쉽고 편리하게 ML/DL(Machine Learning/Deep Learning) 모델 개발 및 학습 환경을 구축할 수 있는 AI/ML 서비스를 제공합니다.
이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
AI-ML
- 1: AIOS
- 1.1: Overview
- 1.2: How-to Guides
- 1.3: References
- 1.3.1: API Reference
- 1.3.2: Tutorial
- 1.3.2.1: Chat Playground
- 1.3.2.2: RAG
- 1.3.2.3: Autogen
- 1.3.3: Request Examples
- 1.4: Release Note
- 1.5: Licenses
- 1.5.1: Llama-4-Scout
- 1.5.2: Llama-Guard-4-12B
- 1.5.3: bge-m3
- 1.5.4: bge-reranker-v2-m3
- 1.5.5: Qwen3-Coder-30B-A3B
- 1.5.6: gpt-oss-120b
- 1.5.7: Qwen3-30B-A3B-Thinking
- 2: CloudML
- 2.1: Overview
- 2.2: How-to guides
- 2.2.1: Kubernetes 클러스터 구성
- 2.3: API Reference
- 2.4: CLI Reference
- 2.5: Release Note
- 3: AI&MLOps Platform
- 3.1: Overview
- 3.2: How-to guides
- 3.2.1: 클러스터 배포
- 3.2.2: Kubeflow 사용 가이드
- 3.3: API Reference
- 3.4: CLI Reference
- 3.5: Release Note
1 - AIOS
1.1 - Overview
서비스 개요
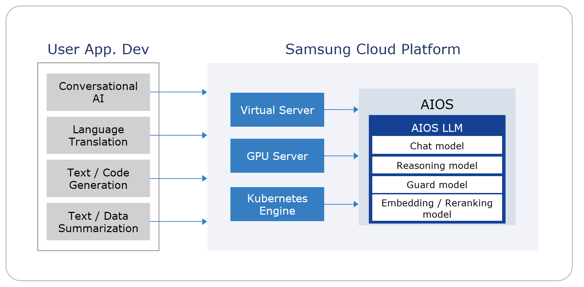
AIOS는 Samsung Cloud Platform에서 Virtual Server, GPU Server, Kubernetes Engine 자원을 생성한 후, 별도의 LLM 서비스 설치나 설정 없이 해당 자원에서 LLM을 사용하여 AI 애플리케이션의 개발을 할 수 있는 환경을 제공합니다.
특장점
- 편리한 LLM 사용 Samsung Cloud Platform에서 Virtual Server, GPU Server, Kubernetes Engine 자원에서 바로 LLM을 이용할 수 있는 LLM Endpoint를 기본으로 제공합니다.
- AI 개발 생산성 향상 : AI 개발자는 다양한 모델에 대해서 동일한 API로 사용이 가능하며, OpenAI 및 LangChain SDK와 호환성을 지원하여 기존 개발 환경과 프레임워크에 쉽게 연동할 수 있습니다.
서비스 구성도
제공 기능
다음과 같은 기능을 제공하고 있습니다.
- AIOS LLM Endpoint 제공: Virtual Server, GPU Server, Kubernetes Engine 서비스를 신청하면 생성된 자원의 상세 페이지에서 LLM Endpoint 정보 및 이용 가이드가 제공되며 이용 가이드에 따라 해당 자원에서 LLM에 접속하여 사용 할 수 있습니다.
- AIOS Report 제공: 유형별, 리소스별, 모델별 호출 횟수와 Token 사용량 및 LLM별 전체 사용량을 확인할 수 있습니다.
제공 모델
AIOS에서 제공하는 LLM 모델은 다음과 같습니다.
| 모델명 | 모델 타입 | 소개 | 주요 활용처 | 특징 |
|---|---|---|---|---|
| gpt-oss-120b | Chat+Reasoning | 1,200억 파라미터 기반 GPT 계열 오픈소스 최신 모델 | 연구·실험, 대규모 언어 이해, 복잡한 추론/분석이 필요한 AI 서비스, 에이전트형 시스템 구축 |
|
| Qwen3-Coder-30B-A3B-Instruct | Code | 코드 생성과 디버깅에 최적화된 Qwen3 시리즈 코드 모델 | 소프트웨어 개발, AI 코드 어시스턴트, 긴 문서/저장소 분석 |
|
| Qwen3-30B-A3B-Thinking-2507 | Chat+Reasoning | 장문 추론과 심층적 사고(Thinking)에 강화된 Qwen3 모델 | 리서치, 분석 보고서, 논리적 글쓰기, 수학, 과학, 코딩 |
|
| Llama-4-Scout | Chat+Vision | 멀티모달 가능한 최신 Llama 모델 | 문서 분석·요약, 고객 지원·챗봇 |
|
| Llama-Guard-4-12B | moderation | 최신 대형 언어모델 및 멀티모달 AI 서비스에서 신뢰성과 안전성을 높이기 위한 핵심 보안 및 모더레이션 모델 | 사용자 입력과 모델의 응답의 유해성 자동 필터링에 활용 |
|
| bge-m3 | embedding | 다기능, 다국어, 대용량 입력 지원이라는 세 가지 특성을 지닌 핵심 임베딩 모델 | 생성형 AI에서 외부 지식 검색 및 정답 근거 제공에 사용 Dense와 Sparse 검색을 결합해 정확도와 일반화 성능을 모두 확보할 때 활용 |
|
| bge-reranker-v2-m3 | rerank | 다국어 환경에서 빠르고 정확한 검색 결과 재정렬이 필요한 다양한 정보 검색, 질의응답, 챗봇 시스템의 핵심 컴포넌트 | 질문에 대한 후보 답변이나 문서를 관련도 순으로 재정렬 |
|
표. AIOS 제공 LLM 모델
리전별 제공 현황
AIOS는 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 미제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. AIOS 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Compute | Virtual Server | 클라우드 컴퓨팅에 최적화된 가상 서버 |
| Compute | GPU Server | 클라우드 환경에서 AI모델 실험, 예측, 추론 등 빠른 연산 속도를 필요로 하는 업무에 적합한 가상 서버 |
| Compute | Cloud Functions | 서버리스 컴퓨팅 기반의 Faas (Function as a Service) |
| Container | Kubernetes Engine | 경량화된 가상 컴퓨팅과 컨테이너와 이를 관리하기 위한 Kubernetes 클러스터 제공 서비스 |
표. AIOS 선행 서비스
1.2 - How-to Guides
AIOS 사용하기
AIOS는 Virtual Server, GPU Server, Kubernetes Engine 서비스를 생성하면 각 자원 내에서 기본적으로 LLM을 사용할 수 있는 환경을 제공합니다.
참고
각 서비스 생성에 대한 자세한 내용은 아래 표를 참고하세요.
| 서비스 | 가이드 |
|---|---|
| Virtual Server | Virtual Server 생성하기 |
| GPU Server | GPU Server 생성하기 |
| Cloud Functions | Cloud Functions 생성하기 |
| Kubernetes Engine | 클러스터 생성하기 |
표. AIOS 사용 가능한 서비스 생성 가이드
LLM 사용하기
LLM은 Samsung Cloud Platform 에서 생성된 Virtual Server, GPU Server, Cloud Functions, Kubernetes Engine 서비스 자원 내부에서 LLM Endpoint 를 활용하여 사용할 수 있습니다. LLM Endpoint는 서비스의 상세 페이지에서 LLM Endpoint에 대한 이용 가이드를 통해 확인할 수 있습니다.
Virtual Server의 LLM Endpoint 확인하기
생성한 Virtual Server의 Virtual Server 상세 페이지에서 LLM Endpoint의 이용 가이드를 확인할 수 있습니다.
LLM Endpoint의 이용 가이드를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Virtual Server 메뉴를 클릭하세요. Virtual Server 목록 페이지로 이동합니다.
- Virtual Server 목록 페이지에서 LLM Endpoint에 연결할 자원을 클릭하세요. Virtual Server 상세 페이지로 이동합니다.
- Virtual Server 상세 페이지에서 LLM Endpoint 항목의 이용 가이드 링크를 클릭하세요. LLM 이용 가이드 팝업창으로 이동합니다.
참고
LLM 이용 가이드에 대한 자세한 내용은 LLM 이용 가이드에서 확인하세요.
GPU Server의 LLM Endpoint 확인하기
생성한 GPU Server의 GPU Server 상세 페이지에서 LLM Endpoint의 이용 가이드를 확인할 수 있습니다.
LLM Endpoint의 이용 가이드를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > GPU Server 메뉴를 클릭하세요. GPU Server의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 GPU Server 메뉴를 클릭하세요. GPU Server 목록 페이지로 이동합니다.
- GPU Server 목록 페이지에서 LLM Endpoint에 연결할 자원을 클릭하세요. GPU Server 상세 페이지로 이동합니다.
- GPU Server 상세 페이지에서 LLM Endpoint 항목의 이용 가이드 링크를 클릭하세요. LLM 이용 가이드 팝업창으로 이동합니다.
참고
LLM 이용 가이드에 대한 자세한 내용은 LLM 이용 가이드에서 확인하세요.
Cloud Functions의 LLM Endpoint 확인하기
생성한 Cloud Functions의 Cloud Functions 상세 페이지에서 LLM Endpoint의 이용 가이드를 확인할 수 있습니다.
LLM Endpoint의 이용 가이드를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Compute > Cloud Functions 메뉴를 클릭하세요. Cloud Functions의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Functions 메뉴를 클릭하세요. Functions 목록 페이지로 이동합니다.
- Functions 목록 페이지에서 LLM Endpoint에 연결할 자원을 클릭하세요. Functions 상세 페이지로 이동합니다.
- Functions 상세 페이지에서 LLM Endpoint 항목의 이용 가이드 링크를 클릭하세요. LLM 이용 가이드 팝업창으로 이동합니다.
참고
LLM 이용 가이드에 대한 자세한 내용은 LLM 이용 가이드에서 확인하세요.
Kubernetes Engine 클러스터의 LLM Endpoint 확인하기
생성한 Kubernetes Engine 클러스터의 클러스터 상세 페이지에서 LLM Endpoint의 이용 가이드를 확인할 수 있습니다.
LLM Endpoint의 이용 가이드를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > Container > Kubernetes Engine 메뉴를 클릭하세요. Kubernetes Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 클러스터 메뉴를 클릭하세요. 클러스터 목록 페이지로 이동합니다.
- 클러스터 목록 페이지에서 LLM Endpoint에 연결할 자원을 클릭하세요. 클러스터 상세 페이지로 이동합니다.
- 클러스터 상세 페이지에서 LLM Endpoint 항목의 이용 가이드 링크를 클릭하세요. LLM 이용 가이드 팝업창으로 이동합니다.
참고
LLM 이용 가이드에 대한 자세한 내용은 LLM 이용 가이드에서 확인하세요.
LLM 이용 가이드
LLM Endpoint의 이용 가이드에서는 AIOS LLM 프라이빗 엔드포인트와 제공 모델, 샘플 코드 예시를 확인할 수 있습니다.
AIOS LLM 프라이빗 엔드포인트
AIOS LLM 프라이빗 엔드포인트의 URL이 표시됩니다. URL을 확인하여 Virtual Server, GPU Server, Kubernetes Engine 서비스의 생성된 자원 내부에서 사용할 수 있습니다.
AIOS LLM 제공 모델
AIOS LLM 제공 모델은 다음과 같습니다.
| 모델명 | 모델ID | 컨텍스트 크기 | RPM (Request per minute) | TPM (Token per minute) | 용도 | 라이선스 | 사용중단일 |
|---|---|---|---|---|---|---|---|
| gpt-oss-120b | openai/gpt-oss-120b | 131,072 | 50 RPM | 200K | 연구, 실험, 고급 언어 이해 | Apache 2.0 | 계획없음 |
| Qwen3-Coder-30B-A3B-Instruct | Qwen/Qwen3-Coder-30B-A3B-Instruct | 65,536 | 20 RPM | 30K | 코드 생성, 분석, 디버깅 지원 | Apache 2.0 | 계획없음 |
| Qwen3-30B-A3B-Thinking-2507 | Qwen/Qwen3-30B-A3B-Thinking-2507 | 32,768 | 10 RPM | 30K | 심층적 추론, 장문 분석, 에세이 작성 | Apache 2.0 | 계획없음 |
| Llama-4-Scout | meta-llama/Llama-4-Scout | 32,768 | 20 RPM | 35K | 멀티모달 가능한 최신 Llama 모델 | llama4 | 계획없음 |
| Llama-Guard-4-12B | meta-llama/Llama-Guard-4-12B | 32,768 | 20 RPM | 200K | 최신 대형 언어모델 및 멀티모달 AI 서비스에서 신뢰성과 안전성을 높이기 위한 핵심 보안 및 모더레이션 모델 | llama4 | 계획없음 |
| bge-m3 | sds/bge-m3 | 8,192 | 100 RPM | 200K | 다국어 임베딩 모델로, 다국어 언어를 지원합니다. | Samsung SDS | 계획없음 |
| bge-reranker-v2-m3 | sds/bge-reranker-v2-m3 | 8,192 | 100 RPM | 200K | 경량화된 다국어 리랭커로 빠른 연산과 높은 성능을 제공합니다. | Samsung SDS | 계획없음 |
표. AIOS LLM 제공 모델
샘플 코드
AIOS LLM 샘플 코드 예시는 다음을 참조하세요.
배경색 변경
curl -H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-120b"
, "prompt" : "Write a haiku about recursion in programming."
, "temperature": 0
, "max_tokens": 100
, "stream": false
}' \
{AIOS LLM 프라이빗 엔드포인트}/{API}curl -H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-120b"
, "prompt" : "Write a haiku about recursion in programming."
, "temperature": 0
, "max_tokens": 100
, "stream": false
}' \
{AIOS LLM 프라이빗 엔드포인트}/{API}LLM 모델별 사용량 확인하기
AIOS의 Service Home 페이지에서 LLM 목록과 모델별 Token 사용량을 확인할 수 있습니다.
- 모든 서비스 > AI-ML > AIOS 메뉴를 클릭하세요. AIOS의 Service Home 페이지로 이동합니다.
- LLM 모델별 사용량 목록에서 LLM의 모델명과 모델 타입, 사용 토큰량(1week)을 확인하세요.
구분 상세 설명 모델명 LLM 이름 - 이름을 클릭하면 해당 모델의 Report 페이지로 이동
모델 타입 LLM 타입 - chat, reasoning, vision, moderation, embedding, rerank
- 모델별 정보는 제공 모델 참고
사용 토큰량(1 Week) 현재일 기준으로 1주일간 사용한 토큰량 표. AIOS LLM 목록 항목
Report 확인하기
AIOS의 Report 페이지에서 일자별 LLM 호출 횟수와 토큰 사용량을 확인할 수 있습니다.
서비스 유형은 Virtual Server, GPU Server, Kubernetes Engine을 선택할 수 있고, 해당 서비스에서 실제로 생성된 자원들 중에서 자원명을 선택하여 조회할 수있고, 사용한 LLM 모델별로도 조회 할 수 있습니다.
- 모든 서비스 > AI-ML > AIOS 메뉴를 클릭하세요. AIOS의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 Report 메뉴를 클릭하세요. AIOS의 Report 페이지로 이동합니다.
- LLM 모델별 사용량 목록에서 LLM 모델명을 클릭하면 해당 LLM의 Report 페이지로 바로 이동할 수 있습니다.
- Report 페이지에서 Report를 확인할 LLM 모델을 선택한 후, 조회 버튼을 클릭하세요. 해당 LLM 모델의 Report 정보가 표시됩니다.
구분 상세 설명 서비스 유형 LLM을 사용하는 서비스 유형 선택 - Virtual Server, GPU Server, Kubernetes Engine
자원명 서비스 이름 선택 - 서비스 유형을 선택하지 않으면 전체만 선택 가능하고, 서비스 유형에서 특정 상품을 선택하면 특정 자원명 선택 가능
Model LLM 모델 종류 선택 - 모델별 정보는 제공 모델 참고
조회 기간 Report를 확인할 기간 선택 - 일주일 단위로 선택 가능
- 이전 기간은 최대 3개월까지 조회 가능
- 조회하는 데이터는 현재시간 기준 최대 30분 전까지의 데이터를 기준으로 제공
호출 횟수 조회 기간 동안 일자별 호출 횟수 - 일자별로 총 횟수, 성공 횟수, 실패 횟수로 표시
- 전체 호출 횟수: 해당 기간동안의 전체 호출 횟수를 모델별로 제공
Token 사용량 조회 기간 동안 일자별 Token 입력량과 출력량 - 전체 Token 수: 조회 기간 동안 전체 Token 사용량
- Request 당 평균 Token 수: 조회 기간 동안 LLM 호출 시 사용한 평균 Token량
표. AIOS Report 항목
1.3 - References
References
AIOS에서 지원하는 API, SDK reference를 확인할 수 있고, AIOS를 활용해볼 수 있는 Tutorial를 제공합니다.
| 구분 | 설명 |
|---|---|
| API Reference | AIOS에서 지원하는 API 목록
|
| SDK Reference | OpenAI의 SDK 등 AIOS와 호환되는 SDK 정보
|
| Tutorial | AIOS를 활용해볼 수 있는 Tutorial을 제공
|
표. AIOS Reference 목록
1.3.1 - API Reference
API Reference 개요
AIOS에서 지원하는 API Reference는 다음과 같습니다.
| API명 | API | 상세 설명 |
|---|---|---|
| Rerank API | POST /rerank, /v1/rerank, /v2/rerank | 임베딩 모델이나 크로스 인코더 모델을 적용하여 단일 쿼리와 문서 목록의 각 항목 간 관련성을 예측합니다. |
| Score API | POST /score, /v1/score | 두 문장의 유사도를 예측합니다. |
| Chat Completions API | POST /v1/chat/completions | OpenAI의 Completions API와 호환되며 OpenAI Python client에서 사용할 수 있습니다. |
| Completions API | POST /v1/completions | OpenAI의 Completions API와 호환되며 OpenAI Python client에서 사용할 수 있습니다. |
| Embedding API | POST /v1/embeddings | 텍스트를 고차원 벡터(임베딩)로 변환하여, 텍스트 간 유사도 계산, 클러스터링, 검색 등 다양한 자연어 처리(NLP) 작업에 활용할 수 있습니다. |
표. AIOS 지원 API 목록
Rerank API
POST /rerank, /v1/rerank, /v2/rerank
개요
Rerank API는 임베딩 모델이나 크로스 인코더 모델을 적용하여 단일 쿼리와 문서 목록의 각 항목 간 관련성을 예측합니다. 일반적으로 문장 쌍의 점수는 두 문장 간 유사도를 0에서 1 사이의 범위로 나타냅니다.
- Embedding 기반 모델: Query와 문서를 각각 벡터로 바꾼 뒤, 벡터간의 유사도(예시: 코사인 유사도)를 측정하여 점수를 계산합니다.
- Reranker(Cross-Encoder) 기반 모델: Query와 문서를 한쌍으로 모델에 넣어서 평가합니다.
Request
Context
| Key | Type | Description | Example |
|---|---|---|---|
| Base URL | string | API 요청을 위한 AIOS URL | AIOS LLM 프라이빗 엔드포인트 |
| Request Method | string | API 요청에 사용되는 HTTP 메서드 | POST |
| Headers | object | 요청 시 필요한 헤더 정보 | { “Content-Type”: “application/json” } |
| Body Parameters | object | 요청 본문에 포함되는 파라미터 | { “model”: “sds/bge-m3”, “query”: …, “documents”: […] } |
표. Re-rank API - Context
Path Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Re-rank API - Path Parameters
Query Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Re-rank API - Query Parameters
Body Parameters
| Name | Name Sub | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|---|
| model | - | string | ✅ | 응답 생성에 사용할 모델을 지정 | “sds/bge-reranker-v2-m3” | ||
| query | - | string | ✅ | 사용자의 검색 질의 또는 질문 | “What is the capital of France?" | ||
| documents | - | array | ✅ | 재정렬 대상인 문서 목록 | 최대 모델 입력 길이 제한 | [“The capital of France is Paris.”] | |
| top_n | - | integer | ❌ | 반환할 상위 문서 개수를 지정(0이면 전체 반환) | 0 | > 0 | 5 |
| truncate_prompt_tokens | - | integer | ❌ | 입력 토큰 수를 제한 | > 0 | 100 |
표. Re-rank API - Body Parameters
Example
배경색 변경
curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-reranker-v2-m3",
"query": "What is the capital of France?",
"documents": [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
],
"top_n": 2,
"truncate_prompt_tokens": 512
}'curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-reranker-v2-m3",
"query": "What is the capital of France?",
"documents": [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
],
"top_n": 2,
"truncate_prompt_tokens": 512
}'Response
200 OK
| Name | Type | Description |
|---|---|---|
| id | string | API 응답의 고유 식별자(UUID 형식) |
| model | string | 결과를 생성한 모델의 이름 |
| usage | integer | 요청에 사용된 리소스 정보를 담은 객체 |
| usage.total_tokens | integer | 요청 처리에 사용된 총 토큰 수 |
| result | string | 쿼리와 관련된 문서들의 결과를 담은 배열 |
| results[].index | integer | 결과 배열 내의 순서 번호 |
| results[].document | object | 검색된 문서의 내용을 담은 객체 |
| results[].document.text | string | 검색된 문서의 실제 텍스트 내용 |
| results[].relevance_score | float | 쿼리와 문서 간의 관련성을 나타내는 점수(0 ~ 1) |
표. Re-rank API - 200 OK
Error Code
| HTTP status code | ErrorCode 설명 |
|---|---|
| 400 | Bad Request |
| 422 | Validation Error |
| 500 | Internal Server Error |
표. Re-rank API - Error Code
Example
배경색 변경
{
"id": "rerank-scp-aios-rerank",
"model": "sds/sds/bge-m3",
"usage": {
"total_tokens": 65
},
"results": [
{
"index": 0,
"document": {
"text": "The capital of France is Paris."
},
"relevance_score": 0.8291233777999878
},
{
"index": 1,
"document": {
"text": "France capital city is known for the Eiffel Tower."
},
"relevance_score": 0.6996355652809143
}
]
}{
"id": "rerank-scp-aios-rerank",
"model": "sds/sds/bge-m3",
"usage": {
"total_tokens": 65
},
"results": [
{
"index": 0,
"document": {
"text": "The capital of France is Paris."
},
"relevance_score": 0.8291233777999878
},
{
"index": 1,
"document": {
"text": "France capital city is known for the Eiffel Tower."
},
"relevance_score": 0.6996355652809143
}
]
}참고
Score API
POST /score, /v1/score
개요
Score API는 두 문장의 유사도를 예측합니다. 이 API는 두 가지 모델 중 하나를 사용하여 점수를 계산합니다
- Reranker(Cross-Encoder) 모델: 문장 쌍을 입력으로 받아 직접 유사도 점수를 예측합니다.
- Embedding 모델: 각 문장의 임베딩 벡터를 생성한 후, 코사인 유사도(Cosine similarity)를 계산하여 점수를 도출합니다.
Request
Context
| Key | Type | Description | Example |
|---|---|---|---|
| Base URL | string | API 요청을 위한 AIOS URL | AIOS LLM 프라이빗 엔드포인트 |
| Request Method | string | API 요청에 사용되는 HTTP 메서드 | POST |
| Headers | object | 요청 시 필요한 헤더 정보 | { “Content-Type”: “application/json” } |
| Body Parameters | object | 요청 본문에 포함되는 파라미터 | { “model”: “sds/bge-reranker-v2-m3”, “text_1”: […], “text_2”: […] } |
표. Score API - Context
Path Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Score API - Path Parameters
Query Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Score API - Query Parameters
Body Parameters
| Name | Name Sub | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|---|
| model | - | string | ✅ | 응답 생성에 사용할 모델을 지정 | “sds/bge-reranker-v2-m3” | ||
| encoding_format | - | string | ❌ | 점수 반환 형식 | “float” |
| “float” |
| text_1 | - | string, array | ✅ | 비교할 첫 번째 텍스트 |
| “What is the capital of France?" | |
| text_2 | - | string, array | ✅ | 비교할 두 번째 텍스트 |
| [“The capital of France is Paris.”, ] | |
| truncate_prompt_tokens | - | integer | ❌ | 입력 토큰 수를 제한 | > 0 | 100 |
표. Score API - Body Parameters
Example
배경색 변경
curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/score \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-reranker-v2-m3",
"encoding_format": "float",
"text_1": [
"태양계에서 가장 큰 행성은 무엇인가요?",
"물의 화학 기호는 무엇인가요?"
],
"text_2": [
"목성은 태양계에서 가장 큰 행성입니다.",
"물의 화학 기호는 H₂O입니다."
]
}'curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/score \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-reranker-v2-m3",
"encoding_format": "float",
"text_1": [
"태양계에서 가장 큰 행성은 무엇인가요?",
"물의 화학 기호는 무엇인가요?"
],
"text_2": [
"목성은 태양계에서 가장 큰 행성입니다.",
"물의 화학 기호는 H₂O입니다."
]
}'Response
200 OK
| Name | Type | Description |
|---|---|---|
| id | string | 응답의 고유 식별자 |
| object | string | 응답 객체의 타입(예시: “list” ) |
| created | integer | 생성 시각(Unix timestamp, 초 단위) |
| model | string | 사용된 모델의 이름 |
| data | array | 점수 계산 결과 목록 |
| data.index | integer | 데이터 배열 내 해당 항목의 인덱스 |
| data.object | string | 데이터 항목 타입(예시: “score”) |
| data.score | number | 계산된 점수 값, 범위는 0 ~ 1로 정규화 값 |
| usage | object | 토큰 사용량 통계 |
| usage.prompt_tokens | integer | 입력 프롬프트에 사용된 토큰 수 |
| usage.total_tokens | integer | 전체 토큰 수(입력 + 출력) |
| usage.completion_tokens | integer | 생성된 응답에 사용된 토큰 수 |
| usage.prompt_tokens_details | null | 프롬프트 토큰의 세부 정보 |
표. Score API - 200 OK
Error Code
| HTTP status code | ErrorCode 설명 |
|---|---|
| 400 | Bad Request |
| 422 | Validation Error |
| 500 | Internal Server Error |
표. Score API - Error Code
Example
배경색 변경
{
"id": "score-scp-aios-score",
"object": "list",
"created": 1748574112,
"model": "sds/bge-reranker-v2-m3",
"data": [
{
"index": 0,
"object": "score",
"score": 1.0
},
{
"index": 1,
"object": "score",
"score": 1.0
}
],
"usage": {
"prompt_tokens": 53,
"total_tokens": 53,
"completion_tokens": 0,
"prompt_tokens_details": null
}
}{
"id": "score-scp-aios-score",
"object": "list",
"created": 1748574112,
"model": "sds/bge-reranker-v2-m3",
"data": [
{
"index": 0,
"object": "score",
"score": 1.0
},
{
"index": 1,
"object": "score",
"score": 1.0
}
],
"usage": {
"prompt_tokens": 53,
"total_tokens": 53,
"completion_tokens": 0,
"prompt_tokens_details": null
}
}참고
Chat Completions API
POST /v1/chat/completions
개요
Chat Completions API는 OpenAI의 Completions API와 호환되며 OpenAI Python client에서 사용할 수 있습니다.
Request
Context
| Key | Type | Description | Example |
|---|---|---|---|
| Base URL | string | API 요청을 위한 AIOS URL | AIOS LLM 프라이빗 엔드포인트 |
| Request Method | string | API 요청에 사용되는 HTTP 메서드 | POST |
| Headers | object | 요청 시 필요한 헤더 정보 | { “Content-Type”: “application/json” } |
| Body Parameters | object | 요청 본문에 포함되는 파라미터 | {“model”: “meta-llama/Llama-3.3-70B-Instruct”, “messages” [{“role”: “user”, “content”: “hello”}], “stream”: true } |
표. Chat Completions API - Context
Path Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Chat Completions API - Path Parameters
Query Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Chat Completions API - Query Parameters
Body Parameters
| Name | Name Sub | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|---|
| model | - | string | ✅ | 응답 생성에 사용할 모델을 지정 | “meta-llama/Llama-3.3-70B-Instruct” | ||
| messages | role | string | ✅ | 대화 내역을 포함하는 메시지 리스트 | [ { “role” : “user” , “content” : “message” }] | ||
| frequency_penalty | - | number | ❌ | 반복되는 토큰에 대한 패널티를 조정 | 0 | -2.0 ~ 2.0 | 0.5 |
| logit_bias | - | object | ❌ | 특정 토큰의 확률을 조정(예시: { “100”: 2.0 }) | null | Key: 토큰 ID, Value: -100 ~ 100 | { “100”: 2.0 } |
| logprobs | - | boolean | ❌ | 상위 logprobs 개수의 토큰 확률을 반환 | false | true, false | true |
| max_completion_tokens | - | integer | ❌ | 최대 생성 토큰 수를 제한 | None | 0 ~ 모델 최대값 | 100 |
| max_tokens (Deprecated) | - | integer | ❌ | 최대 생성 토큰 수를 제한 | None | 0 ~ 모델 최대값 | 100 |
| n | - | integer | ❌ | 생성할 응답 개수를 지정 | 1 | 3 | |
| presence_penalty | - | number | ❌ | 기존 텍스트에 포함된 토큰에 대한 패널티를 조정 | 0 | -2.0 ~ 2.0 | 1.0 |
| seed | - | integer | ❌ | 랜덤성 제어를 위한 시드 값을 지정 | None | ||
| stop | - | string / array / null | ❌ | 특정 문자열이 나타나면 생성을 중단 | null | "\n" | |
| stream | - | boolean | ❌ | 스트리밍 방식으로 결과를 반환할지 여부 | false | true/false | true |
| stream_options | include_usage, continuous_usage_stats | object | ❌ | 스트리밍 옵션을 제어(예시: 사용량 통계 포함 여부) | null | { “include_usage”: true } | |
| temperature | - | number | ❌ | 생성 결과의 창의성을 조절(높을수록 무작위) | 1 | 0.0 ~ 1.0 | 0.7 |
| tool_choice | - | string | ❌ | 어떤 Tool이 모델에 의해 호출될지 조정
|
| ||
| tools | - | array | ❌ | 모델이 호출할수있는 Tool의 리스트
| None | ||
| top_logprobs | - | integer | ❌ | 0과 20사이의 정수 가장 확률이 높은 토큰의 수를 지정
| None | 0 ~ 20 | 3 |
| top_p | - | number | ❌ | 토큰의 샘플링 확률을 제한(높을수록 더 많은 토큰 고려) | 1 | 0.0 ~ 1.0 | 0.9 |
표. Chat Completions API - Body Parameters
Example
배경색 변경
curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/mnt/models/Meta-Llama-3.3-70B-Instruct",
"messages": [
{
"role": "assistant",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "한국의 수도는 어디입니까?"
}
]
}'curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/mnt/models/Meta-Llama-3.3-70B-Instruct",
"messages": [
{
"role": "assistant",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "한국의 수도는 어디입니까?"
}
]
}'Response
200 OK
| Name | Type | Description |
|---|---|---|
| id | string | 응답의 고유 식별자 |
| object | string | 응답 객체의 타입(예시: “chat.completion”) |
| created | integer | 생성 시각(Unix timestamp, 초 단위) |
| model | string | 사용된 모델의 이름 |
| choices | array | 생성된 응답 선택지 목록 |
| choices[].index | integer | 해당 choice의 인덱스 |
| choices[].message | object | 생성된 메시지 객체 |
| choices[].message.role | string | 메시지 작성자의 역할(예시: “assistant”) |
| choices[].message.content | string | 생성된 메시지의 실제 내용 |
| choices[].message.reasoning_content | string | 생성된 추론 메시지의 실제 내용 |
| choices[].message.tool_calls | array (optional) | 도구 호출 정보(모델/설정에 따라 포함될 수 있음) |
| choices[].finish_reason | string or null | 응답이 종료된 이유(예시: “stop”, “length” 등) |
| choices[].stop_reason | object or null | 추가 중단 이유 세부 정보 |
| choices[].logprobs | object or null | 토큰 별 로그 확률 정보(설정에 따라 포함) |
| usage | object | 토큰 사용량 통계 |
| usage.prompt_tokens | integer | 입력 프롬프트에 사용된 토큰 수 |
| usage.completion_tokens | integer | 생성된 응답에 사용된 토큰 수 |
| usage.total_tokens | integer | 전체 토큰 수(입력 + 출력) |
표. Chat Completions API - 200 OK
Error Code
| HTTP status code | ErrorCode 설명 |
|---|---|
| 400 | Bad Request |
| 422 | Validation Error |
| 500 | Internal Server Error |
표. Chat Completions API - Error Code
Example
배경색 변경
{
"id": "chatcmpl-scp-aios-chat-completions",
"object": "chat.completion",
"created": 1749702816,
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "한국의 수도는 서울입니다.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 54,
"total_tokens": 62,
"completion_tokens": 8,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}{
"id": "chatcmpl-scp-aios-chat-completions",
"object": "chat.completion",
"created": 1749702816,
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "한국의 수도는 서울입니다.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 54,
"total_tokens": 62,
"completion_tokens": 8,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}참고
Completions API
POST /v1/completions
개요
Completions API는 OpenAI의 Completions API와 호환되며 OpenAI Python client에서 사용할 수 있습니다.
Request
Context
| Key | Type | Description | Example |
|---|---|---|---|
| Base URL | string | API 요청을 위한 AIOS URL | AIOS LLM 프라이빗 엔드포인트 |
| Request Method | string | API 요청에 사용되는 HTTP 메서드 | POST |
| Headers | object | 요청 시 필요한 헤더 정보 | { “Content-Type”: “application/json” } |
| Body Parameters | object | 요청 본문에 포함되는 파라미터 | {“model”: “meta-llama/Llama-3.3-70B-Instruct”, “prompt” : “hello”, “stream”: true } |
표. Completions API - Context
Path Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Completions API - Path Parameters
Query Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Completions API - Query Parameters
Body Parameters
| Name | Name Sub | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|---|
| model | - | string | ✅ | 응답 생성에 사용할 모델을 지정 | “meta-llama/Llama-3.3-70B-Instruct” | ||
| prompt | - | array | ✅ | 사용자 입력 텍스트 | "" | ||
| echo | - | boolean | ❌ | 입력 텍스트를 출력에 포함시킬지 여부 | false | true/false | true |
| frequency_penalty | - | number | ❌ | 반복되는 토큰에 대한 패널티를 조정 | 0 | -2.0 ~ 2.0 | 0.5 |
| logit_bias | - | object | ❌ | 특정 토큰의 확률을 조정 (예시: { “100”: 2.0 }) | null | Key: 토큰 ID, Value: -100~100 | { “100”: 2.0 } |
| logprobs | - | integer | ❌ | 상위 logprobs 개수의 토큰 확률을 반환 | null | 1 ~ 5 | 5 |
| max_completion_tokens | - | integer | ❌ | 최대 생성 토큰 수를 제한 | None | 0~모델 최대 값 | 100 |
| max_tokens (Deprecated) | - | integer | ❌ | 최대 생성 토큰 수를 제한 | None | 0~모델 최대 값 | 100 |
| n | - | integer | ❌ | 생성할 응답 개수를 지정 | 1 | 3 | |
| presence_penalty | - | number | ❌ | 기존 텍스트에 포함된 토큰에 대한 패널티를 조정 | 0 | -2.0 ~ 2.0 | 1.0 |
| seed | - | integer | ❌ | 랜덤성 제어를 위한 시드값을 지정 | None | ||
| stop | - | string / array / null | ❌ | 특정 문자열이 나타나면 생성을 중단 | null | "\n" | |
| stream | - | boolean | ❌ | 스트리밍 방식으로 결과를 반환할지 여부 | false | true/false | true |
| stream_options | include_usage, continuous_usage_stats | object | ❌ | 스트리밍 옵션을 제어 (예시: 사용량 통계 포함 여부) | null | { “include_usage”: true } | |
| temperature | - | number | ❌ | 생성 결과의 창의성을 조절 (높을수록 무작위) | 1 | 0.0 ~ 1.0 | 0.7 |
| top_p | - | number | ❌ | 토큰의 샘플링 확률을 제한 (높을수록 더 많은 토큰 고려) | 1 | 0.0 ~ 1.0 | 0.9 |
표. Completions API - Body Parameters
Example
배경색 변경
curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"prompt": "한국의 수도는 어디입니까?",
"temperature": 0.7
}'curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"prompt": "한국의 수도는 어디입니까?",
"temperature": 0.7
}'Response
200 OK
| Name | Type | Description |
|---|---|---|
| id | string | 응답의 고유 식별자 |
| object | string | 응답 객체의 타입(예시: “text_completion”) |
| created | integer | 생성 시각(Unix timestamp, 초 단위) |
| model | string | 사용된 모델의 이름 |
| choices | array | 생성된 응답 선택지 목록 |
| choices[].index | number | 해당 choice의 인덱스 |
| choices[].text | string | 생성된 텍스트 객체 |
| choices[].logprobs | object | 토큰 별 로그 확률 정보(설정에 따라 포함) |
| choices[].finish_reason | string or null | 응답이 종료된 이유(예시: “stop”, “length” 등) |
| choices[].stop_reason | object or null | 추가 중단 이유 세부 정보 |
| choices[].prompt_logprobs | object or null | 입력 프롬프트 토큰별 로그 확률(널 가능) |
| usage | object | 토큰 사용량 통계 |
| usage.prompt_tokens | number | 입력 프롬프트에 사용된 토큰 수 |
| usage.total_tokens | number | 전체 토큰 수(입력 + 출력) |
| usage.completion_tokens | number | 생성된 응답에 사용된 토큰 수 |
| usage.prompt_tokens_details | object | 프롬프트 토큰 사용 세부 정보 |
표. Completions API - 200 OK
Error Code
| HTTP status code | ErrorCode 설명 |
|---|---|
| 400 | Bad Request |
| 422 | Validation Error |
| 500 | Internal Server Error |
표. Completions API - Error Code
Example
배경색 변경
{
"id": "cmpl-scp-aios-completions",
"object": "text_completion",
"created": 1749702612,
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"choices": [
{
"index": 0,
"text": " \nOur capital city is Seoul. \n\nA. 1\nB. ",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 9,
"total_tokens": 25,
"completion_tokens": 16,
"prompt_tokens_details": null
}
}{
"id": "cmpl-scp-aios-completions",
"object": "text_completion",
"created": 1749702612,
"model": "meta-llama/Meta-Llama-3.3-70B-Instruct",
"choices": [
{
"index": 0,
"text": " \nOur capital city is Seoul. \n\nA. 1\nB. ",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 9,
"total_tokens": 25,
"completion_tokens": 16,
"prompt_tokens_details": null
}
}참고
Embedding API
POST /v1/embeddings
개요
Embedding API는 텍스트를 고차원 벡터(임베딩)로 변환하여, 텍스트 간 유사도 계산, 클러스터링, 검색 등 다양한 자연어 처리(NLP) 작업에 활용할 수 있습니다.
