Leveraging the country’s top reliability, we conveniently and elastically provide optimal computing resources tailored to each use case.
This is the multi-page printable view of this section. Click here to print.
Compute
- 1: Virtual Server
- 1.1: Overview
- 1.1.1: Server type
- 1.1.2: Monitoring Metrics
- 1.1.3: ServiceWatch Metrics
- 1.2: How-to guides
- 1.2.1: Image
- 1.2.2: Keypair
- 1.2.3: Server Group
- 1.2.4: Change IP
- 1.2.5: Configure Linux NTP
- 1.2.6: Configure RHEL Repo and WKMS
- 1.2.7: Install ServiceWatch Agent
- 1.3: API Reference
- 1.4: CLI Reference
- 1.5: Release Note
- 2: Virtual Server Auto-Scaling
- 2.1: Overview
- 2.1.1: Monitoring Metrics
- 2.1.2: ServiceWatch Metrics
- 2.2: How-to guides
- 2.2.1: Launch Configuration
- 2.2.2: Manage Policy
- 2.2.3: Manage Schedule
- 2.2.4: Manage Notification
- 2.3: API Reference
- 2.4: CLI Reference
- 2.5: Release Note
- 3: GPU Server
- 3.1: Overview
- 3.1.1: Server type
- 3.1.2: Monitoring Metrics
- 3.1.3: ServiceWatch Metrics
- 3.2: How-to guides
- 3.2.1: Manage Image
- 3.2.2: Manage Keypair
- 3.2.3: Use Multi-instance GPU on GPU Server
- 3.2.4: Use NVSwitch on GPU Server
- 3.2.5: Install ServiceWatch Agent
- 3.3: API Reference
- 3.4: CLI Reference
- 3.5: Release Note
- 4: Bare Metal Server
- 4.1: Overview
- 4.1.1: Server type
- 4.1.2: Monitoring Metrics
- 4.2: How-to guides
- 4.2.1: Install ServiceWatch Agent
- 4.2.2: Setting up RHEL Repo and WKMS
- 4.3: API Reference
- 4.4: CLI Reference
- 4.5: Release Note
- 5: Multi-node GPU Cluster
- 5.1: Overview
- 5.1.1: Server type
- 5.1.2: Monitoring Metrics
- 5.2: How-to guides
- 5.2.1: Cluster Fabric Management
- 5.2.2: Install ServiceWatch Agent
- 5.2.3: Multi-node GPU Cluster Service Scope and Inspection Guide
- 5.3: Release Note
- 6: Cloud Functions
- 6.1: Overview
- 6.1.1: ServiceWatch Metrics
- 6.2: How-to guides
- 6.2.1: Configure Trigger
- 6.2.2: Blueprint Detailed Guide
- 6.2.3: Integrate PrivateLink Service
- 6.2.4: Resource-based Policy Guide
- 6.3: API Reference
- 6.4: CLI Reference
- 6.5: Release Note
- 7: Virtual Server DR
- 7.1: Overview
- 7.2: Release Note
- 8: Block Storage
- 8.1: Overview
- 8.1.1: Monitoring Metrics
- 8.1.2: ServiceWatch metric
- 8.2: How-to guides
- 8.2.1: Connect to Server
- 8.2.2: Using Snapshots
- 8.2.3: Transfer volume
- 8.3: API Reference
- 8.4: CLI Reference
- 8.5: Release Note
1 - Virtual Server
1.1 - Overview
Service Overview
Virtual Server is a virtual server optimized for cloud computing that lets you freely allocate and use infrastructure resources provided by the server—such as CPU and memory—without having to purchase them individually, and you can allocate as much as you need, when you need it. In a cloud environment, you can use resources with optimized performance according to the user’s computing purposes such as development, testing, and application execution.
Features
Easy and convenient computing environment setup: Through a web-based Console, users can easily use Self Service from Virtual Server provisioning to resource management and cost management. * When using a Virtual Server, if you need to change the capacity of major resources such as CPU or Memory, you can easily scale up or down without operator intervention.
Various Service Types Offered: Provides virtualized vCore/Memory resources based on predefined server types (1~128 vCore).
- General Virtual Server: Provides commonly used computing specs (up to 16vCore, 256GB)
- Large-capacity Virtual Server: Provided when resources larger than the standard Virtual Server spec are required.
Strong Security Implementation: Through the Security Group service, control inbound/outbound traffic communicating with the external Internet or other VPC(Virtual Private Cloud) to securely protect the server. * Additionally, real-time monitoring enables stable operation of computing resources.
Service architecture diagram
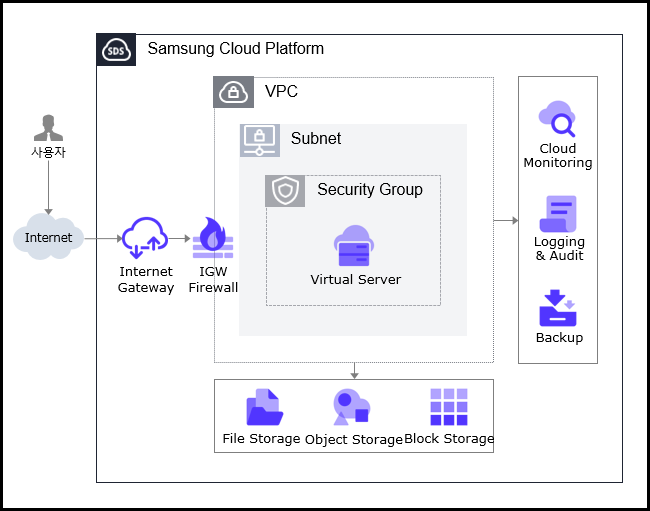
Provided features
Virtual Server provides the following features.
- Auto Provisioning and Management: Provides Virtual Server provisioning, resource management, and cost management functions through a web-based console. * If you need to change the capacity of major resources such as CPU or Memory while using a Virtual Server, you can modify it immediately using the server type edit function.
- Standard Server Type and Image Provision: Provides virtualized vCore/Memory resources according to the standard server type, and supplies a standard OS Image.
- Storage Connection: Provides additional attached storage besides the OS disk. * Block Storage, File Storage, Object Storage can be additionally connected and used.
- Network Connection: You can connect the Virtual Server’s standard subnet/IP settings and Public NAT IP. * Provides a local subnet connection for inter-server communication. * This task can be edited on the detail page.
- Security Group Application: Through the Security Group service, control inbound/outbound traffic communicating with external internet or other VPCs to securely protect the server.
- Monitoring: You can view monitoring information for computing resources such as CPU, Memory, and Disk through the Cloud Monitoring service.
- Backup and Recovery: You can back up and recover Virtual Server Image using the Backup service.
- Cost Management: You can create, stop, or terminate servers as needed, and because billing is based on actual usage time, you can verify costs according to usage.
- ServiceWatch Service Integration: You can monitor data using the ServiceWatch service.
Components
Virtual Server provides standard server types and standard OS images. Users can select and use it according to the desired service scale.
Image
You can create and manage images. The main features are as follows.
- Image creation: You can create an Image from the configuration of the Virtual Server you are using, and you can create an Image by uploading your Image file to Object Storage.
- Create Shared Image: You can create an Image with Visibility set to Private as a Shared Image that can be shared.
- Share with another Account: You can share the Image with another Account.
- For instructions on creating and using images, see the How-to guides > Image document.
Keypair
To ensure a more secure OS login, we strengthen security by providing a Key Pair instead of the ID/Password entry method. The main features are as follows.
- Keypair creation: Creates a user credential for connecting to the Virtual Server.
- Retrieve Public Key: You can retrieve the public key by loading a file or by manually entering the public key. Keypair 생성 및 활용 방법은 How-to guides > Keypair문서를 참고하세요.
Server Group {#server-group}
Server Group 설정을 통해 Virtual Server 및 Virtual Server 생성 시 추가한 Block Storage를 랙(Rack) 및 호스트에 근접 또는 분산 배치 가능합니다. 주요 기능은 다음과 같습니다.
Server Group 생성: 동일 Server Group에 소속된 Virtual Server를 Anti-Affinity(분산배치), Affinity(근접배치), Partition(Virtual Server와 Block Storage 분산배치)로 설정할 수 있습니다.
- For how to create and use Server Groups, please refer to the How-to guides > Server Group document.
OS Image version provided
The OS images provided by Virtual Server are as follows.
| OS Image version | EoS Date |
|---|---|
| Alma Linux 8.10 | 2029-05-31 |
| Alma Linux 9.6 | 2025-11-17 |
| Oracle Linux 8.10 | 2029-07-31 |
| Oracle Linux 9.6 | 2025-11-25 |
| RHEL 8.10 | 2029-05-31 |
| RHEL 9.4 | 2026-04-30 |
| RHEL 9.6 | 2027-05-31 |
| Rocky Linux 8.10 | 2029-05-31 |
| Rocky Linux 9.6 | 2025-11-30 |
| Ubuntu 22.04 | 2027-06-30 |
| Ubuntu 24.04 | 2029-06-30 |
| Windows 2016 | 2027-01-12 |
| Windows 2019 | 2029-01-09 |
| Windows 2022 | 2031-10-14 |
Table. Virtual Server provided OS Image version
Reference
- Linux operating systems such as Alma Linux and Rocky Linux provide only even Minor versions, except for the final release version of a Major version. * This is a policy to ensure the stability and consistency of the SCP system. We recommend checking the EOS (End of Support) and EOL (End of Life) dates for the operating system, and, if necessary, applying new or additional individual packages to maintain a stable environment.
Server type
The server types supported by Virtual Server are as follows. For detailed information about server types, see Virtual Server 서버 타입.
Standard s1v2m4
구분 | 예시 | 상세 설명 |
|---|---|---|
| 서버 타입 | Standard | Provided server type classifications
|
| Server specifications | s1 | Provided server type classification and generation
|
| Server specifications | v2 | vCore count
|
| Server specifications | m4 | Memory capacity
|
Table. Virtual Server server type
Constraints
Reference
- When creating a Virtual Server with Rocky Linux or Oracle Linux, additional configuration is required for time synchronization (NTP:Network Time Protocol). * If created with a different image, it is set automatically and no additional configuration is required.
For more details, please refer to Linux NTP 설정하기. - If RHEL and Windows Server were created before August 2025, the RHEL Repository and WKMS (Windows Key Management Service) settings need to be modified.
For detailed information, refer to RHEL Repo 및 WKMS 설정하기.
Preceding Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
| Networking | Security Group | Virtual firewall that controls server traffic |
Table. Virtual Server Pre-service
1.1.1 - Server type
Virtual Server server type
Virtual Server provides server types according to the intended use. Server types are composed of various combinations such as CPU, Memory, and Network Bandwidth. When creating a Virtual Server, the host server used for the Virtual Server is determined by the selected server type. Please select the server type according to the specifications of the application you want to run on the Virtual Server.
The server types supported by Virtual Server are as follows.
Standard s1v2m4
Category | Example | Detailed description |
|---|---|---|
| Server type | Standard | 제공되는 서버 타입 구분
|
| 서버 사양 | s1 | 제공되는 서버 타입 구분 및 세대를 의미
|
| 서버 사양 | v2 | vCore 개수
|
| 서버 사양 | m4 | 메모리 용량
|
Table. Virtual Server server type format
Notice
For s3 and h3 server types, they are available only on Samsung Cloud Platform for Enterprise and Samsung Cloud Platform for Samsung.
Samsung Cloud Platform Sovereign is scheduled to be offered after November 2026.
s1 server type
The s1 server type of Virtual Server is provided with standard specifications (vCPU, Memory) and is suitable for various applications.
- Samsung Cloud Platform v2’s first generation: Intel 3rd‑generation (Ice Lake) Xeon Gold 6342 Processor up to 3.3 GHz
- Supports up to 16 vCPUs and 256 GB of memory
- Maximum networking speed of 12.5 Gbps
| 구분 | 서버 타입 | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| Standard | s1v1m2 | 1 vCore | 2 GB | Maximum 10 Gbps |
| Standard | s1v2m4 | 2 vCore | 4 GB | Up to 10 Gbps |
| Standard | s1v2m8 | 2 vCore | 8 GB | Up to 10 Gbps |
| Standard | s1v2m16 | 2 vCore | 16 GB | Up to 10 Gbps |
| Standard | s1v2m24 | 2 vCore | 24 GB | Up to 10 Gbps |
| Standard | s1v2m32 | 2 vCore | 32 GB | Up to 10 Gbps |
| Standard | s1v4m8 | 4 vCore | 8 GB | Up to 10 Gbps |
| Standard | s1v4m16 | 4 vCore | 16 GB | Up to 10 Gbps |
| Standard | s1v4m32 | 4 vCore | 32 GB | Up to 10 Gbps |
| Standard | s1v4m48 | 4 vCore | 48 GB | 최대 10 Gbps |
| Standard | s1v4m64 | 4 vCore | 64 GB | 최대 10 Gbps |
| Standard | s1v6m12 | 6 vCore | 12 GB | Up to 10 Gbps |
| Standard | s1v6m24 | 6 vCore | 24 GB | Up to 10 Gbps |
| Standard | s1v6m48 | 6 vCore | 48 GB | Up to 10 Gbps |
| Standard | s1v6m72 | 6 vCore | 72 GB | Up to 10 Gbps |
| Standard | s1v6m96 | 6 vCore | 96 GB | Up to 10 Gbps |
| Standard | s1v8m16 | 8 vCore | 16 GB | Up to 10 Gbps |
| Standard | s1v8m32 | 8 vCore | 32 GB | Up to 10 Gbps |
| Standard | s1v8m64 | 8 vCore | 64 GB | Up to 10 Gbps |
| Standard | s1v8m96 | 8 vCore | 96 GB | Up to 10 Gbps |
| Standard | s1v8m128 | 8 vCore | 128 GB | Up to 10 Gbps |
| Standard | s1v10m20 | 10 vCore | 20 GB | Up to 10 Gbps |
| Standard | s1v10m40 | 10 vCore | 40 GB | 최대 10 Gbps |
| Standard | s1v10m80 | 10 vCore | 80 GB | 최대 10 Gbps |
| Standard | s1v10m120 | 10 vCore | 120 GB | Up to 10 Gbps |
| Standard | s1v10m160 | 10 vCore | 160 GB | Up to 10 Gbps |
| Standard | s1v12m24 | 12 vCore | 24 GB | Up to 12.5 Gbps |
| Standard | s1v12m48 | 12 vCore | 48 GB | Maximum 12.5 Gbps |
| Standard | s1v12m96 | 12 vCore | 96 GB | Up to 12.5 Gbps |
| Standard | s1v12m144 | 12 vCore | 144 GB | Maximum 12.5 Gbps |
| Standard | s1v12m192 | 12 vCore | 192 GB | Maximum 12.5 Gbps |
| Standard | s1v14m28 | 14 vCore | 28 GB | Up to 12.5 Gbps |
| Standard | s1v14m56 | 14 vCore | 56 GB | Up to 12.5 Gbps |
| Standard | s1v14m112 | 14 vCore | 112 GB | Maximum 12.5 Gbps |
| Standard | s1v14m168 | 14 vCore | 168 GB | Up to 12.5 Gbps |
| Standard | s1v14m224 | 14 vCore | 224 GB | 최대 12.5 Gbps |
| Standard | s1v16m32 | 16 vCore | 32 GB | 최대 12.5 Gbps |
| Standard | s1v16m64 | 16 vCore | 64 GB | Up to 12.5 Gbps |
| Standard | s1v16m128 | 16 vCore | 128 GB | Up to 12.5 Gbps |
| Standard | s1v16m192 | 16 vCore | 192 GB | Maximum 12.5 Gbps |
| Standard | s1v16m256 | 16 vCore | 256 GB | Up to 12.5 Gbps |
Table. Virtual Server server type specifications - s1 server type
s2 server type
The Virtual Server s2 server type is offered with standard specifications (vCPU, Memory) and is suitable for various applications.
- Second generation of Samsung Cloud Platform v2: Intel 4th‑generation (Sapphire Rapids) Xeon Gold 6448H processor up to 3.2 GHz
- Supports up to 16 vCPUs and 256 GB of memory
- Maximum networking speed of 12.5 Gbps
| Category | Server type | CPU vCore | Memory | Network Bandwidth(Gbps) |
|---|---|---|---|---|
| Standard | s2v1m2 | 1 vCore | 2 GB | Up to 10 Gbps |
| Standard | s2v2m4 | 2 vCore | 4 GB | Up to 10 Gbps |
| Standard | s2v2m8 | 2 vCore | 8 GB | Up to 10 Gbps |
| Standard | s2v2m16 | 2 vCore | 16 GB | Up to 10 Gbps |
| Standard | s2v2m24 | 2 vCore | 24 GB | Up to 10 Gbps |
| Standard | s2v2m32 | 2 vCore | 32 GB | Up to 10 Gbps |
| Standard | s2v4m8 | 4 vCore | 8 GB | Up to 10 Gbps |
| Standard | s2v4m16 | 4 vCore | 16 GB | Up to 10 Gbps |
| Standard | s2v4m32 | 4 vCore | 32 GB | Up to 10 Gbps |
| Standard | s2v4m48 | 4 vCore | 48 GB | Up to 10 Gbps |
| Standard | s2v4m64 | 4 vCore | 64 GB | Up to 10 Gbps |
| Standard | s2v6m12 | 6 vCore | 12 GB | Up to 10 Gbps |
| Standard | s2v6m24 | 6 vCore | 24 GB | Up to 10 Gbps |
| Standard | s2v6m48 | 6 vCore | 48 GB | Up to 10 Gbps |
| Standard | s2v6m72 | 6 vCore | 72 GB | Maximum 10 Gbps |
| Standard | s2v6m96 | 6 vCore | 96 GB | Up to 10 Gbps |
| Standard | s2v8m16 | 8 vCore | 16 GB | Up to 10 Gbps |
| Standard | s2v8m32 | 8 vCore | 32 GB | Up to 10 Gbps |
| Standard | s2v8m64 | 8 vCore | 64 GB | Up to 10 Gbps |
| Standard | s2v8m96 | 8 vCore | 96 GB | Up to 10 Gbps |
| Standard | s2v8m128 | 8 vCore | 128 GB | Up to 10 Gbps |
| Standard | s2v10m20 | 10 vCore | 20 GB | Up to 10 Gbps |
| Standard | s2v10m40 | 10 vCore | 40 GB | Up to 10 Gbps |
| Standard | s2v10m80 | 10 vCore | 80 GB | Up to 10 Gbps |
| Standard | s2v10m120 | 10 vCore | 120 GB | Up to 10 Gbps |
| Standard | s2v10m160 | 10 vCore | 160 GB | Up to 10 Gbps |
| Standard | s2v12m24 | 12 vCore | 24 GB | 최대 12.5 Gbps |
| Standard | s2v12m48 | 12 vCore | 48 GB | Up to 12.5 Gbps |
| Standard | s2v12m96 | 12 vCore | 96 GB | Up to 12.5 Gbps |
| Standard | s2v12m144 | 12 vCore | 144 GB | Up to 12.5 Gbps |
| Standard | s2v12m192 | 12 vCore | 192 GB | Up to 12.5 Gbps |
| Standard | s2v14m28 | 14 vCore | 28 GB | Up to 12.5 Gbps |
| Standard | s2v14m56 | 14 vCore | 56 GB | Up to 12.5 Gbps |
| Standard | s2v14m112 | 14 vCore | 112 GB | Up to 12.5 Gbps |
| Standard | s2v14m168 | 14 vCore | 168 GB | Up to 12.5 Gbps |
| Standard | s2v14m224 | 14 vCore | 224 GB | Up to 12.5 Gbps |
| Standard | s2v16m32 | 16 vCore | 32 GB | Up to 12.5 Gbps |
| Standard | s2v16m64 | 16 vCore | 64 GB | Up to 12.5 Gbps |
| Standard | s2v16m128 | 16 vCore | 128 GB | Up to 12.5 Gbps |
| Standard | s2v16m192 | 16 vCore | 192 GB | Up to 12.5 Gbps |
| Standard | s2v16m256 | 16 vCore | 256 GB | Up to 12.5 Gbps |
Table. Virtual Server server type specifications – s2 server type
s3 server type
The Virtual Server s3 server type is offered with standard specifications (vCPU, Memory) and is suitable for various applications.
