빅데이터를 쉽고 빠르게 처리할 수 있는 분석 서비스를 제공합니다.
이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
Data Analytics
- 1: Event Streams
- 1.1: Overview
- 1.2: How-to guides
- 1.3: API Reference
- 1.4: CLI Reference
- 1.5: Release Note
- 2: Search Engine
- 2.1: Overview
- 2.2: How-to guides
- 2.3: API Reference
- 2.4: CLI Reference
- 2.5: Release Note
- 3: Vertica(DBaaS)
- 3.1: Overview
- 3.2: How-to guides
- 3.2.1: Vertica 백업 및 복구하기
- 3.3: API Reference
- 3.4: CLI Reference
- 3.5: Release Note
- 4: Data Flow
- 4.1: Overview
- 4.2: How-to guides
- 4.2.1: Data Flow Services
- 4.2.2: Ingress Controller 설치하기
- 4.3: API Reference
- 4.4: CLI Reference
- 4.5: Release Note
- 5: Data Ops
- 5.1: Overview
- 5.2: How-to guides
- 5.2.1: Data Ops Services
- 5.2.2: Ingress Controller 설치하기
- 5.3: API Reference
- 5.4: CLI Reference
- 5.5: Release Note
- 6: Quick Query
- 6.1: Overview
- 6.2: How-to guides
- 6.3: API Reference
- 6.4: CLI Reference
- 6.5: Release Note
1 - Event Streams
1.1 - Overview
서비스 개요
Event Streams은 대용량, 대규모 메시지 데이터 처리를 위한 오픈 소스 Apache Kafka의 생성과 설정을 완전 관리형으로 제공합니다. Samsung Cloud Platform은 웹 기반 Console을 통해 Apache Kafka 생성과 설정을 자동화하여 제공하며, 사용자는 단일 혹은 클러스터 형태로 Apache Kafka의 주요 구성 요소인 Broker, Zookeeper, AKHQ를 구성할 수 있습니다.
Event Streams 클러스터는 여러 개의 Broker 노드로 이루어진 구성으로 Broker는 최소 1개부터 최대 10개까지 설치가 가능하며, 주로 3대 이상으로 설치합니다. Zookeeper는 분산된 Broker들을 관리하는 용도로 별도 설치가 가능하며, 별도 설치하지 않을 경우 Broker 노드에 같이 설치됩니다. 추가로, Kafka를 관리할 수 있는 도구인 AKHQ(Apache Kafka HQ)를 제공하여 사용자는 이를 통해 클러스터 운영 관리가 가능합니다.
제공 기능
Event Streams는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning): UI로 Apache Kafka 클러스터 구성 및 설정이 가능합니다.
- 가동 제어 관리: 가동 중인 서버 상태를 제어하는 기능을 제공합니다. 클러스터의 시작, 중지와 더불어 설정값 반영을 위해 재시작이 가능합니다.
- AKHQ 제공: Kafka를 관리할 수 있는 도구인 AKHQ를 제공하여 사용자는 이를 통해 클러스터 관리 및 모니터링이 가능합니다.
- Broker 노드 추가: 클러스터의 성능 향상과 안정성을 위해 확장이 필요할 경우, 사용 중인 Broker 노드와 동일한 사양으로 노드를 추가할 수 있습니다.
- Parameter 관리: 성능 향상 및 보안 관련 구성 파라미터 설정 및 수정이 가능합니다.
- 모니터링: CPU, 메모리, 클러스터 성능 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
구성 요소
Event Streams은 오픈 소스 지원 정책에 따라 사전에 검증된 엔진 버전과 다양한 서버 타입을 제공하고 있습니다. 사용자는 구성하고자 하는 서비스 규모에 따라 이를 선택하여 사용할 수 있습니다.
엔진 버전
Event Streams에서 지원하는 엔진 버전은 다음과 같습니다.
기술 지원은 공급사의 EoTS(End of Technical Service) 일자까지 사용할 수 있으며, 신규 생성이 중지되는 EOS 일자는 EoTS 일자로부터 6개월 전으로 정해집니다.
공급사 정책에 따라 EOS, EoTS 일자는 변동될 수 있으므로, 자세한 사항은 공급사의 라이선스 관리 정책 페이지를 참고해주세요.
- Apache Kafka: https://docs.confluent.io/platform/current/installation/versions-interoperability.html
안내
Apache Kafka 3.9.1 버전은 2025년 12월 18일 이후에 서비스 제공 예정입니다. 실제 서비스 제공 일정은 변경될 수 있습니다.
| 제공 버전 | EoS Date | EoTS Date |
|---|---|---|
| 3.8.0 | 2026-06 (예정) | 2026-12-02 |
표. Event Streams 제공되는 엔진 버전
서버 타입
Event Streams에서 지원하는 서버 타입은 다음 형식과 같습니다.
Event Streams에서 제공하는 서버 타입에 대한 자세한 내용은 Event Streams 서버 타입을 참고하세요.
Standard ess1v2m4
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입
|
| 서버 사양 | ess1 | 제공되는 서버 사양
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Event Streams 서버 타입 구성 요소
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
표. Event Streams 선행 서비스
1.1.1 - 서버 타입
Event Streams 서버 타입
Event Streams는 CPU, Memory, Network Bandwidth 등 다양한 조합으로 구성된 서버 타입을 제공합니다. Event Streams를 생성할 때 사용 목적에 맞게 선택한 서버 타입에 따라 Apache kafka가 설치됩니다.
Event Streams에서 지원하는 서버 타입은 다음 형식과 같습니다.
Standard ess1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | ess1 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Event Streams 서버 타입 형식
참고
아래와 같이 노드의 최소 사양을 확인하여 서버 타입을 선택하세요.
| 구분 | vCPU | Memory |
|---|---|---|
| Broker | 2 vCore | 4 GB |
| Zookeeper | 1 vCore | 2 GB |
ess1 서버 타입
Event Streams의 ess1 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.3Ghz의 Intel 3세대(Ice Lake) Xeon Gold 6342 Processor
- 최대 16개의 vCPU 및 64 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | ess1v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | ess1v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | ess1v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | ess1v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | ess1v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | ess1v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | ess1v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | ess1v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | ess1v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
표. Event Streams 서버 타입 사양 - ess1 서버 타입
ess2 서버 타입
Event Streams의 ess2 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 16개의 vCPU 및 64 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | CPU vCore | Memory | Network Bandwidth(Gbps) |
|---|---|---|---|---|
| Standard | ess2v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | ess2v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | ess2v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | ess2v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | ess2v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | ess2v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | ess2v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | ess2v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | ess2v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
표. Event Streams 서버 타입 사양 - ess2 서버 타입
esh2 서버 타입
Event Streams의 esh2 서버 타입은 대용량 서버 사양으로 제공하며, 대규모 데이터 처리를 위한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 32개의 vCPU 및 128 GB의 메모리를 지원
- 최대 25Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | esh2v32m64 | 32 vCore | 64 GB | 최대 25 Gbps |
| High Capacity | esh2v32m128 | 32 vCore | 128 GB | 최대 25 Gbps |
표. Event Streams 서버 타입 사양 - esh2 서버 타입
1.1.2 - 모니터링 지표
Event Streams 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Event Streams의 성능 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Event Streams의 서버 모니터링 지표는 Virtual Server 모니터링 지표 가이드를 참고하세요.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| AKHQ State [PID] | AHKQ 프로세스 PID | PID |
| Connections [Zookeeper Client] | ZooKeeper 연결된 건수 | cnt |
| Disk Used | datadir 사용량 | bytes |
| Failed [Client Fetch Request] | 클라이언트 Fetch 요청 처리 실패 건수 | cnt |
| Failed [Produce Request] | Procucer 요청 처리 실패 건수 | cnt |
| Incomming Messages | Broker가 받은 message 건수 | cnt |
| Instance State [PID] | kafka 프로세스 PID | PID |
| Kibana state [PID] | Kibana 프로세스 PID | PID |
| Leader Elections | Leader Election 발생 건수 | cnt |
| Leader Elections [Unclean] | Unclean Leader Election 발생 건수 | cnt |
| Log Flushes | log flush 발생 건수 | cnt |
| Network In Bytes | 전체 Topic이 수신한 바이트 | bytes |
| Network Out Bytes | 전체 Topic이 송신한 바이트 | bytes |
| Rejected Bytes | 전체 Topic이 reject한 바이트 | bytes |
| Request Queue Length | 요청 대기열 크기 | cnt |
| Shards | 클러스터 샤드 수 | cnt |
| Zookeeper Sessions [Closed] | 초당 ZooKeeper 닫힌 세션 | cnt |
| Zookeeper Sessions [Expired] | 초당 ZooKeeper 만료된 세션 | cnt |
| Zookeeper State [PID] | zookeeper 프로세스 PID | PID |
표. Event Streams 모니터링 지표
1.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Event Streams의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Event Streams 생성하기
Samsung Cloud Platform Console에서 Event Streams 서비스를 생성하여 사용할 수 있습니다.
안내
서비스를 생성하기 전에 VPC의 Subnet 유형은 General로 구성해주세요.
- Subnet 유형이 Local인 경우에는 해당 Database 서비스 생성이 불가합니다.
Event Streams를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Event Streams 생성 버튼을 클릭하세요. Event Streams 생성 페이지로 이동합니다.
Event Streams 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 버전 필수 Event Streams의 버전 리스트 제공 표. Event Streams 서비스 정보 입력 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버명 Prefix 필수 Apache kafka가 설치될 서버 이름 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
-)를 사용하여 3 ~ 13자로 입력
- 서버명 기반으로 001, 002와 같은 Postfix가 붙어 실제 서버명이 생성됨
클러스터명 필수 서버들이 구성된 클러스터명 - 영문을 사용하여 3 ~ 20자로 입력
- 클러스터는 여러 개의 서버를 묶는 단위
Broker > Broker Node 수 필수 Broker Node 수 Broker > 서버 타입 필수 Broker가 설치될 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
- Event Streams에서 제공하는 서버 타입에 대한 자세한 내용은 Event Streams 서버 타입을 참고
Broker > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
Broker > Block Storage 필수 Broker 노드에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD_KMS/HDD_KMS: Samsung Cloud Platform KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
Zookeeper 별도 설치 > 사용 선택 Zookeeper 노드 별도 설치 여부 - 사용을 선택하면 Zookeeper 노드를 별도로 설치합니다.
- Zookeeper 노드를 별도 설치하지 않으면, Broker 노드가 Zookeeper 역할도 같이 수행합니다.
Zookeeper 별도 설치 > 서버 타입 선택 Zookeeper가 설치될 서버 타입 - Zookeeper 노드는 vCPU 1, Memory 2G 또는 vCPU 2, Memory 4G를 제공합니다
Zookeeper 별도 설치 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
Zookeeper 별도 설치 > Block Storage 필수 Zookeeper 노드에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD_KMS/HDD_KMS: Samsung Cloud Platform KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
AKHQ > 사용 필수 AKHQ 설치 여부 - 사용을 선택하면 AKHQ를 설치합니다.
AKHQ > 서버 타입 필수 AKHQ 가 설치될 서버 타입 - AKHQ는 vCPU 2, Memory 4G 타입만 제공
AKHQ > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
AKHQ > Block Storage 필수 AKHQ가 설치되는 서버에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
AKHQ > AKHQ 계정 필수 AKHQ 계정 - 영문 소문자를 사용하여 2~20자로 입력
AKHQ > AKHQ 비밀번호 필수 AKHQ 계정 비밀번호 - 영문, 숫자와 특수문자(
“‘제외)를 포함하여 8~30자로 입력
AKHQ > AKHQ 비밀번호 확인 필수 AKHQ 계정 비밀번호 확인 - AKHQ 계정 비밀번호를 동일하게 재입력
AKHQ > AKHQ Port 번호 필수 AKHQ 접속 포트 번호 - 포트 번호는 8080으로 자동으로 설정되며, 수정이 불가
네트워크 > 공통 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 모든 서버에 동일한 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 자동 생성만 가능
- Public NAT 설정의 경우 서버별 설정에서만 가능합니다.
네트워크 > 서버별 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 서버별 다른 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 각 서버의 IP 입력
- Public NAT 기능은 VPC가 Internet Gateway에 연결되어 있어야 사용 가능, 사용을 체크하면 VPC 상품의 Public IP에서 예약된 IP 중에서 선택 가능. 자세한 내용은 Public IP 생성하기를 참고
IP 접근 제어 선택 서비스 접근 정책 설정 - 페이지에 입력된 IP에 대해 접근 정책을 설정하므로 별도로 Security Group 정책 설정은 수행하지 않아도 됩니다.
- IP 형식(예시:
192.168.10.1) 또는 CIDR 형식(예시:192.168.10.0/24,192.168.10.1/32)으로 입력하고, 추가 버튼을 클릭
- 입력한 IP를 삭제하려면, 입력한 IP 옆의 x 버튼을 클릭
유지 관리 기간 선택 Event Streams 유지 관리 기간 - 사용을 선택하면 요일, 시작 시간, 기간을 설정
- 서비스의 안정적인 관리를 위해 유지 관리 기간을 설정할 것을 권고. 설정한 시간에 패치 작업이 진행되며 서비스 중단 발생 가능
- 패치 미적용(미사용으로 설정)으로 발생되는 문제점은 당사에서 책임지지 않음
표. Event Streams 서비스 구성 항목 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
- Database 구성 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Zookeeper SASL 계정 필수 Zookeeper 계정 - 영문 소문자를 사용하여 2~20자 이내로 입력
Zookeeper SASL 비밀번호 필수 Zookeeper 계정 비밀번호 - 영문, 숫자와 특수문자(
“‘제외)를 포함하여 8~30자로 입력
Zookeeper SASL 비밀번호 확인 필수 Zookeeper 계정 비밀번호 확인 - Zookeeper SASL 계정 비밀번호를 동일하게 재입력
Zookeeper Port 번호 필수 Zookeeper 포트 번호 1,024 ~ 65,535중 하나로 입력 가능하며, Broker 포트 혹은2888,3888은 사용 불가
Broker SASL 계정 필수 Kafka 접속 계정 - 영문 소문자를 사용하여 2~20자 이내로 입력
Broker SASL 비밀번호 필수 Kafka 접속 계정 비밀번호 - 영문, 숫자와 특수문자(
“‘제외)를 포함하여 8~30자로 입력
Broker SASL 비밀번호 확인 필수 Kafka 접속 계정 비밀번호 확인 - Broker SASL 계정 비밀번호를 동일하게 재입력
Broker Port 번호 필수 Kafka 포트 번호 1,024 ~ 65,435중 하나로 입력 가능하며, Broker 포트 혹은2888,3888은 사용 불가
Parameter 필수 Event Streams 구성 파라미터 - 조회 버튼을 클릭하여 파라미터의 상세 정보 확인 가능
- 서비스 생성이 완료된 이후에 파라미터 수정 가능하며, 수정 시 재시작이 필요
시간대 선택 서비스가 사용될 표준 시간대 표. Event Streams Database 구성 필수 정보 입력 항목 - 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Event Streams 서비스 추가 정보 입력 항목
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, 자원 목록 페이지에서 생성한 자원을 확인하세요.
Event Streams 상세 정보 확인하기
Event Streams 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Event Streams 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Event Streams 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- Event Streams 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 클러스터 상태 클러스터 상태 - Creating: 클러스터가 만들어지는 중
- Editing: 클러스터가 Operation을 수행 상태로 변경 중
- Error: 클러스터가 작업을 수행하다 실패가 발생된 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Failed: 클러스터가 생성 과정 중 실패한 상태
- Restarting: 클러스터를 재시작하는 중
- Running: 클러스터가 정상적으로 동작하는 상태
- Starting: 클러스터를 시작하는 중
- Stopped: 클러스터가 중지된 상태
- Stopping: 클러스터를 중지 상태 중
- Synchronizing: 클러스터를 동기화 중
- Terminating: 클러스터를 삭제하는 중
- Unknown: 클러스터 상태를 알 수 없는 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Upgrading: 클러스터가 업그레이드를 수행 상태로 변경 중
클러스터 제어 클러스터 상태를 변경할 수 있는 버튼 - 시작: 중지된 클러스터를 시작합니다.
- 중지: 가동 중인 클러스터를 중지합니다.
- 재시작: 가동 중인 클러스터를 재시작 상태
추가 기능 더보기 클러스터 관련 관리 버튼 - 서비스 상태 동기화: 현재 서버 상태를 조회하여 Console에 동기화 가능
- Parameter 관리: 서비스 구성 파라미터 조회 및 수정 가능
- Broker Node 추가: Broker Node를 추가
- 클러스터 구성일 경우, Broker Node 추가 버튼이 표시됨
서비스 해지 서비스를 해지하는 버튼 표. Event Streams 상태 정보 및 부가 기능
- Event Streams 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Event Streams 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서버 정보 | 해당 클러스터에 구성되어 있는 서버 정보
|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 이미지/버전 | 설치된 서비스 이미지 및 버전 정보 |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| 유지 관리 기간 | 패치 작업 기간 설정 현황
|
| 시간대 | 서비스가 사용될 표준 시간대 |
| Zookeeper Port 번호 | Zookeeper 포트 번호 |
| Broker Port 번호 | Kafka 포트 번호 |
| AKHQ 접속정보 | AKHQ 접속정보 |
| 네트워크 | 설치된 네트워크 정보(VPC, Subnet) |
| IP 접근 제어 | 서비스 접근 정책 설정
|
| Zookeeper | Zookeeper 노드에 대한 서버 타입, 기본 OS, 추가 Disk 정보
|
| Broker | Broker 노드에 대한 서버 타입, 기본 OS, 추가 Disk 정보
|
| AKHQ | AKHQ 노드에 대한 서버 타입, 기본 OS 정보
|
표. Event Streams 상세 정보 항목
태그
Event Streams 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Event Streams 태그 탭 항목
작업 이력
Event Streams 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Event Streams 작업 이력 탭 상세 정보 항목
Event Streams 자원 관리하기
생성된 Event Streams 자원의 기존 설정 옵션을 변경하거나 Parameter 관리, Broker Node 추가 구성이 필요한 경우에는 Event Streams 상세 정보 페이지에서 작업을 수행할 수 있습니다.
가동 제어하기
가동 중인 Event Streams 자원의 변경 사항이 발생할 경우, 시작, 중지, 재시작을 할 수 있습니다.
Event Streams의 가동 제어를 하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 가동 제어할 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- Event Streams 상태를 확인하고, 아래 제어 버튼을 통해 변경을 완료하세요.
- 시작: Event Streams 서비스가 설치된 서버와 Event Streams 서비스가 가동(Running)됩니다.
