서비스 개요
Quick Query는 대용량 데이터를 표준 SQL을 사용하여 간편하고 빠르게 분석할 수 있는 대화형 쿼리 서비스입니다. 표준 Kubernetes 클러스터 기반에 자동으로 설치되며, Cloud Hadoop, Object Storage, RDB 등 다양한 데이터 소스에 쉽고 빠르게 접근하여 데이터 조회 및 가공이 가능합니다.
특장점
- 쉽고 빠른 데이터 조회: Object Storage에 저장된 데이터에 대해 스키마를 정의한 후 표준 SQL을 사용하여 쿼리를 실행하면 쉽고 빠르게 조회가 가능합니다. SQL을 다룰 수 있는 사용자는 전문 분석가가 아니더라도 누구나 손쉽게 대규모 데이터 세트를 분석할 수 있습니다.
- 신속한 병렬 분산 처리: 병렬 분산 처리가 가능한 Trino 엔진을 사용하여 자동으로 쿼리를 분할하고, 동시에 여러 노드에서 병렬 처리하여 대용량 데이터도 빠르게 쿼리 결과를 확인할 수 있습니다.
- 다양한 서비스 구조: 공용 고정자원 모드와 공용 자원확장 모드, 그리고 개인용 자원확장 모드를 제공합니다. 공용 고정자원 모드는 대규모 데이터 쿼리에 대한 안정적인 응답 속도를 지원하며, 공용 자원확장 모드는 사용 빈도가 불규칙한 경우 더 저렴한 비용으로 이용할 수 있습니다. 또한 개인용 자원확장 모드는 각 사용자가 독립적인 환경에서 분석 작업을 수행할 수 있도록 지원하여 사용자 요구에 맞는 구조의 Quick Query를 이용할 수 있습니다.
서비스 구성도
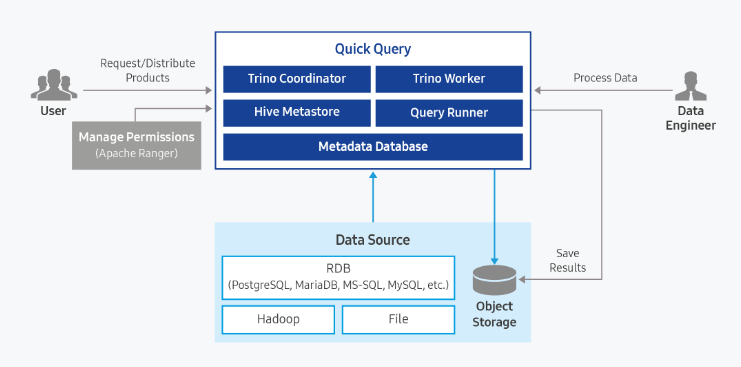
제공 기능
Quick Query는 다음과 같은 기능을 제공합니다.
- 다양한 Data Source의 단일 엑세스 지원 (11종의 Data Source 지원)
- 결과 데이터에 대한 Object Storage내 자동 저장 기능
- 동일한 쿼리문에 대한 조회 결과 재사용 기능
- Ranger 연동을 통한 접근제어 기능
- 데이터 사용량 제어 기능
| 카테고리 | 타입 | 비고 |
|---|---|---|
| Cloud Hadoop | hive_on_cloud_hadoop iceberg_on_cloud_hadoop | Cloud Hadoop의 Hive Metastore 사용 |
| Object Storage | hive_on_object_storage iceberg_on_object_storag | Quick Query에서 Hive Metastore 배포하여 사용 |
| RDB | postgresql mariadb sqlserver oracle mysql | JDBC Driver Upload 필요 (라이선스) |
| TPCDS | tpcds | Quick Query에서 기본 제공하는 내장 Data Source |
| TPCH | tpch | Quick Query에서 기본 제공하는 내장 Data Source |
| 타입 | select | insert | uptate | delete | create | drop | alter | analyze | call |
|---|---|---|---|---|---|---|---|---|---|
| hive_on_cloud_hadoop | O | O | O | O | O | O | O | O | O |
| iceberg_on_cloud_hadoop | O | O | O | O | O | O | O | O | O |
| hive_on_object_storage | O | O | O | O | O | O | O | O | O |
| iceberg_on_object_storage | O | O | O | O | O | O | O | O | O |
| postgresql | O | O | O | O | O | O | |||
| mariadb | O | O | O | O | O | O | |||
| sqlserver | O | O | O | O | O | O | |||
| greenplum | O | O | O | O | O | O | |||
| oracle | O | O | O | O | O | O | |||
| mysql | O | O | O | O | O | O | |||
| tpcds | O | ||||||||
| tpch | O |
구성 요소
쿼리엔진타입: 공용
쿼리엔진은 1개가 기동되면 여러 사용자가 공유하여 사용하는 구조입니다.