- Samsung Cloud Platform v2’s 3rd generation: Intel 6th‑generation (Granite Rapids) Xeon 6737P Processor up to 4.0 GHz
- Supports up to 16 vCPUs and 256 GB of memory
- Maximum networking speed of 12.5 Gbps
| Category | Server type | CPU vCore | Memory | Network Bandwidth(Gbps) |
|---|---|---|---|---|
| Standard | s3v1m2 | 1 vCore | 2 GB | Up to 10 Gbps |
| Standard | s3v2m4 | 2 vCore | 4 GB | Maximum 10 Gbps |
| Standard | s3v2m8 | 2 vCore | 8 GB | Up to 10 Gbps |
| Standard | s3v2m16 | 2 vCore | 16 GB | Up to 10 Gbps |
| Standard | s3v2m24 | 2 vCore | 24 GB | Maximum 10 Gbps |
| Standard | s3v2m32 | 2 vCore | 32 GB | Up to 10 Gbps |
| Standard | s3v4m8 | 4 vCore | 8 GB | Up to 10 Gbps |
| Standard | s3v4m16 | 4 vCore | 16 GB | Up to 10 Gbps |
| Standard | s3v4m32 | 4 vCore | 32 GB | Up to 10 Gbps |
| Standard | s3v4m48 | 4 vCore | 48 GB | Maximum 10 Gbps |
| Standard | s3v4m64 | 4 vCore | 64 GB | Up to 10 Gbps |
| Standard | s3v6m12 | 6 vCore | 12 GB | Maximum 10 Gbps |
| Standard | s3v6m24 | 6 vCore | 24 GB | Up to 10 Gbps |
| Standard | s3v6m48 | 6 vCore | 48 GB | Up to 10 Gbps |
| Standard | s3v6m72 | 6 vCore | 72 GB | Up to 10 Gbps |
| Standard | s3v6m96 | 6 vCore | 96 GB | Maximum 10 Gbps |
| Standard | s3v8m16 | 8 vCore | 16 GB | Maximum 10 Gbps |
| Standard | s3v8m32 | 8 vCore | 32 GB | Up to 10 Gbps |
| Standard | s3v8m64 | 8 vCore | 64 GB | Maximum 10 Gbps |
| Standard | s3v8m96 | 8 vCore | 96 GB | Up to 10 Gbps |
| Standard | s3v8m128 | 8 vCore | 128 GB | Up to 10 Gbps |
| Standard | s3v10m20 | 10 vCore | 20 GB | Up to 10 Gbps |
| Standard | s3v10m40 | 10 vCore | 40 GB | Maximum 10 Gbps |
| Standard | s3v10m80 | 10 vCore | 80 GB | Maximum 10 Gbps |
| Standard | s3v10m120 | 10 vCore | 120 GB | Up to 10 Gbps |
| Standard | s3v10m160 | 10 vCore | 160 GB | Maximum 10 Gbps |
| Standard | s3v12m24 | 12 vCore | 24 GB | Up to 12.5 Gbps |
| Standard | s3v12m48 | 12 vCore | 48 GB | Up to 12.5 Gbps |
| Standard | s3v12m96 | 12 vCore | 96 GB | Up to 12.5 Gbps |
| Standard | s3v12m144 | 12 vCore | 144 GB | Maximum 12.5 Gbps |
| Standard | s3v12m192 | 12 vCore | 192 GB | Up to 12.5 Gbps |
| Standard | s3v14m28 | 14 vCore | 28 GB | Up to 12.5 Gbps |
| Standard | s3v14m56 | 14 vCore | 56 GB | Up to 12.5 Gbps |
| Standard | s3v14m112 | 14 vCore | 112 GB | Up to 12.5 Gbps |
| Standard | s3v14m168 | 14 vCore | 168 GB | Up to 12.5 Gbps |
| Standard | s3v14m224 | 14 vCore | 224 GB | Up to 12.5 Gbps |
| Standard | s3v16m32 | 16 vCore | 32 GB | Up to 12.5 Gbps |
| Standard | s3v16m64 | 16 vCore | 64 GB | Up to 12.5 Gbps |
| Standard | s3v16m128 | 16 vCore | 128 GB | Up to 12.5 Gbps |
| Standard | s3v16m192 | 16 vCore | 192 GB | Up to 12.5 Gbps |
| Standard | s3v16m256 | 16 vCore | 256 GB | Up to 12.5 Gbps |
표. Virtual Server 서버 타입 사양 - s3 서버 타입
h2 Server Type
The h2 server type of Virtual Server is offered with high-capacity server specifications and is suitable for applications that require large-scale data processing.
- Second generation of Samsung Cloud Platform v2: Intel 4th‑generation (Sapphire Rapids) Xeon Gold 6448H processor up to 3.2 GHz
- Supports up to 128 vCPUs and 1,536 GB of memory
- Maximum networking speed of 25 Gbps
| Category | Server type | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | h2v24m48 | 24 vCore | 48 GB | Maximum 25 Gbps |
| High Capacity | h2v24m96 | 24 vCore | 96 GB | Maximum 25 Gbps |
| High Capacity | h2v24m192 | 24 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h2v24m288 | 24 vCore | 288 GB | Maximum 25 Gbps |
| High Capacity | h2v32m64 | 32 vCore | 64 GB | Maximum 25 Gbps |
| High Capacity | h2v32m128 | 32 vCore | 128 GB | Maximum 25 Gbps |
| High Capacity | h2v32m256 | 32 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h2v32m384 | 32 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h2v48m96 | 48 vCore | 96 GB | Maximum 25 Gbps |
| High Capacity | h2v48m192 | 48 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h2v48m384 | 48 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h2v48m576 | 48 vCore | 576 GB | Maximum 25 Gbps |
| High Capacity | h2v64m128 | 64 vCore | 128 GB | Maximum 25 Gbps |
| High Capacity | h2v64m256 | 64 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h2v64m512 | 64 vCore | 512 GB | Maximum 25 Gbps |
| High Capacity | h2v64m768 | 64 vCore | 768 GB | Maximum 25 Gbps |
| High Capacity | h2v72m144 | 72 vCore | 144 GB | Maximum 25 Gbps |
| High Capacity | h2v72m288 | 72 vCore | 288 GB | Maximum 25 Gbps |
| High Capacity | h2v72m576 | 72 vCore | 576 GB | Maximum 25 Gbps |
| High Capacity | h2v72m864 | 72 vCore | 864 GB | Maximum 25 Gbps |
| High Capacity | h2v96m192 | 96 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h2v96m384 | 96 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h2v96m768 | 96 vCore | 768 GB | Maximum 25 Gbps |
| High Capacity | h2v96m1152 | 96 vCore | 1152 GB | Maximum 25 Gbps |
| High Capacity | h2v128m256 | 128 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h2v128m512 | 128 vCore | 512 GB | Maximum 25 Gbps |
| High Capacity | h2v128m1024 | 128 vCore | 1024 GB | Maximum 25 Gbps |
| High Capacity | h2v128m1536 | 128 vCore | 1536 GB | Maximum 25 Gbps |
Table. Virtual Server server type specifications - h2 server type
h3 Server Type
The h3 server type of Virtual Server is offered with high-capacity specifications and is suitable for applications that require large-scale data processing.
- Samsung Cloud Platform v2’s 3rd generation: Intel 6th‑generation (Granite Rapids) Xeon 6738P Processor up to 4.1 GHz
- Supports up to 128 vCPUs and 1,536 GB of memory
- Maximum networking speed of 25G bps
| Category | Server type | vCPU | Memory | Network Bandwidth |
|---|---|---|---|---|
| High Capacity | h3v24m48 | 24 vCore | 48 GB | Maximum 25 Gbps |
| High Capacity | h3v24m96 | 24 vCore | 96 GB | Maximum 25 Gbps |
| High Capacity | h3v24m192 | 24 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h3v24m288 | 24 vCore | 288 GB | Maximum 25 Gbps |
| High Capacity | h3v32m64 | 32 vCore | 64 GB | Maximum 25 Gbps |
| High Capacity | h3v32m128 | 32 vCore | 128 GB | Maximum 25 Gbps |
| High Capacity | h3v32m256 | 32 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h3v32m384 | 32 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h3v48m96 | 48 vCore | 96 GB | Maximum 25 Gbps |
| High Capacity | h3v48m192 | 48 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h3v48m384 | 48 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h3v48m576 | 48 vCore | 576 GB | Maximum 25 Gbps |
| High Capacity | h3v64m128 | 64 vCore | 128 GB | Maximum 25 Gbps |
| High Capacity | h3v64m256 | 64 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h3v64m512 | 64 vCore | 512 GB | Maximum 25 Gbps |
| High Capacity | h3v64m768 | 64 vCore | 768 GB | Maximum 25 Gbps |
| High Capacity | h3v72m144 | 72 vCore | 144 GB | Maximum 25 Gbps |
| High Capacity | h3v72m288 | 72 vCore | 288 GB | Maximum 25 Gbps |
| High Capacity | h3v72m576 | 72 vCore | 576 GB | Maximum 25 Gbps |
| High Capacity | h3v72m864 | 72 vCore | 864 GB | Up to 25 Gbps |
| High Capacity | h3v96m192 | 96 vCore | 192 GB | Maximum 25 Gbps |
| High Capacity | h3v96m384 | 96 vCore | 384 GB | Maximum 25 Gbps |
| High Capacity | h3v96m768 | 96 vCore | 768 GB | Maximum 25 Gbps |
| High Capacity | h3v96m1152 | 96 vCore | 1152 GB | Maximum 25 Gbps |
| High Capacity | h3v128m256 | 128 vCore | 256 GB | Maximum 25 Gbps |
| High Capacity | h3v128m512 | 128 vCore | 512 GB | Maximum 25 Gbps |
| High Capacity | h3v128m1024 | 128 vCore | 1024 GB | Maximum 25 Gbps |
| High Capacity | h3v128m1536 | 128 vCore | 1536 GB | Maximum 25 Gbps |
Table. Virtual Server server type specifications - h3 server type
1.1.2 - Monitoring Metrics
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Starting after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With the new alternative service, you can continuously perform resource monitoring by leveraging ServiceWatch released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a seamless monitoring environment.
Detailed information about ServiceWatch can be found in the ServiceWatch Overview.
Virtual Server Monitoring Metrics
The table below shows the monitoring metrics of Virtual Server that can be viewed through Cloud Monitoring. For detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
Provides basic monitoring metrics even without installing an agent, as shown below table. Please check the Virtual Server monitoring metrics (default). Additionally, the metrics that can be viewed by installing the Agent are in the table below. Virtual Server additional monitoring metrics (Agent installation required)** Please refer to it.
For Windows OS, memory-related metrics can only be viewed after installing the Agent.
| Performance items | Detailed description | unit |
|---|---|---|
| Memory Total [Basic] | bytes of usable memory | bytes |
| Memory Used [Basic] | Current memory usage in bytes | bytes |
| Memory Swap In [Basic] | bytes of the replaced memory | bytes |
| Memory Swap Out [Basic] | bytes of the replaced memory | bytes |
| Memory Free [Basic] | bytes of unused memory | bytes |
| Disk Read Bytes [Basic] | Read bytes | bytes |
| Disk Read Requests [Basic] | Number of read requests | cnt |
| Disk Write Bytes [Basic] | write bytes | bytes |
| Disk Write Requests [Basic] | Number of write requests | cnt |
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Instance State [Basic] | Instance status | state |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Dropped [Basic] | Incoming packet drop | cnt |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Dropped [Basic] | Transmit packet drop | cnt |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. Virtual Server Monitoring Metrics (Provided by default)
| Performance items | Detailed description | unit |
|---|---|---|
| Core Usage [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| Core Usage [System] | Proportion of CPU time spent in kernel space | % |
| Core Usage [User] | Proportion of CPU time spent in user space | % |
| CPU Cores | Number of CPU cores on the host | cnt |
| CPU Usage [Active] | Percentage of CPU time used other than Idle and IOWait states | % |
| CPU Usage [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage [IO Wait] | This is the proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage [User] | Percentage of CPU time used in user space | % |
| CPU Usage/Core [Active] | Percentage of CPU time used other than Idle and IOWait states | % |
| CPU Usage/Core [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage/Core [IO Wait] | This is the proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage/Core [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage/Core [User] | Percentage of CPU time used in user space | % |
| DiskCPU Usage [IO Request] | Proportion of CPU time during which I/O requests to the device were executed | % |
| Disk Queue Size [Avg] | The average queue length of requests executed for the device. | num |
| Disk Read Bytes | The number of bytes read per second from the device. | bytes |
| Disk Read Bytes [Delta Avg] | Average of system.diskio.read.bytes_delta for individual disks | bytes |
| Disk Read Bytes [Delta Max] | Maximum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Min] | Minimum of system.diskio.read.bytes_delta for individual disks | bytes |
| Disk Read Bytes [Delta Sum] | Sum of system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta] | Delta of the system.diskio.read.bytes value for each Disk | bytes |
| Disk Read Bytes [Success] | Total bytes successfully read | bytes |
| Disk Read Requests | Number of read requests to the disk device per second | cnt |
| Disk Read Requests [Delta Avg] | Average of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Max] | Maximum system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Min] | Minimum of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Sum] | Sum of the system.diskio.read.count_delta of individual disks | cnt |
| Disk Read Requests [Success Delta] | Delta of system.diskio.read.count for each Disk | cnt |
| Disk Read Requests [Success] | Total number of successful reads | cnt |
| Disk Request Size [Avg] | It is the average size of requests executed on the device (unit: sectors). | num |
| Disk Service Time [Avg] | Average service time (milliseconds) of input requests executed on the device. | ms |
| Disk Wait Time [Avg] | Average time taken for requests executed on the supported device. | ms |
| Disk Wait Time [Read] | Average disk wait time | ms |
| Disk Wait Time [Write] | Average disk wait time | ms |
| Disk Write Bytes [Delta Avg] | Average of system.diskio.write.bytes_delta for each disk | bytes |
| Disk Write Bytes [Delta Max] | Maximum system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta Min] | Minimum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta Sum] | Sum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta] | Delta of the system.diskio.write.bytes value for each Disk | bytes |
| Disk Write Bytes [Success] | Total number of bytes successfully written | bytes |
| Disk Write Requests | Number of write requests to the disk device per second | cnt |
| Disk Write Requests [Delta Avg] | Average of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Max] | Maximum system.diskio.write.count_delta of individual disks | cnt |
| Disk Write Requests [Delta Min] | Minimum of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Sum] | Sum of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Success Delta] | Delta of system.diskio.write.count for each Disk | cnt |
| Disk Write Requests [Success] | Total number of successful writes | cnt |
| Disk Writes Bytes | Bytes per second written to the device | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang check(normal:1, abnormal:0) | status |
| Filesystem Nodes | Total number of file nodes in the file system. | cnt |
| Filesystem Nodes [Free] | It is the total number of available file nodes in the file system. | cnt |
| Filesystem Size [Available] | Disk space (bytes) available to unauthorized users | bytes |
| Filesystem Size [Free] | Available disk space (bytes) | bytes |
| Filesystem Size [Total] | Total disk space (bytes) | bytes |
| Filesystem Usage | Used disk space percentage | % |
| Filesystem Usage [Avg] | Average of individual filesystem.used.pct | % |
| Filesystem Usage [Inode] | iNode usage rate | % |
| Filesystem Usage [Max] | Maximum among individual filesystem.used.pct | % |
| Filesystem Usage [Min] | Min among individual filesystem.used.pct | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | Used disk space (bytes) | bytes |
| Filesystem Used [Inode] | iNode usage | bytes |
| Memory Free | Total available memory (bytes) | bytes |
| Memory Free [Actual] | Actual usable Memory (bytes) | bytes |
| Memory Free [Swap] | Available Swap memory | bytes |
| Memory Total | Total Memory | bytes |
| Memory Total [Swap] | Total Swap memory. | bytes |
| Memory Usage | Percentage of used memory | % |
| Memory Usage [Actual] | Percentage of memory actually used | % |
| Memory Usage [Cache Swap] | cached swap usage | % |
| Memory Usage [Swap] | Percentage of used Swap memory | % |
| Memory Used | Used Memory | bytes |
| Memory Used [Actual] | Actual memory used (bytes) | bytes |
| Memory Used [Swap] | Used Swap memory | bytes |
| Collisions | Network collision | cnt |
| Network In Bytes | Number of received bytes | bytes |
| Network In Bytes [Delta Avg] | Average of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta Max] | Maximum system.network.in.bytes_delta for each Network | bytes |
| Network In Bytes [Delta Min] | Minimum of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Sum] | Sum of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta] | Delta of received byte count | bytes |
| Network In Dropped | Number of deleted packets among incoming packets | cnt |
| Network In Errors | Number of errors during reception | cnt |
| Network In Packets | Number of received packets | cnt |
| Network In Packets [Delta Avg] | Average of system.network.in.packets_delta for individual Networks | cnt |
| Network In Packets [Delta Max] | Maximum of system.network.in.packets_delta for each Network | cnt |
| Network In Packets [Delta Min] | Minimum of system.network.in.packets_delta for each Network | cnt |
| Network In Packets [Delta Sum] | Sum of system.network.in.packets_delta for individual Networks | cnt |
| Network In Packets [Delta] | Delta of received packet count | cnt |
| Network Out Bytes | Number of transmitted bytes | bytes |
| Network Out Bytes [Delta Avg] | Average of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Max] | Maximum system.network.out.bytes_delta for each Network | bytes |
| Network Out Bytes [Delta Min] | Minimum of system.network.out.bytes_delta for individual Networks | bytes |
| Network Out Bytes [Delta Sum] | Sum of system.network.out.bytes_delta for individual Networks | bytes |
| Network Out Bytes [Delta] | Delta of transmitted byte count | bytes |
| Network Out Dropped | Number of deleted packets among outgoing packets | cnt |
| Network Out Errors | Number of errors during transmission | cnt |
| Network Out Packets | Number of transmitted packets | cnt |
| Network Out Packets [Delta Avg] | Average of system.network.out.packets_delta for each Network | cnt |
| Network Out Packets [Delta Max] | Maximum system.network.out.packets_delta for each Network | cnt |
| Network Out Packets [Delta Min] | Minimum of system.network.out.packets_delta for each Network | cnt |
| Network Out Packets [Delta Sum] | Sum of system.network.out.packets_delta for individual networks | cnt |
| Network Out Packets [Delta] | Delta of transmitted packet count | cnt |
| Open Connections [TCP] | All open TCP connections | cnt |
| Open Connections [UDP] | All open UDP connections | cnt |
| Port Usage | Connectable port utilization | % |
| SYN Sent Sockets | Number of sockets in SYN_SENT state (when connecting from local to remote) | cnt |
| Kernel PID Max | kernel.pid_max value | cnt |
| Kernel Thread Max | kernel.threads-max value | cnt |
| Process CPU Usage | Percentage of CPU time consumed by the process since the last update | % |
| Process CPU Usage/Core | Percentage of CPU time used by the process since the last event | % |
| Process Memory Usage | Proportion of main memory (RAM) occupied by a process | % |
| Process Memory Used | Resident Set size. The amount of memory a process occupies in RAM. | bytes |
| Process PID | process pid | pid |
| Process PPID | Parent process PID | pid |
| Processes [Dead] | Number of deadProcesses | cnt |
| Processes [Idle] | idle Processes count | cnt |
| Processes [Running] | running Processes count | cnt |
| Processes [Sleeping] | sleeping processes count | cnt |
| Processes [Stopped] | stopped processes count | cnt |
| Processes [Total] | Total number of processes | cnt |
| Processes [Unknown] | Number of processes whose status cannot be retrieved or is unknown | cnt |
| Processes [Zombie] | Number of zombie processes | cnt |
| Running Process Usage | process usage | % |
| Running Processes | Number of running processes | cnt |
| Running Thread Usage | Thread usage rate | % |
| Running Threads | Total number of threads running in running processes | cnt |
| Context Switches | context switch count (per second) | cnt |
| Load/Core [1 min] | The load over the last 1 minute divided by the number of cores | cnt |
| Load/Core [15 min] | The load over the last 15 minutes divided by the number of cores | cnt |
| Load/Core [5 min] | The load over the last 5 minutes divided by the number of cores | cnt |
| Multipaths [Active] | External storage connection path status = active count | cnt |
| Multipaths [Failed] | External storage connection path status = failed count | cnt |
| Multipaths [Faulty] | External storage connection path status = faulty count | cnt |
| NTP Offset last | sample’s measured offset (time difference between NTP server and local environment) | num |
| Run Queue Length | Execution queue length | num |
| Uptime | OS uptime (milliseconds) | ms |
| Context Switchies CPU | context switch count (per second) | cnt |
| Disk Read Bytes [Sec] | Number of bytes read in one second from a Windows logical disk
| cnt |
| Disk Read Time [Avg] | Data read average time (seconds)
| sec |
| Disk Transfer Time [Avg] | Disk average wait time (seconds)
| sec |
| Disk Write Bytes [Sec] | Number of bytes written in one second on a Windows logical disk
| cnt |
| Disk Write Time [Avg] | Average data write time (seconds)
| sec |
| Pagingfile Usage | paging file usage
| % |
| Pool Used [Non Paged] | Nonpaged Pool usage in kernel memory
| bytes |
| Pool Used [Paged] | Paged Pool usage in kernel memory
| bytes |
| Process [Running] | Number of currently running processes
| cnt |
| Threads [Running] | Number of currently running threads
| cnt |
| Threads [Waiting] | Number of threads waiting for processor time
| cnt |
Table. Additional monitoring metrics for Virtual Server (Agent installation required)
1.1.3 - ServiceWatch Metrics
Virtual Server sends metrics to ServiceWatch. The metrics provided by default monitoring are data collected at 5‑minute intervals. If detailed monitoring is enabled, you can view data collected at 1‑minute intervals.
