Basic] | 송신 패킷 드롭 | cnt |
| Network Out Packets [Basic] | 송신 패킷 수 | cnt |
표. Multi-node GPU Cluster [Node] 모니터링 지표(기본 제공)
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| GPU Count | gpu 개수 | cnt |
| GPU Temperature | gpu 온도 | ℃ |
| GPU Usage | utilization | % |
| GPU Usage [Avg] | GPU 전체 평균 사용율(%) | % |
| GPU Power Cap | GPU의 최대 전력 용량 | W |
| GPU Power Usage | GPU의 현재 전력 사용량 | W |
| GPU Memory Usage [Avg] | GPU Memory Uti. AVG | % |
| GPU Count in use | Node 내 Job이 수행중인 GPU 수 | cnt |
| Execution Status for nvidia-smi | nvidia-smi 명령어 실행결과 | status |
| Core Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기) | % |
| Core Usage [System] | 커널 공간에서 소요된 CPU 시간의 비율 | % |
| Core Usage [User] | 사용자 공간에서 소요된 CPU 시간의 비율 | % |
| CPU Cores | 호스트에 있는 CPU 코어의 수입니다. 정규화되지 않은 비율의 최대 값은 코어의 100%*입니다. 정규화되지 않은 비율에는 이 값이 이미 반영되어 있으며 최대 값은 코어의 100%*입니다. | cnt |
| CPU Usage [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 (core 4개 모두를 100%사용하는 경우 : 400%) | % |
| CPU Usage [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage [System] | 커널에서 사용한 CPU 시간의 백분율 (core 4개 모두를 100%사용하는 경우 : 400%) | % |
| CPU Usage [User] | 사용자 영역에서 사용한 CPU 시간의 백분율. (core 4개 모두를 100% 사용하는 경우 400%) | % |
| CPU Usage/Core [Active] | Idle 및 IOWait 상태 이외에 사용된 CPU 시간의 백분율 (core 수로 정규화된 값, core 4개 모두를 100% 사용하는 경우 100%) | % |
| CPU Usage/Core [Idle] | 유휴 상태로 소요된 CPU 시간의 비율입니다. | % |
| CPU Usage/Core [IO Wait] | 대기 상태로 소요된 CPU 시간의 비율(디스크 대기)입니다. | % |
| CPU Usage/Core [System] | 커널에서 사용한 CPU 시간의 백분율 (core 수로 정규화된 값, core 4개 모두를 100% 사용하는 경우 100%) | % |
| CPU Usage/Core [User] | 사용자 영역에서 사용한 CPU 시간의 백분율. (core 수로 정규화된 값, core 4개 모두를 100% 사용하는 경우 100%) | % |
| Disk CPU Usage [IO Request] | 장치에 대한 입출력 요청이 실행된 CPU 시간의 비율입니다(장치의 대역폭 활용도). 이 값이 100%에 가까우면 장치 포화 상태가 됩니다. | % |
| Disk Queue Size [Avg] | 장치에 대해 실행된 요청의 평균 대기열 길이입니다. | num |
| Disk Read Bytes | 장치에서 읽는 초당 바이트 수입니다. | bytes |
| Disk Read Bytes [Delta Avg] | 개별 disk들의 system.diskio.read.bytes_delta의 평균 | bytes |
| Disk Read Bytes [Delta Max] | 개별 disk들의 system.diskio.read.bytes_delta의 최대 | bytes |
| Disk Read Bytes [Delta Min] | 개별 disk들의 system.diskio.read.bytes_delta의 최소 | bytes |
| Disk Read Bytes [Delta Sum] | 개별 disk들의 system.diskio.read.bytes_delta의 합 | bytes |
| Disk Read Bytes [Delta] | 개별 disk의 system.diskio.read.bytes 값의 delta | bytes |
| Disk Read Bytes [Success] | 성공적으로 읽은 총 바이트 수. Linux에서는 섹터 크기를 512로 가정하고, 읽어들인 섹터 수에 512를 곱한 값 | bytes |
| Disk Read Requests | 1초동안 디스크 디바이스의 읽기 요청 수 | cnt |
| Disk Read Requests [Delta Avg] | 개별 disk들의 system.diskio.read.count_delta의 평균 | cnt |
| Disk Read Requests [Delta Max] | 개별 disk들의 system.diskio.read.count_delta의 최대 | cnt |
| Disk Read Requests [Delta Min] | 개별 disk들의 system.diskio.read.count_delta의 최소 | cnt |
| Disk Read Requests [Delta Sum] | 개별 disk들의 system.diskio.read.count_delta의 합 | cnt |
| Disk Read Requests [Success Delta] | 개별 disk의 system.diskio.read.count 의 delta | cnt |
| Disk Read Requests [Success] | 성공적으로 완료된 총 읽기 수 | cnt |
| Disk Request Size [Avg] | 장치에 대해 실행된 요청의 평균 크기(단위: 섹터)입니다. | num |
| Disk Service Time [Avg] | 장치에 대해 실행된 입력 요청의 평균 서비스 시간(밀리초)입니다. | ms |
| Disk Wait Time [Avg] | 지원할 장치에 대해 실행된 요청에 소요된 평균 시간입니다. | ms |
| Disk Wait Time [Read] | 디스크 평균 대기 시간 | ms |
| Disk Wait Time [Write] | 디스크 평균 대기 시간 | ms |
| Disk Write Bytes [Delta Avg] | 개별 disk들의 system.diskio.write.bytes_delta의 평균 | bytes |
| Disk Write Bytes [Delta Max] | 개별 disk들의 system.diskio.write.bytes_delta의 최대 | bytes |
| Disk Write Bytes [Delta Min] | 개별 disk들의 system.diskio.write.bytes_delta의 최소 | bytes |
| Disk Write Bytes [Delta Sum] | 개별 disk들의 system.diskio.write.bytes_delta의 합 | bytes |
| Disk Write Bytes [Delta] | 개별 disk의 system.diskio.write.bytes 값의 delta | bytes |
| Disk Write Bytes [Success] | 성공적으로 쓰여진 총 바이트 수. Linux에서는 섹터 크기를 512로 가정하고, 쓰여진 섹터 수에 512를 곱한 값 | bytes |
| Disk Write Requests | 1초동안 디스크 디바이스의 쓰기 요청 수 | cnt |
| Disk Write Requests [Delta Avg] | 개별 disk들의 system.diskio.write.count_delta의 평균 | cnt |
| Disk Write Requests [Delta Max] | 개별 disk들의 system.diskio.write.count_delta의 최대 | cnt |
| Disk Write Requests [Delta Min] | 개별 disk들의 system.diskio.write.count_delta의 최소 | cnt |
| Disk Write Requests [Delta Sum] | 개별 disk들의 system.diskio.write.count_delta의 합 | cnt |
| Disk Write Requests [Success Delta] | 개별 disk의 system.diskio.write.count 의 delta | cnt |
| Disk Write Requests [Success] | 성공적으로 완료된 총 쓰기 수 | cnt |
| Disk Writes Bytes | 장치에 쓰는 초당 바이트 수입니다. | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang 체크 (정상:1, 비정상:0) | status |
| Filesystem Nodes | 파일 시스템의 총 파일 노드 수입니다. | cnt |
| Filesystem Nodes [Free] | 파일 시스템의 총 가용 파일 노드 수입니다. | cnt |
| Filesystem Size [Available] | 권한 없는 사용자가 사용할 수 있는 디스크 공간(바이트)입니다. | bytes |
| Filesystem Size [Free] | 사용 가능한 디스크 공간 (bytes) | bytes |
| Filesystem Size [Total] | 총 디스크 공간 (bytes) | bytes |
| Filesystem Usage | 사용한 디스크 공간 백분율 | % |
| Filesystem Usage [Avg] | 개별 filesystem.used.pct들의 평균 | % |
| Filesystem Usage [Inode] | inode 사용률 | % |
| Filesystem Usage [Max] | 개별 filesystem.used.pct 중에 max | % |
| Filesystem Usage [Min] | 개별 filesystem.used.pct 중에 min | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | 사용한 디스크 공간 (bytes) | bytes |
| Filesystem Used [Inode] | inode 사용량 | bytes |
| Memory Free | 사용 가능한 총 메모리 양 (bytes). 시스템 캐시 및 버퍼에서 사용하는 메모리는 포함하지 않음 (system.memory.actual.free 참조). | bytes |
| Memory Free [Actual] | 실제 사용가능한 memory (bytes). OS 에 따라 계산방식이 다르며, Linux 에서는 /proc/ meminfo 에서 MemAvailable 이거나 meminfo 를 사용할 수 없는 경우에는 사용 가능한 메모리와 캐시 및 버퍼에서 계산함. OSX 에서는 사용가능한 메모리와 비활성 메모리의 합계. Windows 에서는 system.memory.free 와 같은 값. | bytes |
| Memory Free [Swap] | 사용가능한 swap memory. | bytes |
| Memory Total | 총 memory | bytes |
| Memory Total [Swap] | 총 swap memory. | bytes |
| Memory Usage | 사용한 memory의 백분율
| % |
| Memory Usage [Actual] | 실제 사용된 memory의 백분율
| % |
| Memory Usage [Cache Swap] | cache 된 swap 사용률 | % |
| Memory Usage [Swap] | 사용한 swap memory의 백분율 | % |
| Memory Used | 사용한 memory | bytes |
| Memory Used [Actual] | 실제 사용된 memory (bytes). 총 memory 에서 사용된 memory 를 뺀 값. 사용가능 메모리는 OS 마다 다르게 계산됨 (system.actual.free 참조) | bytes |
| Memory Used [Swap] | 사용한 swap memory. | bytes |
| Collisions | 네트워크 충돌 | cnt |
| Network In Bytes | 수신된 byte 수 | bytes |
| Network In Bytes [Delta Avg] | 개별 network들의 system.network.in.bytes_delta의 평균 | bytes |
| Network In Bytes [Delta Max] | 개별 network들의 system.network.in.bytes_delta의 최대 | bytes |
| Network In Bytes [Delta Min] | 개별 network들의 system.network.in.bytes_delta의 최소 | bytes |
| Network In Bytes [Delta Sum] | 개별 network 들의 system.network.in.bytes_delta의 합 | bytes |
| Network In Bytes [Delta] | 수신된 byte 수의 delta | bytes |
| Network In Dropped | 들어온 packet 중 삭제된 패킷의 수 | cnt |
| Network In Errors | 수신 중의 error 수 | cnt |
| Network In Packets | 수신된 packet 수 | cnt |
| Network In Packets [Delta Avg] | 개별 network들의 system.network.in.packets_delta의 평균 | cnt |
| Network In Packets [Delta Max] | 개별 network들의 system.network.in.packets_delta의 최대 | cnt |
| Network In Packets [Delta Min] | 개별 network들의 system.network.in.packets_delta의 최소 | cnt |
| Network In Packets [Delta Sum] | 개별 network들의 system.network.in.packets_delta의 합 | cnt |
| Network In Packets [Delta] | 수신된 packet 수의 delta | cnt |
| Network Out Bytes | 송신된 byte 수 | bytes |
| Network Out Bytes [Delta Avg] | 개별 network들의 system.network.out.bytes_delta의 평균 | bytes |
| Network Out Bytes [Delta Max] | 개별 network들의 system.network.out.bytes_delta의 최대 | bytes |
| Network Out Bytes [Delta Min] | 개별 network들의 system.network.out.bytes_delta의 최소 | bytes |
| Network Out Bytes [Delta Sum] | 개별 network들의 system.network.out.bytes_delta의 합 | bytes |
| Network Out Bytes [Delta] | 송신된 byte 수의 delta | bytes |
| Network Out Dropped | 나가는 packet 중 삭제된 packet 수. 이 값은 운영체제에서 보고되지 않으므로 Darwin 과 BSD에서 항상 0임 | cnt |
| Network Out Errors | 송신 중의 error 수 | cnt |
| Network Out Packets | 송신된 packet 수 | cnt |
| Network Out Packets [Delta Avg] | 개별 network들의 system.network.out.packets_delta의 평균 | cnt |
| Network Out Packets [Delta Max] | 개별 network들의 system.network.out.packets_delta의 최대 | cnt |
| Network Out Packets [Delta Min] | 개별 network들의 system.network.out.packets_delta의 최소 | cnt |
| Network Out Packets [Delta Sum] | 개별 network들의 system.network.out.packets_delta의 합 | cnt |
| Network Out Packets [Delta] | 송신된 packet 수의 delta | cnt |
| Open Connections [TCP] | 열려 있는 모든 TCP 연결 | cnt |
| Open Connections [UDP] | 열려 있는 모든 UDP 연결 | cnt |
| Port Usage | 접속가능한 port 사용률 | % |
| SYN Sent Sockets | SYN_SENT 상태의 소켓 수 (로컬에서 원격 접속시) | cnt |
| Kernel PID Max | kernel.pid_max 값 | cnt |
| Kernel Thread Max | kernel.threads-max 값 | cnt |
| Process CPU Usage | 마지막 업데이트 후 프로세스에서 소비한 CPU 시간의 백분율. 이 값은 Unix 시스템에서 top 명령으로 표시되는 프로세스의 %CPU 값과 유사 | % |
| Process CPU Usage/Core | 마지막 이벤트 이후 프로세스에서 사용한 CPU 시간의 백분율. 코어 수로 정규화되며 0~100% 사이의 값 | % |
| Process Memory Usage | main memory (RAM) 에서 프로세스가 차지하는 비율 | % |
| Process Memory Used | Resident Set 사이즈. 프로세스가 RAM 에서 차지한 메모리 양. Windows 에서는 current working set 사이즈 | bytes |
| Process PID | 프로세스 pid | PID |
| Process PPID | 부모 프로세스의 pid | PID |
| Processes [Dead] | dead processes 수 | cnt |
| Processes [Idle] | idle processes 수 | cnt |
| Processes [Running] | running processes 수 | cnt |
| Processes [Sleeping] | sleeping processes 수 | cnt |
| Processes [Stopped] | stopped processes 수 | cnt |
| Processes [Total] | 총 processes 수 | cnt |
| Processes [Unknown] | 상태를 검색할 수 없거나 알 수 없는 processes 수 | cnt |
| Processes [Zombie] | 좀비 processes 수 | cnt |
| Running Process Usage | process 사용률 | % |
| Running Processes | running processes 수 | cnt |
| Running Thread Usage | thread 사용률 | % |
| Running Threads | running processes 에서 실행중인 thread 수 총합 | cnt |
| Instance Status | 인스턴스 상태 | state |
| Context Switches | context switch 수 (초당) | cnt |
| Load/Core [1 min] | 마지막 1 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [15 min] | 마지막 15 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Load/Core [5 min] | 마지막 5 분 동안의 로드를 코어 수로 나눈 값 | cnt |
| Multipaths [Active] | 외장 스토리지 연결 path status = active 카운트 | cnt |
| Multipaths [Failed] | 외장 스토리지 연결 path status = failed 카운트 | cnt |
| Multipaths [Faulty] | 외장 스토리지 연결 path status = faulty 카운트 | cnt |
| NTP Offset | last sample의 measured offset (NTP 서버와 로컬환경 간의 시간 차이) | num |
| Run Queue Length | 실행 대기열 길이 | num |
| Uptime | OS 가동시간(uptime). (milliseconds) | ms |
| Context Switchies | CPU context switch 수 (초당) | cnt |
| Disk Read Bytes [Sec] | windows logical 디스크에서 1초동안 읽어들인 바이트 수 | cnt |
| Disk Read Time [Avg] | 데이터 읽기 평균 시간 (초) | sec |
| Disk Transfer Time [Avg] | 디스크 average wait time | sec |
| Disk Usage | 디스크 사용률 | % |
| Disk Write Bytes [Sec] | windows logical 디스크에서 1초동안 쓰여진 바이트 수 | cnt |
| Disk Write Time [Avg] | 데이터 쓰기 평균 시간 (초) | sec |
| Pagingfile Usage | paging file 사용률 | % |
| Pool Used [Non Paged] | 커널 메모리 중 Nonpaged Pool 사용량 | bytes |
| Pool Used [Paged] | 커널 메모리 중 Paged Pool 사용량 | bytes |
| Process [Running] | 현재 동작 중인 프로세스 수 | cnt |
| Threads [Running] | 현재 동작 중인 thread 수 | cnt |
| Threads [Waiting] | 프로세서 시간을 기다리는 thread 수 | cnt |
표. Multi-node GPU Cluster [Node] 추가 모니터링 지표 (Agent 설치 필요)
5.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Multi-node GPU Cluster 서비스의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Multi-node GPU Cluster 시작하기
Samsung Cloud Platform Console에서 Multi-node GPU Cluster 서비스를 생성하여 사용할 수 있습니다.
본 서비스는 GPU Node와 Cluster Fabric 서비스로 구성되어 있습니다.
GPU Node 생성하기
Multi-node GPU Cluster 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Multi-node GPU Cluster 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Node 생성 버튼을 클릭하세요. GPU Node생성 페이지로 이동합니다.
- GPU Node 생성 페이지에서 서비스 생성에 필요한 정보를 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 필수 제공하는 이미지 종류 선택 - Ubuntu
이미지 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
표. GPU Node 이미지 및 버전 선택 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버 수 필수 동시 생성할 GPU Node 서버 개수 - 숫자만 입력 가능하며 최소 생성 서버수는 2대 입니다.
- 최초 구성 시에만 2대 이상으로 생성하며 증설은 1대씩 가능합니다.