- 중지: Event Streams 서비스가 설치된 서버와 Event Streams 서비스가 중단(Stopped)됩니다.
- 재시작: Event Streams 서비스만 재시작됩니다.
서비스 상태 동기화하기
현재의 서버 상태를 조회하여 Console에 동기화할 수 있습니다.
Event Streams의 서비스 상태를 동기화하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 서비스 상태를 조회할 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- 서비스 상태 동기화 버튼을 클릭하세요. 조회하는데 약간의 시간이 소요되며, 조회되는 동안 클러스터는 Synchronizing 상태로 변경됩니다.
- 조회가 완료되면 서버 정보 항목에 상태가 업데이트되며, 클러스터는 Running 상태로 변경됩니다.
Parameter 관리하기
파라미터 조회 및 수정 기능을 제공합니다.
구성 파라미터를 조회 및 수정하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 파라미터 조회 및 수정하고자 하는 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- Parameter 관리 버튼을 클릭하세요. Parameter 관리 페이지로 이동합니다.
- Parameter 관리 페이지에서 조회 버튼을 클릭하세요. Database 조회 팝업창이 열립니다.
- Parameter 정보를 조회하려면 확인 버튼을 클릭하세요. 조회하는데 약간의 시간이 소요됩니다.
- 조회를 수행한 다음 Parameter 정보를 수정할 수 있습니다.
- Parameter 정보를 수정하려면 수정 버튼을 클릭한 후 수정할 Parameter의 사용자 정의값 영역에 수정 내용을 입력하세요.
- 적용 유형이 동적인 경우에는 즉시 반영되며, 정적인 경우에는 서비스 재시작이 필요하므로 서비스가 중단됩니다.
- 입력이 완료되면, 저장 버튼을 클릭하세요.
서버 타입 변경하기
구성된 서버 타입을 변경할 수 있습니다.
서버 타입을 변경하려면 다음 절차를 따르세요.
주의
- 서버 타입을 Standard로 구성한 경우에는 High Capacity로 변경할 수 없습니다. High Capacity로 변경하고자 할 경우, 서비스를 신규로 생성하세요.
- 서버 타입을 수정하면 서버 재가동이 필요합니다. 스펙 변경에 따른 SW 라이선스 수정 사항 또는 SW 설정 및 반영은 별도 확인해주세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- 상세 정보 하단의 변경하고자 하는 서버 타입의 수정 버튼을 클릭하세요. 서버 타입 수정 팝업창이 열립니다.
- 서버 타입 수정 팝업창에서 서버 타입을 선택한 후, 확인 버튼을 클릭하세요.
스토리지 증설하기
데이터 영역으로 추가된 스토리지를 최초 할당한 용량 기반 최대 5TB까지 증설할 수 있습니다. Event Streams를 중단하지 않고 스토리지를 증설할 수 있으며, 클러스터로 구성된 경우 모든 노드가 동시에 증설됩니다.
안내
- 기존 Block Storage에 암호화 설정이 된 경우 추가 Disk에도 암호화가 적용됩니다.
- 디스크 사이즈 수정은 현재 디스크 사이즈보다 16GB 이상 증설만 가능합니다.
스토리지 용량을 증설하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- 상세 정보 하단의 증설하고자 하는 추가된 Disk의 수정 버튼을 클릭하세요. Disk 수정 팝업창이 열립니다.
- Disk 수정 팝업창에서 증설 용량 입력한 후, 확인 버튼을 클릭하세요.
Broker Node 추가하기
Event Streams 클러스터 확장이 필요한 경우, 사용 중인 Broker Node와 동일한 사양으로 노드를 추가할수 있습니다. 추가된 노드 수만큼 서버 중단 없이 기존 클러스터에 추가되며, 기존 데이터는 자동으로 분배됩니다.
안내
- 클러스터 내에서 최대 10개의 노드를 사용할 수 있습니다. 생성된 노드에 대해서는 추과 과금되므로 참고하세요.
- 노드 추가 중에는 클러스터의 성능이 저하될 수 있습니다.
Broker 노드를 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 자원 목록 페이지에서 복구하고자 하는 자원을 클릭하세요. Event Streams 상세 페이지로 이동합니다.
- Broker Node 추가 버튼을 클릭하세요. Broker Node 추가 페이지로 이동합니다.
- 필수 정보 입력 영역에 해당 정보를 입력한 후, 완료 버튼을 클릭하세요.
구분 필수 여부상세 설명 서버명 필수 Broker가 설치되는 서버 이름 - 원본 클러스터에 설정된 서버명으로 설정됩니다.
클러스터명 필수 클러스터 이름 - 원본 클러스터에 설정된 클러스터명으로 설정됩니다.
추가 Node 수 필수 추가할 Node 수 - 하나의 클러스터에 최대 10개의 노드를 사용
서비스 유형 > 서버 타입 필수 Broker가 설치될 서버 타입 - 원본 클러스터에 설정된 서버 타입으로 동일하게 설정됩니다.
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 Broker 노드에 사용될 Block Storage 설정 - 원본 클러스터에서 설정한 Storage 유형 및 용량이 동일하게 적용
네트워크 필수 서버들이 설치되는 네트워크 - 원본 클러스터에서 설정한 네트워크와 동일하게 적용
표. Event Streams Broker Node 추가 항목
Event Streams 해지하기
사용하지 않는 Event Streams을 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Event Streams를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Event Streams 메뉴를 클릭하세요. Event Streams의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Event Streams 메뉴를 클릭하세요. Event Streams 목록 페이지로 이동합니다.
- Event Streams 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Event Streams 목록 페이지에서 자원이 해지되었는지 확인하세요.
1.3 - API Reference
API Reference
1.4 - CLI Reference
CLI Reference
1.5 - Release Note
Event Streams
2025.07.01
FEATURE
Terraform 및 디스크 타입 추가- Terraform을 제공합니다.
- HDD, HDD_KMS 디스크 타입을 추가 제공합니다.
2025.02.27
NEW
Event Streams 서비스 정식 버전 출시- 웹 환경에서 Apache Kafka 클러스터를 간편하게 생성하고 관리하는 Event Streams 서비스가 출시되었습니다.
2 - Search Engine
2.1 - Overview
서비스 개요
Search Engine은 웹 기반 Console을 통해 분산형 검색 및 분석 엔진인 Elasticsearch와 OpenSearch의 생성과 설정을 자동화하여 제공합니다. 사용자는 시스템 구성에 맞는 서버 타입을 선택하여 클러스터 구성이 가능하며, 데이터 분석 및 시각화 도구인 Kibana 및 OpenSearch 대시보드를 지원합니다.
안내
- Search Engine은 Elasticsearch Enterprise 버전과 OpenSearch 버전을 제공합니다.
- Elasticsearch Enterprise의 소프트웨어 라이선스는 사용자 보유 라이선스(BYOL, Bring Your Own License)를 사용하며, 클라우드 환경에서의 소프트웨어 라이선스 정책은 공급사 정책을 따라야 합니다.
Search Engine Cluster는 여러 개의 마스터 노드와 데이터 노드로 구성됩니다. 데이터 노드는 최소 1개부터 최대 10개까지 설치가 가능하며, 주로 3대 이상으로 설치합니다. 마스터 노드 별도 설치를 하지 않으면 데이터 노드가 마스터 노드의 역할도 함께 수행하며 최대 10개까지 설치 가능합니다. 마스터 노드 별도 설치시 데이터 노드는 50대까지 가능합니다.
제공 기능
Search Engine는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning): UI로 Elasticsearch 및 OpenSearch 클러스터 구성 및 설정이 가능합니다.
- 가동 제어 관리: 가동 중인 서버 상태를 제어하는 기능을 제공합니다. 클러스터의 시작, 중지와 더불어 설정값 반영을 위해 재시작이 가능합니다.
- 백업 및 복구: 자체 백업 기능을 활용하여 백업이 가능하며, 백업 파일 기준 시점으로 복구가 가능합니다.
- 데이터 노드 추가: 클러스터 확장이 필요할 경우, 사용 중인 데이터 노드와 동일한 사양으로 노드를 추가할 수 있습니다. 클러스터 내에서 최대 10개까지 노드 추가 가능합니다.
- 시각화도구 지원: 데이터 분석 및 시각화 도구를 제공하며 Elasticsearch Kibana 또는 OpenSearch 대시보드 지원이 가능합니다.
- 모니터링: CPU, 메모리, 클러스터 성능 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
구성 요소
Search Engine은 오픈 소스 지원 정책에 따라 사전에 검증된 엔진 버전과 다양한 서버 타입을 제공하고 있습니다. 사용자는 구성하고자 하는 서비스 규모에 따라 이를 선택하여 사용할 수 있습니다.
엔진 버전
Search Engine에서 지원하는 엔진 버전은 다음과 같습니다.
기술 지원은 공급사의 EoTS(End of Technical Service) 일자까지 사용할 수 있으며, 신규 생성이 중지되는 EOS 일자는 EoTS 일자로부터 6개월 전으로 정해집니다.
공급사 정책에 따라 EOS, EoTS 일자는 변동될 수 있으므로, 자세한 사항은 공급사의 라이선스 관리 정책 페이지를 참고해주세요.
안내
Search Engine의 다음 버전은 2025년 12월 18일 이후에 서비스 제공 예정입니다. 실제 서비스 제공 일정은 변경될 수 있습니다.
- ElasticSearch Enterprise 8.19.0 버전
- OpenSearch 2.19.3 버전
- OpenSearch 3.2.0 버전
| 제공 버전 | EoS Date | EoTS Date |
|---|---|---|
| 8.15.0 | TBD | TBD |
표. Search Engine의 Elasticsearch 엔진 버전
- OpenSearch: https://opensearch.org/releases/
| 제공 버전 | EoS Date | EoTS Date |
|---|---|---|
| 2.17.1 | TBD | TBD |
표. Search Engine의 OpenSearch 엔진 버전
서버 타입
Search Engine에서 지원하는 서버 타입은 다음 형식과 같습니다.
Search Engine에서 제공하는 서버 타입에 대한 자세한 내용은 Search Engine 서버 타입을 참고하세요.
Standard se1v2m4
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입
|
| 서버 사양 | se1 | 제공되는 서버 사양
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Search Engine 서버 타입 구성 요소
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
표. Search Engine 선행 서비스
2.1.1 - 서버 타입
Search Engine 서버 타입
Search Engine는 CPU, Memory, Network Bandwidth 등 다양한 조합으로 구성된 서버 타입을 제공합니다. Search Engine를 생성할 때 사용 목적에 맞게 선택한 서버 타입에 따라 Elastic Search가 설치됩니다.
Search Engine에서 지원하는 서버 타입은 다음 형식과 같습니다.
Standard ses1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | db1 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Search Engine 서버 타입 형식
ses1 서버 타입
Search Engine의 ses1 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.3Ghz의 Intel 3세대(Ice Lake) Xeon Gold 6342 Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | ses1v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | ses1v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | ses1v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses1v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | ses1v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses1v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | ses1v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses1v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses1v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | ses1v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | ses1v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | ses1v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | ses1v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | ses1v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | ses1v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | ses1v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses1v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses1v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | ses1v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | ses1v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | ses1v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | ses1v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | ses1v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | ses1v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | ses1v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | ses1v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | ses1v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | ses1v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | ses1v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | ses1v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | ses1v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | ses1v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | ses1v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | ses1v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | ses1v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | ses1v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | ses1v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | ses1v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | ses1v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | ses1v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Search Engine 서버 타입 사양 - ses1 서버 타입
ses2 서버 타입
Search Engine의 ses1 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | CPU vCore | Memory | Network Bandwidth(Gbps) |
|---|---|---|---|---|
| Standard | ses2v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | ses2v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | ses2v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses2v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | ses2v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses2v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | ses2v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses2v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses2v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | ses2v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | ses2v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | ses2v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | ses2v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | ses2v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | ses2v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | ses2v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | ses2v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | ses2v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | ses2v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | ses2v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | ses2v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | ses2v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | ses2v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | ses2v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | ses2v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | ses2v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | ses2v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | ses2v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | ses2v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | ses2v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | ses2v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | ses2v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | ses2v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | ses2v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | ses2v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | ses2v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | ses2v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | ses2v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | ses2v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | ses2v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Search Engine 서버 타입 사양 - ses2 서버 타입
seh2 서버 타입
Search Engine의 seh2 서버 타입은 대용량 서버 사양으로 제공하며, 대규모 데이터 처리를 위한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 72개의 vCPU 및 288 GB의 메모리를 지원
- 최대 25Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | seh2v24m48 | 24 vCore | 48 GB | 최대 25 Gbps |
| High Capacity | seh2v24m96 | 24 vCore | 96 GB | 최대 25 Gbps |
| High Capacity | seh2v24m192 | 24 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | seh2v24m288 | 24 vCore | 288 GB | 최대 25 Gbps |
| High Capacity | seh2v32m64 | 32 vCore | 64 GB | 최대 25 Gbps |
| High Capacity | seh2v32m128 | 32 vCore | 128 GB | 최대 25 Gbps |
| High Capacity | seh2v32m256 | 32 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | seh2v48m96 | 48 vCore | 96 GB | 최대 25 Gbps |
| High Capacity | seh2v48m192 | 48 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | seh2v64m128 | 64 vCore | 128 GB | 최대 25 Gbps |
| High Capacity | seh2v64m256 | 64 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | seh2v72m144 | 72 vCore | 144 GB | 최대 25 Gbps |
| High Capacity | seh2v72m288 | 72 vCore | 288 GB | 최대 25 Gbps |
표. Search Engine 서버 타입 사양 - seh2 서버 타입
2.1.2 - 모니터링 지표
Search Engine 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Event Streams의 성능 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Search Engine의 서버 모니터링 지표는 Virtual Server 모니터링 지표 가이드를 참고하세요.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Disk Usage | datadir 사용량 | MB |
| Documents [Deleted] | 총 삭제된 문서 수 | cnt |
| Documents [Existing] | 총 기존 문서 수 | cnt |
| Filesystem Bytes [Available] | 사용 가능한 파일 시스템 | bytes |
| Filesystem Bytes [Free] | 가용 파일 시스템 | bytes |
| Filesystem Bytes [Total] | 총 파일 시스템 | bytes |
| Instance Status [PID] | Elasticsearch 프로세스 PID | PID |
| JVM Heap Used [Init] | JVM에 사용된 힙 init(바이트) | bytes |
| JVM Heap Used [MAX] | JVM에 사용된 힙 max(바이트) | bytes |
| JVM Non Heap Used [Init] | JVM에 사용된 힙 이외의 init(바이트) | bytes |
| JVM Non Heap Used [MAX] | JVM에 사용된 힙 이외의 max(바이트) | bytes |
| Kibana Connections | Kibana 연결 | cnt |
| Kibana Memory Heap Allocated [Limit] | Node.js 프로세스에 할당된 최대 이전 공간 크기(바이트) | bytes |
| Kibana Memory Heap Allocated [Total] | Node.js 프로세스에 할당된 최대 이전 공간 크기(바이트) | bytes |
| Kibana Memory Heap Used | Node.js 프로세스에 할당된 최대 이전 공간 크기(바이트) | bytes |
| Kibana Process Uptime | Kibana 프로세스 | ms |
| Kibana Requests [Disconnected] | 요청 카운트 지표 | cnt |
| Kibana Requests [Total] | 요청 카운트 지표 | cnt |
| Kibana Response Time [Avg] | 응답 시간 지표 | ms |
| Kibana Response Time [MAX] | 응답 시간 지표 | ms |
| Kibana Status [PID] | Kibana 프로세스 PID | PID |
| License Expiry Date [ms] | 라이선스 만료일자 [milisecond] | ms |
| License Status | 라이선스 상태 | status |
| License Type | 라이선스 유형 | type |
| Queue Time | 대기열 시간 | ms |
| Segments | 총 세그먼트 수 | cnt |
| Segments Bytes | 세그먼트 총 크기(바이트) | bytes |
| Shards | 클러스터 샤드 수 | cnt |
| Store Bytes | 저장소 총 크기(바이트) | bytes |
표. Search Engine 모니터링 지표
2.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Search Engine의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Search Engine 생성하기
Samsung Cloud Platform Console에서 Search Engine 서비스를 생성하여 사용할 수 있습니다.
안내
서비스를 생성하기 전에 VPC의 Subnet 유형은 General로 구성해주세요.
- Subnet 유형이 Local인 경우에는 해당 Database 서비스 생성이 불가합니다.
Search Engine를 생성하려면 다음 절차를 따르세요.
안내
다음은 Elasticsearch Enterprise 이미지를 선택한 경우로 설명합니다.
모든 서비스 > Database > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Search Engine 생성 버튼을 클릭하세요. Search Engine 생성 페이지로 이동합니다.
Search Engine 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 필수 제공하는 이미지 종류 선택 - Elasticsearch Enterprise, OpenSearch
이미지 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
표. Search Engine 이미지 및 버전 선택 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버명 Prefix 필수 Elasticsearch가 설치될 서버 이름 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
-)를 사용하여 3 ~ 13자로 입력
- 서버명 기반으로 001, 002와 같은 Postfix가 붙어 실제 서버명이 생성됨
클러스터명 필수 서버들이 구성된 클러스터명 - 영문을 사용하여 3 ~ 20자로 입력
- 클러스터는 여러 개의 서버를 묶는 단위
MasterNode 별도 설치 > 사용 필수 Master 노드 별도 설치 여부 - 사용을 선택하면 Master 노드를 별도로 설치합니다.
- Master 노드를 별도 설치하지 않으면, 데이터 노드가 마스터 역할도 같이 수행합니다.
MasterNode 별도 설치 > MasterNode 수 필수 Master 노드 수 - 마스터 노드는 복구(Fail-over)를 위해 고정으로 3대가 설치됩니다.
MasterNode 별도 설치 > 서버 타입 필수 Master 노드 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
- Search Engine에서 제공하는 서버 타입에 대한 자세한 내용은 Search Engine 서버 타입을 참고
MasterNode 별도 설치 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
MasterNode 별도 설치 > Block Storage 필수 Master 노드에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD_KMS/HDD_KMS: KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- Disk 추가: 데이터 저장 영역
- 사용을 선택한 후, 스토리지의 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭하세요. 최대 9개까지 추가 가능합니다.
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
Node 수 필수 데이터 노드 수 - Master 노드 별도 설치 시에는 2개 이상, 그 외의 경우에는 1개 이상 선택해야 합니다.