Reference
For how to view metrics in ServiceWatch, refer to the ServiceWatch guide.
See How-to guides > ServiceWatch Enable Detailed Monitoring for instructions on enabling detailed monitoring of Virtual Server.
Basic Metrics
The following are the basic metrics for the Virtual Server namespace.
The indicators whose names are displayed in bold below are the indicators selected as key metrics among the default metrics provided by Virtual Server. The key metrics are used to build service dashboards that are automatically generated for each service in ServiceWatch. They can also be viewed on the Monitoring tab of the Virtual Server detail page.
Each metric provides guidance in the user guide on which statistical value is meaningful to query, and among the meaningful statistics, the values shown in bold text are the primary statistics. In the service dashboard or monitoring tab, you can view primary metrics using these primary statistics.
| Performance item (indicator name) | Detailed description | unit | meaningful statistics | |
|---|---|---|---|---|
| Instance State | Instance status display
| None |
| |
| CPU Usage | CPU usage | Percent |
| |
| Disk Read Bytes | Bytes read from block device (bytes) | Bytes |
| |
| Disk Read Requests | Number of read requests on a block device | Count |
| |
| Disk Write Bytes | Write capacity (bytes) on block device | Bytes |
| |
| Disk Write Requests | Number of write requests on block device | Count |
| |
| Network In Bytes | Received bytes on the network interface | Bytes |
| |
| Network In Dropped | Number of packet drops received on the network interface | Count |
| |
| Network In Packets | Number of packets received on the network interface | Count |
| |
| Network Out Bytes | Data transmitted on the network interface (bytes) | Bytes |
| |
| Network Out Dropped | Number of packet drops transmitted from the network interface | Count |
| |
| Network Out Packets | Number of packets transmitted on the network interface | Count |
|
Table. Virtual Server basic metrics
Reference
Refer to the ServiceWatch Agent guide for how to collect metrics using the ServiceWatch Agent.
1.2 - How-to guides
Users can create the service by entering the required Virtual Server information and selecting detailed options through the Samsung Cloud Platform Console.
Create Virtual Server
You can create and use the Virtual Server service in the Samsung Cloud Platform Console.
To create a Virtual Server, follow these steps.
All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
On the Service Home page, click the Create Virtual Server button. 2. Create Virtual Server page.
On the Virtual Server Creation page, enter the information required to create the service and select detailed options.
- Select the required information in the Image and version selection area.
Category RequiredDetailed description Image Essential Select the type of Image provided - Standard: Samsung Cloud Platform standard Image
- Alma Linux, Oracle Linux, RHEL, Rocky Linux, Ubuntu, Windows
- Custom: User-created Image
- Kubernetes: Kubernetes Image
- RHEL, Ubuntu
- Marketplace: Image subscribed from Marketplace
Image version Essential Select version of the chosen Image - Provide version list of the provided server Image
Table. Virtual Server Image and version selection input items - Standard: Samsung Cloud Platform standard Image
- Enter or select the required information in the Service Information Input area.
Category RequiredDetailed description Number of servers Essential Number of servers to create simultaneously - Only numeric input is allowed, enter a value between 1~100
Service Type > Server Type Essential Virtual Server 서버 타입 - Standard: standard specifications commonly used
- High Capacity: large-capacity server specifications beyond Standard
- For detailed information about the server types provided by Virtual Server, see Virtual Server 서버 타입
Service Type > Planned Compute Essential Status of resources with Planned Compute set - In Use: Number of resources with Planned Compute that are currently in use
- Configured: Number of resources with Planned Compute set
- Coverage Preview: Amount applied per resource by Planned Compute
- Apply for Planned Compute Service: Go to the Planned Compute service creation page
- For more details, refer to Planned Compute 신청하기
Block Storage Essential Block Storage settings used by the server according to purpose - Basic OS: The area where the OS is installed and used
- Enter the size in Units; the minimum size varies depending on the OS Image type
- Alma Linux: Enter a value between 2 and 1,536
- Oracle Linux: Enter a value between 7 and 1,536
- RHEL: Enter a value between 2 and 1,536
- Rocky Linux: Enter a value between 2 and 1,536
- Ubuntu: Enter a value between 2 and 1,536
- Windows: Enter a value between 4 and 1,536
- SSD: High‑performance general volume
- HDD: General volume
- SSD/HDD_KMS: Additional encrypted volume using Samsung Cloud Platform KMS (Key Management Service) encryption keys
- Encryption can only be applied at initial creation and cannot be changed afterward
- Using the SSD_KMS disk type may cause performance degradation
- SSD_Provisioned: SSD volume with configurable IOPS and Throughput
- Enter the size in Units; the minimum size varies depending on the OS Image type
- Additional: Use when additional user space beyond the OS area is needed
- After selecting Use, enter the storage type and size
- Click the + button to add storage, or the x button to delete (up to 25 can be added)
- Enter the size in Units, with a value between 1 and 1,536
- Since 1 Unit equals 8 GB, this creates 8 – 12,288 GB
- SSD: High‑performance general volume
- HDD: General volume
- SSD/HDD_KMS: Additional encrypted volume using Samsung Cloud Platform KMS (Key Management Service) encryption keys
- Encryption can only be applied at initial creation and cannot be changed afterward
- Using the SSD_KMS disk type may result in performance degradation
- SSD/HDD_MultiAttach: Volume that can be attached to two or more servers
- SSD_Provisioned: SSD volume with configurable IOPS and Throughput
- For details on each Block Storage type, see Block Storage 생성하기
- Delete on termination: When Delete on Termination is selected, the volume is terminated together with the server
- Volumes with snapshots are not deleted even when Delete on termination is enabled
- A multi‑attach volume can be deleted only when the server being removed is the last remaining server attached to the volume
- Max IOPS: Enter a maximum IOPS value between 5,000 and 20,000
- Cannot be set for disk types HDD, HDD_KMS, or HDD_MultiAttach
- Max Throughput: Enter a maximum Throughput value between 250 and 1,000
- Cannot be set for disk types HDD, HDD_KMS, or HDD_MultiAttach
Server Group Selection After selecting Use to set Anti-Affinity (distributed placement), Affinity (proximate placement), Partition (distributed placement of Virtual Server and Block Storage) for servers belonging to the same Server Group - , select the Server Group
- , choose Create New to create a Server Group
Place servers belonging to the same Server Group according to the selected policy using a Best Effort method The policy is selected from Anti-Affinity (distributed placement), Affinity (proximate placement), or Partition (distributed placement of Virtual Server and Block Storage) Table. Virtual Server service information input itemsCautionWhen using the Partition (distributed placement of Virtual Server and Block Storage) policy among Server Group policies, you cannot allocate additional Block Storage Volumes after creating a Virtual Server, so create all required Block Storage during the Virtual Server creation stage. - Required Information Input area, please enter or select the necessary information.
Category RequiredDetailed description Server name Essential Enter a name to distinguish the server when the selected number of servers is 1 - Set the hostname to the entered server name
- Enter using English letters, numbers, spaces, and special characters (
-,_) within 63 characters
Network Settings > Create New Network Port Essential Set the network where the Virtual Server will be installed - VPC name: Select a pre‑created VPC
- General Subnet: Select a pre‑created general Subnet
- IP can be auto‑generated or manually entered, and if Enter is selected, the user can input the IP directly
- NAT: Available only when there is a single server and the VPC is attached to an Internet Gateway. Checking Use allows selection of a NAT IP
- NAT IP: Select a NAT IP
- If no NAT IP is available to select, click the Create New button to generate a Public IP
- Refresh button: Click to view and select the created Public IP
- Creating a Public IP incurs charges according to the Public IP pricing policy
- Local Subnet (optional): Select Use for the local Subnet
- It is not a required element for creating the service
- A pre‑created local Subnet must be selected
- IP can be auto‑generated or manually entered, and selecting Enter allows the user to input the IP directly
Network Settings > Specify Existing Network Port Essential Set the network where the Virtual Server will be installed - VPC: Select a pre-created VPC
- General Subnet: Select a pre-created General Subnet and Port
- NAT: Available only when there is a single server and the VPC has an Internet Gateway attached. When selected, you can choose a NAT IP
- NAT IP: Select the NAT IP
- If there is no NAT IP to select, click the Create New button to generate a Public IP
- Refresh button to view and select the created Public IP
- Local Subnet (optional): Select Use for the local subnet
- Select a pre-created local Subnet and Port
Security Group Selection Settings required to connect to the server - Select: Up to 5 pre‑created Security Groups can be selected
- Create New: If there is no applicable Security Group, create one separately in the Security Group service
- If a Security Group is not set, all connections are blocked, so you must configure it to allow the necessary connections
Keypair Essential User authentication method to use when connecting to the server - New creation: Create a new one if a new Keypair is required
- Refer to Keypair 생성하기
- Default login account list by OS
- Alma Linux: almalinux
- Oracle Linux: cloud-user
- RHEL: cloud-user
- Rocky Linux: rocky
- Ubuntu: ubuntu
- Windows: sysadmin
Table. Virtual Server required information input fieldsReference- The default OS account can serve as the default user account in a cloud environment and can be used for initial configuration via cloud-init and SCP-related functions.
- If you delete or change the primary account, related Samsung Cloud Platform functions may not work properly, so deletion or modification is not recommended.
- Additional Information Input area, enter or select the required information.
Category RequiredDetailed description Lock Selection Lock usage setting - When you use Lock, it prevents actions such as terminating, starting, or stopping the server, thereby avoiding malfunctions caused by mistakes
Init script Selection Script executed when the server starts - The init script must be written as a Batch script for Windows, a Shell script for Linux, or cloud‑init, depending on the image type.
- Up to 45,000 bytes can be entered
tag Selection Add Tag - Up to 50 can be added per resource
- After clicking the Add Tag button, input or select Key, Value values
Table. Virtual Server additional information input fields
- Select the required information in the Image and version selection area.
Summary Verify the detailed information and estimated charges generated in the panel, then click the Create button.
When the popup indicating creation opens, click the Confirm button.
- When creation is complete, verify the created resources on the Virtual Server List page.
information
- When entering the server name, if spaces and special characters (
_) are used, the OS hostname will have those spaces and special characters (_) converted to the special character (-) and set. * Refer to this when setting the OS hostname.- Example: If the server name is ‘server name_01’, the OS hostname is set to ‘server-name-01’.
- If you need to manage server names uniquely, specify a different server name (Prefix) when creating them.
- When creating a server, because the numbering does not automatically increment based on the server name (Prefix), a Virtual Server with the same name can be created.
- Example: If you first create two Virtual Servers using the server name (Prefix) ’test’, ’test-1’ and ’test-2’ will be created. * After that, even if you create two Virtual Servers using the prefix ’test’ again, ’test-1’ and ’test-2’ will be created.
Reference
- When creating a Virtual Server with Rocky Linux or Oracle Linux, additional configuration is required for time synchronization (NTP:Network Time Protocol). * For detailed information, refer to Linux NTP 설정하기.
- If RHEL and Windows Server were created before July 2025, the RHEL Repository and WKMS (Windows Key Management Service) settings need to be modified. * For more information, refer to RHEL Repo 및 WKMS 설정하기.
View Virtual Server Details
The Virtual Server service lets you view and modify the complete resource list and detailed information. The Virtual Server Details page consists of Details, Monitoring, Tags, Activity History tabs.
To view detailed information about the Virtual Server service, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- On the Virtual Server List page, click the resource to view detailed information. 3. Navigate to the Virtual Server Details page.
- Virtual Server Details page displays status information and additional feature information, and consists of Details, Monitoring, Tags, Activity Log tabs.
- For detailed information about Virtual Server Additional Features, please refer to Virtual Server 관리 부가 기능.