서비스 유형 > 서버 타입 필수 GPU Node 서버 타입 - 원하는 CPU, Memory, GPU, Disk 사양을 선택
- GPU Node에서 제공하는 서버 타입에 대한 자세한 내용은 Multi-node GPU Cluster 서버 타입을 참고
서비스 유형 > Planned Compute 필수 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기를 참고
표. GPU Node 서비스 정보 입력 항목 - 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 관리자 계정 필수 서버 접속 시 사용할 관리자 계정과 암호를 설정 - Ubuntu OS는 root로 고정하여 제공
서버명 Prefix 필수 선택한 서버 수가 2이상인 경우에 생성되는 각각의 GPU Node 구별을 위한 Prefix 입력 - 사용자 입력값(prefix) + ‘
-###’ 형태로 자동 생성됨
- 영문 소문자로 시작하며, 소문자, 숫자, 특수문자(
-)를 사용하여 3~11자 이내로 입력
- 특수문자(
-)로 끝나지 않음
네트워크 설정 필수 GPU Node가 설치될 네트워크를 설정 - VPC명:미리 생성한 VPC를 선택
- 일반 Subnet명: 미리 생성한 일반 Subnet을 선택
- IP는 자동 생성과 사용자 입력을 선택할 수 있으며, 입력을 선택하면 사용자가 IP를 직접 입력
- NAT: 서버 수가 1대이고 VPC에 Internet Gateway가 연결되어 있어야 사용 가능합니다. 사용을 체크하면 NAT IP를 선택할 수 있습니다.(최초 생성시 서버 수 2대 이상으로만 생성 되니 자원 상세 페이지에서 수정)
- NAT IP: NAT IP를 선택
- 선택할 NAT IP가 없는 경우, 신규 생성 버튼을 클릭하여 Public IP를 생성
- 새로고침 버튼을 클릭하여, 생성한 Public IP를 확인하고 선택
- Public IP를 생성하면 Public IP 요금 기준에 따라 요금이 부과됨
표. GPU Node 필수 정보 입력 항목 - Cluster 선택 영역에서 Cluster Fabric을 생성 또는 선택하세요.
구분 필수 여부상세 설명 Cluster Fabric 필수 GPU Direct RDMA를 함께 적용할 수 있는 GPU Node 서버의 모임 설정 - 동일 Cluster Fabric내에서만 최적의 GPU 성능 및 속도를 확보 가능
- 신규 Cluster Fabric을 생성할 경우, *신규 입력 > Node pool을 선택한 후, 생성할 Cluster Fabric 이름을 입력
- 기존에 생성된 Cluster Fabric에 추가하려면 기존 입력 > Node pool을 선택한 후, 기존에 생성된 Cluster Fabric을 선택
표. GPU Node Cluster Fabric 선택 항목 - 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Lock 선택 Lock을 사용하면 서버 해지/시작/중지를 실행할 수 없도록 실수로 인한 동작을 방지 Init Script 선택 서버 시작 시 실행할 스크립트 - Init Script는 이미지 종류에 따라 다르게 선택해야 함
- Linux의 경우: Shell Script 또는 cloud-init 선택
태그 선택 태그 추가 - 자원당 최대 50개까지 추가가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. GPU Node 추가 정보 입력 항목 - Init Script는 이미지 종류에 따라 다르게 선택해야 함
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
- 요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, GPU Node 목록 페이지에서 생성한 자원을 확인하세요.
주의
- 서비스 생성 시 GPU MIG/ECC 설정을 초기화합니다. 하지만 정확한 설정값을 적용하기 위하여 최초 한번 리부팅을 진행하고 설정값 적용 여부를 직접 확인한 후, 사용하세요.
- GPU MIG/ECC 설정 초기화에 대한 자세한 내용은 GPU MIG/ECC 설정 초기화 점검 가이드를 참고하세요.
GPU Node 상세 정보 확인하기
Multi-node GPU Cluster 서비스는 GPU Node의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다.
GPU Node 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
GPU Node의 상세 정보를 확인하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Multi-node GPU Cluster > GPU Node 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 GPU Node 메뉴를 클릭하세요. GPU Node 목록 페이지로 이동합니다.
- 필수 컬럼 이외의 자원 항목은 설정 버튼을 통해 추가할 수 있습니다.
구분 필수 여부상세 설명 자원 ID 선택 사용자가 생성한 GPU Node ID Cluster Fabric명 필수 사용자가 생성한 Cluster Fabric 이름 서버명 필수 사용자가 생성한 GPU Node 이름 서버 타입 필수 GPU Node의 서버 타입 - 사용자가 생성한 자원의 Core수,메모리 용량, GPU 종류와 수를 확인 가능
이미지 필수 사용자가 생성한 GPU Node 이미지 버전 IP 필수 사용자가 생성한 GPU Node의 IP 상태 필수 사용자가 생성한 GPU Node의 상태 생성 일시 선택 GPU Node를 생성한 일시 표. GPU Node 자원 목록 항목
- 필수 컬럼 이외의 자원 항목은 설정 버튼을 통해 추가할 수 있습니다.
GPU Node 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. GPU Node 상세 페이지로 이동합니다.
- GPU Server 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 설명이 표시됩니다.
구분 상세 설명 GPU Node 상태 사용자가 생성한 GPU Node의 상태 - Creating: 서버 생성 중인 상태
- Running:: 생성 완료되어 사용 가능한 상태
- Editing:: IP 변경중인 상태
- Unknown: 오류 상태
- Starting: 서버 시작 중인 상태
- Stopping: 서버 중지 중인 상태
- Stopped: 서버 중지 완료 상태
- Terminating: 해지 중인 상태
- Terminated: 해지 완료 상태
서버 제어 서버 상태를 변경할 수 있는 버튼 - 시작: 중지된 서버를 시작
- 중지: 가동 중인 서버를 중지
서비스 해지 서비스를 해지하는 버튼 표. GPU Node 상태 정보 및 부가 기능
- GPU Server 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 설명이 표시됩니다.
상세 정보
GPU Node 목록 페이지의 상세 정보 탭에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 서버명 | 서버 이름 |
| Node pool | 같은 Cluster Fabric으로 묶을 수 있는 Node의 모임 |
| Cluster Fabric명 | 사용자가 생성한 Cluster Fabric 이름 |
| 이미지/버전 | 서버의 OS 이미지와 버전 |
| 서버 타입 | CPU, 메모리, GPU, 정보 표시 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| Lock | Lock 사용/미사용 여부 표시
|
| 네트워크 | GPU Node의 네트워크 정보
|
| Block Storage | 서버에 연결된 Block Storage 정보
|
| Init Script | 서버 생성 시 입력한 Init Script 내용을 조회 |
표. GPU Node 상세 정보 탭 항목
태그
GPU Node 목록 페이지의 태그 탭에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. GPU Node 태그 탭 항목
작업 이력
GPU Node 목록 페이지의 작업 이력 탭에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. GPU Node 작업 이력 탭 상세 정보 항목
GPU Node 가동 제어하기
생성된 GPU Node 자원의 서버 제어 및 관리 기능이 필요한 경우, GPU Node 목록 또는 GPU Node 상세 페이지에서 작업을 수행할 수 있습니다. 가동 중인 GPU Node 자원의 시작, 중지를 할 수 있습니다.
GPU Node 시작하기
중지(Stopped)된 GPU Node를 시작할 수 있습니다. GPU Node를 시작하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Multi-node GPU Cluster 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Node 메뉴를 클릭하세요. GPU Node 목록 페이지로 이동합니다.
- GPU Node 목록 페이지에서 개별 또는 여러 대 서버를 체크 박스 선택 후 상단의 더보기 버튼을 통해 시작 할 수 있습니다.
- GPU Node 목록 페이지에서 자원을 클릭하세요. GPU Node 상세 페이지로 이동합니다.
- GPU Node 상세 페이지에서 상단의 시작 버튼을 클릭하여, 서버를 시작합니다.
- 서버 상태를 확인하고 상태 변경을 완료하세요.
GPU Node 중지하기
가동(Active)중인 GPU Node를 중지할 수 있습니다. GPU Node를 중지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Multi-node GPU Cluster 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Node 메뉴를 클릭하세요. GPU Node 목록 페이지로 이동합니다.
- GPU Node 목록 페이지에서 개별 또는 여러 대 서버를 체크 박스 선택 후 상단의 중지 버튼을 통해 제어할 수 있습니다.
- GPU Node 목록 페이지에서 자원을 클릭하세요. GPU Node 상세 페이지로 이동합니다.
- GPU Node 상세 페이지에서 상단의 중지 버튼을 클릭하여, 서버를 중지합니다.
- 서버 상태를 확인하고 상태 변경을 완료하세요.
GPU Node 해지하기
사용하지 않는 GPU Node를 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 해지 후에는 데이터를 복구할 수 없으므로 주의해주세요.
GPU Node를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Multi-node GPU Server 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Cluster Fabric 메뉴를 클릭하세요. Cluster Fabric 목록 페이지로 이동합니다.
- Cluster Fabric 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 동일한 Cluster Fabric을 사용하는 자원은 동시에 해지할 수 있습니다.
- 해지가 완료되면, GPU Node 목록 페이지에서 자원이 해지되었는지 확인하세요.
안내
GPU Node 해지가 불가한 경우는 아래와 같습니다.
- Block Storage(BM)가 연결된 경우: Block Storage(BM) 연결을 먼저 해지해 주세요.
- File Storage가 연결된 경우: File Storage 연결을 먼저 해지해주세요.
- Lock이 설정된 경우: Lock 설정을 미사용으로 변경 후 재시도 해주세요.
- 동시에 해지할 수 없는 서버가 포함된 경우: 해지 가능한 자원만 다시 선택하세요.
- 해지하려는 서버의 Cluster Fabric이 다른 경우: 동일한 Cluster Fabric을 사용하는 자원만 선택하세요.
참고
Cluster Fabric 내에 있는 GPU Node가 전부 삭제되면 Cluster Fabric은 자동으로 삭제됩니다.
5.2.1 - Cluster Fabric 관리
Cluster Fabric은 GPU Cluster에 포함된 서버들(GPU Node)의 관리를 도와주는 서비스입니다. Cluster Fabric을 이용하면 같은 Node pool에 있는 GPU Cluster간 서버를 이동할 수 있으며, 동일 GPU Cluster 내에서 GPU의 성능과 속도를 최적화 할 수 있습니다.
Cluster Fabric 생성하기
Cluster Fabric은 GPU Node를 생성 시 함께 생성할 수 있고, 또한 별도로 생성하거나 삭제할 수 없습니다. Cluster Fabric 내에 있는 GPU Node가 전부 해지되면 Cluster Fabric은 자동으로 삭제됩니다.
GPU Node를 생성하지 않은 경우에는 GPU Node를 먼저 생성해주세요. 자세한 내용은 GPU Node 생성하기를 참고하세요.
Cluster Fabric 상세 정보 확인하기
안내
- Cluster Fabric은 GPU Node를 생성 시 함께 생성할 수 있고, 또한 별도로 생성하거나 삭제할 수 없습니다.
- Cluster Fabric 내에 있는 GPU Node가 전부 해지되면 Cluster Fabric은 자동으로 삭제됩니다.
- GPU Node를 생성하지 않은 경우에는 GPU Node를 먼저 생성해주세요. 자세한 내용은 GPU Node 생성하기를 참고하세요.
Cluster Fabric 목록 페이지와 Cluster Fabric 상세페이지에서 생성된 Cluster Fabric 목록과 상세 정보를 확인하고 서버를 이동할 수 있습니다.
모든 서비스 > Compute > Multi-node GPU Server 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Cluster Fabric 메뉴를 클릭하세요. Cluster Fabric 목록 페이지로 이동합니다.
- Cluster Fabric 목록 페이지에서 사용자가 생성한 GPU Cluster의 자원 목록을 조회 할 수 있습니다.
- 필수 컬럼 이외의 자원 항목은 설정 버튼을 통해 추가할 수 있습니다.
구분 필수 여부상세 설명 자원 ID 선택 사용자가 생성한 Cluster Fabric ID Cluster Fabric명 필수 사용자가 생성한 Cluster Fabric 이름 Node pool 선택 같은 Cluster Fabric으로 묶을 수 있는 Node의 모임 서버 수 선택 GPU Node의 수 서버 타입 선택 GPU Node의 서버 타입 - 사용자가 생성한 자원의 Core수,메모리 용량, GPU 종류와 수를 확인 가능
상태 선택 사용자가 생성한 Cluster Fabric의 상태 생성 일시 선택 Cluster Fabric을 생성한 일시 표. Cluster Fabric 자원 목록 항목
Cluster Fabric 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Cluster Fabric 상세 페이지로 이동합니다.
- Cluster Fabric 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 설명이 표시됩니다.
구분 상세 설명 Cluster Fabric 상태 사용자가 생성한 Cluster Fabric의 상태 - Creating: 클러스터 생성 중인 상태
- Active: 생성 완료되어 사용 가능한 상태
- Editing: IP 변경중인 상태
- Deleting: 해지 중인 상태
- Deleted: 해지 완료 상태
대상 서버 추가 다른 클러스터에 있는 서버를 해당 클러스터로 이동 할 수 있는 기능 표. Cluster Fabric 상태 정보 및 부가 기능
- Cluster Fabric 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 설명이 표시됩니다.
상세 정보
Cluster Fabric 목록 페이지의 상세 정보 탭에서 선택한 자원의 상세 정보를 확인하고, 다른 클러스터의 서버를 가져 올 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Cluster Fabric명 | 사용자가 생성한 Cluster Fabric 이름 |
| Node pool | 같은 Cluster Fabric으로 묶을 수 있는 Node의 모임 |
| 대상 서버 | Cluster Fabric에 묶여 있는 GPU Node 목록
|
표. Cluster Fabric 상세 정보 탭 항목
Cluster Fabric 서버 가져오기
Cluster Fabric 상세 페이지의 대상 서버 추가 기능을 사용하여 다른 클러스터에 있는 서버를 가져와 선택한 클러스터에 추가할 수 있습니다.
- 모든 서비스 > Compute > Multi-node GPU Server 메뉴를 클릭하세요. Multi-node GPU Cluster의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Cluster Fabric 메뉴를 클릭하세요. Cluster Fabric 목록 페이지로 이동합니다.
- Cluster Fabric 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Cluster Fabric 상세 페이지로 이동합니다.
- 상세 정보 탭의 대상 서버에서 오른쪽 추가 버튼을 클릭하세요.
- 대상 서버 추가 팝업창이 열립니다.
- Cluster Fabric에서 클러스터를 선택하세요.
- 선택한 클러스터에 묶여 있는 GPU Node가 조회되며 가져오려는 GPU Node를 선택하세요.
- 선택된 GPU Node는 하단에 GPU Node명이 나열됩니다.
- 확인 버튼을 눌러 완료 합니다.
- 취소 버튼을 누르면 작업이 취소됩니다.
- 대상 서버에서 추가한 GPU Node가 조회되는지 확인하세요.
- 대상 서버 추가 팝업창이 열립니다.
Cluster Fabric 해지하기
Cluster Fabric 내에 있는 GPU Node가 전부 해지되면 Cluster Fabric은 자동으로 삭제됩니다. 자세한 내용은 GPU Node 해지하기를 참고하세요.
5.2.2 - ServiceWatch Agent 설치하기
사용자는 Multi-node GPU Cluster의 GPU Node에 ServiceWatch Agent를 설치하여 사용자 정의 지표와 로그를 수집할 수 있습니다.
참고
ServiceWatch Agent를 통한 사용자 정의 지표/로그 수집은 현재 Samsung Cloud Platform For Enterprise에서만 사용 가능합니다. 이외 오퍼링에서도 향후 제공 예정입니다.
주의
ServiceWatch Agent를 통한 지표 수집은 사용자 정의 지표로 구분되어 기본으로 수집되는 지표와는 달리 요금이 부과되므로, 불필요한 메트릭 수집 설정은 제거하거나 비활성화하기를 권장합니다.
ServiceWatch Agent
Multi-node GPU Cluster의 GPU Node에 ServiceWatch의 사용자 정의 지표 및 로그 수집을 위해 설치해야 하는 Agent는 크게 2가지로 나눌 수 있습니다. Prometheus Exporter와 Open Telemetry Collector 입니다.
| 구분 | 상세 설명 | |
|---|---|---|
| Prometheus Exporter | 특정 애플리케이션이나 서비스의 메트릭을 Prometheus가 스크랩(scrape)할 수 있는 형식으로 제공
| |
| Open Telemetry Collector | 분산 시스템의 메트릭, 로그와 같은 텔레메트리 데이터를 수집하고, 처리(필터링, 샘플링 등)한 후, 여러 백엔드(예: Prometheus, Jaeger, Elasticsearch 등)로 내보내는 중앙 집중식 수집기 역할
|
표. Prometheus Exporter와 Open Telemetry Collector 설명
안내
GPU Node에 Kubernetes Engine을 구성한 경우, Kubernetes Engine에서 제공되는 지표를 통해 GPU 지표를 확인하기 바랍니다.
- Kubernetes Engine이 구성되어 있는 GPU Node에 DCGM Exporter를 설치하게 되면 정상 동작하지 않을 수 있습니다.
참고
GPU Node의 GPU 지표 수집을 위한 ServiceWatch Agent 가이드는 GPU Server와 동일하게 사용할 수 있습니다.
자세한 내용은 GPU Server > ServiceWatch Agent를 참고하세요.
5.2.3 - Multi-node GPU Cluster 서비스 범위 및 점검 가이드
Multi-node GPU Cluster 서비스 범위
Multi-node GPU Cluster 서비스의 IaaS HW 레벨 문제 발생 시 Support Center의 문의하기를 통해 기술 지원을 받을 수 있습니다. 하지만 OS Kernel 업데이트 또는 애플리케이션 설치 등의 변경에 따른 리스크는 사용자의 영역이므로 기술 지원이 어려우니, 시스템 업데이트 등의 작업에 유의해 주시기 바랍니다.
IaaS HW 레벨 문제
- IPMI(iLO) HW모니터링 콘솔에서 발생하는 서버 내의 HW fault event 발생 메시지
- nvdia-smi 명령에서 확인되는 GPU HW 동작 오류
- InfiniBand HCA 카드 또는 InfiniBand Switch 점검에서 발생하는 HW 오류 메시지
주의
Multi-node GPU Cluster 는 Ubuntu OS / NVDIA / Infiniband 의 Software Version 호환성에 민감한 서비스이므로, 사용자의 OS Kernel 업데이트 또는 애플리케이션 설치 등의 변경 이후 공식적인 기술지원이 불가합니다.