고정자원 모드(Auto Scaling 미사용): Auto Scaling을 미사용하는 경우 사용자가 선택한 리소스에 맞춰 고정된 리소스의 쿼리 엔진이 기동됩니다. 쿼리엔진이 항시 동일한 리소스로 실행되어 있는 구조라 동일한 쿼리 성능을 보장해 줄 수 있는 구조입니다.
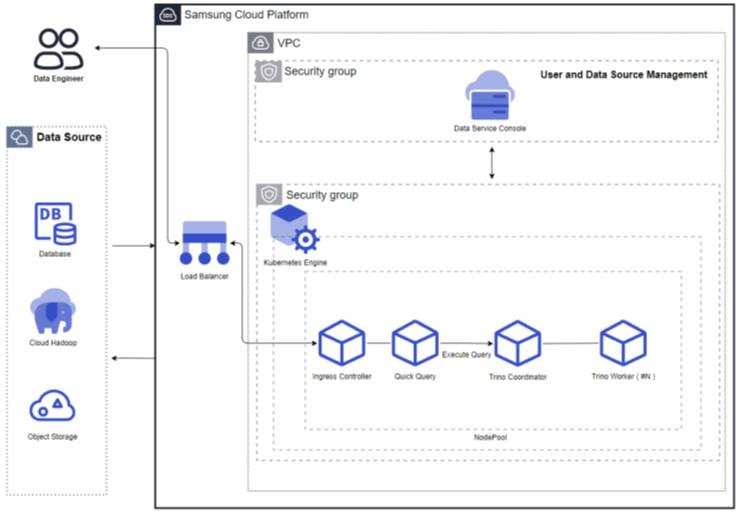
그림. 고정자원 모드(Auto Scaling 미사용) 자원확장 모드(Auto Scaling 사용): Auto Scaling을 사용하는 경우 쿼리엔진의 Worker 노드가 처리량에 따라 자동으로 Auto Scale in/out 됩니다. 처리량이 적을 경우는 1개까지 Worker 노드가 줄어 들고 처리량이 많아지면 Worker 노드가 늘어납니다. 또한 클러스터 사이즈에 따라 리소스를 조정할 수 있습니다.