Category Detailed description Virtual Server status State of a user-created Virtual Server - Build: State where a Build command has been issued
- Building: Build in progress
- Networking: Server creation process in progress
- Scheduling: Server creation process in progress
- Block_Device_Mapping: Connecting Block Storage during server creation
- Spawning: State where the server creation process is ongoing
- Active: Available state
- Powering_off: State when a stop request is made
- Deleting: Server deletion in progress
- Reboot_Started: Reboot in progress state
- Error: Error state
- Migrating: State where the server is migrating to another host
- Reboot: State where a Reboot command has been issued
- Rebooting: Reboot in progress
- Rebuild: State where a Rebuild command has been issued
- Rebuilding: State when a Rebuild request is made
- Rebuild_Spawning: State where the Rebuild process is ongoing
- Resize: State where a Resize command has been issued
- Resizing: Resize in progress
- Resize_Prep: State when a server type modification is requested
- Resize_Migrating: State where the server is moving to another host while resizing
- Resize_Migrated: State where the server has completed moving to another host during resize
- Resize_Finish: Resize completed
- Revert_Resize: Resize or migration of the server failed for some reason. The target server is cleaned up and the original source server is restarted
- Shutoff: State when powering off is completed
- Verity_ Resize: State after Resize_Prep is performed following a server type modification request, where the server type is finalized or can be reverted
- Resize_Reverting: State when a server type revert request is made
- Resize_Confirming: State where the server’s Resize request is being confirmed
Server control Button to change server status - Start: Start a stopped server
- Stop: Stop a running server
- Restart: Restart a running server
Image generation Create a user Image from the current server’s Image - For detailed Image creation instructions, refer to Image 생성하기
Console log Current server console log view - You can view the console logs output by the current server. For more details, refer to 콘솔 로그 확인하기
Create dump Create a dump of the current server - The dump file is created inside the Virtual Server
- For detailed dump creation instructions, see Dump 생성하기
Rebuild The OS area data and settings of the existing Virtual Server are deleted, and it is rebuilt as a new server - For more details, refer to Rebuild 수행하기
Service cancellation Cancel service button Table. Virtual Server status information and additional features
Detailed Information
On the Virtual Server List page, you can view detailed information of the selected resource and, if needed, modify the information.
| Category | Detailed description |
|---|---|
| service | Service Name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation Date/Time | Service creation date and time |
| Editor | User who edited the service information |
| Modification timestamp | Date and time the service information was modified |
| Server name | Server name
|
| Server type | vCPU, memory information display
|
| Image name | Server OS Image and version
|
| Lock | Indicates whether Lock is enabled or disabled
|
| Server group | Server group name to which the server belongs
|
| Keypair name | Server authentication information set by the user
|
| Planned Compute | Resource status with Planned Compute configured
|
| ServiceWatch detailed monitoring | Display whether ServiceWatch detailed monitoring is enabled
|
| network | Network information of the Virtual Server
|
| Local Subnet | Local Subnet information of the Virtual Server
|
| Block Storage | Block Storage information attached to the server
|
Table. Virtual Server detailed information tab items
Monitoring
On the Virtual Server List page, you can monitor the ServiceWatch metrics of the selected resources. In the Monitoring tab, you can view monitoring charts for the Virtual Server, and each chart is based on the available Service Watch metrics.
| Category | Detailed description |
|---|---|
| Period setting area | Period selection applied to the chart
|
| Time Zone Settings Area | Select the time zone applied to the chart |
| Reset button | Reset all modifications and settings in the chart. |
| Refresh Settings Area | Select chart refresh interval
|
| Go to the service dashboard | Go to the ServiceWatch dashboard list screen |
| More | Display additional tasks for managing charts
|
| graph area | Data graph collected during the period applied to the chart
|
Table. Virtual Server Monitoring Tab Chart Items
Reference
- The metrics provided by basic monitoring are data collected at 5‑minute intervals.
- For detailed information about the ServiceWatch metrics of Virtual Server, see Virtual Server의 ServiceWatch 지표.
Tag
On the Virtual Server List page, you can view the tag information of the selected resource, and you can add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Virtual Server Tag Tab Items
Job History
On the Virtual Server List page, you can view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Virtual Server operation history tab detailed information items
Control Virtual Server Operation
If you need to control the operation of a created Virtual Server resource, you can perform the task from the Virtual Server List or Virtual Server Details page. You can start, stop, and restart a running server.
Virtual Server Getting Started
You can start a Virtual Server that is shut off. To start the Virtual Server, follow the steps below.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- Virtual Server List page, click the resource to start among the stopped (Shutoff) servers, and navigate to the Virtual Server Details page.
- On the Virtual Server List page, you can Start each resource using the right More button.
- After selecting multiple servers with checkboxes, you can control multiple servers simultaneously via the Start button at the top.
- On the Virtual Server Details page, click the Start button at the top to start the server. 4. Check the status of the changed server in the Status Indicator item.
- When the Virtual Server start is complete, the server status changes from Shutoff to Active.
- For detailed information about the Virtual Server status, please refer to Virtual Server 상세 정보 확인하기.
Stop Virtual Server
You can stop a Virtual Server that is running (Active). To stop the Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Virtual Server List Navigate to the page.
- Virtual Server List page, click the resource to stop among the servers that are active, and navigate to the Virtual Server Details page.
- On the Virtual Server List page, you can Stop each resource using the right More button.
- After selecting multiple servers with checkboxes, you can control multiple servers simultaneously using the Stop button at the top.
- On the Virtual Server Details page, click the Stop button at the top to start the server. 4. Check the status of the changed server in the Status Indicator item.
- When the Virtual Server shutdown is complete, the server status changes from Active to Shutoff.
- For detailed information about the Virtual Server status, please refer to Virtual Server 상세 정보 확인하기.
Restart Virtual Server
You can restart the created Virtual Server. To restart the Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- Virtual Server List page, click the resource to restart, and navigate to the Virtual Server Details page.
- Virtual Server List page allows you to restart each resource via the right More button.
- After selecting multiple servers with checkboxes, you can control multiple servers simultaneously via the Restart button at the top.
- On the Virtual Server Details page, click the Restart button at the top to start the server. 4. Check the status of the changed server in the Status Indicator item.
- During a Virtual Server restart, the server status passes through Rebooting and finally changes to Active.
- For detailed information about the Virtual Server status, please refer to Virtual Server 상세 정보 확인하기.
Managing Virtual Server Resources
If you need server control and management functions for the created Virtual Server resources, you can perform tasks from the Virtual Server List or Virtual Server Details page.
Create Image
You can create an image of a running Virtual Server.
Reference
This document provides instructions on how to create a user image on a running Virtual Server.
- Virtual Server List or Virtual Server Details page, click the Create Image button to generate a user Image.
- Refer to Image 상세 가이드 내 Image 생성하기 for the method of uploading a user’s owned Image file to create an Image.
To create a Virtual Server Image, follow the steps below.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
On the Virtual Server List page, click the resource to create an Image. 3. Navigate to the Virtual Server Details page.
On the Virtual Server Details page, click the Create Image button. 4. Go to the Image creation page.
- Enter the required information in the Service Information Input area.
Category RequiredDetailed description Image name Essential the name of the Image to be created - Enter within 200 characters using English letters, numbers, spaces, and special characters(
-,_)
Table. Image service information input items - Enter within 200 characters using English letters, numbers, spaces, and special characters(
- Enter the required information in the Service Information Input area.
Check the input information and click the Done button.
- Once creation is complete, check the created resource on the All Services > Compute > Virtual Server > Image List page.
information
- When an Image is created, the generated Image is stored in the Object Storage used as internal storage. * Therefore, usage fees will be charged for Image storage.
- Since the file system of an Image created from an Active Virtual Server cannot be guaranteed to be intact, it is recommended to stop the server before creating the Image.
Edit server type
You can modify the server type of a Virtual Server.
Reference
For the configurable server types provided by Virtual Server, refer to Virtual Server 서버 타입.
To modify the server type of a Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- On the Virtual Server List page, click the resource to control its operation. 3. Navigate to the Virtual Server Details page.
- On the Virtual Server Details page, check the server status and click the server type Edit button. 4. Edit Server Type popup window opens.
- Edit Server Type In the popup window, after changing the server type, click the Confirm button.
- If you modify the Virtual Server’s server type, the Virtual Server status changes to a state related to performing a resize.
- For detailed information about the Virtual Server status, please refer to Virtual Server 상세 정보 확인하기.
Reference
If you change the Virtual Server’s server type, monitoring performance metric data may not be collected properly for a short period. In the next collection cycle (1 minute), normal performance metrics will be collected.
Change IP
Please refer to IP 변경하기 for instructions on changing the IP.
Caution
- If you proceed with changing the IP, you will no longer be able to communicate using that IP, and you cannot cancel the IP change while it is in progress.
- The server is rebooted to apply the changed IP.
- If the server is running the Load Balancer service, you must delete the old IP from the LB server group and directly add the new IP as a member of the LB server group.
- Servers using Public NAT/Private NAT must disable and reconfigure Public NAT/Private NAT after changing the IP.
- If you are using Public NAT/Private NAT, first disable the use of Public NAT/Private NAT, complete the IP change, and then reconfigure.
- Whether to use Public NAT/Private NAT can be changed by clicking the Edit button of Public NAT IP/Private NAT IP on the Virtual Server Details page.
- Public NAT IP can only be modified when there is one server, the VPC is connected to an Internet Gateway, and the regular subnet is public.
Enable detailed monitoring for ServiceWatch
By default, Virtual Server is linked with ServiceWatch for basic monitoring. You can enable detailed monitoring as needed to identify operational issues more quickly and take action. For detailed information about ServiceWatch, refer to the ServiceWatch 개요.
Caution
Basic monitoring is provided for free, but enabling detailed monitoring incurs additional charges. Please note the usage.
To enable detailed ServiceWatch monitoring for a Virtual Server, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Navigate to the Virtual Server List page.
- On the Virtual Server List page, click the resource to enable detailed ServiceWatch monitoring. 3. Navigate to the Virtual Server Details page.
- Click the Edit button for ServiceWatch detailed monitoring on the Virtual Server Details page. 4. ServiceWatch Detailed Monitoring Edit Navigate to the popup window.
- ServiceWatch Detailed Monitoring Edit In the popup window, after selecting Enable, review the instructions and click the Confirm button.
- On the Virtual Server Details page, view the detailed ServiceWatch monitoring items.
Disable detailed monitoring for ServiceWatch
Caution
Disabling detailed monitoring is required for cost efficiency. Maintain detailed monitoring only when absolutely necessary, and disable detailed monitoring otherwise.
To disable detailed ServiceWatch monitoring of a Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Navigate to the Virtual Server List page.
- Virtual Server list on the page, click the resource to disable ServiceWatch detailed monitoring. 3. Navigate to the Virtual Server Details page.
- On the Virtual Server Details page, click the Edit button for ServiceWatch detailed monitoring. 4. ServiceWatch Detailed Monitoring Edit Navigate to the popup window.
- ServiceWatch Detailed Monitoring Edit In the popup window, after deselecting Enable, review the guidance message and click the Confirm button.
- On the Virtual Server Details page, check the ServiceWatch detailed monitoring items.
Virtual Server management add‑on features
For Virtual Server management, you can view console logs, generate dumps, and perform rebuilds. To view the console log, generate a dump, and rebuild a Virtual Server, follow these steps.
Check console log
You can view the current console log of the Virtual Server.
To view the console log of a Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- Virtual Server List On the page, click the resource to view the console log. 3. Navigate to the Virtual Server Details page.
- Virtual Server Details on the page, click the Console Log button. 4. Console Log navigates to the popup window.
- Console Log Check the console log output in the popup window.
Create Dump
To create a Dump file of the Virtual Server, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Navigate to the Virtual Server List page.
- On the Virtual Server List page, click the resource to view detailed information. 3. Navigate to the Virtual Server Details page.
- Click the Create Dump button on the Virtual Server Details page.
- The dump file is created inside the Virtual Server.
Execute Rebuild
You can delete the OS data and configuration of the existing Virtual Server and rebuild it on a new server.
To perform a Rebuild of a Virtual Server, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- On the Virtual Server List page, click the resource to perform Rebuild. 3. Navigate to the Virtual Server Details page.
- On the Virtual Server Details page, click the Rebuild button.
- During a Virtual Server Rebuild, the server status changes to Rebuilding, and when the Rebuild is complete, it returns to its pre‑Rebuild state.
- For detailed information about the Virtual Server status, please refer to Virtual Server 상세 정보 확인하기.
Terminate Virtual Server
If you terminate an unused Virtual Server, you can reduce operating costs. However, if you terminate a Virtual Server, the running service may be stopped immediately, so you should proceed with the termination only after fully considering the impact of service interruption.
Caution
Please be aware that data cannot be recovered after terminating the service.
To cancel a Virtual Server, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Virtual Server List page is accessed.
- On the Virtual Server List page, select the resource to terminate, and click the Terminate Service button.
- The termination of attached storage depends on the Delete on termination setting; see 해지 제약 사항.
- If the termination is complete, check on the Virtual Server list page whether the resource has been terminated.
Termination constraints
When a Virtual Server termination request cannot be processed, a popup window will provide guidance. Please refer to the case below.
Cancellation not allowed
- If File Storage is connected: Disconnect the File Storage first.
- If the LB server group is connected: First, disconnect the LB server group pool connection.
- When Lock is set: After changing the Lock setting to disabled, try again.
- If the Auto-Scaling Group attached to the Virtual Server is not In Service: After changing the status of the attached Auto-Scaling Group, try again.
Termination of attached storage varies depending on the Delete on termination setting; please refer to it.
Delete on termination: delete per configuration
- Whether the volume is deleted also depends on the Delete on termination setting.
- Delete on termination when not set: Even if you terminate the Virtual Server, the volume will not be deleted.
- Delete on termination when set: If the Virtual Server is terminated, the volume will be deleted.
- Volumes that have a snapshot will not be deleted even if Delete on termination is set.
- A multi-attach volume can be deleted only when the server being deleted is the last remaining server attached to the volume.
1.2.1 - Image
Users can create the service by entering the required information for the Image service within the Virtual Server service and selecting detailed options through the Samsung Cloud Platform Console.
Create Image
You can create and use the Image service while using the Virtual Server service in the Samsung Cloud Platform Console.
To create an Image, follow the steps below.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
On the Service Home page, click the Image menu. 2. Go to the Image list page.
Click the Create Image button on the Image List page. 3. Navigate to the Image creation page.
- Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Image name Required the name of the Image to create - Enter within 255 characters using English letters, numbers, spaces, and special characters(
-,_)
Image file > URL Required After uploading an image file to Object Storage, enter the URL - The URL can be copied on the Object Storage Details page
- The bucket in Object Storage where the image file is uploaded must exist in the same zone as the server to be created
- Image files can only be in the .qcow2 format
- You must upload a secure image file to minimize security risks.
OS type Required OS type of the uploaded Image file - Select from Alma Linux, CentOS, Oracle Linux, RHEL, Rocky Linux, Ubuntu
Minimum disk Required Minimum disk capacity (GB) of the Image to be created 0~12,288GB, please enter a value
Minimum RAM Required Minimum RAM size (GB) of the Image to be created 0~2,097,151GB Enter a value
Visibility Required Display access permissions for the Image - Private: Only usable within the account
- Shared: Can be shared across accounts
Protected Selection Select whether Image deletion is prohibited - If you check Use, it prevents accidental deletion of the Image
- This setting cannot be changed after the Image is created
Table. Image service information input items - Enter within 255 characters using English letters, numbers, spaces, and special characters(
- Additional Information Input in this area, enter or select the required information.
Category required statusDetailed description tag Selection Add Tag - Up to 50 per resource can be added
- After clicking the Add Tag button, enter or select Key, Value values
Table. Image additional information input fields
- Enter or select the required information in the Service Information Input area.
Summary Check the detailed information and estimated billing amount generated in the panel, and click the Create button.
- When creation is complete, check the created resources on the Image List page.
Check Image detailed information
The Image service allows you to view and edit the full resource list and detailed information. Image Details page consists of Details, Tags, Activity Log tabs.
To view detailed information of the Image service, follow the steps below.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Image menu. 2. Go to the Image list page.
- On the Image list page, click the resource to view detailed information. 3. Navigate to the Image Details page.
- Image Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Category Detailed description Image status Status of the Image created by the user - Active: Available state
- Queued: When an Image creation request is made, the Image is uploaded and is pending processing
- Importing: When an Image creation request is made, the Image is uploaded and is being processed
Create shared Image Create an Image to share with another Account - Creation is possible only when the Image’s Visibility is private and the Image contains snapshot information
- Creation is not allowed if the OS disk size is 500 GB or larger
- For more details, refer to 공유용 Image 생성하기
Share with another account Image can be shared with another Account - If the Image’s Visibility is Shared, it can be shared with another Account
- Create shared Image or displayed only on Images created by uploading a qcow2 file
Delete Image Delete Image button - Deleting the Image cannot be undone
Table. Image status information and additional functions
- Image Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Detailed Information
On the Image list page, you can view detailed information of the selected resource and edit the information if needed.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Image name |
| Resource ID | Image’s unique resource ID |
| Constructor | User who created the Image |
| Creation date and time | Image creation timestamp |
| Modifier | User who edited the image information |
| Modification date and time | Date and time the image information was modified |
| Image name | Image name |
| Minimum disk | Image’s minimum disk capacity (GB)
|
| Minimum RAM | Minimum RAM size (GB) of the Image |
| OS type | Image OS type
|
| OS hash algorithm | OS hash algorithm method |
| Visibility | Display access permissions for the Image
|
| Protected | Select whether Image deletion is prohibited
|
| Image size | Image size
|
| Image type | Classification by Image creation method
|
| Image file URL | When creating an Image, the URL of the Image file uploaded to Object Storage
|
| Sharing status | Current status of sharing the Image with another Account
|
Table. Image detail information tab items
Tag
Image List page allows you to view the tag information of the selected resource, and to add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Image tag tab item
Job History
You can view the operation history of the selected resource on the Image list page.
| Category | Detailed description |
|---|---|
| Task History List | Resource change history
|
Table. Image Work History Tab Detailed Information Items
Image resource management
Describes the control and management functions of the generated Image.
Create shared Image
Create an Image to share with another Account.
Notice
- You can create a shared Image only when the Image’s Visibility is private and the Image contains snapshot information.
- If the OS disk size is 500 GB or larger, a shared Image cannot be created.
- Only one OS area disk volume is included in the imaging target for shared images. * Since the additional attached data volume is not included in the Image, if needed, copy the data to a separate volume and use the volume migration feature.
To create a shared Image, follow the steps below.
- Log in to the account to be shared and click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Image menu. 2. Go to the Image list page.
- On the Image List page, click the Image to create a shared Image. 3. Navigate to the Image Details page.
- Click the Create Image for Sharing button. 4. A popup window opens to notify the creation of a shared Image.
- After reviewing the notification content, click the Complete button.
Share Image to another Account
Create an Image to share with another Account.
Notice
- You can share only the Image created by uploading a .qcow2 extension file or by using Create Shared Image on the Image Details page with another Account.
- The Visibility of the Image to be shared must be Shared.
To share an Image with another Account, follow these steps.
Log in to the account to be shared and click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
On the Service Home page, click the Image menu. 2. Go to the Image list page.
Image List page, click the Image you want to share with another Account. 3. Go to the Image Details page.
Share to another Account Click the button. 4. A popup window notifying image sharing opens.
After reviewing the notification content, click the Confirm button. 5. Go to the Share Image with another Account page.
Share Image with another Account on the page, enter Share Account ID, and click the Complete button. 6. A popup window notifying image sharing opens.
Category required statusDetailed description Image name - Name of the Image to share - Input not allowed
Image ID - Image ID to share - Input not allowed
Shared Account ID Required Enter another Account ID to share - English letters, numbers, and special characters
-using them, enter within 64 characters
Table. Image sharing items to another accountAfter reviewing the notification content, click the Confirm button. 7. You can check the information from the sharing status on the Image Details page.