IaaS HW 점검 가이드
Multi-node GPU Cluster 서비스를 신청한 후에는 점검 가이드에 따라 IaaS HW 레벨을 점검하는 것을 권장합니다.
OS Kernel 및 Package holding
안내
- 패키지 버전의 자동 업데이트를 원하지 않을 경우,
apt-mark명령어로 패키지 업데이트를 차단하는 것을 권장합니다. - Linux 커널이나 IB 관련된 패키지 버전의 업데이트 차단을 권장합니다.
OS Kernel 및 Package holding을 진행하려면 다음 절차를 따르세요.
- 다음 명령어를 사용하여 커널과 IB 관련된 패키지 버전을 확인하세요.배경색 변경
root@bm-dev-001:~# dpkg -l | egrep -i "kernel | mlnx" root@bm-dev-001:~# dpkg -l | egrep -i "kernel | nvidia" root@bm-dev-001:~# dpkg -l | egrep -i "kernel | linux-image" ii crash 7.2.8-1ubuntu1.20.04.1 amd64 kernel debugging utility, allowing gdb like syntax ii dkms 2.8.1-5ubuntu2 all Dynamic Kernel Module Support Framework ii dmeventd 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper event daemon ii dmsetup 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper userspace library ii iser-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo iser kernel modules ii isert-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo isert kernel modules ii kernel-mft-dkms 4.17.2-12 all DKMS support for kernel-mft kernel modules ii kmod 27-1ubuntu2 amd64 tools for managing Linux kernel modules ii knem 1.1.4.90mlnx1-OFED.5.1.2.5.0.1 amd64 userspace tools for the KNEM kernel module ii knem-dkms 1.1.4.90mlnx1-OFED.5.1.2.5.0.1 all DKMS support for mlnx-ofed kernel modules ii libaio1:amd64 0.3.112-5 amd64 Linux kernel AIO access library - shared library ii libdevmapper-event1.02.1:amd64 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper event support library ii libdevmapper1.02.1:amd64 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper userspace library ii libdrm-amdgpu1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to amdgpu-specific kernel DRM services -- runtime ii libdrm-common 2.4.107-8ubuntu1~20.04.2 all Userspace interface to kernel DRM services -- common files ii libdrm-intel1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to intel-specific kernel DRM services -- runtime ii libdrm-nouveau2:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to nouveau-specific kernel DRM services -- runtime ii libdrm-radeon1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to radeon-specific kernel DRM services -- runtime ii libdrm2:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to kernel DRM services -- runtime ii linux-firmware 1.187.29 all Firmware for Linux kernel drivers hi linux-generic 5.4.0.105.109 amd64 Complete Generic Linux kernel and headers ii linux-headers-5.4.0-104 5.4.0-104.118 all Header files related to Linux kernel version 5.4.0 ii linux-headers-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel headers for version 5.4.0 on 64 bit x86 SMP ii linux-headers-5.4.0-105 5.4.0-105.119 all Header files related to Linux kernel version 5.4.0 ii linux-headers-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel headers for version 5.4.0 on 64 bit x86 SMP hi linux-headers-generic 5.4.0.105.109 amd64 Generic Linux kernel headers ii linux-image-5.4.0-104-generic 5.4.0-104.118 amd64 Signed kernel image generic ii linux-image-5.4.0-105-generic 5.4.0-105.119 amd64 Signed kernel image generic hi linux-image-generic 5.4.0.105.109 amd64 Generic Linux kernel image ii linux-libc-dev:amd64 5.4.0-105.119 amd64 Linux Kernel Headers for development ii linux-modules-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-extra-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-extra-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii mlnx-ofed-kernel-dkms 5.4-OFED.5.4.3.0.3.1 all DKMS support for mlnx-ofed kernel modules ii mlnx-ofed-kernel-utils 5.4-OFED.5.4.3.0.3.1 amd64 Userspace tools to restart and tune mlnx-ofed kernel modules ii mlnx-tools 5.2.0-0.54303 amd64 Userspace tools to restart and tune MLNX_OFED kernel modules ii nvidia-kernel-common-470 470.103.01-0ubuntu0.20.04.1 amd64 Shared files used with the kernel module ii nvidia-kernel-source-470 470.103.01-0ubuntu0.20.04.1 amd64 NVIDIA kernel source package ii nvidia-peer-memory 1.2-0 all nvidia peer memory kernel module. ii nvidia-peer-memory-dkms 1.2-0 all DKMS support for nvidia-peer-memory kernel modules ii rsyslog 8.2001.0-1ubuntu1.1 amd64 reliable system and kernel logging daemon ii srp-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo srp kernel modulesroot@bm-dev-001:~# dpkg -l | egrep -i "kernel | mlnx" root@bm-dev-001:~# dpkg -l | egrep -i "kernel | nvidia" root@bm-dev-001:~# dpkg -l | egrep -i "kernel | linux-image" ii crash 7.2.8-1ubuntu1.20.04.1 amd64 kernel debugging utility, allowing gdb like syntax ii dkms 2.8.1-5ubuntu2 all Dynamic Kernel Module Support Framework ii dmeventd 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper event daemon ii dmsetup 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper userspace library ii iser-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo iser kernel modules ii isert-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo isert kernel modules ii kernel-mft-dkms 4.17.2-12 all DKMS support for kernel-mft kernel modules ii kmod 27-1ubuntu2 amd64 tools for managing Linux kernel modules ii knem 1.1.4.90mlnx1-OFED.5.1.2.5.0.1 amd64 userspace tools for the KNEM kernel module ii knem-dkms 1.1.4.90mlnx1-OFED.5.1.2.5.0.1 all DKMS support for mlnx-ofed kernel modules ii libaio1:amd64 0.3.112-5 amd64 Linux kernel AIO access library - shared library ii libdevmapper-event1.02.1:amd64 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper event support library ii libdevmapper1.02.1:amd64 2:1.02.167-1ubuntu1 amd64 Linux Kernel Device Mapper userspace library ii libdrm-amdgpu1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to amdgpu-specific kernel DRM services -- runtime ii libdrm-common 2.4.107-8ubuntu1~20.04.2 all Userspace interface to kernel DRM services -- common files ii libdrm-intel1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to intel-specific kernel DRM services -- runtime ii libdrm-nouveau2:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to nouveau-specific kernel DRM services -- runtime ii libdrm-radeon1:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to radeon-specific kernel DRM services -- runtime ii libdrm2:amd64 2.4.107-8ubuntu1~20.04.2 amd64 Userspace interface to kernel DRM services -- runtime ii linux-firmware 1.187.29 all Firmware for Linux kernel drivers hi linux-generic 5.4.0.105.109 amd64 Complete Generic Linux kernel and headers ii linux-headers-5.4.0-104 5.4.0-104.118 all Header files related to Linux kernel version 5.4.0 ii linux-headers-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel headers for version 5.4.0 on 64 bit x86 SMP ii linux-headers-5.4.0-105 5.4.0-105.119 all Header files related to Linux kernel version 5.4.0 ii linux-headers-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel headers for version 5.4.0 on 64 bit x86 SMP hi linux-headers-generic 5.4.0.105.109 amd64 Generic Linux kernel headers ii linux-image-5.4.0-104-generic 5.4.0-104.118 amd64 Signed kernel image generic ii linux-image-5.4.0-105-generic 5.4.0-105.119 amd64 Signed kernel image generic hi linux-image-generic 5.4.0.105.109 amd64 Generic Linux kernel image ii linux-libc-dev:amd64 5.4.0-105.119 amd64 Linux Kernel Headers for development ii linux-modules-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-extra-5.4.0-104-generic 5.4.0-104.118 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii linux-modules-extra-5.4.0-105-generic 5.4.0-105.119 amd64 Linux kernel extra modules for version 5.4.0 on 64 bit x86 SMP ii mlnx-ofed-kernel-dkms 5.4-OFED.5.4.3.0.3.1 all DKMS support for mlnx-ofed kernel modules ii mlnx-ofed-kernel-utils 5.4-OFED.5.4.3.0.3.1 amd64 Userspace tools to restart and tune mlnx-ofed kernel modules ii mlnx-tools 5.2.0-0.54303 amd64 Userspace tools to restart and tune MLNX_OFED kernel modules ii nvidia-kernel-common-470 470.103.01-0ubuntu0.20.04.1 amd64 Shared files used with the kernel module ii nvidia-kernel-source-470 470.103.01-0ubuntu0.20.04.1 amd64 NVIDIA kernel source package ii nvidia-peer-memory 1.2-0 all nvidia peer memory kernel module. ii nvidia-peer-memory-dkms 1.2-0 all DKMS support for nvidia-peer-memory kernel modules ii rsyslog 8.2001.0-1ubuntu1.1 amd64 reliable system and kernel logging daemon ii srp-dkms 5.4-OFED.5.4.3.0.1.1 all DKMS support fo srp kernel modules코드블록. 커널, IB 관련 패키지 버전 확인 - apt-mark 명령어를 사용하여 패키지 업데이트를 hold하세요.배경색 변경
# apt-mark hold <패키지이름># apt-mark hold <패키지이름>코드블록. 패키지 업데이트 hold
Intel E810 드라이버 업데이트
Intel E810 드라이버의 버전을 확인하고, 권장 버전으로 업데이트하세요.
안내
- 서버 제조사 Intel E810 드라이버 권장 버전: 1.15.4
- 드라이버(ice-1.15.4.tar.gz) 다운로드
드라이버 업데이트 방법은 다음과 같습니다.
- 기본 드라이버 tar 파일을 원하는 디렉토리로 이동합니다.
예시: /home/username/ice 또는 /usr/local/src/ice
Archiver 파일을 untar / unzip하세요.
- x.x.x는 드라이버 tar 파일의 버전 번호입니다.배경색 변경
tar zxf ice-x.x.x.tar.gztar zxf ice-x.x.x.tar.gz코드블록. 압축 파일 해제
- x.x.x는 드라이버 tar 파일의 버전 번호입니다.
드라이버 src 디렉토리로 변경하세요.
- x.x.x는 드라이버 tar 파일의 버전 번호입니다.배경색 변경
cd ice-x.x.x/src/cd ice-x.x.x/src/코드블록. 디렉토리 변경
- x.x.x는 드라이버 tar 파일의 버전 번호입니다.
드라이버 모듈을 컴파일하세요.
배경색 변경make installmake install코드블록. 드라이버 모듈 컴파일 업데이트가 끝난 후, 버전을 확인하세요.
배경색 변경lsmod | grep ice modinfo ice | grep versionlsmod | grep ice modinfo ice | grep version코드블록. 버전 확인
NVIDIA driver 확인
참고
nvidia-smi topo, IB nv_peer_mem status 확인NVIDIA driver를 확인(nvidia-smi topo, IB nv_peer_mem status)하여 IaaS HW 레벨을 점검하려면 다음 절차를 따르세요.
GPU 드라이버와 HW 상태를 확인하세요.
배경색 변경user@bm-dev-001:~$ nvidia-smi topo -m GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 mlx5_0 mlx5_1 mlx5_2 mlx5_3 CPU Affinity NUMA Affinity GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 SYS PXB SYS SYS 48-63 3 GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 SYS PXB SYS SYS 48-63 3 GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 PXB SYS SYS SYS 16-31 1 GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 PXB SYS SYS SYS 16-31 1 GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 SYS SYS SYS PXB 112-127 7 GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 SYS SYS SYS PXB 112-127 7 GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 SYS SYS PXB SYS 80-95 5 GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X SYS SYS PXB SYS 80-95 5 mlx5_0 SYS SYS PXB PXB SYS SYS SYS SYS X SYS SYS SYS mlx5_1 PXB PXB SYS SYS SYS SYS SYS SYS SYS X SYS SYS mlx5_2 SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS X SYS mlx5_3 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS X Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinksuser@bm-dev-001:~$ nvidia-smi topo -m GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 mlx5_0 mlx5_1 mlx5_2 mlx5_3 CPU Affinity NUMA Affinity GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 SYS PXB SYS SYS 48-63 3 GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 SYS PXB SYS SYS 48-63 3 GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 PXB SYS SYS SYS 16-31 1 GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 PXB SYS SYS SYS 16-31 1 GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 SYS SYS SYS PXB 112-127 7 GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 SYS SYS SYS PXB 112-127 7 GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 SYS SYS PXB SYS 80-95 5 GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X SYS SYS PXB SYS 80-95 5 mlx5_0 SYS SYS PXB PXB SYS SYS SYS SYS X SYS SYS SYS mlx5_1 PXB PXB SYS SYS SYS SYS SYS SYS SYS X SYS SYS mlx5_2 SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS X SYS mlx5_3 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS X Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinks코드블록. GPU 드라이버 및 HW 상태 확인 NVSwitch HW 상태를 확인하세요.
배경색 변경user@bm-dev-001:~$ nvidia-smi nvlink --status GPU 0: NVIDIA A100-SXM4-80GB (UUID: GPU-2c0d1d6b-e348-55fc-44cf-cd65a954b36c) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-96f429d8-893a-a9ea-deca-feffd90669e9) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2e601952-b442-b757-a035-725cd320f589) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-bcbfd885-a9f8-ec8c-045b-c521472b4fed) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-30273090-2d78-fc7a-a360-ec5f871dd488) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-5ce7ef61-56dd-fb18-aa7c-be610c8d51c3) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-740a527b-b286-8b85-35eb-b6b41c0bb6d7) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-1fb6de95-60f6-dbf2-ffca-f7680577e37c) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/suser@bm-dev-001:~$ nvidia-smi nvlink --status GPU 0: NVIDIA A100-SXM4-80GB (UUID: GPU-2c0d1d6b-e348-55fc-44cf-cd65a954b36c) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-96f429d8-893a-a9ea-deca-feffd90669e9) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2e601952-b442-b757-a035-725cd320f589) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-bcbfd885-a9f8-ec8c-045b-c521472b4fed) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-30273090-2d78-fc7a-a360-ec5f871dd488) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-5ce7ef61-56dd-fb18-aa7c-be610c8d51c3) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-740a527b-b286-8b85-35eb-b6b41c0bb6d7) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-1fb6de95-60f6-dbf2-ffca-f7680577e37c) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s코드블록. NVSwitch HW 상태 확인 InfiniBand(IB) HCA 카드 HW 상태와 Link를 확인하세요.
배경색 변경user@bm-dev-001:~$ ibdev2netdev -v cat: /sys/class/infiniband/mlx5_0/device/vpd: Permission denied 0000:45:00.0 mlx5_0 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs18 (Down) cat: /sys/class/infiniband/mlx5_1/device/vpd: Permission denied 0000:0e:00.0 mlx5_1 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs17 (Down) cat: /sys/class/infiniband/mlx5_2/device/vpd: Permission denied 0000:c5:00.0 mlx5_2 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs20 (Down) cat: /sys/class/infiniband/mlx5_3/device/vpd: Permission denied 0000:85:00.0 mlx5_3 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs19 (Down) user@bm-dev-001:~$ root@bm-dev-001:~# ibstat CA 'mlx5_0' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff5060ac System image GUID: 0x88e9a4ffff5060ac Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 8 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff5060ac Link layer: InfiniBand CA 'mlx5_1' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504080 System image GUID: 0x88e9a4ffff504080 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 5 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504080 Link layer: InfiniBand CA 'mlx5_2' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff505038 System image GUID: 0x88e9a4ffff505038 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 2 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff505038 Link layer: InfiniBand CA 'mlx5_3' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504094 System image GUID: 0x88e9a4ffff504094 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 7 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504094 Link layer: InfiniBanduser@bm-dev-001:~$ ibdev2netdev -v cat: /sys/class/infiniband/mlx5_0/device/vpd: Permission denied 0000:45:00.0 mlx5_0 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs18 (Down) cat: /sys/class/infiniband/mlx5_1/device/vpd: Permission denied 0000:0e:00.0 mlx5_1 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs17 (Down) cat: /sys/class/infiniband/mlx5_2/device/vpd: Permission denied 0000:c5:00.0 mlx5_2 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs20 (Down) cat: /sys/class/infiniband/mlx5_3/device/vpd: Permission denied 0000:85:00.0 mlx5_3 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs19 (Down) user@bm-dev-001:~$ root@bm-dev-001:~# ibstat CA 'mlx5_0' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff5060ac System image GUID: 0x88e9a4ffff5060ac Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 8 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff5060ac Link layer: InfiniBand CA 'mlx5_1' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504080 System image GUID: 0x88e9a4ffff504080 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 5 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504080 Link layer: InfiniBand CA 'mlx5_2' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff505038 System image GUID: 0x88e9a4ffff505038 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 2 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff505038 Link layer: InfiniBand CA 'mlx5_3' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504094 System image GUID: 0x88e9a4ffff504094 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 7 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504094 Link layer: InfiniBand코드블록. InfiniBand(IB) HCA 카드 HW 상태 및 Link 확인
IB bandwidth 통신 확인
IB bandwidth 통신 상태를 확인(ib_send_bw)하여 IaaS HW 레벨을 점검하려면 다음 절차를 따르세요.
IB HCA 인터페이스의 이름을 확인하세요.
배경색 변경user@bm-dev-001:~$ ibdev2netdev mlx5_0 port 1 ==> ibs18 (Down) mlx5_1 port 1 ==> ibs17 (Down) mlx5_2 port 1 ==> ibs20 (Down) mlx5_3 port 1 ==> ibs19 (Down)user@bm-dev-001:~$ ibdev2netdev mlx5_0 port 1 ==> ibs18 (Down) mlx5_1 port 1 ==> ibs17 (Down) mlx5_2 port 1 ==> ibs20 (Down) mlx5_3 port 1 ==> ibs19 (Down)코드블록. IB HCA 인터페이스의 이름 확인 IB스위치#1과 통신이 가능한 HCA 인터페이스를 확인하세요.