Request
Context
| Key | Type | Description | Example |
|---|---|---|---|
| Base URL | string | API 요청을 위한 AIOS URL | application/json |
| Request Method | string | API 요청에 사용되는 HTTP 메서드 | POST |
| Headers | object | 요청 시 필요한 헤더 정보 | { “accept”: “application/json”, “Content-Type”: “application/json” } |
| Body Parameters | object | 요청 본문에 포함되는 파라미터 | { “model”: “sds/bge-m3”, “input”: “What is the capital of France?”} |
표. Embedding API - Context
Path Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Embedding API - Path Parameters
Query Parameters
| Name | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|
| None |
표. Embedding API - Query Parameters
Body Parameters
| Name | Name Sub | type | Required | Description | Default value | Boundary value | Example |
|---|---|---|---|---|---|---|---|
| model | - | string | ✅ | 응답 생성에 사용할 모델을 지정 | “sds/bge-reranker-v2-m3” | ||
| input | - | array<string | ✅ | 사용자의 검색 질의 또는 질문 | “What is the capital of France?" | ||
| encoding_format | - | string | ❌ | 임베딩을 반환할 형식을 지정 | “float” | “float”, “base64” | [0.01319122314453125,0.057220458984375, … (생략) |
| truncate_prompt_tokens | - | integer | ❌ | 입력 토큰 수를 제한 | > 0 | 100 |
표. Embedding API - Body Parameters
Example
배경색 변경
curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/embedding \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-m3",
"input": "What is the capital of France?",
"encoding_format": "float"
}'curl -X "POST" \
{AIOS LLM 프라이빗 엔드포인트}/v1/embedding \
-H "Content-Type: application/json" \
-d '{
"model": "sds/bge-m3",
"input": "What is the capital of France?",
"encoding_format": "float"
}'Response
200 OK
| Name | Type | Description |
|---|---|---|
| id | string | 응답의 고유 식별자 |
| object | string | 응답 객체의 타입(예시: “list” ) |
| created | number | 생성 시각(Unix timestamp, 초 단위) |
| model | string | 사용된 모델의 이름 |
| data | array | 임베딩 결과를 담은 객체 배열 |
| data.index | number | 입력 텍스트의 순서 인덱스 (예시: 입력 텍스트가 여러 개일 경우 순서를 나타냄) |
| data.object | string | 데이터 항목 타입 |
| data.embedding | array | 입력 텍스트의 임베딩 벡터 값 (sds-bge-m3는 1024 차원의 float 배열로 구성) |
| usage | object | 토큰 사용량 통계 |
| usage.prompt_tokens | number | 입력 프롬프트에 사용된 토큰 수 |
| usage.total_tokens | number | 전체 토큰 수(입력 + 출력) |
| usage.completion_tokens | number | 생성된 응답에 사용된 토큰 수 |
| usage.prompt_tokens_details | object | 프롬프트 토큰의 세부 정보 |
표. Embedding API - 200 OK
Error Code
| HTTP status code | ErrorCode 설명 |
|---|---|
| 400 | Bad Request |
| 422 | Validation Error |
| 500 | Internal Server Error |
표. Embedding API - Error Code
Example
배경색 변경
{
"id":"embd-scp-aios-embeddings",
"object":"list","created":1749035024,
"model":"sds/bge-m3",
"data":[
{
"index":0,
"object":"embedding",
"embedding":
[0.01319122314453125,0.057220458984375,-0.028533935546875,-0.0008697509765625,-0.01422119140625,0.033416748046875,-0.0062408447265625,-0.04364013671875,-0.004497528076171875,0.0008072853088378906,-0.0193328857421875,0.041168212890625,-0.019317626953125,-0.0188751220703125,-0.047088623046875,
-0 ....(생략)
-0.05706787109375,-0.0147705078125]
}
],
"usage":
{
"prompt_tokens":9,
"total_tokens":9,
"completion_tokens":0,
"prompt_tokens_details":null
}
}{
"id":"embd-scp-aios-embeddings",
"object":"list","created":1749035024,
"model":"sds/bge-m3",
"data":[
{
"index":0,
"object":"embedding",
"embedding":
[0.01319122314453125,0.057220458984375,-0.028533935546875,-0.0008697509765625,-0.01422119140625,0.033416748046875,-0.0062408447265625,-0.04364013671875,-0.004497528076171875,0.0008072853088378906,-0.0193328857421875,0.041168212890625,-0.019317626953125,-0.0188751220703125,-0.047088623046875,
-0 ....(생략)
-0.05706787109375,-0.0147705078125]
}
],
"usage":
{
"prompt_tokens":9,
"total_tokens":9,
"completion_tokens":0,
"prompt_tokens_details":null
}
}참고
1.3.2 - Tutorial
Tutorial
AIOS를 활용해볼 수 있는 Tutorial를 제공합니다.
| 구분 | 설명 |
|---|---|
| Chat Playground | 웹 기반 Playground을 만들고 활용하는 방법
|
| RAG | RAG 기반의 PR리뷰 보조 챗봇 만들기
|
| Autogen | Autogen을 활용한 에이전트 애플리케이션 만들기
|
표. AIOS Tutorial 목록
1.3.2.1 - Chat Playground
목표
이 튜토리얼에서는 SCP for Enterprise 환경에서 Streamlit을 사용하여 AIOS가 제공하는 여러 AI 모델의 API를 쉽게 시험해볼 수 있는 웹 기반 Playground를 만들고 활용하는 방법을 소개합니다.
환경
이 튜토리얼을 진행하려면 아래와 같은 환경이 준비되어 있어야 합니다.
시스템 환경
- Python 3.10 +
- pip
설치 필요 패키지
배경색 변경
pip install streamlitpip install streamlit참고
Streamlit
Python 기반의 오픈소스 웹 애플리케이션 프레임워크로, 데이터 사이언스, 머신러닝, 데이터 분석 결과를 시각적으로 표현하고 공유하기에 매우 적합한 도구입니다. 복잡한 웹 개발 지식 없이도 코드를 몇 줄만 작성해도 웹 인터페이스를 빠르게 만들 수 있습니다.
Python 기반의 오픈소스 웹 애플리케이션 프레임워크로, 데이터 사이언스, 머신러닝, 데이터 분석 결과를 시각적으로 표현하고 공유하기에 매우 적합한 도구입니다. 복잡한 웹 개발 지식 없이도 코드를 몇 줄만 작성해도 웹 인터페이스를 빠르게 만들 수 있습니다.
구현
사전 점검
애플리케이션이 구동되는 환경에서 curl로 모델 호출이 정상적인지 점검합니다. 여기서 AIOS_LLM_Private_Endpoint 는 LLM 이용 가이드를 참고해주세요.
- 예시 : {AIOS LLM 프라이빗 엔드포인트}/{API}
배경색 변경
curl -H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-3.3-70B-Instruct"
, "prompt" : "Hello, I am jihye, who are you"
, "temperature": 0
, "max_tokens": 100
, "stream": false}' -L AIOS_LLM_Private_Endpointcurl -H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-3.3-70B-Instruct"
, "prompt" : "Hello, I am jihye, who are you"
, "temperature": 0
, "max_tokens": 100
, "stream": false}' -L AIOS_LLM_Private_Endpointchoices의 text 필드에 모델의 답변이 포함되어 있는 것을 확인할 수 있습니다.
{"id":"cmpl-4ac698a99c014d758300a3ec5583d73b","object":"text_completion","created":1750140201,"model":"meta-llama/Llama-3.3-70B-Instruct","choices":[{"index":0,"text":"?\nI am a Korean student who is studying English.\nI am interested in learning about different cultures and making friends from around the world.\nI like to watch movies, listen to music, and read books in my free time.\nI am looking forward to chatting with you and learning more about your culture and way of life.\nNice to meet you, jihye! I'm happy to chat with you and learn more about Korean culture. What kind of movies, music, and books do you enjoy? Do","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":11,"total_tokens":111,"completion_tokens":100}}
프로젝트 구조
chat-playground
├── app.py # streamlit 메인 웹 앱 파일
├── endpoints.json # AIOS 모델의 호출 타입 정의
├── img
│ └── aios.png
└── models.json # AIOS 모델 목록
Chat Playground 코드
참고
- models.json, endpoints.json 파일이 존재하고 적절한 형식으로 구성되어야 합니다. 아래 코드를 참고해주세요.
- 코드 내 BASE_URL 은 LLM 이용 가이드를 참고하여 AIOS LLM Private Endpoint 주소로 수정해야 합니다.
- 이 Playground는 단발성 요청 기반의 구조로 설계되어 있어, 사용자가 입력값을 제공하고 버튼을 눌러 한번의 요청을 보내고 결과를 확인하는 방식입니다. 이는 복잡한 세션 관리 없이 빠르게 테스트하고 응답을 확인할 수 있습니다.
- 사이드바에 구성된 Model, Type, Temperature, Max Tokens 의 파라미터는 st.sidebar를 통해 구성된 인터페이스이며, 필요에 따라 자유롭게 기능을 확장하거나 수정할 수 있습니다.
- st.file_uploader()로 업로드한 이미지(파일)은 서버 메모리상의 일시적인 BytesIO 객체로 존재하고, 자동으로 디스크에 저장되지 않습니다.
app.py
streamlit 메인 웹 앱 파일입니다. 여기서 BASE_URL인 AIOS_LLM_Private_Endpoint는 LLM 이용 가이드를 참고해주세요.
배경색 변경
import streamlit as st
import base64
import json
import requests
from urllib.parse import urljoin
BASE_URL = "AIOS_LLM_Private_Endpoint"
# ===== 설정 =====
st.set_page_config(page_title="AIOS Chat Playground", layout="wide")
st.title("🤖 AIOS Chat Playground")
# ===== 공통 함수 =====
def load_models():
with open("models.json", "r") as f:
return json.load(f)
def load_endpoints():
with open("endpoints.json", "r") as f:
return json.load(f)
models = load_models()
endpoints_config = load_endpoints()
# ===== 사이드바 설정 =====
st.sidebar.title('Hello!')
st.sidebar.image("img/aios.png")
st.sidebar.header("⚙️ Setting")
model = st.sidebar.selectbox("Model", models)
endpoint_labels = [ep["label"] for ep in endpoints_config]
endpoint_label = st.sidebar.selectbox("Type", endpoint_labels)
selected_endpoint = next(ep for ep in endpoints_config if ep["label"] == endpoint_label)
temperature = st.sidebar.slider("🔥 Temperature", 0.0, 1.0, 0.7)
max_tokens = st.sidebar.number_input("🧮 Max Tokens", min_value=1, max_value=5000, value=100)
base_url = BASE_URL
path = selected_endpoint["path"]
endpoint_type = selected_endpoint["type"]
api_style = selected_endpoint.get("style", "openai") # openai or cohere
# ===== 입력 UI =====
prompt = ""
docs = []
image_base64 = None
if endpoint_type == "image":
prompt = st.text_area("✍️ Enter your question:", "Explain this image.")
uploaded_image = st.file_uploader("🖼️ Upload an image", type=["png", "jpg", "jpeg"])
if uploaded_image:
st.image(uploaded_image, caption="Uploaded image", use_container_width=300)
image_bytes = uploaded_image.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
elif endpoint_type == "rerank":
prompt = st.text_area("✍️ Enter your query:", "What is the capital of France?")
raw_docs = st.text_area("📄 Documents (one per line)", "The capital of France is Paris.\nFrance capital city is known for the Eiffel Tower.\nParis is located in the north-central part of France.")
docs = raw_docs.strip().splitlines()
elif endpoint_type == "reasoning":
prompt = st.text_area("✍️ Enter prompt:", "9.11 and 9.8, which is greater?")
elif endpoint_type == "embedding":
prompt = st.text_area("✍️ Enter prompt:", "What is the capital of France?")
else:
prompt = st.text_area("✍️ Enter prompt:", "Hello, who are you?")
uploaded_image = st.file_uploader("🖼️ Upload an image (Optional)", type=["png", "jpg", "jpeg"])
if uploaded_image:
image_bytes = uploaded_image.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
# ===== 호출 버튼 =====
if st.button("🚀 Invoke model"):
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer EMPTY_KEY"
}
try:
if endpoint_type == "chat":
url = urljoin(base_url, "v1/chat/completions")
payload = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "completion":
url = urljoin(base_url, "v1/completions")
payload = {
"model": model,
"prompt": prompt,
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "embedding":
url = urljoin(base_url, "v1/embeddings")
payload = {
"model": model,
"input": prompt
}
elif endpoint_type == "reasoning":
url = urljoin(BASE_URL, "v1/chat/completions")
payload = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "image":
url = urljoin(base_url, "v1/chat/completions")
if not image_base64:
st.warning("🖼️ Upload an image")
st.stop()
payload = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_base64}"}}
]
}
]
}
elif endpoint_type == "rerank":
url = urljoin(base_url, "v2/rerank")
payload = {
"model": model,
"query": prompt,
"documents": docs,
"top_n": len(docs)
}
else:
st.error("❌ Unknown endpoint type")
st.stop()
st.expander("📤 Request payload").code(json.dumps(payload, indent=2), language="json")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
res = response.json()
# ===== 응답 파싱 =====
if endpoint_type == "chat" or endpoint_type == "image":
output = res["choices"][0]["message"]["content"]
elif endpoint_type == "completion":
output = res["choices"][0]["text"]
elif endpoint_type == "embedding":
vec = res["data"][0]["embedding"]
output = f"🔢 Vector dimensions: {len(vec)}"
st.expander("📐 Vector preview").code(vec[:20])
elif endpoint_type == "rerank":
results = res["results"]
output = "\n\n".join(
[f"{i+1}. {r['document']['text']} (score: {r['relevance_score']:.3f})" for i, r in enumerate(results)]
)
elif endpoint_type == "reasoning":
message = res.get("choices", [{}])[0].get("message", {})
reasoning = message.get("reasoning_content", "❌ No reasoning_content")
content = message.get("content", "❌ No content")
output = f"""📘 <b>response:</b><br>{content}<br><br>🧠 <b>Reasoning:</b><br>{reasoning}"""
st.success("✅ Model response:")
st.markdown(f"<div style='padding:1rem;background:#f0f0f0;border-radius:8px'>{output}</div>", unsafe_allow_html=True)
st.expander("📦 View full response").json(res)
except requests.RequestException as e:
st.error("❌ Request failed")
st.code(str(e))import streamlit as st
import base64
import json
import requests
from urllib.parse import urljoin
BASE_URL = "AIOS_LLM_Private_Endpoint"
# ===== 설정 =====
st.set_page_config(page_title="AIOS Chat Playground", layout="wide")
st.title("🤖 AIOS Chat Playground")
# ===== 공통 함수 =====
def load_models():
with open("models.json", "r") as f:
return json.load(f)
def load_endpoints():
with open("endpoints.json", "r") as f:
return json.load(f)
models = load_models()
endpoints_config = load_endpoints()
# ===== 사이드바 설정 =====
st.sidebar.title('Hello!')
st.sidebar.image("img/aios.png")
st.sidebar.header("⚙️ Setting")
model = st.sidebar.selectbox("Model", models)
endpoint_labels = [ep["label"] for ep in endpoints_config]
endpoint_label = st.sidebar.selectbox("Type", endpoint_labels)
selected_endpoint = next(ep for ep in endpoints_config if ep["label"] == endpoint_label)
temperature = st.sidebar.slider("🔥 Temperature", 0.0, 1.0, 0.7)
max_tokens = st.sidebar.number_input("🧮 Max Tokens", min_value=1, max_value=5000, value=100)
base_url = BASE_URL
path = selected_endpoint["path"]
endpoint_type = selected_endpoint["type"]
api_style = selected_endpoint.get("style", "openai") # openai or cohere
# ===== 입력 UI =====
prompt = ""
docs = []
image_base64 = None
if endpoint_type == "image":
prompt = st.text_area("✍️ Enter your question:", "Explain this image.")
uploaded_image = st.file_uploader("🖼️ Upload an image", type=["png", "jpg", "jpeg"])
if uploaded_image:
st.image(uploaded_image, caption="Uploaded image", use_container_width=300)
image_bytes = uploaded_image.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
elif endpoint_type == "rerank":
prompt = st.text_area("✍️ Enter your query:", "What is the capital of France?")
raw_docs = st.text_area("📄 Documents (one per line)", "The capital of France is Paris.\nFrance capital city is known for the Eiffel Tower.\nParis is located in the north-central part of France.")
docs = raw_docs.strip().splitlines()
elif endpoint_type == "reasoning":
prompt = st.text_area("✍️ Enter prompt:", "9.11 and 9.8, which is greater?")
elif endpoint_type == "embedding":
prompt = st.text_area("✍️ Enter prompt:", "What is the capital of France?")
else:
prompt = st.text_area("✍️ Enter prompt:", "Hello, who are you?")
uploaded_image = st.file_uploader("🖼️ Upload an image (Optional)", type=["png", "jpg", "jpeg"])
if uploaded_image:
image_bytes = uploaded_image.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
# ===== 호출 버튼 =====
if st.button("🚀 Invoke model"):
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer EMPTY_KEY"
}
try:
if endpoint_type == "chat":
url = urljoin(base_url, "v1/chat/completions")
payload = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "completion":
url = urljoin(base_url, "v1/completions")
payload = {
"model": model,
"prompt": prompt,
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "embedding":
url = urljoin(base_url, "v1/embeddings")
payload = {
"model": model,
"input": prompt
}
elif endpoint_type == "reasoning":
url = urljoin(BASE_URL, "v1/chat/completions")
payload = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": temperature,
"max_tokens": max_tokens
}
elif endpoint_type == "image":
url = urljoin(base_url, "v1/chat/completions")
if not image_base64:
st.warning("🖼️ Upload an image")
st.stop()
payload = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_base64}"}}
]
}
]
}
elif endpoint_type == "rerank":
url = urljoin(base_url, "v2/rerank")
payload = {
"model": model,
"query": prompt,
"documents": docs,
"top_n": len(docs)
}
else:
st.error("❌ Unknown endpoint type")
st.stop()
st.expander("📤 Request payload").code(json.dumps(payload, indent=2), language="json")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
res = response.json()
# ===== 응답 파싱 =====
if endpoint_type == "chat" or endpoint_type == "image":
output = res["choices"][0]["message"]["content"]
elif endpoint_type == "completion":
output = res["choices"][0]["text"]
elif endpoint_type == "embedding":
vec = res["data"][0]["embedding"]
output = f"🔢 Vector dimensions: {len(vec)}"
st.expander("📐 Vector preview").code(vec[:20])
elif endpoint_type == "rerank":
results = res["results"]
output = "\n\n".join(
[f"{i+1}. {r['document']['text']} (score: {r['relevance_score']:.3f})" for i, r in enumerate(results)]
)
elif endpoint_type == "reasoning":
message = res.get("choices", [{}])[0].get("message", {})
reasoning = message.get("reasoning_content", "❌ No reasoning_content")
content = message.get("content", "❌ No content")
output = f"""📘 <b>response:</b><br>{content}<br><br>🧠 <b>Reasoning:</b><br>{reasoning}"""
st.success("✅ Model response:")
st.markdown(f"<div style='padding:1rem;background:#f0f0f0;border-radius:8px'>{output}</div>", unsafe_allow_html=True)
st.expander("📦 View full response").json(res)
except requests.RequestException as e:
st.error("❌ Request failed")
st.code(str(e))models.json
AIOS 모델 목록입니다. LLM 이용 가이드를 참고하여 이용할 모델을 설정합니다.
배경색 변경
[
"meta-llama/Llama-3.3-70B-Instruct",
"qwen/Qwen3-30B-A3B",
"qwen/QwQ-32B",
"google/gemma-3-27b-it",
"meta-llama/Llama-4-Scout",
"meta-llama/Llama-Guard-4-12B",
"sds/bge-m3",
"sds/bge-reranker-v2-m3"
][
"meta-llama/Llama-3.3-70B-Instruct",
"qwen/Qwen3-30B-A3B",
"qwen/QwQ-32B",
"google/gemma-3-27b-it",
"meta-llama/Llama-4-Scout",
"meta-llama/Llama-Guard-4-12B",
"sds/bge-m3",
"sds/bge-reranker-v2-m3"
]endpoints.json
AIOS 모델의 호출 타입이 정의되어 있습니다. 타입에 따라 입력 화면 및 결과가 다르게 출력됩니다.
배경색 변경
[
{
"label": "Chat Model",
"path": "/v1/chat/completions",
"type": "chat"
},
{
"label": "Completion Model",
"path": "/v1/completions",
"type": "completion"
},
{
"label": "Embedding Model",
"path": "/v1/embeddings",
"type": "embedding"
},
{
"label": "Image Chat Model",
"path": "/v1/chat/completions",
"type": "image"
},
{
"label": "Rerank Model",
"path": "/v2/rerank",
"type": "rerank"
},
{
"label": "Reasoning Model",
"path": "/v1/chat/completions",
"type": "reasoning"
}
][
{
"label": "Chat Model",
"path": "/v1/chat/completions",
"type": "chat"
},
{
"label": "Completion Model",
"path": "/v1/completions",
"type": "completion"
},
{
"label": "Embedding Model",
"path": "/v1/embeddings",
"type": "embedding"
},
{
"label": "Image Chat Model",
"path": "/v1/chat/completions",
"type": "image"
},
{
"label": "Rerank Model",
"path": "/v2/rerank",
"type": "rerank"
},
{
"label": "Reasoning Model",
"path": "/v1/chat/completions",
"type": "reasoning"
}
]Playground 사용 방법
이 문서에서는 Playground의 두 가지 실행 방법을 다룹니다.
Virtual Server에서 실행 하기
1. Virtual Server에서 Streamlit 실행
배경색 변경
streamlit run app.py --server.port 8501 --server.address 0.0.0.0streamlit run app.py --server.port 8501 --server.address 0.0.0.0You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:8501
브라우저에서 http://{your_server_ip}:8501 또는 서버 SSH 터널링 설정 후 http://localhost:8501 로 접속합니다. SSH 터널링은 아래를 참고하세요.
2. 로컬PC에서 터널링으로 Virtual Server접속 (http://localhost:8501 로 접속하는 경우)
배경색 변경
ssh -i {your_pemkey.pem} -L 8501:localhost:8501 ubuntu@{your_server_ip}ssh -i {your_pemkey.pem} -L 8501:localhost:8501 ubuntu@{your_server_ip}SCP Kubernetes Engine에서 실행 하기
1. Deployment와 Service 기동
다음의 YAML을 실행하여 Deployment와 Service를 기동합니다. Chat Playground 튜토리얼 실행을 위해 코드와 파이썬 라이브러리 파일이 패키징된 컨테이너 이미지를 제공합니다.
참고
이미지 주소 : aios-zcavifox.scr.private.kr-west1.e.samsungsdscloud.com/tutorial/chat-playground:v1.0
배경색 변경
apiVersion: apps/v1
kind: Deployment
metadata:
name: streamlit-deployment
spec:
replicas: 1
selector:
matchLabels:
app: streamlit
template:
metadata:
labels:
app: streamlit
spec:
containers:
- name: streamlit-app
image: aios-zcavifox.scr.private.kr-west1.e.samsungsdscloud.com/tutorial/chat-playground:v1.0
ports:
- containerPort: 8501
---
apiVersion: v1
kind: Service
metadata:
name: streamlit-service
spec:
type: NodePort
selector:
app: streamlit
ports:
- protocol: TCP
port: 80
targetPort: 8501
nodePort: 30081apiVersion: apps/v1
kind: Deployment
metadata:
name: streamlit-deployment
spec:
replicas: 1
selector:
matchLabels:
app: streamlit
template:
metadata:
labels:
app: streamlit
spec:
containers:
- name: streamlit-app
image: aios-zcavifox.scr.private.kr-west1.e.samsungsdscloud.com/tutorial/chat-playground:v1.0
ports:
- containerPort: 8501
---
apiVersion: v1
kind: Service
metadata:
name: streamlit-service
spec:
type: NodePort
selector:
app: streamlit
ports:
- protocol: TCP
port: 80
targetPort: 8501
nodePort: 30081배경색 변경
kubectl apply -f run.yamlkubectl apply -f run.yaml$ kubectl get pod
NAME READY STATUS RESTARTS AGE
streamlit-deployment-8bfcd5959-6xpx9 1/1 Running 0 17s
$ kubectl logs streamlit-deployment-8bfcd5959-6xpx9
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:8501
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 172.20.0.1 <none> 443/TCP 46h
streamlit-service NodePort 172.20.95.192 <none> 80:30081/TCP 130m
브라우저에서 http://{worker_node_ip}:30081 또는 서버 SSH 터널링 설정 후 http://localhost:8501 로 접속합니다. SSH 터널링은 아래를 참고하세요.
2. 로컬PC에서 터널링으로 워커노드 접속 (http://localhost:8501 로 접속하는 경우)
배경색 변경
ssh -i {your_pemkey.pem} -L 8501:{worker_node_ip}:30081 ubuntu@{worker_node_ip}ssh -i {your_pemkey.pem} -L 8501:{worker_node_ip}:30081 ubuntu@{worker_node_ip}3. 로컬PC에서 터널링으로 중계서버 통하여 워커노드 접속 (http://localhost:8501 로 접속하는 경우)
배경색 변경
ssh -i {your_pemkey.pem} -L 8501:{worker_node_ip}:30081 ubuntu@{your_server_ip}ssh -i {your_pemkey.pem} -L 8501:{worker_node_ip}:30081 ubuntu@{your_server_ip}사용 예시
주요 화면 구성

| 항목 | 설명 | |
|---|---|---|
| 1 | Model | models.json 파일에 설정된 호출 가능한 모델 목록입니다. |
| 2 | Endpoint type | endpoints.json 파일에 설정된 모델 호출 형식으로 모델에 맞게 선택해야 합니다. |
| 3 | Temperature | 모델 출력의 “랜덤성” 또는 “창의성"정도를 조절하는 파라미터입니다. 이 튜토리얼에서는 0.00 ~ 1.00 범위로 지정되어 있습니다.
|
| 4 | Max Tokens | 출력 길이 제한 파라미터로 응답 텍스트에서 생성 가능한 최대 토큰 수를 설정합니다. 이 튜토리얼에서는 1 ~ 5000 범위로 지정되어 있습니다. |
| 5 | 입력 영역 | 엔드포인트 유형별로 prompt, 이미지 등 받는 방식이 달라집니다.
|
표. 주요 화면 구성
Chat 모델 호출하기

Image 모델 호출하기

Reasoning 모델 호출하기

마무리
이 튜토리얼을 통해 AIOS에서 제공하는 다양한 AI모델 API를 손쉽게 테스트 할 수 있는 Playground UI를 직접 구축하고 활용하는 방법을 익히셨기를 바랍니다. 실제 서비스 목적에 따라 원하는 모델과 엔드포인트 구조에 맞춰 유연하게 커스터마이징해서 사용하실 수 있습니다.
참고 링크
1.3.2.2 - RAG
목표
AIOS에서 제공하는 AI모델을 활용해 GIT 로그, PR 설명, 리뷰 코멘트 등을 벡터화하고, 이를 기반으로 RAG 기반의 PR리뷰 보조 챗봇을 구현합니다.
참고
RAG
RAG(Retrieval-Augmented Generation, 검색 증강 생성)는 대규모 언어 모델(LLM)이 응답을 생성하기 전에 외부의 신뢰할 수 있는 지식 베이스나 데이터베이스에서 관련 정보를 검색(Retrieval)하고, 그 검색된 정보를 바탕으로 답변을 생성(Generation)하는 자연어 처리 기술입니다. 기존 LLM은 훈련된 데이터에만 의존하기 때문에 최신 정보나 특정 도메인에 특화된 지식을 반영하는 데 한계가 있습니다. RAG는 이 한계를 보완하여, 사용자의 질문에 대해 먼저 관련 문서나 데이터를 벡터 검색 등의 방법으로 찾아내고, 그 정보를 활용해 더 정확하고 맥락에 맞는 답변을 생성합니다.
RAG(Retrieval-Augmented Generation, 검색 증강 생성)는 대규모 언어 모델(LLM)이 응답을 생성하기 전에 외부의 신뢰할 수 있는 지식 베이스나 데이터베이스에서 관련 정보를 검색(Retrieval)하고, 그 검색된 정보를 바탕으로 답변을 생성(Generation)하는 자연어 처리 기술입니다. 기존 LLM은 훈련된 데이터에만 의존하기 때문에 최신 정보나 특정 도메인에 특화된 지식을 반영하는 데 한계가 있습니다. RAG는 이 한계를 보완하여, 사용자의 질문에 대해 먼저 관련 문서나 데이터를 벡터 검색 등의 방법으로 찾아내고, 그 정보를 활용해 더 정확하고 맥락에 맞는 답변을 생성합니다.
환경
이 튜토리얼을 진행하려면 아래와 같은 환경이 준비되어 있어야 합니다.
시스템 환경
- Python 3.10 +
- pip
설치 필요 패키지
배경색 변경
pip install streamlit
pip install opensearch-pypip install streamlit
pip install opensearch-py사전 준비 사항
- 사용자 지식 베이스나 데이터베이스
참고
- 이 튜토리얼에서는 VM 내부에 OpenSearch를 구성하여 벡터 데이터베이스로 활용하였습니다.
- 사용자의 기존 저장소를 사용하거나, SCP의 Search Engine 상품을 활용 할 수 있습니다.
시스템 아키텍처
GitHub PR 데이터를 수집하여 RAG 기반 QA 시스템을 구성하고, AIOS 모델을 활용해 임베딩 및 응답 생성을 수행하는 전체 흐름을 보여줍니다.

RAG Flow
- Git 저장소에서 PR 데이터를 수집하여 pr_dataset.jsonl 생성
- RAG 입력에 적합하도록 텍스트 정제 → rag_ready.jsonl
- AIOS Embedding 모델을 통해 벡터 생성 후 rag_embedded.jsonl 파일로 저장
- 해당 벡터 파일을 OpenSearch에 업로드하여 검색 가능한 형태로 구성
RAG QA Application Flow
- 사용자의 질의(예: “이 PR을 분석해줘.")를 임베딩하여 검색 질의로 변환
- OpenSearch에서 KNN 검색 또는 AIOS Embedding 모델(score API) 호출을 통해 연관 문서 추출
- 추출된 문서 기반으로 프롬프트를 구성하고 AIOS Chat 모델로 전송
- 응답을 생성하여 최종 결과 출력
구현
참고
- 이 튜토리얼에서는 kubeflow 프로젝트 github 을 활용하였습니다.
- 벡터 데이터베이스 데이터는 일회성으로 구성하였으며, 실제 서비스 시에는 실시간 연동 등으로 커스터마이징하여 사용하실 수 있습니다.
프로젝트 구조
rag-tutorial
├── app.py # streamlit 메인 웹 앱 파일
├── generate_pr_dateset_from_branch.py # 1. Github PR 데이터 수집
├── generate_rag_data_from_pr_dataset.py # 2. RAG 입력용 텍스트 구성 (RAG 입력에 적합하도록 요약하여 텍스트 정제)
├── embed_prs.py # 3. RAG 입력용 텍스트 구성 (AIOS Embedding 모델을 통해 벡터 생성)
└── upload_rag_documnets.py # 4. OpenSearch에 업로드
Github PR 데이터 수집
Git 저장소에서 PR 데이터를 수집하여 pr_dataset.jsonl 생성합니다.
참고
- 아래 코드는 git 디렉토리 내에서 실행합니다.
- 추가 PR 병합 기록이 없거나, PR 병합이 rebase 방식 또는 squash-merge 방식으로 이루어져 정규 merge 커밋이 생성되지 않으면 데이터 수집이 되지 않습니다.
- 데이터 수집 시 각 커밋의 diff 항목은 최대 3000자로 제한하였습니다. 실제 시스템을 구성할 때는 효율적인 검색과 응답 생성을 위해, 내용의 길이나 구조에 따라 적절한 청킹(chunking) 작업이 추가적으로 필요합니다.
$ git branch
* (HEAD detached at v1.9.1)
master
$ python3 generate_pr_dateset_from_branch.py
🔍 Searching for merged PRs...
✅ Generated pr_dataset.jsonl with 43 merged PRs.