- When the request is first made, the status is Pending, and when the receiving Account approves it, it changes to Accepted; if the approval is denied, it changes to Rejected.
Receive an Image shared from another Account
To receive an Image shared from another Account, follow these steps.
Log in to the account to be shared and click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
On the Service Home page, click the Image menu. 2. Go to the Image list page.
On the Image List page, click the More > Image Share Request List button. 3. Image sharing request list The popup window opens.
Image Sharing Request List In the popup window, click the Approve or Reject button for the Image to be shared.
Category Detailed description Image name Name of shared Image OS type OS type of shared Image Owner Account ID Owner Account ID of the shared Image Creation date and time Creation time of shared Image Approval Approve the shared image Reject Reject the shared image Table. Image sharing request list itemAfter reviewing the notification content, click the Confirm button. 5. You can view the shared Image from the Image list.
Delete Image
You can delete unused Image. However, since an Image cannot be recovered once deleted, you should fully consider the impact before proceeding with the deletion.
Caution
Please be aware that data cannot be recovered after deleting the service.
To delete the Image, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Image menu. 2. Go to the Image list page.
- On the Image list page, select the resource to delete, and click the Delete button.
- On the Image List page, select multiple Image check boxes and click the Delete button at the top of the resource list.
- After the deletion is complete, verify on the Image List page that the resource has been removed.
1.2.2 - Keypair
Users can create the service by entering the required information for the Keypair within the Virtual Server service and selecting detailed options through the Samsung Cloud Platform Console.
Creating a Keypair
In the Samsung Cloud Platform Console, you can create and use the Keypair service while using the Virtual Server service.
To create a keypair, follow these steps.
Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
On the Keypair List page, click the Create Keypair button. You will be taken to the Create Keypair page.
- Enter the required information in the Service Information Input area.
Category Required statusDetailed description Keypair name Required Name of the Keypair to create - Enter within 255 characters using English letters, numbers, spaces, and special characters(
-,_)
Keypair type Required ssh Table. Keypair service information input fields - Enter within 255 characters using English letters, numbers, spaces, and special characters(
- In the Additional Information Input area, enter or select the required information.
Category RequiredDetailed description tag Selection Add Tag - Up to 50 can be added per resource
- After clicking the Add Tag button, enter or select Key, Value values
Table. Keypair additional information input fields
- Enter the required information in the Service Information Input area.
Check the input information and click the Create button.
- After creation is complete, check the created resources on the Keypair list page.
Caution
- After creation is complete, you can download the Key only once for the first time. Since reissuance is not possible, ensure that it has been downloaded.
- Store the downloaded Private Key in a safe place.
View detailed information of the Keypair
The Keypair service allows you to view and edit the full list of resources and detailed information. On the Keypair Details page, it consists of Details, Tags, Activity Log tabs.
To view detailed information about a keypair, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
- On the Keypair List page, click the resource to view detailed information. You will be taken to the Keypair Details page.
- Keypair Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Detailed Information
On the Keypair List page, you can view detailed information of the selected resource and edit the information if needed.
| Category | Detailed description |
|---|---|
| service | Service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Keypair name |
| Resource ID | Unique resource ID of the keypair |
| Constructor | User who created the keypair |
| Creation date and time | Keypair creation timestamp |
| editor | User who modified the keypair information |
| Modification date | Keypair information modification timestamp |
| Keypair name | Keypair name |
| Fingerprint | A unique value for identifying the key |
| User ID | User ID of the keypair creator |
| public key | Public key information |
Table. Keypair detailed information tab items
tag
On the Keypair List page, you can view the tag information of the selected resource and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Keypair Tag Tab Items
Job History
On the Keypair list page, you can view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Keypair operation history tab detailed information items
Keypair Resource Management
Describes the control and management functions of a keypair.
Get public key
To retrieve the public key, follow these steps.
Click the All Services > Compute > Virtual Server menu. Go to the Service Home page of Virtual Server.
On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
On the Keypair List page, click the More button at the top and then click the Import Public Key button. You will be taken to the Import Public Key page.
- Required Information Input area, please enter or select the required information.
Category RequiredDetailed description Keypair name Required Keypair name to create Keypair type Required ssh public key Required Public Key Input - Load File: Select the Attach File button to attach the public key file
- Only files with the .pem extension can be attached
- Public Key Input: Paste the copied public key value
- Keypair Details page allows copying the public key value
Table. Required input fields for retrieving the public key - Load File: Select the Attach File button to attach the public key file
- Required Information Input area, please enter or select the required information.
Review the entered information and click the Complete button.
- When creation is complete, check the created resource on the Keypair list page.
Notice
Even if you generate a new Keypair using Get Public Key, the Keypair cannot be re-downloaded. Use the Keypair that was issued at the time of initial creation.
Delete Keypair
You can delete unused Keypairs. However, once a Keypair is deleted it cannot be recovered, so please review the impact thoroughly beforehand before proceeding with deletion.
Caution
Please note that data cannot be recovered after deleting the service.
To delete a keypair, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Go to the Service Home page of Virtual Server.
- On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
- On the Keypair List page, select the resource to delete, and click the Delete button.
- On the Keypair List page, select multiple Keypair check boxes and click the Delete button at the top of the resource list.
- After the deletion is complete, verify on the Keypair List page that the resource has been deleted.
1.2.3 - Server Group
Users can create the service by entering the required information for a Server Group within the Virtual Server service and selecting detailed options through the Samsung Cloud Platform Console.
Create Server Group
In the Samsung Cloud Platform Console, you can create and use the Server Group service while using the Virtual Server service.
To create a Server Group, follow the steps below.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
On the Server Group page, click the Server Group menu. 2. Navigate to the Server Group List page.
On the Server Group List page, click the Create Server Group button. 3. Server Group creation navigate to the page.
- Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Server Group name Required Enter the name of the Server Group to be created - using English letters, numbers, spaces, and special characters (
-,_) within 255 characters
Policy Required Select the placement policy for Virtual Servers belonging to the same Server Group - Anti-Affinity(Distributed placement): A policy that places servers belonging to a Server Group on different racks and hosts as much as possible
- Affinity(Proximity placement): A policy that places servers belonging to a Server Group close together within the same rack and host as much as possible
- Partition(Virtual Server and Block Storage distributed placement): A policy that places Virtual Servers and their associated Block Storage from a Server Group into different distribution units (Partitions)
- Up to three distributions are possible, and the setting can be applied when the number of possible distributions is two or more to ensure resource availability
- Display the Partition number alongside to clearly indicate which Partition each Virtual Server and its associated Block Storage belong to
- Partition numbers are assigned based on the Partition Size (up to 3) configured for the Server Group
Table. Server Group Service Information Input ItemsReference- Virtual Servers that belong to the same Server Group are placed on a Best Effort basis according to policy, but this is not strictly guaranteed.
- using English letters, numbers, spaces, and special characters (
- Enter or select the required information in the Additional Information Input area.
Category required statusDetailed description tag Selection Add Tag - Up to 50 per resource can be added
- After clicking the Add Tag button, input or select Key, Value values
Table. Server Group additional information input items
- Enter or select the required information in the Service Information Input area.
Check the input information and click the Generate button.
When the popup notifying creation opens, click the Confirm button.
- When creation is complete, check the created resources on the Server Group List page.
Check Server Group detailed information
The Server Group service lets you view and modify the complete resource list and detailed information. Server Group Details page consists of Details, Tags, Activity Log tabs.
To view detailed information about the Server Group, follow the steps below.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Server Group menu. 2. Go to the Server Group List page.
- On the Server Group list page, click the resource to view detailed information. 3. Navigate to the Server Group Details page.
- The Server Group Details page displays status information and additional feature information, and consists of Details, Tags, Operation History tabs.
Detailed Information
Server Group List page allows you to view detailed information of the selected resource and, if necessary, edit the information.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Server Group name |
| Resource ID | Server Group’s unique resource ID |
| Constructor | User who created the Server Group |
| Creation date and time | Server Group creation date and time |
| Server Group name | Server Group name |
| Policy | Anti-Affinity(distributed placement), Affinity(proximal placement), Partition(distributed placement of Virtual Server and Block Storage) |
| Partition Size | Partition Size |
| Server Group member | Server name and Partition information of Virtual Servers belonging to the Server Group
|
Table. Server Group detailed information tab items
Tag
Server Group list page lets you view the tag information of the selected resource, and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Server Group Tag Tab Items
Job History
Server Group List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource change history
|
Table. Server Group operation history tab detailed information items
Delete Server Group
You can delete unused Server Groups. However, since a Server Group cannot be recovered once deleted, please review the impact thoroughly in advance before proceeding with deletion.
Caution
Please be aware that data cannot be recovered after deleting the service.
To delete a Server Group, follow these steps.
- All Services > Compute > Virtual Server menu, click. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Server Group menu. 2. Go to the Server Group List page.
- On the Server Group List page, select the resource to delete, and click the Delete button.
- On the Server Group List page, select multiple Server Group check boxes, and click the Delete button at the top of the resource list.
- After deletion is complete, check on the Server Group List page whether the resource has been deleted.
1.2.4 - Change IP
You can change the Virtual Server’s IP and add a network port to the Virtual Server to configure the IP.
Change IP
You can change the IP of the Virtual Server.
Caution
- If you proceed with changing the IP, you will no longer be able to communicate using that IP, and you cannot cancel the IP change while it is in progress.
- The server is rebooted to apply the changed IP.
- If the server is running the Load Balancer service, you must delete the old IP from the LB server group and directly add the new IP as a member of the LB server group.
- Servers using Public NAT/Private NAT must disable and reconfigure Public NAT/Private NAT after changing the IP.
- If you are using Public NAT/Private NAT, first disable the use of Public NAT/Private NAT, complete the IP change, and then reconfigure.
- You can change the usage of Public NAT/Private NAT by clicking the Edit button of Public NAT IP/Private NAT IP on the Virtual Server Details page.
- Public NAT IP can only be modified when there is one server, the VPC is connected to an Internet Gateway, and the regular subnet is public.
To change the IP, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- Click the Virtual Server menu on the Service Home page. 2. Go to the Virtual Server List page.
- On the Virtual Server list page, click the resource whose IP you want to change. 3. Virtual Server Details navigate to the page.
- On the Virtual Server Details page, click the Edit button for the IP entry you want to change. 4. IP edit The popup window opens.
- Edit IP in the popup window, after selecting Subnet, enter the IP to change.
- When the setup is complete, click the Confirm button.
- When the popup notifying IP modification opens, click the Confirm button.
Configure IP on the server after adding a network port
If you create a Virtual Server with Ubuntu Linux, after adding a network port in Samsung Cloud Platform, you also need to configure the IP on the server.
As the root user on the Virtual Server’s OS, use the ip command to verify the assigned network interface name.
Color modeip aip a코드블록. ip 명령어 - 네트워크 인터페이스 확인 명령어 - If an added interface is present, the following result is displayed.
Color mode[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7코드블록. ip 명령어 - 네트워크 인터페이스 확인 결과 Open the /etc/netplan/50-cloud-init.yaml file using a text editor (e.g., vim).
Add the following content to the /etc/netplan/50-cloud-init.yaml file and save it.
Color modenetwork: version: 2 ethernets: ens7: match: macaddress: "fa:16:3e:98:b6:64" dhcp4: true set-name: "ens7" mtu: 9000network: version: 2 ethernets: ens7: match: macaddress: "fa:16:3e:98:b6:64" dhcp4: true set-name: "ens7" mtu: 9000코드블록. YAML 파일 편집
Reference
Indentation is important in YAML files that configure netplan. When modifying a YAML file, please refer to the existing settings and be careful.
Use the netplan command to set an IP on the added network DEVICE.
Color modenetplan --debug applynetplan --debug apply코드블록. netplan 적용 Use the ip command to verify that the IP is set correctly.
Color mode[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7 inet 10.10.10.10/24 metric 100 brd 10.10.10.255 scope global dynamic ens7 valid_lft 43197sec preferred_lft 43197sec inet6 fe80::f816:3eff:fe0a:96bf/64 scope link valid_lft forever preferred_lft forever[root@scp-test-vm-01 ~] # ip a 3: ens7: <BROADCAST,MULTICAST> mtu 9000 qdisc noop state DOWN group default qlen 1000 link/ether fa:16:3e:98:b6:64 brd ff:ff:ff:ff:ff:ff altname enp0s7 inet 10.10.10.10/24 metric 100 brd 10.10.10.255 scope global dynamic ens7 valid_lft 43197sec preferred_lft 43197sec inet6 fe80::f816:3eff:fe0a:96bf/64 scope link valid_lft forever preferred_lft forever코드블록. IP 설정 확인
1.2.5 - Configure Linux NTP
Users who create a Virtual Server with Rocky Linux or Oracle Linux via the Samsung Cloud Platform Console need additional configuration for time synchronization (NTP:Network Time Protocol). For other standard Linux images (RHEL, Alma Linux, Ubuntu), NTP is already configured, so no extra setup is required.
Installing NTP Daemon
You can configure NTP by installing the chrony daemon. To install the chrony daemon, follow the steps below.
Reference
For detailed information about chrony, see the chronyc page.
Check whether the chrony package is installed by using the dnf command as the root user on the OS of the Virtual Server.
Color modednf list chronydnf list chronyCode block. dnf command - command to verify the chrony package installation - If the chrony package is installed, the following result is displayed.
Color mode
[root@scp-test-vm-01 ~] # dnf list chrony
Last metadata expiration check: 1:47:29 ago on Wed 19 Feb 2025 05:55:57 PM KST.
Installed Packages
chrony.x86_64 3.5-1.0.1.el8 @anaconda[root@scp-test-vm-01 ~] # dnf list chrony
Last metadata expiration check: 1:47:29 ago on Wed 19 Feb 2025 05:55:57 PM KST.
Installed Packages
chrony.x86_64 3.5-1.0.1.el8 @anaconda- If the chrony package is not installed, install the chrony package using the dnf command.Color mode
dnf install chrony -ydnf install chrony -ycode block. dnf command - chrony package installation verification command
Configuring NTP Daemon
Reference
For detailed information about chrony, see the chronyc page.
To configure the chrony daemon, follow these steps.
- Open the /etc/chrony.conf file using a text editor (e.g., vim).
- Add the following content to the /etc/chrony.conf file and save it.
Color mode
server 198.19.0.54 iburstserver 198.19.0.54 iburst- Use the systemctl command to configure the chrony daemon to start automatically.
Color mode
systemctl enable chronydsystemctl enable chronydRestart the chrony daemon using the systemctl command.
Color modesystemctl restart chronydsystemctl restart chronydcode block. systemctl command - restart chrony daemon Run the chronyc sources command with the “v” option (display detailed information) to check the IP address of the configured NTP server and verify whether synchronization is in progress.
Color modechronyc sources -vchronyc sources -vCode block. chronyc sources command - check NTP synchronization - When you run the chronyc sources command, the following result is displayed.
Color mode
[root@scp-test-vm-01 ~] # chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
=========================================================================
^* 198.19.0.54 2 6 377 52 -129us[ -128us] +/- 14ms[root@scp-test-vm-01 ~] # chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
=========================================================================
^* 198.19.0.54 2 6 377 52 -129us[ -128us] +/- 14ms- Run the chronyc tracking command to check the synchronization metrics.Color mode
[root@scp-test-vm-01 ~] # chronyc tracking Reference ID : A9FEA9FE (198.19.0.54) Stratum : 3 Ref time (UTC) : Wed Feb 19 18:48:41 2025 System time : 0.000000039 seconds fast of NTP time Last offset : -0.000084246 seconds RMS offset : 0.000084246 seconds Frequency : 21.667 ppm slow Residual freq : +4.723 ppm Skew : 0.410 ppm Root delay : 0.000564836 seconds Root dispersion : 0.027399288 seconds Update interval : 2.0 seconds Leap status : Normal[root@scp-test-vm-01 ~] # chronyc tracking Reference ID : A9FEA9FE (198.19.0.54) Stratum : 3 Ref time (UTC) : Wed Feb 19 18:48:41 2025 System time : 0.000000039 seconds fast of NTP time Last offset : -0.000084246 seconds RMS offset : 0.000084246 seconds Frequency : 21.667 ppm slow Residual freq : +4.723 ppm Skew : 0.410 ppm Root delay : 0.000564836 seconds Root dispersion : 0.027399288 seconds Update interval : 2.0 seconds Leap status : Normalcode block. chronyc tracking command - NTP synchronization metric
1.2.6 - Configure RHEL Repo and WKMS
information
- If a user creates RHEL and Windows Server prior to August 2025 via the Samsung Cloud Platform Console, they need to modify the RHEL Repository and WKMS (Windows Key Management Service) settings.
- The SCP RHEL Repository is a repository provided by SCP to support user environments such as VPC Private Subnets where external access is restricted.
Since the SCP RHEL Repository synchronizes with each Region Local Repository according to an internal schedule, it is recommended to switch to an external public mirror site to apply the latest patches quickly.
RHEL Repository Configuration Guide
In Samsung Cloud Platform, when using RHEL, you can install and download the same packages as the official RHEL Repository by using the RHEL Repository provided by SCP.
SCP provides the latest repository for the given major version by default. To configure the RHEL repository, follow the steps below.
As the root user on the Virtual Server, use the cat command to verify the
/etc/yum.repos.d/scp.rhel8.repoor/etc/yum.repos.d/scp.rhel9.reposettings.Color modecat /etc/yum.repos.d/scp.rhel8.repocat /etc/yum.repos.d/scp.rhel8.repoCode block. Verify repo configuration (RHEL8) Color modecat /etc/yum.repos.d/scp.rhel9.repocat /etc/yum.repos.d/scp.rhel9.repoCode block. Verify repo configuration (RHEL9) - When checking the configuration file, the following result is displayed.Color mode
[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstream[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstreamCode block. Verify repo configuration (RHEL8) Color mode[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1Code block. Check repo configuration (RHEL9)
- When checking the configuration file, the following result is displayed.
Use a text editor (e.g., vim) to open the
/etc/hostsfile.Modify the
/etc/hostsfile with the following content and save it.Color mode198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ip198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ipcode block. Change /etc/hosts file settings Use the yum command to verify the RHEL repository connection configured on the server.
Color modeyum repolist –vyum repolist –vCode block. Verify repository connection settings - If the RHEL repository is successfully connected, you can view the repository list.Color mode
Repo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repoRepo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repoCode block. Check repository list
- If the RHEL repository is successfully connected, you can view the repository list.