서비스 유형 > 서버 타입 필수 데이터 노드 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 데이터 노드에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- SSD: 고성능 일반 볼륨
- HDD: 일반 볼륨
- SSD_KMS/HDD_KMS: KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- 스토리지 유형을 선택한 후 용량을 입력하세요.(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- Disk 추가: 데이터, 백업 추가 저장 영역
- 사용을 선택한 후, 스토리지의 용도, 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭하세요. 최대 9개까지 추가 가능합니다.
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
Kibana > 서버 타입 필수 Kibana가 설치될 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
Kibana > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
Kibana > Block Storage 필수 Kibana가 설치되는 서버에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
네트워크 > 공통 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 모든 서버에 동일한 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 자동 생성만 가능
- Public NAT 설정의 경우 서버별 설정에서만 가능합니다.
네트워크 > 서버별 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 서버별 다른 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 각 서버의 IP 입력
- Public NAT 기능은 VPC가 Internet Gateway에 연결되어 있어야 사용 가능, 사용을 체크하면 VPC 상품의 Public IP에서 예약된 IP 중에서 선택 가능. 자세한 내용은 Public IP 생성하기를 참고
IP 접근 제어 선택 서비스 접근 정책 설정 - 페이지에 입력된 IP에 대해 접근 정책을 설정하므로 별도로 Security Group 정책 설정은 수행하지 않아도 됩니다.
- IP 형식(예시:
192.168.10.1) 또는 CIDR 형식(예시:192.168.10.0/24,192.168.10.1/32)으로 입력하고, 추가 버튼을 클릭
- 입력한 IP를 삭제하려면, 입력한 IP 옆의 x 버튼을 클릭
유지 관리 기간 선택 Search Engine 유지 관리 기간 - 사용을 선택하면 요일, 시작 시간, 기간을 설정
- 서비스의 안정적인 관리를 위해 유지 관리 기간을 설정할 것을 권고합니다. 설정한 시간에 패치 작업이 진행되며 서비스 중단이 발생
- 미사용으로 설정 시, 패치 미적용으로 발생되는 문제점은 당사에서 책임지지 않습니다.
표. Search Engine 서비스 정보 입력 항목 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
- Database 구성 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 백업 > 사용 선택 노드 백업 사용 여부 - 노드 백업 사용 선택 시, 보관 기간 및 백업 시작 시간을 선택
백업 > 보관 기간 선택 백업 보관 기간 - 백업 보관 기간을 선택하세요. 파일 보관 기간은 7일 ~ 35일까지 설정
- 백업 파일은 용량에 따라 별도 과금이 발생됩니다.
백업 > 백업 시작 시간 선택 백업 시작 시간 - 백업 시작 시간을 선택
- 백업이 수행되는 분(minutes)은 랜덤으로 설정되며, 백업 종료 시간은 설정 불가
클러스터 Port 번호 필수 Elasticsearch 접속 포트 번호 1,024 ~ 65,535중 하나로 입력 가능하며, Elasticsearch 내부 포트인 9300과 Kibana 포트인 5301은 사용 불가
Elastic 사용자명 필수 Elasticsearch 사용자 이름 - 영문 소문자를 사용하여 2~20자 이내로 입력
- 아래 사용자명은 사용할 수 없습니다.
- apm_system, beats_system, elastic, kibana, kibana_system, logstash_system, remote_monitoring_user, scp_kibana_system, scp_manager, maxigent_cl
Elastic 비밀번호 필수 Elasticsearch 접속 비밀번호 - 영문, 숫자와 특수문자(
“‘</code>제외)를 포함하여 8~30자로 입력
Elastic 비밀번호 확인 필수 Elasticsearch 접속 비밀번호 확인 - Elasticsearch 접속 비밀번호 비밀번호를 동일하게 재입력
License Key 필수 Elasticsearch License Key - 발급받은 라이선스 파일(.json)에 있는 전체 내용을 입력
- 입력한 라이선스 key가 유효하지 않을 경우 서비스 생성이 안될 수 있습니다.
- OpenSearch는 License Key가 필요 없습니다.
시간대 선택 서비스가 사용될 표준 시간대 표. Search Engine Database 구성 필수 정보 입력 항목 - 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Search Engine 서비스 추가 정보 입력 항목
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, 자원 목록 페이지에서 생성한 자원을 확인하세요.
Search Engine 상세 정보 확인하기
Search Engine 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Search Engine 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Search Engine 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- Search Engine 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 클러스터 상태 클러스터 상태 - Creating: 클러스터가 만들어지는 중
- Editing: 클러스터가 Operation을 수행 상태로 변경 중
- Error: 클러스터가 작업을 수행하다 실패가 발생된 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Failed: 클러스터가 생성 과정 중 실패한 상태
- Restarting: 클러스터를 재시작하는 중
- Running: 클러스터가 정상적으로 동작하는 상태
- Starting: 클러스터를 시작하는 중
- Stopped: 클러스터가 중지된 상태
- Stopping: 클러스터를 중지 상태 중
- Synchronizing: 클러스터를 동기화 중
- Terminating: 클러스터를 삭제하는 중
- Unknown: 클러스터 상태를 알 수 없는 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Upgrading: 클러스터가 업그레이드를 수행 상태로 변경 중
클러스터 제어 클러스터 상태를 변경할 수 있는 버튼 - 시작: 중지된 클러스터를 시작합니다.
- 중지: 가동 중인 클러스터를 중지합니다.
- 재시작: 가동 중인 클러스터를 재시작 상태
추가 기능 더보기 클러스터 관련 관리 버튼 - 서비스 상태 동기화: 현재 서버 상태를 조회하여 Console에 동기화 가능
- 백업 이력: 백업 설정한 경우, 백업 정상 실행 여부 및 이력을 확인
- 클러스터 복구: 특정 시점 기반으로 클러스터를 복구합니다.
- Node 추가: 데이터 노드를 추가합니다.
서비스 해지 서비스를 해지하는 버튼 표. Search Engine 상태 정보 및 부가 기능
- Search Engine 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Search Engine 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서버 정보 | 해당 클러스터에 구성되어 있는 서버 정보
|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 이미지/버전 | 설치된 서비스 이미지 및 버전 정보 |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| 유지 관리 기간 | 유지 관리 기간 현황
|
| 백업 | 백업 설정 현황
|
| 시간대 | 서비스가 사용될 표준 시간대 |
| License | Elasticsearch 라이선스 정보
|
| Elastic 사용자명 | Elasticsearch 사용자 이름 |
| Kibana 접속 정보 | Kibana 접속 정보 |
| 네트워크 | 설치된 네트워크 정보(VPC, Subnet) |
| IP 접근 제어 | 서비스 접근 정책 설정
|
| Master | Master 노드에 대한 서버 타입, 기본 OS, 추가 Disk 정보
|
| Data | Broker 노드에 대한 서버 타입, 기본 OS, 추가 Disk 정보
|
| Kibana | Kibana 노드에 대한 서버 타입, 기본 OS 정보
|
표. Search Engine 상세 정보 항목
태그
Search Engine 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Search Engine 태그 탭 항목
작업 이력
Search Engine 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Search Engine 작업 이력 탭 상세 정보 항목
Search Engine 자원 관리하기
생성된 Search Engine 자원의 기존 설정 옵션을 변경하거나 Parameter 관리, Node 추가 구성이 필요한 경우에는 Search Engine 상세 정보 페이지에서 작업을 수행할 수 있습니다.
가동 제어하기
가동 중인 Search Engine 자원의 변경 사항이 발생할 경우, 시작, 중지, 재시작을 할 수 있습니다.
Search Engine의 가동 제어를 하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 가동 제어할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- Search Engine 상태를 확인하고, 아래 제어 버튼을 통해 변경을 완료하세요.
- 시작: Search Engine 서비스가 설치된 서버와 Search Engine 서비스가 가동(Running)됩니다.
- 중지: Search Engine 서비스가 설치된 서버와 Search Engine 서비스가 중단(Stopped)됩니다.
- 재시작: Search Engine 서비스만 재시작됩니다.
서비스 상태 동기화하기
현재의 서버 상태를 조회하여 Console에 동기화할 수 있습니다.
Search Engine의 서비스 상태를 동기화하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 서비스 상태를 조회할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 서비스 상태 동기화 버튼을 클릭하세요. 조회하는데 약간의 시간이 소요되며, 조회되는 동안 클러스터는 Synchronizing 상태로 변경됩니다.
- 조회가 완료되면 서버 정보 항목에 상태가 업데이트되며, 클러스터는 Running 상태로 변경됩니다.
서버 타입 변경하기
구성된 서버 타입을 변경할 수 있습니다.
서버 타입을 변경하려면 다음 절차를 따르세요.
주의
- 서버 타입을 Standard로 구성한 경우에는 High Capacity로 변경할 수 없습니다. High Capacity로 변경하고자 할 경우, 서비스를 신규로 생성하세요.
- 서버 타입을 수정하면 서버 재가동이 필요합니다. 스펙 변경에 따른 SW 라이선스 수정 사항 또는 SW 설정 및 반영은 별도 확인해주세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 상세 정보 하단의 변경하고자 하는 서버 타입의 수정 버튼을 클릭하세요. 서버 타입 수정 팝업창이 열립니다.
- 서버 타입 수정 팝업창에서 서버 타입을 선택한 후, 확인 버튼을 클릭하세요.
스토리지 증설하기
데이터 영역으로 추가된 스토리지를 최초 할당한 용량 기반 최대 5TB까지 증설할 수 있습니다. Search Engine를 중단하지 않고 스토리지를 증설할 수 있으며, 클러스터로 구성된 경우 모든 노드가 동시에 증설됩니다.
안내
- 기존 Block Storage에 암호화 설정이 된 경우 추가 Disk에도 암호화가 적용됩니다.
- 디스크 사이즈 수정은 현재 디스크 사이즈보다 16GB 이상 증설만 가능합니다.
스토리지 용량을 증설하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 상세 정보 하단의 증설하고자 하는 추가된 Disk의 수정 버튼을 클릭하세요. Disk 수정 팝업창이 열립니다.
- Disk 수정 팝업창에서 증설 용량 입력한 후, 확인 버튼을 클릭하세요.
스토리지 추가하기
데이터 저장 공간이 5TB 이상 필요한 경우, 스토리지를 추가할 수 있습니다.
안내
- 기존 Block Storage에 암호화 설정이 된 경우 추가 Disk에도 암호화가 적용됩니다.
스토리지 용량을 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 스토리지 추가할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 상세 정보 하단의 Disk 추가 버튼을 클릭하세요. Disk 추가 팝업창이 열립니다.
- Disk 추가 팝업창에서 용도, 용량 입력한 후, 확인 버튼을 클릭하세요.
Search Engine 백업하기
백업 설정 기능을 통해 사용자는 데이터 보관 기간, 시작 주기를 설정할 수 있으며, 백업 이력 기능을 통해 백업 내역 조회 및 삭제를 수행할 수 있습니다.
백업 설정하기
Search Engine을 생성하면서 백업 설정하는 절차는 Search Engine 생성하기 가이드를 참고하시기 바라며, 생성된 자원의 백업 설정을 수정하려면 다음 절차를 따르세요.
주의
- 백업을 설정한 경우에는 설정한 시간 이후 지정된 시간에 백업이 수행되며, 백업 용량에 따라 추가 요금이 발생합니다.
- 백업 설정을 미설정으로 변경할 경우에는 백업 수행이 즉시 중지되며, 저장된 백업 데이터는 삭제되어 더 이상 사용이 불가합니다.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 백업을 설정할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 백업 항목의 수정 버튼을 클릭하세요. 백업 수정 팝업창이 열립니다.
- 백업 설정을 할 경우에는 백업 수정 팝업창에서 사용을 클릭하고, 보관 기간, 백업 시작 시간, Archive 백업 주기를 선택하여 확인 버튼을 클릭하세요.
- 백업 설정을 중지할 경우에는 백업 수정 팝업창에서 사용을 해제하고, 확인 버튼을 클릭하세요.
백업 이력 확인하기
안내
백업 성공 및 실패에 대한 알림을 설정하려면 Notification Manager 상품을 통해 설정할 수 있습니다. 알림 정책 설정에 대한 자세한 사용 가이드는 알림 정책 생성하기를 참고하세요.
백업 이력을 조회하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 백업 이력을 확인할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 백업 이력 버튼을 클릭하세요. 백업 이력 팝업창이 열립니다.
- 백업 이력 팝업창에서 백업 상태, 버전, 백업 시작 일시, 백업 완료 일시, 용량을 확인할 수 있습니다.
백업 파일 삭제하기
백업 이력을 삭제하려면 다음 절차를 따르세요.
주의
삭제된 백업 파일은 복원할 수 없으니 필요 없는 데이터인지 반드시 확인한 후에 삭제해주세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 백업 이력을 확인할 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 백업 이력 버튼을 클릭하세요. 백업 이력 팝업창이 열립니다.
- 백업 이력 팝업창에서 삭제하고자 하는 파일을 체크한 후, 삭제 버튼을 클릭하세요.
Search Engine 복구하기
장애 혹은 데이터 손실로 인하여 백업 파일로 복원이 필요한 경우 클러스터 복구 기능을 통해 특정 시점 기반으로 복구가 가능합니다.
주의
복구 수행을 위해서는 데이터 유형 Disk 용량과 적어도 동일한 용량이 필요합니다. Disk 용량이 부족할 경우 복구가 실패할 수 있습니다.
안내
클러스터 복구는 원본과 동일한 구성으로 복원됩니다. 예를 들어 Master 노드 3개, Data 노드 2개로 구성되어 있다면 동일한 구성으로 복원됩니다
Search Engine를 복구하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 자원 목록 페이지에서 복구하고자 하는 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- 클러스터 복구 버튼을 클릭하세요. 클러스터 복구 페이지로 이동합니다.
- 클러스터 복구 구성 영역에 해당 정보를 입력한 후, 완료 버튼을 클릭하세요.
구분 필수 여부상세 설명 복구 시점 필수 사용자가 복구하고자 하는 시점 설정 - 목록에 표시되는 백업 파일의 시점 목록에서 선택
서버명 Prefix 필수 복구 서버 이름 - 영문 소문자로 시작하여 소문자, 숫자와 특수문자(
-)를 사용하여 3~16자로 입력
- 서버명 기반으로 001, 002와 같은 postfix 가 붙어 실제 서버명이 생성됨
클러스터명 필수 복구 서버 클러스터명 - 영문을 사용하여 3 ~ 20자로 입력
- 클러스터는 여러 개의 서버를 묶는 단위
Node 수 필수 데이터 노드 수 - 원본 클러스터에 설정된 노드 수와 동일하게 설정됩니다.
서비스 유형 > 서버 타입 필수 데이터 노드 서버 타입 - 원본 클러스터에 설정된 노드 수와 동일하게 설정됩니다.
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 데이터 노드에 사용될 Block Storage - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 원본 클러스터에서 설정한 Storage 유형으로 동일하게 적용
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- Disk 추가: 데이터, 백업 추가 저장 영역
- 사용을 선택한 후 스토리지의 용도, 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
MasterNode 별도 설치 > 사용 필수 Master 노드 별도 설치 여부 - 원본 클러스터의 설치 여부에 따라 동일하게 적용
MasterNode 별도 설치 > MasterNode 수 필수 Master 노드 수 MasterNode 별도 설치 > 서버 타입 필수 Master 노드 서버 타입 - 원본 클러스터에 설정된 노드 수와 동일하게 설정됩니다.
MasterNode 별도 설치 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
MasterNode 별도 설치 > Block Storage 필수 Master 노드에 사용될 Block Storage - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 원본 클러스터에서 설정한 Storage 유형으로 동일하게 적용
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- Disk 추가: 데이터 추가 저장 영역
- 사용을 선택한 후 스토리지의 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
Kibana > 서버 타입 필수 Kibana 노드 서버 타입 - 원본 클러스터에 설정된 노드 수와 동일하게 설정됩니다.
Kibana > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
Kibana > Block Storage 필수 Kibana 노드에 사용될 Block Storage - 기본 OS: 엔진이 설치되는 영역
클러스터 Port 번호 필수 Elasticsearch 접속 포트 번호 - 원본 클러스터에 설정된 포트 번호로 동일하게 설정됩니다.
Licnese Key 필수 Elasticsearch License Key - 발급받은 라이선스 파일(.json)에 있는 전체 내용을 입력
- 입력한 라이선스 key가 유효하지 않을 경우 서비스 생성이 안될 수 있습니다.
- OpenSearch는 License Key가 필요 없습니다.
IP 접근 제어 선택 서비스 접근 정책 설정 - 페이지에 입력된 IP에 대해 접근 정책을 설정하므로 별도로 Security Group 정책 설정은 수행하지 않아도 됩니다.
- IP 형식(예시:
192.168.10.1) 또는 CIDR 형식(예시:192.168.10.0/24,192.168.10.1/32)으로 입력하고, 추가 버튼을 클릭
- 입력한 IP를 삭제하려면, 입력한 IP 옆의 x 버튼을 클릭
유지 관리 기간 선택 유지 관리 기간 - 사용을 선택하면 요일, 시작 시간, 기간을 설정
- 서비스의 안정적인 관리를 위해 유지 관리 기간을 설정할 것을 권고합니다. 설정한 시간에 패치 작업이 진행되며 서비스 중단이 발생
- 미사용으로 설정 시, 패치 미적용으로 발생되는 문제점은 당사에서 책임지지 않습니다.
표. Search Engine 복구 구성 항목
Node 추가하기
Search Engine 클러스터 확장이 필요한 경우, 사용 중인 데이터 노드와 동일한 사양으로 노드를 추가할수 있습니다.
안내
- 클러스터 내에서 최대 10개의 노드를 사용할 수 있습니다. 생성된 노드에 대해서는 추과 과금되므로 참고하세요.
- 노드 추가 중에는 클러스터의 성능이 저하될 수 있습니다.
노드를 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engines 자원 목록 페이지에서 복구하고자 하는 자원을 클릭하세요. Search Engine 상세 페이지로 이동합니다.
- Broker Node 추가 버튼을 클릭하세요. Broker Node 추가 페이지로 이동합니다.
- 필수 정보 입력 영역에 해당 정보를 입력한 후, 완료 버튼을 클릭하세요.
구분 필수 여부상세 설명 서버명 Prefix 필수 데이터 노드 서버 이름 - 원본 클러스터에 설정된 서버명으로 설정됩니다.
클러스터명 필수 클러스터 이름 - 원본 클러스터에 설정된 클러스터명으로 설정됩니다.
추가 Node 수 필수 추가할 Node 수 - 하나의 클러스터에 최대 10개의 노드를 사용
서비스 유형 > 서버 타입 필수 데이터 노드 서버 타입 - 원본 클러스터에 설정된 서버 타입으로 동일하게 설정됩니다.