$ head -n 1 pr_dataset.jsonl | jq
{
"merge_sha": "167e162ef7dffc033ddc82e55b0a108db27fc340",
"author": "Ricardo Martinelli de Oliveira",
"date": "Tue Mar 5 11:46:36 2024 -0300",
"title": "Merge pull request #7461 from rimolive/kf-1.9",
"pr_id": null,
"commits": [
{
"sha": "68e4d10bbf976bb89810b4e16e8b765a2a0e68b7",
"author": "Ricardo Martinelli de Oliveira",
"message": "Update ROADMAP.md",
"date": "Mon Feb 19 18:51:40 2024 -0300",
"files": [
"ROADMAP.md"
],
"diff": "commit 68e4d10bbf976bb89810b4e16e8b765a2a0e68b7\nAuthor: Ricardo Martinelli de Oliveira <rmartine@redhat.com>\nDate: Mon Feb 19 18:51:40 2024 -0300\n\n Update ROADMAP.md\n \n Co-authored-by: Tommy Li <Tommy.chaoping.li@ibm.com>\n\ndiff --git a/ROADMAP.md b/ROADMAP.md\nindex 35021954..cfd39558 100644\n--- a/ROADMAP.md\n+++ b/ROADMAP.md\n@@ -8,7 +8,7 @@ The Kubeflow Community plans to deliver its v1.9 release in Jul 2024 per this [t\n * CNCF Transition\n * LLM APIs\n * New component: Model Registry\n-* Kubeflow Pipelines and kfp-tekton merged in a single GitHub repository\n+* Kubeflow Pipelines and kfp-tekton V2 merged in a single GitHub repository\n \n ### Detailed features, bug fixes and enhancements are identified in the Working Group Roadmaps and Tracking Issues:\n * [Training Operators](https://github.com/kubeflow/training-operator/issues/1994)"
},
{
"sha": "5c3404782fa2700f8547b37132ff7ab2d1ed99fe",
"author": "Ricardo M. Oliveira",
"message": "Add Kubeflow 1.9 release roadmap",
"date": "Mon Feb 5 14:43:45 2024 -0300",
"files": [
"ROADMAP.md"
],
"diff": "commit 5c3404782fa2700f8547b37132ff7ab2d1ed99fe\nAuthor: Ricardo M. Oliveira <rmartine@redhat.com>\nDate: Mon Feb 5 14:43:45 2024 -0300\n\n Add Kubeflow 1.9 release roadmap\n \n Signed-off-by: Ricardo M. Oliveira <rmartine@redhat.com>\n\ndiff --git a/ROADMAP.md b/ROADMAP.md\nindex de3c8951..35021954 100644\n--- a/ROADMAP.md\n+++ b/ROADMAP.md\n@@ -1,6 +1,26 @@\n # Kubeflow Roadmap\n \n-## Kubeflow 1.8 Release, Planned for release: Oct 2023\n+## Kubeflow 1.9 Release, Planned for release: Jul 2024\n+The Kubeflow Community plans to deliver its v1.9 release in Jul 2024 per this [timeline](https://github.com/kubeflow/community/blob/master/releases/release-1.9/README.md#timeline). The high level deliverables are tracked in the [v1.9 Release](https://github.com/orgs/kubeflow/projects/61) Github project board. The v1.9 release process will be managed by the v1.9 [release team](https://github.com/kubeflow/community/blob/master/releases/release-1.9/release-team.md) using the best practices in the [Release Handbook](https://github.com/kubeflow/community/blob/master/releases/handbook.md).\n+\n+### Themes\n+* Kubernetes 1.29 support\n+* CNCF Transition\n+* LLM APIs\n+* New component: Model Registry\n+* Kubeflow Pipelines and kfp-tekton merged in a single GitHub repository\n+\n+### Detailed features, bug fixes and enhancements are identified in the Working Group Roadmaps and Tracking Issues:\n+* [Training Operators](https://github.com/kubeflow/training-operator/issues/1994)\n+* [KServe](https://github.com/orgs/kserve/projects/12)\n+* [Katib](https://github.com/kubeflow/katib/issues/2255)\n+* [Kubeflow Pipelines](https://github.com/kubeflow/pipelines/issues/10402)\n+* [Notebooks](https://github.com/kubeflow/kubeflow/issues/7459)\n+* [Manifests](https://github.com/kubeflow/manifests/issues/2592)\n+* [Security](https://github.com/kubeflow/manifests/issues/2598)\n+* [Model Registry](https://github.com/kubeflow/model-registry/issues/3)\n+\n+## Kubeflow 1.8 Release, Delivered: Nov 2023\n The Kubeflow Community plans to deliver its v1.8 release in Oct 2023 per this [timeline](https://github.com/kubeflow/community/tree/master/releases/release-1.8#timeline). The high level deliverables are tracked in the [v1.8 Release](https://github.com/orgs/kubeflow/projects/58/) Github project board. The v1.8 release process will be managed by the v1.8 [release team](https://github.com/kubeflow/community/blob/a956b3f6f15c49f928e37eaafec40d7f73ee1d5b/releases/release-team.md) using the best practices in the [Release Handbook](https://github.com/kubeflow/community/blob/master/releases/handbook.md).\n \n ### Themes"
}
]
}
generate_pr_dateset_from_branch.py
배경색 변경
import subprocess
import json
def run(cmd):
return subprocess.check_output(cmd, shell=True, text=True).strip()
def extract_pr_commits(merge_sha):
try:
parent1 = run(f"git rev-parse {merge_sha}^1")
parent2 = run(f"git rev-parse {merge_sha}^2")
except subprocess.CalledProcessError:
return []
try:
lines = run(f"git log {parent1}..{parent2} --pretty=format:'%H|%an|%s|%ad'").splitlines()
except subprocess.CalledProcessError:
return []
commits = []
for line in lines:
try:
sha, author, msg, date = line.split("|", 3)
files = run(f"git show --pretty=format:'' --name-only {sha}").splitlines()
diff = run(f"git show {sha}")
commits.append({
"sha": sha,
"author": author,
"message": msg,
"date": date,
"files": files,
"diff": diff[:3000] # diff가 너무 길면 자름
})
except:
continue
return commits
def extract_pr_id(title):
if "# " in title:
try:
return title.split("#")[1].split()[0]
except:
return None
return None
output = []
print("🔍 Searching for merged PRs...")
log_lines = run("git log --merges --pretty=format:'%H|%an|%ad|%s'").splitlines()
for line in log_lines:
try:
merge_sha, author, date, title = line.split("|", 3)
except ValueError:
continue
commits = extract_pr_commits(merge_sha)
if not commits:
continue
pr_doc = {
"merge_sha": merge_sha,
"author": author,
"date": date,
"title": title,
"pr_id": extract_pr_id(title),
"commits": commits
}
output.append(pr_doc)
with open("pr_dataset.jsonl", "w") as f:
for item in output:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"✅ Generated pr_dataset.jsonl with {len(output)} merged PRs.")import subprocess
import json
def run(cmd):
return subprocess.check_output(cmd, shell=True, text=True).strip()
def extract_pr_commits(merge_sha):
try:
parent1 = run(f"git rev-parse {merge_sha}^1")
parent2 = run(f"git rev-parse {merge_sha}^2")
except subprocess.CalledProcessError:
return []
try:
lines = run(f"git log {parent1}..{parent2} --pretty=format:'%H|%an|%s|%ad'").splitlines()
except subprocess.CalledProcessError:
return []
commits = []
for line in lines:
try:
sha, author, msg, date = line.split("|", 3)
files = run(f"git show --pretty=format:'' --name-only {sha}").splitlines()
diff = run(f"git show {sha}")
commits.append({
"sha": sha,
"author": author,
"message": msg,
"date": date,
"files": files,
"diff": diff[:3000] # diff가 너무 길면 자름
})
except:
continue
return commits
def extract_pr_id(title):
if "# " in title:
try:
return title.split("#")[1].split()[0]
except:
return None
return None
output = []
print("🔍 Searching for merged PRs...")
log_lines = run("git log --merges --pretty=format:'%H|%an|%ad|%s'").splitlines()
for line in log_lines:
try:
merge_sha, author, date, title = line.split("|", 3)
except ValueError:
continue
commits = extract_pr_commits(merge_sha)
if not commits:
continue
pr_doc = {
"merge_sha": merge_sha,
"author": author,
"date": date,
"title": title,
"pr_id": extract_pr_id(title),
"commits": commits
}
output.append(pr_doc)
with open("pr_dataset.jsonl", "w") as f:
for item in output:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"✅ Generated pr_dataset.jsonl with {len(output)} merged PRs.")RAG 입력용 텍스트 구성
RAG 입력에 적합하도록 요약하여 텍스트 정제후, AIOS Embedding 모델을 통해 벡터를 생성합니다.
$ python3 generate_rag_data_from_pr_dataset.py
✅ RAG용 텍스트 생성 완료 → rag_ready.jsonl
$ head -n 1 rag_ready.jsonl | jq
{
"pr_id": null,
"title": "Merge pull request #7461 from rimolive/kf-1.9",
"text": "PR 제목: Merge pull request #7461 from rimolive/kf-1.9\n병합자: Ricardo Martinelli de Oliveira / 날짜: Tue Mar 5 11:46:36 2024 -0300\n커밋 요약:\n- Ricardo Martinelli de Oliveira (Mon Feb 19 18:51:40 2024 -0300): Update ROADMAP.md\n 변경 파일: ROADMAP.md\n 변경사항:\ncommit 68e4d10bbf976bb89810b4e16e8b765a2a0e68b7\nAuthor: Ricardo Martinelli de Oliveira <rmartine@redhat.com>\nDate: Mon Feb 19 18:51:40 2024 -0300\n\n Update ROADMAP.md\n \n Co-authored-by: Tommy Li <Tommy.chaoping.li@ibm.com>\n\ndiff --git a/ROADMAP.md b/ROADMAP.md\nindex 35021954..cfd39558 100644\n--- a/ROADMAP.md\n+++ b/ROADMAP.md\n@@ -8,7 +8,7 @@ The Kubeflow Community plans to deliver its v1.9 release in Jul 2024 per this [t\n * CNCF Transition\n * LLM APIs\n * New component: Model Registry\n-* Kubeflow Pipelines and kfp-tekton merged in a single GitHub repository\n+* Kubeflow Pipelines and kfp-tekton V2 merged in a single GitHub repository\n \n ### Detailed features, bug fixes and enhancements are identified in the Working Group Roadmaps and Tracking Issues:\n * [Training Operators](https://github.com/kubeflow/training-operator/issues/1994)\n- Ricardo M. Oliveira (Mon Feb 5 14:43:45 2024 -0300): Add Kubeflow 1.9 release roadmap\n 변경 파일: ROADMAP.md\n 변경사항:\ncommit 5c3404782fa2700f8547b37132ff7ab2d1ed99fe\nAuthor: Ricardo M. Oliveira <rmartine@redhat.com>\nDate: Mon Feb 5 14:43:45 2024 -0300\n\n Add Kubeflow 1.9 release roadmap\n \n Signed-off-by: Ricardo M. Oliveira <rmartine@redhat.com>\n\ndiff --git a/ROADMAP.md b/ROADMAP.md\nindex de3c8951..35021954 100644\n--- a/ROADMAP.md\n+++ b/ROADMAP.md\n@@ -1,6 +1,26 @@\n # Kubeflow Roadmap\n \n-## Kubeflow 1.8 Release, Planned for release: Oct 2023\n+## Kubeflow 1.9 Release, Planned for release: Jul 2024\n+The Kubeflow Community plans to deliver its v1.9 release in Jul 2024 per this [timeline](https://github.com/kubeflow/community/blob/master/releases/release-1.9/README.md#timeline). The high level deliverables are tracked in the [v1.9 Release](https://github.com/orgs/kubeflow/projects/61) Github project board. The v1.9 release process will be managed by the v1.9 [release team](https://github.com/kubeflow/community/blob/master/releases/release-1.9/release-team.md) using the best practices in the [Rele"
}
$ python3 embed_prs.py
✅ Line 1: embedded
✅ Line 2: embedded
✅ Line 3: embedded
✅ Line 4: embedded
✅ Line 5: embedded
✅ Line 6: embedded
✅ Line 7: embedded
✅ Line 8: embedded
✅ Line 9: embedded
✅ Line 10: embedded
... (중략) ...
generate_rag_data_from_pr_dataset.py
배경색 변경
import json
def build_text(pr):
lines = []
lines.append(f"PR 제목: {pr['title']}")
lines.append(f"병합자: {pr['author']} / 날짜: {pr['date']}")
lines.append("커밋 요약:")
for c in pr["commits"]:
lines.append(f"- {c['author']} ({c['date']}): {c['message']}")
if c["files"]:
lines.append(f" 변경 파일: {', '.join(c['files'])}")
lines.append(" 변경사항:")
lines.append(c["diff"][:1000]) # 너무 길면 자름
return "\n".join(lines)
with open("pr_dataset.jsonl") as fin, open("rag_ready.jsonl", "w") as fout:
for line in fin:
pr = json.loads(line)
text = build_text(pr)
out = {
"pr_id": pr.get("pr_id"),
"title": pr.get("title"),
"text": text
}
fout.write(json.dumps(out, ensure_ascii=False) + "\n")
print("✅ RAG용 텍스트 생성 완료 → rag_ready.jsonl")import json
def build_text(pr):
lines = []
lines.append(f"PR 제목: {pr['title']}")
lines.append(f"병합자: {pr['author']} / 날짜: {pr['date']}")
lines.append("커밋 요약:")
for c in pr["commits"]:
lines.append(f"- {c['author']} ({c['date']}): {c['message']}")
if c["files"]:
lines.append(f" 변경 파일: {', '.join(c['files'])}")
lines.append(" 변경사항:")
lines.append(c["diff"][:1000]) # 너무 길면 자름
return "\n".join(lines)
with open("pr_dataset.jsonl") as fin, open("rag_ready.jsonl", "w") as fout:
for line in fin:
pr = json.loads(line)
text = build_text(pr)
out = {
"pr_id": pr.get("pr_id"),
"title": pr.get("title"),
"text": text
}
fout.write(json.dumps(out, ensure_ascii=False) + "\n")
print("✅ RAG용 텍스트 생성 완료 → rag_ready.jsonl")embed_prs.py
참고
- 코드 내 EMBEDDING_API_URL인 AIOS_LLM_Private_Endpoint과 model의 MODEL_ID는 LLM 이용 가이드를 참고해주세요. 아래의 예시처럼 입력할 수 있습니다.
- EMBEDDING_API_URL = “{AIOS LLM 프라이빗 엔드포인트}/{API}”
- “model”: “{모델ID}”
배경색 변경
import json
import requests
import time
EMBEDDING_API_URL = "AIOS_LLM_Private_Endpoint"
HEADERS = {"Content-Type": "application/json"}
def get_embedding(text):
payload = {
"model": "MODEL_ID",
"input": text,
"stream": False
}
try:
response = requests.post(EMBEDDING_API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
return result["data"][0]["embedding"]
else:
print(f"❌ Failed with status {response.status_code}: {response.text}")
return None
except Exception as e:
print(f"⚠️ Error calling embedding API: {e}")
return None
def main():
with open("rag_ready.jsonl", "r", encoding="utf-8") as fin, \
open("rag_embedded.jsonl", "w", encoding="utf-8") as fout:
for i, line in enumerate(fin, start=1):
try:
item = json.loads(line)
text = item.get("text", "").strip()
if not text:
print(f"⚠️ Line {i}: empty text, skipping")
continue
embedding = get_embedding(text)
if embedding is None:
print(f"⚠️ Line {i}: embedding failed, skipping")
continue
item["embedding"] = embedding
fout.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"✅ Line {i}: embedded")
time.sleep(0.2) # optional: rate limiting
except Exception as e:
print(f"❌ Line {i}: error - {e}")
continue
if __name__ == "__main__":
main()import json
import requests
import time
EMBEDDING_API_URL = "AIOS_LLM_Private_Endpoint"
HEADERS = {"Content-Type": "application/json"}
def get_embedding(text):
payload = {
"model": "MODEL_ID",
"input": text,
"stream": False
}
try:
response = requests.post(EMBEDDING_API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
return result["data"][0]["embedding"]
else:
print(f"❌ Failed with status {response.status_code}: {response.text}")
return None
except Exception as e:
print(f"⚠️ Error calling embedding API: {e}")
return None
def main():
with open("rag_ready.jsonl", "r", encoding="utf-8") as fin, \
open("rag_embedded.jsonl", "w", encoding="utf-8") as fout:
for i, line in enumerate(fin, start=1):
try:
item = json.loads(line)
text = item.get("text", "").strip()
if not text:
print(f"⚠️ Line {i}: empty text, skipping")
continue
embedding = get_embedding(text)
if embedding is None:
print(f"⚠️ Line {i}: embedding failed, skipping")
continue
item["embedding"] = embedding
fout.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"✅ Line {i}: embedded")
time.sleep(0.2) # optional: rate limiting
except Exception as e:
print(f"❌ Line {i}: error - {e}")
continue
if __name__ == "__main__":
main()OpenSearch에 업로드
벡터 파일을 OpenSearch에 업로드하여 검색 가능한 형태로 구성합니다.
참고
- 이 튜토리얼에서는 VM 내부에 OpenSearch를 구성하고, http://localhost:9200 주소로 호출합니다. 사용자 벡터 데이터베이스를 사용하는 경우에는 URL을 알맞게 변경해 주세요.
# OpenSearch에 "kubeflow-pr-rag-index"이름의 인덱스 생성
$ curl -X PUT "http://localhost:9200/kubeflow-pr-rag-index" \
-H "Content-Type: application/json" \
-d '{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"title": { "type": "text" },
"text": { "type": "text" },
"embedding": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "nmslib"
}
}
}
}
}'
{"acknowledged":true,"shards_acknowledged":true,"index":"kubeflow-pr-rag-index"}
$ python3 upload_rag_documnets.py
✅ Uploaded document pr-1
✅ Uploaded document pr-2
✅ Uploaded document pr-3
✅ Uploaded document pr-4
✅ Uploaded document pr-5
✅ Uploaded document pr-6
✅ Uploaded document pr-7
✅ Uploaded document pr-8
✅ Uploaded document pr-9
✅ Uploaded document pr-10
... (중략) ...
upload_rag_documnets.py
배경색 변경
import json
from opensearchpy import OpenSearch
# OpenSearch 연결 설정
client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
use_ssl=False,
verify_certs=False
)
index_name = "kubeflow-pr-rag-index"
with open("rag_embedded.jsonl", "r", encoding="utf-8") as f:
for i, line in enumerate(f, 1):
try:
doc = json.loads(line)
title = doc.get("title", "")
text = doc.get("text", "")
embedding = doc.get("embedding", [])
if not embedding or len(embedding) != 1024:
print(f"⚠️ Line {i}: Invalid embedding length, skipping.")
continue
body = {
"title": title,
"text": text,
"embedding": embedding
}
doc_id = f"pr-{i}"
client.index(index=index_name, id=doc_id, body=body)
print(f"✅ Uploaded document {doc_id}")
except Exception as e:
print(f"❌ Line {i}: Failed to upload due to {e}")import json
from opensearchpy import OpenSearch
# OpenSearch 연결 설정
client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
use_ssl=False,
verify_certs=False
)
index_name = "kubeflow-pr-rag-index"
with open("rag_embedded.jsonl", "r", encoding="utf-8") as f:
for i, line in enumerate(f, 1):
try:
doc = json.loads(line)
title = doc.get("title", "")
text = doc.get("text", "")
embedding = doc.get("embedding", [])
if not embedding or len(embedding) != 1024:
print(f"⚠️ Line {i}: Invalid embedding length, skipping.")
continue
body = {
"title": title,
"text": text,
"embedding": embedding
}
doc_id = f"pr-{i}"
client.index(index=index_name, id=doc_id, body=body)
print(f"✅ Uploaded document {doc_id}")
except Exception as e:
print(f"❌ Line {i}: Failed to upload due to {e}")OpenSearch Dashboards에서 확인
아래 그림과 같이 OpenSearch Dashboard에서 kubeflow-pr-rag-index 에 해당하는 데이터를 확인할 수 있습니다. 데이터는 title, text, embedding으로 구성되어 있습니다.
참고
OpenSearch Dashboard에서 Index Patterns 등록
왼쪽 메뉴 → Dashboards Management → Index patterns → Create index pattern 클릭
왼쪽 메뉴 → Dashboards Management → Index patterns → Create index pattern 클릭

RAG QA Application 구성
사용자의 질의를 임베딩하여 검색 질의로 변환한 뒤, RAG를 활용해 연관 문서를 추출하고, AIOS Chat 모델을 통해 최종 결과를 제공합니다.
참고
- 이 코드에서는 유사도 검색 방식으로 OpenSearch의 KNN(K-Nearest Neightbors) 검색과 AIOS에서 제공하는 Embedding 모델의 Score API를 호출하여 입력 벡터와 가장 유사한 문서를 계산하는 방식을 지원합니다. 사용자는 두 방식 중 하나를 선택하여 사용할 수 있으며, 이 튜토리얼에서는 AIOS Score API 기반의 유사도 검색 방식을 사용합니다.
- OpenSearch의 KNN 호출 :
docs = search_similar_docs(query_vec, K) - AIOS Embedding 모델 호출 :
docs = search_similar_docs_with_score(question, K)
- OpenSearch의 KNN 호출 :
- 코드 내 EMBEDDING_API_URL, LLM_API_URL, SCORE_API_URL, MODEL_EMBEDDING, MODEL_CHAT은 LLM 이용 가이드를 참고하여 사용할 API와 Model로 입력해주세요. 아래의 예시처럼 입력할 수 있습니다.
- EMBEDDING_API_URL = “{AIOS LLM 프라이빗 엔드포인트}/{API}”
- MODEL_EMBEDDING = “{모델ID}”
app.py
배경색 변경
import streamlit as st
import requests
from opensearchpy import OpenSearch
# 설정
def get_opensearch_client():
return OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
use_ssl=False,
verify_certs=False
)
EMBEDDING_API_URL = "YOUR_EMBEDDING_API_URL"
LLM_API_URL = "YOUR_LLM_API_URL"
SCORE_API_URL = "YOUR_SCORE_API_URL"
MODEL_EMBEDDING = "YOUR_MODEL_EMBEDDING"
MODEL_CHAT = "YOUR_MODEL_CHAT"
INDEX_NAME = "kubeflow-pr-rag-index"
VECTOR_DIM = 1024
K = 3
# 임베딩 생성 함수
def embed_text(text):
res = requests.post(
EMBEDDING_API_URL,
headers={"Content-Type": "application/json"},
json={"model": MODEL_EMBEDDING, "input": text, "stream": False}
)
return res.json()["data"][0]["embedding"]
# 모든 문서 불러오기 (OpenSearch)
def fetch_all_docs():
client = get_opensearch_client()
res = client.search(
index=INDEX_NAME,
body={
"size": 1000, # 필요한 만큼 설정 (작을 경우 스크롤 API 활용 가능)
"query": {"match_all": {}}
}
)
return [doc["_source"] for doc in res["hits"]["hits"]]
# 두 문장 리스트를 받아 유사도 점수 계산
def score_text_pairs(text_1, text_2):
payload = {
"model": MODEL_EMBEDDING,
"encoding_format": "float",
"text_1": text_1,
"text_2": text_2
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
response = requests.post(SCORE_API_URL, headers=headers, json=payload)
response.raise_for_status()
# 유사도 score만 추출
scores = [item["score"] for item in response.json()["data"]]
return scores
# 유사 문서 선택 (점수 기반 Top-K)
def search_similar_docs_with_score(query, k):
all_docs = fetch_all_docs()
doc_texts = [doc["text"] for doc in all_docs]
queries = [query] * len(doc_texts)
scores = score_text_pairs(queries, doc_texts)
# 점수 높은 순으로 정렬
scored_docs = sorted(zip(all_docs, scores), key=lambda x: x[1], reverse=True)
top_docs = [doc for doc, score in scored_docs[:k]]
return top_docs
# KNN 검색 함수
def search_similar_docs(query_vector, k):
client = get_opensearch_client()
res = client.search(
index=INDEX_NAME,
body={
"size": k,
"query": {
"knn": {
"embedding": {
"vector": query_vector,
"k": k
}
}
}
}
)
return [doc["_source"] for doc in res["hits"]["hits"]]
# 프롬프트 구성
def build_prompt(docs, question):
context_blocks = []
for i, doc in enumerate(docs):
context_blocks.append(f"[문서 {i+1}]\n{doc['text']}")
context = "\n\n".join(context_blocks)
return f"""다음은 Kubeflow 프로젝트에서 유사한 PR 문서들입니다:
{context}
사용자 질문: {question}
위 내용을 참고하여 질문에 대해 자연어로 답변해 주세요. 가능한 문서 번호를 인용해서 설명해주세요."""
# LLM 호출 함수
def call_llm(prompt):
res = requests.post(
LLM_API_URL,
headers={"Content-Type": "application/json"},
json={
"model": MODEL_CHAT,
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
)
return res.json()["choices"][0]["message"]["content"]
# Streamlit UI 시작
st.set_page_config(page_title="RAG QA", layout="wide")
st.title("📘 RAG-based PR Summary Chatbot")
question = st.text_input("Enter your question:", "Please summarize the PR the Add Kubeflow 1.9 release roadmap.")
if st.button("Searching and generating response"):
with st.spinner("Generating embeddings..."):
query_vec = embed_text(question)
with st.spinner("Searching for similar documents in OpenSearch..."):
#docs = search_similar_docs(query_vec, K)
docs = search_similar_docs_with_score(question, K)
with st.spinner("Constructing prompt and invoking LLM..."):
prompt = build_prompt(docs, question)
answer = call_llm(prompt)
st.markdown("### 🤖 LLM response")
st.write(answer)
st.markdown("---")
st.markdown("### 🔍 Highlighted PR document")
for i, doc in enumerate(docs):
with st.expander(f"문서 {i+1}: {doc['title']}"):
# 간단한 질문 키워드 하이라이트
highlighted = doc['text'].replace(question.split()[0], f"**{question.split()[0]}**")
st.markdown(highlighted)import streamlit as st
import requests
from opensearchpy import OpenSearch
# 설정
def get_opensearch_client():
return OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
use_ssl=False,
verify_certs=False
)
EMBEDDING_API_URL = "YOUR_EMBEDDING_API_URL"
LLM_API_URL = "YOUR_LLM_API_URL"
SCORE_API_URL = "YOUR_SCORE_API_URL"
MODEL_EMBEDDING = "YOUR_MODEL_EMBEDDING"
MODEL_CHAT = "YOUR_MODEL_CHAT"
INDEX_NAME = "kubeflow-pr-rag-index"
VECTOR_DIM = 1024
K = 3
# 임베딩 생성 함수
def embed_text(text):
res = requests.post(
EMBEDDING_API_URL,
headers={"Content-Type": "application/json"},
json={"model": MODEL_EMBEDDING, "input": text, "stream": False}
)
return res.json()["data"][0]["embedding"]
# 모든 문서 불러오기 (OpenSearch)
def fetch_all_docs():
client = get_opensearch_client()
res = client.search(
index=INDEX_NAME,
body={
"size": 1000, # 필요한 만큼 설정 (작을 경우 스크롤 API 활용 가능)
"query": {"match_all": {}}
}
)
return [doc["_source"] for doc in res["hits"]["hits"]]
# 두 문장 리스트를 받아 유사도 점수 계산
def score_text_pairs(text_1, text_2):
payload = {
"model": MODEL_EMBEDDING,
"encoding_format": "float",
"text_1": text_1,
"text_2": text_2
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
response = requests.post(SCORE_API_URL, headers=headers, json=payload)
response.raise_for_status()
# 유사도 score만 추출
scores = [item["score"] for item in response.json()["data"]]
return scores
# 유사 문서 선택 (점수 기반 Top-K)
def search_similar_docs_with_score(query, k):
all_docs = fetch_all_docs()
doc_texts = [doc["text"] for doc in all_docs]
queries = [query] * len(doc_texts)
scores = score_text_pairs(queries, doc_texts)
# 점수 높은 순으로 정렬
scored_docs = sorted(zip(all_docs, scores), key=lambda x: x[1], reverse=True)
top_docs = [doc for doc, score in scored_docs[:k]]
return top_docs
# KNN 검색 함수
def search_similar_docs(query_vector, k):
client = get_opensearch_client()
res = client.search(
index=INDEX_NAME,
body={
"size": k,
"query": {
"knn": {
"embedding": {
"vector": query_vector,
"k": k
}
}
}
}
)
return [doc["_source"] for doc in res["hits"]["hits"]]
# 프롬프트 구성
def build_prompt(docs, question):
context_blocks = []
for i, doc in enumerate(docs):
context_blocks.append(f"[문서 {i+1}]\n{doc['text']}")
context = "\n\n".join(context_blocks)
return f"""다음은 Kubeflow 프로젝트에서 유사한 PR 문서들입니다:
{context}
사용자 질문: {question}
위 내용을 참고하여 질문에 대해 자연어로 답변해 주세요. 가능한 문서 번호를 인용해서 설명해주세요."""
# LLM 호출 함수
def call_llm(prompt):
res = requests.post(
LLM_API_URL,
headers={"Content-Type": "application/json"},
json={
"model": MODEL_CHAT,
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
)
return res.json()["choices"][0]["message"]["content"]
# Streamlit UI 시작
st.set_page_config(page_title="RAG QA", layout="wide")
st.title("📘 RAG-based PR Summary Chatbot")
question = st.text_input("Enter your question:", "Please summarize the PR the Add Kubeflow 1.9 release roadmap.")
if st.button("Searching and generating response"):
with st.spinner("Generating embeddings..."):
query_vec = embed_text(question)
with st.spinner("Searching for similar documents in OpenSearch..."):
#docs = search_similar_docs(query_vec, K)
docs = search_similar_docs_with_score(question, K)
with st.spinner("Constructing prompt and invoking LLM..."):
prompt = build_prompt(docs, question)
answer = call_llm(prompt)
st.markdown("### 🤖 LLM response")
st.write(answer)
st.markdown("---")
st.markdown("### 🔍 Highlighted PR document")
for i, doc in enumerate(docs):
with st.expander(f"문서 {i+1}: {doc['title']}"):
# 간단한 질문 키워드 하이라이트
highlighted = doc['text'].replace(question.split()[0], f"**{question.split()[0]}**")
st.markdown(highlighted)RAG QA Chatbot UI 사용 방법
호출 코드 실행
- VM에서 Streamlit 실행배경색 변경
streamlit run app.py --server.port 8501 --server.address 0.0.0.0streamlit run app.py --server.port 8501 --server.address 0.0.0.0코드 블럭. Streamlit 실행
You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:8501
브라우저에서 http://{your_server_ip}:8501 또는 서버 SSH 터널링 설정 후 http://0.0.0.0:8501 로 접속합니다. SSH 터널링은 아래를 참고하세요.
2. 로컬PC에서 터널링으로 VM접속 (http://0.0.0.0:8501 로 접속하는 경우)
배경색 변경
ssh -i {your_pemkey.pem} -L 8501:localhost:8501 ubuntu@{your_server_ip}ssh -i {your_pemkey.pem} -L 8501:localhost:8501 ubuntu@{your_server_ip}사용 예시
Kubeflow 프로젝트 Git에서 Add Kubeflow 1.9 release roadmap PR 에 대한 요약을 질문합니다.

Kubeflow 프로젝트의 해당 PR에 대한 정보입니다.

마무리
이번 튜토리얼에서는 AIOS에서 제공하는 AI 모델을 활용하여 GIT PR 관련 데이터를 벡터화하고, OpenSearch 기반의 벡터 검색 및 LLM 응답을 조합하여 PR 리뷰 보조 챗봇을 구현해 보았습니다.이를 통해 과거 PR 히스토리에 기반한 질의응답이 가능해져, 개발자의 코드 리뷰 효율성과 품질을 향상시킬 수 있습니다. 본 시스템은 다음과 같은 방식으로 사용자 환경에 맞게 확장 및 커스터마이징할 수 있습니다.
- 벡터 데이터베이스 교체 : OpenSearch 외에 SCP Search Engine 상품 활용, 사용자 벡터 데이터베이스를 연동할 수 있습니다.
- 실시간 데이터 수집 연동 : Github Webhook 또는 Gitlab API 연동을 통해 실시간 PR 생성/업데이트 정보를 수집하고 자동 인덱싱 가능합니다.
- 대화형 UI 고도화: Streamlit 외에도 Slack Bot, 사내 메신저 등 다양한 인터페이스로 확장 가능합니다.
이번 튜토리얼을 기반으로 실제 서비스 목적에 따라 적합한 AIOS 기반 협업 도우미를 직접 구축해 보시길 바랍니다.
참고 링크
1.3.2.3 - Autogen
목표
AIOS에서 제공하는 AI모델을 활용해 Autogen AI Agent 애플리케이션을 생성합니다.
참고
Autogen
Autogen은 LLM 기반 다중 에이전트 협업과 이벤트 기반 자동화 워크플로우를 손쉽게 구축, 관리할 수 있는 오픈소스 프레임워크입니다.
Autogen은 LLM 기반 다중 에이전트 협업과 이벤트 기반 자동화 워크플로우를 손쉽게 구축, 관리할 수 있는 오픈소스 프레임워크입니다.
환경
이 튜토리얼을 진행하려면 아래와 같은 환경이 준비되어 있어야 합니다.
시스템 환경
- Python 3.10 +
- pip
설치 필요 패키지
배경색 변경
pip install autogen-agentchat==0.6.1 autogen-ext[openai,mcp]==0.6.1 mcp-server-time==0.6.2pip install autogen-agentchat==0.6.1 autogen-ext[openai,mcp]==0.6.1 mcp-server-time==0.6.2시스템 아키텍처
다중 AI 에이전트 아키텍처 및 MCP를 활용한 에이전트 아키텍처의 전체 흐름을 보여줍니다.
Travel Planning Agent Flow

- 사용자가 3일간의 네팔 여행 계획을 세워달라고 요청
- Groupchat manger는 등록된 에이전트(여행 계획, 로컬 정보, 여행 회화, 종합 요약)의 실행 순서를 조정
- 각각의 에이전트는 각자의 역할에 맞게 주어진 작업을 협업하여 수행
- 최종적으로 여행 계획 결과물이 도출되면 사용자에게 전달
MCP Flow

참고
MCP
MCP(Model Context Protocol)는 모델과 외부 데이터나 도구와의 상호작용을 조율하는 개방형 표준 프로토콜입니다.
MCP 서버는 이를 구현한 서버로, 도구 메타데이터를 활용해 함수 호출을 중계, 실행합니다.
- 사용자가 한국의 현재 시각에 대해 질의
- mcp_server_time 서버를 통해 현재 시각을 가져올 수 있는 도구의 메타데이터를 포함하여 모델 요청
get_current_time함수를 호출하는 tool calls 메시지 생성- MCP 서버를 통해
get_current_time함수를 실행하여 결과물을 모델 요청으로 전달하면 최종 응답을 생성하여 사용자에게 전달
구현
Travel Planning Agent
참고
- 코드 내 AIOS_BASE_URL인 AIOS_LLM_Private_Endpoint와 MODEL의 MODEL_ID는 LLM 이용 가이드를 참고해주세요.
autogen_travel_planning.py
배경색 변경
from urllib.parse import urljoin
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_core.models import ModelFamily
# 모델 접근을 위한 API URL과 모델 이름을 설정합니다.
AIOS_BASE_URL = "AIOS_LLM_Private_Endpoint"
MODEL = "MODEL_ID"
# OpenAIChatCompletionClient를 사용하여 모델 클라이언트를 생성합니다.
model_client = OpenAIChatCompletionClient(
model=MODEL,
base_url=urljoin(AIOS_BASE_URL, "v1"),
api_key="EMPTY_KEY",
model_info={
# 이미지를 지원하는 경우 True로 설정합니다.
"vision": False,
# 함수 호출을 지원하는 경우 True로 설정합니다.
"function_calling": True,
# JSON 출력을 지원하는 경우 True로 설정합니다.
"json_output": True,
# 사용하고자 하는 모델이 ModelFamily에서 제공하지 않는 경우 UNKNOWN을 사용합니다.
# "family": ModelFamily.UNKNOWN,
"family": ModelFamily.LLAMA_3_3_70B,
# 구조화된 출력을 지원하는 경우 True로 설정합니다.
"structured_output": True,
},
)
# 여러 에이전트를 생성합니다.
# 각 에이전트는 여행 계획, 지역 활동 추천, 언어 팁 제공, 여행 계획 요약 등의 역할을 수행합니다.
planner_agent = AssistantAgent(
"planner_agent",
model_client=model_client,
description="A helpful assistant that can plan trips.",
system_message=("You are a helpful assistant that can suggest a travel plan "
"for a user based on their request."),
)
local_agent = AssistantAgent(
"local_agent",
model_client=model_client,
description="A local assistant that can suggest local activities or places to visit.",
system_message=("You are a helpful assistant that can suggest authentic and "
"interesting local activities or places to visit for a user "
"and can utilize any context information provided."),
)
language_agent = AssistantAgent(
"language_agent",
model_client=model_client,
description="A helpful assistant that can provide language tips for a given destination.",
system_message=("You are a helpful assistant that can review travel plans, "
"providing feedback on important/critical tips about how best to address "
"language or communication challenges for the given destination. "
"If the plan already includes language tips, "
"you can mention that the plan is satisfactory, with rationale."),
)
travel_summary_agent = AssistantAgent(
"travel_summary_agent",
model_client=model_client,
description="A helpful assistant that can summarize the travel plan.",
system_message=("You are a helpful assistant that can take in all of the suggestions "
"and advice from the other agents and provide a detailed final travel plan. "
"You must ensure that the final plan is integrated and complete. "
"YOUR FINAL RESPONSE MUST BE THE COMPLETE PLAN. "
"When the plan is complete and all perspectives are integrated, "
"you can respond with TERMINATE."),
)
# 에이전트들을 그룹으로 묶어 RoundRobinGroupChat을 생성합니다.
# RoundRobinGroupChat은 에이전트들이 등록된 순서대로 돌아가면서 작업을 수행하도록 조정합니다.
# 이 그룹은 에이전트들이 상호작용하며 여행 계획을 세울 수 있도록 합니다.
# 종료 조건은 TextMentionTermination을 사용하여 "TERMINATE"라는 텍스트가 언급될 때 그룹 채팅을 종료합니다.
termination = TextMentionTermination("TERMINATE")
group_chat = RoundRobinGroupChat(
[planner_agent, local_agent, language_agent, travel_summary_agent],
termination_condition=termination,
)
async def main():
"""메인 함수로, 그룹 채팅을 실행하고 여행 계획을 세웁니다."""