배경색 변경mlx5_0 port 1 ==> ibs18 (Down) mlx5_2 port 1 ==> ibs20 (Down)mlx5_0 port 1 ==> ibs18 (Down) mlx5_2 port 1 ==> ibs20 (Down)코드블록. HCA 인터페이스 확인 IB스위치#2와 통신이 가능한 HCA 인터페이스를 확인하세요.
배경색 변경mlx5_1 port 1 ==> ibs17 (Down) mlx5_3 port 1 ==> ibs19 (Down)mlx5_1 port 1 ==> ibs17 (Down) mlx5_3 port 1 ==> ibs19 (Down)코드블록. HCA 인터페이스 확인 SERVER Side 명령어를 사용하여 상호 통신 상태를 확인하세요.
Client Side명령어를 2차로 입력하여 상호 통신배경색 변경user@bm-dev-001:~$ ib_send_bw -d mlx5_3 -i 1 –F ************************************ * Waiting for client to connect... * ************************************ --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_3 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON RX depth : 512 CQ Moderation : 1 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x07 QPN 0x002e PSN 0xa86622 remote address: LID 0x0a QPN 0x002d PSN 0xfc58dd --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 0.00 19827.40 0.317238 ---------------------------------------------------------------------------------------user@bm-dev-001:~$ ib_send_bw -d mlx5_3 -i 1 –F ************************************ * Waiting for client to connect... * ************************************ --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_3 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON RX depth : 512 CQ Moderation : 1 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x07 QPN 0x002e PSN 0xa86622 remote address: LID 0x0a QPN 0x002d PSN 0xfc58dd --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 0.00 19827.40 0.317238 ---------------------------------------------------------------------------------------코드블록. 통신 상태 확인
CLIENT Side명령어를 사용하여 상호 통신 상태를 확인하세요.SERVER Side명령어를 1차로 입력하여 상호 통신배경색 변경root@bm-dev-003:~# ib_send_bw -d mlx5_3 -i 1 -F <SERVER Side IP> --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_3 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 1 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x0a QPN 0x002a PSN 0x98a48e remote address: LID 0x07 QPN 0x002c PSN 0xe68304 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 19008.49 19006.37 0.304102 ---------------------------------------------------------------------------------------root@bm-dev-003:~# ib_send_bw -d mlx5_3 -i 1 -F <SERVER Side IP> --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_3 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 1 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x0a QPN 0x002a PSN 0x98a48e remote address: LID 0x07 QPN 0x002c PSN 0xe68304 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 19008.49 19006.37 0.304102 ---------------------------------------------------------------------------------------코드블록. 통신 상태 확인
IB 서비스 유관 커널 모듈 확인
IB 서비스 유관 커널 모듈을 확인(lsmod)하여 IaaS HW 레벨을 점검하세요.
배경색 변경
user@bm-dev-001:~$ lsmod | grep nv_peer_mem
nv_peer_mem 16384 0
ib_core 315392 9 rdma_cm,ib_ipoib,nv_peer_mem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
nvidia 35315712 156 nvidia_uvm,nv_peer_mem,nvidia_modesetuser@bm-dev-001:~$ lsmod | grep nv_peer_mem
nv_peer_mem 16384 0
ib_core 315392 9 rdma_cm,ib_ipoib,nv_peer_mem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
nvidia 35315712 156 nvidia_uvm,nv_peer_mem,nvidia_modeset배경색 변경
user@bm-dev-001:~$ service nv_peer_mem status
nv_peer_mem.service - LSB: Activates/Deactivates nv_peer_mem to \ start at boot time.
Loaded: loaded (/etc/init.d/nv_peer_mem; generated)
Active: active (exited) since Mon 2023-03-13 16:21:33 KST; 2 days ago
Docs: man:systemd-sysv-generator(8)
Process: 4913 ExecStart=/etc/init.d/nv_peer_mem start (code=exited, status=0/SUCCESS)user@bm-dev-001:~$ service nv_peer_mem status
nv_peer_mem.service - LSB: Activates/Deactivates nv_peer_mem to \ start at boot time.
Loaded: loaded (/etc/init.d/nv_peer_mem; generated)
Active: active (exited) since Mon 2023-03-13 16:21:33 KST; 2 days ago
Docs: man:systemd-sysv-generator(8)
Process: 4913 ExecStart=/etc/init.d/nv_peer_mem start (code=exited, status=0/SUCCESS)배경색 변경
user@bm-dev-001:~$ lsmod | grep ib
libiscsi_tcp 32768 1 iscsi_tcp
libiscsi 57344 2 libiscsi_tcp,iscsi_tcp
scsi_transport_iscsi 110592 4 libiscsi_tcp,iscsi_tcp,libiscsi
ib_ipoib 131072 0
ib_cm 57344 2 rdma_cm,ib_ipoib
ib_umad 24576 8
mlx5_ib 380928 0
ib_uverbs 135168 18 rdma_ucm,mlx5_ib
ib_core 315392 9 rdma_cm,ib_ipoib,nv_peer_mem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
libcrc32c 16384 2 btrfs,raid456
mlx5_core 1458176 1 mlx5_ib
auxiliary 16384 2 mlx5_ib,mlx5_core
mlx_compat 65536 12 rdma_cm,ib_ipoib,mlxdevm,iw_cm,auxiliary,ib_umad,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_coreuser@bm-dev-001:~$ lsmod | grep ib
libiscsi_tcp 32768 1 iscsi_tcp
libiscsi 57344 2 libiscsi_tcp,iscsi_tcp
scsi_transport_iscsi 110592 4 libiscsi_tcp,iscsi_tcp,libiscsi
ib_ipoib 131072 0
ib_cm 57344 2 rdma_cm,ib_ipoib
ib_umad 24576 8
mlx5_ib 380928 0
ib_uverbs 135168 18 rdma_ucm,mlx5_ib
ib_core 315392 9 rdma_cm,ib_ipoib,nv_peer_mem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
libcrc32c 16384 2 btrfs,raid456
mlx5_core 1458176 1 mlx5_ib
auxiliary 16384 2 mlx5_ib,mlx5_core
mlx_compat 65536 12 rdma_cm,ib_ipoib,mlxdevm,iw_cm,auxiliary,ib_umad,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_core스토리지 물리 디스크 자원 및 Multi-Path 확인
스토리지 물리 디스크 자원 및 Multi-Path를 확인하여 IaaS HW 레벨을 점검하세요.
배경색 변경
root@bm-dev-002:/tmp# fdisk –lroot@bm-dev-002:/tmp# fdisk –l배경색 변경
root@bm-dev-002:/tmp# multipath –llroot@bm-dev-002:/tmp# multipath –llMulti-node GPU Cluster 신규 배포 후 Service Network 확인
다음 명령어를 이용하여 Bonding 및 Slave Interface의 MII Status가 up인지 확인하세요.
명령어
배경색 변경root@mngc-001:~# cat /proc/net/bonding/bond-srv Ethernet Channel Bonding Driver: v5.15.0-25-genericroot@mngc-001:~# cat /proc/net/bonding/bond-srv Ethernet Channel Bonding Driver: v5.15.0-25-generic코드블록. Service Network 확인 명령어 확인 결과
배경색 변경Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens9f0 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 Slave Interface: ens9f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:35:70 Slave queue ID: 0 Slave Interface: ens11f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:2f:e8 Slave queue ID: 0Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens9f0 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 Slave Interface: ens9f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:35:70 Slave queue ID: 0 Slave Interface: ens11f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:2f:e8 Slave queue ID: 0코드블록. Service Network 확인 명령어 확인 결과
참고
일부 Slave Interface가 down 상태일 경우, Support Center의 문의하기를 이용하여 이상 상황을 전달하고 조치받으세요.
Multi-node GPU Cluster 신규 배포 후 Time Server와 시간 동기화 확인
OS 이미지에는 chrony 데몬 설치 및 SCP NTP 서버 동기화가 설정되어 있습니다. 다음 명령어를 이용하여 MS Name 열에 ^*로 표기된 라인이 있는지 확인하세요.
명령어
배경색 변경root@mngc-001:~# chronyc sources -Vroot@mngc-001:~# chronyc sources -V코드블록. chrony 데몬 설치 명령어 확인 결과
배경색 변경MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^+ 198.19.1.53 4 10 377 1040 -16us[ -37us] +/- 9982us ^* 198.19.1.54 4 10 377 312 -367us[ -388us] +/- 13msMS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^+ 198.19.1.53 4 10 377 1040 -16us[ -37us] +/- 9982us ^* 198.19.1.54 4 10 377 312 -367us[ -388us] +/- 13ms코드블록. chrony 데몬 설치 확인 결과
GPU MIG/ECC 설정 초기화 점검 가이드
Multi-node GPU Cluster 상품 신청 시 GPU MIG/ECC 설정을 초기화합니다. 하지만 정확한 설정값을 적용하기 위하여 최초 한 번 리부팅을 진행한 후, 점검 가이드에 따라 설정값 적용 여부를 직접 확인하고 사용해주시기 바랍니다.
참고
- MIG: Multi-Instance GPU
- ECC: Error Correction Code
MIG 설정 초기화
MIG 설정값을 확인하고 초기화하는 방법은 다음을 참조하세요.
다음 명령어를 사용하여 MIG M.의 상태값이 Disabled인지 확인하세요.
명령어
배경색 변경root@bm-dev-001:~#nvidia-smiroot@bm-dev-001:~#nvidia-smi코드블록. MIG M. 설정 초기화 확인 결과
배경색 변경+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 470.129.06 Driver version: 470.129.06 CUDA Version: 11.4 | |----------------------------------+-----------------------------+------------------------| | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |==================================+=============================+========================| | 0 NVIDIA A100-SXM... Off | 00000000:03:00.0 Off | Off | | N/A 29C P0 57W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +----------------------------------+-----------------------------+------------------------+ | 0 NVIDIA A100-SXM... Off | 00000000:0C:00.0 Off | Off | | N/A 30C P0 58W / 400W | 0MiB / 81251MiB | 18% Default | | | | Disabled | +-----------------------------------------------------------------------------------------++-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 470.129.06 Driver version: 470.129.06 CUDA Version: 11.4 | |----------------------------------+-----------------------------+------------------------| | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |==================================+=============================+========================| | 0 NVIDIA A100-SXM... Off | 00000000:03:00.0 Off | Off | | N/A 29C P0 57W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +----------------------------------+-----------------------------+------------------------+ | 0 NVIDIA A100-SXM... Off | 00000000:0C:00.0 Off | Off | | N/A 30C P0 58W / 400W | 0MiB / 81251MiB | 18% Default | | | | Disabled | +-----------------------------------------------------------------------------------------+코드블록. MIG M. 설정 초기화 확인 결과 MIG M.의 상태값이 Disabled이 아닐 경우, 다음 명령어를 사용하여 MIG를 초기화하세요.
배경색 변경root@bm-dev-001:~# nvidia-smi -mig 0 root@bm-dev-001:~# nvidia-smi --gpu-resetroot@bm-dev-001:~# nvidia-smi -mig 0 root@bm-dev-001:~# nvidia-smi --gpu-reset코드블록. MIG M. 상태값 초기화
ECC 설정 초기화
ECC 설정값을 확인하고 초기화하는 방법은 다음을 참조하세요.
다음 명령어를 사용하여 Volatile Uncorr. ECC의 상태값이 Off인지 확인하세요.
명령어
배경색 변경root@bm-dev-001:~#nvidia-smiroot@bm-dev-001:~#nvidia-smi코드블록. ECC 설정 명령어 확인 결과
배경색 변경+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 470.129.06 Driver version: 470.129.06 CUDA Version: 11.4 | |----------------------------------+-----------------------------+------------------------| | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |==================================+=============================+========================| | 0 NVIDIA A100-SXM... Off | 00000000:03:00.0 Off | Off | | N/A 29C P0 57W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +----------------------------------+-----------------------------+------------------------+ | 0 NVIDIA A100-SXM... Off | 00000000:0C:00.0 Off | Off | | N/A 30C P0 61W / 400W | 0MiB / 81251MiB | 18% Default | | | | Disabled | +-----------------------------------------------------------------------------------------++-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 470.129.06 Driver version: 470.129.06 CUDA Version: 11.4 | |----------------------------------+-----------------------------+------------------------| | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |==================================+=============================+========================| | 0 NVIDIA A100-SXM... Off | 00000000:03:00.0 Off | Off | | N/A 29C P0 57W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +----------------------------------+-----------------------------+------------------------+ | 0 NVIDIA A100-SXM... Off | 00000000:0C:00.0 Off | Off | | N/A 30C P0 61W / 400W | 0MiB / 81251MiB | 18% Default | | | | Disabled | +-----------------------------------------------------------------------------------------+코드블록. ECC 설정 확인 결과 Volatile Uncorr. ECC의 상태값이 On*일 경우, 리부팅을 진행하세요.
Volatile Uncorr. ECC의 상태값이 On*이나 Off가 아닐 경우, 다음 명령어를 사용하여 ECC를 초기화하세요. 초기화가 끝나면 리부팅 후, 상태값이 Off인지 확인하세요.
배경색 변경
root@bm-dev-001:~# nvidia-smi --ecc-config=0root@bm-dev-001:~# nvidia-smi --ecc-config=05.3 - Release Note
Multi-node GPU Cluster
2025.07.01
FEATURE
신규 기능 추가 및 모니터링 연계- GPU Node 목록에서 여러 자원을 동시에 해지할 수 있습니다.
- 동일한 DataSet, Cluster Fabric을 사용하는 노드여야 합니다.
- Cloud Monitoring과 연계하였습니다.
- Cloud Monitoring에서 주요 성능 항목을 실시간으로 확인할 수 있습니다.
2025.02.27
NEW
Multi-node GPU Cluster 서비스 정식 버전 출시- Multi-node GPU Cluster 서비스를 출시하였습니다.
- 대규모의 고성능 AI 연산을 위해 물리 GPU 서버를 가상화없이 제공하는 서비스를 제공합니다.
6 - Cloud Functions
6.1 - Overview
서비스 개요
Cloud Functions는 서버 프로비저닝 필요 없이 함수 형태의 애플리케이션을 간편하게 실행하는 서버리스 컴퓨팅 기반의 FaaS(Function as a Service)입니다. 사용자는 스케일 조정을 위해 번거롭게 서버나 컨테이너를 관리할 필요가 없으며, 애플리케이션 개발을 위한 코드 작성과 배포에 집중할 수 있습니다.
특장점
- 쉽고 편리한 개발 환경: 개발자는 선택한 런타임에 적합한 Code Editor를 이용하여 여러 환경에서 이벤트에 연결할 Function 리소스를 간편하게 생성할 수 있으며, 코드를 손쉽게 작성하고 호출할 수 있습니다.
- 서버리스 컴퓨팅: Samsung Cloud Platform 환경에서 개발을 위한 서버리스 형태의 코드 실행 서비스를 이용할 수 있습니다. 함수 형태의 애플리케이션을 호출, 실행하기 위해 필요한 자원은 실행하는 규모에 따라 Samsung Cloud Platform이 할당하고 관리합니다.
- 효율적인 비용 관리: 호출된 Function은 사용량(총 호출 횟수, 총 호출 시간)을 집계하여 실제 애플리케이션 구동에 사용된 시간만큼 과금됩니다. 사용량이 적은 Function은 Cloud Functions의 Scaler가 Scale-to-zero 상태로 조정하여 자원을 소모하지 않으므로 효율적인 비용 관리가 가능합니다.
서비스 구성도
제공 기능
Cloud Functions는 다음과 같은 기능을 제공하고 있습니다.
- 코드 작성 환경: Runtime에 최적화된 Function 생성, Code 작성 및 편집
- 지원 Runtime은 구성 요소 > Runtime 참고
- Function 실행, 환경 관리, 모니터링: 엔드포인트 정의, Token 관리, 접근제어 설정, 트리거 설정 등, 구동 환경/변수 정의 및 수정, Deploy/Test를 위한 산출물 호출/테스트, 서비스 배포, 진행 상태 모니터링/로깅
- 서버리스 컴퓨팅: 코드 작성 및 배포에 필요한 모든 요소는 Samsung Cloud Platform에서 관리, 배포에 따른 자동 스케일 조정
- 샘플 코드 제공: Blueprint를 통해 다양한 샘플 코드를 제공함으로써 손쉽고 빠르게 시작 가능
구성 요소
Runtime
Cloud Functions는 현재 다음과 같은 Runtime을 지원합니다. 또한 지속적으로 지원되는 Runtime이 추가될 예정입니다.
| Runtime | 버전 |
|---|---|
| GO | 1.21, 1.23 |
| java | 17 |
| Node.js | 18, 20 |
| PHP | 8.1 |
| Python | 3.9, 3.10, 3.11 |
표. 지원 Runtime 항목
리전별 제공 현황
Cloud Functions 서비스는 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부1(kr-west1) | 제공 |
| 한국 동부1(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. Cloud Functions 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 선택 사항으로 구성할 수 있는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해 주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Application Service | API Gateway | API를 손쉽게 관리하고 모니터링하는 서비스 |
표. Cloud Functions 선행 서비스
6.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Cloud Functions의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Cloud Functions 생성하기
모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Cloud Functions 생성 버튼을 클릭하세요. Cloud Functions 생성 페이지로 이동합니다.
Cloud Functions 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하세요.
구분 필수 여부상세 설명 Funtion 명 필수 생성할 Funtion 이름 입력 - 영문 소문자 시작하며 영문 소문자, 숫자, 특수문자(
-)를 이용하여 3 ~ 64자 이내로 입력
Runtime 필수 Runtime 생성 방법 선택 - 새로 작성: Runtime을 새로 작성
- Blueprint로 시작하기: 서비스에서 제공하는 Runtime 소스코드 활용하여 작성
Runtime & Vesion 필수 Runtime 및 버전 선택 - 새로 작성을 선택한 경우
- Runtime & Version 목록은 구성 요소 > Runtime 참고
- Java 런타임의 경우, UI 코드 편집을 지원하지 않으며, Object Storage에서 Jar파일을 가져와서 실행 가능
- Blueprint로 시작하기를 선택한 경우
- 해당 Runtime & Version의 소스코드 보기 버튼을 클릭하여 소스코드 예시 확인 가능
- Blueprint 설정에 대한 자세한 내용은 Blueprint 상세 가이드 참고
표. Cloud Functions 서비스 정보 입력 항목- 영문 소문자 시작하며 영문 소문자, 숫자, 특수문자(
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Cloud Functions 목록 페이지에서 생성한 자원을 확인하세요.