Windows Key Management Service Configuration Guide
In Samsung Cloud Platform, when using Windows Server, you can activate genuine licensing by utilizing the Key Management Service provided by SCP. Follow the steps below.
Right-click the Windows Start icon, then run cmd from Windows PowerShell (Administrator) or the Windows Run menu.
In Windows PowerShell (Administrator) or cmd, please register the KMS Server by running the command below.
Color modeslmgr /skms 198.19.2.23:1688slmgr /skms 198.19.2.23:1688Code block. WKMS configuration After executing the KMS Server registration command, confirm the notification popup indicating successful registration, then click OK.
Figure. Verify WKMS settings In Windows PowerShell (Administrator) or cmd, run the command below to activate the product.
Color modeslmgr /atoslmgr /atoCode block. Windows Server activation settings After confirming the notification popup that the product activation was completed successfully, click OK.
Figure. Verify Windows Server activation Please run the command below in Windows PowerShell (Administrator) or cmd to verify that activation has been completed.
Color modeslmgr /dlvslmgr /dlvCode block. Verify Windows Server activation After confirming the notification popup that the product activation was completed successfully, click OK.
Figure. Windows Server genuine activation verification
1.2.7 - Install ServiceWatch Agent
Users can install the ServiceWatch Agent on a Virtual Server to collect custom metrics and logs.
Reference
Collecting custom metrics/logs via the ServiceWatch Agent is currently available only on Samsung Cloud Platform For Enterprise. It will also be available in other offerings in the future.
Caution
Metric collection through the ServiceWatch Agent is classified as custom metrics and, unlike the default metrics collected from each service, incurs charges; therefore, we recommend removing or disabling unnecessary metric collection settings.
ServiceWatch Agent
The agents that must be installed on a Virtual Server to collect ServiceWatch’s custom metrics and logs can be divided into two main types. It is the Prometheus Exporter and OpenTelemetry Collector.
| Category | Detailed description | |
|---|---|---|
| Prometheus Exporter | Provide metrics of a specific application or service in a format that Prometheus can scrape
| |
| Open Telemetry Collector | Acts as a centralized collector that gathers telemetry data such as metrics and logs from distributed systems, processes (filtering, sampling, etc.), and exports them to various backends (e.g., Prometheus, Jaeger, Elasticsearch, etc.)
|
Table. Explanation of Prometheus Exporter and Open Telemetry Collector
Pre-configuration for Using ServiceWatch Agent
To use the ServiceWatch Agent, please refer to ServiceWatch Agent를 위한 사전 환경 설정 and prepare the prerequisite configuration.
Install Prometheus Exporter for Virtual Server (for Linux)
Install the Prometheus Exporter on a Linux server according to the steps below.
Node Exporter installation
Install Node Exporter according to the steps below.
Create Node Exporter User
Create a dedicated user to securely isolate the Node Exporter process.
Color mode
sudo useradd --no-create-home --shell /bin/false node_exportersudo useradd --no-create-home --shell /bin/false node_exporterNode Exporter configuration
- Download to install Node Exporter.
This guide refers to the version below.
- Download path: /tmp
- Installed version: 1.7.0Color mode
cd /tmp wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gzcd /tmp wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gzCode block. Node Exporter download command
Reference
The latest version of Node Exporter can be found at Node Exporter > Releases > Lastest, and specific versions of Node Exporter can be found at Node Exporter > Releases.
Install the downloaded Node Exporter and grant permission to the executable file.
Color modecd /tmp sudo tar -xvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --strip-components=1 node_exporter-1.7.0.linux-amd64/node_exportercd /tmp sudo tar -xvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --strip-components=1 node_exporter-1.7.0.linux-amd64/node_exportercode block. Node Exporter installation command Color modesudo chown node_exporter:node_exporter /usr/local/bin/node_exportersudo chown node_exporter:node_exporter /usr/local/bin/node_exporterCode block. Node Exporter permission setting command Create service file Configure Node Exporter to collect memory metrics (meminfo) or block storage metrics (filesystem).
Color modesudo vi /etc/systemd/system/node_exporter.servicesudo vi /etc/systemd/system/node_exporter.serviceCode block. Command to open the Node Exporter service file Color mode[Unit] Description=Prometheus Node Exporter (meminfo only) Wants=network-online.target After=network-online.target [Service] User=node_exporter Group=node_exporter Type=simple ExecStart=/usr/local/bin/node_exporter \ --collector.disable-defaults \ # disable default metrics --collector.meminfo \ # Enable memory metrics --collector.filesystem # Block Storage filesystem metrics enable Restart=on-failure [Install] WantedBy=multi-user.target[Unit] Description=Prometheus Node Exporter (meminfo only) Wants=network-online.target After=network-online.target [Service] User=node_exporter Group=node_exporter Type=simple ExecStart=/usr/local/bin/node_exporter \ --collector.disable-defaults \ # disable default metrics --collector.meminfo \ # Enable memory metrics --collector.filesystem # Block Storage filesystem metrics enable Restart=on-failure [Install] WantedBy=multi-user.targetcode block. Result of opening the Node Exporter service file
Reference
The collector can be enabled or disabled using a flag.
–collector.{name}: Used to enable a specific metric.–no-collector.{name}: Disables a specific metric.- To disable all default metrics and enable only a specific collector, you can use
–collector.disable-defaults –collector.{name} ….
Below is a description of the main collector.
| Collector | Explanation | Label |
|---|---|---|
| meminfo | Provide memory statistics | - |
| filesystem | Provides file system statistics such as used disk space |
|
Table: Description of major Node Exporter collectors
- Node Exporter 지표 you can check the main metrics provided by Node Exporter and the Node Exporter Collector configuration method.
Reference
- Detailed information about the collectable metrics and how to configure them can be found in Node Exporter > Collector.
- The metrics available may vary depending on the version of the Node Exporter you are using. * Please refer to Node Exporter.
Caution
Since metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges unlike the default metrics, unnecessary metric collection must be removed or disabled to prevent excessive fees.
- Service activation and start
Register the Node Exporter service and verify the registered service and configured metrics.Color mode
sudo systemctl daemon-reload sudo systemctl enable --now node_exportersudo systemctl daemon-reload sudo systemctl enable --now node_exporterCode block. Node Exporter service activation and start command Color modesudo systemctl status node_exportersudo systemctl status node_exporterCode block. Node Exporter service check command Color modecurl http://localhost:9100/metrics | grep node_memorycurl http://localhost:9100/metrics | grep node_memoryCode block. Node Exporter metric information check command
information
If you have completed the Node Exporter configuration, you must install the Open Telemetry Collector provided by ServiceWatch to finish setting up the ServiceWatch Agent.
For more details, see ServiceWatch > ServiceWatch Agent 사용하기.
For more details, see ServiceWatch > ServiceWatch Agent 사용하기.
Install Prometheus Exporter for Virtual Server (for Windows)
Install according to the steps below to use Prometheus Exporter on a Windows server.
Install Windows Exporter
Install the Windows Exporter following the steps below.
Windows Exporter configuration
- Download the installation file to install the Windows Exporter.
- Download path: C:\Temp
- Test version: 0.31.3Color mode
$ mkdir /Temp $ Invoke-WebRequest -Uri "https://github.com/prometheus-community/windows_exporter/releases/download/v0.31.3/windows_exporter-0.31.3-amd64.exe" -OutFile "C:\Temp\windows_exporter-0.31.3-amd64.exe"$ mkdir /Temp $ Invoke-WebRequest -Uri "https://github.com/prometheus-community/windows_exporter/releases/download/v0.31.3/windows_exporter-0.31.3-amd64.exe" -OutFile "C:\Temp\windows_exporter-0.31.3-amd64.exe"code block. Download Windows Exporter
Reference
Windows Exporter version and installation files can be found at Windows Exporter > Releases.
- Windows Exporter execution test
Windows Exporter enables all collectors by default, but to collect only the metrics you want, you need to enable the following collectors. The following is an example that activates a collector specified by the user.- Memory metric: memory
- Block storage metric: local_disk
- Host name: osColor mode
$ cd C:\Temp $ .\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os$ cd C:\Temp $ .\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,oscode block. Windows Exporter execution test
Reference
The collector can be enabled using a flag.
–collectors.enabled “[defaults]"Metrics provided by default–collector.enabled {name},{name},{name}…: Used to enable specific metrics.
Below is a description of the main collector.
| Collector | Explanation | Label |
|---|---|---|
| memory | Provide memory statistics | |
| logical_disk | Collect performance and health metrics of logical disks (e.g., C:, D: drives) on the local system. |
|
Table. Description of major Windows Exporter collectors
- Windows Exporter 지표 you can find the main metrics provided by Windows Exporter and the method to configure the Windows Exporter Collector.
Reference
Detailed information about the collectable metrics and how to configure them can be found in Windows Exporter > Collector.
The metrics that can be provided may vary depending on the version of the Windoes Exporter you are using. * Please refer to Windows Exporter.
Caution
Since metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges unlike the default metrics, unnecessary metric collection must be removed or disabled to prevent excessive fees.
Service registration and verification Register the Windows Exporter service and verify the configured metrics.
Color mode$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --collectors.enabled memory,logical_disk,os" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exportercode block. Windows Exporter service registration Color mode# Service check $ Get-Service windows_exporter # Check metrics $ Invoke-WebRequest -Uri "http://localhost:9182/metrics" | Select-String memory# Service check $ Get-Service windows_exporter # Check metrics $ Invoke-WebRequest -Uri "http://localhost:9182/metrics" | Select-String memoryCode block. Check Windows Exporter service Configuration file settings
- You can set it to use a YAML configuration file by using the
–config.fileoption.Color mode$ .\windows_exporter.exe --config.file=config.yml $ .\windows_exporter.exe --config.file="C:\Program Files\windows_exporter\config.yml" # If you use an absolute path, you must enclose the path in quotes.$ .\windows_exporter.exe --config.file=config.yml $ .\windows_exporter.exe --config.file="C:\Program Files\windows_exporter\config.yml" # If you use an absolute path, you must enclose the path in quotes.code block. Windows Exporter configuration file settings Color modecollectors: enabled: cpu,net,service collector: service: include: windows_exporter log: level: warncollectors: enabled: cpu,net,service collector: service: include: windows_exporter log: level: warnCode block. Example of a part of a Windows Exporter configuration file - Please refer to Windows Exporter > Official Example Configuration File.Refer to the following to register a service using a configuration file.Color mode
--- #Note this is not an exhaustive list of all configuration values collectors: enabled: cpu,logical_disk,net,os,service,system collector: service: include: windows_exporter scheduled_task: include: /Microsoft/.+ log: level: debug scrape: timeout-margin: 0.5 telemetry: path: /metrics web: listen-address: :9182--- #Note this is not an exhaustive list of all configuration values collectors: enabled: cpu,logical_disk,net,os,service,system collector: service: include: windows_exporter scheduled_task: include: /Microsoft/.+ log: level: debug scrape: timeout-margin: 0.5 telemetry: path: /metrics web: listen-address: :9182Code block. Example of a Windows Exporter configuration file Color mode$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exporter$ sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto $ Start-Service windows_exportercode block. Service registration using Windows Exporter configuration file
- You can set it to use a YAML configuration file by using the
Reference
When using a configuration file together with command-line options, the values specified in the command-line options take precedence. Consequently, command-line options override the configuration file settings.
notice
If you have completed the Node Exporter configuration, you must install the OpenTelemetry Collector provided by ServiceWatch to finish the ServiceWatch Agent setup.
For detailed information, refer to ServiceWatch > ServiceWatch Agent 사용하기.
For detailed information, refer to ServiceWatch > ServiceWatch Agent 사용하기.
#Node Exporter metrics
Below is the collector and metric information that can be viewed through Node Exporter. It can be set as a Collector, or you can enable only specific metrics.
| Category | Collector | Metric | Description |
|---|---|---|---|
| Memory | meminfo | node_memory_MemTotal_bytes | Total memory |
| Memory | meminfo | node_memory_MemAvailable_bytes | Available memory (used to determine if memory is insufficient) |
| Memory | meminfo | node_memory_MemFree_bytes | Free memory (empty memory) |
| Memory | meminfo | node_memory_Buffers_bytes | IO buffer |
| Memory | meminfo | node_memory_Cached_bytes | Page cache |
| Memory | meminfo | node_memory_SwapTotal_bytes | Total swap |
| Memory | meminfo | node_memory_SwapFree_bytes | Remaining swap |
| Filesystem | filesystem | node_filesystem_size_bytes | Total file system size |
| Filesystem | filesystem | node_filesystem_free_bytes | total free space |
| Filesystem | filesystem | node_filesystem_avail_bytes | Space actually available to the user (available space for unprivileged users) |
Table. Node Exporter key metrics
Node Exporter enables most collectors by default, but you can enable or disable only the collectors you want.
- 메모리, 파일 시스템 Collector만 사용하고 싶을 때:Color mode
./node_exporter --collector.meminfo --collector.filesystem./node_exporter --collector.meminfo --collector.filesystemcode block. Enable specific collector in Node Exporter - Default 설정은 모두 해제하고 메모리, 파일 시스템 Collector만 사용하고 싶을 때:Enable file system Collector for a specific mount pointColor mode
./node_exporter --collector.disable-defaults --collector.meminfo --collector.filesystem./node_exporter --collector.disable-defaults --collector.meminfo --collector.filesystemcode block. Enable specific collector of Node Exporter Enable the file system Collector, excluding specific mount pointsColor mode./node_exporter --collector.disable-defaults --collector.filesystem.mount-points-include="/|/data"./node_exporter --collector.disable-defaults --collector.filesystem.mount-points-include="/|/data"code block. Enable specific collector in Node Exporter Color mode./node_exporter --collector.disable-defaults --collector.filesystem.mount-points-exclude="/boot|/var/log"./node_exporter --collector.disable-defaults --collector.filesystem.mount-points-exclude="/boot|/var/log"code block. Enable specific collector in Node Exporter
파일 시스템 collector를 사용하고 싶지 않을때:
Color mode
./node_exporter --no-collector.filesystem./node_exporter --no-collector.filesystemColor mode
[Unit]
Description=Node Exporter
After=network-online.target
[Service]
User=nodeexp
ExecStart=/usr/local/bin/node_exporter
--collector.disable-defaults
--collector.meminfo
--collector.filesystem
[Install]
WantedBy=multi-user.target[Unit]
Description=Node Exporter
After=network-online.target
[Service]
User=nodeexp
ExecStart=/usr/local/bin/node_exporter
--collector.disable-defaults
--collector.meminfo
--collector.filesystem
[Install]
WantedBy=multi-user.targetYou can configure the Open Telemetry Collector to select and collect only the necessary metrics gathered from the Node Exporter. When you want to collect only specific metrics among those provided by a particular collector of Node Exporter, ServiceWatch를 위한 Open Telemetry Collector 사전 설정
Caution
Collecting metrics through the ServiceWatch Agent is classified as custom metrics, and unlike the default metrics collected from each service, it incurs charges; therefore, we recommend configuring only the metrics that are essential.
#Windows Exporter metrics
Below is the collector and metric information that can be viewed through the Windows Exporter. You can configure it as a Collector, or enable only specific metrics.
| Category | Collector | Indicator name | Explanation |
|---|---|---|---|
| Memory | memory | windows_memory_available_bytes | Available memory |
| Memory | memory | windows_memory_cache_bytes | Cache memory |
| Memory | memory | windows_memory_committed_bytes | Committed memory |
| Memory | memory | windows_memory_commit_limit | Commit limit |
| Memory | memory | windows_memory_pool_paged_bytes | paged pool |
| Memory | memory | windows_memory_pool_nonpaged_bytes | non-paged pool |
| Disk information | logical_disk | windows_logical_disk_free_bytes | Remaining capacity |
| Disk information | logical_disk | windows_logical_disk_size_bytes | Total capacity |
| Disk information | logical_disk | windows_logical_disk_read_bytes_total | Number of bytes read |
| Disk information | logical_disk | windows_logical_disk_write_bytes_total | Write byte count |
| Disk information | logical_disk | windows_logical_disk_read_seconds_total | read latency |
| Disk information | logical_disk | windows_logical_disk_write_seconds_total | write latency |
| Disk information | logical_disk | windows_logical_disk_idle_seconds_total | idle time |
Table. Windows Exporter Key Metrics
Windows Exporter enables most collectors by default, but you can configure only the collectors you want.
CPU, 메모리, 논리 디스크만 사용하고 싶을 때:
Color mode
#--collector.enabled option disables the default and activates only the specified Collector
.\windows_exporter.exe --collectors.enabled="memory,logical_disk"#--collector.enabled option disables the default and activates only the specified Collector
.\windows_exporter.exe --collectors.enabled="memory,logical_disk"Reference
Even without disabling unused collectors, using
–collector.enabled will collect only the collectors specified in that option.Color mode
#Register windows_exporter as a service
sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto
#Service start
Start-Service windows_exporter#Register windows_exporter as a service
sc.exe create windows_exporter binPath= "C:\Temp\windows_exporter-0.31.3-amd64.exe --config.file=C:\Temp\config.yml" DisplayName= "Prometheus Windows Exporter" start= auto
#Service start
Start-Service windows_exporterColor mode
#Note this is not an exhaustive list of all configuration values
collectors:
enabled: logical_disk,memory
collector:
service:
include: windows_exporter
scheduled_task:
include: /Microsoft/.+
log:
level: debug
scrape:
timeout-margin: 0.5
telemetry:
path: /metrics
web:
listen-address: ":9182"#Note this is not an exhaustive list of all configuration values
collectors:
enabled: logical_disk,memory
collector:
service:
include: windows_exporter
scheduled_task:
include: /Microsoft/.+
log:
level: debug
scrape:
timeout-margin: 0.5
telemetry:
path: /metrics
web:
listen-address: ":9182"Through the Open Telemetry Collector configuration, you can set it to collect only the required metrics gathered from the Windows Exporter. When you want to collect only specific metrics among those provided by a particular collector of the Windows Exporter, [ServiceWatch를 위한 Open Telemetry Collector 사전 설정](/userguide/management/service_watch/how_to_guides/service_watch_agent/
Caution
Metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges, unlike the default metrics collected from each service; therefore, we recommend configuring only the metrics that are essential.
1.3 - API Reference
API Reference
1.4 - CLI Reference
CLI Reference
1.5 - Release Note
Virtual Server
2026.07.16
FEATURE
Add server type and other feature changes- Even if the Backup service is connected, you can delete the server.