# 그룹 채팅을 실행하여 여행 계획을 세웁니다.
# 사용자가 "Plan a 3 day trip to Nepal."라는 작업을 요청합니다.
# Console을 사용하여 결과를 출력합니다.
await Console(group_chat.run_stream(task="Plan a 3 day trip to Nepal."))
await model_client.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())from urllib.parse import urljoin
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_core.models import ModelFamily
# 모델 접근을 위한 API URL과 모델 이름을 설정합니다.
AIOS_BASE_URL = "AIOS_LLM_Private_Endpoint"
MODEL = "MODEL_ID"
# OpenAIChatCompletionClient를 사용하여 모델 클라이언트를 생성합니다.
model_client = OpenAIChatCompletionClient(
model=MODEL,
base_url=urljoin(AIOS_BASE_URL, "v1"),
api_key="EMPTY_KEY",
model_info={
# 이미지를 지원하는 경우 True로 설정합니다.
"vision": False,
# 함수 호출을 지원하는 경우 True로 설정합니다.
"function_calling": True,
# JSON 출력을 지원하는 경우 True로 설정합니다.
"json_output": True,
# 사용하고자 하는 모델이 ModelFamily에서 제공하지 않는 경우 UNKNOWN을 사용합니다.
# "family": ModelFamily.UNKNOWN,
"family": ModelFamily.LLAMA_3_3_70B,
# 구조화된 출력을 지원하는 경우 True로 설정합니다.
"structured_output": True,
},
)
# 여러 에이전트를 생성합니다.
# 각 에이전트는 여행 계획, 지역 활동 추천, 언어 팁 제공, 여행 계획 요약 등의 역할을 수행합니다.
planner_agent = AssistantAgent(
"planner_agent",
model_client=model_client,
description="A helpful assistant that can plan trips.",
system_message=("You are a helpful assistant that can suggest a travel plan "
"for a user based on their request."),
)
local_agent = AssistantAgent(
"local_agent",
model_client=model_client,
description="A local assistant that can suggest local activities or places to visit.",
system_message=("You are a helpful assistant that can suggest authentic and "
"interesting local activities or places to visit for a user "
"and can utilize any context information provided."),
)
language_agent = AssistantAgent(
"language_agent",
model_client=model_client,
description="A helpful assistant that can provide language tips for a given destination.",
system_message=("You are a helpful assistant that can review travel plans, "
"providing feedback on important/critical tips about how best to address "
"language or communication challenges for the given destination. "
"If the plan already includes language tips, "
"you can mention that the plan is satisfactory, with rationale."),
)
travel_summary_agent = AssistantAgent(
"travel_summary_agent",
model_client=model_client,
description="A helpful assistant that can summarize the travel plan.",
system_message=("You are a helpful assistant that can take in all of the suggestions "
"and advice from the other agents and provide a detailed final travel plan. "
"You must ensure that the final plan is integrated and complete. "
"YOUR FINAL RESPONSE MUST BE THE COMPLETE PLAN. "
"When the plan is complete and all perspectives are integrated, "
"you can respond with TERMINATE."),
)
# 에이전트들을 그룹으로 묶어 RoundRobinGroupChat을 생성합니다.
# RoundRobinGroupChat은 에이전트들이 등록된 순서대로 돌아가면서 작업을 수행하도록 조정합니다.
# 이 그룹은 에이전트들이 상호작용하며 여행 계획을 세울 수 있도록 합니다.
# 종료 조건은 TextMentionTermination을 사용하여 "TERMINATE"라는 텍스트가 언급될 때 그룹 채팅을 종료합니다.
termination = TextMentionTermination("TERMINATE")
group_chat = RoundRobinGroupChat(
[planner_agent, local_agent, language_agent, travel_summary_agent],
termination_condition=termination,
)
async def main():
"""메인 함수로, 그룹 채팅을 실행하고 여행 계획을 세웁니다."""
# 그룹 채팅을 실행하여 여행 계획을 세웁니다.
# 사용자가 "Plan a 3 day trip to Nepal."라는 작업을 요청합니다.
# Console을 사용하여 결과를 출력합니다.
await Console(group_chat.run_stream(task="Plan a 3 day trip to Nepal."))
await model_client.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())python을 이용하여 파일을 실행하면 하나의 태스크를 위해 여러 개의 에이전트가 함께 각각의 역할을 수행하는 모습을 확인할 수 있습니다.
배경색 변경
python autogen_travel_planning.pypython autogen_travel_planning.py실행결과
---------- TextMessage (user) ----------
Plan a 3 day trip to Nepal.
---------- TextMessage (planner_agent) ----------
Nepal! A country with a rich cultural heritage, breathtaking natural beauty, and warm hospitality. Here's a suggested 3-day itinerary for your trip to Nepal:
**Day 1: Arrival in Kathmandu and Exploration of the City**
* Arrive at Tribhuvan International Airport in Kathmandu, the capital city of Nepal.
* Check-in to your hotel and freshen up.
* Visit the famous **Boudhanath Stupa**, one of the largest Buddhist stupas in the world.
* Explore the **Thamel** area, a popular tourist hub known for its narrow streets, shops, and restaurants.
* In the evening, enjoy a traditional Nepali dinner and watch a cultural performance at a local restaurant.
**Day 2: Kathmandu Valley Tour**
* Start the day with a visit to the **Pashupatinath Temple**, a sacred Hindu temple dedicated to Lord Shiva.
* Next, head to the **Kathmandu Durbar Square**, a UNESCO World Heritage Site and the former royal palace of the Malla kings.
* Visit the **Swayambhunath Stupa**, also known as the Monkey Temple, which offers stunning views of the city.
* In the afternoon, take a short drive to the **Patan City**, known for its rich cultural heritage and traditional crafts.
* Explore the **Patan Durbar Square** and visit the **Krishna Temple**, a beautiful example of Nepali architecture.
**Day 3: Bhaktapur and Nagarkot**
* Drive to **Bhaktapur**, a medieval town and a UNESCO World Heritage Site (approximately 1 hour).
* Explore the **Bhaktapur Durbar Square**, which features stunning architecture, temples, and palaces.
* Visit the **Pottery Square**, where you can see traditional pottery-making techniques.
* In the afternoon, drive to **Nagarkot**, a scenic hill station with breathtaking views of the Himalayas (approximately 1.5 hours).
* Watch the sunset over the Himalayas and enjoy the peaceful atmosphere.
**Additional Tips:**
* Make sure to try some local Nepali cuisine, such as momos, dal bhat, and gorkhali lamb.
* Bargain while shopping in the markets, as it's a common practice in Nepal.
* Respect local customs and traditions, especially when visiting temples and cultural sites.
* Stay hydrated and bring sunscreen, as the sun can be strong in Nepal.
**Accommodation:**
Kathmandu has a wide range of accommodation options, from budget-friendly guesthouses to luxury hotels. Some popular areas to stay include Thamel, Lazimpat, and Boudha.
**Transportation:**
You can hire a taxi or a private vehicle for the day to travel between destinations. Alternatively, you can use public transportation, such as buses or microbuses, which are affordable and convenient.
**Budget:**
The budget for a 3-day trip to Nepal can vary depending on your accommodation choices, transportation, and activities. However, here's a rough estimate:
* Accommodation: $20-50 per night
* Transportation: $10-20 per day
* Food: $10-20 per meal
* Activities: $10-20 per person
Total estimated budget for 3 days: $200-500 per person
I hope this helps, and you have a wonderful trip to Nepal!
---------- TextMessage (local_agent) ----------
Your 3-day itinerary for Nepal is well-planned and covers many of the country's cultural and natural highlights. Here are a few additional suggestions and tips to enhance your trip:
**Day 1:**
* After visiting the Boudhanath Stupa, consider exploring the surrounding streets, which are filled with Tibetan shops, restaurants, and monasteries.
* In the Thamel area, be sure to try some of the local street food, such as momos or sel roti.
* For dinner, consider trying a traditional Nepali restaurant, such as the Kathmandu Guest House or the Northfield Cafe.
**Day 2:**
* At the Pashupatinath Temple, be respectful of the Hindu rituals and customs. You can also take a stroll along the Bagmati River, which runs through the temple complex.
* At the Kathmandu Durbar Square, consider hiring a guide to provide more insight into the history and significance of the temples and palaces.
* In the afternoon, visit the Patan Museum, which showcases the art and culture of the Kathmandu Valley.
**Day 3:**
* In Bhaktapur, be sure to try some of the local pottery and handicrafts. You can also visit the Bhaktapur National Art Gallery, which features traditional Nepali art.
* At Nagarkot, consider taking a short hike to the nearby villages, which offer stunning views of the Himalayas.
* For sunset, find a spot with a clear view of the mountains, and enjoy the peaceful atmosphere.
**Additional Tips:**
* Nepal is a relatively conservative country, so dress modestly and respect local customs.
* Try to learn some basic Nepali phrases, such as "namaste" (hello) and "dhanyabaad" (thank you).
* Be prepared for crowds and chaos in the cities, especially in Thamel and Kathmandu Durbar Square.
* Consider purchasing a local SIM card or portable Wi-Fi hotspot to stay connected during your trip.
**Accommodation:**
* Consider staying in a hotel or guesthouse that is centrally located and has good reviews.
* Look for accommodations that offer amenities such as free Wi-Fi, hot water, and a restaurant or cafe.
**Transportation:**
* Consider hiring a private vehicle or taxi for the day, as this will give you more flexibility and convenience.
* Be sure to negotiate the price and agree on the itinerary before setting off.
**Budget:**
* Be prepared for variable prices and exchange rates, and have some local currency (Nepali rupees) on hand.
* Consider budgeting extra for unexpected expenses, such as transportation or food.
Overall, your itinerary provides a good balance of culture, history, and natural beauty, and with these additional tips and suggestions, you'll be well-prepared for an unforgettable trip to Nepal!
---------- TextMessage (language_agent) ----------
Your 3-day itinerary for Nepal is well-planned and covers many of the country's cultural and natural highlights. The additional suggestions and tips you provided are excellent and will help enhance the trip experience.
One aspect that is well-covered in your plan is the cultural and historical significance of the destinations. You have included a mix of temples, stupas, and cultural sites, which will give visitors a good understanding of Nepal's rich heritage.
Regarding language and communication challenges, your tip to "try to learn some basic Nepali phrases, such as 'namaste' (hello) and 'dhanyabaad' (thank you)" is excellent. This will help visitors show respect for the local culture and people, and can also facilitate interactions with locals.
Additionally, your suggestion to "consider purchasing a local SIM card or portable Wi-Fi hotspot to stay connected during your trip" is practical and will help visitors stay in touch with family and friends back home, as well as navigate the local area.
Your plan is satisfactory, and with the additional tips and suggestions, visitors will be well-prepared for an unforgettable trip to Nepal. The itinerary provides a good balance of culture, history, and natural beauty, and the tips on language, communication, and logistics will help ensure a smooth and enjoyable journey.
Overall, your plan is well-thought-out, and the additional suggestions and tips will help visitors make the most of their trip to Nepal. Well done!
However, one minor suggestion I might make is to consider including a few phrases in the local language for emergency situations, such as "where is the hospital?" or "how do I get to the airport?" This can help visitors in case of an unexpected situation, and can also give them more confidence when navigating unfamiliar areas.
But overall, your plan is excellent, and with these minor suggestions, it can be even more comprehensive and helpful for visitors to Nepal.
---------- TextMessage (travel_summary_agent) ----------
TERMINATE
Here is the complete and integrated 3-day travel plan to Nepal:
**Day 1: Arrival in Kathmandu and Exploration of the City**
* Arrive at Tribhuvan International Airport in Kathmandu, the capital city of Nepal.
* Check-in to your hotel and freshen up.
* Visit the famous **Boudhanath Stupa**, one of the largest Buddhist stupas in the world.
* Explore the surrounding streets, which are filled with Tibetan shops, restaurants, and monasteries.
* Explore the **Thamel** area, a popular tourist hub known for its narrow streets, shops, and restaurants. Be sure to try some of the local street food, such as momos or sel roti.
* In the evening, enjoy a traditional Nepali dinner and watch a cultural performance at a local restaurant, such as the Kathmandu Guest House or the Northfield Cafe.
**Day 2: Kathmandu Valley Tour**
* Start the day with a visit to the **Pashupatinath Temple**, a sacred Hindu temple dedicated to Lord Shiva. Be respectful of the Hindu rituals and customs, and take a stroll along the Bagmati River, which runs through the temple complex.
* Next, head to the **Kathmandu Durbar Square**, a UNESCO World Heritage Site and the former royal palace of the Malla kings. Consider hiring a guide to provide more insight into the history and significance of the temples and palaces.
* Visit the **Swayambhunath Stupa**, also known as the Monkey Temple, which offers stunning views of the city.
* In the afternoon, visit the **Patan City**, known for its rich cultural heritage and traditional crafts. Explore the **Patan Durbar Square** and visit the **Krishna Temple**, a beautiful example of Nepali architecture. Also, visit the Patan Museum, which showcases the art and culture of the Kathmandu Valley.
**Day 3: Bhaktapur and Nagarkot**
* Drive to **Bhaktapur**, a medieval town and a UNESCO World Heritage Site (approximately 1 hour). Explore the **Bhaktapur Durbar Square**, which features stunning architecture, temples, and palaces. Be sure to try some of the local pottery and handicrafts, and visit the Bhaktapur National Art Gallery, which features traditional Nepali art.
* In the afternoon, drive to **Nagarkot**, a scenic hill station with breathtaking views of the Himalayas (approximately 1.5 hours). Consider taking a short hike to the nearby villages, which offer stunning views of the Himalayas. Find a spot with a clear view of the mountains, and enjoy the peaceful atmosphere during sunset.
**Additional Tips:**
* Make sure to try some local Nepali cuisine, such as momos, dal bhat, and gorkhali lamb.
* Bargain while shopping in the markets, as it's a common practice in Nepal.
* Respect local customs and traditions, especially when visiting temples and cultural sites.
* Stay hydrated and bring sunscreen, as the sun can be strong in Nepal.
* Dress modestly and respect local customs, as Nepal is a relatively conservative country.
* Try to learn some basic Nepali phrases, such as "namaste" (hello), "dhanyabaad" (thank you), "where is the hospital?" and "how do I get to the airport?".
* Consider purchasing a local SIM card or portable Wi-Fi hotspot to stay connected during your trip.
* Be prepared for crowds and chaos in the cities, especially in Thamel and Kathmandu Durbar Square.
**Accommodation:**
* Consider staying in a hotel or guesthouse that is centrally located and has good reviews.
* Look for accommodations that offer amenities such as free Wi-Fi, hot water, and a restaurant or cafe.
**Transportation:**
* Consider hiring a private vehicle or taxi for the day, as this will give you more flexibility and convenience.
* Be sure to negotiate the price and agree on the itinerary before setting off.
**Budget:**
* The budget for a 3-day trip to Nepal can vary depending on your accommodation choices, transportation, and activities. However, here's a rough estimate:
+ Accommodation: $20-50 per night
+ Transportation: $10-20 per day
+ Food: $10-20 per meal
+ Activities: $10-20 per person
* Total estimated budget for 3 days: $200-500 per person
* Be prepared for variable prices and exchange rates, and have some local currency (Nepali rupees) on hand.
* Consider budgeting extra for unexpected expenses, such as transportation or food.
에이전트별 대화내용 요약
| 에이전트 | 대화 내용 요약 |
|---|---|
| planner_agent | 네팔 3일 여행 일정을 제안합니다. 추가 팁: 현지 풍습 존중, 현지 음식 시도, 교통 수단 선택 등 |
| local_agent | planner_agent의 3일 여행 일정을 기반으로 추가적인 제안과 팁을 제공합니다. 추가 팁: 현지 풍습 존중, 기본 네팔어 학습, 현지 시설 이용 등 |
| language_agent | 여행 일정을 평가하고, 추가적인 제안을 제공합니다. 기본 네팔어 학습, 현지 시설 이용, 비상 상황에 대비한 언어 준비 등 |
| travel_summary_agent | 전체적인 3일 여행 계획을 요약합니다. 추가 팁: 현지 풍습 존중, 현지 음식 시도, 교통 수단 선택 등 |
MCP 활용 Agent
참고
- 코드 내 AIOS_BASE_URL인 AIOS_LLM_Private_Endpoint와 MODEL의 MODEL_ID는 LLM 이용 가이드를 참고해주세요.
autogen_mcp.py
배경색 변경
from urllib.parse import urljoin
from autogen_core.models import ModelFamily
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.tools.mcp import McpWorkbench, StdioServerParams
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
# 모델 접근을 위한 API URL과 모델 이름을 설정합니다.
AIOS_BASE_URL = "AIOS_LLM_Private_Endpoint"
MODEL = "MODEL_ID"
# OpenAIChatCompletionClient를 사용하여 모델 클라이언트를 생성합니다.
model_client = OpenAIChatCompletionClient(
model=MODEL,
base_url=urljoin(AIOS_BASE_URL, "v1"),
api_key="EMPTY_KEY",
model_info={
# 이미지를 지원하는 경우 True로 설정합니다.
"vision": False,
# 함수 호출을 지원하는 경우 True로 설정합니다.
"function_calling": True,
# JSON 출력을 지원하는 경우 True로 설정합니다.
"json_output": True,
# 사용하고자 하는 모델이 ModelFamily에서 제공하지 않는 경우 UNKNOWN을 사용합니다.
# "family": ModelFamily.UNKNOWN,
"family": ModelFamily.LLAMA_3_3_70B,
# 구조화된 출력을 지원하는 경우 True로 설정합니다.
"structured_output": True,
}
)
# MCP 서버 파라미터를 설정합니다.
# mcp_server_time은 python으로 구현된 MCP 서버로,
# 내부에 현재 시각을 알려주는 get_current_time, 시간대를 변환해 주는 convert_time 함수가 포함됩니다.
# 이 파라미터는 MCP 서버를 로컬 타임존으로 설정하여 시간을 확인할 수 있도록 합니다.
# 예를 들어, "Asia/Seoul"로 설정하면 한국 시간대에 맞춰 시간을 확인할 수 있습니다.
mcp_server_params = StdioServerParams(
command="python",
args=["-m", "mcp_server_time", "--local-timezone", "Asia/Seoul"],
)
async def main():
"""메인 함수로, MCP 워크벤치를 사용하여 시간을 확인하는 에이전트를 실행합니다."""
# MCP 워크벤치를 사용하여 시간을 확인하는 에이전트를 생성하고 실행합니다.
# 에이전트는 "What time is it now in South Korea?"라는 작업을 수행합니다.
# Console을 사용하여 결과를 출력합니다.
# MCP 워크벤치가 실행되는 동안 에이전트는 시간을 확인하고
# 결과를 스트리밍 방식으로 출력합니다.
# MCP 워크벤치가 종료되면 에이전트도 종료됩니다.
async with McpWorkbench(mcp_server_params) as workbench:
time_agent = AssistantAgent(
"time_assistant",
model_client=model_client,
workbench=workbench,
reflect_on_tool_use=True,
)
await Console(time_agent.run_stream(task="What time is it now in South Korea?"))
await model_client.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())from urllib.parse import urljoin
from autogen_core.models import ModelFamily
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.tools.mcp import McpWorkbench, StdioServerParams
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
# 모델 접근을 위한 API URL과 모델 이름을 설정합니다.
AIOS_BASE_URL = "AIOS_LLM_Private_Endpoint"
MODEL = "MODEL_ID"
# OpenAIChatCompletionClient를 사용하여 모델 클라이언트를 생성합니다.
model_client = OpenAIChatCompletionClient(
model=MODEL,
base_url=urljoin(AIOS_BASE_URL, "v1"),
api_key="EMPTY_KEY",
model_info={
# 이미지를 지원하는 경우 True로 설정합니다.
"vision": False,
# 함수 호출을 지원하는 경우 True로 설정합니다.
"function_calling": True,
# JSON 출력을 지원하는 경우 True로 설정합니다.
"json_output": True,
# 사용하고자 하는 모델이 ModelFamily에서 제공하지 않는 경우 UNKNOWN을 사용합니다.
# "family": ModelFamily.UNKNOWN,
"family": ModelFamily.LLAMA_3_3_70B,
# 구조화된 출력을 지원하는 경우 True로 설정합니다.
"structured_output": True,
}
)
# MCP 서버 파라미터를 설정합니다.
# mcp_server_time은 python으로 구현된 MCP 서버로,
# 내부에 현재 시각을 알려주는 get_current_time, 시간대를 변환해 주는 convert_time 함수가 포함됩니다.
# 이 파라미터는 MCP 서버를 로컬 타임존으로 설정하여 시간을 확인할 수 있도록 합니다.
# 예를 들어, "Asia/Seoul"로 설정하면 한국 시간대에 맞춰 시간을 확인할 수 있습니다.
mcp_server_params = StdioServerParams(
command="python",
args=["-m", "mcp_server_time", "--local-timezone", "Asia/Seoul"],
)
async def main():
"""메인 함수로, MCP 워크벤치를 사용하여 시간을 확인하는 에이전트를 실행합니다."""
# MCP 워크벤치를 사용하여 시간을 확인하는 에이전트를 생성하고 실행합니다.
# 에이전트는 "What time is it now in South Korea?"라는 작업을 수행합니다.
# Console을 사용하여 결과를 출력합니다.
# MCP 워크벤치가 실행되는 동안 에이전트는 시간을 확인하고
# 결과를 스트리밍 방식으로 출력합니다.
# MCP 워크벤치가 종료되면 에이전트도 종료됩니다.
async with McpWorkbench(mcp_server_params) as workbench:
time_agent = AssistantAgent(
"time_assistant",
model_client=model_client,
workbench=workbench,
reflect_on_tool_use=True,
)
await Console(time_agent.run_stream(task="What time is it now in South Korea?"))
await model_client.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())python을 이용하여 파일을 실행하면 MCP 서버로부터 도구의 메타데이터를 가져와서 모델을 호출하고, 모델이 tool calls 메시지를 생성하면
현재 시각을 조회하기 위해 get_current_time 함수를 실행하는 것을 확인할 수 있습니다.
배경색 변경
python autogen_mcp.pypython autogen_mcp.py실행결과
# TextMessage (user): 사용자가 준 입력 메시지
---------- TextMessage (user) ----------
What time is it now in South Korea?
# MCP 서버에서 사용할 수 있는 도구들의 메타데이터 조회
INFO:mcp.server.lowlevel.server:Processing request of type ListToolsRequest
...생략...
INFO:autogen_core.events:{
# MCP 서버에서 사용 가능한 도구들의 메타데이터
"tools": [
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "Get current time in a specific timezones",
"parameters": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA timezone name (e.g., 'America/New_York', 'Europe/London'). Use 'Asia/Seoul' as local timezone if no timezone provided by the user."
}
},
"required": [
"timezone"
],
"additionalProperties": false
},
"strict": false
}
},
{
"type": "function",
"function": {
"name": "convert_time",
"description": "Convert time between timezones",
"parameters": {
"type": "object",
"properties": {
"source_timezone": {
"type": "string",
"description": "Source IANA timezone name (e.g., 'America/New_York', 'Europe/London'). Use 'Asia/Seoul' as local timezone if no source timezone provided by the user."
},
"time": {
"type": "string",
"description": "Time to convert in 24-hour format (HH:MM)"
},
"target_timezone": {
"type": "string",
"description": "Target IANA timezone name (e.g., 'Asia/Tokyo', 'America/San_Francisco'). Use 'Asia/Seoul' as local timezone if no target timezone provided by the user."
}
},
"required": [
"source_timezone",
"time",
"target_timezone"
],
"additionalProperties": false
},
"strict": false
}
}
],
"type": "LLMCall",
# 입력 메시지
"messages": [
{
"content": "You are a helpful AI assistant. Solve tasks using your tools. Reply with TERMINATE when the task has been completed.",
"role": "system"
},
{
"role": "user",
"name": "user",
"content": "What time is it now in South Korea?"
}
],
# 모델 응답
"response": {
"id": "chatcmpl-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"choices": [
{
"finish_reason": "tool_calls",
"index": 0,
"logprobs": null,
"message": {
"content": null,
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "chatcmpl-tool-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"function": {
"arguments": "{\"timezone\": \"Asia/Seoul\"}",
"name": "get_current_time"
},
"type": "function"
}
],
"reasoning_content": null
},
"stop_reason": 128008
}
],
"created": 1751278737,
"model": "MODEL_ID",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 21,
"prompt_tokens": 508,
"total_tokens": 529,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"prompt_logprobs": null
},
"prompt_tokens": 508,
"completion_tokens": 21,
"agent_id": null
}
# ToolCallRequestEvent: 모델로부터 tool call 메시지를 받음
---------- ToolCallRequestEvent (time_assistant) ----------
[FunctionCall(id='chatcmpl-tool-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx', arguments='{"timezone": "Asia/Seoul"}', name='get_current_time')]
INFO:mcp.server.lowlevel.server:Processing request of type ListToolsRequest
# MCP 서버를 통해 tool call 메시지의 함수 실행
INFO:mcp.server.lowlevel.server:Processing request of type CallToolRequest
# ToolCallExecutionEvent: 함수의 실행 결과를 모델에게 전달
---------- ToolCallExecutionEvent (time_assistant) ----------
[FunctionExecutionResult(content='{\n "timezone": "Asia/Seoul",\n "datetime": "2025-06-30T19:18:58+09:00",\n "is_dst": false\n}', name='get_current_time', call_id='chatcmpl-tool-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx', is_error=False)]
...생략...
# TextMessage (time_assistant): 모델이 생성한 최종 답변
---------- TextMessage (time_assistant) ----------
The current time in South Korea is 19:18:58 KST.
TERMINATE
MCP 서버 시간 조회 시스템 로그 분석 결과
MCP(Model Control Protocol) 서버를 통한 시간 조회 시스템의 실행 과정을 보여주는 로그 분석 결과입니다.
요청 정보
| 항목 | 내용 |
|---|---|
| 사용자 요청 | What time is it now in South Korea? |
| 요청 시간 | 2025-06-30 19:18:58 KST |
| 처리 방식 | MCP 서버 도구 호출 |
사용 가능한 도구
| 도구명 | 설명 | 매개변수 | 기본값 |
|---|---|---|---|
get_current_time | 특정 시간대의 현재 시간 조회 | timezone (IANA 시간대 이름) | Asia/Seoul |
convert_time | 시간대 간 시간 변환 | source_timezone, time, target_timezone | Asia/Seoul |
처리 과정
| 단계 | 액션 | 상세 내용 |
|---|---|---|
| 1 | 도구 메타데이터 조회 | MCP 서버에서 사용 가능한 도구 목록 확인 |
| 2 | AI 모델 응답 | get_current_time 함수를 Asia/Seoul 시간대로 호출 |
| 3 | 함수 실행 | MCP 서버가 시간 조회 도구 실행 |
| 4 | 결과 반환 | 구조화된 JSON 형식으로 시간 정보 제공 |
| 5 | 최종 답변 | 사용자에게 읽기 쉬운 형태로 시간 전달 |
함수 호출 상세
| 항목 | 값 |
|---|---|
| 함수명 | get_current_time |
| 매개변수 | {"timezone": "Asia/Seoul"} |
| 호출 ID | chatcmpl-tool-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
| 타입 | function |
실행 결과
| 필드 | 값 | 설명 |
|---|---|---|
timezone | Asia/Seoul | 시간대 |
datetime | 2025-06-30T19:18:58+09:00 | ISO 8601 형식 시간 |
is_dst | false | 서머타임 적용 여부 |
최종 응답
| 항목 | 내용 |
|---|---|
| 응답 메시지 | The current time in South Korea is 19:18:58 KST. |
| 완료 표시 | TERMINATE |
| 응답 시간 | 19:18:58 KST |
사용량 지표표
| 지표 | 값 |
|---|---|
| 프롬프트 토큰 | 508 |
| 완료 토큰 | 21 |
| 총 토큰 사용량 | 529 |
| 처리 시간 | 즉시 (실시간) |
주요 특징
| 특징 | 설명 |
|---|---|
| MCP 프로토콜 활용 | 외부 도구와의 원활한 연동 |
| 한국 시간대 기본 설정 | Asia/Seoul을 기본값으로 사용 |
| 구조화된 응답 | JSON 형식의 명확한 데이터 반환 |
| 자동 완료 표시 | TERMINATE로 작업 완료 알림 |
| 실시간 정보 제공 | 정확한 현재 시간 조회 |
기술적 의의
이는 AI 어시스턴트가 외부 시스템과 연동하여 실시간 정보를 제공하는 현대적인 아키텍처의 예시입니다. MCP를 통해 AI 모델이 다양한 외부 도구와 서비스에 접근할 수 있어, 더욱 실용적이고 동적인 응답이 가능합니다.
마무리
이번 튜토리얼에서는 AIOS에서 제공하는 AI 모델과 autogen을 활용하여 다중 에이전트를 이용하여 여행 일정을 세워 주는 애플리케이션, MCP 서버를 활용하여 외부 도구를 활용할 수 있는 에이전트 애플리케이션을 구현하였습니다. 이를 통해 각각의 관점을 가진 여러 에이전트를 통해 다각도로 문제를 해결하고 외부 도구를 활용할 수 있다는 것을 알게 되었습니다. 본 시스템은 다음과 같은 방식으로 사용자 환경에 맞게 확장 및 커스터마이징할 수 있습니다.
- 에이전트 흐름 조절 : 작업을 진행할 에이전트를 선택할 때 다양한 기법을 활용할 수 있습니다. 신뢰성있는 결과를 위해 에이전트의 순서를 고정하여 구현할 수도 있고, 유연한 처리를 위해 AI 모델이 에이전트를 선택하게 할 수 있습니다. 또한 이벤트 기법을 이용하여 병렬적으로 복수의 에이전트가 작업을 처리하도록 구현할 수도 있습니다.
- 다양한 MCP 서버 도입 : mcp_server_time 외에 이미 구현된 다양한 MCP 서버들이 존재합니다. 이를 활용하여 AI 모델이 유연하게 다양한 외부 도구를 활용하게 하여 유용한 애플리케이션을 구현할 수 있습니다.
이번 튜토리얼을 기반으로 실제 서비스 목적에 따라 적합한 AIOS 기반 협업 도우미를 직접 구축해 보시길 바랍니다.
참고 링크
https://microsoft.github.io/autogen
https://modelcontextprotocol.io/
https://github.com/modelcontextprotocol/servers
1.3.3 - Request Examples
API별 지원되는 SDK
AIOS의 모델은 OpenAI 및 Cohere의 API와 호환되므로 OpenAI, Cohere의 SDK와도 호환됩니다. Samsung Cloud Platform AIOS 서비스에서 지원하는 OpenAI, Cohere 호환 API 목록은 다음과 같습니다.
| API명 | API | 상세 설명 | 지원 SDK |
|---|---|---|---|
| 텍스트 완성 API | 입력값으로 주어진 문자열에 이어지는 자연스러운 문장을 생성합니다. |
| |
| 대화 완성 API | 대화 내용에 뒤이은 답변을 생성합니다. |
| |
| Embeddings API | 텍스트를 고차원 벡터(임베딩)로 변환하여 텍스트 간 유사도 계산, 클러스터링, 검색 등 다양한 자연어 처리(NLP) 작업에 활용할 수 있습니다. |
| |
| Rerank API | 임베딩 모델이나 크로스 인코더 모델을 적용하여 단일 쿼리와 문서 목록의 각 항목 간 관련성을 예측합니다. |
|
표. SDK 호환 API 목록
주의
- Request Examples 가이드는 Python/NodeJS/Go 런타임 환경이 구성된 Virtual Server 환경을 기준으로 설명합니다.
- 실제 실행 시 토큰 수, 메시지 내용이 예시와 다를 수 있습니다.
패키지 설치
사용 중인 실행 환경에 따라 AIOS 모델의 API 요청을 지원하는 SDK 패키지를 설치할 수 있습니다.
배경색 변경
pip install requests openai cohere \
langchain langchain-openai langchain-cohere langchain-togetherpip install requests openai cohere \
langchain langchain-openai langchain-cohere langchain-togethernpm install openai cohere-ai langchain \
@langchain/core @langchain/openai @langchain/coherenpm install openai cohere-ai langchain \
@langchain/core @langchain/openai @langchain/coherego get github.com/openai/openai-go \
github.com/cohere-ai/cohere-go/v2go get github.com/openai/openai-go \
github.com/cohere-ai/cohere-go/v2텍스트 완성 API
텍스트 완성 API는 입력값으로 주어진 문자열에 바로 이어지는 자연스러운 문장을 생성합니다.
non-stream 요청
Request
주의
텍스트 완성 API 입력값으로 오직 문자열만을 사용할 수 있습니다.
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 프롬프트(prompt)가 포함됩니다.
data = {
"model": model,
"prompt": "Hi"
}
# AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
# urljoin 함수를 사용하여 기본 URL과 엔드포인트 경로를 결합합니다.
response = requests.post(urljoin(aios_base_url, "v1/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(body["choices"][0]["text"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 프롬프트(prompt)가 포함됩니다.
data = {
"model": model,
"prompt": "Hi"
}
# AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
# urljoin 함수를 사용하여 기본 URL과 엔드포인트 경로를 결합합니다.
response = requests.post(urljoin(aios_base_url, "v1/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(body["choices"][0]["text"])from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정하고,
# prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
response = client.completions.create(
model=model,
prompt="Hi"
)
# response.choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(response.choices[0].text)from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정하고,
# prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
response = client.completions.create(
model=model,
prompt="Hi"
)
# response.choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(response.choices[0].text)from langchain_openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = OpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# LLM에 "Hi"라는 프롬프트를 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
print(llm.invoke("Hi"))from langchain_openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = OpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# LLM에 "Hi"라는 프롬프트를 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
print(llm.invoke("Hi"))const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 프롬프트(prompt)가 포함됩니다.
const data = {
model: model,
prompt: "Hi",
};
// AIOS API의 v1/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
const body = await response.json();
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(body.choices[0].text);const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 프롬프트(prompt)가 포함됩니다.
const data = {
model: model,
prompt: "Hi",
};
// AIOS API의 v1/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
const body = await response.json();
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(body.choices[0].text);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정하고,
// prompt 매개변수는 AI에게 제공할 입력 텍스트입니다
const completions = await client.completions.create({
model: model,
prompt: "Hi",
});
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(completions.choices[0].text);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정하고,
// prompt 매개변수는 AI에게 제공할 입력 텍스트입니다
const completions = await client.completions.create({
model: model,
prompt: "Hi",
});
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(completions.choices[0].text);import { OpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new OpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// LLM에 "Hi"라는 프롬프트를 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
const completion = await llm.invoke("Hi");
// 생성된 응답을 출력합니다.
// 이 텍스트는 AI 모델이 생성한 응답입니다.
console.log(completion);import { OpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new OpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// LLM에 "Hi"라는 프롬프트를 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
const completion = await llm.invoke("Hi");
// 생성된 응답을 출력합니다.