Cloud Functions 상세정보 확인하기
Cloud Functions 상세 페이지는 상세 정보, 모니터링, 로그, 코드, 구성, 트리거, 태그, 작업이력 탭으로 구성되어 있습니다.
Cloud Functions 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- Function 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 모니터링, 로그, 코드, 구성, 트리거, 태그, 작업이력 탭으로 구성됩니다.
구분 상세 설명 Cloud Functions 상태 Cloud Functions의 상태 정보 - Ready: 녹색 아이콘, 정상적인 함수 호출이 가능한 상태
- Not Ready: 회색 아이콘, 정상적인 함수 불가능한 상태
- Deploying: 황색 아이콘, 함수 생성 또는 변경 중인 상태로써 다음 동작으로 발동
- 함수 생성 및 수정
- 코드 탭에서 편집기로 코드 수정
- 코드 탭에서 jar 파일 검사
- 트리거 탭에서 추가 및 변경
- 구성 탭에서 변경
- Running: 청색 아이콘, 정상적인 함수 호출이 가능하고 콜드 스타트 방지 정책이 적용된 상태
서비스 해지 서비스를 해지하는 버튼 표. Cloud Functions 상태 정보 및 부가 기능
- Function 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 모니터링, 로그, 코드, 구성, 트리거, 태그, 작업이력 탭으로 구성됩니다.
상세 정보
Function 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID |
| 자원명 | 자원 이름
|
| 자원 ID | 서비스의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스를 수정한 사용자 |
| 수정 일시 | 서비스를 수정한 일시 |
| Function명 | Cloud Function의 이름 |
| Runtime | Runtime 종류 및 버전 |
| LLM Endpoint | 이용 가이드를 클릭하여 LLM Endpoint 정보 및 사용 방법 확인 가능 |
표. Cloud Functions 상세 - 상세 정보 탭 항목
참고
AIOS를 연계하여 LLM을 활용하는 방법에 대한 자세한 내용은 AIOS 연계하기 를 참고하시길 바랍니다.
모니터링
Function 목록 페이지에서 선택한 자원의 Cloud Functions 사용 정보를 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 호출수 | 단위 시간 동안 해당 Function이 호출된 평균 횟수(건) |
| 실행시간 | 단위 시간 동안 해당 Function을 실행한 평균 실행 시간(초) |
| 메모리 사용량 | 해당 Function 실행하는 중 중 단위 시간 동안 사용한 평균 메모리 사용량(kb) |
| 현재 작업수 | 함수가 동시에 여러 번 호출될 경우, 동시 처리를 위해 단위 시간 동안 생성된 작업의 평균 횟수(건) |
| 성공 호출수 | 함수 호출 시 단위 시간 동안 런타임 코드가 정상적으로 동작하여 응답 코드를 전달한 평균 횟수(건) |
| 실패 호출수 | 함수 호출 시 단위 시간 동안 오류가 발생한 평균 호출 횟수
|
표. Cloud Functions 상세 - 모니터링 탭 항목
로그
Function 목록 페이지에서 선택한 자원의 Cloud Functions 로그를 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 단위 기간 | Cloud Functions의 로그 정보를 확인할 기간 선택
|
| 로그 메시지 | 최근 발생 함수부터 순서대로 표시됩니다. |
표. Cloud Functions 상세 - 로그 탭 항목
참고
로그 메시지는 최근 발생 메시지를 기준으로 이전 1,000개의 메시지까지 확인이 가능합니다.
코드
Function 목록 페이지에서 선택한 자원의 Cloud Functions 코드를 확인하고 수정할 수 있습니다.
참고
사용 Runtime에 따라 소스 코드 확인 및 편집 방식이 달라집니다.
- 인라인 편집기: Node.js, Python, PHP, Go
- 압축파일(.jar/.zip) 실행: Java
| 구분 | 상세 설명 |
|---|---|
| 소스 코드 | 인라인 편집기 방식 |
| 코드 정보 | 코드 정보를 표시 |
| 수정 | 수정 버튼을 클릭한 후, 인라인 편집기에서 코드 수정 가능 |
표. Cloud Functions 상세 - 코드 탭 내 인라인 편집기 항목
| 구분 | 상세 설명 |
|---|---|
| 소스 코드 | 압축파일(.jar/.zip) 실행 방식 |
| 코드 정보 | 압축 파일 정보 표시
|
| 수정 | Jar 파일 변경 가능
|
표. Cloud Functions 상세 - 코드 탭 내 압축파일(.jar/.zip) 실행 항목
참고
- Java Runtime의 경우 UI 코드 편집 기능을 제공하지 않으며, Object Storage 서비스의 버킷에서 압축파일(.jar/.zip) 파일을 선택해야 합니다.
- Object Storage 서비스의 인증키가 생성되지 않은 사용자의 경우, Object Storage에서 가져오기를 실행할 수 없으므로, 사전에 인증키를 생성해야 합니다.
- 인증키 생성에 대한 자세한 내용은 인증키 생성하기를 참고하세요.
- Cloud Functions 서비스에 대한 Object Storage 버킷의 접근제어를 허용 상태로 변경해야 합니다.
- Object Storage 접근 제어에 대한 자세한 내용은 Cloud Functions 서비스 접근 허용하기를 참고하세요.
구성
Function 목록 페이지에서 선택한 자원의 Cloud Functions 구성을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 일반 구성 | Cloud Function의 메모리와 제한 시간 설정
|
| 환경 변수 | 런타임 환경 변수를 설정
|
| 함수 URL | 함수에 접근 가능한 HTTPS URL 주소 발급
|
| Private 연결 구성 | PrivateLink Service와 연계하여 사용 가능
|
표. Cloud Functions 상세 - 구성 탭 항목
주의
접근 제어 사용을 해제하는 경우, 등록된 접근 정보가 삭제되어 함수 접근 제어가 불가능하므로 외부 스캔, 해킹 등의 보안 공격에 노출될 수 있습니다.
참고
- 일반 구성의 메모리 할당량에 비례하는 CPU 코어 갯수가 자동으로 할당됩니다.
- 일반 구성의 실행 최소 수가 1이상 일 경우 Cold Start가 방지 되지만, 지속적으로 비용이 부과됩니다.
트리거
Function 목록 페이지에서 선택한 자원의 트리거 정보를 확인하고 설정할 수 있습니다. 트리거를 설정하면 이벤트 발생 시 Function을 자동으로 실행할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| Cronjob | Cronjob을 트리거로 사용
|
| API Gateway | API Gateway를 트리거로 사용
|
표. Cloud Functions 상세 - 트리거 탭 항목
주의
Cronjob 트리거를 함수 제한 시간 전에 호출할 경우, 함수가 중첩 실행되어 실행 횟수와 시간이 증가하게 됩니다. 따라서 지속적으로 추가 비용이 발생하여 높은 비용이 발생할 수 있으므로 주의하세요.
참고
- Deploying 상태일 경우, 수정할 수 없습니다.
- 트리거 설정에 대한 트리거 설정하기를 참고하세요.
태그
태그 탭에서 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Cloud Functions 상세 - 태그 탭 항목
작업 이력
작업 이력 페이지에서 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Cloud Functions 상세 - 작업 이력 탭 항목
Java Runtime 코드 변경하기
Java Runtime을 사용하는 경우, 코드를 직접 수정할 수 없으므로 Object Storage 서비스의 버킷에서 압축 파일(.jar/.zip)을 선택하여 변경해야 합니다.
압축 파일을 변경하는 방법은 다음 절차를 따르세요.
Cloud Functions 서비스를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 코드 내 압축 파일을 변경할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- Function 상세 페이지의 코드 탭에서 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- Object Storage에서 가져오기 버튼을 클릭하세요. Object Storage에서 가져오기 팝업창이 열립니다.
| 구분 | 상세 설명 |
|---|---|
| Java Runtime | Java Runtime 정보 |
| Handler 정보 | Handler 정보
|
| 압축파일(.jar/.zip) | 변경할 압축 파일을 설정
|
표. Cloud Functions 상세 - Function 코드 수정 항목
- Object Storage URL에 압축 파일을 가져올 Object Storage의 URL 정보를 입력한 후, 확인 버튼을 클릭하세요. 알림 팝업창이 열립니다.
- URL 정보는 가져올 Object Storage의 상세 페이지의 폴더 리스트 탭에서 파일 정보 > Private URL 항목에서 확인할 수 있습니다.
- 확인 버튼을 클릭하세요. Function 코드 수정 페이지의 **압축파일명(.jar/.zip)**에 가져온 압축 파일의 이름이 표시됩니다.
- 저장 버튼을 클릭하세요.
주의
- 인증키가 생성되지 않은 사용자의 경우, Object Storage에서 가져오기를 실행할 수 없습니다.
- URL이 존재하지 않거나 압축 파일이 다음에 해당하는 경우, 변경할 수 없습니다.
- 지원하지 않는 확장자를 사용하는 경우
- 압축 파일 내 유해한 파일이 있는 경우
- 지원 가능한 크기를 초과한 경우
Cloud Functions 해지하기
Cloud Functions 서비스를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 해지할 자원을 클릭하고 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면 Function 목록 페이지에서 자원이 해지되었는지 확인하세요.
6.2.1 - 트리거 설정하기
트리거 설정하기
참고
- 기본적으로 모든 트리거는 Cloud Functions에서 추가할 수 있습니다.
- 만약 특정 상품에서 트리거할 경우, Cloud Functions에 전달해야 합니다.
Cronjob 트리거 설정하기
Cronjob 트리거를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요.로 설정하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류에서 Cronjob을 선택하세요. 하단에 필수 정보 입력 영역이 나타납니다.
구분 상세 설명 Cronjob 설정 트리거의 반복 빈도를 설정 - 분, 시간, 일, 월, 요일 단위로 설정 가능
Timezone 설정 트리거의 기준 시간대를 설정 표. Cronjob 트리거 필수 정보 항목 - 필수 정보를 입력한 후, 확인 버튼을 클릭하세요.
- 추가를 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
API Gateway 트리거 설정하기
API Gateway 트리거를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요.로 설정하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류에서 API Gateway을 선택하세요. 하단에 필수 정보 입력 영역이 나타납니다.
구분 상세 설명 API명 API 선택 - 기존에 생성된 API를 선택하거나 새로 생성 가능
스테이지 배포 대상 선택 - 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
표. API Gateway 트리거 필수 정보 항목 - 필수 정보를 입력한 후, 확인 버튼을 클릭하세요.
- 추가를 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
멀티 트리거 설정하기
하나의 함수에 여러개의 트리거를 연결하여 사용할 수 있습니다.
트리거 수정하기
추가된 트리거를 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 수정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 목록에서 설정값을 수정할 트리거의 수정 버튼을 클릭하세요. 트리거 수정 팝업창이 열립니다.
- 트리거 수정 팝업창에서 설정값을 수정한 후, 확인 버튼을 클릭하세요.
- 설정값은 트리거의 종류에 따라 달라집니다(Cronjob 트리거, API Gateway 트리거 참고).
- 수정을 알리는 팝업창이 열리면 확인을 클릭하세요.
트리거 삭제하기
트리거를 삭제하려면 다음 절차를 따르세요.
주의
특정 상품과 연계한 트리거는, 해당 상품에서 연계 시점에 전달한 상품만 관리하며, Functions 해지 시 해당 상품에 삭제 상태를 전달해야 합니다.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭의 트리거 목록에서 삭제할 트리거를 선택한 후, 삭제 버튼을 클릭하세요.
- 트리거 삭제를 알리는 팝업창이 열리면 확인 버튼을 클릭하세요.
6.2.2 - AIOS 연계하기
AIOS 연계하기
Cloud Functions와 AIOS를 연계하여 LLM을 활용할 수 있습니다.
AIOS LLM 프라이빗 엔드포인트
AIOS LLM 프라이빗 엔드포인트의 URL은 다음과 같습니다.
- Samsung Cloud Platform for Samsung: https://aios.private.kr-west1.s.samsungsdscloud.com
- Samsung Cloud Platform for Enterprize: https://aios.private.kr-west1.e.samsungsdscloud.com
참고
AIOS 서비스의 리전별 제공 여부와 제공 모델에 대한 자세한 내용은 다음을 참조하세요.
- 리전별 AIOS 서비스의 제공 여부: AIOS 서비스 - 리전별 제공 현황 참고
- AIOS 서비스 제공 LLM 모델: AIOS 서비스 - LLM 제공 모델 참고
Blueprint 소스코드 변경하기
Cloud Functions와 AIOS를 연계하려면 각 리전 내 사용하는 LLM Endpoint에 맞춰 Blueprint에 있는 URL 주소를 변경해야 합니다. Blueprint 소스코드를 변경하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Cloud Functions 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 URL로 호출할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 코드 탭을 클릭하여 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- Python, Node.js, Go Runtime 소스코드를 사용하여 Blueprint를 변경한 후, 저장 버튼을 클릭하세요.
Python 소스코드
배경색 변경import json import requests def handle_request(params): # User writing area (Function details) url = "{AIOS LLM 프라이빗 엔드포인트}/{API}" # Destination URL data = { "model": "openai/gpt-oss-120b" , "prompt" : "Write a haiku about recursion in programming." , "temperature": 0 , "max_tokens": 100 , "stream": False } try: response = requests.post(url, json=data, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)import json import requests def handle_request(params): # User writing area (Function details) url = "{AIOS LLM 프라이빗 엔드포인트}/{API}" # Destination URL data = { "model": "openai/gpt-oss-120b" , "prompt" : "Write a haiku about recursion in programming." , "temperature": 0 , "max_tokens": 100 , "stream": False } try: response = requests.post(url, json=data, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)Python 소스코드 Node.js 소스코드
배경색 변경const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { url = "{AIOS LLM 프라이빗 엔드포인트}/{API}" data = { model: 'openai/gpt-oss-120b' , prompt : 'Write a haiku about recursion in programming.' , temperature: 0 , max_tokens: 100 , stream: false } const options = { uri: url, method:'POST', body: data, json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { url = "{AIOS LLM 프라이빗 엔드포인트}/{API}" data = { model: 'openai/gpt-oss-120b' , prompt : 'Write a haiku about recursion in programming.' , temperature: 0 , max_tokens: 100 , stream: false } const options = { uri: url, method:'POST', body: data, json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }Node.js 소스코드 GO 소스코드
배경색 변경package gofunction import ( "bytes" "net/http" "encoding/json" "io/ioutil" ) type PostData struct { Model string `json:"model"` Prompt string `json:"prompt"` Temperature int `json:"temperature"` MaxTokens int `json:"max_tokens"` Stream bool `json:"stream"` } func HandleRequest(r *http.Request)(string, error) { url := "{AIOS LLM 프라이빗 엔드포인트}/{API}" data := PostData { Model: "openai/gpt-oss-120b", Prompt: "Write a haiku about recursion in programming.", Temperature: 0, MaxTokens: 100, Stream: false, } jsonData, err := json.Marshal(data) if err != nil { panic(err) } req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonData)) if err != nil { panic(err) } req.Header.Set("Content-Type", "application/json") client := &http.Client{} resp, err := client.Do(req) if err != nil { panic(err) } defer resp.Body.Close() // 응답 본문 읽기 body, err := ioutil.ReadAll(resp.Body) if err != nil { panic(err) } return string(body), nil }package gofunction import ( "bytes" "net/http" "encoding/json" "io/ioutil" ) type PostData struct { Model string `json:"model"` Prompt string `json:"prompt"` Temperature int `json:"temperature"` MaxTokens int `json:"max_tokens"` Stream bool `json:"stream"` } func HandleRequest(r *http.Request)(string, error) { url := "{AIOS LLM 프라이빗 엔드포인트}/{API}" data := PostData { Model: "openai/gpt-oss-120b", Prompt: "Write a haiku about recursion in programming.", Temperature: 0, MaxTokens: 100, Stream: false, } jsonData, err := json.Marshal(data) if err != nil { panic(err) } req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonData)) if err != nil { panic(err) } req.Header.Set("Content-Type", "application/json") client := &http.Client{} resp, err := client.Do(req) if err != nil { panic(err) } defer resp.Body.Close() // 응답 본문 읽기 body, err := ioutil.ReadAll(resp.Body) if err != nil { panic(err) } return string(body), nil }GO 소스코드
6.2.3 - Blueprint 상세 가이드
Blueprint 개요
Cloud Functions 생성 시 Blueprint를 설정하여 Cloud Functions에서 제공하는 Runtime 소스코드를 활용할 수 있습니다. Cloud Functions에서 제공하는 Blueprint 항목은 다음을 참조하세요.
| 구분 | 상세 설명 | 비고 |
|---|---|---|
| Hello World | 함수 호출 시 Hello Serverless World!를 응답합니다. | |
| Execution after timeout | 함수 호출 시간이 초과된 후에 실행되어야 하지만 실행되지 않는 코드를 출력합니다. | PHP, Python 미지원 |
| HTTP request body | Request Body를 파싱합니다. | PHP 미지원 |
| Send HTTP requests | Cloud 함수에서 HTTP 요청을 전송합니다. | PHP 미지원 |
| Print logs | 사용자의 Samsung Cloud Platform Console Request를 로그로 출력합니다. | PHP 미지원 |
| Throw a custom error | 에러 로직을 직접 입력하여 에러를 처리합니다. | |
| Using Environment Variable | Cloud 함수 내에 환경 변수를 구성하여 실행합니다. |
표. Blueprint 항목
Hello World
Hello World 응답 받기 설정 및 함수 호출 예시(함수 URL 이용)를 설명합니다.