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 데이터 노드에 사용될 Block Storage 설정 - 원본 클러스터에서 설정한 Storage 유형 및 용량이 동일하게 적용
네트워크 필수 서버들이 설치되는 네트워크 - 원본 클러스터에서 설정한 네트워크와 동일하게 적용
표. Search Engine Node 추가 항목
Search Engine 해지하기
사용하지 않는 Search Engine을 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Search Engine를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Search Engine 메뉴를 클릭하세요. Search Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Search Engine 메뉴를 클릭하세요. Search Engine 목록 페이지로 이동합니다.
- Search Engine 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Search Engine 목록 페이지에서 자원이 해지되었는지 확인하세요.
2.3 - API Reference
API Reference
2.4 - CLI Reference
CLI Reference
2.5 - Release Note
Search Engine
2025.07.01
FEATURE
신규 기능, Terraform 및 디스크 타입 추가- OpenSearch 2.17.1을 신규로 제공합니다.
- Terraform을 제공합니다.
- HDD, HDD_KMS 디스크 타입을 추가 제공합니다.
2025.02.27
NEW
Search Engine 서비스 정식 버전 출시- 웹 환경에서 ElasticSearch Enterprise를 간편하게 생성하고 관리 기능이 가능한 Search Engine 서비스가 출시되었습니다.
3 - Vertica(DBaaS)
3.1 - Overview
서비스 개요
Vertica(DBaaS)는 대용량 데이터 분석/처리를 위한 Data Warehouse 기반의 고가용성 엔터프라이즈 데이터베이스 입니다. 하나의 엔진을 통해 다양한 곳에서 들어오는 데이터들을 이동 없이 조회와 같은 기본 분석은 물론 머신러닝 등의 AI 분석을 수행할 수 있는 데이터 분석 플랫폼으로 Samsung Cloud Platform에서 단일 인스턴스나 중요 데이터의 안정적인 관리를 위해 고가용성 구성, 백업/복구, 패치, 파라미터 관리, 모니터링 등 DB 관리 기능을 추가하여 데이터베이스의 생명주기 내 업무를 자동화할 수 있습니다. 또한, DB 서버나 데이터에 문제가 있을 경우를 대비하여 사용자가 지정한 시간에 자동으로 백업하는 기능을 제공하여 원하는 시점에 데이터를 복구할 수 있도록 지원합니다.
서비스 구성도
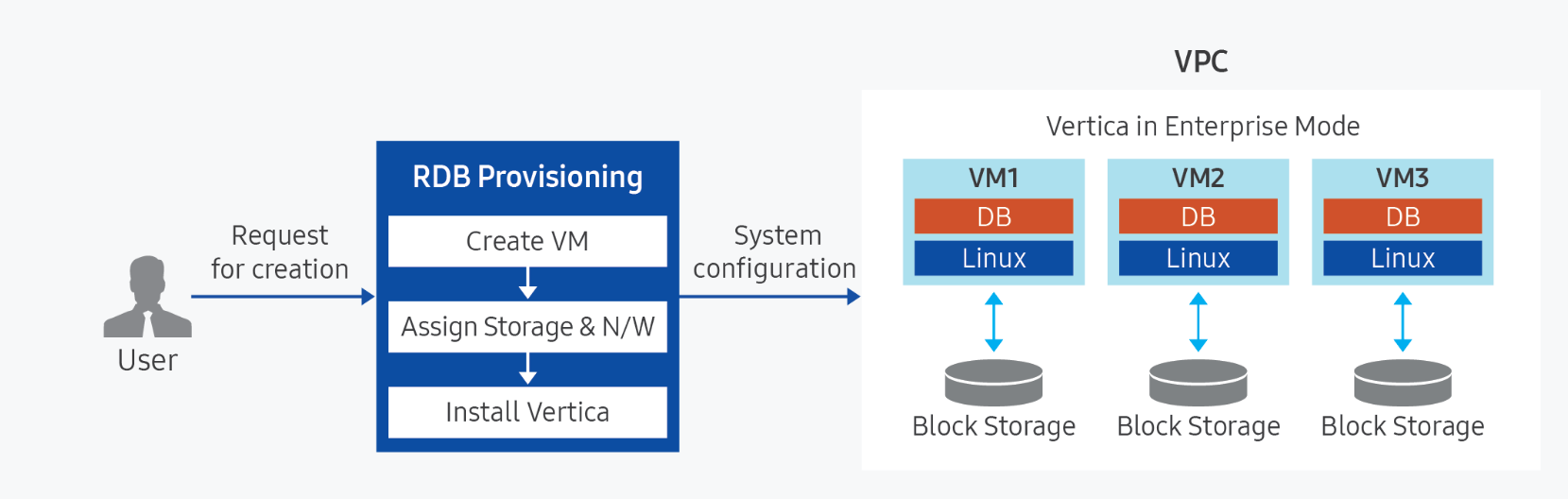
제공 기능
Vertica(DBaaS)는 다음과 같은 기능을 제공하고 있습니다.
- 자동 프로비저닝(Auto Provisioning): 다양한 사양의 Virtual Server를 기반으로 Samsung Cloud Platform 표준 버전의 DB를 자동 설치합니다.
- 클러스터 구성: Masterless 형태로 자체 고가용성 아키텍처를 제공합니다.
- 가동 제어 관리: 가동 중인 서버 상태를 제어하는 기능을 제공합니다. 서버를 시작, 중지할 수 있으며 DB에 이상이 있거나 설정값 반영을 위해 재시작이 가능합니다.
- 백업 및 복구: 자체 백업 명령어 기반의 데이터 백업 기능을 제공합니다. 백업 보관기간과 백업 시작시간은 사용자가 설정할 수 있으며, 백업 용량에 따라 추가 요금이 발생합니다. 그리고 백업된 데이터의 복구 기능을 제공하여 사용자는 복구를 수행하면 별도의 DB가 생성되며 사용자가 선택한 시점(백업 저장 시점, 사용자 지정 시점)으로 복구가 진행됩니다. Database 복구시에 Management Console의 설치를 선택하여 사용할 수 있습니다.
- 서비스 상태 조회: 현재 DB 서비스의 최종 상태를 조회할 수 있습니다.
- 모니터링: CPU, 메모리, DB 성능 모니터링 정보를 Cloud Monitoring 서비스를 통해 확인할 수 있습니다.
- 대용량 데이터 고성능 처리: 대량 병렬 처리(MPP, Massively Parallel Processing)와 SQL 조회의 Mixed Workload 환경에서 안정적인 성능을 보장합니다. Vertica는 분산 프로세싱을 통해 쿼리를 처리하며, 어느 노드에서나 쿼리를 시작할 수 있는 구조를 가지고있어 특정 노드 장애시 쿼리가 수행되지 않는 Single Point of Failure가 발생하지 않습니다.
구성 요소
Vertica(DBaaS)는 사전에 검증된 엔진 버전과 다양한 서버 타입을 제공하고 있습니다. 사용자는 구성하고자 하는 서비스 규모에 따라 이를 선택하여 사용할 수 있습니다.
엔진 버전
Vertica(DBaaS)에서 지원하는 엔진 버전은 다음과 같습니다.
기술 지원은 공급사의 EoTS(End of Technical Service) 일자까지 사용할 수 있으며, 신규 생성이 중지되는 EOS 일자는 EoTS 일자로부터 6개월 전으로 정해집니다.
공급사 정책에 따라 EOS, EoTS 일자는 변동될 수 있으므로, 자세한 사항은 공급사의 라이선스 관리 정책 페이지를 참고해주세요.
| 제공 버전 | EOS date(Samsung Cloud Platform 신규 생성 중지일자) | EoTS date(공급사 기술지원 종료일자) |
|---|---|---|
| 24.2.0-2 | 2026-09 (예정) | 2027-04-30 |
표. Vertica(DBaaS) 서비스 제공 엔진 버전
서버 타입
Vertica(DBaaS)에서 지원하는 서버 타입은 다음 형식과 같습니다.
Vertica(DBaaS)에서 제공하는 서버 타입에 대한 자세한 내용은 Vertica 서버 타입을 참고하세요.
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입
|
| 서버 사양 | Db1 | 제공되는 서버 사양
|
| 서버 사양 | V2 | vCore 개수
|
| 서버 사양 | M4 | 메모리 용량
|
표. Vertica(DBaaS) 서버 타입 구성 요소
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
표. Vertica(DBaaS) 선행 서비스
3.1.1 - 서버 타입
Vertica(DBaaS) 서버 타입
Vertica(DBaaS)는 CPU, Memory, Network Bandwidth 등 다양한 조합으로 구성된 서버 타입을 제공합니다. Vertica(DBaaS)를 생성할 때 사용 목적에 맞게 선택한 서버 타입에 따라 Database Engine이 설치됩니다.
Vertica(DBaaS)에서 지원하는 서버 타입은 다음 형식과 같습니다.
Standard db1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | db1 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
표. Vertica(DBaaS) 서버 타입 형식
db1 서버 타입
Vertica(DBaaS)의 db1 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.3Ghz의 Intel 3세대(Ice Lake) Xeon Gold 6342 Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | db1v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | db1v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | db1v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | db1v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | db1v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | db1v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | db1v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | db1v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | db1v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | db1v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | db1v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | db1v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | db1v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | db1v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | db1v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | db1v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | db1v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | db1v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | db1v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | db1v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | db1v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | db1v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | db1v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | db1v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | db1v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | db1v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | db1v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | db1v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | db1v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | db1v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | db1v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | db1v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | db1v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | db1v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | db1v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | db1v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | db1v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | db1v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | db1v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | db1v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | db1v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Vertica(DBaaS) 서버 타입 사양 - db1 서버 타입
db2 서버 타입
Vertica(DBaaS)의 db2 서버 타입은 표준 사양(vCPU, Memory)으로 제공하며 다양한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 16개의 vCPU 및 256 GB의 메모리를 지원
- 최대 12.5 Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | db2v1m2 | 1 vCore | 2 GB | 최대 10 Gbps |
| Standard | db2v2m4 | 2 vCore | 4 GB | 최대 10 Gbps |
| Standard | db2v2m8 | 2 vCore | 8 GB | 최대 10 Gbps |
| Standard | db2v2m16 | 2 vCore | 16 GB | 최대 10 Gbps |
| Standard | db2v2m24 | 2 vCore | 24 GB | 최대 10 Gbps |
| Standard | db2v2m32 | 2 vCore | 32 GB | 최대 10 Gbps |
| Standard | db2v4m8 | 4 vCore | 8 GB | 최대 10 Gbps |
| Standard | db2v4m16 | 4 vCore | 16 GB | 최대 10 Gbps |
| Standard | db2v4m32 | 4 vCore | 32 GB | 최대 10 Gbps |
| Standard | db2v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | db2v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | db2v6m12 | 6 vCore | 12 GB | 최대 10 Gbps |
| Standard | db2v6m24 | 6 vCore | 24 GB | 최대 10 Gbps |
| Standard | db2v6m48 | 6 vCore | 48 GB | 최대 10 Gbps |
| Standard | db2v6m72 | 6 vCore | 72 GB | 최대 10 Gbps |
| Standard | db2v6m96 | 6 vCore | 96 GB | 최대 10 Gbps |
| Standard | db2v8m16 | 8 vCore | 16 GB | 최대 10 Gbps |
| Standard | db2v8m32 | 8 vCore | 32 GB | 최대 10 Gbps |
| Standard | db2v8m64 | 8 vCore | 64 GB | 최대 10 Gbps |
| Standard | db2v8m96 | 8 vCore | 96 GB | 최대 10 Gbps |
| Standard | db2v8m128 | 8 vCore | 128 GB | 최대 10 Gbps |
| Standard | db2v10m20 | 10 vCore | 20 GB | 최대 10 Gbps |
| Standard | db2v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | db2v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | db2v10m120 | 10 vCore | 120 GB | 최대 10 Gbps |
| Standard | db2v10m160 | 10 vCore | 160 GB | 최대 10 Gbps |
| Standard | db2v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | db2v12m48 | 12 vCore | 48 GB | 최대 12.5 Gbps |
| Standard | db2v12m96 | 12 vCore | 96 GB | 최대 12.5 Gbps |
| Standard | db2v12m144 | 12 vCore | 144 GB | 최대 12.5 Gbps |
| Standard | db2v12m192 | 12 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | db2v14m28 | 14 vCore | 28 GB | 최대 12.5 Gbps |
| Standard | db2v14m56 | 14 vCore | 56 GB | 최대 12.5 Gbps |
| Standard | db2v14m112 | 14 vCore | 112 GB | 최대 12.5 Gbps |
| Standard | db2v14m168 | 14 vCore | 168 GB | 최대 12.5 Gbps |
| Standard | db2v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | db2v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | db2v16m64 | 16 vCore | 64 GB | 최대 12.5 Gbps |
| Standard | db2v16m128 | 16 vCore | 128 GB | 최대 12.5 Gbps |
| Standard | db2v16m192 | 16 vCore | 192 GB | 최대 12.5 Gbps |
| Standard | db2v16m256 | 16 vCore | 256 GB | 최대 12.5 Gbps |
표. Vertica(DBaaS) 서버 타입 사양 - db2 서버 타입
dbh2 서버 타입
Vertica(DBaaS)의 dbh2 서버 타입은 대용량 서버 사양으로 제공하며, 대규모 데이터 처리를 위한 데이터베이스 워크로드에 적합합니다.
- 최대 3.2GHz의 Intel 4세대(Sapphire Rapids) Xeon Gold 6448H Processor
- 최대 128개의 vCPU 및 1,536 GB의 메모리를 지원
- 최대 25Gbps의 네트워킹 속도
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | dbh2v24m48 | 24 vCore | 48 GB | 최대 25 Gbps |
| High Capacity | dbh2v24m96 | 24 vCore | 96 GB | 최대 25 Gbps |
| High Capacity | dbh2v24m192 | 24 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | dbh2v24m288 | 24 vCore | 288 GB | 최대 25 Gbps |
| High Capacity | dbh2v32m64 | 32 vCore | 64 GB | 최대 25 Gbps |
| High Capacity | dbh2v32m128 | 32 vCore | 128 GB | 최대 25 Gbps |
| High Capacity | dbh2v32m256 | 32 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | dbh2v32m384 | 32 vCore | 384 GB | 최대 25 Gbps |
| High Capacity | dbh2v48m192 | 48 vCore | 192 GB | 최대 25 Gbps |
| High Capacity | dbh2v48m576 | 48 vCore | 576 GB | 최대 25 Gbps |
| High Capacity | dbh2v64m256 | 64 vCore | 256 GB | 최대 25 Gbps |
| High Capacity | dbh2v64m768 | 64 vCore | 768 GB | 최대 25 Gbps |
| High Capacity | dbh2v72m288 | 72 vCore | 288 GB | 최대 25 Gbps |
| High Capacity | dbh2v72m864 | 72 vCore | 864 GB | 최대 25 Gbps |
| High Capacity | dbh2v96m384 | 96 vCore | 384 GB | 최대 25 Gbps |
| High Capacity | dbh2v96m1152 | 96 vCore | 1152 GB | 최대 25 Gbps |
| High Capacity | dbh2v128m512 | 128 vCore | 512 GB | 최대 25 Gbps |
| High Capacity | dbh2v128m1536 | 128 vCore | 1536 GB | 최대 25 Gbps |
표. Vertica(DBaaS) 서버 타입 사양 - dbh2 서버 타입
3.1.2 - 모니터링 지표
Vertica(DBaaS) 모니터링 지표
아래 표는 Cloud Monitoring을 통해 확인할 수 있는 Vertica(DBaaS)의 성능 모니터링 지표를 나타냅니다. 자세한 Cloud Monitoring 사용 방법은 Cloud Monitoring 가이드를 참고하세요.
Vertica(DBaaS)의 서버 모니터링 지표는 Virtual Server 모니터링 지표 가이드를 참고하세요.
| 성능 항목 | 상세 설명 | 단위 |
|---|---|---|
| Active Locks | Active Locks 개수 | cnt |
| Active Sessions | Active 상태인 Session 총 개수 | cnt |
| Instance Status | 노드 alive 상태 | status |
| Tablespace Used | Tablespace 사용량 | bytes |
표. Vertica(DBaaS) 모니터링 지표
3.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Vertica(DBaaS)의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Vertica(DBaaS) 생성하기
Samsung Cloud Platform Console에서 Vertica(DBaaS) 서비스를 생성하여 사용할 수 있습니다.
Vertica(DBaaS)를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Vertica(DBaaS) 생성 버튼을 클릭하세요. ** 생성** 페이지로 이동합니다.
Vertica(DBaaS) 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 이미지 버전 필수 Vertica(DBaaS)의 버전 리스트 제공 표. Vertica(DBaaS) 이미지 및 버전 입력 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 서버명 Prefix 필수 Vertica가 설치될 서버 이름 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
-)를 사용하여 3 ~ 13자로 입력
- 서버명 기반으로 001, 002와 같은 Postfix가 붙어 실제 서버명이 생성됨
클러스터명 필수 서버들이 구성된 클러스터명 - 영문을 사용하여 3 ~ 20자로 입력
- 클러스터는 여러 개의 서버를 묶는 단위
Node 수 필수 데이터 노드 수 - 노드 수는 1-10개 범위에서 입력
- Node 수를 2 이상으로 입력해 클러스터를 구성하면 고가용성(High Availability)을 확보
서비스 유형 > 서버 타입 필수 데이터 노드 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
- Vertica(DBaaS)에서 제공하는 서버 타입에 대한 자세한 내용은 Vertica(DBaaS) 서버 타입을 참고
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 데이터 노드에 사용될 Block Storage 유형 - 기본 OS: 엔진이 설치되는 영역
- DATA: 데이터 파일 저장 영역
- 스토리지 유형을 선택한 후 용량을 입력(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- SSD: 일반 Block Storage
- SSD_KMS: KMS(Key Management System) 암호화키를 사용하는 추가 암호화 볼륨
- 설정한 Storage 유형은 추가 스토리지에도 동일하게 적용
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력
- 스토리지 유형을 선택한 후 용량을 입력(Block Storage 유형별 자세한 내용은 Block Storage 생성하기를 참고)
- 추가: DATA, Backup 데이터 저장 영역
- 사용을 선택한 후, 스토리지의 용도, 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭, 최대 9개까지 추가 가능
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
Management Console 선택 사용을 선택하면 클러스터 관리 및 모니터링을 위한 Node의 서버 타입과 Block Storage 설정 Management Console > 서버 타입 필수 클러스터 관리 및 모니터링을 위한 데이터 노드 서버 타입 선택 Management Console > Block Storage 필수 클러스터 관리 및 모니터링을 위한 데이터 노드에 사용될 Block Storage 유형 선택 네트워크 > 공통 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 모든 서버에 동일한 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 각 서버의 IP 입력
- Public NAT 설정은 서버별 설정에서만 가능
네트워크 > 서버별 설정 필수 서비스에서 생성되는 서버들이 설치되는 네트워크 설정 - 설치하는 서버별 다른 설정을 적용하려는 경우 선택
- 미리 생성한 VPC와 Subnet을 선택
- IP: 각 서버의 IP 입력
- Public NAT 기능은 VPC가 Internet Gateway에 연결되어 있어야 사용 가능, 사용을 체크하면 VPC 상품의 Public IP에서 예약된 IP 중에서 선택 가능. 자세한 내용은 Public IP 생성하기를 참고
IP 접근 제어 선택 서비스 접근 정책 설정 - 페이지에 입력된 IP에 대해 접근 정책을 설정하므로 별도로 Security Group 정책 설정은 수행하지 않아도 됨
- IP 형식(예시:
192.168.10.1) 또는 CIDR 형식(예시:192.168.10.0/24,192.168.10.1/32)으로 입력하고, 추가 버튼을 클릭
- 입력한 IP를 삭제하려면, 입력한 IP 옆의 x 버튼을 클릭
유지 관리 기간 선택 DB 유지 관리 기간 - 사용을 선택하면 요일, 시작 시간, 기간을 설정
- DB의 안정적인 관리를 위해 유지 관리 기간을 설정할 것을 권고. 설정한 시간에 패치 작업이 진행되며 서비스 중단이 발생
- 미사용으로 설정 시, 패치 미적용으로 발생되는 문제점은 삼성SDS에서 책임지지 않습니다.
