Service Overview
Kubernetes Engine is a service that provides lightweight virtual computing, containers, and a Kubernetes cluster to manage them. Users can leverage a Kubernetes environment without complex preparation by installing, operating, and maintaining the Kubernetes Control Plane.
Features
Standard Kubernetes Environment Setup: You can use a standard Kubernetes environment without additional configuration through the built-in Kubernetes Control Plane. It is compatible with applications in other standard Kubernetes environments, allowing you to use standard Kubernetes applications without modifying code.
Easy Kubernetes Deployment: provides secure communication between the worker node (Worker Node) and the managed control plane, and quickly provisions worker nodes so users can focus on building applications on the provided container environment.
Convenient Kubernetes Management: For enterprise environments, we provide various management features to conveniently use the created Kubernetes clusters, including cluster information lookup and management via a dashboard, namespace management, and workload management functions.
Service Diagram
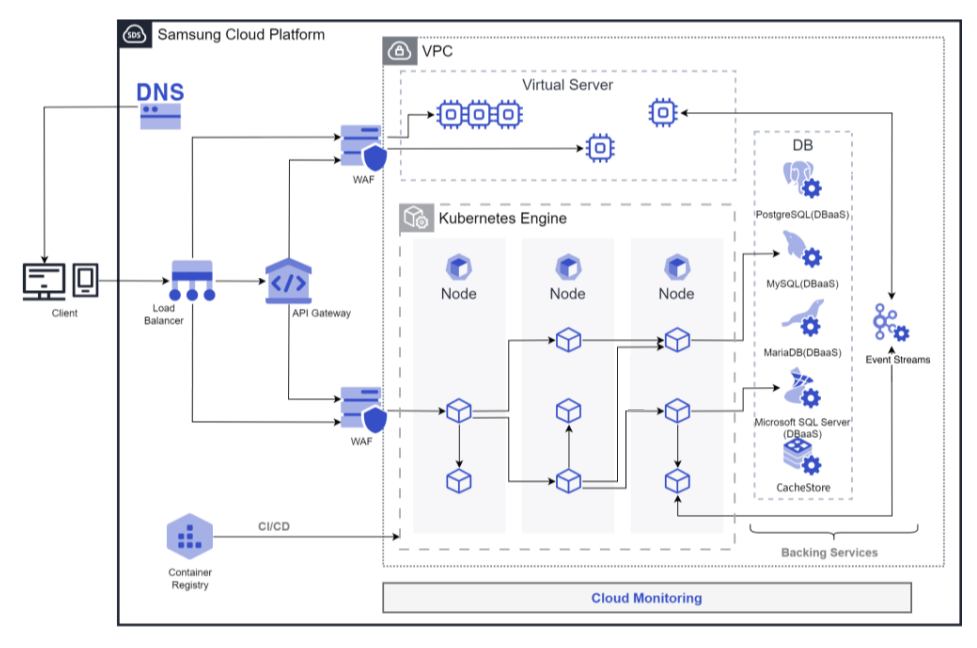
Provided features
Kubernetes Engine provides the following features.
- Cluster Management: You can create and manage clusters to use the Kubernetes Engine service. After creating a cluster, you can add services needed for operation such as nodes, namespaces, and workloads.
- Node Management: A node is a set of machines that run containerized applications. Every cluster must have at least one worker node to deploy applications. Nodes can be used by defining node pools. Nodes belonging to a node pool must have the same server type, size, and OS image, and creating multiple node pools enables flexible deployment strategies.
- Namespace Management: A namespace is a logical partition within a Kubernetes cluster and is used to specify access permissions or resource usage limits per namespace.
- Workload Management: A workload is an application running on Kubernetes Engine. After creating a namespace, you can add or delete workloads. Workloads are created and managed per item such as Deployment, Pod, StatefulSet, DaemonSet, Job, and CronJob.
- Service and Ingress Management: A service is an abstraction that exposes applications running in a set of pods as a network service, and an ingress is used to expose HTTP and HTTPS paths from outside the cluster to inside the cluster. After creating a namespace, you can create or delete services, endpoints, ingresses, and ingress classes.
- Storage Management: You can create and manage the storage to be used when using Kubernetes Engine. Storage is created and managed per PVC, PV, and StorageClass items.
- Configuration Management: When you need to manage values that change inside containers across multiple environments such as Dev/Prod, creating separate images to handle them via environment variables is inconvenient and wasteful. In Kubernetes, you can manage environment variables or configuration settings as variables that can be changed externally and injected when a Pod is created; at that point you can use ConfigMaps and Secrets.
- Permission Management: When multiple users access a Kubernetes cluster, you can assign permissions per specific API or namespace to define the access scope. By applying Kubernetes’ role-based access control (RBAC) feature, you can set permissions for clusters or namespaces. You can create and manage ClusterRoles, ClusterRoleBindings, Roles, and RoleBindings.
Component
control plane
Control Plane is the component that serves as the master node in the Kubernetes Engine service. The master node is the cluster’s management node, responsible for managing the other nodes in the cluster. A cluster is the basic creation unit of the Kubernetes Engine service and is used for managing node pools, objects, controllers, etc., that belong to it. Users configure the cluster name (cluster name), control plane, network, File Storage, and then create node pools within the cluster for use. The master node assigns work to the cluster, monitors node status, and handles data communication between nodes.
The cluster name creation rules are as follows.
- It must start with a letter and can be set using letters, numbers, and special characters (
-) within 3 to 30 characters. - It must not duplicate an already existing cluster name.
worker node
The worker node (Worker Node) is a compute node in the cluster that performs tasks. It receives task assignments from the cluster’s master node, executes them, and reports the results back to the master node. All nodes created within a node pool and namespace serve as worker nodes.
The rules for creating a node pool, which is a collection of worker nodes, are as follows.
- A node pool must contain at least one node for the application deployment to be possible.
- A maximum of 100 nodes can be created within a node pool.
- Since the maximum number of nodes is 100, you can freely create up to 100 nodes—for example, with 100 node pools you get 1 node per pool, and with 50 node pools you get 2 nodes per pool.
- It is possible to configure block storage attached to a node pool.
- You can configure the server type, size, and OS image for nodes in a node pool, and they must all be identical.
- Through the Auto-Scaling service, you can configure automatic scaling and shrinking of node pools according to the requirements of the deployed application.
Preliminary Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service for details and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
| Networking | Security Group | Virtual firewall that controls server traffic |
| Storage | File Storage | A storage that allows multiple clients to share files over the network
|