Hello World 설정하기
Hello World를 설정하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
Function 목록 페이지에서 URL로 호출할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
구성 탭을 클릭한 후, 함수 URL 항목의 수정 버튼을 클릭하세요. 함수 URL 수정 팝업창이 열립니다.
함수 URL 수정 팝업창에서 활성화 여부를 사용으로 설정한 후, 확인 버튼을 클릭하세요.
구분 상세 설명 활성화 여부 함수 URL의 사용 여부를 설정 인증 유형 함수 URL에 대한 요청 시 IAM 인증 사용 여부 선택 접근 제어 접근 가능한 IP를 추가하여 관리 가능 - 사용으로 설정한 후, 퍼블릭 접근 IP 입력 및 추가 가능
표. 트리거 추가 시 필수 입력 항목코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; };Hello World - Node.js 소스코드 - Python 소스코드배경색 변경
import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps('Hello Serverless World!') }import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps('Hello Serverless World!') }Hello World - Python 소스코드 - PHP 소스코드배경색 변경
<?php function handle_request() { # User writing area (Function details) $res = array( 'statusCode' => 200, 'body' => 'Hello Serverless World!', ); return $res; } ?><?php function handle_request() { # User writing area (Function details) $res = array( 'statusCode' => 200, 'body' => 'Hello Serverless World!', ); return $res; } ?>Hello World - PHP 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, 응답을 확인합니다.
Hello Serverless World!
Execution after timeout
제한시간 이후 함수 실행(Execution after timeout) 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
Execution after timeout 설정하기
Execution after timeout을 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ console.log("Hello world 3"); await delay(3000); const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; }; const delay = (ms) => { return new Promise(resolve=>{ setTimeout(resolve,ms) }) }exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ console.log("Hello world 3"); await delay(3000); const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; }; const delay = (ms) => { return new Promise(resolve=>{ setTimeout(resolve,ms) }) }Execution after timeout - Node.js 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출하고 일정 시간이 지난 후, 응답을 확인합니다.
Hello Serverless World!
HTTP request body
Request Body 파싱하기 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
HTTP request body 설정하기
HTTP request body를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; return response; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; return response; };Execution after timeout - Node.js 소스코드 - Python 소스코드배경색 변경
import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps(params.json) }import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps(params.json) }Execution after timeout - Python 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, Body 데이터와 요청 Body값, 응답 Body값을 확인합니다.
요청 Body값
배경색 변경{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }요청 Body 값 응답 Body값
배경색 변경{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }응답 Body 값
Send HTTP requests
HTTP 요청하기 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
Send HTTP requests 설정하기
Send HTTP requests를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { // Port 80 and Port 443 are available url = "https://example.com"; // Destination URL const options = { uri: url, method:'GET', json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { // Port 80 and Port 443 are available url = "https://example.com"; // Destination URL const options = { uri: url, method:'GET', json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }Send HTTP requests - Node.js 소스코드 - Python 소스코드배경색 변경
import json import requests def handle_request(params): # User writing area (Function details) # Port 80 and Port 443 are available url = "https://example.com" # Destination URL try: response = requests.get(url, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)import json import requests def handle_request(params): # User writing area (Function details) # Port 80 and Port 443 are available url = "https://example.com" # Destination URL try: response = requests.get(url, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)Send HTTP requests - Python 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, 응답을 확인합니다.
배경색 변경
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html><!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>Print logs
Log 출력하기 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
Print logs 설정하기
Print logs 응답 받기를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
const winston = require('winston'); // Log module setting const logger = winston.createLogger({ format: winston.format.combine( winston.format.timestamp(), winston.format.printf(info => info.timestamp + ' ' + info.level + ': ' + info.message) ), transports: [ new winston.transports.Console() ] }); exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; logger.info(JSON.stringify(response, null, 2)); return response; };const winston = require('winston'); // Log module setting const logger = winston.createLogger({ format: winston.format.combine( winston.format.timestamp(), winston.format.printf(info => info.timestamp + ' ' + info.level + ': ' + info.message) ), transports: [ new winston.transports.Console() ] }); exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; logger.info(JSON.stringify(response, null, 2)); return response; };Print logs - Node.js 소스코드 - Python 소스코드배경색 변경
import json import logging # Log module setting logging.basicConfig(level=logging.INFO) def handle_request(params): # User writing area (Function details) response = { 'statusCode': 200, 'body': json.dumps(params.json) } logging.info(response) return responseimport json import logging # Log module setting logging.basicConfig(level=logging.INFO) def handle_request(params): # User writing area (Function details) response = { 'statusCode': 200, 'body': json.dumps(params.json) } logging.info(response) return responsePrint logs - Python 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, 로그 탭에서 로그를 확인합니다.
배경색 변경
[2023-09-07] 12:06:23] "host": "scf-xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-id": "xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-source": "xxxxxxxxxxxxxxxxxxxxx",[2023-09-07] 12:06:23] "host": "scf-xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-id": "xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-source": "xxxxxxxxxxxxxxxxxxxxx",Throw a custom error
커스텀 에러 발생(Throw a custom error) 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
Throw a custom error 설정하기
Throw a custom error를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
class CustomError extends Error { constructor(message) { super(message); this.name = 'CustomError'; } } exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ throw new CustomError('This is a custom error!'); };class CustomError extends Error { constructor(message) { super(message); this.name = 'CustomError'; } } exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ throw new CustomError('This is a custom error!'); };Throw a custom error - Node.js 소스코드 - Python 소스코드배경색 변경
class CustomError(Exception): def __init__(self, message): self.message = message def handle_request(parmas): raise CustomError('This is a custom error!')class CustomError(Exception): def __init__(self, message): self.message = message def handle_request(parmas): raise CustomError('This is a custom error!')Throw a custom error - Python 소스코드 - PHP 소스코드배경색 변경
<?php class CustomError extends Exception { public function __construct($message) { parent::__construct($message); $this->message = $message; } } function handle_request() { throw new CustomError('This is a custom error!'); } ?><?php class CustomError extends Exception { public function __construct($message) { parent::__construct($message); $this->message = $message; } } function handle_request() { throw new CustomError('This is a custom error!'); } ?>Throw a custom error - PHP 소스코드
- Node.js 소스코드
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, 로그 탭에서 에러 발생 여부를 확인합니다.
Using Environment Variable
환경 변수 사용(Using Environment Variable) 설정 및 함수 호출 예시(함수 URL 사용)를 설명합니다.
Using Environment Variable 설정하기
Using Environment Variable를 설정하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 트리거를 설정할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- 트리거 탭을 클릭한 후, 트리거 추가 버튼을 클릭하세요. 트리거 추가 팝업창이 열립니다.
- 트리거 추가 팝업창에서 트리거 종류 항목을 선택한 후, 하단에 표시되는 필수 정보를 입력하고 확인 버튼을 클릭하세요.
- 필수 정보는 트리거 종류에 따라 달라집니다.
트리거 종류 입력 항목 API Gateway - API명: 기존에 생성된 API를 선택하거나 새로 생성 가능
- 스테이지: 기존에 생성된 스테이지를 선택하거나 새로 생성 가능
Cronjob - 예시를 참고하여 트리거의 반복 빈도(분, 시, 일, 월, 요일)를 입력
- Timezone 설정: 적용할 기준 시간대를 선택
표. 트리거 추가 시 필수 입력 항목
- 필수 정보는 트리거 종류에 따라 달라집니다.
- 코드 탭으로 이동한 후, 수정 버튼을 클릭하세요. Function 코드 수정 페이지로 이동합니다.
- 성공 및 실패 케이스에 대한 처리 로직을 추가한 후, 저장 버튼을 클릭하세요.
- Node.js 소스코드배경색 변경
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ return process.env.test; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ return process.env.test; };Using Environment Variable - Node.js 소스코드 - Python 소스코드배경색 변경
import json import os def handle_request(params): # User writing area (Function details) return os.environ.get("test")import json import os def handle_request(params): # User writing area (Function details) return os.environ.get("test")Using Environment Variable - Python 소스코드 - PHP 소스코드배경색 변경
import json def handle_request(params): # User writing area (Function details) return os.environ.get("test")import json def handle_request(params): # User writing area (Function details) return os.environ.get("test")Using Environment Variable - PHP 소스코드
- Node.js 소스코드
- 구성 탭으로 이동한 후, 환경 변수 영역의 수정 버튼을 클릭하세요. 환경 변수 수정 팝업창이 열립니다.
- 환경 변수 정보를 입력한 후, 확인 버튼을 클릭하세요.
구분 상세 설명 이름 Key값을 입력 값 Value값을 입력 표. 환경 변수 입력 항목
함수 호출 확인하기
Function 상세 페이지의 구성 탭에서 함수 URL을 호출한 후, 로그 탭에서 환경 변수값을 확인합니다.
6.2.4 - PrivateLink 서비스 연계하기
Cloud Functions와 PrivateLink 서비스를 연계하여 Samsung Cloud Platform 내부의 VPC와 VPC, VPC와 서비스를 외부 인터넷 없이 연결할 수 있습니다.
데이터가 내부 네트워크만 이용하게되어 보안성이 높고, 퍼블릭 IP, NAT, VPN, 인터넷 게이트웨이 등이 필요하지 않습니다.
PrivateLink 서비스 활성화하기
PrivateLink Service를 연계하기 위해 서비스를 먼저 활성화해야 합니다.
PrivateLink 서비스를 활성화하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 PrivateLink를 연계할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- Function 상세 페이지에서 구성 탭을 클릭하세요.
- Private 연결 구성에서 PrivateLink Service의 수정 버튼을 클릭하세요. PrivateLink Service 수정 팝업창이 열립니다.
- PrivateLink Service 수정 팝업창에서 활성화 여부의 사용 항목을 체크한 후, 확인 버튼을 클릭하세요. 구성 탭의 Private 연결 구성에 PrivateLink Service 정보가 표시됩니다.
| 구분 | 상세 설명 |
|---|---|
| Private URL | PrivateLink Service URL 정보 |
| PrivateLink Service ID | PrivateLink Service ID 정보 |
| 요청 Endpoint 관리 | PrivateLink Service 연결을 요청한 PrivateLink Endpoint 목록
|
표. PrivateLink Service 상세 정보 항목
PrivateLink 서비스 연계하기
PrivateLink Service를 연계하여 함수를 다른 VPC에서 프라이빗하게 접근할 수 있도록 노출시킬 수 있습니다.
안내
PrivateLink Service를 먼저 활성화한 후, 연계 작업을 진행하세요.
PrivateLink 서비스를 연계하려면 다음 작업을 확인하세요.
- 발급된 Private URL 호출을 위하여 PrivateLink Endpoint의 IP주소와 Private URL 주소에 대한 도메인을 등록하세요.
192.168.0.13 abc123.scf.private.kr-west1.qa2.samsungsdscloud.com - PrivateLink Service 호출 시 필요한 Endpoint 생성자의 인증 정보를 기반으로 IAM 인증을 확인하세요.
x-scf-access-keyx-scf-secret-key
PrivateLink Endpoint 생성하기
사용자 VPC의 PrivateLink Service에 접근하기 위한 Entry Point를 생성합니다.
주의
Endpoint 생성 시 추가 비용이 발생할 수 있습니다.
PrivateLink Endpoint를 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Function 메뉴를 클릭하세요. Function 목록 페이지로 이동합니다.
- Function 목록 페이지에서 PrivateLink를 연계할 자원을 클릭하세요. Function 상세 페이지로 이동합니다.
- Function 상세 페이지에서 구성 탭을 클릭하세요.
- Private 연결 구성에서 PrivateLink Endpoint의 추가 버튼을 클릭하세요. PrivateLink Endpoint 추가 팝업창이 열립니다.
- PrivateLink Service 추가 팝업창에서 PrivateLink Service ID와 Alias 정보를 입력한 후, 확인 버튼을 클릭하세요.
- 생성을 알리는 팝업창이 열리면 확인 버튼을 클릭하세요. 구성 탭의 Private 연결 구성에 PrivateLink Endpoint 정보가 표시됩니다.
| 구분 | 상세 설명 |
|---|---|
| PrivateLink Endpoint ID | PrivateLink Endpoint ID 정보 |
| PrivateLink Service ID | PrivateLink Service ID 정보 |
| Alias | PrivateLink Endpoint 접근을 위해 IP 주소 대신 사용 가능한 hostalias 정보 |
| 상태 | PrivateLink Endpoint의 승인 상태
|
표. PrivateLink Endpoint 상세 정보 항목
APIGW Private EPS 연계하기
SCF Endpoint와 APIGW Private Endpoint를 연결하려면 SCF Endpoint Alias에 APIGW EPS의 resource path를 대신하여 Private URL을 기재해야 합니다.
- Private URL 예시:
181b6126ef6d4e4b81370df5.apigw.private.kr-west1.s.samsungsdscloud.com/get/resourcepath
APIGW Private EPS 연계하려면 다음 코드를 참조하세요.
배경색 변경
const request = require('request');
/**
* @description User writing area (Function details)
*/
exports.handleRequest = async function (params) {
return await sendRequest(params);
};
async function sendRequest(req) {
return new Promise((resolve, reject) => {
// Port 80 and Port 443 are available
url = "https://{alias}/{resource_path}"; // Destination URL
/**
{alias}는 함수 내에서 Endpoint 생성 시 입력한 alias명
{resoure_path}는 APIGW EPS의 Private URL에서 지정한 resource path (/get/resourcepath)
*/
const options = {
uri: url,
method:'GET',
json: true,
strictSSL: false,
rejectUnauthorized: false
}
request(options, (error, response, body) => {
if (error) {
reject(error);
} else {
resolve({
statusCode: response.statusCode,
body: JSON.stringify(body)
});
}
});
});
}const request = require('request');
/**
* @description User writing area (Function details)
*/
exports.handleRequest = async function (params) {
return await sendRequest(params);
};
async function sendRequest(req) {
return new Promise((resolve, reject) => {
// Port 80 and Port 443 are available
url = "https://{alias}/{resource_path}"; // Destination URL
/**
{alias}는 함수 내에서 Endpoint 생성 시 입력한 alias명
{resoure_path}는 APIGW EPS의 Private URL에서 지정한 resource path (/get/resourcepath)
*/
const options = {
uri: url,
method:'GET',
json: true,
strictSSL: false,
rejectUnauthorized: false
}
request(options, (error, response, body) => {
if (error) {
reject(error);
} else {
resolve({
statusCode: response.statusCode,
body: JSON.stringify(body)
});
}
});
});
}6.3 - API Reference
API Reference
6.4 - CLI Reference
CLI Reference
6.5 - Release Note
Cloud Functions
2025.12.16
FEATURE
AIOS, PrivateLink 서비스 연계- AIOS 서비스와 연계하여 함수를 이용할 수 있습니다.
- Cloud Functions와 AIOS를 연계하여 LLM을 활용할 수 있습니다.
- PrivateLink 서비스와 연계하여 함수를 이용할 수 있습니다.
- Private 연결(PrivateLink)을 통해 Samsung Cloud Platform의 VPC와 VPC, VPC와 서비스 사이에 인터넷을 거치지 않고 내부적 연결할 수 있습니다.
2025.10.23
FEATURE
Java Runtime 실행 파일 업로드 기능 추가- Java Runtime 실행 파일을 업로드하는 기능이 추가되었습니다.
- Object Storage에 Java Runtime 실행 압축 파일(.jar/.zip)을 가져와서 설정할 수 있습니다.
2025.07.01
NEW
Cloud Functions 서비스 정식 버전 출시- Cloud Functions 서비스를 정식 출시하였습니다.
- 서버 프로비저닝 필요 없이 함수 형태의 애플리케이션을 간편하게 실행하는 서버리스 컴퓨팅 기반의 FaaS (Function as a Service)입니다.
7 - Virtual Server DR
각종 재해 상황 및 위험 요소에 의해 시스템이 중단되었을 때 다른 리전의 Virtual Server에 연결된 Block Storage를 복제하여 빠른 시간 안에 정상적인 운영 상태로 복구할 수 있습니다.
7.1 - Overview
서비스 개요
Virtual Server DR은 현재 사용 중인 리전과 다른 리전에 있는 Virtual Server 및 연결된 Block Storage를 복제하여 빠르게 시스템을 복구할 수 있는 서비스입니다. 각종 재해 상황 및 예기치 못한 상황으로 시스템이 중단되더라도 Virtual Server DR을 이용하여 신속하게 정상 운영 상태로 복구할 수 있습니다.
안내
- Virtual Server DR 서비스는 Samsung Cloud Platform의 Marketplace에서 판매하고 있는 파트너 솔루션을 통해 구성할 수 있습니다.
- Marketplace 이용에 대한 자세한 내용은 Marketplace를 참고하세요.
주의
- Marketplace에서 판매되는 서비스를 구매하여 사용하는 경우, Marketplace 소프트웨어 공급사와의 별도 계약에 따라 위탁 세금계산서가 발행됩니다.
- Marketplace에서 Virtual Server DR용 파트너 솔루션 상품을 신청한 경우, 신청 정보가 담당자에게 메일로 발송됩니다. 상품 상세 사항 및 일정은 담당자와 조율하세요. 확정된 날짜를 기준으로 소프트웨어 설치와 비용이 청구됩니다.
- Samsung Cloud Platform의 Marketplace에서 판매되는 서비스는 개별 판매자가 판매하는 서비스로써, 삼성SDS는 통신판매중개자이며 통신판매의 당사자가 아닙니다. 따라서 삼성SDS는 개별 판매자가 판매하는 서비스 정보 및 거래에 대하여 보증하거나 책임을 지지 않습니다.
특장점
- 손쉬운 DR 환경 구성: Samsung Cloud Platform의 Marketplace에서 파트너 솔루션을 통해 DR 구성을 위한 Virtual Server를 간편하게 구성할 수 있습니다.