표. Vertica(DBaaS) 서비스 구성 항목 - 영문 소문자로 시작하며, 소문자, 숫자와 특수문자(
- Database 구성 필수 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Database명 필수 DB 설치 시 적용되는 서버 이름 - 영문으로 시작하며, 영문과 숫자를 사용하여 3 ~ 20자로 입력
Database 사용자명 필수 DB 사용자 이름 - OS에도 해당 이름으로 계정이 생성됨
- 영문 소문자를 사용하여 2 ~ 20자로 입력
- 사용이 제한된 Database 사용자명은 Console에서 확인 가능
Database 비밀번호 필수 DB 접근 시 사용할 비밀번호 - 영문, 숫자와 특수문자(
“‘제외)를 포함하여 8~30자로 입력
Database 비밀번호 확인 필수 DB 접근 시 사용할 비밀번호를 동일하게 재입력 Database Port번호 필수 DB 접속에 필요한 포트 번호 - DB 포트는 1,024 ~ 65,535 범위 안에서 입력
백업 > 사용 선택 노드 백업 사용 여부 - 사용을 선택하여 노드 백업 보관 기간 및 백업 시작 시간을 선택
백업 > 보관 기간 선택 백업 보관 기간 - 백업 보관 기간을 선택. 파일 보관 기간은 7일 ~ 35일까지 설정
- 백업 파일은 용량에 따라 별도 요금이 부과됨
백업 > 백업 시작 시간 선택 백업 시작 시간 - 백업 시작 시간을 선택
- 백업이 수행되는 분(minutes)은 랜덤으로 설정되며, 백업 종료 시간은 설정 불가
License Key 필수 고객이 보유한 Vertica License Key 입력 - 입력한 라이선스 key가 유효하지 않을 경우 서비스 생성 불가
DB Locale 필수 Vertica(DBaaS)에 사용할 문자열 처리, 숫자/통화/날짜/시간 표시형식 등과 관련된 설정 - 선택한 Locale로 기본 설정되어 DB가 생성됨
시간대 필수 Vertica(DBaaS)에 사용할 표준 시간대 표. Vertica(DBaaS) 필수 구성 항목 - 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Vertica(DBaaS) 추가 정보 입력 항목
- 이미지 및 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, 자원 목록 페이지에서 생성한 자원을 확인하세요.
Vertica(DBaaS) 상세 정보 확인하기
Vertica(DBaaS) 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Vertica(DBaaS) 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Vertica(DBaaS) 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- Vertica(DBaaS) 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 클러스터 상태 클러스터 상태 - Creating: 클러스터 생성 중
- Editing: 클러스터가 Operation을 수행 상태로 변경 중
- Error: 클러스터가 작업 수행 중 실패가 발생된 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Failed: 클러스터가 생성 과정 중 실패한 상태
- Restarting: 클러스터를 재시작하는 중
- Running: 클러스터가 정상적으로 동작하는 상태
- Starting: 클러스터를 시작하는 중
- Stopped: 클러스터가 중지된 상태
- Stopping: 클러스터를 중지 상태 중
- Synchronizing: 클러스터를 동기화 중
- Terminating: 클러스터를 삭제하는 중
- Unknown: 클러스터 상태를 알 수 없는 상태
- 지속적으로 발생될 경우, 관리자에게 문의
- Upgrading: 클러스터가 업그레이드를 수행 상태로 변경 중
클러스터 제어 클러스터 상태를 변경할 수 있는 버튼 - 시작: 중지된 클러스터를 시작
- 중지: 가동 중인 클러스터를 중지
- 재시작: 가동 중인 클러스터를 재시작
추가 기능 더보기 클러스터 관련 관리 버튼 - 서비스 상태 동기화: 실시간 DB 서비스 상태 조회
- 백업 이력: 백업 설정한 경우, 백업 정상 실행 여부 및 이력을 확인
- Database 복구: 특정 시점 기반으로 DB를 복구
서비스 해지 서비스를 해지하는 버튼 표. Vertica(DBaaS) 상태 정보 및 부가 기능
- Vertica(DBaaS) 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Vertica(DBaaS) 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서버 정보 | 해당 클러스터에 구성되어 있는 서버 정보
|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 이미지/버전 | 설치된 DB 이미지 및 버전 정보 |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| Database 명 | DB 설치 시 적용된 서버 이름 |
| Database 사용자명 | DB 사용자 이름 |
| Planned Compute | Planned Compute가 설정된 자원 현황
|
| 유지 관리 기간 | DB 유지 관리 기간 현황
|
| 백업 | 백업 설정 현황
|
| Managed Console | DB 설치 시 설정된 Managed Console 자원 현황 |
| 네트워크 | 설치된 네트워크 정보(VPC, Subnet) |
| IP 접근 제어 | 서비스 접근 정책 설정
|
| 시간대 | Vertica(DBaaS) DB가 사용될 표준 시간대 |
| License | Vertica(DBaaS) 라이선스 정보 |
| 서버 정보 | Data/Console 서버 타입, 기본 OS, 추가 Disk 정보
|
표. Vertica(DBaaS) 상세 정보 항목
태그
Vertica(DBaaS) 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Vertica(DBaaS) 태그 탭 항목
작업 이력
Vertica(DBaaS) 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Vertica(DBaaS) 작업 이력 탭 상세 정보 항목
Vertica(DBaaS) 자원 관리하기
생성된 Vertica(DBaaS) 자원의 기존 설정 옵션을 변경하거나 스토리지 추가 구성이 필요한 경우에는 Vertica(DBaaS) 상세 정보 페이지에서 작업을 수행할 수 있습니다.
가동 제어하기
가동 중인 Vertica(DBaaS) 자원의 변경 사항이 발생할 경우, 시작, 중지, 재시작을 할 수 있습니다.
Vertica(DBaaS)의 가동 제어를 하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 가동 제어할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- Vertica(DBaaS) 상태를 확인하고, 아래 제어 버튼을 통해 변경을 완료하세요.
- 시작: Vertica(DBaaS) 서비스가 설치된 서버와 Vertica(DBaaS) 서비스가 가동(Running)됩니다.
- 중지: Vertica(DBaaS) 서비스가 설치된 서버와 Vertica(DBaaS) 서비스가 중단(Stopped)됩니다.
- 재시작: Vertica(DBaaS) 서비스만 재시작됩니다.
서비스 상태 동기화하기
Vertica(DBaaS)의 실시간 서비스 상태를 동기화할 수 있습니다.
Vertica(DBaaS)의 서비스 상태를 조회하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 서비스 상태를 조회할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 서비스 상태 동기화 버튼을 클릭하세요. 조회되는 동안 클러스터는 Synchronizing 상태로 변경됩니다.
- 조회가 완료되면 서버 정보 항목에 상태가 업데이트되며, 클러스터는 Running 상태로 변경됩니다.
서버 타입 변경하기
구성된 서버 타입을 변경할 수 있습니다.
주의
- 서버 타입을 Standard로 구성한 경우에는 High Capacity로 변경할 수 없습니다. High Capacity로 변경하고자 할 경우, 서비스를 신규로 생성하세요.
- 서버 타입을 수정하면 서버 재가동이 필요합니다. 서버 사양 변경에 따른 SW 라이선스 수정 사항 또는 SW 설정 및 반영은 별도 확인하세요.
서버 타입을 변경하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 상세 정보 하단의 변경하고자 하는 서버 타입의 수정 아이콘을 클릭하세요. 서버 타입 수정 팝업창이 열립니다.
- 서버 타입 수정 팝업창에서 서버 타입을 선택한 후, 확인 버튼을 클릭하세요.
스토리지 추가하기
데이터 저장 공간이 5 TB 이상 필요한 경우, 스토리지를 추가할 수 있습니다. 고가용성 구성(HA 클러스터)인 경우, 스토리지 용량을 증설하거나 추가하면 모든 DB에 동시 적용됩니다.
스토리지를 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 스토리지 추가할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 상세 정보 하단의 Disk 추가 버튼을 클릭하세요. 추가 스토리지 요청 팝업창이 열립니다.
- 추가 스토리지 요청 팝업창에서 용도, 용량 입력한 후, 확인 버튼을 클릭하세요.
스토리지 증설하기
데이터 영역으로 추가된 스토리지를 최초 할당한 용량 기반 최대 5TB까지 증설할 수 있습니다. Vertica(DBaaS)를 중단하지 않고 스토리지를 증설할 수 있으며, 클러스터로 구성된 경우 모든 노드가 동시에 증설됩니다.
스토리지 용량을 증설하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 서버 타입을 변경할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 상세 정보 하단의 증설하고자 하는 추가 Disk의 수정 버튼을 클릭하세요. 추가 스토리지 수정 팝업창이 열립니다.
- 추가 스토리지 수정 팝업창에서 증설 용량 입력한 후, 확인 버튼을 클릭하세요.
Recovery DB 인스턴스 유형 변경하기
DB 복구 완료 후, Recovery 상세정보 화면에서 인스턴스 유형을 변경할 수 있습니다.
Recovery DB 인스턴스 유형을 변경하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 Recovery DB 인스턴스 유형을 변경할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 인스턴스 유형 변경 버튼을 클릭하세요. 인스턴스 유형 변경 확인창이 표시됩니다.
- 단일 DB와 동일한 기능을 수행하도록 DB 인스턴스 유형이 Recovery에서 Active로 변경됩니다.
Vertica(DBaaS) 해지하기
사용하지 않는 Vertica(DBaaS)을 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Vertica(DBaaS)를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Vertica(DBaaS) 목록 페이지에서 자원이 해지되었는지 확인하세요.
3.2.1 - Vertica 백업 및 복구하기
사용자는 Samsung Cloud Platform Console을 통해 Vertica (DBaaS)의 백업을 설정하고, 백업된 파일로 복구를 할 수 있습니다.
Vertica(DBaaS) 백업하기
사용자의 데이터가 안전하게 보관될 수 있도록 백업 기능을 설정할 수 있습니다. 또한, 백업 이력 기능을 통해 정상적으로 백업이 되었는지 확인할 수 있으며 백업된 파일 삭제도 수행할 수 있습니다.
백업 설정하기
Vertica(DBaaS)의 백업 설정 방법은 Vertica(DBaaS) 생성하기를 참고하세요.
Vertica(DBaaS)의 백업 설정을 수정하려면 다음 절차를 따르세요.
주의
- 백업을 설정한 경우에는 설정한 시간 이후 지정된 시간에 백업이 수행되며, 백업 용량에 따라 추가 요금이 발생합니다.
- 백업 설정을 미사용으로 변경할 경우에는 백업 수행이 즉시 중지되며, 저장된 백업 데이터는 삭제되어 더 이상 사용이 불가합니다.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 백업을 설정할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 백업 항목의 수정 버튼을 클릭하세요. 백업 설정 팝업창이 열립니다.
- 백업 설정을 할 경우에는 백업 설정 팝업창에서 사용을 클릭하고, 보관 기간, 백업 시작 시간을 선택하여 확인 버튼을 클릭하세요.
- 백업 설정을 중지할 경우에는 백업 설정 팝업창에서 사용을 해제하고, 확인 버튼을 클릭하세요.
백업 이력 확인하기
안내
백업 성공 및 실패에 대한 알림을 설정하려면 Notification Manager 상품을 통해 설정할 수 있습니다. 알림 정책 설정에 대한 자세한 사용 가이드는 알림 정책 생성하기를 참고하세요.
백업 이력을 조회하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 백업 이력을 확인할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 백업 이력 버튼을 클릭하세요. 백업 이력 팝업창이 열립니다.
- 백업 이력 팝업창에서 백업 상태, 버전, 백업 시작 일시, 백업 완료 일시, 용량을 확인할 수 있습니다.
백업 파일 삭제하기
백업 이력을 삭제하려면 다음 절차를 따르세요.
주의
백업 파일은 삭제 후 복원이 불가능합니다. 불필요한 데이터인지 반드시 확인한 후에 삭제하시기 바랍니다.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 목록 페이지에서 백업 이력을 확인할 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- 백업 이력 버튼을 클릭하세요. 백업 이력 팝업창이 열립니다.
- 백업 이력 팝업창에서 삭제하고자 하는 파일을 체크한 후, 삭제 버튼을 클릭하세요.
Vertica(DBaaS) 복구하기
장애 혹은 데이터 손실로 인하여 백업 파일로 복원이 필요한 경우 클러스터 복구 기능을 사용해 특정 시점 기반으로 복구할 수 있습니다.
주의
복구 수행을 위해서는 데이터 유형 Disk 용량과 적어도 동일한 용량이 필요합니다. Disk 용량이 부족할 경우 복구가 실패할 수 있습니다.
Vertica(DBaaS)를 복구하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS)의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Vertica(DBaaS) 메뉴를 클릭하세요. Vertica(DBaaS) 목록 페이지로 이동합니다.
- Vertica(DBaaS) 자원 목록 페이지에서 복구하고자 하는 자원을 클릭하세요. Vertica(DBaaS) 상세 페이지로 이동합니다.
- Database 복구 버튼을 클릭하세요. Database(DBaaS) 복구 페이지로 이동합니다.
- Database 복구 영역에 해당 정보를 입력한 후, 완료 버튼을 클릭하세요.
구분 필수 여부상세 설명 복구 유형 필수 사용자가 복구하고자 하는 시점 설정 - 백업 시점(권장): 백업 파일 기준으로 복구. 목록에 표시되는 백업 파일의 시점 목록에서 선택
- 복구 시점: 백업하고자 하는 날짜와 시각을 선택. 백업 이력의 시작 시간에서 선택 가능
서버명 Prefix 필수 복구 DB 서버 이름 - 영문 소문자로 시작하여 소문자, 숫자와 특수문자(
-)를 사용하여 3~16자로 입력
- 서버명 기반으로 001, 002와 같은 postfix 가 붙어 실제 서버명이 생성됨
클러스터명 필수 복구 DB 클러스터 이름 - 영문을 사용하여 3 ~ 20자로 입력
- 클러스터는 여러 개의 서버를 묶는 단위
노드 수 선택 데이터 노드 수 - 원본 클러스터에 설정된 노드 수와 동일하게 설정
서비스 유형 > 서버 타입 필수 복구 DB 서버 타입 - Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
서비스 유형 > Planned Compute 선택 Planned Compute가 설정된 자원 현황 - 사용중: Planned Compute가 설정된 자원 중 사용 중인 개수
- 설정: Planned Compute가 설정된 자원의 개수
- Coverage 미리보기: 자원별 Planned Compute로 적용된 금액
- Planned Compute 서비스 신청: Planned Compute 서비스 신청 페이지로 이동
- 자세한 내용은 Planned Compute 신청하기 를 참고
서비스 유형 > Block Storage 필수 복구 DB가 사용하는 Block Storage 설정 - 기본 OS: DB 엔진이 설치되는 영역
- DATA: 테이블 데이터 및 아카이브 파일 등 저장 영역
- 원본 클러스터에서 설정한 Storage 유형으로 동일하게 적용
- 사용을 선택한 후 스토리지의 용도, 용량을 입력
- 스토리지를 추가하려면 + 버튼을 클릭하고, 삭제하려면 x 버튼을 클릭
- 용량은 16 ~ 5,120 범위에서 8의 배수로 입력 가능하며, 최대 9개까지 생성 가능
Management Console > 서버 타입 필수 Management Console 서버 타입 - 사용을 선택한 후 스토리지의 용도, 용량을 선택
- Standard: 일반적으로 사용되는 표준 사양
- High Capacity: 24vCore 이상의 대용량 서버
Management Console > Block Storage 필수 Management Console이 사용하는 Block Storage 설정 - 사용을 선택한 후 기본 OS를 선택
Database 사용자명 필수 Database 사용자명 - 원본 클러스터에서 설정한 사용자명으로 동일하게 적용
Database 비밀번호 필수 Database 비밀번호 - 원본 클러스터에서 설정한 비밀번호 동일하게 적용
Database Port 번호 필수 Database Port 번호 - 원본 클러스터에서 설정한 Port 번호로 동일하게 적용
IP 접근 제어 선택 서비스 접근 정책 설정 - 페이지에 입력된 IP에 대해 접근 정책을 설정하므로 별도로 Security Group 정책 설정은 수행하지 않아도 됨
- IP 형식(예시:
192.168.10.1) 또는 CIDR 형식(예시:192.168.10.0/24,192.168.10.1/32)으로 입력하고, 추가 버튼을 클릭
- 입력한 IP를 삭제하려면, 입력한 IP 옆의 x 버튼을 클릭
유지 관리 기간 선택 DB 유지 관리 기간 - 사용을 선택하면 요일, 시작 시간, 기간을 설정
- DB의 안정적인 관리를 위해 유지 관리 기간을 설정할 것을 권고함. 설정한 시간에 패치 작업이 진행되며 서비스 중단이 발생
- 미사용으로 설정 시, 패치 미적용으로 발생되는 문제점은 삼성 SDS에서 책임지지 않습니다.