// 이 텍스트는 AI 모델이 생성한 응답입니다.
console.log(completion);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Prompt: AI에게 제공할 입력 텍스트
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Prompt string `json:"prompt"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
data := PostData{
Model: model,
Prompt: "Hi",
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl + "/v1/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
var v map[string]interface{}
json.Unmarshal(body, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터의 text를 추출합니다.
choice := choices[0].(map[string]interface{})
text := choice["text"]
// AI 모델이 생성한 응답 텍스트를 출력합니다.
fmt.Println(text)
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Prompt: AI에게 제공할 입력 텍스트
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Prompt string `json:"prompt"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
data := PostData{
Model: model,
Prompt: "Hi",
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl + "/v1/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
var v map[string]interface{}
json.Unmarshal(body, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터의 text를 추출합니다.
choice := choices[0].(map[string]interface{})
text := choice["text"]
// AI 모델이 생성한 응답 텍스트를 출력합니다.
fmt.Println(text)
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
"github.com/openai/openai-go/packages/param"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl+"/v1"),
)
// AIOS 모델을 사용하여 completion을 생성합니다.
// openai.CompletionNewParams를 사용하여 모델과 프롬프트를 설정합니다.
completion, err := client.Completions.New(context.TODO(), openai.CompletionNewParams{
Model: openai.CompletionNewParamsModel(model),
Prompt: openai.CompletionNewParamsPromptUnion{OfString: param.Opt[string]{Value: "Hi"}},
})
if err != nil {
panic(err)
}
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
fmt.Println(completion.Choices[0].Text)
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
"github.com/openai/openai-go/packages/param"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl+"/v1"),
)
// AIOS 모델을 사용하여 completion을 생성합니다.
// openai.CompletionNewParams를 사용하여 모델과 프롬프트를 설정합니다.
completion, err := client.Completions.New(context.TODO(), openai.CompletionNewParams{
Model: openai.CompletionNewParamsModel(model),
Prompt: openai.CompletionNewParamsPromptUnion{OfString: param.Opt[string]{Value: "Hi"}},
})
if err != nil {
panic(err)
}
// 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
fmt.Println(completion.Choices[0].Text)
}참고
모델 호출을 위한 aios endpoint-url과 모델 ID 정보는 자원 상세 페이지의 LLM Endpoint 이용 가이드에서 제공됩니다. LLM 사용하기를 참조해 주세요.
Response
choices의 text 필드에 모델의 답변이 포함되어 있는 것을 확인할 수 있습니다.
future president of the United States, I hope you’re doing well. As a
stream 요청
stream 기능을 이용하면 모델이 답변을 전부 완성할 때까지 기다리지 않고, 모델이 토큰을 생성할 때마다 토큰 단위로 답변을 받을 수 있습니다.
Request
stream 파라미터값을 True로 입력합니다.
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 프롬프트(prompt), 그리고 스트리밍 여부(stream)가 포함됩니다.
data = {
"model": model,
"prompt": "Hi",
"stream": True
}
# AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = requests.post(urljoin(aios_base_url, "v1/completions"), json=data, stream=True)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# 응답은 각 줄(line)로 분리되어 전송되므로 iter_lines()로 처리합니다.
for line in response.iter_lines():
if line:
try:
# 'data: ' 접두사를 제거하고 JSON 데이터를 파싱합니다.
body = json.loads(line[len("data: "):])
# 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(body["choices"][0]["text"])
except:
passimport json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 프롬프트(prompt), 그리고 스트리밍 여부(stream)가 포함됩니다.
data = {
"model": model,
"prompt": "Hi",
"stream": True
}
# AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = requests.post(urljoin(aios_base_url, "v1/completions"), json=data, stream=True)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# 응답은 각 줄(line)로 분리되어 전송되므로 iter_lines()로 처리합니다.
for line in response.iter_lines():
if line:
try:
# 'data: ' 접두사를 제거하고 JSON 데이터를 파싱합니다.
body = json.loads(line[len("data: "):])
# 응답 본문의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(body["choices"][0]["text"])
except:
passfrom openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정하고,
# prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = client.completions.create(
model=model,
prompt="Hi",
stream=True
)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 각 청크에서 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(chunk.choices[0].text)from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정하고,
# prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = client.completions.create(
model=model,
prompt="Hi",
stream=True
)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 각 청크에서 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
print(chunk.choices[0].text)from langchain_openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = OpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# LLM에 "Hi"라는 프롬프트를 전달하여 스트리밍 응답을 받습니다.
# stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
response = llm.stream("Hi")
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 각 청크를 출력합니다.
# 이 청크는 AI 모델이 생성한 응답 토큰입니다.
print(chunk)from langchain_openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = OpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# LLM에 "Hi"라는 프롬프트를 전달하여 스트리밍 응답을 받습니다.
# stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
response = llm.stream("Hi")
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 각 청크를 출력합니다.
# 이 청크는 AI 모델이 생성한 응답 토큰입니다.
print(chunk)const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 프롬프트(prompt), 그리고 스트리밍 여부(stream)가 포함됩니다.
const data = {
model: model,
prompt: "Hi",
stream: true,
};
// AIOS API의 v1/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// 응답 본문을 텍스트 디코더 스트림으로 변환하여 읽습니다.
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader();
let buf = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
// 받은 데이터를 버퍼에 추가합니다.
buf += value;
let sep;
// 버퍼에서 줄바꿈 문자(\n\n)를 찾아서 데이터를 분리합니다.
while ((sep = buf.indexOf("\n\n")) >= 0) {
const data = buf.slice(0, sep);
buf = buf.slice(sep + 2);
// 각 줄을 처리합니다.
for (const rawLine of data.split("\n")) {
const line = rawLine.trim();
if (!line.startsWith("data: ")) continue;
// "data: " 접두사를 제거하고 JSON 데이터를 추출합니다.
const payload = line.slice("data: ".length).trim();
if (payload === "[DONE]") break;
// JSON 데이터를 파싱합니다.
const json = JSON.parse(payload);
// choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(json.choices[0].text);
}
}
}const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 프롬프트(prompt), 그리고 스트리밍 여부(stream)가 포함됩니다.
const data = {
model: model,
prompt: "Hi",
stream: true,
};
// AIOS API의 v1/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// 응답 본문을 텍스트 디코더 스트림으로 변환하여 읽습니다.
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader();
let buf = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
// 받은 데이터를 버퍼에 추가합니다.
buf += value;
let sep;
// 버퍼에서 줄바꿈 문자(\n\n)를 찾아서 데이터를 분리합니다.
while ((sep = buf.indexOf("\n\n")) >= 0) {
const data = buf.slice(0, sep);
buf = buf.slice(sep + 2);
// 각 줄을 처리합니다.
for (const rawLine of data.split("\n")) {
const line = rawLine.trim();
if (!line.startsWith("data: ")) continue;
// "data: " 접두사를 제거하고 JSON 데이터를 추출합니다.
const payload = line.slice("data: ".length).trim();
if (payload === "[DONE]") break;
// JSON 데이터를 파싱합니다.
const json = JSON.parse(payload);
// choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(json.choices[0].text);
}
}
}import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정하고,
// prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const completions = await client.completions.create({
model: model,
prompt: "Hi",
stream: true,
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 이벤트를 순차적으로 처리합니다.
for await (const event of completions) {
// 각 이벤트의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(event.choices[0].text);
}import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정하고,
// prompt 매개변수는 AI에게 제공할 입력 텍스트입니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const completions = await client.completions.create({
model: model,
prompt: "Hi",
stream: true,
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 이벤트를 순차적으로 처리합니다.
for await (const event of completions) {
// 각 이벤트의 choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
console.log(event.choices[0].text);
}import { OpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new OpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// LLM에 "Hi"라는 프롬프트를 전달하여 스트리밍 응답을 받습니다.
// stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
const completion = await llm.stream("Hi");
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 청크를 순차적으로 처리합니다.
for await (const chunk of completion) {
// 각 청크를 출력합니다.
// 이 청크는 AI 모델이 생성한 응답 토큰입니다.
console.log(chunk);
}import { OpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAI 클래스를 사용하여 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new OpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// LLM에 "Hi"라는 프롬프트를 전달하여 스트리밍 응답을 받습니다.
// stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
const completion = await llm.stream("Hi");
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 청크를 순차적으로 처리합니다.
for await (const chunk of completion) {
// 각 청크를 출력합니다.
// 이 청크는 AI 모델이 생성한 응답 토큰입니다.
console.log(chunk);
}package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Prompt: AI에게 제공할 입력 텍스트
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Prompt string `json:"prompt"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// Stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
data := PostData{
Model: model,
Prompt: "Hi",
Stream: true,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// HTTP 응답 본문을 스캔하여 줄 단위로 처리합니다.
var v map[string]interface{}
scanner := bufio.NewScanner(response.Body)
for scanner.Scan() {
line := bytes.TrimSpace(scanner.Bytes())
// 줄이 "data: "로 시작하지 않으면 건너뜁니다.
if !bytes.HasPrefix(line, []byte("data: ")) {
continue
}
// "data: " 접두사를 제거합니다.
payload := bytes.TrimPrefix(line, []byte("data: "))
// payload가 "[DONE]"이라면 스트리밍을 종료합니다.
if bytes.Equal(payload, []byte("[DONE]")) {
break
}
// JSON 데이터를 파싱합니다.
json.Unmarshal(payload, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// AI 모델이 생성한 응답 토큰을 추출합니다.
text := choice["text"]
fmt.Println(text)
}
}package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Prompt: AI에게 제공할 입력 텍스트
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Prompt string `json:"prompt"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// Stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
data := PostData{
Model: model,
Prompt: "Hi",
Stream: true,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// HTTP 응답 본문을 스캔하여 줄 단위로 처리합니다.
var v map[string]interface{}
scanner := bufio.NewScanner(response.Body)
for scanner.Scan() {
line := bytes.TrimSpace(scanner.Bytes())
// 줄이 "data: "로 시작하지 않으면 건너뜁니다.
if !bytes.HasPrefix(line, []byte("data: ")) {
continue
}
// "data: " 접두사를 제거합니다.
payload := bytes.TrimPrefix(line, []byte("data: "))
// payload가 "[DONE]"이라면 스트리밍을 종료합니다.
if bytes.Equal(payload, []byte("[DONE]")) {
break
}
// JSON 데이터를 파싱합니다.
json.Unmarshal(payload, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// AI 모델이 생성한 응답 토큰을 추출합니다.
text := choice["text"]
fmt.Println(text)
}
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
"github.com/openai/openai-go/packages/param"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 스트리밍 completion을 생성합니다.
// openai.CompletionNewParams를 사용하여 모델과 프롬프트를 설정합니다.
completion := client.Completions.NewStreaming(context.TODO(), openai.CompletionNewParams{
Model: openai.CompletionNewParamsModel(model),
Prompt: openai.CompletionNewParamsPromptUnion{OfString: param.Opt[string]{Value: "Hi"}},
})
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// Next() 메서드는 다음 청크가 있을 때 true를 반환합니다.
for completion.Next() {
// 현재 청크의 choices 슬라이스를 가져옵니다.
chunk := completion.Current().Choices
// choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
fmt.Println(chunk[0].Text)
}
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
"github.com/openai/openai-go/packages/param"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 스트리밍 completion을 생성합니다.
// openai.CompletionNewParams를 사용하여 모델과 프롬프트를 설정합니다.
completion := client.Completions.NewStreaming(context.TODO(), openai.CompletionNewParams{
Model: openai.CompletionNewParamsModel(model),
Prompt: openai.CompletionNewParamsPromptUnion{OfString: param.Opt[string]{Value: "Hi"}},
})
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// Next() 메서드는 다음 청크가 있을 때 true를 반환합니다.
for completion.Next() {
// 현재 청크의 choices 슬라이스를 가져옵니다.
chunk := completion.Current().Choices
// choices[0].text는 AI 모델이 생성한 응답 텍스트입니다.
fmt.Println(chunk[0].Text)
}
}Response
토큰마다 답변이 생성되고, 각 토큰은 choices의 text 필드에서 확인할 수 있습니다.
I
'm
looking
for
a
way
to
check
if
a
specific
process
is
running
on
대화 완성 API
대화 완성 API는 순서대로 나열된 메시지 목록(맥락)을 입력받으면 모델이 다음 순서로 적합한 메시지를 생성하여 응답합니다.
non-stream 요청
Request
텍스트 메시지로만 이루어진 경우, 다음과 같이 호출할 수 있습니다.
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 메시지 목록(messages)가 포함됩니다.
# 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
data = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# choices[0].message는 AI 모델이 생성한 응답입니다.
print(body["choices"][0]["message"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 메시지 목록(messages)가 포함됩니다.
# 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
data = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# choices[0].message는 AI 모델이 생성한 응답입니다.
print(body["choices"][0]["message"])from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
]
)
# 생성된 응답에서 choices[0].message를 출력합니다.
print(response.choices[0].message.model_dump())from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
]
)
# 생성된 응답에서 choices[0].message를 출력합니다.
print(response.choices[0].message.model_dump())from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 시스템 메시지와 사용자 메시지를 포함합니다.
messages = [
("system", "You are a helpful assistant."),
("human", "Hi"),
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
chat_completion = chat_llm.invoke(messages)
# 생성된 응답을 출력합니다.
print(chat_completion.model_dump())from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 시스템 메시지와 사용자 메시지를 포함합니다.
messages = [
("system", "You are a helpful assistant."),
("human", "Hi"),
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
chat_completion = chat_llm.invoke(messages)
# 생성된 응답을 출력합니다.
print(chat_completion.model_dump())const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 메시지 목록(messages)가 포함됩니다.
// 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
const data = {
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
const body = await response.json();
// 생성된 응답에서 choices[0].message를 출력합니다.
console.log(body.choices[0].message);const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 메시지 목록(messages)가 포함됩니다.
// 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
const data = {
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
const body = await response.json();
// 생성된 응답에서 choices[0].message를 출력합니다.
console.log(body.choices[0].message);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
});
// 생성된 응답에서 choices[0].message를 출력합니다.
console.log(response.choices[0].message);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
});
// 생성된 응답에서 choices[0].message를 출력합니다.
console.log(response.choices[0].message);import { HumanMessage, SystemMessage } from "@langchain/core/messages";
import { ChatOpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// SystemMessage와 HumanMessage 객체를 사용하여 시스템 메시지와 사용자 메시지를 포함합니다.
const messages = [
new SystemMessage("You are a helpful assistant."),
new HumanMessage("Hi"),
];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
const response = await llm.invoke(messages);
// 생성된 응답의 내용(content)을 출력합니다.
// 이 내용은 AI 모델이 생성한 응답 텍스트입니다.
console.log(response.content);import { HumanMessage, SystemMessage } from "@langchain/core/messages";
import { ChatOpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// SystemMessage와 HumanMessage 객체를 사용하여 시스템 메시지와 사용자 메시지를 포함합니다.
const messages = [
new SystemMessage("You are a helpful assistant."),
new HumanMessage("Hi"),
];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
const response = await llm.invoke(messages);
// 생성된 응답의 내용(content)을 출력합니다.
// 이 내용은 AI 모델이 생성한 응답 텍스트입니다.
console.log(response.content);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조를 정의합니다.
// Role: 메시지 역할 (예: system, user)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "system",
Content: "You are a helpful assistant.",
},
{
Role: "user",
Content: "Hi",
},
},
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// AI 모델이 생성한 응답 메시지를 JSON 형식으로 포맷하여 출력합니다.
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조를 정의합니다.
// Role: 메시지 역할 (예: system, user)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "system",
Content: "You are a helpful assistant.",
},
{
Role: "user",
Content: "Hi",
},
},
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// AI 모델이 생성한 응답 메시지를 JSON 형식으로 포맷하여 출력합니다.
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// openai.ChatCompletionNewParams를 사용하여 모델과 메시지 목록을 설정합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("You are a helpful assistant."),
openai.UserMessage("Hi"),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답 메시지를 JSON 형식으로 포맷하여 출력합니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// openai.ChatCompletionNewParams를 사용하여 모델과 메시지 목록을 설정합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("You are a helpful assistant."),
openai.UserMessage("Hi"),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답 메시지를 JSON 형식으로 포맷하여 출력합니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}참고
모델 호출을 위한 aios endpoint-url과 모델 ID 정보는 자원 상세 페이지의 LLM Endpoint 이용 가이드에서 제공됩니다. LLM 사용하기를 참조해 주세요.
Response
choices의 message에서 모델의 답변 내용을 확인할 수 있습니다.
{
'annotations': None,
'audio': None,
'content': 'Hello! How can I help you today?',
'function_call': None,
'reasoning_content': 'The user says "Hi". We respond politely.',
'refusal': None,
'role': 'assistant',
'tool_calls': []
}
stream 요청
stream을 이용하여 모델이 모든 답변을 생성할 때까지 기다렸다가 한번에 응답을 받지 않고, 모델이 생성하는 토큰마다 응답을 받아 처리할 수 있습니다.
Request
stream 파라미터값을 True로 입력합니다.
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 메시지 목록(messages), 그리고 스트리밍 여부(stream)가 포함됩니다.
# 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
data = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
],
"stream": True
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data, stream=True)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# 응답은 각 줄(line)로 분리되어 전송되므로 iter_lines()로 처리합니다.
for line in response.iter_lines():
if line:
try:
# 'data: ' 접두사를 제거하고 JSON 데이터를 파싱합니다.
body = json.loads(line[len("data: "):])
# 델타(choices[0].delta)를 출력합니다.
# 델타는 AI 모델이 생성한 응답 토큰입니다.
print(body["choices"][0]["delta"])
except:
passimport json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 메시지 목록(messages), 그리고 스트리밍 여부(stream)가 포함됩니다.
# 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
data = {
"model": model,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
],
"stream": True
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data, stream=True)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# 응답은 각 줄(line)로 분리되어 전송되므로 iter_lines()로 처리합니다.
for line in response.iter_lines():
if line:
try:
# 'data: ' 접두사를 제거하고 JSON 데이터를 파싱합니다.
body = json.loads(line[len("data: "):])
# 델타(choices[0].delta)를 출력합니다.
# 델타는 AI 모델이 생성한 응답 토큰입니다.
print(body["choices"][0]["delta"])
except:
passfrom openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
],
stream=True
)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 델타(choices[0].delta)를 출력합니다.
# 델타는 AI 모델이 생성한 응답 토큰입니다.
print(chunk.choices[0].delta.model_dump())from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
# stream=True를 설정하여 실시간 스트리밍 응답을 받습니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi"}
],
stream=True
)
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# response는 스트림 형태로 전송되므로 반복하여 처리할 수 있습니다.
for chunk in response:
# 델타(choices[0].delta)를 출력합니다.
# 델타는 AI 모델이 생성한 응답 토큰입니다.
print(chunk.choices[0].delta.model_dump())from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 시스템 메시지와 사용자 메시지를 포함합니다.
messages = [
("system", "You are a helpful assistant."),
("human", "Hi"),
]
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# llm.stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
for chunk in llm.stream(messages):
# 각 청크를 출력합니다.
# 이 청크는 AI 모델이 생성한 응답 토큰입니다.
print(chunk)from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 시스템 메시지와 사용자 메시지를 포함합니다.
messages = [
("system", "You are a helpful assistant."),
("human", "Hi"),
]
# 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
# llm.stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
for chunk in llm.stream(messages):
# 각 청크를 출력합니다.
# 이 청크는 AI 모델이 생성한 응답 토큰입니다.
print(chunk)const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 그리고 스트리밍 여부(stream)가 포함됩니다.
// 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
const data = {
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
stream: true,
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// 응답 본문을 텍스트 디코더 스트림으로 변환하여 읽습니다.
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader();
let buf = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
// 받은 데이터를 버퍼에 추가합니다.
buf += value;
let sep;
// 버퍼에서 줄바꿈 문자(\n\n)를 찾아서 데이터를 분리합니다.
while ((sep = buf.indexOf("\n\n")) >= 0) {
const data = buf.slice(0, sep);
buf = buf.slice(sep + 2);
// 각 줄을 처리합니다.
for (const rawLine of data.split("\n")) {
const line = rawLine.trim();
if (!line.startsWith("data: ")) continue;
// "data: " 접두사를 제거하고 JSON 데이터를 추출합니다.
const payload = line.slice("data: ".length).trim();
if (payload === "[DONE]") break;
// JSON 데이터를 파싱합니다.
const json = JSON.parse(payload);
// 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
console.log(json.choices[0].delta);
}
}
}const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 그리고 스트리밍 여부(stream)가 포함됩니다.
// 메시지 목록은 시스템 메시지와 사용자 메시지를 포함합니다.
const data = {
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
stream: true,
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// 응답 본문을 텍스트 디코더 스트림으로 변환하여 읽습니다.
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader();
let buf = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
// 받은 데이터를 버퍼에 추가합니다.
buf += value;
let sep;
// 버퍼에서 줄바꿈 문자(\n\n)를 찾아서 데이터를 분리합니다.
while ((sep = buf.indexOf("\n\n")) >= 0) {
const data = buf.slice(0, sep);
buf = buf.slice(sep + 2);
// 각 줄을 처리합니다.
for (const rawLine of data.split("\n")) {
const line = rawLine.trim();
if (!line.startsWith("data: ")) continue;
// "data: " 접두사를 제거하고 JSON 데이터를 추출합니다.
const payload = line.slice("data: ".length).trim();
if (payload === "[DONE]") break;
// JSON 데이터를 파싱합니다.
const json = JSON.parse(payload);
// 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
console.log(json.choices[0].delta);
}
}
}import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
stream: true,
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 이벤트를 순차적으로 처리합니다.
for await (const event of response) {
// 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
console.log(event.choices[0].delta);
}import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 시스템 메시지와 사용자 메시지를 포함하는 메시지 목록입니다.
// stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
],
stream: true,
});
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// for await...of 루프를 사용하여 스트림 이벤트를 순차적으로 처리합니다.
for await (const event of response) {
// 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
console.log(event.choices[0].delta);
}import { ChatOpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// 시스템 메시지와 사용자 메시지를 포함합니다.
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
];
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// llm.stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
const completion = await llm.stream(messages);
for await (const chunk of completion) {
// 각 청크의 내용(content)을 출력합니다.
// 이 내용은 AI 모델이 생성한 응답 토큰입니다.
console.log(chunk.content);
}import { ChatOpenAI } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// configuration.baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// 시스템 메시지와 사용자 메시지를 포함합니다.
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hi" },
];
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// llm.stream 메서드는 실시간으로 토큰을 생성하는 스트림을 반환합니다.
const completion = await llm.stream(messages);
for await (const chunk of completion) {
// 각 청크의 내용(content)을 출력합니다.
// 이 내용은 AI 모델이 생성한 응답 토큰입니다.
console.log(chunk.content);
}package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조를 정의합니다.
// Role: 메시지 역할 (예: system, user)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
// Stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "system",
Content: "You are a helpful assistant.",
},
{
Role: "user",
Content: "Hi",
},
},
Stream: true,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// HTTP 응답 본문을 스캔하여 줄 단위로 처리합니다.
var v map[string]interface{}
scanner := bufio.NewScanner(response.Body)
for scanner.Scan() {
line := bytes.TrimSpace(scanner.Bytes())
// 줄이 "data: "로 시작하지 않으면 건너뜁니다.
if !bytes.HasPrefix(line, []byte("data: ")) {
continue
}
// "data: " 접두사를 제거합니다.
payload := bytes.TrimPrefix(line, []byte("data: "))
// payload가 "[DONE]"이라면 스트리밍을 종료합니다.
if bytes.Equal(payload, []byte("[DONE]")) {
break
}
// JSON 데이터를 파싱합니다.
json.Unmarshal(payload, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// 델타(delta)를 JSON 형식으로 직렬화하여 출력합니다.
message, err := json.Marshal(choice["delta"])
if err != nil {
panic(err)
}
fmt.Println(string(message))
}
}package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조를 정의합니다.
// Role: 메시지 역할 (예: system, user)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 응답 여부 (옵션)
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 생성합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
// Stream: true를 설정하여 실시간 스트리밍 응답을 받습니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "system",
Content: "You are a helpful assistant.",
},
{
Role: "user",
Content: "Hi",
},
},
Stream: true,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// HTTP 응답 본문을 스캔하여 줄 단위로 처리합니다.
var v map[string]interface{}
scanner := bufio.NewScanner(response.Body)
for scanner.Scan() {
line := bytes.TrimSpace(scanner.Bytes())
// 줄이 "data: "로 시작하지 않으면 건너뜁니다.
if !bytes.HasPrefix(line, []byte("data: ")) {
continue
}
// "data: " 접두사를 제거합니다.
payload := bytes.TrimPrefix(line, []byte("data: "))
// payload가 "[DONE]"이라면 스트리밍을 종료합니다.
if bytes.Equal(payload, []byte("[DONE]")) {
break
}
// JSON 데이터를 파싱합니다.
json.Unmarshal(payload, &v)
// 응답에서 choices 배열을 추출합니다.
choices := v["choices"].([]interface{})
// 첫 번째 데이터를 추출합니다.
choice := choices[0].(map[string]interface{})
// 델타(delta)를 JSON 형식으로 직렬화하여 출력합니다.
message, err := json.Marshal(choice["delta"])
if err != nil {
panic(err)
}
fmt.Println(string(message))
}
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 스트리밍 채팅 completion을 생성합니다.
// openai.ChatCompletionNewParams를 사용하여 모델과 메시지 목록을 설정합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
response := client.Chat.Completions.NewStreaming(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("You are a helpful assistant."),
openai.UserMessage("Hi"),
},
})
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// Next() 메서드는 다음 청크가 있을 때 true를 반환합니다.
for response.Next() {
// 현재 chunk의 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
chunk := response.Current().Choices[0].Delta
fmt.Println(chunk.RawJSON())
}
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 스트리밍 채팅 completion을 생성합니다.
// openai.ChatCompletionNewParams를 사용하여 모델과 메시지 목록을 설정합니다.
// 메시지 목록에는 시스템 메시지와 사용자 메시지가 포함됩니다.
response := client.Chat.Completions.NewStreaming(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("You are a helpful assistant."),
openai.UserMessage("Hi"),
},
})
// 모델이 토큰을 생성할 때마다 응답으로 받을 수 있습니다.
// Next() 메서드는 다음 청크가 있을 때 true를 반환합니다.
for response.Next() {
// 현재 chunk의 델타(choices[0].delta)를 출력합니다.
// 델타는 AI 모델이 생성한 응답 토큰입니다.
chunk := response.Current().Choices[0].Delta
fmt.Println(chunk.RawJSON())
}
}Response
토큰마다 답변이 생성되고, 각 토큰은 choices의 delta 필드에서 확인할 수 있습니다.
{'role': 'assistant', 'content': ''}
{'reasoning_content': ''}
{'reasoning_content': 'The'}
{'reasoning_content': ' user'}
{'reasoning_content': ' says'}
{'reasoning_content': ' "'}
{'reasoning_content': 'Hi'}
{'reasoning_content': '".'}
{'reasoning_content': ' We'}
{'reasoning_content': ' respond'}
{'reasoning_content': ' with'}
{'reasoning_content': ' a'}
{'reasoning_content': ' greeting'}
{'reasoning_content': '.'}
{'content': ''}
{'content': 'Hello'}
{'content': '!'}
{'content': ' How'}
{'content': ' can'}
{'content': ' I'}
{'content': ' assist'}
{'content': ' you'}
{'content': ' today'}
{'content': '?'}
{}
tool calling
Tool Calling 기능은 모델이 특정 작업을 수행하기 위해 외부 함수를 호출할 수 있게 해줍니다.
모델은 사용자의 요청을 분석하여 필요한 도구를 선택하고, 해당 도구를 호출하기 위한 인수를 응답으로 생성합니다.
모델이 생성한 tool call 메시지를 활용하여 실제 도구를 실행한 다음 그 결과를 tool message로 구성하여 모델에게 다시 요청하면,
도구 실행 결과를 바탕으로 사용자에게 자연스러운 답변을 생성합니다.
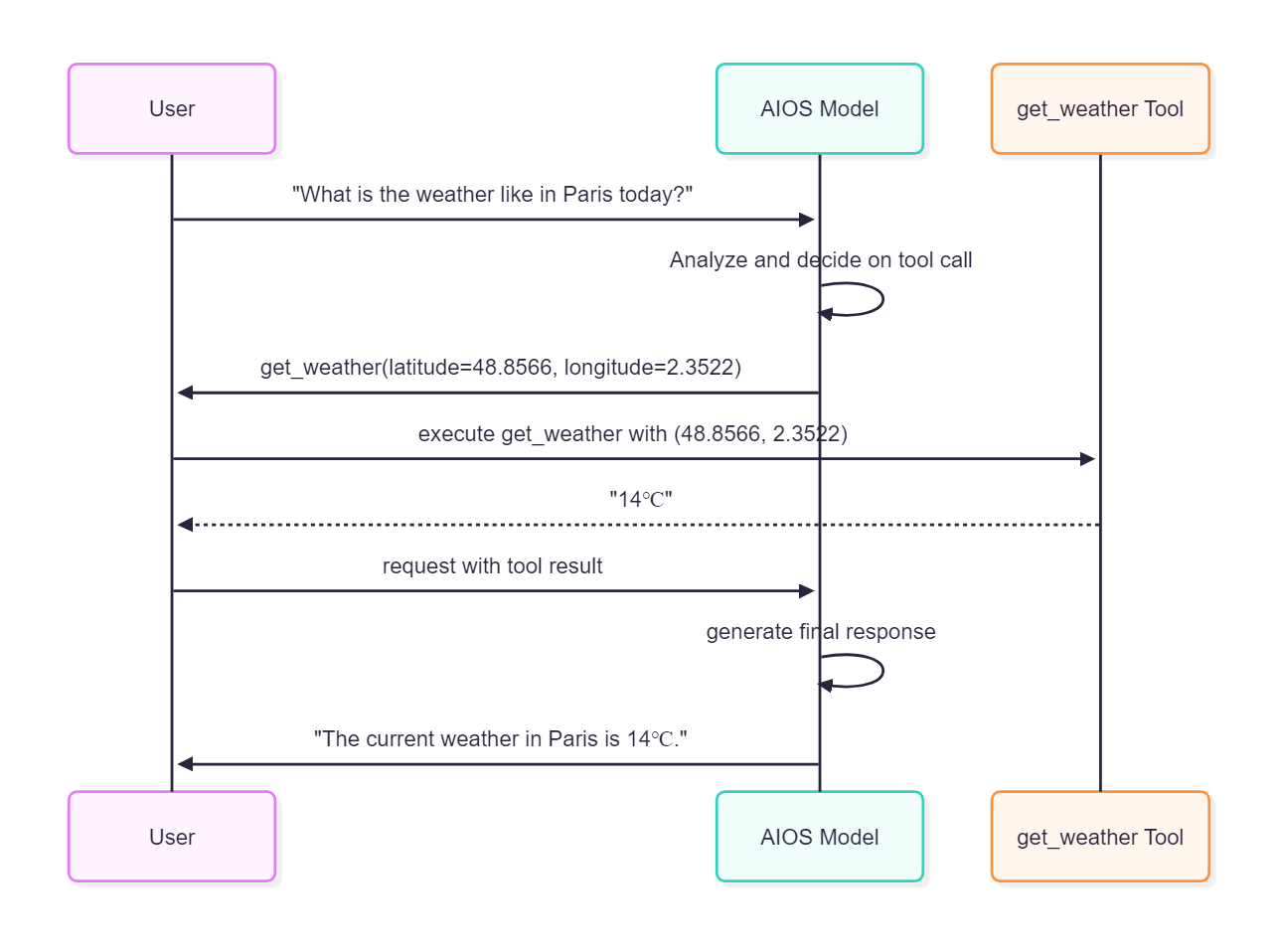
참고
- openai/gpt-oss-120b 모델은 tool calling 기능이 작동되지 않습니다.
Request
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 날씨 정보를 알아보는 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
# 사용자 메시지를 정의합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [{"role": "user", "content": "What is the weather like in Paris today?"}]
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
data = {
"model": model,
"messages": messages,
"tools": tools
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(body["choices"][0]["message"]["tool_calls"])
# 날씨 함수의 구현체, 항상 14도를 응답합니다.
def get_weather(latitude, longitude):
return "14℃"
# 첫 번째 응답에서 도구 호출 정보를 추출합니다.
# 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
tool_call = body["choices"][0]["message"]["tool_calls"][0]
# json 문자열 형식의 도구 호출의 인수를 dict 포맷으로 파싱합니다.
args = json.loads(tool_call["function"]["arguments"])
# 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
# 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result = get_weather(args["latitude"], args["longitude"]) # "14℃"
# 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
# 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.append(body["choices"][0]["message"])
# 실제 함수를 호출한 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append({
"role": "tool",
"tool_call_id": tool_call["id"],
"content": str(result)
})
# 두 번째 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
data = {
"model": model,
"messages": messages,
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response_2 = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response_2.text)
# 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(body["choices"][0]["message"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 날씨 정보를 알아보는 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
# 사용자 메시지를 정의합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [{"role": "user", "content": "What is the weather like in Paris today?"}]
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
data = {
"model": model,
"messages": messages,
"tools": tools
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response.text)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(body["choices"][0]["message"]["tool_calls"])
# 날씨 함수의 구현체, 항상 14도를 응답합니다.
def get_weather(latitude, longitude):
return "14℃"
# 첫 번째 응답에서 도구 호출 정보를 추출합니다.
# 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
tool_call = body["choices"][0]["message"]["tool_calls"][0]
# json 문자열 형식의 도구 호출의 인수를 dict 포맷으로 파싱합니다.
args = json.loads(tool_call["function"]["arguments"])
# 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
# 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result = get_weather(args["latitude"], args["longitude"]) # "14℃"
# 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
# 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.append(body["choices"][0]["message"])
# 실제 함수를 호출한 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append({
"role": "tool",
"tool_call_id": tool_call["id"],
"content": str(result)
})
# 두 번째 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
data = {
"model": model,
"messages": messages,
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response_2 = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
# 응답 본문을 JSON 형식으로 파싱합니다.
body = json.loads(response_2.text)
# 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(body["choices"][0]["message"])import json
from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# 날씨 정보를 알아보는 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
# 사용자 메시지를 정의합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [{"role": "user", "content": "What is the weather like in Paris today?"}]
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools # 모델에게 사용할 수 있는 도구의 메타데이터를 알려 줍니다.
)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(response.choices[0].message.tool_calls[0].model_dump())
# 날씨 함수의 구현체, 항상 14도를 응답합니다.
def get_weather(latitude, longitude):
return "14℃"
# 첫 번째 응답에서 도구 호출 정보를 추출합니다.
# 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
tool_call = response.choices[0].message.tool_calls[0]
# 도구 호출의 인수를 JSON 형식으로 파싱합니다.
args = json.loads(tool_call.function.arguments)
# 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
# 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result = get_weather(args["latitude"], args["longitude"]) # "14℃"
# 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
# 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.append(response.choices[0].message)
# 실제 함수를 호출한 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(result)
})
# 두 번째 채팅 completion을 생성합니다.
# 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
# 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response_2 = client.chat.completions.create(
model=model,
messages=messages,
)
# 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(response_2.choices[0].message.model_dump())import json
from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# 날씨 정보를 알아보는 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
# 사용자 메시지를 정의합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [{"role": "user", "content": "What is the weather like in Paris today?"}]
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools # 모델에게 사용할 수 있는 도구의 메타데이터를 알려 줍니다.
)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(response.choices[0].message.tool_calls[0].model_dump())
# 날씨 함수의 구현체, 항상 14도를 응답합니다.
def get_weather(latitude, longitude):
return "14℃"
# 첫 번째 응답에서 도구 호출 정보를 추출합니다.
# 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
tool_call = response.choices[0].message.tool_calls[0]
# 도구 호출의 인수를 JSON 형식으로 파싱합니다.
args = json.loads(tool_call.function.arguments)
# 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
# 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result = get_weather(args["latitude"], args["longitude"]) # "14℃"
# 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
# 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.append(response.choices[0].message)
# 실제 함수를 호출한 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(result)
})
# 두 번째 채팅 completion을 생성합니다.
# 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
# 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response_2 = client.chat.completions.create(
model=model,
messages=messages,
)
# 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(response_2.choices[0].message.model_dump())from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 날씨 정보를 조회하는 도구 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
@tool
def get_weather(latitude: float, longitude: float) -> str:
"""Get current temperature for provided coordinates in celsius."""
return "14℃"
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 모델에 도구를 바인딩합니다.