- 다양한 환경 구성: 파트너 솔루션을 이용하여 물리 to 가상 환경(P2V), 가상 to 가상 환경(V2V) 등의 다양한 환경을 구성할 수 있으며, 다수의 운영체제(Windows, Linux)를 지원합니다.
서비스 구성도
제공 기능
주요 기능은 Samsung Cloud Platform의 Marketplace에서 판매하고 있는 파트너 솔루션의 상품 Catalog 상세 페이지를 참고해주세요.
참고
Marketplace 이용에 대한 자세한 내용은 Marketplace를 참고하세요.
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
| Compute | Virtual Server | 클라우드 컴퓨팅에 최적화된 가상 서버 |
표. Virtual Server DR 선행 서비스
7.2 - Release Note
Virtual Server DR
2025.07.01
NEW
Virtual Server DR 서비스 정식 출시- Virtual Server DR 서비스를 정식 출시하였습니다.
- 각종 재해 상황 및 위험 요소에 의해 시스템이 중단되었을 때 빠른 시간 안에 정상 운영 상태로 복구할 수 있습니다.
8 - Block Storage
8.1 - Overview
서비스 개요
Block Storage는 일정 크기와 배열로 정렬된 블록 단위에 데이터를 저장하는 고성능 스토리지 입니다.
데이터베이스, 메일 서버 등과 같은 대용량, 고성능 요건에 적합하며 사용자는 서버에 볼륨을 직접 할당하여 사용할 수 있습니다.
특장점
- 대용량 볼륨 제공: OS 구성용 볼륨은 이미지 별 최소 용량 이상으로 생성되어 12TB 이내로 증설이 가능하고, OS 외 데이터 저장 볼륨은 최소 8GB에서 최대 12TB 이내의 용량으로 생성 및 증설할 수 있습니다. 용량 증설은 온라인 상태에서 안정적으로 진행됩니다.
- Full SSD 기반 고성능 제공: 이중화 된 Controller 및 Disk Array Raid 기반으로 높은 내구성과 가용성을 제공합니다. Full SSD 디스크가 기본 제공되므로 데이터베이스 워크로드 등 고속 데이터 처리 업무에 적합합니다.
- 스냅샷 백업: 이미지 스냅샷 기능을 통해 변경 및 삭제된 데이터의 복구가 가능합니다. 사용자는 목록에서 복구하고자 하는 시점에 생성된 스냅샷을 선택하여 복구를 수행합니다.
서비스 구성도
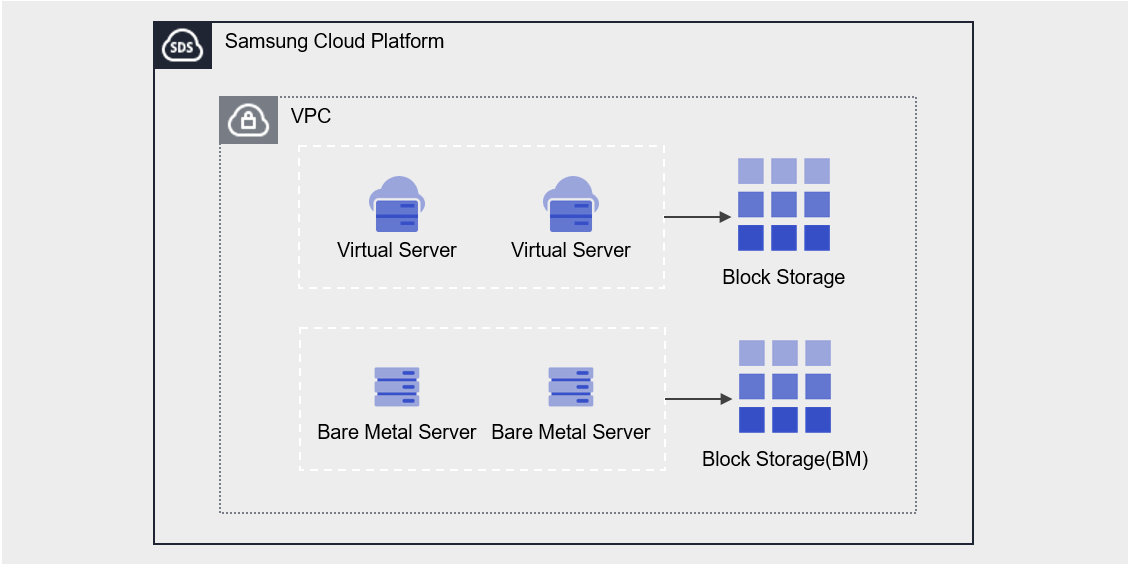
제공 기능
Block Storage는 다음과 같은 기능을 제공하고 있습니다.
- 볼륨명: 사용자는 볼륨별로 이름을 설정 또는 수정할 수 있습니다.
- 용량: 최소 8GB에서 최대 12TB 이내의 용량으로 볼륨 생성이 가능하며, 사용 중 증설할 수 있습니다. OS 기본 볼륨은 이미지별 최소 용량 이상으로 생성할 수 있습니다.
- 연결 서버: Virtual Server를 선택하여 연결 또는 연결 해제할 수 있습니다.
- 다중 서버 연결(Multi Attach): 2개 이상의 서버에 연결, 볼륨당 연결 서버 대수 제약 없으며 Virtual Server는 최대 26개의 볼륨 연결 가능
- 암호화: Block Storage의 모든 볼륨에는 AES-256 알고리즘 암호화가 기본으로 적용되며, 볼륨이 HDD/SSD_KMS 디스크 유형일 경우에는 인스턴스와 인스턴스에 연결된 Block Storage 구간의 전송 암호화를 추가로 제공합니다.
- 스냅샷: 이미지 스냅샷 기능을 통하여 변경 및 삭제된 데이터의 복구가 가능합니다. 사용자는 목록에서 복구하고자 하는 시점에 생성된 스냅샷을 선택하여 복구합니다.
- 볼륨 이전: 볼륨 이전 기능을 통하여 다른 Account로 볼륨을 이전할 수 있습니다.
- 모니터링: IOPS, Latency, Throughput, 사용량 등 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
구성 요소
사용자의 서비스 규모 및 성능 요건에 따라 용량을 입력하고 디스크 타입을 선택하여 볼륨을 생성할 수 있습니다. 스냅샷 기능 활용 시에는 복구하고자 하는 시점으로 데이터를 복구할 수 있습니다.
볼륨
볼륨(Volume)은 Block Storage 서비스의 기본 생성 단위이며 데이터 저장 공간으로 사용됩니다. 사용자는 이름, 용량, 디스크 유형을 선택하여 볼륨을 생성한 후 Virtual Server에 연결하여 사용합니다.
볼륨명 생성 규칙은 다음과 같습니다.
참고
영문, 숫자, 공백과 특수문자(
-, _) 사용하여 255자 이내로 입력하세요.스냅샷
스냅샷(Snapshot)은 특정 시점 볼륨의 이미지 백업본 입니다. 사용자는 스냅샷 목록에서 스냅샷 명과 생성 일시를 확인하여 복구하고자 하는 스냅샷을 선택할 수 있으며 해당 스냅샷을 통하여 변경하거나 삭제한 데이터를 복구할 수 있습니다.
스냅샷 사용 시 참고 사항은 다음과 같습니다.
참고
- 스냅샷 생성 일시는 Asia/Seoul(GMT +09:00) 기준입니다.
- 스냅샷 복구 버튼을 선택하여, Block Storage 볼륨을 가장 최신의 스냅샷으로 복구할 수 있습니다.
- 스냅샷 목록에서 특정 스냅샷을 선택하는 경우, 스냅샷 기반의 신규 볼륨을 생성하는 방식으로 복구할 수 있습니다.
- 스냅샷은 원본 Block Storage의 크기에 따라 요금이 부과되오니 불필요한 스냅샷은 삭제하시기 바랍니다.
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Compute | Virtual Server | 클라우드 컴퓨팅에 최적화된 가상 서버 |
표. Block Storage 선행 서비스
8.1.1 - 모니터링 지표
Block Storage 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Block Storage의 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
| 성능항목 명 | 설명 | 단위 |
|---|---|---|
| Volume Total | 총 바이트 수 | bytes |
| IOPS [Read] | iops(읽기) | iops |
| IOPS [Write] | iops(쓰기) | iops |
| Latency Time [Read] | 지연 시간(읽기) | usec |
| Latency Time [write] | 지연 시간(쓰기) | usec |
| Throughput [Read] | 처리량(읽기) | bytes/s |
| Throughput [Write] | 처리량(쓰기) | bytes/s |
표. Block Storage 모니터링 지표
8.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Block Storage의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Block Storage 생성하기
Samsung Cloud Platform Console에서 Block Storage 서비스를 생성하여 사용할 수 있습니다.
Block Storage를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
Block Storage 페이지에서 서비스 생성 버튼을 클릭하세요. Block Storage 생성 페이지로 이동합니다.
Block Storage 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
구분 필수 여부상세 설명 볼륨명 필수 볼륨 이름 - 영문, 숫자, 공백과 특수문자(
-,_) 사용하여 255자 입력
스냅샷명 선택 스냅샷을 통해 볼륨을 생성할 경우에 사용할 스냅샷 선택 - 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시, 복구 스냅샷명 제공
- 미선택 시 빈 볼륨이 생성
- 선택 후, 이름 옆의 X 버튼을 클릭하여 삭제 가능
디스크 유형 필수 디스크 유형 선택 - HDD: 일반 볼륨
- SSD: 고성능 일반 볼륨
- HDD/SSD_KMS: 인스턴스와 Block Storage 간 전송 암호화를 추가로 제공하는 볼륨
- HDD/SSD_MultiAttach: 2개 이상의 서버 연결이 가능한 볼륨
- 서비스 생성 후 수정 불가
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본과 동일하게 설정되며 수정이 불가함
용량 선택 용량 설정 - 8~12,228GB 이내로 생성 가능
- 8GB 단위로 제공되는 Unit 개수 입력
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본보다 크거나 같은 용량으로 입력
표. Block Storage 서비스 정보 입력 항목- 영문, 숫자, 공백과 특수문자(
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Block Storage 목록 페이지에서 생성한 자원을 확인하세요.
참고
- Block Storage의 모든 볼륨에는 AES-256 AES-256 알고리즘 암호화가 기본으로 적용됩니다.
- Windows 기반의 Virtual Server는 MultiAttach 디스크를 사용할 수 없습니다. 별도의 복제 방식이나 솔루션을 사용하세요.
- 볼륨이 HDD/SSD_KMS 디스크 유형일 경우에는 인스턴스와 인스턴스에 연결된 Block Storage 구간의 전송 암호화를 추가로 제공합니다.
주의
HDD/SSD_KMS 디스크 유형을 사용하는 경우 약 60%의 성능 저하가 발생할 수 있습니다.
Block Storage 상세 정보 확인하기
Block Storage 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Block Storage 상세 페이지는 상세 정보, 스냅샷 목록, 태그, 작업 이력 탭으로 구성되어 있습니다.
Block Storage 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- Block Storage 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 스냅샷 목록, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 볼륨 상태 볼륨의 상태 - Creating: 생성 중
- Downloading: 생성 중 (OS 이미지 적용)
- Available: 생성 완료, 서버 연결 가능
- Reserved: 서버 연결 대기
- Attaching: 서버 연결 중
- Detaching: 서버 연결 해제
- In Use: 서버 연결 완료
- Deleting: 서비스 해지 중
- Awaiting Transfer: 볼륨 이전 대기
- Extending: 용량 증설
- Error Extending: 용량 증설 중 비정상 상태
- Backing Up: 볼륨 백업 중
- Restoring Backup: 볼륨 백업 복구 중
- Error Backing Up: 볼륨 백업 비정상 상태
- Error Restoring: 볼륨 백업 복구 비정상 상태
- Error Deleting: 삭제 중 비정상 상태
- Error Managing: 비정상 상태
- Error: 비정상 상태
- Maintenance: 일시적 유지 보수 상태
- Reverting: 스냅샷 복구 중
볼륨 이전 다른 Account로 볼륨을 이전 - 볼륨 이전에 대한 자세한 내용은 볼륨 이전 참고
스냅샷 생성 생성 시점의 스냅샷을 즉시 생성 - 스냅샷 생성에 대한 자세한 내용은 스냅샷 생성하기 참고
스냅샷 복구 Available 상태의 최신 스냅샷으로 볼륨을 복구 - 스냅샷 복구에 대한 자세한 내용은 스냅샷 복구하기 참고
서비스 해지 서비스를 해지하는 버튼 표. 상태 정보 및 부가 기능
- Block Storage 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 스냅샷 목록, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
Block Storage 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스군 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스를 수정한 사용자 |
| 수정 일시 | 서비스를 수정한 일시 |
| 볼륨명 | 볼륨 이름
|
| 볼륨 ID | 볼륨 고유 ID |
| 디스크 유형 | 디스크 유형 |
| 종류 | 볼륨 생성 방식 및 용도에 따른 구분 |
| 용량 | 볼륨 용량
|
| 연결 서버 | 연결된 Virtual Server
|
표. Block Storage 상세 정보 항목
참고
vProtect명이 포함된 볼륨은 Backup 서비스 이용 시 생성되는 임시 볼륨이며 요금이 부과되지 않습니다.
스냅샷 목록
Block Storage 목록 페이지에서 선택한 자원의 스냅샷을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 스냅샷명 | 스냅샷 이름 |
| 설명 | 스냅샷 설명 |
| 볼륨 용량 | 스냅샷 대상 Block Storage 원본 볼륨의 용량
|
| 생성 일시 | 스냅샷 생성 일시 |
| 상태 | 스냅샷의 상태
|
| 추가기능 > 더보기 | 스냅샷 관리 버튼
|
표. 스냅샷 목록 탭 상세 정보 항목
주의
- 스냅샷은 볼륨의 용량 관리에 영향을 줄 수 있습니다. 사용 후 불필요한 스냅샷은 삭제하세요.
- 스냅샷 복구는 서버에 연결되어 있지 않은 상태에서 가능합니다.
참고
- 스냅샷 생성 일시는 Asia/Seoul (GMT +09:00) 기준 입니다.
- 스냅샷 복구 버튼 클릭 시 해당 볼륨은 Available 상태의 최신 스냅샷으로 복구됩니다.
- 스냅샷 목록 페이지에서 복구 볼륨 생성 선택 시 기존 볼륨 변경 없이 스냅샷 기반의 신규 볼륨이 생성됩니다.
- vProtect명이 포함된 스냅샷은 Backup 서비스 이용 시 생성되는 임시 스냅샷이며 요금이 부과되지 않습니다.
태그
Block Storage 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Block Storage 태그 탭 항목
작업 이력
Block Storage 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. 작업 이력 탭 상세 정보 항목
Block Storage 자원 관리하기
생성된 Block Storage의 설정을 수정하거나 연결 서버 추가 또는 삭제가 필요한 경우, Block Storage 상세 정보 페이지에서 작업을 수행할 수 있습니다.
볼륨명 수정하기
볼륨의 이름을 수정할 수 있습니다. 볼륨명을 수정을 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 볼륨명을 수정할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 볼륨명의 수정 버튼을 클릭하세요. 볼륨명 수정 팝업창이 열립니다.
- 볼륨명 입력하고, 확인 버튼을 클릭하세요.
참고
영문, 숫자, 공백과 특수문자(
-, _) 사용하여 255자 이내로 입력하세요.용량 증설하기
볼륨의 용량을 증설할 수 있습니다. 용량을 증설하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 용량을 증설할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 용량의 수정버튼을 클릭하세요. 용량 수정 팝업창이 열립니다.
- 용량을 입력하고, 확인 버튼을 클릭하세요.
주의
- 용량 축소는 제공하지 않습니다.
- 용량 증설 후에는 증설 전의 스냅샷으로 복구되지 않습니다.
- 용량 증설 이전에 생성한 스냅샷으로는 신규 볼륨 생성 방식의 복구만 가능합니다.
참고
- 8~12,228GB 이내에서 기존 용량보다 큰 용량으로 증설 가능합니다.
- 8GB 단위로 제공되는 Unit 개수를 입력하세요.
연결 서버 수정하기
서버를 연결하거나 연결 해제할 수 있습니다. 연결 서버를 수정 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 연결 서버를 수정할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- Virtual Server 연결을 추가하는 경우 연결 서버 항목의 추가 버튼을 클릭하세요. 연결 서버 추가 팝업창이 열립니다.
- 연결하고자 하는 Virtual Server 선택 후 확인 버튼을 클릭하세요.
- Virtual Server 연결을 해제하는 경우 연결 서버 항목에서 연결 해제 버튼을 클릭하세요.
- 반드시 서버에서 연결 해제 작업(Umount, Disk Offline) 후 해제를 진행하세요.
주의
서버에 접속하여 반드시 연결 해제 작업(Umount, Disk Offline)을 수행한 후 연결 서버를 해제하세요. OS 작업 없이 해제하는 경우 연결 서버에서 상태 오류(Hang)가 발생할 수 있습니다. 서버 연결 해제에 대한 자세한 내용은 서버 연결 해제하기를 참고하세요.
참고
- Block Storage와 동일한 위치에 생성된 Virtual Server를 연결할 수 있습니다.
- Server Group 정책으로 Partition을 사용하는 Virtual Server는 연결할 수 없습니다.
- HDD/SSD_MultiAttach 디스크 유형의 경우 2개 이상의 Virtual Server와 연결할 수 있으며 연결 개수 제약은 없습니다.
- Windows 기반의 Virtual Server는 MultiAttach 디스크를 사용할 수 없으며, 별도의 복제 방식이나 솔루션을 사용해야 합니다.
- Virtual Server는 OS 기본 포함 최대 26개의 볼륨을 연결할 수 있습니다.
- OS 기본 볼륨은 연결 서버 수정 및 서비스 해지가 불가합니다.
- 연결 서버 추가 시 서버에서 연결 작업(Mount, Disk Online) 수행 후 사용할 수 있습니다. 서버 연결에 대한 자세한 내용은 서버 연결하기를 참고하세요.