License Key 필수 복구할 Vertica License Key 입력 - 입력한 라이선스 key가 유효하지 않을 경우 서비스 생성 불가
태그 선택 태그 추가 - 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. Vertica(DBaaS) 복구 구성 항목
3.3 - API Reference
API Reference
3.4 - CLI Reference
CLI Reference
3.5 - Release Note
Vertica(DBaaS)
2025.07.01
NEW
Vertica(DBaaS) 서비스 정식 버전 출시- Columnar 저장소 기반의 압축과 인코딩 기능으로 데이터를 효율적으로 저장하고 쿼리 수행 속도를 향상시킬 수 있는 Vertica(DBaaS) 서비스를 출시하였습니다.
4 - Data Flow
4.1 - Overview
서비스 개요
Data Flow는 다양한 데이터 소스로부터 대용량의 데이터를 추출하고, 스트림/배치 데이터의 변환/전송에 대한 처리 흐름을 시각적으로 작성하는 데이터 처리 흐름 도구로, 오픈소스 Apache NiFi를 제공합니다. Data Flow는 Samsung Cloud Platform의 Kubernetes Engine 클러스터 환경에서 단독으로 사용하거나, 다른 애플리케이션 SW와 함께 사용할 수 있습니다.
제공 기능
Data Flow는 다음과 같은 기능을 제공하고 있습니다.
- 편리한 설치 및 관리: Data Flow는 표준 Kubernetes 클러스터 환경에서 웹 기반 Samsung Cloud Platform Console을 통해 손쉽게 설치가 가능합니다. 오픈소스 Apache NiFi 기반의 확장형 클러스터링에 필요한 아키텍처를 자동으로 구성하여, ZooKeeper, Registry 및 관리 모듈이 자동 설치됩니다. Data Flow를 통해 서비스 연결에 필요한 설정 파일, NiFi 템플릿 등을 설정/배포할 수 있습니다.
- 손쉬운 데이터 흐름 관리: 스트림/배치 데이터의 처리 흐름을 사용자 환경에 맞게 GUI 기반으로 쉽게 작성할 수 있으며, GUI 기반의 데이터 처리 흐름 작성으로 시스템 간 데이터를 효율적으로 추출/전송/처리할 수 있습니다.
- NiFi 템플릿 갤러리: 레퍼런스 NiFi 템플릿을 공유/배포할 수 있습니다. Data Flow는 현업에서 자주 사용하는 데이터 처리 흐름에 대한 작업 파일을 갤러리로 제공하며, 사용자는 자신이 작성한 데이터 처리 흐름 작업을 공유할 수 있습니다.
구성 요소
Data Flow는 Manager와 Service 모듈로 구성되며, Apache NiFi를 패키징하여 제공합니다.
Data Flow Manager
Data Flow Manager는 NiFi를 더 효율적으로 활용할 수 있도록 다양한 Managing 기능을 제공합니다.
- Data Flow Manager를 통해 고객이 생성한 Nar File을 업로드하여 Processor에서 사용하고, 설정 파일들을 업로드하여 공유할 수 있습니다.
- NiFi Template 중에 사용 빈도가 높은 Template을 자산화하여 Gallery로 제공하며, 클릭 한 번으로 바로 사용 가능합니다.
- Native NiFi Service를 위해 구성된 여러 Service에 대한 실시간 모니터링 및 자원 현황 모니터링을 제공합니다.
- 클러스터 내의 NiFi 구성 컴포넌트에 대한 설정 정보를 손쉽게 프로비저닝할 수 있습니다.
Data Flow Service
- Apache NiFi 기반의 데이터 플로우 관리 서비스를 제공합니다.
- Apache NiFi 기반의 확장형 클러스터링에 필요한 아키텍처를 자동으로 구성하며, Nifi, ZooKeeper, Nifi Registry 모듈이 자동 설치됩니다.
- Nifi 제공시 Description, 필요한 자원 규모, 접속 ID/PW, Host Alias를 설정할 수 있습니다.
- 서비스 생성 이후 Description, 필요한 자원규모, 접속 password, Host Alias 등을 수정하여 서비스에 반영할 수 있습니다.
서버 스펙 유형
Data Flow 서비스 생성시 다음 내용을 확인하세요.
- 서비스 설치 권장 사양: CPU 21 core, Memory 57 GB, 스토리지 100 GB 이상
참고
- Data Flow 서비스를 생성하기 전에 Ingress Controller 설치가 필요합니다.
- Kubernetes 클러스터에는 1개의 Ingress Controller만 설치할 수 있습니다.
- 자세한 내용은 Ingress Controller 설치하기를 참고하세요.
리전별 제공 현황
Data Flow는 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. Data Flow 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해 주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Storage | File Storage | 네트워크 연결을 통하여 다수의 클라이언트 서버가 파일을 공유하는 스토리지 |
| Container | Kubernetes Engine | Kubernetes 컨테이너 오케스트레이션 서비스 |
표. Data Flow 선행 서비스
4.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Data Flow의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Data Flow 생성하기
Samsung Cloud Platform Console에서 Data Flow 서비스를 생성하여 사용할 수 있습니다.
Data Flow를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Data Flow 생성 버튼을 클릭하세요. Data Flow 생성 페이지로 이동합니다.
Data Flow 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 Data Flow 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
표. Data Flow 버전 선택 항목 - 클러스터 선택 영역에서 필요한 정보를 입력 또는 선택하세요. Data Flow 설치를 위해서는 Kubernetes 클러스터 및 작업 환경을 위한 노드 생성이 먼저 필요합니다.
구분 필수 여부상세 설명 클러스터명 필수 사용할 클러스터 선택 Ingress Controller 필수 클러스터에 설치된 Ingress Controller 선택 - 설치된 Ingress Controller의 상세 정보 탭에서 ConfigMap 항목에 다음의 정보를 추가하세요.
- Key: allow-snippet-annotations
- Value: true
표. Data Flow 클러스터 선택 항목 - 설치된 Ingress Controller의 상세 정보 탭에서 ConfigMap 항목에 다음의 정보를 추가하세요.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Data Flow명 필수 Data Flow 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 영문 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
스토리지 클래스 필수 선택한 클러스터가 사용하는 스토리지 클래스 선택 설명 선택 Data Flow에 대한 추가 정보나 설명을 150자 이내로 입력 도메인 설정 필수 Data Flow 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 50자로 입력
- {Data Flow명}.{설정한 도메인}이 Data Flow 접속 주소가 됩니다.
Node Selector 필수 특정 노드에 설치하려면 해당 노드의 Label 중 구별할 수 있는 Label을 입력 - 노드 Label을 잘못 입력하면 설치 에러가 발생할 수 있으니 노드 Label을 미리 확인
- 노드 Label은 해당 노드의 yaml 파일에서 확인
계정 필수 Data Flow Manager 계정 입력 - 아이디: 영문 소문자로 시작하며 소문자와 숫자를 사용하여 6 ~ 30 사이의 값 입력
- 비밀번호: 대문자(영문), 소문자(영문), 숫자와 특수문자(
!@#$%^&*)를 포함하여 8~50자로 입력
- 비밀번호 확인: 비밀번호를 동일하게 한 번 더 입력
Host Alias 선택 Data Flow와 연결될 호스트 정보 추가 (기본 포함 총 20개 생성 가능) - 사용을 선택한 후, + 버튼 클릭
- Hostname: 호스트명 또는 도메일 형식으로, 소문자, 숫자와 특수문자(
-)를 사용하여3~63자로 입력
- IP: IP 형식으로 입력
- 삭제하려면 X 버튼 클릭
- 클러스터와 해당 서버와의 방화벽이 오픈되어 있어야 추가한 호스트 정보 사용 가능
표. Data Flow 서비스 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Data Flow 추가 정보 입력 항목
- 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Data Flow 목록 페이지에서 생성한 자원을 확인하세요.
Data Flow 상세 정보 확인하기
Data Flow의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Data Flow 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Data Flow의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Flow 메뉴를 클릭하세요. Data Flow 목록 페이지로 이동합니다.
- Data Flow 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Data Flow 상세 페이지로 이동합니다.
- Data Flow 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 상태 표시 Data Flow 상태 - Creating: 생성 중
- Running: 작동 중, Data Flow Services 생성 가능 상태
- Updating: 설정 업데이트 중
- Terminating: 서비스 해지 중
- Error: 생성 중 오류 발생 또는 서비스 이상 상태
Hosts 파일 셋팅 정보 Data Flow에 접속하기 위한 호스트 파일 정보를 확인하고 복사하는 버튼 서비스 해지 서비스를 해지하는 버튼 표. Data Flow 상태 정보 및 부가 기능
- Data Flow 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Data Flow 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| 스토리지 클래스 | 선택한 클러스터가 사용하는 스토리지 클래스 |
| 설명 | Data Flow에 대한 추가 정보나 설명 |
| 도메인 설정 | Data Flow 도메인 이름 |
| Node Selector | 노드 Lable |
| Web Url | Data Flow URL |
| 계정 | Data Flow Manager 계정 |
| Host Alias | Data Flow와 연결될 호스트 정보 |
표. Data Flow 상세 정보 탭 항목
태그
Data Flow 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Data Flow 태그 탭 항목
작업 이력
Data Flow 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Data Flow 작업 이력 탭 상세 정보 항목
Data Flow 해지하기
사용하지 않는 Data Flow를 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Data Flow를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Flow 메뉴를 클릭하세요. Data Flow 목록 페이지로 이동합니다.
- Data Flow 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Data Flow 목록 페이지에서 자원이 해지되었는지 확인하세요.
안내
- Data Flow 해지는 연결된 Data Flow Services를 먼저 삭제해야 해지할 수 있습니다.
- Data Flow를 해지할 경우, 생성된 네임스페이스도 같이 삭제됩니다.
4.2.1 - Data Flow Services
사용자는 Samsung Cloud Platform Console을 통해 Data Flow 서비스 내 Data Flow Services의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Data Flow Services 생성하기
사용자는 Data Flow의 서비스 상세 옵션을 선택하거나 설정값을 입력하여 서비스를 추가할 수 있습니다.
안내
Data Flow Services 신청 시 자원의 규모는 K8s 클러스터의 가용 용량 이상으로 확보되어야 합니다.
Data Flow Services를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow Service Home 페이지로 이동합니다.
Service Home 페이지에서 Data Flow Servies를 클릭하세요. Data Flow Services 목록 페이지로 이동합니다.
Data Flow Services 목록 페이지에서 Data Flow Services 생성 버튼을 클릭하세요. Data Flow Services 생성 페이지로 이동합니다.
Data Flow Services 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Data Flow명 필수 Data Flow 선택 Flow Service명 필수 Data Flow Services 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
스토리지 클래스 필수 선택한 클러스터가 사용하는 스토리지 클래스 선택 설명 선택 Data Flow Services에 대한 추가 정보나 설명을 150자 이내로 입력 도메인 설정 필수 Data Flow Services 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 50자로 입력
- {Data Flow Services명}.{설정한 도메인}이 Data Flow Services 접속 주소가 됩니다.
Node Selector 필수 특정 노드에 설치하려면 해당 노드의 Label 중 구별할 수 있는 Label을 입력 - 노드 Label을 잘못 입력하면 설치 에러가 발생할 수 있으니 노드 Label을 미리 확인
- 노드 Label은 해당 노드의 yaml 파일에서 확인
Service Workload 필수 - Nifi: Apache Nifi의 서비스와 UI를 제공하는 모듈
- Nifi Registry: Nifi의 템플릿을 설정하고 배포하는 모듈
- Zookeeper: 다수의 노드에서 Nifi 분산 처리가 잘 수행되도록 지원하는 모듈
계정 필수 Nifi 계정 입력 - 아이디: 영문 소문자로 시작하며 소문자와 숫자를 사용하여 6 ~ 30 사이의 값 입력
- 비밀번호: 대문자(영문), 소문자(영문), 숫자와 특수문자(
!@#$%^&*)를 포함하여 8 ~ 50자로 입력
- 비밀번호 확인: 비밀번호를 동일하게 한 번 더 입력
표. Data Flow Services 서비스 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Host Alias 선택 Data Flow와 연결될 호스트 정보 추가 (기본 포함 총 20개 생성 가능) - 사용을 선택한 후, + 버튼 클릭
- Hostname: 호스트명 또는 도메일 형식으로, 소문자, 숫자와 특수문자(
-)를 사용하여 3 ~ 63자로 입력
- IP: IP 형식으로 입력
- 삭제하려면 X 버튼 클릭
- 클러스터와 해당 서버와의 방화벽이 오픈되어 있어야 추가한 호스트 정보 사용 가능
태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Data Flow 추가 정보 입력 항목
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Data Flow Services 목록 페이지에서 생성한 자원을 확인하세요.
Data Flow Services 상세 정보 확인하기
Data Flow Services의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Data Flow Services 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Data Flow Services의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Flow Services 메뉴를 클릭하세요. Data Flow Services 목록 페이지로 이동합니다.
- Data Flow Services 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Data Flow Services 상세 페이지로 이동합니다.
- Data Flow Services 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 상태 표시 Data Flow Services 상태 - Creating: 생성 중
- Running: 작동 중
- Updating: 설정 업데이트 중
- Terminating: 서비스 해지 중
- Error: 생성 실패 또는 서비스 사용 불가
Hosts 파일 셋팅 정보 Data Flow Services에 접속하기 위한 호스트 파일 정보를 확인하고 복사하는 버튼 Data Flow Services 삭제 서비스를 해지하는 버튼 표. Data Flow Services 상태 정보 및 부가 기능
- Data Flow Services 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Data Flow Services 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Data Flow명 | Data Flow 이름 |
| 스토리지 클래스 | 선택한 클러스터가 사용하는 스토리지 클래스 |
| 설명 | Data Flow Services에 대한 추가 정보나 설명 |
| 도메인 설정 | Data Flow Services 도메인 이름 |
| Node Selector | 노드 Lable |
| Web Url | Data Flow Services URL |
| 계정 | Airflow 계정 |
| Host Alias | Data Flow Services와 연결될 호스트 정보 |
표. Data Flow Services 상세 정보 탭 항목
태그
Data Flow Services 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Data Flow Services 태그 탭 항목
작업 이력
Data Flow Services 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Data Flow Services 작업 이력 탭 상세 정보 항목
Data Flow Services 해지하기
사용하지 않는 Data Flow Services를 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Data Flow 또는 Data Flow Services를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Flow 메뉴를 클릭하세요. Data Flow의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Flow Services 메뉴를 클릭하세요. Data Flow Services 목록 페이지로 이동합니다.
- Data Flow Services 목록 페이지에서 해지할 자원을 선택하고, Data Flow Services 삭제 버튼을 클릭하세요.
- 해지가 완료되면, Data Flow Services 목록 페이지에서 자원이 해지되었는지 확인하세요.
안내
- Data Flow Services를 해지할 경우, 생성된 네임스페이스도 같이 삭제됩니다.
4.2.2 - Ingress Controller 설치하기
사용자는 Data Flow 서비스를 생성하기 전에 Ingress Controller를 설치해야 합니다. Kubernetes 클러스터에는 1개의 Ingress Controller만 설치해야 합니다.
Container Registry를 이용하여 Ingress Controller 설치하기
Container Registry를 이용하여 Ingress Controller를 설치하려면 다음 절차를 따르세요.
자세한 Container Registry 생성 방법은 Container > Container Registry > How-to guides 가이드를 참고하세요.
Ingress Controller 이미지를 저장할 SCR(Samsung Container Registry)을 준비하세요.
SCR(Samsung Container Registry)에 Ingress Controller 이미지를 Push하세요.
설치에 사용한 YAML 파일을 Ingress GitHub에서 다운로드한 후, 아래 항목을 수정하세요.
배경색 변경kind: Deployment ... spec: template: spec: containers: image: {SCR private endpoint}.{repository name}.{image name}:{tag}kind: Deployment ... spec: template: spec: containers: image: {SCR private endpoint}.{repository name}.{image name}:{tag}코드 블럭. SCR 정보 변경 배경색 변경kind: ConfigMap ... metadata: labels: app: ingress-controller kind: Service ... metadata: labels: app: ingress-controller kind: Deployment ... metadata: labels: app: ingress-controller kind: IngressClass ... metadata: labels: app: ingress-controllerkind: ConfigMap ... metadata: labels: app: ingress-controller kind: Service ... metadata: labels: app: ingress-controller kind: Deployment ... metadata: labels: app: ingress-controller kind: IngressClass ... metadata: labels: app: ingress-controller코드 블럭. Label 정보 추가 - metadata: labels: app: ingress-controller 수정한 YAML 파일을 사용하여 Kubernetes Engine에서 워크로드 > 디플로이먼트 목록에서 오브젝트 생성 버튼을 이용하여 Ingress Controller를 설치할 수 있습니다.
참고자세한 오브젝트 생성 방법은 Container > Kubernetes Engine > 디플로이먼트 생성하기 를 참고하세요.
4.3 - API Reference
API Reference
4.4 - CLI Reference
CLI Reference
4.5 - Release Note
Data Flow
2025.04.28
NEW
Data Flow 서비스 정식 버전 출시- 다양한 소스로부터 데이터를 추출/변환/전송하고 데이터 처리 흐름을 자동화하는 Data Flow 서비스가 출시되었습니다.
- 오픈소스 Apache NiFi를 제공합니다.
5 - Data Ops
5.1 - Overview
서비스 개요
Data Ops는 주기적 또는 반복적으로 발생하는 데이터 처리 작업에 대해 워크플로우를 작성하고, 작업 스케줄링을 자동화하는 Apache Airflow 기반의 관리형 워크플로우 오케스트레이션 서비스입니다. 사용자는 유용한 데이터를 필요한 시간에 올바른 장소로 가져오는 프로세스를 자동화하고, 데이터 파이프라인의 구성 및 진행 상황을 모니터링할 수 있습니다.
제공 기능
Data Ops는 다음과 같은 기능을 제공하고 있습니다.
- 편리한 설치 및 관리: Data Ops는 표준 Kubernetes 클러스터 환경에서 웹 기반 Console을 통해 손쉽게 설치가 가능합니다. Apache Airflow와 관리 모듈이 자동 설치되며, 통합 대시보드를 통해 웹 서버 및 스케줄러의 실행 상태에 대한 통합 모니터링이 가능합니다.