# get_weather 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
llm_with_tools = chat_llm.bind_tools([get_weather])
# 채팅 메시지 목록을 구성합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [("human", "What is the weather like in Paris today?")]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 단계에서는 모델이 사용자 질문을 분석하고 필요한 도구 호출을 결정합니다.
response = llm_with_tools.invoke(messages)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(response.tool_calls)
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
# 이는 모델이 이전 대화 내용을 기억하고 연결할 수 있도록 합니다.
messages.append(response)
# 실제 도구 함수를 호출하여 결과를 얻습니다.
# 이 단계에서는 get_weather 함수가 실행되어 날씨 정보를 반환합니다.
tool_call = response.tool_calls[0]
tool_message = get_weather.invoke(tool_call)
# 도구 호출 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append(tool_message)
# 두 번째 요청을 수행하여 최종 답변을 얻습니다.
# 이제 모델은 도구 호출 결과를 바탕으로 사용자에게 적절한 답변을 생성합니다.
response2 = chat_llm.invoke(messages)
# 최종 AI 모델 응답을 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(response2.model_dump())from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 날씨 정보를 조회하는 도구 함수를 정의합니다.
# 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
@tool
def get_weather(latitude: float, longitude: float) -> str:
"""Get current temperature for provided coordinates in celsius."""
return "14℃"
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 모델에 도구를 바인딩합니다.
# get_weather 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
llm_with_tools = chat_llm.bind_tools([get_weather])
# 채팅 메시지 목록을 구성합니다.
# 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages = [("human", "What is the weather like in Paris today?")]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 단계에서는 모델이 사용자 질문을 분석하고 필요한 도구 호출을 결정합니다.
response = llm_with_tools.invoke(messages)
# AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
# 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
print(response.tool_calls)
# 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
# 이는 모델이 이전 대화 내용을 기억하고 연결할 수 있도록 합니다.
messages.append(response)
# 실제 도구 함수를 호출하여 결과를 얻습니다.
# 이 단계에서는 get_weather 함수가 실행되어 날씨 정보를 반환합니다.
tool_call = response.tool_calls[0]
tool_message = get_weather.invoke(tool_call)
# 도구 호출 결과를 messages에 추가합니다.
# 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.append(tool_message)
# 두 번째 요청을 수행하여 최종 답변을 얻습니다.
# 이제 모델은 도구 호출 결과를 바탕으로 사용자에게 적절한 답변을 생성합니다.
response2 = chat_llm.invoke(messages)
# 최종 AI 모델 응답을 출력합니다.
# 이는 사용자 질문에 대한 최종 답변입니다.
print(response2.model_dump())const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 알아보는 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const tools = [
{
type: "function",
function: {
name: "get_weather",
description:
"Get current temperature for provided coordinates in celsius.",
parameters: {
type: "object",
properties: {
latitude: { type: "number" },
longitude: { type: "number" },
},
required: ["latitude", "longitude"],
additionalProperties: false,
},
strict: true,
},
},
];
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [
{ role: "user", content: "What is the weather like in Paris today?" },
];
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
let data = {
model: model,
messages: messages,
tools: tools,
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
let body = await response.json();
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(JSON.stringify(body.choices[0].message.tool_calls));
// 날씨 함수의 구현체, 항상 14도를 응답합니다.
function getWeather(latitude, longitude) {
return "14℃";
}
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
const toolCall = body.choices[0].message.tool_calls[0];
// 도구 호출의 인수를 JSON 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
const args = JSON.parse(toolCall.function.arguments);
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
const result = getWeather(args.latitude, args.longitude);
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.push(body.choices[0].message);
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: String(result),
});
// 두 번째 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
data = {
model: model,
messages: messages,
};
// AIOS API에 다시 POST 요청을 보냅니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
const response2 = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
body = await response2.json();
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
console.log(JSON.stringify(body.choices[0].message));const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 알아보는 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const tools = [
{
type: "function",
function: {
name: "get_weather",
description:
"Get current temperature for provided coordinates in celsius.",
parameters: {
type: "object",
properties: {
latitude: { type: "number" },
longitude: { type: "number" },
},
required: ["latitude", "longitude"],
additionalProperties: false,
},
strict: true,
},
},
];
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [
{ role: "user", content: "What is the weather like in Paris today?" },
];
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
let data = {
model: model,
messages: messages,
tools: tools,
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
// 응답 본문을 JSON 형식으로 파싱합니다.
let body = await response.json();
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(JSON.stringify(body.choices[0].message.tool_calls));
// 날씨 함수의 구현체, 항상 14도를 응답합니다.
function getWeather(latitude, longitude) {
return "14℃";
}
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
const toolCall = body.choices[0].message.tool_calls[0];
// 도구 호출의 인수를 JSON 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
const args = JSON.parse(toolCall.function.arguments);
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
const result = getWeather(args.latitude, args.longitude);
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.push(body.choices[0].message);
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: String(result),
});
// 두 번째 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
data = {
model: model,
messages: messages,
};
// AIOS API에 다시 POST 요청을 보냅니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
const response2 = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
body = await response2.json();
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
console.log(JSON.stringify(body.choices[0].message));import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 알아보는 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const tools = [
{
type: "function",
function: {
name: "get_weather",
description:
"Get current temperature for provided coordinates in celsius.",
parameters: {
type: "object",
properties: {
latitude: { type: "number" },
longitude: { type: "number" },
},
required: ["latitude", "longitude"],
additionalProperties: false,
},
strict: true,
},
},
];
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [
{ role: "user", content: "What is the weather like in Paris today?" },
];
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
const response = await client.chat.completions.create({
model: model,
messages: messages,
tools: tools,
});
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(JSON.stringify(response.choices[0].message.tool_calls));
// 날씨 함수의 구현체, 항상 14도를 응답합니다.
function getWeather(latitude, longitude) {
return "14℃";
}
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
const toolCall = response.choices[0].message.tool_calls[0];
// 도구 호출의 인수를 JSON 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
const args = JSON.parse(toolCall.function.arguments);
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
const result = getWeather(args.latitude, args.longitude);
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.push(response.choices[0].message);
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: String(result),
});
// 두 번째 채팅 completion을 생성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
const response2 = await client.chat.completions.create({
model: model,
messages: messages,
});
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
console.log(JSON.stringify(response2.choices[0].message));import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 알아보는 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const tools = [
{
type: "function",
function: {
name: "get_weather",
description:
"Get current temperature for provided coordinates in celsius.",
parameters: {
type: "object",
properties: {
latitude: { type: "number" },
longitude: { type: "number" },
},
required: ["latitude", "longitude"],
additionalProperties: false,
},
strict: true,
},
},
];
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [
{ role: "user", content: "What is the weather like in Paris today?" },
];
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
const response = await client.chat.completions.create({
model: model,
messages: messages,
tools: tools,
});
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(JSON.stringify(response.choices[0].message.tool_calls));
// 날씨 함수의 구현체, 항상 14도를 응답합니다.
function getWeather(latitude, longitude) {
return "14℃";
}
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
const toolCall = response.choices[0].message.tool_calls[0];
// 도구 호출의 인수를 JSON 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
const args = JSON.parse(toolCall.function.arguments);
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
const result = getWeather(args.latitude, args.longitude);
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages.push(response.choices[0].message);
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: String(result),
});
// 두 번째 채팅 completion을 생성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
const response2 = await client.chat.completions.create({
model: model,
messages: messages,
});
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
console.log(JSON.stringify(response2.choices[0].message));import { HumanMessage } from "@langchain/core/messages";
import { tool } from "@langchain/core/tools";
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 조회하는 도구 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const getWeather = tool(
function (latitude, longitude) {
/**
* Get current temperature for provided coordinates in celsius.
*/
return "14℃";
},
{
name: "get_weather",
description: "Get current temperature for provided coordinates in celsius.",
schema: z.object({
latitude: z.number(),
longitude: z.number(),
}),
}
);
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 모델에 도구를 바인딩합니다.
// getWeather 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const llmWithTools = llm.bindTools([getWeather]);
// 채팅 메시지 목록을 구성합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [new HumanMessage("What is the weather like in Paris today?")];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 지시합니다.
const response = await llmWithTools.invoke(messages);
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(response.tool_calls);
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
// 이는 모델이 이전 대화 내용을 기억하고 연결할 수 있도록 합니다.
messages.push(response);
// 실제 도구 함수를 호출하여 결과를 얻습니다.
// 이 단계에서는 getWeather 함수가 실행되어 날씨 정보를 반환합니다.
const toolCall = response.tool_calls[0];
const toolMessage = await getWeather.invoke(toolCall);
// 도구 호출 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push(toolMessage);
// 두 번째 요청을 수행하여 최종 답변을 얻습니다.
// 이제 모델은 도구 호출 결과를 바탕으로 사용자에게 적절한 답변을 생성합니다.
const response2 = await llm.invoke(messages);
// 최종 AI 모델 응답을 출력합니다.
console.log(response2.content);import { HumanMessage } from "@langchain/core/messages";
import { tool } from "@langchain/core/tools";
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 날씨 정보를 조회하는 도구 함수를 정의합니다.
// 이 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const getWeather = tool(
function (latitude, longitude) {
/**
* Get current temperature for provided coordinates in celsius.
*/
return "14℃";
},
{
name: "get_weather",
description: "Get current temperature for provided coordinates in celsius.",
schema: z.object({
latitude: z.number(),
longitude: z.number(),
}),
}
);
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 모델에 도구를 바인딩합니다.
// getWeather 함수는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
const llmWithTools = llm.bindTools([getWeather]);
// 채팅 메시지 목록을 구성합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
const messages = [new HumanMessage("What is the weather like in Paris today?")];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 지시합니다.
const response = await llmWithTools.invoke(messages);
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
console.log(response.tool_calls);
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
// 이는 모델이 이전 대화 내용을 기억하고 연결할 수 있도록 합니다.
messages.push(response);
// 실제 도구 함수를 호출하여 결과를 얻습니다.
// 이 단계에서는 getWeather 함수가 실행되어 날씨 정보를 반환합니다.
const toolCall = response.tool_calls[0];
const toolMessage = await getWeather.invoke(toolCall);
// 도구 호출 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages.push(toolMessage);
// 두 번째 요청을 수행하여 최종 답변을 얻습니다.
// 이제 모델은 도구 호출 결과를 바탕으로 사용자에게 적절한 답변을 생성합니다.
const response2 = await llm.invoke(messages);
// 최종 AI 모델 응답을 출력합니다.
console.log(response2.content);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant, tool 등)
// Content: 메시지 내용
// ToolCalls: 도구 호출 정보
// ToolCallId: 도구 호출 식별자
type Message struct {
Role string `json:"role"`
Content string `json:"content,omitempty"`
ToolCalls []map[string]any `json:"tool_calls,omitempty"`
ToolCallId string `json:"tool_call_id,omitempty"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Tools: 사용 가능한 도구 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Tools []map[string]any `json:"tools,omitempty"`
Stream bool `json:"stream,omitempty"`
}
// 날씨 정보를 조회하는 함수를 정의합니다.
// 이 함수는 항상 14도를 반환합니다 (샘플 구현).
func getWeather(latitude float32, longitude float32) string {
_ = fmt.Sprintf("latitude: %f, longitude: %f", latitude, longitude)
return "14℃"
}
func main() {
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages := []Message{
{
Role: "user",
Content: "What is the weather like in Paris today?",
},
}
// 날씨 정보를 알아보는 함수
// 이 도구는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools := []map[string]any{
{
"type": "function",
"function": map[string]any{
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": map[string]any{
"type": "object",
"properties": map[string]any{
"latitude": map[string]string{"type": "number"},
"longitude": map[string]string{"type": "number"},
},
"required": []string{"latitude", "longitude"},
"additionalProperties": false,
},
"strict": true,
},
},
}
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
data := PostData{
Model: model,
Messages: messages,
Tools: tools,
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 map 형식으로 파싱합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 첫 번째 응답에서 메시지 정보를 추출합니다.
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
messageData := choice["message"].(map[string]interface{})
toolCalls := messageData["tool_calls"].([]interface{})
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
toolCallJson, err := json.MarshalIndent(toolCalls, "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(toolCallJson))
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
toolCall := toolCalls[0].(map[string]interface{})
function := toolCall["function"].(map[string]interface{})
// JSON 문자열 형식의 도구 호출의 인수를 map 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
var args map[string]float32
err = json.Unmarshal([]byte(function["arguments"].(string)), &args)
if err != nil {
panic(err)
}
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result := getWeather(args["latitude"], args["longitude"])
// 도구 호출 결과를 메시지로 변환합니다.
var toolMessage Message
err = json.Unmarshal(message, &toolMessage)
if err != nil {
panic(err)
}
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages = append(messages, toolMessage)
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages = append(messages, Message{
Role: "tool",
ToolCallId: toolCall["id"].(string),
Content: string(result),
})
// 두 번째 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
data = PostData{
Model: model,
Messages: messages,
}
jsonData, err = json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API에 다시 POST 요청을 보냅니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response2, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response2.Body.Close()
// 두 번째 응답 본문을 읽습니다.
body, err = io.ReadAll(response2.Body)
if err != nil {
panic(err)
}
// 두 번째 응답을 JSON 형식으로 파싱합니다.
json.Unmarshal(body, &v)
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
choices = v["choices"].([]interface{})
choice = choices[0].(map[string]interface{})
message, err = json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant, tool 등)
// Content: 메시지 내용
// ToolCalls: 도구 호출 정보
// ToolCallId: 도구 호출 식별자
type Message struct {
Role string `json:"role"`
Content string `json:"content,omitempty"`
ToolCalls []map[string]any `json:"tool_calls,omitempty"`
ToolCallId string `json:"tool_call_id,omitempty"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Tools: 사용 가능한 도구 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Tools []map[string]any `json:"tools,omitempty"`
Stream bool `json:"stream,omitempty"`
}
// 날씨 정보를 조회하는 함수를 정의합니다.
// 이 함수는 항상 14도를 반환합니다 (샘플 구현).
func getWeather(latitude float32, longitude float32) string {
_ = fmt.Sprintf("latitude: %f, longitude: %f", latitude, longitude)
return "14℃"
}
func main() {
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages := []Message{
{
Role: "user",
Content: "What is the weather like in Paris today?",
},
}
// 날씨 정보를 알아보는 함수
// 이 도구는 제공된 좌표에 대한 현재 온도를 섭씨로 반환합니다.
tools := []map[string]any{
{
"type": "function",
"function": map[string]any{
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": map[string]any{
"type": "object",
"properties": map[string]any{
"latitude": map[string]string{"type": "number"},
"longitude": map[string]string{"type": "number"},
},
"required": []string{"latitude", "longitude"},
"additionalProperties": false,
},
"strict": true,
},
},
}
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 메시지 목록(messages), 및 도구 목록(tools)이 포함됩니다.
data := PostData{
Model: model,
Messages: messages,
Tools: tools,
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하고 필요한 도구 호출을 결정하도록 합니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 map 형식으로 파싱합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 첫 번째 응답에서 메시지 정보를 추출합니다.
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
messageData := choice["message"].(map[string]interface{})
toolCalls := messageData["tool_calls"].([]interface{})
// AI 모델이 생성한 응답에서 도구 호출 정보를 출력합니다.
// 이 정보는 모델이 어떤 도구를 호출해야 하는지를 나타냅니다.
toolCallJson, err := json.MarshalIndent(toolCalls, "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(toolCallJson))
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
toolCall := toolCalls[0].(map[string]interface{})
function := toolCall["function"].(map[string]interface{})
// JSON 문자열 형식의 도구 호출의 인수를 map 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
var args map[string]float32
err = json.Unmarshal([]byte(function["arguments"].(string)), &args)
if err != nil {
panic(err)
}
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result := getWeather(args["latitude"], args["longitude"])
// 도구 호출 결과를 메시지로 변환합니다.
var toolMessage Message
err = json.Unmarshal(message, &toolMessage)
if err != nil {
panic(err)
}
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages = append(messages, toolMessage)
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages = append(messages, Message{
Role: "tool",
ToolCallId: toolCall["id"].(string),
Content: string(result),
})
// 두 번째 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
data = PostData{
Model: model,
Messages: messages,
}
jsonData, err = json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API에 다시 POST 요청을 보냅니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response2, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response2.Body.Close()
// 두 번째 응답 본문을 읽습니다.
body, err = io.ReadAll(response2.Body)
if err != nil {
panic(err)
}
// 두 번째 응답을 JSON 형식으로 파싱합니다.
json.Unmarshal(body, &v)
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
choices = v["choices"].([]interface{})
choice = choices[0].(map[string]interface{})
message, err = json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"context"
"encoding/json"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 날씨 정보를 조회하는 함수를 정의합니다.
// 이 함수는 항상 14도를 반환합니다 (샘플 구현).
func getWeather(latitude float32, longitude float32) string {
_ = fmt.Sprintf("latitude: %f, longitude: %f", latitude, longitude)
return "14℃"
}
func main() {
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages := []openai.ChatCompletionMessageParamUnion{
openai.UserMessage("What is the weather like in Paris today?"),
}
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: messages,
Tools: []openai.ChatCompletionToolParam{
{
Function: openai.FunctionDefinitionParam{
Name: "get_weather",
Description: openai.String("Get current temperature for provided coordinates in celsius."),
Parameters: openai.FunctionParameters{
"type": "object",
"properties": map[string]interface{}{
"latitude": map[string]string{
"type": "number",
},
"longitude": map[string]string{
"type": "number",
},
},
"required": []string{"latitude", "longitude"},
"additionalProperties": false,
},
Strict: openai.Bool(true),
},
},
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 도구 호출 정보를 포함합니다.
fmt.Println([]string{response.Choices[0].Message.ToolCalls[0].RawJSON()})
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
var v map[string]float32
toolCall := response.Choices[0].Message.ToolCalls[0]
args := toolCall.Function.Arguments
// JSON 문자열 형식의 도구 호출의 인수를 map 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
err = json.Unmarshal([]byte(args), &v)
if err != nil {
panic(err)
}
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result := getWeather(v["latitude"], v["longitude"])
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages = append(messages, response.Choices[0].Message.ToParam())
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages = append(messages, openai.ToolMessage(string(result), toolCall.ID))
// 두 번째 채팅 completion을 생성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response2, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: messages,
})
if err != nil {
panic(err)
}
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
fmt.Println(response2.Choices[0].Message.RawJSON())
}package main
import (
"context"
"encoding/json"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 날씨 정보를 조회하는 함수를 정의합니다.
// 이 함수는 항상 14도를 반환합니다 (샘플 구현).
func getWeather(latitude float32, longitude float32) string {
_ = fmt.Sprintf("latitude: %f, longitude: %f", latitude, longitude)
return "14℃"
}
func main() {
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// 사용자 메시지를 정의합니다.
// 사용자는 파리의 오늘 날씨를 묻고 있습니다.
messages := []openai.ChatCompletionMessageParamUnion{
openai.UserMessage("What is the weather like in Paris today?"),
}
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// tools 매개변수는 모델에게 사용할 수 있는 도구의 메타데이터를 제공합니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: messages,
Tools: []openai.ChatCompletionToolParam{
{
Function: openai.FunctionDefinitionParam{
Name: "get_weather",
Description: openai.String("Get current temperature for provided coordinates in celsius."),
Parameters: openai.FunctionParameters{
"type": "object",
"properties": map[string]interface{}{
"latitude": map[string]string{
"type": "number",
},
"longitude": map[string]string{
"type": "number",
},
},
"required": []string{"latitude", "longitude"},
"additionalProperties": false,
},
Strict: openai.Bool(true),
},
},
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 도구 호출 정보를 포함합니다.
fmt.Println([]string{response.Choices[0].Message.ToolCalls[0].RawJSON()})
// 첫 번째 응답에서 도구 호출 정보를 추출합니다.
// 이는 모델이 요청한 도구 호출 정보를 가져옵니다.
var v map[string]float32
toolCall := response.Choices[0].Message.ToolCalls[0]
args := toolCall.Function.Arguments
// JSON 문자열 형식의 도구 호출의 인수를 map 형식으로 파싱합니다.
// 이는 도구 호출에 필요한 파라미터들을 추출합니다.
err = json.Unmarshal([]byte(args), &v)
if err != nil {
panic(err)
}
// 실제 함수를 호출하여 결과를 얻습니다. (예: "14℃")
// 이 단계에서는 실제 날씨 정보 조회 로직이 실행됩니다.
result := getWeather(v["latitude"], v["longitude"])
// 함수의 호출 결과값을 **tool** 메시지로 대화 맥락에 추가하고 다시 모델을 호출하면
// 함수의 호출 결과값을 이용하여 모델이 적절한 답변을 생성합니다.
// 모델의 tool call 메시지를 messages에 추가하여 대화 맥락을 유지합니다.
messages = append(messages, response.Choices[0].Message.ToParam())
// 실제 함수를 호출한 결과를 messages에 추가합니다.
// 이는 모델이 도구 호출 결과를 기반으로 최종 답변을 생성할 수 있도록 합니다.
messages = append(messages, openai.ToolMessage(string(result), toolCall.ID))
// 두 번째 채팅 completion을 생성합니다.
// 여기에는 사용할 모델 ID와 업데이트된 메시지 목록(messages)이 포함됩니다.
// 이 요청은 도구 호출 결과를 바탕으로 최종 답변을 생성합니다.
response2, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: messages,
})
if err != nil {
panic(err)
}
// 두 번째 응답에서 AI가 생성한 메시지를 출력합니다.
// 이는 사용자 질문에 대한 최종 답변입니다.
fmt.Println(response2.Choices[0].Message.RawJSON())
}Response
첫 번째 응답 choices의 message.tool_calls에서 모델이 사용하기 좋다고 판단한 도구의 실행 방법을 확인할 수 있습니다.
tool_calls의 function에서 get_weather 함수를 사용하고, 어떤 인자를 넣어서 실행하는지 확인할 수 있습니다.
[
{
'id': 'chatcmpl-tool-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'type': 'function',
'function': {
'name': 'get_weather',
'arguments': '{"latitude": 48.8566, "longitude": 2.3522}'
}
}
]
두 번째 요청에는 메시지에 3개의 메시지가 포함되었습니다.
- 최초의 사용자 메시지
- 첫 번째 모델이 생성한 tool calling 메시지
- get_weather 도구를 실행한 결과가 들어 있는 tool message
두 번째 응답에서는 위 메시지의 내용을 모두 이용하여 모델이 최종 응답을 생성합니다.
{
'content': 'The current weather in Paris is 14℃.',
'refusal': None,
'role': 'assistant',
'annotations': None,
'audio': None,
'function_call': None,
'tool_calls': [],
'reasoning_content': 'We have user asking weather in Paris today. We called '
'get_weather function with coordinates and got "14℃" as '
'comment. We need to respond. Should incorporate info '
'and maybe note we are using approximate. Provide '
'answer.',
}
reasoning
Request
reasoning을 지원하는 모델의 경우, 다음과 같이 reasoning값을 확인할 수 있습니다.
주의
reasoning 지원 모델은 추론 과정에서 많은 토큰을 생성하므로 답변 생성 시간이 크게 소요될 수 있습니다.
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
data = {
"model": model,
"messages": [
{"role": "user", "content": "Think step by step. 9.11 and 9.8, which is greater?"}
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
body = json.loads(response.text)
# AI 모델이 생성한 응답을 출력합니다.
print(body["choices"][0]["message"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
data = {
"model": model,
"messages": [
{"role": "user", "content": "Think step by step. 9.11 and 9.8, which is greater?"}
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
body = json.loads(response.text)
# AI 모델이 생성한 응답을 출력합니다.
print(body["choices"][0]["message"])from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": "Think step by step. 9.11 and 9.8, which is greater?"}
],
)
# AI 모델이 생성한 응답을 출력합니다.
print(response.choices[0].message.model_dump())from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": "Think step by step. 9.11 and 9.8, which is greater?"}
],
)
# AI 모델이 생성한 응답을 출력합니다.
print(response.choices[0].message.model_dump())from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 사용자는 두 숫자 중 어느 것이 큰지 비교하도록 요청하고 있습니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
messages = [
("human", "Think step by step. 9.11 and 9.8, which is greater?"),
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
chat_completion = chat_llm.invoke(messages)
# AI 모델이 생성한 응답을 출력합니다.
print(chat_completion.model_dump())from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 채팅 메시지 목록을 구성합니다.
# 사용자는 두 숫자 중 어느 것이 큰지 비교하도록 요청하고 있습니다.
# "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
messages = [
("human", "Think step by step. 9.11 and 9.8, which is greater?"),
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
chat_completion = chat_llm.invoke(messages)
# AI 모델이 생성한 응답을 출력합니다.
print(chat_completion.model_dump())const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
const data = {
model: model,
messages: [
{
role: "user",
content: "Think step by step. 9.11 and 9.8, which is greater?",
},
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// AI 모델이 생성한 응답을 출력합니다.
console.log(body.choices[0].message);const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
const data = {
model: model,
messages: [
{
role: "user",
content: "Think step by step. 9.11 and 9.8, which is greater?",
},
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 사용자 질문을 처리하도록 지시합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// AI 모델이 생성한 응답을 출력합니다.
console.log(body.choices[0].message);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: "user",
content: "Think step by step. 9.11 and 9.8, which is greater?",
},
],
});
// AI 모델이 생성한 응답을 출력합니다.
console.log(response.choices[0].message);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: "user",
content: "Think step by step. 9.11 and 9.8, which is greater?",
},
],
});
// AI 모델이 생성한 응답을 출력합니다.
console.log(response.choices[0].message);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant 등)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "user",
Content: "Think step by step. 9.11 and 9.8, which is greater?",
},
},
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 JSON 형식으로 파싱합니다.
// 이는 서버로부터 받은 모델의 응답을 구조화된 데이터로 변환합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
fmt.Println(string(message))
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant 등)
// Content: 메시지 내용
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
func main() {
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 두 숫자 중 어느 것이 큰지 비교하도록 요청합니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "user",
Content: "Think step by step. 9.11 and 9.8, which is greater?",
},
},
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 JSON 형식으로 파싱합니다.
// 이는 서버로부터 받은 모델의 응답을 구조화된 데이터로 변환합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
fmt.Println(string(message))
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.UserMessage("Think step by step. 9.11 and 9.8, which is greater?"),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// "Think step by step"는 모델이 논리적 단계를 거쳐 생각하도록 유도하는 지시어입니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.UserMessage("Think step by step. 9.11 and 9.8, which is greater?"),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}Response
choices의 message 필드를 확인하면 content 외에도 reasoning_content를 확인할 수 있습니다.
reasoning_content는 최종 답변을 생성하기 전 추론(reasoning)단계에서 생성한 토큰을 의미합니다.
{
'annotations': None,
'audio': None,
'content': 'Sure! Let’s compare the two numbers step by step.\n'
'\n'
'1. **Identify the numbers** \n'
' - First number: **9.11** \n'
' - Second number: **9.8**\n'
'\n'
'2. **Look at the whole-number part** \n'
' Both numbers have the same whole‑number part, **9**. So the '
'comparison will depend on the decimal part.\n'
'\n'
'3. **Compare the decimal parts** \n'
' - Decimal part of 9.11 = **0.11** \n'
' - Decimal part of 9.8 = **0.80** (since 9.8 = 9.80)\n'
'\n'
'4. **Determine which decimal part is larger** \n'
' - 0.80 is greater than 0.11.\n'
'\n'
'5. **Conclude** \n'
' Because the whole-number parts are equal and the decimal part '
'of 9.8 is larger, **9.8 is greater than 9.11**.',
'function_call': None,
'reasoning_content': 'User asks: "Think step by step. 9.11 and 9.8, which is '
'greater?" We need to compare numbers 9.11 and 9.8. '
'Value: 9.11 < 9.8, so 9.8 is greater. Provide '
'step-by-step reasoning. No policy conflict.',
'refusal': None,
'role': 'assistant',
'tool_calls': []
}
image to text
vision을 지원하는 모델의 경우, 다음과 같이 이미지를 입력할 수 있습니다.

주의
vision 지원 모델에서의 입력 이미지는 크기 및 개수 제한이 있습니다.
이미지 입력 제한에 대한 내용은 제공 모델을 참조해 주세요.
Request
이미지를 MIME type과 함께 base64로 인코딩된 data URL 형식으로 입력할 수 있습니다.
배경색 변경
import base64
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# 요청 데이터를 구성합니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
data = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 이미지 분석을 요청합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
body = json.loads(response.text)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(body["choices"][0]["message"])import base64
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# 요청 데이터를 구성합니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
data = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
]
}
# AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
# 이 요청은 모델에게 이미지 분석을 요청합니다.
response = requests.post(urljoin(aios_base_url, "v1/chat/completions"), json=data)
body = json.loads(response.text)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(body["choices"][0]["message"])import base64
from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
],
)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(response.choices[0].message.model_dump())import base64
from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# AIOS 모델을 사용하여 채팅 completion을 생성합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
],
)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(response.choices[0].message.model_dump())import base64
from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# 채팅 메시지 목록을 구성합니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 요청은 모델에게 이미지 분석을 요청합니다.
chat_completion = chat_llm.invoke(messages)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(chat_completion.model_dump())import base64
from langchain_openai import ChatOpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
# base_url은 AIOS API의 v1 엔드포인트를 가리키며,
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
chat_llm = ChatOpenAI(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
image_path = "이미지/경로.jpg"
# 이미지를 Base64 인코딩하는 함수를 정의합니다.
# 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
def encode_image(image_path: str):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지를 Base64 형식으로 인코딩합니다.
base64_image = encode_image(image_path)
# 채팅 메시지 목록을 구성합니다.
# 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
# 이미지는 Base64 인코딩된 문자열로 전송됩니다.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "what's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
]
},
]
# 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
# invoke 메서드는 모델의 출력을 반환합니다.
# 이 요청은 모델에게 이미지 분석을 요청합니다.
chat_completion = chat_llm.invoke(messages)
# AI 모델이 생성한 응답을 출력합니다.
# 이 응답은 이미지 내용에 대한 모델의 설명입니다.
print(chat_completion.model_dump())import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const data = {
model: model,
messages: [
{
role: "user",
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
},
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(body.choices[0].message);import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const data = {
model: model,
messages: [
{
role: "user",
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
},
],
};
// AIOS API의 v1/chat/completions 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/chat/completions", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(body.choices[0].message);import OpenAI from "openai";
import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: "user",
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
},
],
});
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(response.choices[0].message);import OpenAI from "openai";
import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// OpenAI 클라이언트를 생성합니다.
// apiKey는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// baseURL은 AIOS API의 v1 엔드포인트를 가리킵니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: "user",
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
},
],
});
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(response.choices[0].message);import { HumanMessage } from "@langchain/core/messages";
import { ChatOpenAI } from "@langchain/openai";
import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const messages = [
new HumanMessage({
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
}),
];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
const response = await llm.invoke(messages);
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(response.content);import { HumanMessage } from "@langchain/core/messages";
import { ChatOpenAI } from "@langchain/openai";
import { readFile } from "fs/promises";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
const imagePath = "이미지/경로.jpg";
// 이미지 파일을 Base64로 변환하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
async function imageFileToBase64(imagePath) {
// 파일 내용을 버퍼로 읽음
const fileBuffer = await readFile(imagePath);
// 버퍼를 Base64 문자열로 변환
return fileBuffer.toString("base64");
}
// 이미지 파일을 Base64 형식으로 변환합니다.
const base64Image = await imageFileToBase64(imagePath);
// LangChain의 ChatOpenAI 클래스를 사용하여 채팅 LLM(대형 언어 모델) 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const llm = new ChatOpenAI({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 채팅 메시지 목록을 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
const messages = [
new HumanMessage({
content: [
{ type: "text", text: "what's in this image?" },
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${base64Image}`,
},
},
],
}),
];
// 채팅 LLM에 메시지 목록을 전달하여 응답을 받습니다.
// invoke 메서드는 모델의 출력을 반환합니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
const response = await llm.invoke(messages);
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
console.log(response.content);package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io"
"net/http"
"os"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
var imagePath = "이미지/경로.jpg"
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant 등)
// Content: 메시지 내용 (텍스트와 이미지 URL 포함)
type Message struct {
Role string `json:"role"`
Content []map[string]interface{} `json:"content"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
// 이미지 파일을 Base64로 인코딩하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
func imageFileToBase64(imagePath string) (string, error) {
data, err := os.ReadFile(imagePath)
if err != nil {
return "", err
}
return base64.StdEncoding.EncodeToString([]byte(data)), nil
}
func main() {
// 이미지 파일을 Base64 형식으로 인코딩합니다.
base64Image, err := imageFileToBase64(imagePath)
if err != nil {
panic(err)
}
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "user",
Content: []map[string]interface{}{
{
"type": "text",
"text": "what's in this image?",
},
{
"type": "image_url",
"image_url": map[string]string{
"url": fmt.Sprintf("data:image/jpeg;base64,%s", base64Image),
},
},
},
},
},
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 JSON 형식으로 파싱합니다.
// 이는 서버로부터 받은 모델의 응답을 구조화된 데이터로 변환합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io"
"net/http"
"os"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
var imagePath = "이미지/경로.jpg"
// 메시지 구조체를 정의합니다.
// Role: 메시지 역할 (user, assistant 등)
// Content: 메시지 내용 (텍스트와 이미지 URL 포함)
type Message struct {
Role string `json:"role"`
Content []map[string]interface{} `json:"content"`
}
// POST 요청 데이터 구조체를 정의합니다.
// Model: 사용할 모델 ID
// Messages: 메시지 목록
// Stream: 스트리밍 여부
type PostData struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream,omitempty"`
}
// 이미지 파일을 Base64로 인코딩하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
func imageFileToBase64(imagePath string) (string, error) {
data, err := os.ReadFile(imagePath)
if err != nil {
return "", err
}
return base64.StdEncoding.EncodeToString([]byte(data)), nil
}
func main() {
// 이미지 파일을 Base64 형식으로 인코딩합니다.
base64Image, err := imageFileToBase64(imagePath)
if err != nil {
panic(err)
}
// 요청 데이터를 구성합니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
data := PostData{
Model: model,
Messages: []Message{
{
Role: "user",
Content: []map[string]interface{}{
{
"type": "text",
"text": "what's in this image?",
},
{
"type": "image_url",
"image_url": map[string]string{
"url": fmt.Sprintf("data:image/jpeg;base64,%s", base64Image),
},
},
},
},
},
}
// 요청 데이터를 JSON 형식으로 직렬화합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/chat/completions 엔드포인트로 POST 요청을 보냅니다.
// 이 요청은 모델에게 이미지 분석을 요청합니다.
response, err := http.Post(aiosBaseUrl+"/v1/chat/completions", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 JSON 형식으로 파싱합니다.
// 이는 서버로부터 받은 모델의 응답을 구조화된 데이터로 변환합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
choices := v["choices"].([]interface{})
choice := choices[0].(map[string]interface{})
message, err := json.MarshalIndent(choice["message"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(message))
}package main
import (
"context"
"encoding/base64"
"fmt"
"os"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
var imagePath = "이미지/경로.jpg"
// 이미지 파일을 Base64로 인코딩하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
func imageFileToBase64(imagePath string) (string, error) {
data, err := os.ReadFile(imagePath)
if err != nil {
return "", err
}
return base64.StdEncoding.EncodeToString([]byte(data)), nil
}
func main() {
// 이미지 파일을 Base64 형식으로 인코딩합니다.
base64Image, err := imageFileToBase64(imagePath)
if err != nil {
panic(err)
}
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.UserMessage([]openai.ChatCompletionContentPartUnionParam{
{
OfText: &openai.ChatCompletionContentPartTextParam{
Text: "what's in this image?",
},
},
{
OfImageURL: &openai.ChatCompletionContentPartImageParam{
ImageURL: openai.ChatCompletionContentPartImageImageURLParam{
URL: fmt.Sprintf("data:image/jpeg;base64,%s", base64Image),
},
},
},
}),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}package main
import (
"context"
"encoding/base64"
"fmt"
"os"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
var imagePath = "이미지/경로.jpg"
// 이미지 파일을 Base64로 인코딩하는 함수를 정의합니다.