Block Storage 해지하기
사용하지 않는 Block Storage을 해지하여 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
- 해지 후에는 데이터를 복구할 수 없으므로 주의하세요.
- 아래의 경우 Block Storage 볼륨을 해지할 수 없습니다.
- 서버 연결 중
- OS 기본 볼륨
- Virtual Server의 Custom 이미지와 연결
- 볼륨 상태가 Available, Error, Error Extending, Error Restoring, Error Managing 아닌 경우
- 2개 이상의 볼륨을 선택하여 해지하는 경우, 해지 가능한 볼륨만 해지됩니다.
Block Storage를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Block Storage 목록 페이지에서 자원이 해지 되었는지 확인하세요.
8.2.1 - 서버 연결하기
서버에서 볼륨 사용 시에는 연결 작업 또는 연결 해제 작업이 필요합니다.
Block Storage 상세 페이지에서 연결 서버를 추가한 후 서버에 접속하여 연결 작업(Mount, Disk Online)을 수행하세요. 사용 완료 후에는 연결 해제 작업(Umount, Disk Offline) 수행한 후 연결 서버를 제거합니다.
서버 연결하기(Mount, Disk Online)
연결 서버에 추가된 볼륨을 사용하기 위해서는 서버에 접속 후 연결 작업(Mount, Disk Online)을 수행해야 합니다. 다음 절차를 따르세요.
Linux 운영 체제
서버 연결 예시 구성
- 서버 OS: LINUX
- 마운트 위치: /data
- 볼륨 용량: 24 GB
- 파일 시스템: ext3, ext4, xfs etc
- 추가 할당된 디스크: /dev/vdb
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 연결 서버에서 사용할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 연결 서버 항목에서 서버 확인 후 접속하세요.
- 아래 절차 참고하여 볼륨을 연결(Mount) 하세요.
root 권한으로 전환
$ sudo -i디스크 확인
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 disk파티션 생성
# fdisk /dev/vdb Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): p Partition number (1-4, default 1): 1 First sector (2048-50331646, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-50331646, default 50331646): Created a new partition 1 of type 'Linux' and of size 24 GiB. Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.파티션 포맷 설정 (예시: ext4)
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 disk └─vdb1 252:17 0 24G 0 part # mkfs.ext4 /dev/vdb1 mke2fs 1.46.5 (30-Dec-2021) ... Writing superblocks and filesystem accounting information: done볼륨 Mount
# mkdir /data # mount /dev/vdb1 /data # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 disk └─vdb1 252:17 0 24G 0 part /data # vi /etc/fstab (추가) /dev/vdb1 /data ext4 defaults 0 0
| 항목 | 설명 |
|---|---|
| cat /etc/fstab | 파일시스템 정보 파일
|
| df -h | Mount된 전체 디스크 사용량을 확인 |
| fdisk -l | 파티션 정보를 확인
|
표. Mount 명령어 참고
| 명령어 | 설명 |
|---|---|
| m | fdisk 명령어의 사용법을 확인 |
| n | 신규 파티션을 생성 |
| p | 변경된 파티션 정보를 확인 |
| t | 파티션의 시스템 ID를 변경 |
| w | 파티션 정보 저장 후 fdisk 설정을 종료 |
표. 파티션 생성 명령어(fdisk) 참고
Windows 운영 체제
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 연결 서버에서 사용할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 연결 서버 항목에서 서버 확인 후 접속하세요.
- 아래 절차 참고하여 볼륨을 연결(Disk Online) 하세요.
Windows 시작 아이콘 우클릭 후,
Computer Management를 실행Computer Management 트리 구조에서
Storage > Disk Management선택디스크 확인
디스크 Online
디스크 초기화
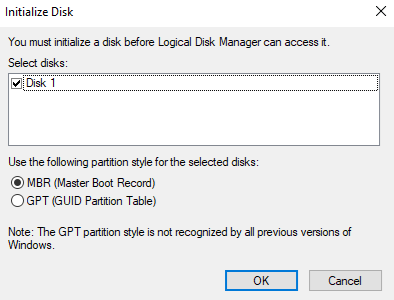
파티션 포맷
볼륨 확인
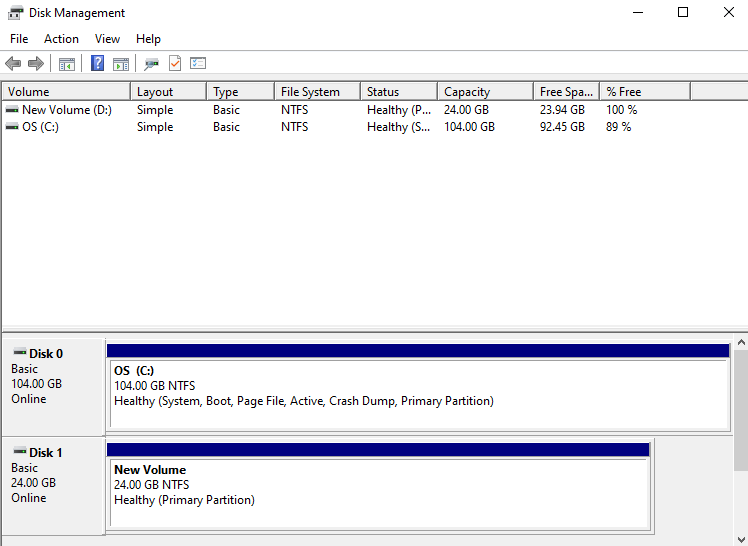
서버 연결 해제하기(Umount, Disk Offline)
서버 접속하여 연결 해제 작업(Umount, Disk Offline)을 진행하고, Console에서 연결 서버를 해제해야 합니다.
다음 절차를 따르세요.
주의
- 서버에서 연결 해제 작업(Umount, Disk Offlline)을 하지 않고 Console에서 연결 서버를 해제하는 경우에는 서버 상태 오류(Hang)가 발생할 수 있습니다.
- 반드시 OS 작업을 먼저 진행하세요.
- OS 기본 볼륨의 경우 연결 서버 수정 및 서비스 해지가 불가합니다.
Linux 운영 체제
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 연결 서버를 해제할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 연결 서버 항목에서 서버 확인 후 접속하세요.
- 아래 절차 참고하여 볼륨을 연결 해제(Umount) 하세요.
- 볼륨 Umount
# umount /dev/vdb1 /data
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 24G 0 disk
├─vda1 252:1 0 23.9G 0 part [SWAP]
└─vda14 252:14 0 4M 0 part /
└─vda15 252:15 0 106M 0 part /boot/efi
vdb 252:16 0 24G 0 disk
└─vdb1 252:17 0 24G 0 part
# vi /etc/fstab
(삭제) /dev/vdb1 /data ext4 defaults 0 0
Windows 운영 체제
모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
Block Storage 목록 페이지에서 연결 서버를 해제할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
연결 서버 항목에서 서버 확인 후 접속하세요.
마운트 된 파일 시스템을 해제하세요.
아래 절차 참고하여 볼륨을 연결 해제(Disk Offline) 하세요.
Windows 시작 아이콘 우클릭 후,
Computer Management를 실행Computer Management 트리 구조에서
Storage > Disk Management선택제거할 디스크 우클릭 후,
Offline을 실행
디스크 상태 확인
8.2.2 - 스냅샷 사용하기
생성된 Block Storage에 스냅샷을 생성, 삭제하거나 스냅샷을 이용하여 복구 할 수 있습니다. Block Storage 상세 페이지과 스냅샷 목록 페이지에서 작업을 수행할 수 있습니다.
스냅샷 생성하기
현재 시점의 스냅샷을 생성할 수 있습니다. 스냅샷을 생성 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 스냅샷을 생성할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 스냅샷 생성 버튼을 클릭하세요. 스냅샷 생성 팝업창이 열립니다.
- 스냅샷명과 설명을 입력하고 확인 버튼을 클릭하세요. 현재 시점의 스냅샷을 생성합니다.
- 스냅샷 목록 버튼을 클릭하세요. Block Storage 스냅샷 목록 페이지로 이동합니다.
- 생성된 스냅샷을 확인하세요.
주의
스냅샷은 원본 Block Storage의 크기에 따라 요금이 부과되오니 불필요한 스냅샷은 삭제하시기 바랍니다.
참고
스냅샷 생성 일시는 Asia/Seoul (GMT +09:00) 기준 입니다.
스냅샷 수정하기
스냅샷 정보를 수정할 수 있습니다. 스냅샷명 또는 설명을 수정 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 스냅샷 정보를 수정할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 스냅샷 목록 버튼을 클릭하세요. Block Storage 스냅샷 목록 페이지로 이동합니다.
- 수정할 스냅샷을 확인한 후 더보기 버튼을 클릭하세요.
- 수정 버튼을 클릭하세요. 스냅샷 수정 팝업창이 열립니다.
- 스냅샷명 또는 설명을 입력하고 확인 버튼을 클릭하세요.
스냅샷 복구하기
Block Storage 볼륨을 Available 상태의 최신 스냅샷으로 복구할 수 있습니다. 스냅샷 복구를 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 스냅샷으로 복구할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 연결 서버 항목에 추가된 서버가 있는 경우, 서버 접속 후 연결 해제 작업(Umount, Disk Offline) 수행하세요.
- 서버 연결 해제에 대한 자세한 내용은 서버 연결 해제하기를 참고하세요.
- Block Storage 상세 페이지에서 연결 서버 항목의 연결 해제 버튼을 클릭하여 서버를 제거하세요. 연결 서버가 제거됩니다.
- 연결 서버 해제에 대한 자세한 내용은 연결 서버 수정하기를 참고하세요.
- 스냅샷 목록 버튼을 클릭하세요. Block Storage 스냅샷 목록 페이지로 이동합니다.
- Available 상태의 최신 스냅샷을 확인하세요. 해당 스냅샷으로 볼륨이 복구됩니다.
- 스냅샷 복구 버튼을 클릭하세요. 스냅샷 복구 팝업창이 열립니다.
- 스냅샷명과 생성 일시를 확인한 후 확인 버튼을 클릭하세요.
- 복구 시작 시 Reverting, 완료 시 Available 상태가 됩니다.
- 상세 정보 페이지 버튼을 클릭하세요. Block Storage 상세 페이지으로 이동합니다.
- 연결 서버의 추가 버튼을 클릭하세요. Virtual Server를 다시 연결합니다.
- 연결 서버 추가에 대한 자세한 내용은 연결 서버 수정하기를 참고하세요.
- 추가된 서버에 접속 후 운영 체제에 따라 연결 작업(Mount, Disk Online)을 수행하세요.
- 서버 연결에 대한 자세한 내용은 서버 연결하기 를 참고하세요.
주의
- 스냅샷 복구는 서버에 연결되어 있지 않은 상태에서 가능합니다.
- 최신 스냅샷이 아닌 스냅샷으로 복구하고자 하는 경우, 복구 볼륨 생성을 통하여 복구 가능합니다.
- 아래 상황에서는 복구가 불가합니다.
- Block Storage 볼륨이 Available 상태가 아닌 경우
- Block Storage 볼륨에 연결 서버가 있는 경우
- 복구 가능한 스냅샷이 없는 경우
- 복구 생성 중 최신 스냅샷이 변경되는 경우
- 최신 스냅샷이 Available 상태가 아닌 경우
- 스냅샷의 볼륨 용량이 Block Storage 볼륨의 용량과 다른 경우 (볼륨을 증설한 경우)
스냅샷 복구 볼륨 생성하기
스냅샷을 이용하여 볼륨을 생성할 수 있습니다. 스냅샷 복구 볼륨을 생성 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 스냅샷 복구 볼륨을 생성할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 스냅샷 목록 버튼을 클릭하세요. Block Storage 스냅샷 목록 페이지로 이동합니다.
- 스냅샷명, 설명과 생성 일시를 확인 후 복구하고자 하는 스냅샷의 더보기 버튼을 클릭하세요.
- 복구 볼륨 생성을 클릭합니다. 스냅샷 복구 볼륨 생성 팝업창이 열립니다.
- 확인 버튼을 클릭하세요. Block Storage 생성 페이지로 이동합니다.
- Block Storage 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 볼륨명과 용량을 입력하세요. 원본 볼륨 보다 크거나 같은 용량으로 입력할 수 있습니다.
- 디스크 유형은 원본과 동일하게 설정되며 수정이 불가합니다.
구분 필수 여부상세 설명 볼륨명 필수 볼륨 이름 - 영문, 숫자, 공백과 특수문자(
-,_) 사용하여 255자 입력
디스크 유형 필수 디스크 유형 선택 - HDD: 일반 볼륨
- SSD: 고성능 일반 볼륨
- HDD/SSD_KMS: 인스턴스와 Block Storage 간 전송 암호화를 추가로 제공하는 볼륨
- HDD/SSD_MultiAttach: 2개 이상의 서버 연결이 가능한 볼륨
- 서비스 생성 후 수정 불가
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본과 동일하게 설정되며 수정이 불가함
용량 선택 용량 설정 - 8~12,228GB 이내로 생성 가능
- 8GB 단위로 제공되는 Unit 개수 입력
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본보다 크거나 같은 용량으로 입력
복구 스냅샷명 선택 볼륨 생성 시 사용한 복구 스냅샷의 이름 - 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시, 복구 스냅샷명 제공
표. Block Storage 서비스 정보 입력 항목 - 영문, 숫자, 공백과 특수문자(
- 요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Block Storage 목록 페이지에서 생성한 자원을 확인하세요.
스냅샷 삭제하기
스냅샷을 선택하여 삭제할 수 있습니다. 스냅샷을 삭제 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 스냅샷을 삭제할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 스냅샷 목록 버튼을 클릭하세요. Block Storage 스냅샷 목록 페이지로 이동합니다.
- 스냅샷명, 설명과 생성 일시를 확인 후 삭제하고자 하는 스냅샷의 더보기 버튼을 클릭하세요.
- 삭제 버튼을 클릭하세요. 스냅샷 목록 페이지에서 스냅샷이 제거됩니다.
8.2.3 - 볼륨 이전 하기
다른 Account로 볼륨을 이전할 수 있으며 이전하는 경우 기존 위치에서는 볼륨이 제거됩니다. Block Storage 목록이나 Block Storage 상세 페이지에서 볼륨 이전을 수행할 수 있습니다.
볼륨 이전
리전 내 다른 Account로 볼륨을 이전할 수 있습니다. 볼륨을 이전하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 이전할 자원을 선택한 후, 목록 좌측 상단에 있는 더보기 > 볼륨 이전 버튼을 클릭하세요.
- 또는 이전할 자원의 Block Storage 상세 페이지 상단에 있는 볼륨 이전 버튼을 클릭하세요.
- 볼륨 이전을 알리는 팝업창이 열리면 이전하려는 볼륨명을 확인한 후, 확인 버튼을 클릭하세요.
- 이전 완료를 팝업창이 열리면 확인 버튼을 클릭하세요. 볼륨 이전 ID와 승인 Key 정보가 텍스트 파일로 다운로드됩니다.
- 볼륨이 Awaiting Transfer 상태로 변경됩니다.
주의
- 동일한 리전 내에서 볼륨 이전이 가능합니다.
- 볼륨이 Available 상태인 경우에만 볼륨 이전이 가능합니다. In Use 상태인 경우 연결 서버를 모두 해제하세요.
볼륨 이전 취소
볼륨 이전 생성 후 취소할 수 있습니다. 볼륨 이전을 취소 하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 볼륨 이전을 취소할 자원을 클릭하세요. Block Storage 상세 페이지로 이동합니다.
- 볼륨이 Awaiting Transfer 상태인 경우 취소할 수 있습니다.
- 볼륨 이전 취소 버튼을 클릭하세요. 볼륨 이전 취소 팝업창이 열립니다.
- 볼륨 이전을 취소하고자 하는 볼륨명 확인 후 확인 버튼을 클릭하세요.
- 볼륨이 Available 상태로 변경됩니다.
볼륨 이전 받기
리전 내 다른 Account로부터 볼륨을 이전 받을 수 있습니다. 볼륨을 이전 받으려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다.
- Block Storage 목록 페이지에서 목록 좌측 상단에 있는 더보기 > 볼륨 이전 받기 버튼을 클릭하세요. 볼륨 이전 받기 팝업창이 열립니다.
- 볼륨 이전 생성 시 제공된 볼륨 이전 ID와 승인 Key를 입력하세요.
- Block Storage 목록 페이지에 볼륨이 생성됩니다.
안내
- 실제 반영까지 시간이 소요됩니다.
- 볼륨 이전을 생성한 Account에서는 이전된 볼륨이 제거됩니다.
8.3 - API Reference
API Reference
8.4 - CLI Reference
CLI Reference
8.5 - Release Note
Block Storage
2025.07.01
FEATURE
스냅샷 요금 정책 변경 및 모니터링 연계- 스냅샷은 원본 Block Storage의 크기 기준으로 요금이 부과됩니다.
- Cloud Monitoring과 연계하였습니다.
- Cloud Monitoring에서 IOPS, Latency, Throughput 정보를 확인할 수 있습니다.
2025.02.27
FEATURE
Block Storage 디스크 유형 추가- Block Storage 기능 변경
- HDD 디스크 유형이 추가되어, 목적에 따라 추가된 유형(HDD, HDD_MultiAttach, HDD_KMS)을 선택할 수 있습니다.
- Samsung Cloud Platform 공통 기능 변경
- Account, IAM 및 Service Home, 태그 등 공통 CX 변경 사항을 반영하였습니다.
2024.10.01
NEW
Block Storage 서비스 정식 버전 출시- SSD_KMS 디스크 유형을 추가하였습니다.
- SSD_KMS 선택 시, KMS(Key Management Service) 암호화키를 통한 암호화가 추가됩니다.
- 대규모 데이터와 데이터베이스 워크로드 처리에 적합한 고성능 스토리지 서비스를 출시하였습니다.
2024.07.02
NEW
Beta 버전 출시- 대규모 데이터와 데이터베이스 워크로드 처리에 적합한 고성능 스토리지 서비스를 출시하였습니다.