- When a server is deleted, the schedule of the associated backup is removed, but the backup itself remains intact and can be restored and utilized.
- s3 and h3 server types have been added.
- Samsung Cloud Platform Sovereign will be offered after November 2026.
2026.05.21
CHANGED
Shared Image generation size limit and AIOS integration suspension- Creating a shared Image is limited based on the OS disk size.
- If the OS disk size is 500 GB or larger, you cannot create a shared Image.
- The AIOS service integration has been stopped.
- Since the AIOS service has been discontinued, the AIOS integrated service (LLM Endpoint) has been removed from Virtual Server.
2026.03.19
FEATURE
Add standard image, add SSD_Provisioned disk type, and add ServiceWatch metric monitoring capability- Additional OS Image provision
- Standard Image has been added. * (Window server 2016)
- An SSD volume with configurable IOPS and Throughput has been added.
- When creating Block Storage, you can select the SSD_Provisioned disk type.
- You can set the maximum IOPS and Throughput.
- You can view the Virtual Server ServiceWatch metric monitoring graph on the detail page.
2025.12.16
FEATURE
Virtual Server feature addition- Additional OS Image provision
- Standard Image has been added. * (Alma Linux 9.6, Oracle Linux 9.6, RHEL 9.6, Rocky Linux 9.6)
- Add new Server Group policy
- Partition(Virtual Server and Block Storage distributed placement) policy has been added.
- You can install the Virtual Server ServiceWatch Agent to collect custom metrics and logs.
2025.10.23
FEATURE
Add server name change feature and provide ServiceWatch service integration- You can change the server name on the Virtual Server detail page in the Samsung Cloud Platform Console.
- When the server name is changed, the OS hostname remains unchanged, and only the information within the Samsung Cloud Platform Console is updated.
- ServiceWatch service integration provision
- You can monitor data through the ServiceWatch service.
2025.07.01
FEATURE
Add Virtual Server feature and change Image sharing method- Add Virtual Server feature
- IP, Public NAT IP, Private NAT IP configuration feature has been added.
- An LLM Endpoint is provided for LLM usage.
- When creating a Virtual Server, you can select an OS Image subscribed from the Marketplace.
- The second-generation server type has been added.
- Add a 2nd-generation (s2) server type based on the Intel 4th-generation (Sapphire Rapids) Processor. * For detailed information, see Virtual Server 서버 타입.
- The method for sharing images between accounts has changed.
- qcow2 Image or shared Image can be newly created and shared.
2025.02.27
FEATURE
NAT configuration feature and addition of OS Image, server type- Add Virtual Server feature
- The NAT configuration feature has been added to Virtual Server.
- Additional OS Image provision
- Standard Image has been added. * (Alma Linux 8.10, Alma Linux 9.4, Oracle Linux 8.10, Oracle Linux 9.4, RHEL 8.10, RHEL 9.4, Rocky Linux 8.10, Rocky Linux 9.4, Ubuntu 24.04)
- An image for Kubernetes has been added. * You can create a Kubernetes Engine using an image for Kubernetes.
- Add second-generation server type
- Add 2nd-generation (h2) server type based on Intel 4th-generation (Sapphire Rapids) Processor. * For detailed information, see Virtual Server 서버 타입.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, and Service Home, tags, etc., have been updated to reflect common CX changes.
2024.10.01
NEW
Virtual Server service official version release- Virtual Server service has been officially launched.
- We have launched a virtualized server that can be freely allocated and used as needed at the required time without having to purchase infrastructure resources individually.
2024.07.02
NEW
Beta version release- We have launched a virtualized server that can be freely allocated and used as needed at the required time without having to purchase infrastructure resources individually.
2025.10.23
FEATURE
Add server name change feature and provide ServiceWatch service integration- You can change the server name on the Virtual Server detail page in the Samsung Cloud Platform Console.
- When the server name is changed, the OS hostname remains unchanged, and only the information within the Samsung Cloud Platform Console is updated.
- ServiceWatch service integration provision
- You can monitor data through the ServiceWatch service.
2025.07.01
FEATURE
Add Virtual Server feature and change Image sharing method- Add Virtual Server feature
- IP, Public NAT IP, Private NAT IP configuration feature has been added.
- An LLM Endpoint is provided for LLM usage.
- When creating a Virtual Server, you can select an OS Image subscribed from the Marketplace.
- The second-generation server type has been added.
- Add a 2nd‑generation (s2) server type based on the Intel 4th‑generation (Sapphire Rapids) Processor. * For detailed information, see Virtual Server 서버 타입.
- The method for sharing images between accounts has changed.
- qcow2 Image or shared Image can be newly created and shared.
2025.02.27
FEATURE
NAT configuration feature and addition of OS Image, server type- Add Virtual Server feature
- The NAT configuration feature has been added to Virtual Server.
- Additional OS Image provision
- Standard Image has been added. * (Alma Linux 8.10, Alma Linux 9.4, Oracle Linux 8.10, Oracle Linux 9.4, RHEL 8.10, RHEL 9.4, Rocky Linux 8.10, Rocky Linux 9.4, Ubuntu 24.04)
- An image for Kubernetes has been added. * You can create a Kubernetes Engine using an image for Kubernetes.
- Add second-generation server type
- Add 2nd-generation (h2) server type based on Intel 4th-generation (Sapphire Rapids) Processor. * For detailed information, see Virtual Server 서버 타입.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, and Service Home, tags, etc., have been updated to reflect common CX changes.
2024.10.01
NEW
Virtual Server service official version release- Virtual Server service has been officially launched.
- We have launched a virtualized server that can be freely allocated and used as needed at the required time without having to purchase infrastructure resources individually.
2024.07.02
NEW
Beta version release- We have launched a virtualized server that can be freely allocated and used as needed at the required time without having to purchase infrastructure resources individually.
2 - Virtual Server Auto-Scaling
2.1 - Overview
Service Overview
Virtual Server Auto-Scaling is a service that automatically scales resources up or down based on demand. You can add or terminate servers running the application according to predefined conditions or schedules.
An Auto-Scaling Group uses a pre-created Launch Configuration as a configuration template to launch servers, and can adjust and manage the number of servers. It adjusts to ensure the number of servers does not fall below the specified minimum or exceed the specified maximum.
If you register a schedule with an Auto-Scaling Group, you can set the number of servers according to the specified schedule. If you register a policy, you can increase or decrease the number of servers based on predefined conditions.
Features
Easy and convenient computing environment setup: Through a web-based Console, users can easily configure the required computing environment themselves via Self Service, from creating Launch Configurations to creating/modifying/deleting Auto-Scaling Groups.
Elastic Resource Usage: Computing resources can be used elastically according to the service load and usage. Users can schedule resource usage for predictable specific time periods, and can adjust resource consumption to accommodate temporary access by an unspecified large number of users.
Availability Improvement: Virtual Server Auto-Scaling provides a function that adjusts resources to match variable demand so that the traffic required by the user can always be handled. Through this, users can achieve improved application performance and availability.
Maximize Cost Savings: You can reduce unnecessary expenses by using resources only as needed according to demand fluctuations. By flexibly allocating resources in response to traffic increases or decreases during specific periods such as nights, weekends, and month-ends, you can maximize cost-saving effects.
Service Architecture Diagram
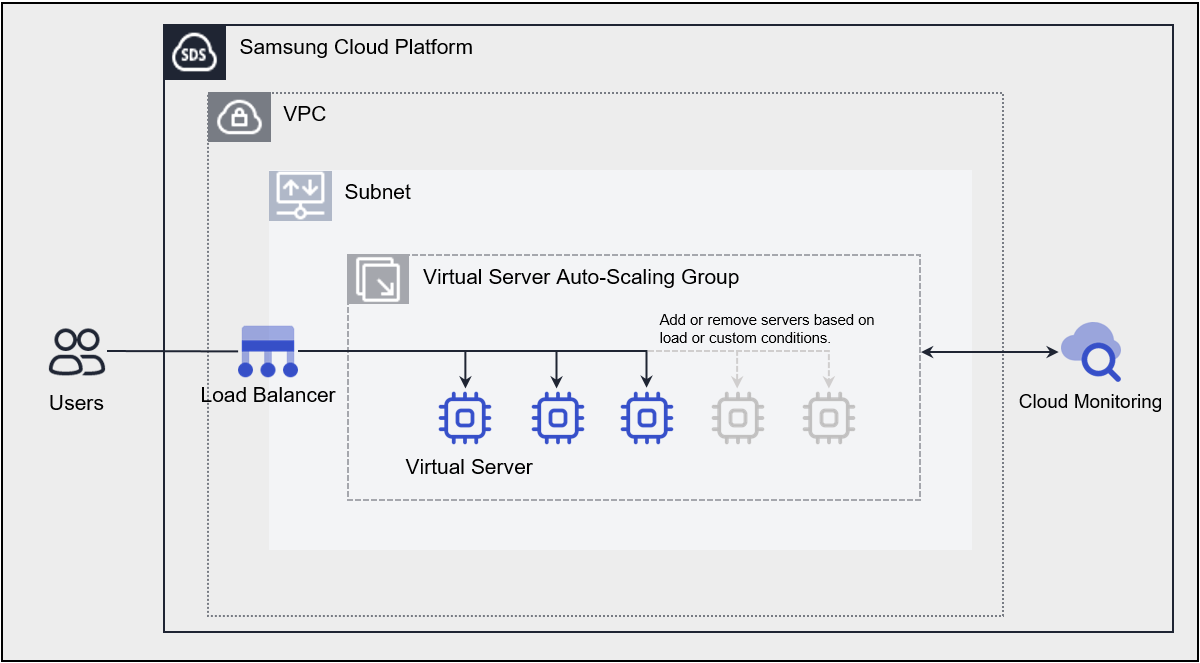
Provided features
Virtual Server Auto-Scaling provides the following features.
- Launch Configuration: It is a configuration template used to create a Virtual Server in an Auto-Scaling Group. When creating a Launch Configuration, you set information about the Virtual Server such as the image, server type, Key Pair, Block Storage, etc.
- Server Count Adjustment: Provides several ways to adjust the number of servers. By using policies, you can add a Virtual Server when load exceeds a threshold and release the Virtual Server when demand is low, maintaining application availability while reducing costs. You can also add and release Virtual Servers according to a predefined schedule, and manually adjust the number of servers in an Auto-Scaling Group as needed.
- Load Balancer Integration: You can use a Load Balancer to evenly distribute application traffic across Virtual Servers. Whenever a Virtual Server is added or removed, it is automatically registered with or deregistered from the Load Balancer.
- Network Connection: You can connect the Auto-Scaling Group’s standard subnet, automatic IP allocation, and Public NAT IP. Provides a local subnet connection for inter-server communication.
- Security Group Application: Security Group is a virtual logical firewall that controls inbound/outbound traffic generated on a Virtual Server. Inbound rules control incoming traffic to the Virtual Server, and outbound rules control outgoing traffic from the Virtual Server.
- Monitoring: You can view monitoring data such as CPU, Memory, and Disk of Virtual Servers created in an Auto-Scaling Group via the ServiceWatch service. Based on the monitoring data, you can set load thresholds using Auto-Scaling policies, and when thresholds are exceeded, you can add or remove servers.
Reference
The policy of the Auto-Scaling Group will be integrated with ServiceWatch starting March 25, 2026.
The policies of an Auto-Scaling Group are created in conjunction with ServiceWatch alarm policies, and alarm policies linked to an Auto-Scaling Group cannot be modified or deleted in ServiceWatch; they can only be managed through the Auto-Scaling Group.
Component
Virtual Server Auto-Scaling creates an Auto-Scaling Group through a Launch Configuration and monitors and manages the servers.
Launch Configuration
This is a Configuration template used to create a Virtual Server in an Auto-Scaling Group. The main features are as follows.
- Image: Provides OS standard images and Custom images created by the user. Users can select and use them according to the service they wish to configure.
- Keypair: Provides the Keypair method for secure OS access.
- Init script: Users can define a script to be executed when the Virtual Server starts.
- For more details, refer to Launch Configuration Create.
Reference
In Launch Configuration, please refer to the Virtual Server OS Image Provisioning Versions and Virtual Server Server Types for the selectable images and server types.
Auto-Scaling Group
Launch Configuration is used as a pre-configuration template for creating servers. By creating an Auto-Scaling Group, you can adjust and manage the number of servers. The main features are as follows.
- Launch Configuration: A Configuration template used to create a Virtual Server in an Auto-Scaling Group.
- Server Count Setting: Virtual Server Auto-Scaling provides several ways to adjust the number of servers in an Auto-Scaling Group.
- Fixed Server Count Method: When creating an Auto-Scaling Group, this method keeps the default settings using the configured number of servers without any additional schedules or policies. Refer to Create Auto-Scaling Group to set the Min, Desired, and Max server counts.
- Server Count Manual Adjustment Method: In an Auto-Scaling Group, you can increase or decrease the number of servers by modifying the server count to the desired amount. You can choose whether to manually set the desired server count. Please refer to 서버 수 수정하기.
- Schedule reservation method: You can schedule daily, weekly, monthly, or one-time, and set the desired number of servers at the specified time. This is useful when you can predict when to scale the number of servers up or down. If you use the schedule method, please refer to Manage Schedules to add and manage schedules.
- Policy Mode: You can use a policy to dynamically adjust servers. When a monitoring metric exceeds a configured threshold, the number of servers is adjusted. At this time, you can choose one of three methods to adjust the server count: increase or decrease by a specified number, increase or decrease by a specified percentage, or fix the server count to a given value. When servers are started or terminated due to a policy, the monitoring metric (CPU utilization) may temporarily exceed the threshold registered in the policy. However, because this is a brief moment, a cooldown period is set to avoid treating it as an abnormal situation. If you want to use the policy mode, see Managing Policies.
- Load Balancer: Automatically connects and disconnects to the Load Balancer registered in the Auto-Scaling Group whenever a Virtual Server is added or terminated.
- Refer to Auto-Scaling Group Detailed Information for detailed information about the Load Balancer of an Auto-Scaling Group.
Reference
The Load Balancer of the Auo-Scaling Group will operate in conjunction with the Load Balancer starting in February 2025.
Constraints
The constraints of Virtual Server Auto-Scaling are as follows.
| Category | Explanation |
|---|---|
| Number of Virtual Servers per Auto-Scaling Group | 50 or fewer |
| Number of policies per Auto-Scaling Group | 12 or fewer |
| Number of schedules per Auto-Scaling Group | 20 or fewer |
| Number of LB server groups and ports per Auto-Scaling Group | 3 or fewer |
Table. Virtual Server Auto-Scaling Group Constraints
Caution
- If the Image you are using is a discontinued standard Image, Scale-out will not work.
If the Image you are using is Custom Image, Scale out will continue to operate correctly even after that version is discontinued. - We recommend replacing the Launch Configuration with the latest version of the Image or a Custom Image before the current Image reaches end of support.
- For detailed information about the OS Image provided by Virtual Server, see OS Image Provided Versions.
Prior Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
| Networking | Security Group | Virtual firewall that controls server traffic |
Table. Virtual Server Auto-Scaling Prerequisite Service
2.1.1 - Monitoring Metrics
information
The Auto-Scaling Group policy will be linked with the ServiceWatch alarm policy starting March 25, 2026. Please refer to Virtual Server Auto-Scaling > ServiceWatch Metrics.
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Accordingly, after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With the new alternative service, you can continuously perform resource monitoring by using ServiceWatch, released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a smooth monitoring environment.
Detailed information about ServiceWatch is available in the ServiceWatch Overview.
Virtual Server Auto-Scaling is a service provided for Virtual Servers that offers individual Virtual Server monitoring metrics and monitoring metrics provided by policies based on Cloud Monitoring.
Virtual Server Monitoring Metrics
The table below shows the monitoring metrics of Virtual Server that can be viewed through Cloud Monitoring. For detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
Memory-related metrics are not provided for Windows OS.
| Performance items | Detailed description | unit |
|---|---|---|
| Memory Total [Basic] | bytes of usable memory | bytes |
| Memory Used [Basic] | bytes of currently used memory | bytes |
| Memory Swap In [Basic] | bytes of the replaced memory | bytes |
| Memory Swap Out [Basic] | bytes of the replaced memory | bytes |
| Memory Free [Basic] | bytes of unused memory | bytes |
| Disk Read Bytes [Basic] | Read bytes | bytes |
| Disk Read Requests [Basic] | Number of read requests | cnt |
| Disk Write Bytes [Basic] | write bytes | bytes |
| Disk Write Requests [Basic] | Number of write requests | cnt |
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Instance State [Basic] | Instance status | state |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Dropped [Basic] | Incoming packet drop | cnt |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Dropped [Basic] | Transmit packet drop | cnt |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. Virtual Server Monitoring Metrics (Provided by default)
Monitoring metrics provided by Cloud Monitoring-based policies
The table below shows the monitoring metrics provided by the policy of a Cloud Monitoring‑based Auto‑Scaling Group. For detailed information on policy settings based on Cloud Monitoring, see 정책 관리하기.
| Performance items | Detailed description | unit |
|---|---|---|
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Memory Used [Basic] | bytes of currently used memory | bytes |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. Monitoring metrics provided by Cloud Monitoring-based policies
2.1.2 - ServiceWatch Metrics
Virtual Server Auto-Scaling is a service provided for Virtual Servers that offers individual Virtual Server monitoring metrics and monitoring metrics supplied by ServiceWatch-based policies.
Virtual Server Monitoring Metrics
The basic metrics provided by Virtual Server can be found in ServiceWatch > Virtual Server Basic Metrics.
Reference
For checking metrics in ServiceWatch, refer to the ServiceWatch guide.
ServiceWatch monitoring metrics provided by the Auto-Scaling Group policy
The table below shows the ServiceWatch monitoring metrics provided by the Auto-Scaling Group policy. For detailed information on configuring Auto-Scaling Group policies, see Managing Policies.
| Performance items | Detailed description | unit |
|---|---|---|
| CPU Usage | CPU usage | Percent |
| Network In Bytes | Received bytes on the network interface | Bytes |
| Network In Packets | Number of packets received on the network interface | Count |
| Network Out Bytes | Data transmitted on the network interface (bytes) | Bytes |
| Network Out Packets | Number of packets transmitted on the network interface | Count |
Table. ServiceWatch monitoring metrics provided by the Auto-Scaling Group policy
2.2 - How-to guides
Users can create the service by entering the required information for the Auto-Scaling Group and selecting detailed options through the Samsung Cloud Platform Console.