// 이는 이미지를 텍스트 형식으로 변환하여 API에 전송할 수 있도록 합니다.
func imageFileToBase64(imagePath string) (string, error) {
data, err := os.ReadFile(imagePath)
if err != nil {
return "", err
}
return base64.StdEncoding.EncodeToString([]byte(data)), nil
}
func main() {
// 이미지 파일을 Base64 형식으로 인코딩합니다.
base64Image, err := imageFileToBase64(imagePath)
if err != nil {
panic(err)
}
// OpenAI 클라이언트를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리킵니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 채팅 completion을 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// messages 매개변수는 사용자 메시지를 포함하는 메시지 목록입니다.
// 이 예제에서는 사용자가 이미지에 대해 질문을 하도록 요청합니다.
// 이미지는 Base64 인코딩된 문자열로 전송됩니다.
response, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Model: model,
Messages: []openai.ChatCompletionMessageParamUnion{
openai.UserMessage([]openai.ChatCompletionContentPartUnionParam{
{
OfText: &openai.ChatCompletionContentPartTextParam{
Text: "what's in this image?",
},
},
{
OfImageURL: &openai.ChatCompletionContentPartImageParam{
ImageURL: openai.ChatCompletionContentPartImageImageURLParam{
URL: fmt.Sprintf("data:image/jpeg;base64,%s", base64Image),
},
},
},
}),
},
})
if err != nil {
panic(err)
}
// AI 모델이 생성한 응답을 출력합니다.
// 이 응답은 이미지 내용에 대한 모델의 설명입니다.
fmt.Println(response.Choices[0].Message.RawJSON())
}Response
다음과 같이 이미지를 분석하여 텍스트를 생성합니다.
{
'annotations': None,
'audio': None,
'content': "Here's what's in the image:\n"
'\n'
'* **A Golden Retriever puppy:** The main focus is a cute, '
'fluffy golden retriever puppy lying on a patch of grass.\n'
'* **A bone:** The puppy is chewing on a pink bone.\n'
'* **Green grass:** The puppy is lying on a vibrant green lawn.\n'
'* **Background:** There’s a bit of foliage and some elements of '
'a garden or yard in the background, including a small shed and '
'some plants.\n'
'\n'
'It’s a really heartwarming image!',
'function_call': None,
'reasoning_content': None,
'refusal': None,
'role': 'assistant',
'tool_calls': []
}
Embeddings API
Embeddings는 입력 텍스트를 정해진 차원의 고차원의 벡터로 변환합니다.
생성된 벡터를 활용하여 텍스트 간 유사도, 클러스터링, 검색 등 다양한 자연어 처리 작업에 활용할 수 있습니다.
Request
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 모델에 전달할 데이터를 구성합니다.
data = {
"model": model,
"input": "What is the capital of France?"
}
# AIOS의 /v1/embeddings API 엔드포인트로 POST 요청을 보냅니다.
response = requests.post(urljoin(aios_base_url, "v1/embeddings"), json=data)
body = json.loads(response.text)
# 응답에서 생성된 임베딩 벡터를 출력합니다.
print(body["data"][0]["embedding"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 모델에 전달할 데이터를 구성합니다.
data = {
"model": model,
"input": "What is the capital of France?"
}
# AIOS의 /v1/embeddings API 엔드포인트로 POST 요청을 보냅니다.
response = requests.post(urljoin(aios_base_url, "v1/embeddings"), json=data)
body = json.loads(response.text)
# 응답에서 생성된 임베딩 벡터를 출력합니다.
print(body["data"][0]["embedding"])from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS의 API 엔드포인트를 지정하고,
# api_key는 dummy 값("EMPTY_KEY")으로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# 임베딩(embedding)을 생성하기 위해 OpenAI 클라이언트의 embeddings.create 메서드를 호출합니다.
# 입력 텍스트와 모델 ID를 전달하여 임베딩 벡터를 생성합니다.
response = client.embeddings.create(
input="What is the capital of France?",
model=model
)
# 생성된 임베딩 벡터를 출력합니다.
print(response.data[0].embedding)from openai import OpenAI
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# OpenAI 클라이언트를 생성합니다.
# base_url은 AIOS의 API 엔드포인트를 지정하고,
# api_key는 dummy 값("EMPTY_KEY")으로 설정됩니다.
client = OpenAI(base_url=urljoin(aios_base_url, "v1"), api_key="EMPTY_KEY")
# 임베딩(embedding)을 생성하기 위해 OpenAI 클라이언트의 embeddings.create 메서드를 호출합니다.
# 입력 텍스트와 모델 ID를 전달하여 임베딩 벡터를 생성합니다.
response = client.embeddings.create(
input="What is the capital of France?",
model=model
)
# 생성된 임베딩 벡터를 출력합니다.
print(response.data[0].embedding)from langchain_together import TogetherEmbeddings
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# TogetherEmbeddings 클래스를 사용하여 임베딩 인스턴스를 생성합니다.
# base_url은 AIOS의 API 엔드포인트를 지정하고,
# api_key는 dummy 값("EMPTY_KEY")으로 설정됩니다.
# model은 사용할 임베딩 모델을 지정합니다.
embeddings = TogetherEmbeddings(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 입력 텍스트에 대한 임베딩 벡터를 생성합니다.
# embed_query 메서드는 단일 문장에 대한 임베딩을 생성합니다.
embedding = embeddings.embed_query("What is the capital of France?")
# 생성된 임베딩 벡터를 출력합니다.
print(embedding)from langchain_together import TogetherEmbeddings
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# TogetherEmbeddings 클래스를 사용하여 임베딩 인스턴스를 생성합니다.
# base_url은 AIOS의 API 엔드포인트를 지정하고,
# api_key는 dummy 값("EMPTY_KEY")으로 설정됩니다.
# model은 사용할 임베딩 모델을 지정합니다.
embeddings = TogetherEmbeddings(
base_url=urljoin(aios_base_url, "v1"),
api_key="EMPTY_KEY",
model=model
)
# 입력 텍스트에 대한 임베딩 벡터를 생성합니다.
# embed_query 메서드는 단일 문장에 대한 임베딩을 생성합니다.
embedding = embeddings.embed_query("What is the capital of France?")
# 생성된 임베딩 벡터를 출력합니다.
print(embedding)const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 모델에 전달할 데이터를 구성합니다.
const data = {
model: model,
input: "What is the capital of France?"
};
// AIOS API의 v1/embeddings 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/embeddings", aios_base_url);
// AIOS의 임베딩 API 엔드포인트로 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// 응답에서 생성된 임베딩 벡터를 출력합니다.
console.log(body.data[0].embedding);const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 모델에 전달할 데이터를 구성합니다.
const data = {
model: model,
input: "What is the capital of France?"
};
// AIOS API의 v1/embeddings 엔드포인트 URL을 생성합니다.
let url = new URL("/v1/embeddings", aios_base_url);
// AIOS의 임베딩 API 엔드포인트로 POST 요청을 보냅니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// 응답에서 생성된 임베딩 벡터를 출력합니다.
console.log(body.data[0].embedding);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 dummy 값("EMPTY_KEY")으로 설정되며,
// baseURL은 AIOS의 API 엔드포인트를 지정합니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// 임베딩(embedding)을 생성하기 위해 OpenAI 클라이언트의 embeddings.create 메서드를 호출합니다.
// 입력 텍스트와 모델 ID를 전달하여 임베딩 벡터를 생성합니다.
const response = await client.embeddings.create({
model: model,
input: "What is the capital of France?",
});
// 생성된 임베딩 벡터를 출력합니다.
console.log(response.data[0].embedding);import OpenAI from "openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// OpenAI 클라이언트를 생성합니다.
// apiKey는 dummy 값("EMPTY_KEY")으로 설정되며,
// baseURL은 AIOS의 API 엔드포인트를 지정합니다.
const client = new OpenAI({
apiKey: "EMPTY_KEY",
baseURL: new URL("v1", aios_base_url).href,
});
// 임베딩(embedding)을 생성하기 위해 OpenAI 클라이언트의 embeddings.create 메서드를 호출합니다.
// 입력 텍스트와 모델 ID를 전달하여 임베딩 벡터를 생성합니다.
const response = await client.embeddings.create({
model: model,
input: "What is the capital of France?",
});
// 생성된 임베딩 벡터를 출력합니다.
console.log(response.data[0].embedding);import { OpenAIEmbeddings } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAIEmbeddings 클래스를 사용하여 임베딩 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const embeddings = new OpenAIEmbeddings({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 입력 텍스트에 대한 임베딩 벡터를 생성합니다.
// embedQuery 메서드는 단일 문장에 대한 임베딩을 생성합니다.
const response = await embeddings.embedQuery("What is the capital of France?");
// 생성된 임베딩 벡터를 출력합니다.
console.log(response);import { OpenAIEmbeddings } from "@langchain/openai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// LangChain의 OpenAIEmbeddings 클래스를 사용하여 임베딩 인스턴스를 생성합니다.
// base_url은 AIOS API의 v1 엔드포인트를 가리키며,
// api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
const embeddings = new OpenAIEmbeddings({
model: model,
apiKey: "EMPTY_KEY",
configuration: {
baseURL: new URL("v1", aios_base_url).href,
},
});
// 입력 텍스트에 대한 임베딩 벡터를 생성합니다.
// embedQuery 메서드는 단일 문장에 대한 임베딩을 생성합니다.
const response = await embeddings.embedQuery("What is the capital of France?");
// 생성된 임베딩 벡터를 출력합니다.
console.log(response);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Input: 임베딩을 생성할 입력 텍스트
type PostData struct {
Model string `json:"model"`
Input string `json:"input"`
}
func main() {
// 요청 데이터를 생성합니다.
data := PostData{
Model: model,
Input: "What is the capital of France?",
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/embeddings 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/embeddings", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
responseData := v["data"].([]interface{})
firstData := responseData[0].(map[string]interface{})
// 첫 번째 데이터의 임베딩 벡터를 JSON 형식으로 포맷하여 출력합니다.
embedding, err := json.MarshalIndent(firstData["embedding"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(embedding))
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Input: 임베딩을 생성할 입력 텍스트
type PostData struct {
Model string `json:"model"`
Input string `json:"input"`
}
func main() {
// 요청 데이터를 생성합니다.
data := PostData{
Model: model,
Input: "What is the capital of France?",
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v1/embeddings 엔드포인트로 POST 요청을 보냅니다.
response, err := http.Post(aiosBaseUrl+"/v1/embeddings", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
responseData := v["data"].([]interface{})
firstData := responseData[0].(map[string]interface{})
// 첫 번째 데이터의 임베딩 벡터를 JSON 형식으로 포맷하여 출력합니다.
embedding, err := json.MarshalIndent(firstData["embedding"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(embedding))
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 임베딩을 생성합니다.
// openai.EmbeddingNewParams를 사용하여 모델과 입력 텍스트를 설정합니다.
// 입력 텍스트는 "What is the capital of France?"입니다.
completion, err := client.Embeddings.New(context.TODO(), openai.EmbeddingNewParams{
Model: model,
Input: openai.EmbeddingNewParamsInputUnion{
OfString: openai.String("What is the capital of France?"),
},
})
if err != nil {
panic(err)
}
// 생성된 임베딩 벡터를 출력합니다.
fmt.Println(completion.Data[0].Embedding)
}package main
import (
"context"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// OpenAI 클라이언트를 생성합니다.
// option.WithBaseURL을 사용하여 AIOS API의 v1 엔드포인트를 설정합니다.
client := openai.NewClient(
option.WithBaseURL(aiosBaseUrl + "/v1"),
)
// AIOS 모델을 사용하여 임베딩을 생성합니다.
// openai.EmbeddingNewParams를 사용하여 모델과 입력 텍스트를 설정합니다.
// 입력 텍스트는 "What is the capital of France?"입니다.
completion, err := client.Embeddings.New(context.TODO(), openai.EmbeddingNewParams{
Model: model,
Input: openai.EmbeddingNewParamsInputUnion{
OfString: openai.String("What is the capital of France?"),
},
})
if err != nil {
panic(err)
}
// 생성된 임베딩 벡터를 출력합니다.
fmt.Println(completion.Data[0].Embedding)
}참고
모델 호출을 위한 aios endpoint-url과 모델 ID 정보는 자원 상세 페이지의 LLM Endpoint 이용 가이드에서 제공됩니다. LLM 사용하기를 참조해 주세요.
Response
data의 embedding에 벡터 형태로 변환된 값을 응답으로 받습니다.
[
0.01319122314453125,
0.057220458984375,
-0.028533935546875,
-0.0008697509765625,
-0.01422119140625,
...생략...
]
Rerank API
Rerank는 주어진 문서들에 대해서 query와 연관도를 계산하여 순위를 부여합니다.
연관있는 문서를 앞쪽으로 조정하여 RAG(Retrieval-Augmented Generation) 구조의 애플리케이션의 성능을 향상시키는데 도움이 될 수 있습니다.
Request
배경색 변경
import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 쿼리(query), 문서 목록(documents), 그리고 상위 N개 결과(top_n)가 포함됩니다.
data = {
"model": model,
"query": "What is the capital of France?",
"documents": [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
],
"top_n": 3
}
# AIOS API의 v2/rerank 엔드포인트로 POST 요청을 보냅니다.
# 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
response = requests.post(urljoin(aios_base_url, "v2/rerank"), json=data)
body = json.loads(response.text)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print(body["results"])import json
import requests
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# 요청 데이터를 구성합니다.
# 여기에는 사용할 모델 ID, 쿼리(query), 문서 목록(documents), 그리고 상위 N개 결과(top_n)가 포함됩니다.
data = {
"model": model,
"query": "What is the capital of France?",
"documents": [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
],
"top_n": 3
}
# AIOS API의 v2/rerank 엔드포인트로 POST 요청을 보냅니다.
# 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
response = requests.post(urljoin(aios_base_url, "v2/rerank"), json=data)
body = json.loads(response.text)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print(body["results"])import cohere
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# Cohere 클라이언트를 생성합니다.
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# base_url은 AIOS API의 기본 경로를 가리킵니다.
client = cohere.ClientV2("EMPTY_KEY", base_url=aios_base_url)
# 문서 목록을 정의합니다.
# 이 문서들은 검색할 문서들입니다.
docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
]
# AIOS 모델을 사용하여 문서를 재정렬합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# query 매개변수는 검색할 쿼리입니다.
# documents 매개변수는 검색할 문서 목록입니다.
# top_n 매개변수는 상위 N개의 결과를 반환합니다.
response = client.rerank(
model=model,
query="What is the capital of France?",
documents=docs,
top_n=3,
)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print([result.model_dump() for result in response.results])import cohere
from urllib.parse import urljoin
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# Cohere 클라이언트를 생성합니다.
# api_key는 AIOS에서 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# base_url은 AIOS API의 기본 경로를 가리킵니다.
client = cohere.ClientV2("EMPTY_KEY", base_url=aios_base_url)
# 문서 목록을 정의합니다.
# 이 문서들은 검색할 문서들입니다.
docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
]
# AIOS 모델을 사용하여 문서를 재정렬합니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
# query 매개변수는 검색할 쿼리입니다.
# documents 매개변수는 검색할 문서 목록입니다.
# top_n 매개변수는 상위 N개의 결과를 반환합니다.
response = client.rerank(
model=model,
query="What is the capital of France?",
documents=docs,
top_n=3,
)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print([result.model_dump() for result in response.results])from langchain_cohere.rerank import CohereRerank
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# CohereRerank 클래스를 사용하여 reranker 인스턴스를 생성합니다.
# base_url은 AIOS API의 기본 경로를 가리킵니다.
# cohere_api_key는 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
rerank = CohereRerank(
base_url=aios_base_url,
cohere_api_key="EMPTY_KEY",
model=model
)
# 문서 목록을 정의합니다.
# 이 문서들은 재정렬할 문서들입니다.
docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
]
# reranker를를 사용하여 문서들을 재정렬합니다.
# documents 매개변수는 재정렬할 문서 목록입니다.
# query 매개변수는 검색할 쿼리입니다.
# top_n 매개변수는 상위 N개의 결과를 반환합니다.
ranks = rerank.rerank(
documents=docs,
query="What is the capital of France?",
top_n=3
)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print(ranks)from langchain_cohere.rerank import CohereRerank
aios_base_url = "<<aios endpoint-url>>" # AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" # AIOS 모델 호출을 위한 모델 ID를 입력합니다.
# CohereRerank 클래스를 사용하여 reranker 인스턴스를 생성합니다.
# base_url은 AIOS API의 기본 경로를 가리킵니다.
# cohere_api_key는 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
# model 매개변수는 사용할 모델 ID를 지정합니다.
rerank = CohereRerank(
base_url=aios_base_url,
cohere_api_key="EMPTY_KEY",
model=model
)
# 문서 목록을 정의합니다.
# 이 문서들은 재정렬할 문서들입니다.
docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France."
]
# reranker를를 사용하여 문서들을 재정렬합니다.
# documents 매개변수는 재정렬할 문서 목록입니다.
# query 매개변수는 검색할 쿼리입니다.
# top_n 매개변수는 상위 N개의 결과를 반환합니다.
ranks = rerank.rerank(
documents=docs,
query="What is the capital of France?",
top_n=3
)
# 재정렬된 결과를 출력합니다.
# 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
print(ranks)const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 쿼리(query), 문서 목록(documents), 그리고 상위 N개 결과(top_n)가 포함됩니다.
const data = {
model: model,
query: "What is the capital of France?",
documents: [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
],
top_n: 3,
};
// AIOS API의 v2/rerank 엔드포인트 URL을 생성합니다.
let url = new URL("/v2/rerank", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 엔드포인트는 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(body.results);const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// 요청 데이터를 구성합니다.
// 여기에는 사용할 모델 ID, 쿼리(query), 문서 목록(documents), 그리고 상위 N개 결과(top_n)가 포함됩니다.
const data = {
model: model,
query: "What is the capital of France?",
documents: [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
],
top_n: 3,
};
// AIOS API의 v2/rerank 엔드포인트 URL을 생성합니다.
let url = new URL("/v2/rerank", aios_base_url);
// AIOS API에 POST 요청을 보냅니다.
// 이 엔드포인트는 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const body = await response.json();
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(body.results);import { CohereClientV2 } from "cohere-ai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// CohereClientV2 클라이언트를 생성합니다.
// token은 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// environment는 AIOS API의 기본 경로를 가리킵니다.
const cohere = new CohereClientV2({
token: "EMPTY_KEY",
environment: aios_base_url,
});
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
const docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
];
// AIOS 모델을 사용하여 문서를 재정렬합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// query 매개변수는 검색할 쿼리입니다.
// documents 매개변수는 재정렬할 문서 목록입니다.
// topN 매개변수는 상위 N개의 결과를 반환합니다.
const response = await cohere.rerank({
model: model,
query: "What is the capital of France?",
documents: docs,
topN: 3,
});
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(response.results);import { CohereClientV2 } from "cohere-ai";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// CohereClientV2 클라이언트를 생성합니다.
// token은 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// environment는 AIOS API의 기본 경로를 가리킵니다.
const cohere = new CohereClientV2({
token: "EMPTY_KEY",
environment: aios_base_url,
});
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
const docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
];
// AIOS 모델을 사용하여 문서를 재정렬합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// query 매개변수는 검색할 쿼리입니다.
// documents 매개변수는 재정렬할 문서 목록입니다.
// topN 매개변수는 상위 N개의 결과를 반환합니다.
const response = await cohere.rerank({
model: model,
query: "What is the capital of France?",
documents: docs,
topN: 3,
});
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(response.results);import { CohereClientV2 } from "cohere-ai";
import { CohereRerank } from "@langchain/cohere";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// CohereClientV2 클라이언트를 생성합니다.
// token은 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// environment는 AIOS API의 기본 경로를 가리킵니다.
const cohere = new CohereClientV2({
token: "EMPTY_KEY",
environment: aios_base_url,
});
// CohereRerank 클래스를 사용하여 재정렬기 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// client 매개변수는 위에서 생성한 CohereClientV2 인스턴스를 전달합니다.
const reranker = new CohereRerank({
model: model,
client: cohere,
});
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
const docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
];
// 검색할 쿼리를 정의합니다.
const query = "What is the capital of France?";
// reranker의 rerank 메서드를 사용하여 문서들을 재정렬합니다.
// 첫 번째 인자는 재정렬할 문서 목록입니다.
// 두 번째 인자는 검색할 쿼리입니다.
const response = await reranker.rerank(docs, query);
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(response);import { CohereClientV2 } from "cohere-ai";
import { CohereRerank } from "@langchain/cohere";
const aios_base_url = "<<aios endpoint-url>>"; // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
const model = "<<model>>"; // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
// CohereClientV2 클라이언트를 생성합니다.
// token은 API 요청을 위해 요구하는 키로, 일반적으로 "EMPTY_KEY"로 설정됩니다.
// environment는 AIOS API의 기본 경로를 가리킵니다.
const cohere = new CohereClientV2({
token: "EMPTY_KEY",
environment: aios_base_url,
});
// CohereRerank 클래스를 사용하여 재정렬기 인스턴스를 생성합니다.
// model 매개변수는 사용할 모델 ID를 지정합니다.
// client 매개변수는 위에서 생성한 CohereClientV2 인스턴스를 전달합니다.
const reranker = new CohereRerank({
model: model,
client: cohere,
});
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
const docs = [
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
];
// 검색할 쿼리를 정의합니다.
const query = "What is the capital of France?";
// reranker의 rerank 메서드를 사용하여 문서들을 재정렬합니다.
// 첫 번째 인자는 재정렬할 문서 목록입니다.
// 두 번째 인자는 검색할 쿼리입니다.
const response = await reranker.rerank(docs, query);
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
console.log(response);package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Query: 검색할 쿼리
// Documents: 재정렬할 문서 목록
// TopN: 상위 N개의 결과를 반환
type PostData struct {
Model string `json:"model"`
Query string `json:"query"`
Documents []string `json:"documents"`
TopN int32 `json:"top_n"`
}
func main() {
// 요청 데이터를 생성합니다.
// 쿼리는 "What is the capital of France?"이고,
// 문서 목록은 세 개의 문장으로 구성됩니다.
// TopN은 3으로 설정하여 상위 3개의 결과를 반환합니다.
data := PostData{
Model: model,
Query: "What is the capital of France?",
Documents: []string{
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
},
TopN: 3,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v2/rerank 엔드포인트로 POST 요청을 보냅니다.
// 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
response, err := http.Post(aiosBaseUrl+"/v2/rerank", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 재정렬된 결과를 JSON 형식으로 포맷하여 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
rerank, err := json.MarshalIndent(v["results"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(rerank))
}package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
// POST 요청에 사용될 데이터 구조를 정의합니다.
// Model: 사용할 모델 ID
// Query: 검색할 쿼리
// Documents: 재정렬할 문서 목록
// TopN: 상위 N개의 결과를 반환
type PostData struct {
Model string `json:"model"`
Query string `json:"query"`
Documents []string `json:"documents"`
TopN int32 `json:"top_n"`
}
func main() {
// 요청 데이터를 생성합니다.
// 쿼리는 "What is the capital of France?"이고,
// 문서 목록은 세 개의 문장으로 구성됩니다.
// TopN은 3으로 설정하여 상위 3개의 결과를 반환합니다.
data := PostData{
Model: model,
Query: "What is the capital of France?",
Documents: []string{
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
},
TopN: 3,
}
// 데이터를 JSON 형식으로 마샬링합니다.
jsonData, err := json.Marshal(data)
if err != nil {
panic(err)
}
// AIOS API의 v2/rerank 엔드포인트로 POST 요청을 보냅니다.
// 쿼리와 문서 목록을 비교하여 관련성 높은 문서를 재정렬합니다.
response, err := http.Post(aiosBaseUrl+"/v2/rerank", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer response.Body.Close()
// 응답 본문을 모두 읽습니다.
body, err := io.ReadAll(response.Body)
if err != nil {
panic(err)
}
// 응답 본문을 맵 형식으로 언마샬링합니다.
var v map[string]interface{}
json.Unmarshal(body, &v)
// 재정렬된 결과를 JSON 형식으로 포맷하여 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
rerank, err := json.MarshalIndent(v["results"], "", " ")
if err != nil {
panic(err)
}
fmt.Println(string(rerank))
}package main
import (
"context"
"fmt"
api "github.com/cohere-ai/cohere-go/v2"
client "github.com/cohere-ai/cohere-go/v2/client"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// Cohere 클라이언트를 생성합니다.
// WithBaseURL을 사용하여 AIOS API의 기본 경로를 설정합니다.
co := client.NewClient(
client.WithBaseURL(aiosBaseUrl),
)
// 검색할 쿼리를 정의합니다.
query := "What is the capital of France?"
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
docs := []string{
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
}
// AIOS 모델을 사용하여 문서를 재정렬합니다.
// &api.V2RerankRequest를 사용하여 모델, 쿼리, 문서 목록을 설정합니다.
resp, err := co.V2.Rerank(
context.TODO(),
&api.V2RerankRequest{
Model: model,
Query: query,
Documents: docs,
},
)
if err != nil {
panic(err)
}
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
fmt.Println(resp.Results)
}package main
import (
"context"
"fmt"
api "github.com/cohere-ai/cohere-go/v2"
client "github.com/cohere-ai/cohere-go/v2/client"
)
const (
aiosBaseUrl = "<<aios endpoint-url>>" // AIOS 모델 호출을 위한 aios endpoint-url을 입력합니다.
model = "<<model>>" // AIOS 모델 호출을 위한 모델 ID를 입력합니다.
)
func main() {
// Cohere 클라이언트를 생성합니다.
// WithBaseURL을 사용하여 AIOS API의 기본 경로를 설정합니다.
co := client.NewClient(
client.WithBaseURL(aiosBaseUrl),
)
// 검색할 쿼리를 정의합니다.
query := "What is the capital of France?"
// 문서 목록을 정의합니다.
// 이 문서들은 재정렬할 문서들입니다.
docs := []string{
"The capital of France is Paris.",
"France capital city is known for the Eiffel Tower.",
"Paris is located in the north-central part of France.",
}
// AIOS 모델을 사용하여 문서를 재정렬합니다.
// &api.V2RerankRequest를 사용하여 모델, 쿼리, 문서 목록을 설정합니다.
resp, err := co.V2.Rerank(
context.TODO(),
&api.V2RerankRequest{
Model: model,
Query: query,
Documents: docs,
},
)
if err != nil {
panic(err)
}
// 재정렬된 결과를 출력합니다.
// 이 결과는 쿼리와 문서 간의 관련성 점수를 기준으로 정렬된 문서 목록입니다.
fmt.Println(resp.Results)
}참고
모델 호출을 위한 aios endpoint-url과 모델 ID 정보는 자원 상세 페이지의 LLM Endpoint 이용 가이드에서 제공됩니다. LLM 사용하기를 참조해 주세요.
Response
results에서 query와 연관도가 높은 순서대로 정렬된 documents를 확인할 수 있습니다.
[
{'document': {'text': 'The capital of France is Paris.'},
'index': 0,
'relevance_score': 0.9999659061431885},
{'document': {'text': 'France capital city is known for the Eiffel Tower.'},
'index': 1,
'relevance_score': 0.9663000106811523},
{'document': {'text': 'Paris is located in the north-central part of France.'},
'index': 2,
'relevance_score': 0.7127546668052673}
]
1.4 - Release Note
2025.07.01
NEW
AIOS 서비스 정식 출시- AIOS 서비스를 정식 출시하였습니다.
- Samsung Cloud Platform에서 Virtual Server, GPU Server, Kubernetes Engine 자원을 생성한 후, 해당 자원에서 LLM을 이용할 수 있습니다.
1.5 - Licenses
AIOS Licenses
AIOS 제공 모델별 Liscense 정보는 다음과 같습니다.
| Model | License |
|---|---|
| openai/gpt-oss-120b | Apache 2.0 |
| Qwen/Qwen3-Coder-30B-A3B-Instruct | Apache 2.0 |
| Qwen/Qwen3-30B-A3B-Thinking-2507 | Apache 2.0 |
| meta-llama/Llama-4-Scout | llama4 |
| meta-llama/Llama-Guard-4-12B | llama4 |
| sds/bge-m3 | Samsung SDS |
| sds/bge-reranker-v2-m3 | Samsung SDS |
표. AIOS 제공 모델별 Licenses
1.5.1 - Llama-4-Scout
LLAMA 4 COMMUNITY LICENSE AGREEMENT
Llama 4 Version Effective Date: April 5, 2025
“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 4 distributed by Meta at https://www.llama.com/docs/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
“Llama 4” means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 4 and Documentation (and any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display "Built with Llama" on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include "Llama" at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a "Notice" text file distributed as a part of such copies: "Llama 4 is licensed under the Llama 4 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at [https://www.llama.com/llama4/use-policy](https://www.llama.com/llama4/use-policy)), which is hereby incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 4 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use "Llama" (the "Mark") solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at [https://about.meta.com/brand/resources/meta/company-brand/](https://about.meta.com/brand/resources/meta/company-brand/)[)](https://en.facebookbrand.com/). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 4 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
1.5.2 - Llama-Guard-4-12B
LLAMA 4 COMMUNITY LICENSE AGREEMENT
Llama 4 Version Effective Date: April 5, 2025
“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 4 distributed by Meta at https://www.llama.com/docs/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
“Llama 4” means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 4 and Documentation (and any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty- free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a “Notice” text file distributed as a part of such copies: “Llama 4 is licensed under the Llama 4 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.com/llama4/use-policy), which is hereby incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 4 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross- claim or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 4 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
1.5.3 - bge-m3
MIT License
Copyright (c) [year] [fullname]
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
1.5.4 - bge-reranker-v2-m3
모델 개요
BGE Reranker 기반으로 한글 검색 능력을 강화하기 위해서 public dataset 인 aihub 016(행정), 021(책), 151(법률/금융) , 일반상식 110만건(Query-Passage Pair) 으로 한글기반 리랭킹 능력 강화
- 모델 유형: Reranker
- 주요 용도: Vector Search (RAG)
- Vocab.size: 250,002
- 버젼정보: v1.0.0
- 베이스모델 라이센스: apache-2.0
기술적 특징
- 구조: XLMRobertaModel 기반
- Max Input Token : 1024(Max 8K 이나 파인튜닝시 1024로 파인튜닝)
- 크기: ~568M 파라미터 (2.27GB, FP32)
- 학습데이터: aihub 016(행정), 021(책), 151(법률/금융) , 일반상식 110만건 으로 한글기반 리랭킹 능력 강화
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2023 The k8sgpt Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
1.5.5 - Qwen3-Coder-30B-A3B
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2023 The k8sgpt Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
1.5.6 - gpt-oss-120b
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2023 The k8sgpt Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
1.5.7 - Qwen3-30B-A3B-Thinking
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2023 The k8sgpt Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
2 - CloudML
2.1 - Overview
서비스 개요
CloudML은 클라우드 환경에서 데이터 분석부터 모델 개발, 학습, 검증, 배포까지 머신러닝 전 과정을 지원하는 통합 플랫폼입니다.
특장점
- Cloud ML은 분석가, 머신러닝 엔지니어, 개발자 등 다양한 역할의 사용자가 하나의 환경에서 협업하고, 손쉽게 머신러닝 워크플로우를 설계하고 운영할 수 있도록 설계되었습니다.
- Cloud ML은 Python과 R을 기반으로 분석 환경을 제공하며, 프로그래밍 경험이 있는 사용자는 더욱 유연하고 효과적으로 플랫폼을 활용할 수 있습니다. 특히, 생성형 AI 기반의 Copilot 기능을 이용하면 자연어 입력만으로 코드 작성, 리펙토링, 오류 수정, 함수 추천 등을 손쉽게 수행할 수 있어, 분석 생산성과 분석 접근성을 높여줍니다.
- Cloud ML은 분석 환경 구성, 모델 개발 및 서빙, 분석 자동화, 시각화 등 각 단계를 체계적으로 지원합니다. 반복적인 실험과 운영 자동화를 통해 생산성과 모델 품질을 모두 향상시킬 수 있도록 지원합니다.
서비스 구성도
CloudML은 분석 환경, 머신러닝 라이프사이클 관리, 자동분석 지원, 시각화, 생성형 AI 기반 Copilot 기능 등으로 구성되어 있으며, 사용자는 이 구성요소를 통해 머신러닝 전 과정을 통합적으로 수행할 수 있습니다.
제공 기능
CloudML은 다음과 같은 기능을 제공하고 있습니다.
- 시각적 모델링: Drag&Drop 방식으로 코딩 없이 머신러닝 모델을 구축하고 배포할 수 있는 직관적인 인터페이스를 제공합니다. 데이터 불러오기부터 모델 평가, 배포까지 모든 과정을 쉽게 관리할 수 있습니다.
- 코드 기반 개발: Jupyter Notebook 환경에서 Python, R 등을 사용하여 자유롭게 코드를 작성하고 실행할 수 있습니다. 고급 사용자 및 연구자를 위한 강력한 기능을 제공합니다.
- 워크플로우 자동화: 데이터 전처리, 모델 학습, 평가, 배포 등 복잡한 머신러닝 워크플로우를 효율적으로 자동화합니다.
- 실험 관리: 다양한 파라미터 조합으로 머신러닝 모델을 학습시키고, 그 결과를 체계적으로 관리하고 비교할 수 있습니다.
- Copilot 기능 활용: 자연어 기반의 AI 어시스턴트 기능을 제공하여 모델 개발 과정을 가이드하고 자동화합니다. 코드 생성, 리펙토링, 오류 수정, 설명 등 다양한 작업을 지원하여 생산성을 향상시킵니다.
- 통합 플랫폼: 모든 기능이 CloudML 내에서 통합되어 편리하게 사용할 수 있습니다.
- 확장성 및 유연성: 필요에 따라 컴퓨팅 자원 확장 및 다양한 데이터 소스 연결을 지원합니다.
제약 사항
CloudML 사용 전 아래 제약 사항을 반드시 확인하고, 서비스 이용 계획에 반영하세요. Cloud ML은 Kubernetes 기반 환경에서 동작하므로, 안정적인 서비스 운영을 위해 적절한 클러스터 자원 설정이 필요합니다.
- Application 기본 자원: Application 구동을 위해 최소 vCPU 24코어, 메모리 96GBi가 기본적으로 할당됩니다.
- 분석 작업 자원: 분석 작업 수행을 위해서는 위 기본 자원 외에 추가적인 CPU 또는 GPU 자원 설정이 필요합니다. 분석 작업의 부하량을 고려하여 적절히 설정해야 합니다.
- Copilot (CPU 기반 사용): Copilot을 CPU 자원에서 실행하려면 최소 vCPU 16코어, 메모리 10GBi가 필요합니다. 이 경우, 분석 작업에 사용 가능한 CPU 자원은 그만큼 줄어듭니다.
- Copilot (GPU 기반 사용): Copilot은 전용 GPU 자원을 설정하여 사용할 수도 있습니다.
- 지원 LLM 모델: 현재 Copilot에 적용 가능한 LLM 모델은 Llama3로 제한됩니다.
리전별 제공 현황
CloudML은 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. CloudML 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Container | Container Registry | 컨테이너 이미지를 저장, 관리, 공유하는 서비스 |
| Container | Kubernetes Engine | Kubernetes 컨테이너 오케스트레이션 서비스 |
| Networking | Load Balancer | 서버 트래픽 부하를 자동으로 분산하는 서비스 |
표. CloudML 선행 서비스
2.2 - How-to guides
CloudML 생성하기
사용자는 Samsung Cloud Platform Console을 통해 CloudML의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
CloudML을 생성하려면 다음 절차를 따르세요.
모든 서비스 > AI/ML > CloudML 메뉴를 클릭하세요. CloudML의 Service Home 페이지로 이동합니다.
Service Home 페이지에서 CloudML 생성 버튼을 클릭하세요. CloudML 페이지로 이동합니다.
CloudML 생성 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
버전 선택 영역에서 해당 서비스의 버전을 선택하세요.
구분 필수 여부상세 설명 버전 선택 필수 CloudML 버전 선택 표. CloudML 서비스 버전 선택 항목SCP Kubernetes Engine에서 배포 영역에서 서비스 생성에 필요한 옵션을 선택하세요.