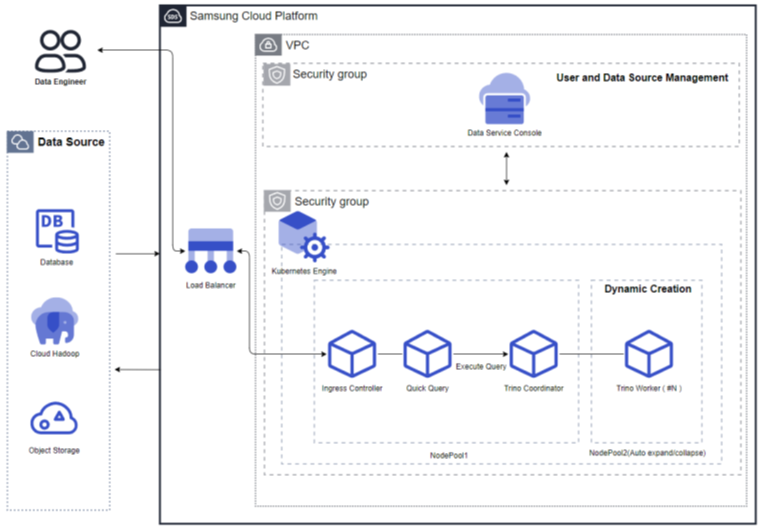
그림. 자원확장 모드(Auto Scaling 사용)
쿼리엔진타입: 개인용
자원확장 모드(Auto Scaling 사용): 개인용 쿼리엔진타입은 쿼리엔진이 사용자별로 별도 실행되는 구조입니다. 각 쿼리엔진은 Auto Scale in/out을 지원하며 장기간 미 사용시 엔진은 자동으로 Stop 되는 구조입니다. 다시 사용을 위해 재 접속시 쿼리엔진이 자동으로 다시 실행됩니다. 처리량이 적을 경우는 1개까지 Worker 노드가 줄어 들고 처리량이 많아지면 Worker 노드가 늘어납니다. 또한 클러스터 사이즈에 따라 리소스를 조정할 수 있습니다.
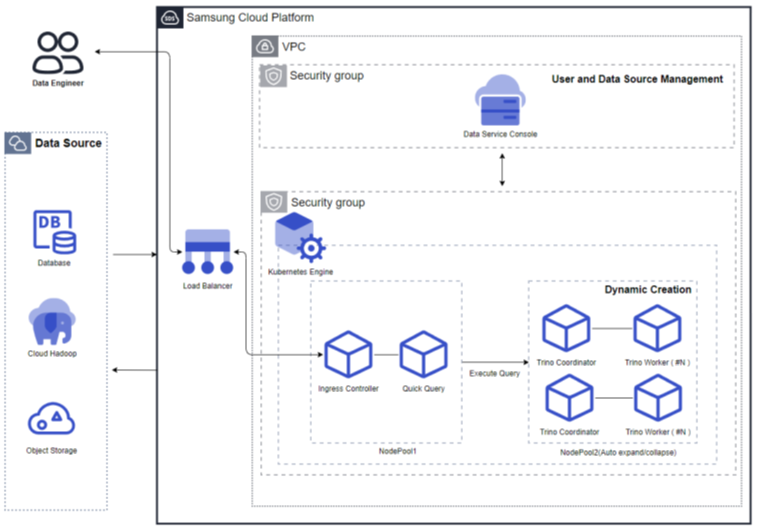
그림. 자원확장 모드(Auto Scaling 사용)
서버 타입
Quick Query에서 지원하는 서버 타입은 다음과 같습니다.
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 유형 | Standard | 제공되는 서버 타입
|
| 서버 크기 | s1v2m4 | 제공되는 서버 사양
|
Quick Query를 사용하기 위한 최소 사양은 다음과 같습니다.
| 구분 | 상세 | 클러스터 사이즈(사용자 입력 값) | 고정 노드풀 | 자동 확장 노드풀 |
|---|---|---|---|---|
| 공용 | 고정자원 모드(Auto Scaling 미사용) | Replica: 1 CPU: 4 Core Memory: 8GB | 8 Core, 16GB * 4 | N/A |
| 공용 | 자원확장 모드(Auto Scaling 사용) | Small(1 Core, 4GB) | 8 Core, 16GB * 3 | 8 Core, 16GB * 1 |
| 개인용 | 자원확장 모드(Auto Scaling 사용) | Small(1 Core, 4GB) | 8 Core, 16GB * 3 | 8 Core, 32GB * 2 |
리전별 제공 현황
Quick Query은 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하시기 바랍니다.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
| Storage | File Storage | 네트워크 연결을 통하여 다수의 클라이언트 서버가 파일을 공유하는 스토리지 |