- 동적 파이프라인 구성: Python 코드를 기반으로 데이터 작업에 대한 파이프라인 구성이 가능합니다. 데이터 작업 예약과 연동하여 동적으로 작업을 생성하기 때문에 원하는 워크플로우 형태와 스케줄링을 자유롭게 구성할 수 있습니다.
- 편리한 워크플로우 관리: DAG (Direct Acyclic Graph: 방향성 비순환 그래프) 구성을 웹 기반의 UI를 통해 시각화하여 관리하기 때문에 데이터 흐름의 전후 및 병렬 관계를 쉽게 이해할 수 있습니다. 또한 각 작업의 타임아웃, 재시도 횟수, 우선순위 정의 등을 손쉽게 관리할 수 있습니다.
구성 요소
Data Ops는 Manager와 Service 모듈로 구성되며, Apache Airflow를 패키징하여 제공합니다.
Data Ops Manager
Data Ops Manager는 Airflow를 더 효율적으로 활용할 수 있도록 다양한 Managing 기능을 제공합니다.
- Ops Manager를 통해 Ops Service에서 사용할 Plugin File, Shared File, Python Library File을 업로드할 수 있습니다.
- 클러스터 내의 Airflow 구성 컴포넌트에 대한 설정 정보를 손쉽게 프로비저닝할 수 있습니다.
- Airflow 클러스터 내에 다른 서비스 설정 정보를 관리하고 쉽게 프로비저닝할 수 있습니다.
Data Ops Service
- Apache Airflow 기반의 관리형 워크플로우 오케스트레이션 서비스를 제공합니다.
- Airflow 제공시 Description, 필요한 자원규모, DAGs GitSync, Host Alias를 설정할 수 있습니다.
- 서비스 생성 이후에는 Description, 사용하는 자원규모, DAGs GitSync, Host Alias를 수정하여 서비스 반영할 수 있습니다.
서버 스펙 유형
Data Ops 서비스 생성 시 다음 내용을 확인하세요.
- 서비스 설치 권장 사양: CPU KubernetesExecutor 43 core, CPU CeleryExecutor 25 core, Memory 50 GB, 스토리지 100 GB 이상
참고
- Data Ops 서비스를 생성하기 전에 Ingress Controller 설치가 필요합니다.
- Kubernetes 클러스터에는 1개의 Ingress Controller만 설치할 수 있습니다.
- 자세한 내용은 Ingress Controller 설치하기를 참고하세요.
리전별 제공 현황
Data Ops는 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. Data Ops 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비해 주세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Storage | File Storage | 네트워크 연결을 통하여 다수의 클라이언트 서버가 파일을 공유하는 스토리지 |
| Container | Kubernetes Engine | Kubernetes 컨테이너 오케스트레이션 서비스 |
표. Data Ops 선행 서비스
5.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Data Ops의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Data Ops 생성하기
Samsung Cloud Platform Console에서 Data Ops 서비스를 생성하여 사용할 수 있습니다.
Data Ops를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Data Ops 생성 버튼을 클릭하세요. Data Ops 생성 페이지로 이동합니다.
Data Ops 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 Data Ops 버전 필수 선택한 이미지의 버전 선택 - 제공하는 서버 이미지의 버전 리스트 제공
표. Data Ops 버전 선택 항목 - 클러스터 선택 영역에서 필요한 정보를 입력 또는 선택하세요. Data Ops 설치를 위해서는 Kubernetes 클러스터 및 작업 환경을 위한 노드 생성이 먼저 필요합니다.
구분 필수 여부상세 설명 클러스터명 필수 사용할 클러스터 선택 Ingress Controller 필수 클러스터에 설치된 Ingress Controller 선택 표. Data Ops 클러스터 선택 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Data Ops명 필수 Data Ops 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
스토리지 클래스 필수 선택한 클러스터가 사용하는 스토리지 클래스 선택 설명 선택 Data Ops에 대한 추가 정보나 설명을 150자 이내로 입력 도메인 설정 필수 Data Ops 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 50자로 입력
- {Data Ops명}.{설정한 도메인}이 Data Ops 접속 주소가 됩니다.
Node Selector 필수 특정 노드에 설치하려면 해당 노드의 Label 중 구별할 수 있는 Label을 입력 - 노드 Label을 잘못 입력하면 설치 에러가 발생할 수 있으니 노드 Label을 미리 확인
- 노드 Label은 해당 노드의 yaml 파일에서 확인
계정 필수 Data Ops Manager 계정 입력 - 아이디: 영문 소문자로 시작하며 소문자와 숫자를 사용하여 6 ~ 30 사이의 값 입력
- 비밀번호: 대문자(영문), 소문자(영문), 숫자와 특수문자(
!@#$%^&*)를 포함하여 8~50자로 입력
- 비밀번호 확인: 비밀번호를 동일하게 한 번 더 입력
Host Alias 선택 Data Ops와 연결될 호스트 정보 추가 (기본 포함 총 20개 생성 가능) - 사용을 선택한 후, + 버튼 클릭
- Hostname: 호스트명 또는 도메일 형식으로, 소문자, 숫자와 특수문자(
-)를 사용하여3~63자로 입력
- IP: IP 형식으로 입력
- 삭제하려면 X 버튼 클릭
- 클러스터와 해당 서버와의 방화벽이 오픈되어 있어야 추가한 호스트 정보 사용 가능
표. Data Ops 서비스 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Data Ops 추가 정보 입력 항목
- 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Data Ops 목록 페이지에서 생성한 자원을 확인하세요.
Data Ops 상세 정보 확인하기
Data Ops의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Data Ops 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Data Ops의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Ops 메뉴를 클릭하세요. Data Ops 목록 페이지로 이동합니다.
- Data Ops 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Data Ops 상세 페이지로 이동합니다.
- Data Ops 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 상태 표시 Data Ops 상태 - Creating: 생성 중
- Running: 작동 중, Data Ops Services 생성 가능 상태
- Updating: 설정 업데이트 중
- Terminating: 서비스 해지 중
- Error: 생성 중 오류 발생 또는 서비스 이상 상태
Hosts 파일 셋팅 정보 Data Ops에 접속하기 위한 호스트 파일 정보를 확인하고 복사하는 버튼 서비스 해지 서비스를 해지하는 버튼 표. Data Ops 상태 정보 및 부가 기능
- Data Ops 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Data Ops 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| 스토리지 클래스 | 선택한 클러스터가 사용하는 스토리지 클래스 |
| 설명 | Data Ops에 대한 추가 정보나 설명 |
| 도메인 설정 | Data Ops 도메인 이름 |
| Node Selector | 노드 Lable |
| Web Url | Data Ops URL |
| 계정 | Data Ops Manager 계정 |
| Host Alias | Data Ops와 연결될 호스트 정보 |
표. Data Ops 상세 정보 탭 항목
태그
Data Ops 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Data Ops 태그 탭 항목
작업 이력
Data Ops 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Data Ops 작업 이력 탭 상세 정보 항목
Data Ops 해지하기
사용하지 않는 Data Ops를 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Data Ops를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Ops 메뉴를 클릭하세요. Data Ops 목록 페이지로 이동합니다.
- Data Ops 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Data Ops 목록 페이지에서 자원이 해지되었는지 확인하세요.
안내
Data Ops 해지는 연결된 Data Ops Services를 먼저 삭제해야 해지할 수 있습니다.
5.2.1 - Data Ops Services
사용자는 Samsung Cloud Platform Console을 통해 Data Ops 서비스 내 Data Ops Services의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Data Ops Services 생성하기
사용자는 Data Ops의 서비스 상세 옵션을 선택하거나 설정값을 입력하여 서비스를 추가할 수 있습니다.
안내
Data Ops Services 신청 시 자원의 규모는 K8s 클러스터의 가용 용량 이상으로 확보되어야 합니다.
Data Ops Services를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Data Ops Servies를 클릭하세요. Data Ops Services 목록 페이지로 이동합니다.
Data Ops Services 목록 페이지에서 Data Ops Services 생성 버튼을 클릭하세요. Data Ops Services 생성 페이지로 이동합니다.
Data Ops Services 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Data Ops명 필수 Data Ops 선택 Ops Service명 필수 Data Ops Services 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
스토리지 클래스 필수 선택한 클러스터가 사용하는 스토리지 클래스 선택 설명 선택 Data Ops Services에 대한 추가 정보나 설명을 150자 이내로 입력 도메인 설정 필수 Data Ops Services 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 50자로 입력
- {Data Ops Services명}.{설정한 도메인}이 Data Ops Services 접속 주소가 됩니다.
Node Selector 필수 특정 노드에 설치하려면 해당 노드의 Label 중 구별할 수 있는 Label을 입력 - 노드 Label을 잘못 입력하면 설치 에러가 발생할 수 있으니 노드 Label을 미리 확인
- 노드 Label은 해당 노드의 yaml 파일에서 확인
Service Workload 필수 - Web Server: DAG의 구성 요소와 상태를 시각화하여 제공하며 Airflow 구성 관리 모듈
- Scheculer: 다양한 DAG와 해당 작업을 오케스트레이션 하기 위한 DAG 예약/실행 관리 모듈
- Worker: 실제 오케스트레이션 및 데이터 처리 작업을 수행하는 모듈
- Worker(Kubernetes): Worker 작동 조건시 다이내믹하게 pod가 생성되어 동작하므로 자원을 효율적으로 사용할 수 있음. Kubernetes 선택시 Replica의 text box는 비활성화됨.
- Worker(Celery): Worker 작동 조건시 Static pod를 생성하여 유지하며 많은 양의 요청에 대해 좀 더 빠르게 수행할 수 있음. Celery 선택시 Replica의 text box는 활성화되고 사용자 입력이 가능.
- 한 번 선택된 executor의 타입은 변경 불가
계정 필수 Airflow 계정 입력 - 아이디: 영문 소문자로 시작하며 소문자와 숫자를 사용하여 6 ~ 30 사이의 값 입력
- 비밀번호: 대문자(영문), 소문자(영문), 숫자와 특수문자(
!@#$%^&*)를 포함하여 8 ~ 50자로 입력
- 비밀번호 확인: 비밀번호를 동일하게 한 번 더 입력
표. Data Ops Services 서비스 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Host Alias 선택 Data Ops와 연결될 호스트 정보 추가 (기본 포함 총 20개 생성 가능) - 사용을 선택한 후, + 버튼 클릭
- Hostname: 호스트명 또는 도메일 형식으로, 소문자, 숫자와 특수문자(
-)를 사용하여 3 ~ 63자로 입력
- IP: IP 형식으로 입력
- 삭제하려면 X 버튼 클릭
- 클러스터와 해당 서버와의 방화벽이 오픈되어 있어야 추가한 호스트 정보 사용 가능
태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Data Ops 추가 정보 입력 항목
- 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Data Ops Services 목록 페이지에서 생성한 자원을 확인하세요.
Data Ops Services 상세 정보 확인하기
Data Ops Services의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Data Ops Services 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
Data Ops Services의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Ops Services 메뉴를 클릭하세요. Data Ops Services 목록 페이지로 이동합니다.
- Data Ops Services 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Data Ops Services 상세 페이지로 이동합니다.
- Data Ops Services 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 상태 표시 Data Ops Services 상태 - Creating: 생성 중
- Running: 작동 중
- Updating: 설정 업데이트 중
- Terminating: 서비스 해지 중
- Error: 생성 실패 또는 서비스 사용 불가
Hosts 파일 셋팅 정보 Data Ops Services에 접속하기 위한 호스트 파일 정보를 확인하고 복사하는 버튼 Data Ops Services 삭제 서비스를 해지하는 버튼 표. Data Ops Services 상태 정보 및 부가 기능
- Data Ops Services 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Data Ops Services 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Data Ops명 | Data Ops 이름 |
| 스토리지 클래스 | 선택한 클러스터가 사용하는 스토리지 클래스 |
| 설명 | Data Ops Services에 대한 추가 정보나 설명 |
| 도메인 설정 | Data Ops Services 도메인 이름 |
| Node Selector | 노드 Lable |
| Web Url | Data Ops Services URL |
| 계정 | Airflow 계정 |
| Host Alias | Data Ops Services와 연결될 호스트 정보 |
표. Data Ops Services 상세 정보 탭 항목
태그
Data Ops Services 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Data Ops Services 태그 탭 항목
작업 이력
Data Ops Services 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Data Ops Services 작업 이력 탭 상세 정보 항목
Data Ops Services 해지하기
사용하지 않는 Data Ops Services를 해지해 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Data Ops Services를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Data Ops 메뉴를 클릭하세요. Data Ops의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Data Ops Services 메뉴를 클릭하세요. Data Ops Services 목록 페이지로 이동합니다.
- Data Ops Services 목록 페이지에서 해지할 자원을 선택하고, Data Ops Services 삭제 버튼을 클릭하세요.
- 해지가 완료되면, Data Ops Services 목록 페이지에서 자원이 해지되었는지 확인하세요.
5.2.2 - Ingress Controller 설치하기
사용자는 Data Ops 서비스를 생성하기 전에 Ingress Controller를 설치해야 합니다. Kubernetes 클러스터에는 1개의 Ingress Controller만 설치해야 합니다.
Container Registry를 이용하여 Ingress Controller 설치하기
Container Registry를 이용하여 Ingress Controller를 설치하려면 다음 절차를 따르세요.
자세한 Container Registry 생성 방법은 Container > Container Registry > How-to guides 가이드를 참고하세요.
Ingress Controller 이미지를 저장할 SCR(Samsung Container Registry)을 준비하세요.
SCR(Samsung Container Registry)에 Ingress Controller 이미지를 Push하세요.
설치에 사용한 YAML 파일을 Ingress GitHub에서 다운로드한 후, 아래 항목을 수정하세요.
배경색 변경kind: Deployment ... spec: template: spec: containers: image: {SCR private endpoint}.{repository name}.{image name}:{tag}kind: Deployment ... spec: template: spec: containers: image: {SCR private endpoint}.{repository name}.{image name}:{tag}코드 블럭. SCR 정보 변경 배경색 변경kind: ConfigMap ... metadata: labels: app: ingress-controller kind: Service ... metadata: labels: app: ingress-controller kind: Deployment ... metadata: labels: app: ingress-controller kind: IngressClass ... metadata: labels: app: ingress-controllerkind: ConfigMap ... metadata: labels: app: ingress-controller kind: Service ... metadata: labels: app: ingress-controller kind: Deployment ... metadata: labels: app: ingress-controller kind: IngressClass ... metadata: labels: app: ingress-controller코드 블럭. Label 정보 추가 - metadata: labels: app: ingress-controller 수정한 YAML 파일을 사용하여 Kubernetes Engine에서 워크로드 > 디플로이먼트 목록에서 오브젝트 생성 버튼을 이용하여 Ingress Controller를 설치할 수 있습니다.
참고자세한 오브젝트 생성 방법은 Container > Kubernetes Engine > 디플로이먼트 생성하기 를 참고하세요.
5.3 - API Reference
API Reference
5.4 - CLI Reference
CLI Reference
5.5 - Release Note
Data Ops
2025.04.28
NEW
Data Ops 서비스 정식 버전 출시- 주기적 또는 반복적으로 발생하는 데이터 처리 작업에 대해 워크플로우를 작성하고, 작업 스케줄링을 자동화하는 Data Ops 서비스가 출시되었습니다.
- Apache Airflow 기반의 관리형 워크플로우 오케스트레이션 서비스입니다.
6 - Quick Query
6.1 - Overview
서비스 개요
Quick Query는 대용량 데이터를 표준 SQL을 사용하여 간편하고 빠르게 분석할 수 있는 대화형 쿼리 서비스입니다. 표준 Kubernetes 클러스터 기반에 자동으로 설치되며, Cloud Hadoop, Object Storage, RDB 등 다양한 데이터 소스에 쉽고 빠르게 접근하여 데이터 조회 및 가공이 가능합니다.
특장점
- 쉽고 빠른 데이터 조회: Object Storage에 저장된 데이터에 대해 스키마를 정의한 후 표준 SQL을 사용하여 쿼리를 실행하면 쉽고 빠르게 조회가 가능합니다. SQL을 다룰 수 있는 사용자는 전문 분석가가 아니더라도 누구나 손쉽게 대규모 데이터 세트를 분석할 수 있습니다.
- 신속한 병렬 분산 처리: 병렬 분산 처리가 가능한 Trino 엔진을 사용하여 자동으로 쿼리를 분할하고, 동시에 여러 노드에서 병렬 처리하여 대용량 데이터도 빠르게 쿼리 결과를 확인할 수 있습니다.
- 다양한 서비스 구조: 공용 고정자원 모드와 공용 자원확장 모드, 그리고 개인용 자원확장 모드를 제공합니다. 공용 고정자원 모드는 대규모 데이터 쿼리에 대한 안정적인 응답 속도를 지원하며, 공용 자원확장 모드는 사용 빈도가 불규칙한 경우 더 저렴한 비용으로 이용할 수 있습니다. 또한 개인용 자원확장 모드는 각 사용자가 독립적인 환경에서 분석 작업을 수행할 수 있도록 지원하여 사용자 요구에 맞는 구조의 Quick Query를 이용할 수 있습니다.
서비스 구성도
제공 기능
Quick Query는 다음과 같은 기능을 제공합니다.
- 다양한 Data Source의 단일 엑세스 지원 (11종의 Data Source 지원)
- 결과 데이터에 대한 Object Storage내 자동 저장 기능
- 동일한 쿼리문에 대한 조회 결과 재사용 기능
- Ranger 연동을 통한 접근제어 기능
- 데이터 사용량 제어 기능
| 카테고리 | 타입 | 비고 |
|---|---|---|
| Cloud Hadoop | hive_on_cloud_hadoop iceberg_on_cloud_hadoop | Cloud Hadoop의 Hive Metastore 사용 |
| Object Storage | hive_on_object_storage iceberg_on_object_storag | Quick Query에서 Hive Metastore 배포하여 사용 |
| RDB | postgresql mariadb sqlserver oracle mysql | JDBC Driver Upload 필요 (라이선스) |
| TPCDS | tpcds | Quick Query에서 기본 제공하는 내장 Data Source |
| TPCH | tpch | Quick Query에서 기본 제공하는 내장 Data Source |
표. 지원 Data Source
| 타입 | select | insert | uptate | delete | create | drop | alter | analyze | call |
|---|---|---|---|---|---|---|---|---|---|
| hive_on_cloud_hadoop | O | O | O | O | O | O | O | O | O |
| iceberg_on_cloud_hadoop | O | O | O | O | O | O | O | O | O |
| hive_on_object_storage | O | O | O | O | O | O | O | O | O |
| iceberg_on_object_storage | O | O | O | O | O | O | O | O | O |
| postgresql | O | O | O | O | O | O | |||
| mariadb | O | O | O | O | O | O | |||
| sqlserver | O | O | O | O | O | O | |||
| greenplum | O | O | O | O | O | O | |||
| oracle | O | O | O | O | O | O | |||
| mysql | O | O | O | O | O | O | |||
| tpcds | O | ||||||||
| tpch | O |
표. 지원 SQL
구성 요소
쿼리엔진타입: 공용
쿼리엔진은 1개가 기동되면 여러 사용자가 공유하여 사용하는 구조입니다.