구분 필수 여부상세 설명 클러스터명 필수 Kubernetes Engine 클러스터 선택 표. CloudML 서비스 클러스터 선택 항목서비스 정보 입력 영역에서 서비스 생성에 필요한 옵션을 선택하세요.
구분 필수 여부상세 설명 CloudML명 필수 서비스명 입력 설명 선택 서비스 설명 입력 도메인명 필수 서비스에서 사용할 도메인명 입력 - 영문 소문자, 숫자, 특수문자를 사용해 2-63자 입력
엔드포인트 필수 서비스에서 사용할 엔드포인트 선택 - Private과 Public 중 선택
Copilot 선택 서비스에서 Copilot 사용 여부 선택 - 신청 선택 시 팝업창에서 약관 동의 필요
- 선택한 클러스터가 LLM 전용 GPU로 구성되지 않고, LLM 할당 자원이 충분하지 않은 경우 Copilot 신청 불가
자원 정보 필수 선택한 클러스터의 자원 정보 표시 SCR 정보 입력 필수 서비스에서 사용할 SCR 정보 입력 - 프라이빗 엔드포인트, 인증키, 시크릿 키 입력
표. CloudML 서비스 정보 입력 항목추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 태그 추가 - 자원 당 최대 50개까지 추가 가능
- 태그 추가 버튼을 클릭한 후 Key, Value 값을 입력 또는 선택
표. CloudML 추가 정보 입력 항목
요약 패널에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, CloudML 목록 페이지에서 생성한 자원을 확인하세요.
CloudML 상세 정보 확인하기
CloudML 서비스의 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. CloudML 상세 페이지는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
CloudML 상세정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > CloudML 메뉴를 클릭하세요. CloudML의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 상세 정보를 확인할 자원(CloudML)을 클릭하세요. CloudML 상세 페이지로 이동합니다.
- CloudML 상세 페이지에는 CloudML의 상태 정보 및 상세 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
구분 상세 설명 서비스 상태 CloudML의 상태 - Creating: 생성 중
- Deployed: 생성 완료/정상 작동 중
- Updating: 설정 업데이트 중
- Terminating: 삭제 중
- Error: 에러 발생
접속 가이드 서비스 접속 가이드 - 사용자 PC에 등록할 host 정보 안내
서비스 해지 서비스를 해지하는 버튼 표. CloudML 상태 정보 및 부가 기능
- CloudML 상세 페이지에는 CloudML의 상태 정보 및 상세 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
CloudML 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID |
| 자원명 | 자원 이름 |
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 상품명 | CloudML 이름 |
| Copilot | Copilot 사용 여부 |
| 설명 | 서비스에 대한 설명 |
| 클러스터명 | 선택한 Kubernetes Engine 클러스터명 |
| 도메인명 | 입력한 서비스 도메인명 |
| 버전 | 선택한 서비스 버전 |
| 설치 노드 정보 | 클러스터에 설치된 노드 정보 |
| SCR 정보 | 입력한 SCR 정보 |
표. CloudML 상세 정보 항목
태그
CloudML 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. CloudML 태그 탭 항목
작업 이력
CloudML 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. 작업 이력 탭 상세 정보 항목
CloudML 서비스 해지하기
사용자는 Samsung Cloud Platform Console을 통해 CloudML 서비스를 해지할 수 있습니다.
참고
CloudML 서비스 상태가 Creating, Updating, Terminating인 경우에는 서비스를 해지할 수 없습니다.
CloudML을 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > CloudML 메뉴를 클릭하세요. CloudML의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 서비스 해지 버튼을 클릭하세요. 서비스 해지 알림창이 나타납니다.
- 알림창에서 삭제할 CloudML 이름을 입력하고 확인 버튼을 클릭하세요.
2.2.1 - Kubernetes 클러스터 구성
Kubernetes 클러스터 구성하기
CloudML 서비스를 신청하기 위해서는 CloudML만을 위한 전용 클러스터가 구성되어 있어야 합니다. 전용 클러스터란 요구되는 최소 사양 이상의 Kubernetes Engine을 생성하고 몇 가지 필요 사항을 설정하는 것을 의미합니다. CloudML 서비스를 신청하기 전에 전용 클러스터를 미리 생성하세요.
- 클러스터를 생성하는 방법은 클러스터 생성 가이드를 참고하세요.
- CloudML은 443 포트의 HTTPS 엔드포인트를 노출합니다. 클러스터 생성 시 퍼블릭 엔드포인트를 선택하세요.
클러스터 노드 및 저장소 권장 사양
클러스터 노드는 클러스터 생성 후 추가하거나 수정할 수 있습니다. 다음은 사용자 5명을 기준으로 CloudML를 설치하기 위해 준비되어야 하는 클러스터 노드 및 저장소의 권장 사양입니다.
| 구분 | 항목 | 역할 | 용량 |
|---|---|---|---|
| 클러스터 노드 | Kubernetes 노드 풀 (Virtual Server) | Application 구동
| 24 core / 96 GBi |
| 클러스터 노드 | Kubernetes 노드 풀 (Virtual Server) | Analysis 실행
| 8 core / 32 GBi x 2 EA
|
| 저장소 | File Storage | 데이터 저장 | 1 TB |
표. 클러스터 노드 및 저장소 권장 사양 항목
안내
노드 개수의 변경, GPU 노드 추가 또는 리소스 증설 등 사양 변경이 필요한 경우에는 기술 지원을 요청하세요.
- 기술 지원 안내 페이지: https://www.samsungsds.com/kr/support/support_tech.html
- 기술 지원 신청 메일: brightics.cs@samsung.com
노드에 라벨 추가하기
클러스터 노드 및 저장소 권장 사양에서 제시한 역할별로 노드에 라벨을 직접 추가하세요.
- 노드 YAML에 라벨을 추가하는 방법은 노드 YAML 편집하기 가이드를 참고하세요.
클러스터 노드에 라벨을 추가하려면 다음 절차를 따르세요.
- 모든 서비스 > Container > Kubernetes Engine 메뉴를 클릭하세요. Kubernetes Engine의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 노드 메뉴를 클릭하세요. 노드 목록 페이지로 이동합니다.
- 노드 목록 페이지에서 상세 정보를 확인하려는 클러스터를 왼쪽 상단의 톱니바퀴 버튼에서 선택한 후, 확인 버튼을 클릭하세요.
- 상세 정보를 확인하려는 노드를 선택해 클릭하세요. 노드 상세 페이지로 이동합니다.
- 노드 상세 페이지에서 YAML 탭을 클릭하세요. YAML 탭 페이지로 이동합니다.
- YAML 탭 페이지에서 편집 버튼을 클릭하세요. 노드 편집창이 열립니다.
- 노드 편집창에서 역할에 맞는 라벨을 추가하고 저장 버튼을 클릭하세요.
- 다음 정보를 확인해 노드 사양에 맞는 라벨을 추가합니다.
구분 목적별 라벨 CPU 노드 - 앱용:
node.kubernetes.io/nodetype: ml-app
- 분석용:
node.kubernetes.io/nodetype: ml-analytics
GPU 노드 - 분석용:
node.kubernetes.io/nodetype: ml-analytics-gpu
- copilot용:
node.kubernetes.io/nodetype: ml-gpu
표. Kubernetes 노드의 목적별 라벨 항목 - 앱용:
- 다음 정보를 확인해 노드 사양에 맞는 라벨을 추가합니다.
2.3 - API Reference
API Reference
2.4 - CLI Reference
CLI Reference
2.5 - Release Note
CloudML
2025.07.01
NEW
CloudML 서비스 정식 버전 출시- Samsung Cloud Platform을 통해 클라우드 환경에서 데이터 분석부터 모델 개발, 학습, 검증, 배포까지 머신러닝 전 과정을 지원하는 CloudML 서비스를 출시하였습니다.
3 - AI&MLOps Platform
3.1 - Overview
서비스 개요
AI&MLOps Platform은 머신러닝 모델의 개발, 학습, 배포 과정 전체 파이프라인의 반복적인 작업을 자동화하는 머신러닝 플랫폼입니다. AI&MLOps Platform 서비스를 통해 Kubernetes 기반의 AI/MLOps 환경을 기반으로, 학습 데이터와 모델, 운영 데이터의 통합적인 관리가 가능합니다.
AI&MLOps Platform은 머신러닝 모델의 개발, 학습, 튜닝, 배포 기능을 활용할 수 있는 오픈소스 상품인 Kubeflow.Mini 서비스와 분산학습 Job 실행 및 모니터링 등 Add-on 기능을 추가한 Enterprise 서비스를 제공합니다.
참고
AI&MLOps Platform 관련 사이트는 Kubeflow를 참고하세요.
특장점
Cloud Native MLOps 환경 제공: AI&MLOps Platform은 클라우드에 최적화된 머신러닝 모델 개발 환경을 제공하며, Kubernetes 기반으로 다양한 오픈소스와의 연계가 편리합니다.
머신 러닝 개발 및 운영 편의성: TensorFlow, PyTorch, scikit-learn, Keras 등 다양한 머신러닝 프레임워크를 지원하는 표준화된 환경을 제공합니다. 머신러닝 모델의 개발, 학습, 배포 과정의 전체 Pipeline을 자동화하여 제공함으로써 모델 구성 및 생성이 쉽고 재사용이 용이합니다.
GPU 연계 활용 강화: Bare Metal Server 기반의 Multi Node GPU 및 GPUDirect RDMA(Remote Direct Memory Access)를 통해 LLM(Large Language Model)과 자연어처리(NLP)의 Job 속도를 획기적으로 개선할 수 있습니다.
서비스 구성도
제공 기능
AI&MLOps Platform은 다음과 같은 기능을 제공하고 있습니다.
ML 모델 개발 환경 및 기능
- Notebook 제공: ML Framework(Tensorflow, Pytorch 등)를 포함한 Jupyter Notebook과 VS Code를 생성합니다.
- TensorBoard: TensorBoard(*ML 모델 학습과정 시각화/분석 도구) 서버를 생성하고 관리합니다.
- Volumes: ML 모델 개발 시 데이터셋과 모델 저장, Jupyter Notebook 생성 시 Volume 연결하여 사용합니다.
ML 모델 분산훈련 Job 수행/관리
- 분산학습 Job 실행 및 모니터링, 추론서비스 관리 및 분석을 지원합니다. (Add-on)
- Job Queue 관리 등 MLOps 환경 구성을 위한 다양한 기능을 제공합니다. (Add-on)
- Job Scheduler(FIFO, Bin-packing, Gang 기반), GPU Fraction, GPU 자원 모니터링 등 효율적인 GPU 자원 활용 기능을 제공합니다. (Add-on)
- BM 기반의 Multi Node GPU 및 GPU Direct RDMA(Remote Direct Memory Access)를 통해LLM(Large Language Model)과 자연어처리(NLP)의 Job 속도를 획기적으로 개선하였습니다. (Add-on)
ML 모델 실험관리 및 파이프라인
- ML 파이프라인 실험관리를 위한 Experiments(KFP)를 제공합니다.
- ML Task를 단계적으로 구성하여 실행하기 위한 Pipeline 자동화 구성 기능을 지원합니다.
구성 요소
운영체제 버전
AI&MLOps Platform에서 지원하는 운영체제는 다음과 같습니다.
| 운영체제(OS) | 버전 |
|---|---|
| RHEL | RHEL 8.3 |
| Ubuntu | Ubuntu 18.04, Ubuntu 20.04, Ubuntu 22.04 |
표. 지원하는 운영체제 버전
리전별 제공 현황
AI&MLOps Platform은 아래의 환경에서 제공 가능합니다.
| 리전 | 제공 여부 |
|---|---|
| 한국 서부(kr-west1) | 제공 |
| 한국 동부(kr-east1) | 제공 |
| 한국 남부1(kr-south1) | 미제공 |
| 한국 남부2(kr-south2) | 미제공 |
| 한국 남부3(kr-south3) | 미제공 |
표. AI&MLOps Platform 리전별 제공 현황
선행 서비스
해당 서비스를 생성하기 전에 미리 구성되어 있어야 하는 서비스 목록입니다. 자세한 내용은 각 서비스 별로 제공되는 가이드를 참고하여 사전에 준비하세요.
| 서비스 카테고리 | 서비스 | 상세 설명 |
|---|---|---|
| Container | Kubernetes Engine | Kubernetes 컨테이너 오케스트레이션 서비스 |
표. AI&MLOps Platform 선행 서비스
3.2 - How-to guides
AI&MLOps Platform 생성하기
사용자는 Samsung Cloud Platform Console을 통해 AI&MLOps Platform의 필수 정보를 입력하고, 상세 옵션을 선택하여 해당 서비스를 생성할 수 있습니다.
AI&MLOps Platform을 생성하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > AI&MLOps Platform 메뉴를 클릭하세요. AI&MLOps Platform의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 생성 버튼을 클릭하세요. AI&MLOps Platform 생성 페이지로 이동합니다.
- AI&MLOps Platform 생성의 서비스 유형 선택 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 서비스 유형 및 버전 선택 영역에서 서비스 유형을 선택하세요.
구분 필수 여부상세 설명 서비스 유형 필수 사용자가 선택하는 서비스 유형 - AI&MLOps Platform
- Kubeflow Mini
서비스 유형 버전 필수 선택한 서비스의 버전 선택 - 제공하는 서비스의 버전 리스트 제공
표. AI&MLOps Platform 서비스 유형 및 버전 선택 항목 - 클러스터 배포 영역 구분 영역에서 서비스 생성에 필요한 옵션을 선택하세요.
구분 필수 여부상세 설명 클러스터 배포 영역 필수 - Kubernetes Engine에서 배포: 기존에 생성한 Kubernetes Engine을 선택
- 새 클러스터에 배포: AI&MLOps Platform 생성 시에 Kubernetes Engine을 함께 생성
표. AI&MLOps Platform 서비스 클러스터 배포 영역 구분 항목참고해당 클러스터 배포 설정에 따라 다음 서비스 정보 입력 페이지의 설정 요소들이 달라집니다.
- 서비스 유형 및 버전 선택 영역에서 서비스 유형을 선택하세요.
- AI&MLOps Platform 생성의 서비스 정보 입력 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 클러스터 배포 영역을 선택할 수 있습니다.
- 새 클러스터에 배포 설정 방법은 새 클러스터에 배포 가이드를 참고하세요.
- SCP Kubernetes Engine에서 배포 설정 방법은 SCP Kubernetes Engine에서 배포 가이드를 참고하세요.
- 설치에 필요한 Kubernetes 클러스터 사양은 설치에 필요한 Kubernetes 클러스터 사양 가이드를 참고하세요.
- 클러스터 배포 영역을 선택할 수 있습니다.
- AI&MLOps Platform 생성의 생성 정보 확인 페이지에서 생성한 상세 정보와 예상 청구 금액을 확인하고, 완료 버튼을 클릭하세요.
- 생성이 완료되면, AI&MLOps Platform 서비스 목록 페이지에서 생성한 자원을 확인하세요.
AI&MLOps Platform 상세 정보 확인하기
AI&MLOps Platform 서비스는 전체 자원 목록과 상세 정보를 확인하고 수정할 수 있습니다. AI&MLOps Platform 서비스 상세 페이지에서는 상세 정보, 태그, 작업 이력 탭으로 구성되어 있습니다.
AI&MLOps Platform 서비스의 상세 정보를 확인하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > AI&MLOps Platform 서비스 메뉴를 클릭하세요. AI&MLOps Platform 서비스의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 메뉴를 클릭하세요. AI&MLOps Platform 서비스 목록 페이지로 이동합니다.
- AI&MLOps Platform 서비스 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. AI&MLOps Platform 서비스 상세 페이지로 이동합니다.
- AI&MLOps Platform 서비스 상세 페이지에는 상태 정보 및 부가 기능 정보가 표시되며, 상세 정보, 태그, 작업 이력 탭으로 구성됩니다.
상세 정보
AI&MLOps Platform 서비스 목록 페이지에서 선택한 자원의 상세 정보를 확인하고, 필요한 경우 정보를 수정할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 서비스 | 서비스명 |
| 자원 유형 | 자원 유형 |
| SRN | Samsung Cloud Platform에서의 고유 자원 ID |
| 자원명 | 자원 이름
|
| 자원 ID | 서비스에서의 고유 자원 ID |
| 생성자 | 서비스를 생성한 사용자 |
| 생성 일시 | 서비스를 생성한 일시 |
| 수정자 | 서비스 정보를 수정한 사용자 |
| 수정 일시 | 서비스 정보를 수정한 일시 |
| 대시보드상태 | 대시보드 상태값 |
| 서비스명 | 서비스 이름 |
| Admin Email Address | 관리자 이메일 주소 |
| 이미지명 | 서비스 이미지 이름 |
| 버전 | 이미지 버전 |
| 서비스 유형 | 베포된 서비스 유형 |
표. AI&MLOps Platform 서비스 상세 정보 항목
태그
AI&MLOps Platform 서비스 목록 페이지에서 선택한 자원의 태그 정보를 확인하고, 추가하거나 변경 또는 삭제할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 태그 목록 | 태그 목록
|
표. 클러스터 태그 탭 항목
작업 이력
AI&MLOps Platform 서비스 목록 페이지에서 선택한 자원의 작업 이력을 확인할 수 있습니다.
| 구분 | 상세 설명 |
|---|---|
| 작업 이력 목록 | 자원 변경 이력
|
표. AI&MLOps Platform 서비스 작업 이력 탭 상세 정보 항목
AI&MLOps Platform 접속하기
AI&MLOps Platform 대시보드에 접속하려면 하시 사전작업이 선행되어야 합니다.
사전작업
해당 AI&MLOps Platform 접속하기 위해서 사전에 Security Group과 Firewall(방화벽 사용 시)에 관련 포트와 접속이 필요한 IP를 설정해야 합니다.
Kubeflow Mini: 31390 포트 (Security Group의 인바운드 룰, VPC 방화벽)
클러스터 Worker Node에 접근하려면 Security Group과 Firewall (VPC 방화벽 사용 시)에 22 포트의 인바운드 룰을 설정해야 합니다.
대시보드 접속하기
AI&MLOps Platform 서비스에 접속하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > AI&MLOps Platform 서비스 메뉴를 클릭하세요. AI&MLOps Platform 서비스의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 서비스 메뉴를 클릭하세요. AI&MLOps Platform 서비스 목록 페이지로 이동합니다.
- AI&MLOps Platform 서비스 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. AI&MLOps Platform 상세 페이지로 이동합니다.
- AI&MLOps Platform 상세 페이지에서 접속 가이드 버튼을 클릭하세요. 접속 가이드 팝업창이 열립니다.
- 접속 가이드 팝업창에서 대시보드의 URL 링크 를 클릭하세요. 해당 대시보드 페이지로 이동합니다.
주의
Public Subnet 사용 및 공인 IP 할당 시 외부 해킹, 악성코드 감염 등의 보안 공격에 노출될 수 있습니다.
AI&MLOps Platform 해지하기
사용하지 않는 해당 서비스를 해지하여 운영 비용을 절감할 수 있습니다. 단, 서비스를 해지하면 운영 중인 서비스가 즉시 중단될 수 있으므로 서비스 중단 시 발생하는 영향을 충분히 고려한 후 해지 작업을 진행해야 합니다.
주의
서비스 해지 후에는 데이터를 복구할 수 없으므로 주의해주세요.
AI&MLOps Platform을 해지하려면 다음 절차를 따르세요.
- 모든 서비스 > AI/ML > AI&MLOps Platform 서비스 메뉴를 클릭하세요. AI&MLOps Platform 서비스의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 서비스 메뉴를 클릭하세요. AI&MLOps Platform 서비스 목록 페이지로 이동합니다.
- AI&MLOps Platform 서비스 목록 페이지에서 상세 정보를 확인할 자원을 클릭하세요. AI&MLOps Platform 상세 페이지로 이동합니다.
- AI&MLOps Platform 상세 페이지에서 서비스 해지 버튼을 클릭하세요. 서비스 해지 팝업창이 열립니다.
- 확인을 위해 서비스명을 입력한 후 확인을 클릭하세요.
- 해지가 완료되면, AI&MLOps Platform 서비스 목록 페이지에서 자원이 해지되었는지 확인하세요.
3.2.1 - 클러스터 배포
클러스터 배포 영역
Samsung Cloud Platform에서 AI&MLOps Platform 생성의 서비스 유형 선택에서 2가지의 클라우드 배포 영역을 제공하고 있습니다.
공통
클러스터 배포 작업을 진행하기 전에 꼭 설치에 필요한 Kubernetes 클러스터 사양을 확인하세요.
- 클러스터 배포 영역의 선택에 상관없이 사전에 Kubernetes 클러스터 사양을 확인해야 합니다.
- 상세한 사양 정보는 클러스터 사양 가이드를 참고하세요.
클러스터 배포 영역의 선택에 따라 AI&MLOps Platform 생성의 서비스 정보 입력 페이지의 설치 내용이 달라집니다.
SCP Kubernetes Engine에서 배포
- 모든 서비스 > AI/ML > AI&MLOps Platform 메뉴를 클릭하세요. AI&MLOps Platform의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 생성 버튼을 클릭하세요. AI&MLOps Platform 생성 페이지로 이동합니다.
- AI&MLOps Platform 생성의 서비스 유형 선택 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.클러스터 배포SCP Kubernetes Engine에서 배포 옵션을 선택하세요.
- AI&MLOps Platform 생성의 서비스 정보 입력 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
- 서비스 정보 입력 영역에서 서비스 생성에 필요한 정보들을 입력하거나 조회하세요.
구분 필수 여부상세 설명 서비스명 필수 AI&MLOps Platform 이름 입력 - AI&MLOps Platform 이름은 프로젝트 내에서 중복하여 사용 불가
Storage Class 필수 Storage Class는 자동으로 등록 설치 노드 정보 조회 선택한 Kubernetes Engine의 노드 정보를 확인 Admin Email Address 필수 로그인 시 사용할 관리자(Admin)의 이메일 주소 입력 비밀번호 필수 로그인 시 사용할 비밀번호를 입력 비밀번호 확인 필수 비밀번호 오류를 방지하기 위해 비밀번호 재입력 표. AI&MLOps Platform 서비스 정보 입력 항목 - 추가 정보 입력 영역에서 서비스 생성에 필요한 정보들을 입력하거나 선택하세요.
구분 필수 여부상세 설명 태그 선택 AI&MLOps Platform에 추가할 태그 선택 - 태그 추가를 클릭하면 태그를 생성하여 추가하거나 기존 태그를 추가
- 태그는 최대 50개까지 등록
- 추가한 신규 태그는 서비스 생성 완료 후 적용
표. AI&MLOps Platform 서비스 추가 정보 입력 항목
- 서비스 정보 입력 영역에서 서비스 생성에 필요한 정보들을 입력하거나 조회하세요.
새 클러스터에 배포
- 모든 서비스 > AI/ML > AI&MLOps Platform 메뉴를 클릭하세요. AI&MLOps Platform의 Service Home 페이지로 이동합니다.
- Service Home 페이지에서 AI&MLOps Platform 생성 버튼을 클릭하세요. AI&MLOps Platform 생성 페이지로 이동합니다.
- AI&MLOps Platform 생성의 서비스 유형 선택 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.클러스터 배포새 클러스터에 배포 옵션을 선택하세요.
- AI&MLOps Platform 생성의 서비스 정보 입력 페이지에서 서비스 생성에 필요한 정보들을 입력하고, 상세 옵션을 선택하세요.
서비스 정보 입력 영역에서 서비스 생성에 필요한 정보들을 입력하거나 조회하세요.
구분 필수 여부상세 설명 서비스명 필수 AI&MLOps Platform 이름 입력 - AI&MLOps Platform 이름은 프로젝트 내에서 중복하여 사용 불가
Storage Class 필수 Storage Class는 자동으로 등록 설치 노드 정보 조회 선택한 Kubernetes Engine의 노드 정보를 확인 Admin Email Address 필수 로그인 시 사용할 관리자(Admin)의 이메일 주소를 입력 비밀번호 필수 로그인 시 사용할 비밀번호를 입력 비밀번호 확인 필수 비밀번호 오류를 방지하기 위해 비밀번호 재입력 표. AI&MLOps Platform 서비스 정보 입력 항목Kubernetes Engine 정보입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 클러스터명 필수 클러스터 이름 - 영문으로 시작하며 영문, 숫자, 특수문자(
-) 사용
- 3~30자 이내로 입력
제어 영역 설정 > Kubernetes 버전 필수 Kubernetes 버전 선택 제어 영역 설정 > 제어 영역 로깅 선택 제어 영역 로깅 사용 여부 선택 - 클러스터 제어 영역의 Audit/Event 로그를 Cloud Monitoring의 로그 분석에서 확인 가능
- Account 내 전체 서비스 대상으로 1GB의 로그 저장은 무료로 제공되며, 1GB가 넘을 경우 순차적으로 삭제됨
- 자세한 내용은 Cloud Monitoring > 로그 분석을 참고
네트워크 설정 필수 노드 풀의 네트워크 연결 설정 - VPC: 미리 생성한 VPC를 선택
- Subnet: 선택한 VPC의 서브넷 중 사용할 일반 Subnet을 선택
- Security Group: 검색 버튼을 클릭한 후 Security Group 선택 팝업창에서 Security Group을 선택
- Load Balancer: Kubernetes Service 객체에서
type:LoadBalancer기능 제공- 동일 네트워크 상의 로드 밸런서를 선택
- 사용 여부를 선택
- 설정 후에는 변경 불가
File Storage 설정 필수 클러스터에서 사용할 파일 스토리지 볼륨을 선택 - 기본 볼륨(NFS): 검색 버튼을 통해 File Storage를 선택
- 기본 Volume 파일 스토리지는 NFS 형식만 제공
표. Kubernetes Engine 서비스 정보 입력 항목- 영문으로 시작하며 영문, 숫자, 특수문자(
노드 풀 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 노드 풀 구성 필수 노드 풀 정보를 선택 - * 표시된 항목은 필수 입력 항목이므로 반드시 입력
- AI&MLOps Platform의 경우 사용에 따라 이미지 용량이 지속적으로 늘어날 수 있으므로 Block Storage를 최소 200GB 이상으로 설정 시 원활한 시스템 구성이 가능
표. AI&MLOps Platform 서비스 정보 입력 항목참고- Windows OS의 노드 풀은 클러스터에서 추가 스토리지(CIFS) 볼륨이 사용 중인 경우에만 생성할 수 있습니다.
- 노드 풀 Block Storage의 볼륨 암호화는 최초 생성 시에만 설정할 수 있습니다.
- 암호화를 설정하면 일부 기능의 성능 저하가 발생할 수 있습니다.
- 노드 풀 자동 확장 또는 축소 기능을 사용으로 선택한 경우에만 노드 수, 최소 노드 수, 최대 노드 수 를 입력할 수 있습니다.
추가 정보 입력 영역에서 필요한 정보를 입력 또는 선택하세요.
구분 필수 여부상세 설명 태그 선택 AI&MLOps Platform에 추가할 태그 선택 - 태그 추가를 클릭하면 태그를 생성하여 추가하거나 기존 태그를 추가
- 태그는 최대 50개까지 등록
- 추가한 신규 태그는 서비스 생성 완료 후 적용
표. AI&MLOps Platform 서비스 정보 입력 항목
클러스터 사양
AI&MLOps Platform을 이용하려면 AI&MLOps Platform을 설치할 Kubernetes Engine이 필요합니다. 기존에 생성한 Kubernetes Engine을 선택하거나, AI&MLOps Platform 생성 시 함께 Kubernetes Engine을 생성할 수 있습니다.
설치에 필요한 Kubernetes 클러스터의 사양은 다음과 같습니다.
노드 풀 자원 규모 (2개 이상의 노드로 구성)
- AI&MLOps Platfom : vCPU 32, Memory 128G 이상
- Kubeflow Mini: vCPU 24, Memory 96G 이상
Kubernetes 버전
- AI&MLOps Platform v1.9.1 (k8s v1.30)
- Kubeflow Mini v1.9.1 (k8s v1.30)
안내
Kubernetes 클러스터 당 1대의 AI&MLOps Platform만 설치할 수 있으며, 다른 용도로 사용 중인 클러스터에는 AI&MLOps Platform을 설치할 수 없습니다.
3.2.2 - Kubeflow 사용 가이드
아래에서는 Kubeflow를 생성한 후, Kubeflow의 사용 방법에 대해 가이드합니다.
Kubeflow 사용자 추가
아래에서는 Kubeflow를 생성한 이후의 Kubeflow의 사용 방법에 대해 가이드합니다.
Kubeflow는 설치 초기 화면에서 입력한 Admin User 1명의 계정만 생성되어있습니다.
Kubeflow Dashboard 이용 시, 초기 사용자 이외에 사용자를 추가하기 위해서는 Dex(Kubeflow의 인증 연계 컴포넌트)의 설정을 변경해야 합니다.
- Dex는 auth 네임스페이스(namespace)에 배포되며, 환경설정은 dex 라는 이름의 configmap 으로 저장되어 있습니다.
참고
kubeflow는 사용자별로 namespace가 분리되어 있습니다
다음은 Dex 환경 설정의 예시입니다.
배경색 변경
apiVersion: v1
kind: ConfigMap
metadata:
name: dex
namespace: auth
data:
config.yaml: |
issuer: http://dex.auth.svc.cluster.local:5556/dex
storage:
type: kubernetes
config:
inCluster: true
web:
http: 0.0.0.0:5556
logger:
level: "debug"
format: text
oauth2:
skipApprovalScreen: true
enablePasswordDB: true
staticPasswords:
- email: admin@kubeflow.org
hash: $2y$10$Yb9WVbn8pzVSM6fBgKdFae1Bh6Z.XTihi7bNu3sB6/h5bt1JuUOgq
username: admin
userID: 9cb67307-fd6d-4441-9b59-52acd78f4c9e
staticClients:
- id: kubeflow-oidc-authservice
redirectURIs: ["/login/oidc"]
name: 'Dex Login Application'
secret: pUBnBOY80SnXgjibTYM9ZWNzY2xreNGQok apiVersion: v1
kind: ConfigMap
metadata:
name: dex
namespace: auth
data:
config.yaml: |
issuer: http://dex.auth.svc.cluster.local:5556/dex
storage:
type: kubernetes
config:
inCluster: true
web:
http: 0.0.0.0:5556
logger:
level: "debug"
format: text
oauth2:
skipApprovalScreen: true
enablePasswordDB: true
staticPasswords:
- email: admin@kubeflow.org
hash: $2y$10$Yb9WVbn8pzVSM6fBgKdFae1Bh6Z.XTihi7bNu3sB6/h5bt1JuUOgq
username: admin
userID: 9cb67307-fd6d-4441-9b59-52acd78f4c9e
staticClients:
- id: kubeflow-oidc-authservice
redirectURIs: ["/login/oidc"]
name: 'Dex Login Application'
secret: pUBnBOY80SnXgjibTYM9ZWNzY2xreNGQok 환경 설정에서 enablePasswordDB 값이 true인 경우, Dex는 서비스 기동 시 configmap 에서 staticPasswords 에 정의된 사용자 목록을 내부 저장소에 저장합니다. 따라서 staticPasswords에 email, hash, username, userID 로 구성된 신규 사용자 값을 추가하게 되면 초기 사용자 이외에도 사용자를 자유롭게 추가하여 Kubeflow 서비스 이용이 가능합니다.
사용자를 추가하기 위한 속성값은 다음과 같이 정의할 수 있습니다.
| 파라미터 | 설명 |
|---|---|
| 일반적인 E-mail 형식의 값 | |
| hash | Bcrypt 알고리즘으로 암호화 된 사용자 암호 값이며 Bcrypt 알고리즘으로 생성된 Hash 값을 직접 입력
|
| username | 사용자 이름
|
| userID | 유일하게 식별될 수 있는 ID 값
|
표. 사용자를 추가하기 위한 속성값
kubectl을 사용할 수 있는 노드에서 다음 명령어를 이용해 dex configmap의 수정 화면으로 진입합니다.
배경색 변경
kubectl edit configmap dex -n authkubectl edit configmap dex -n auth배경색 변경
staticPasswords:
- email: admin@kubeflow.org
hash: $2y$10$Yb9WVbn8pzVSM6fBgKdFae1Bh6Z.XTihi7bNu3sB6/h5bt1JuUOgq
username: admin
userID: 9cb67307-fd6d-4441-9b59-52acd78f4c9e
- email: sds@samsung.com
hash: $2y$12$0g5.y86jnrt0v6In5NRCZ.YVuvrAUQ6j/RJYO3rV.kNulaDALOKfq
username: sds
userID: 8961d517-3498-4148-90c9-7e442ee91154staticPasswords:
- email: admin@kubeflow.org
hash: $2y$10$Yb9WVbn8pzVSM6fBgKdFae1Bh6Z.XTihi7bNu3sB6/h5bt1JuUOgq
username: admin
userID: 9cb67307-fd6d-4441-9b59-52acd78f4c9e
- email: sds@samsung.com
hash: $2y$12$0g5.y86jnrt0v6In5NRCZ.YVuvrAUQ6j/RJYO3rV.kNulaDALOKfq
username: sds
userID: 8961d517-3498-4148-90c9-7e442ee91154configmap의 staticPasswords 값은 Dex 서비스가 기동되는 시점에 반영되기 때문에 Dex 서비스를 다음 명령어로 재기동합니다.
배경색 변경
kubectl rollout restart deployment dex -n authkubectl rollout restart deployment dex -n auth신규 사용자 정보를 이용해 로그인을 시도합니다
정상적으로 로그인 되어 새로운 Namespace(profile)을 생성하는 화면으로 전환되는것을 확인합니다.
위 내용은 Kubeflow 공식 사이트를 참고하여 작성하였습니다. 자세한 내용은 Kubeflow Profiles 참고하세요.
Kubeflow Jupyter Notebook의 Custom Image 활용방법
Kubeflow의 Notebook Life Cycle을 관리하는 Kubeflow Notebook Controller에서 Custom Image를 사용하기 위해서는 몇 가지 요구사항을 만족해야 합니다.
Kubeflow는 Notebook 이미지가 실행되면 Jupyter가 자동으로 시작되는 것으로 인식합니다. 그래서 컨테이너 이미지에 Jupyter를 시작하는 기본 명령을 설정해야 합니다.
다음은 Dockerfile에 포함해야 하는 내용의 예시입니다.
배경색 변경
ENV NB_PREFIX /
CMD ["sh","-c", "jupyter notebook --notebook-dir=/home/${NB_USER} --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX}"]ENV NB_PREFIX /
CMD ["sh","-c", "jupyter notebook --notebook-dir=/home/${NB_USER} --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX}"]위 항목을 설명하면 아래와 같습니다.
| 파라미터 | 설명 |
|---|---|
--notebook-dir=/home/jovyan | 작업 디렉토리 설정
|
--ip=0.0.0.0 | Jupyter Notebook이 모든 IP에서 수신하도록 허용 |
--allow-root | Jupyter Notebook을 사용자가 root로 실행하도록 허용 |
--port=8888 | Port 설정 |
--NotebookApp.token=’’ –NotebookApp.password=’’ | Jupyter 인증 비활성화
|
--NotebookApp.allow_origin=’*’ | Allow origin |
--NotebookApp.base_url=NB_PREFIX | Base URL 설정 |
표. Dockerfile에 포함해야하는 설정
Custom Image 생성은 tesorflow notebook image를 생성하는 Dockerfile을 참고하여 생성할 수 있습니다.
- https://github.com/kubeflow/kubeflow/blob/v1.2.0/components/tensorflow-notebook-image/Dockerfile 참고하세요.
참고
Custom Image는 Docker Hub와 같은 Public Registry 또는 Private Registry에 저장되어 Kubeflow에서 push/pull이 가능하여야 합니다.
Notebook Servers 페이지에서 +NEW SERVER 버튼을 클릭하세요.

일단 Custom Image를 생성했다면 kubeflow Notebook Server 화면에서 Custom Image를 체크하고, Custom Image의 주소 를 입력하여 새로운 Notebook Server를 생성합니다.

안내
위 내용은 Kubeflow 공식 사이트를 참고하여 작성하였습니다.
- 자세한 내용은 Kubeflow 공식 사이트의 Kubeflow Notebooks > Container Images 문서를 확인하세요.
3.3 - API Reference
API Reference
3.4 - CLI Reference
CLI Reference