고정자원 모드(Auto Scaling 미사용): Auto Scaling을 미사용하는 경우 사용자가 선택한 리소스에 맞춰 고정된 리소스의 쿼리 엔진이 기동됩니다. 쿼리엔진이 항시 동일한 리소스로 실행되어 있는 구조라 동일한 쿼리 성능을 보장해 줄 수 있는 구조입니다.
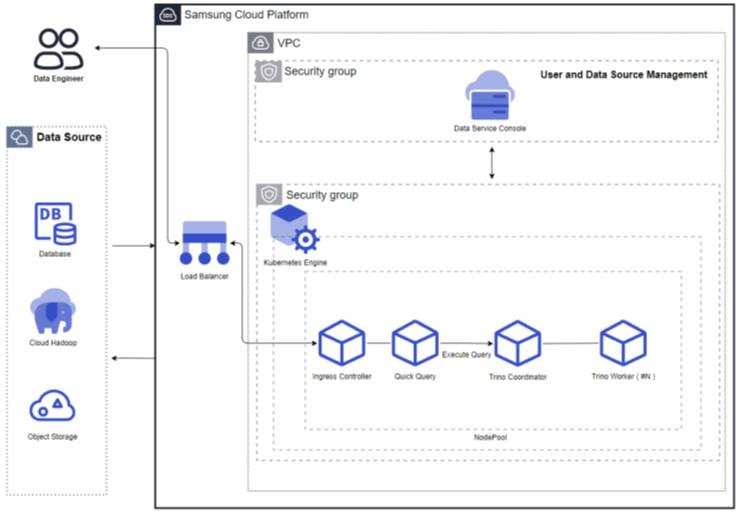
그림. 고정자원 모드(Auto Scaling 미사용) 자원확장 모드(Auto Scaling 사용): Auto Scaling을 사용하는 경우 쿼리엔진의 Worker 노드가 처리량에 따라 자동으로 Auto Scale in/out 됩니다. 처리량이 적을 경우는 1개까지 Worker 노드가 줄어 들고 처리량이 많아지면 Worker 노드가 늘어납니다. 또한 클러스터 사이즈에 따라 리소스를 조정할 수 있습니다.
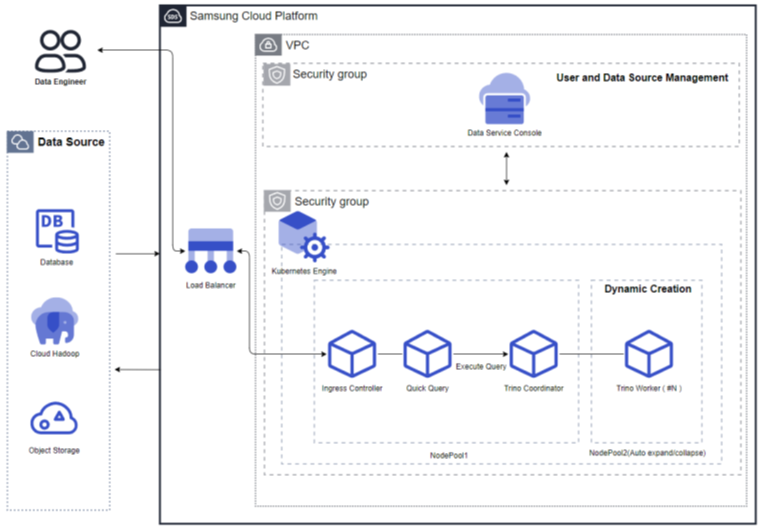
그림. 자원확장 모드(Auto Scaling 사용)
쿼리엔진타입: 개인용
자원확장 모드(Auto Scaling 사용): 개인용 쿼리엔진타입은 쿼리엔진이 사용자별로 별도 실행되는 구조입니다. 각 쿼리엔진은 Auto Scale in/out을 지원하며 장기간 미 사용시 엔진은 자동으로 Stop 되는 구조입니다. 다시 사용을 위해 재 접속시 쿼리엔진이 자동으로 다시 실행됩니다. 처리량이 적을 경우는 1개까지 Worker 노드가 줄어 들고 처리량이 많아지면 Worker 노드가 늘어납니다. 또한 클러스터 사이즈에 따라 리소스를 조정할 수 있습니다.
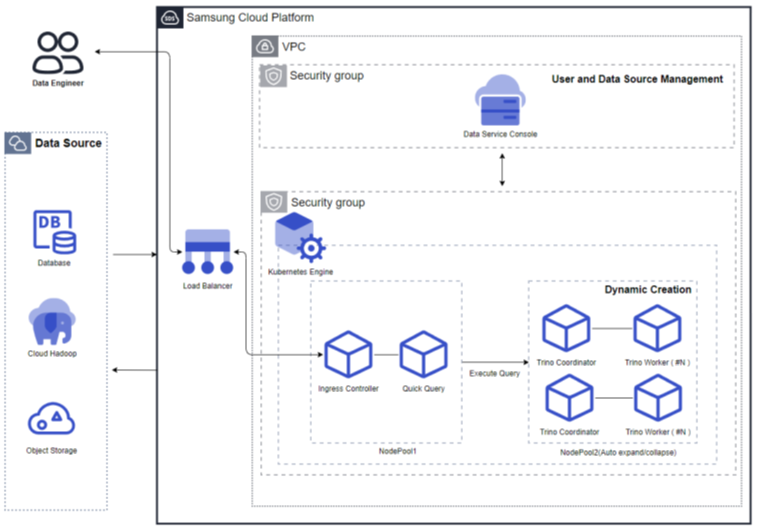
그림. 자원확장 모드(Auto Scaling 사용)
서버 타입
Quick Query에서 지원하는 서버 타입은 다음과 같습니다.
| 구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 유형 | Standard | 제공되는 서버 타입
|
| 서버 크기 | s1v2m4 | 제공되는 서버 사양
|
표. Quick Query 지원 서버 타입
Quick Query를 사용하기 위한 최소 사양은 다음과 같습니다.
| 구분 | 상세 | 클러스터 사이즈(사용자 입력 값) | 고정 노드풀 | 자동 확장 노드풀 |
|---|---|---|---|---|
| 공용 | 고정자원 모드(Auto Scaling 미사용) | Replica: 1 CPU: 4 Core Memory: 8GB | 8 Core, 16GB * 4 | N/A |
| 공용 | 자원확장 모드(Auto Scaling 사용) | Small(1 Core, 4GB) | 8 Core, 16GB * 3 | 8 Core, 16GB * 1 |
| 개인용 | 자원확장 모드(Auto Scaling 사용) | Small(1 Core, 4GB) | 8 Core, 16GB * 3 | 8 Core, 32GB * 2 |
표. Quick Query 최소 사양
리전별 제공 현황
Quick Query은 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. Quick Query 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하시기 바랍니다.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Networking | VPC | 클라우드 환경에서 독립된 가상 네트워크를 제공하는 서비스 |
| Networking | Security Group | 서버의 트래픽을 제어하는 가상 방화벽 |
| Storage | File Storage | 네트워크 연결을 통하여 다수의 클라이언트 서버가 파일을 공유하는 스토리지 |
표. Quick Query 선행 서비스
6.2 - How-to guides
사용자는 Samsung Cloud Platform Console을 통해 Quick Query의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
Quick Query 생성하기
Samsung Cloud Platform Console에서 Quick Query 서비스를 생성하여 사용할 수 있습니다.
Quick Query를 생성하려면 다음 절차를 따르세요.
모든 서비스 > Data Analytics > Quick Query 메뉴를 클릭하세요. Quick Query의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 Quick Query 생성 버튼을 클릭하세요. Quick Query 생성 페이지로 이동합니다.
Quick Query 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 버전 선택 영역에서 필요한 정보를 선택하세요.
구분 필수 여부상세 설명 Quick Query 필수 Quick Query 서비스 버전 선택 - 제공하는 버전 리스트 제공
표. Quick Query 서비스 버전 선택 항목 - 서비스 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 Quick Query명 필수 Quick Query 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
설명 선택 Quick Query에 대한 추가 정보나 설명을 150자 이내로 입력 도메인 설정 필수 Quick Query 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-,.)로 끝나지 않도록, 소문자, 숫자와 특수문자(-,.)를 사용하여 3 ~ 50자로 입력
- {Quick Query명}.{설정한 도메인}이 Quick Query 접속 주소가 됩니다.
쿼리 엔진 타입 필수 쿼리 엔진 타입 선택 - 공용: 한 개의 쿼리 엔진을 여러 사용자가 공유하여 사용
- 개인용: 사용자 별로 별도의 엔진 사용
클러스터 사이즈 필수 클러스터 구성을 위한 자원 용량 선택 - 엔진 타입을 공용으로 선택한 경우
- Auto Scaling을 사용으로 선택하면, 클러스터 용량을 Small, Medium, Large, Extra Large 중에 선택할 수 있습니다.
- Auto Scaling을 사용으로 선택하지 않으면, 클러스터 용량을 Replica, CPU, Memory 입력을 통해 설정할 수 있습니다.
- 엔진 타입을 개인용으로 선택한 경우
- 클러스터 용량을 Small, Medium, Large, Extra Large 중에 선택할 수 있습니다.
- 엔진 용량(Auto Scaling 사용 시)
- Small: 1Core, 4GB
- Medium: 4Core, 16GB
- Large: 8Core, 64GB
- Extra Large: 16Core, 128GB
- 엔진 용량(Auto Scaling 미사용 시)
- Replica: 1 ~ 9 입력 가능, 기본값: 1
- CPU: 4 ~ 24 입력 가능 (4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24 입력 가능), 기본값: 4
- Memory: 8 ~ 256 입력 가능 (8, 16, 32, 64, 128, 192, 256 입력 가능), 기본값: 8
최대 동시 실행 쿼리 수 필수 Quick Query에서 동시에 실행하려는 최대 쿼리 수 선택 - 선택 가능 값: 32, 64, 96, 128
Data Service Console 연결 필수 Data Service Console 도메인 입력 - 영문 소문자로 시작하며 특수문자(
-,.)로 끝나지 않도록, 소문자, 숫자와 특수문자(-,.)를 사용하여 3 ~ 50자로 입력
Host Alias 선택 Quick Query와 연결될 호스트 정보 추가 (기본 포함 총 20개 생성 가능) - 사용을 선택한 후, + 버튼 클릭
- Hostname: 호스트명 또는 도메인 형식으로, 소문자, 숫자와 특수문자(
-,.)를 사용하여 3~63자로 입력
- IP: IP 형식으로 입력
- 삭제하려면 X 버튼 클릭
- 클러스터와 해당 서버와의 방화벽이 오픈되어 있어야 추가한 호스트 정보 사용 가능
표. Quick Query 서비스 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 클러스터 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 클러스터명 필수 클러스터 이름 입력 - 영문 소문자로 시작하며 특수문자(
-)로 끝나지 않도록, 소문자, 숫자와 특수문자(-)를 사용하여 3 ~ 30자로 입력
제어영역 설정 필수/선택 - Kubernetes 버전: Kubernetes 버전 표시
- 프로비저닝 이후 Kubernetes 버전을 업그레이드할 수 있습니다.
- 퍼블릭 엔드포인트 엑세스: 외부에서 Kubernetes API 서버 엔드포인트를 엑세스하도록 설정하려면 사용을 선택한 후, 접근 제어 IP 범위를 입력하세요(서비스 신청 후 변경 불가).
- 제어영역 로깅: 제어영역 로깅의 사용 여부 선택
- 사용을 선택하면, Management > Cloud Monitoring > 로그 분석에서 클러스터 제어영역의 Audit/이벤트 로그를 확인할 수 있습니다.
- 프로젝트 내의 전체 서비스를 대상으로 1GB의 로그 저장은 무료로 제공되며, 1GB를 넘을 경우에는 순차적으로 삭제됩니다.
네트워크 설정 필수 네트워크 연결 설정 - VPC: Data Service Console과 동일한 VPC 사용
- 서브넷: 선택한 VPC의 서브넷 중에서 사용할 항목 선택
- Security Group: 검색을 클릭한 후, Security Group 선택 팝업창에서 보안 그룹 선택
File Storage 설정 필수 클러스터에서 사용할 파일 스토리지 볼륨 선택 - 기본 Volume (NFS): 검색을 클릭한 후, File Storage 선택 팝업창에서 파일 스토리지 선택
표. Quick Query 서비스 클러스터 정보 입력 항목 - 영문 소문자로 시작하며 특수문자(
- 노드 풀 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 노드 풀 구성 필수/선택 추가할 노드 풀의 상세 정보 입력 - * 표시된 항목은 필수 입력 항목
- 쿼리 엔진 타입이 공용이고 Auto Scaling을 미사용으로 선택한 경우에는, 노드 풀 구성(고정) 항목만 설정할 수 있습니다.
- Keypair: Virtual Server에 연결할 때 사용하는 증명 방법 선택
표. Quick Query 서비스 노드 풀 정보 입력 항목 - * 표시된 항목은 필수 입력 항목
- 추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 태그 추가 버튼을 클릭하여 태그를 생성하여 추가하거나 기존 태그 추가 가능
- 최대 50개까지 태그 추가 가능
- 추가된 신규 태그는 서비스 생성 완료 후 적용
표. Quick Query 서비스 추가 정보 입력 항목
- 버전 선택 영역에서 필요한 정보를 선택하세요.
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, Quick Query 목록 페이지에서 생성한 자원을 확인하세요.
Quick Query 상세 정보 확인하기
Quick Query 서비스의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. Quick Query 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
Quick Query 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Quick Query 메뉴를 클릭하세요. Quick Query의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Quick Query 메뉴를 클릭하세요. Quick Query 목록 페이지로 이동합니다.
- Quick Query 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. Quick Query 상세 페이지로 이동합니다.
- Quick Query 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
구분 상세 설명 상태 표시 사용자가 생성한 Quick Query의 상태 - Creating: 생성 중
- Running: 생성 완료, 서비스 사용 가능 상태
- Updating: 설정 업데이트 중
- Terminating: 서비스 해지 중
- Error: 생성 중 오류 발생 또는 서비스 이상 상태
Hosts 파일 셋팅 정보 Quick Query와 Data Service Console에 접속하기 위한 호스트 파일 정보를 확인하고 복사하는 버튼 서비스 해지 서비스를 해지하는 버튼 표. Quick Query 상태 정보 및 부가 기능
- Quick Query 상세 페이지 상단에는 상태 정보 및 부가 기능에 대한 정보가 표시됩니다.
상세 정보
Quick Query 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID
|
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| Quick Query명 | Quick Query 이름 |
| 설명 | Quick Query에 대한 추가 정보나 설명 |
| 버전 | Quick Query 버전 |
| 서비스 유형 | Quick Query 서비스 유형 |
| 쿼리 엔진 타입 | Quick Query 엔진 타입 |
| 엔진 Spec |
|
| 최대 동시 실행 쿼리 수 | Quick Query에서 동시에 실행하려는 최대 쿼리 수 |
| 도메인 설정 | Quick Query 도메인 |
| Data Service Console | Data Service Console 도메인 |
| Host Alias | Quick Query와 연결될 호스트 정보 |
| Web URL | Data Service Console과 Quick Query의 웹 URL |
| 클러스터명 | 서버들이 구성된 클러스터 이름 |
| 설치 노드 정보 | 설치된 노드 풀의 상세 정보 |
표. Quick Query 상세 정보 탭 항목
태그
Quick Query 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. Quick Query 태그 탭 항목
작업 이력
Quick Query 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. Quick Query 작업 이력 탭 상세 정보 항목
Quick Query 접속하기
Quick Query에 접속하려면 다음 절차를 따르세요.
- Quick Query에 접속하려는 Windows 시스템(PC)의 IP를 확인하세요.
- 외부 접속이 필요하므로 시스템의 Public IP를 확인해야 합니다.
- Quick Query가 설치된 VPC에 IGW 연결이 사용으로 되어있는지 확인하세요.
- 외부에서 접속 시 연결 가능한 Internet Gateway 설정이 되어있어야 합니다.
- Windows 시스템의 hosts 파일에 다음 내용을 추가하세요. Quick Query 상세 화면에서 Hosts 파일 세팅정보를 클릭하여 확인할 수 있습니다.
- Data Service Console의 도메인 주소
- Data Service Console IAM의 도메인 주소
- Quick Query의 도메인 주소
- Quick Query 서비스 신청 시 선택했던 VPC IGW Firewall에 다음 규칙을 추가하세요.
구분 Protocol Source Target IP Port Inbound TCP User IP Load Balancer 서비스 IP 80,443 표. VPC IGW Firewall 규칙 - Quick Query 서비스 신청 시 선택했던 Load Balancer Firewall에 다음 규칙을 추가하세요.
구분 Protocol Source Target IP Port Outbound TCP User IP Load Balancer 서비스 IP 80,443 Inbound TCP Load Balancer의 Source NAT IP Kubernetes Node Pool의 Subnet 대역 30000-32767 TCP Load Balancer의 Health Check IP Kubernetes Node Pool의 Subnet 대역 30000-32767 표. Load Balancer Firewall 규칙 - Quick Query 서비스 신청 시 선택했던 Security Group에 다음 규칙을 추가하세요.
구분 Protocol Target IP Port Inbound TCP Load Balancer의 Source NAT IP 30000-32767 TCP Load Balancer의 Health Check IP 30000-32767 표. Security Group 규칙 - 접속하려는 Windows 시스템(PC)에서 Chrome 브라우저를 실행한 후 Quick Query URL에 접속하세요.
Quick Query 해지하기
사용하지 않는 해당 서비스를 해지하여 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
Quick Query를 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > Data Analytics > Quick Query 메뉴를 클릭하세요. Quick Query의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Quick Query 메뉴를 클릭하세요. Quick Query 목록 페이지로 이동합니다.
- Quick Query 목록 페이지에서 해지할 자원을 선택하고, 서비스 해지 버튼을 클릭하세요.
- 해지가 완료되면, Quick Query 목록 페이지에서 자원이 해지되었는지 확인하세요.
6.3 - API Reference
API Reference
6.4 - CLI Reference
CLI Reference