Create Auto-Scaling Group
You can create and use the Auto-Scaling Group service from the Samsung Cloud Platform Console.
Reference
To create an Auto-Scaling Group, you need to create a Launch Configuration in advance.
Refer to Launch Configuration 생성하기.
To create an Auto-Scaling Group, follow the steps below.
Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
Click the Auto-Scaling Group menu. 2. Auto-Scaling Group List Navigate to the page.
On the Auto-Scaling Group List page, click the Create Auto-Scaling Group button. 3. Auto-Scaling Group Creation Navigate to the page.
On the Auto-Scaling Group creation page, enter the information required to create the service.
- In the Launch Configuration area, select the Launch Configuration.
- Click the Launch Configuration creation button to create a new Launch Configuration.
- Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Auto-Scaling Group name Required Auto-Scaling Group name - manage servers of the same type and purpose as a group
Server name Required Server name to be created within the Auto-Scaling Group - Automatically assign a server name by combining the entered server name, which serves as an identifier to distinguish servers created within the Auto-Scaling Group, with a sequence
Number of servers Required Number of servers to create in the Auto-Scaling Group - Enter a value between 0 and 20 (Min≤Desired≤Max)
- Min: Set the minimum number of servers the Auto-Scailg Group should maintain
- Desired: Set the target number of servers within the Auto-Scailg Group; also indicates the number of servers initially created when the Auto-Scailg Group is created
- Max: Set the maximum number of servers the Auto-Scailg Group can maintain
- After creating the Auto-Scaling Group, you can adjust the settings using the Edit button. For details, see 서버 수 수정하기
Desired server count manual setting Selection Select whether to manually change the Desired server count - Even after creating the Auto-Scaling Group, set it via the Edit button. For details, see Desired 서버 수 수동 설정 수정하기
Network Settings > Network Settings Required Network settings for Auto-Scaling Group - Select the desired VPC and standard Subnet
- IP can only be auto-generated.
- When you select local Subnet, you can choose the desired local Subnet, and IP can only be auto-generated
Network Settings > Security Group Selection To allow required connections, you need to configure a Security Group - If you do not configure a Security Group, all inbound and outbound traffic will be blocked according to the default rule (Any/Deny)
- For Linux servers, allow SSH traffic
- For Windows servers, allow RDP traffic
- Even after creating an Auto-Scaling Group, configure it via the Edit button. For more details, see Security Group 설정하기
Load Balancer Selection Connect the Auto-Scaling Group to a Load Balancer - Register the Auto-Scaling Group’s servers as members of the LB server group
- LB server group: Select the LB server group that exists in the chosen VPC
- Port: Enter a value between 1 and 65,534
- Press the + button to add an LB server group (up to a total of three LB server groups and ports are allowed)
- LB server groups that use Weighted Round Robin or Weighted Least Connection load balancing cannot be selected
- Draining Timeout value: After checking Draining Timeout as Enabled, you can set the Draining Timeout value
- Draining Timeout: The waiting period before removing a server from the Load Balancer
- Since sessions may remain connected to the server, setting a Draining Timeout and waiting allows safe session cleanup
- If the Load Balancer is unused, Draining Timeout cannot be configured
- The default is 300 seconds; you can enter values from a minimum of 1 second up to a maximum of 3,600 seconds.
- Draining Timeout: The waiting period before removing a server from the Load Balancer
- Changes can be made after creating the Auto-Scaling Group; for details, refer to Auto-Scaling Group Load Balancer 사용하기.
Table. Auto-Scaling Group service information entry items - In the Scaling policy configuration area, set the Scaling policy.
- For detailed information on policy settings, see 정책 추가하기.
Category required statusDetailed description Current setting Selection Set the Scaling policy now - Add Policy button click displays policy information input fields
Set later Selection After creating an Auto-Scaling Group, set the policy on the details page Table. Auto-Scaling Group Scaling policy configuration items
- For detailed information on policy settings, see 정책 추가하기.
- In the Notification Settings area, configure the notification recipients and notification method.
- For detailed information about notification settings, refer to 알림 추가하기.
Category required statusDetailed description Current setting Selection Set the notification recipients and notification method now - Click the Add Notification button to open the Add Notification popup
- For detailed information on notification settings, refer to the details
- You can modify notification information by clicking the Edit button in the notification recipients list
Set later Selection After creating an Auto-Scaling Group, set the notification recipients and notification method on the details page. Table. Auto-Scaling Group notification configuration items
- For detailed information about notification settings, refer to 알림 추가하기.
- In the Additional Information Input area, enter or select the required information.
Category required statusDetailed description Status check Selection Check the status of Virtual Server and Load Balancer and replace servers that are in an Unhealthy state - Virtual Server status check: Enabled is the default and cannot be changed
- Load Balancer status check: Enabled only when a Load Balancer is connected in the service information input area
- Grace period: Set the time to defer status checks until the newly added server operates normally
- Enter 0 to disable the status check grace period
tag Selection Add Tag - Up to 50 per resource can be added
- Add Tag button after clicking, enter or select Key, Value values
Table. Auto-Scaling Group additional information input fieldsCautionA server that the user changes to Stop is not considered Unhealthy, so even when using the health check feature, the server will not be replaced.
- In the Launch Configuration area, select the Launch Configuration.
Summary Check the detailed information and estimated billing amount generated in the panel, and click the Create button.
- When creation is complete, verify the created Auto-Scaling Group on the Auto-Scaling Group list page.
Auto-Scaling Group Check detailed information
The Auto-Scaling Group service allows you to view and edit the full resource list and detailed information. Auto-Scaling Group Details page is organized into Detailed Information, Policies, Schedule, Virtual Server, Load Balancer, Tags, Operation History tabs.
To view detailed information about the Auto-Scaling Group, follow these steps.
- All Services > Compute > Virtual Server menu, click. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Navigate to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to view detailed information. 3. Go to the Auto-Scaling Group Details page.
- Auto-Scaling Group Details The page displays status information and additional feature information, and Details, Policies, Schedule, Virtual Server, Load Balancer, Tags, Operation History are organized as tabs.
Category Detailed description Auto-Scaling Group status Status of the Auto-Scaling Group created by the user - Creating: Creating Auto-Scaling Group
- In Service: In Service
- Scale In: Scale In in progress
- Scale Out: Scale Out in progress
- Cool Down: Cooling down
- Terminating: Terminating Auto-Scaling Group
- Attach to LB: Attaching to Load Balancer
- Detach from LB: Detaching from Load Balancer
Delete Auto-Scaling Group Button to delete Auto-Scaling Group Table. Auto-Scaling Group status information and additional features
- Auto-Scaling Group Details The page displays status information and additional feature information, and Details, Policies, Schedule, Virtual Server, Load Balancer, Tags, Operation History are organized as tabs.
Detailed Information
Auto-Scaling Group list page allows you to view detailed information of the selected resource and, if needed, modify the information.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Auto-Scaling Group name | Auto-Scaling Group name |
| Launch Configuration name | When creating an Auto-Scaling Group, the selected Launch Configuration name
|
| Number of servers | Current number of servers created in the Auto-Scaling Group and the configured Min, Desired, Max server counts
|
| Desired server count manual setting | Desired server count manual setting enable/disable
|
| VPC | Auto-Scaling Group VPC information |
| Standard Subnet | General Subnet and NAT IP usage information for Auto-Scaling Group |
| Local Subnet | Local Subnet of Auto-Scaling Group |
| Security Group | Auto-Scaling Group’s Security Group
|
| Status check | Whether to use the replacement function for Virtual Server and Load Balancer in an Unhealthy state
|
Table. Auto-Scaling Group Details – Details Tab Items
Caution
A server that the user changes to Stop is not considered Unhealthy, so even when using the health check feature, the server will not be replaced.
Policy
On the Auto-Scaling Group List page, you can view the list of policies for the selected resource and, if needed, add or manage policies.
| Category | Detailed description |
|---|---|
| Category | Policy Type
|
| Policy Name | Name for policy classification |
| Execution conditions | Conditions to trigger the policy
|
| execution unit | Policy execution method
|
| Cooldown | The waiting time (seconds) when a server is started or terminated due to a policy
|
| More > Edit | Modify the policy information
|
| More > Activate | Enable this policy
|
| More > Disable | Disable this policy
|
Table. Auto-Scaling Group Details - Policy Tab Items
Reference
For policy management and policy example explanations, please refer to 정책 관리하기.
Schedule
Auto-Scaling Group List page allows you to view the schedule list of the selected resources and, if necessary, add or manage schedules.
| Category | Detailed description |
|---|---|
| name | Schedule name |
| Min | Minimum number of servers set in the schedule |
| Desired | Number of target servers set in the schedule |
| Max | Maximum number of servers set in the schedule |
| Period | Schedule execution frequency
|
| Date/Day | Schedule execution date or day of week
|
| Execution time | Schedule execution time |
| Time zone | Schedule execution time window |
| status | Schedule status |
| More > Edit | Edit the schedule information |
| More > Activate | Activate this schedule
|
| More > Disable | Disable this schedule
|
| Add schedule | Add a new schedule |
| Delete | Delete the selected schedule from the list |
Table. Auto-Scaling Group Details - Schedule Tab Items
Reference
For detailed information on schedule management, refer to 스케줄 관리하기.
Virtual Server
On the Auto-Scaling Group List page, you can view the Virtual Server list of the selected resource.
| Category | Detailed description |
|---|---|
| Server name | Server name created in the Auto-Scaling Group
|
| IP | IP assigned to the server |
| Creation date and time | The date and time the server was created |
| status | Result of status check for Virtual Server and Load Balancer
|
Table. Auto-Scaling Group Details - Virtual Server Tab Items
Load Balancer
Auto-Scaling Group List page allows you to view the Load Balancer list of the selected resources, and, if necessary, you can add or manage Load Balancers.
| Category | Detailed description |
|---|---|
| Draining Timeout | Whether to use Draining Timeout
|
| Load Balancer | Load Balancer usage
|
| Load Balancer > Load Balancer name | Load Balancer name to attach to the Auto-Scaling Group |
| Load Balancer > LB server group | Load Balancer’s LB server group
|
| Load Balancer > Port | Port registered as a Member in the LB server group |
Table. Auto-Scaling Group Details – Load Balancer Tab Items
Reference
- The LB server group member information set in the Auto-Scaling Group can also be checked in LB 서버 그룹 연결된 자원.
- Also, if manual connection/disconnection between the server and Load Balancer is required, please refer to LB 서버 그룹 Member 추기하기.
Notification
On the Auto-Scaling Group List page, you can view the notification recipients and notification methods for the selected resource.
| Category | Detailed description |
|---|---|
| Notification recipient | Name of the notification recipient |
| Notification recipient’s email | |
| Create Server | Whether to send a notification when a server creation-related alert occurs
|
| Server termination | Whether to send a notification when a server termination-related alert occurs
|
| When the policy execution condition is met | Whether a notification is triggered when the policy execution conditions are met |
| status | Notification activation status
|
| More > Edit | Edit the notification information |
| More > Activate | Enable this notification information
|
| More > Disable | Disable the notification information
|
| Add notification | Add a new notification |
| Delete | Delete the selected notification from the list |
Table. Auto-Scaling Group Details - Notification Tab Items
Reference
For detailed information about notification settings, refer to 알림 관리하기.
Tag
On the Auto-Scaling Group List page, you can view the tag information of the selected resource, and you can add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Auto-Scaling Group Details - Tag Tab Items
Operation History
Auto-Scaling Group List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Auto-Scaling Group Details - Task History Tab Items
Auto-Scaling Group Managing Resources
If you need management functions for the created Auto-Scaling Group, you can perform tasks on the Auto-Scaling Group Details page.
Edit Launch Configuration
You can modify the Launch Configuration of an Auto-Scaling Group.
참고
Even if you modify the Launch Configuration, it does not apply to servers already created in the Auto-Scaling Group; it only takes effect for servers created thereafter. If you want to apply the updated Launch Configuation to all servers in the Auto-Scaling Group, set the server count (Desired) to 0 to delete all existing servers, then change the server count (Desired) to the desired amount.
To modify the Launch Configuration of an Auto-Scaling Group, follow these steps.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
On the Auto-Scaling Group List page, click the resource to edit the Launch Configuration. 3. Auto-Scaling Group Details Navigate to the page.
Click the Edit button for the Launch Configuration name. 4. Launch Configuration Edit The popup window opens. 4. You can view the list of selectable Launch Configurations.
CategoryDetailed description Launch Configuration name Launch Configuration name Image Launch Configuration OS Image Server type Launch Configuration server type Block Storage Launch Configuration Block Storage Settings Auto-Scaling Group count Number of Auto-Scaling Groups with a Launch Configuration applied View Details Button to view Launch Configuration details Table. Launch Configuration list itemsLaunch Configuration Edit In the popup window, select the Launch Configuration to change, then click the Confirm button. 5. Launch Configuration Modification Notification A popup window opens. 5. Launch Configuration Modification Notification Check the message in the popup window and click the Confirm button.
Modify server count
You can modify the number of servers in the Auto-Scaling Group.
Reference
The maximum number of servers that can be configured is 20. However, when a Load Balancer is present, exclude servers that are not connected to the Load Balancer.
To modify the number of servers in an Auto-Scaling Group, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Navigate to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource to modify the server count. 3. Go to the Auto-Scaling Group Details page.
- Click the Edit server count button. 4. Edit Server Count popup window opens.
- Edit Server Count After entering the required fields in the popup window, click the Confirm button.
Category required statusDetailed description Number of servers > Min Required Minimum number of servers to modify - Set the number of servers that the Auto-Scaling Group maintains at a minimum
Number of servers > Desired Required Number of target servers to modify - Set the number of target servers within the Auto-Scaling Group
- Desired server count manual setting is disabled, you cannot modify the Desired server count. To modify the Desired server count, refer to Desired server count manual setting modification
Number of servers > Max Required Target number of servers to modify - Set the number of servers that the Auto-Scailg Group can maintain at maximum
Table. Auto-Scailg Group server count modification items
Terminate Virtual Server Created by Auto-Scaling Group
Virtual Server created in the Auto-Scaling Group can be terminated by clicking the Terminate button on its detail page or by modifying the server count.
Caution
- Please note that data cannot be recovered after terminating the service.
- To cancel the service, first disconnect the File Storage and disable the Lock. * If the File Storage is connected or a lock is set, the Virtual Server cannot be terminated.
Reference
- If you terminate a Virtual Server created in the Auto-Scaling Group, the associated Load Balancer is automatically detached.
- When a Virtual Server is terminated, the status of the attached Storage is as follows.
- If Delete on termination is not set: the volume will not be deleted even if the Virtual Server is terminated.
- When Delete on termination is set: If you terminate the Virtual Server, the volume will be deleted. * However, if a Snapshot exists, it will not be deleted even if Delete on termination is set.
- Multi-attach volume: It can only be deleted when the server you are trying to delete is the last remaining server attached to the volume.
Cancel on the Virtual Server detail page
To cancel a Virtual Server on the Virtual Server detail page, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Virtual Server menu. 2. Go to the Virtual Server List page.
- On the Virtual Server List page, select the Virtual Server created by the Auto-Scaling Group. 3. Navigate to the Virtual Server Details page.
- On the Virtual Server Details page, click the Service Cancellation button. 4. A popup window announcing the server termination opens.
- Confirm Click the button. 5. Server termination is complete.
Terminate by adjusting the server count
To terminate a Virtual Server by adjusting the server count, follow the steps below.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to terminate the Virtual Server. 3. Auto-Scaling Group Details page.
- Click the Edit button for the Server Count item. 4. Edit Server Count popup window opens.
- Server Count Modification In the popup window, after reducing the Desired count, click the Confirm button. 5. When the desired number of servers is adjusted, the Virtual Server is terminated.
Notice
- Desired server count manual setting is unused, you cannot modify the Desired server count. * To modify the Desired server count, refer to Desired 서버 수 수동 설정 수정하기.
- When a Virtual Server is terminated, the Desired server count remains unchanged, and scale-out proceeds according to the Desired check batch.
Manually modify the desired number of servers
You can manually change the Desired server count setting of the Auto-Scaling Group.
Reference
If you do not select Use for manual Desired server count setting, you cannot modify the Desired server count in the details’ server count edit. The desired number of servers is automatically adjusted by checking the Virtual Server status every 10 minutes.
To modify the manual setting of the Desired server count for an Auto-Scaling Group, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Navigate to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to manually change the Desired server count. 3. Auto-Scaling Group Details Navigate to the page.
- Click the Edit server count button. 4. Desired server count manual setting The popup window opens.
- Desired server count manual setting After selecting whether to use it in the popup window, click the Confirm button.
Setting up Security Group
You can configure the Security Group of an Auto-Scaling Group.
Reference
Even if you modify the Security Group, it does not apply to servers already created in the Auto-Scaling Group; it only applies to servers created thereafter. If you want to apply the updated Security Group to all servers in the Auto-Scaling Group, set the server count (Desired) to 0 to delete all existing servers, then adjust the server count (Desired) to the desired quantity again.
Follow these steps to configure the Security Group of an Auto-Scaling Group.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
Auto-Scaling Group List page, click the resource to configure the Security Group. 3. Go to the Auto-Scaling Group Details page.
Click the Edit button for Security Group. 4. Security Group Edit The popup window opens. 4. You can view the list of selectable Security Groups.
Category Detailed description Security Group name Security Group name Table. Security Group list itemsSecurity Group Edit In the popup window, after selecting the Security Group, click the Confirm button. 5. Security Group Modification Notification A popup window opens. 5. Security Group Modification Alert Check the message in the popup window and click the Confirm button.
Change status check
You can configure it to automatically replace servers that are in an Unhealthy state by checking the status of Virtual Server and Load Balancer.
Caution
- The Load Balancer status check feature can be used only when a Load Balancer is in use.
- A server that the user changes to Stop is not considered Unhealthy, so even when using the health check feature, the server will not be replaced.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource to modify the Load Balancer health check feature. 3. Navigate to the Auto-Scaling Group Details page.
- Click the Edit button of Status Check. 4. Edit Status Check The popup window opens.
- Status Check Edit In the popup, choose whether to enable Load Balancer Status Check.
- After entering the Grace period, click the Confirm button.
- If you do not want to use the grace period, set the grace period to 0.
Auto-Scaling Group Manage Additional Information
You can set the Auto-Scaling Group’s Load Balancer to enabled and select the LB server group. For an Auto-Scaling Group that uses a Load Balancer, you can set it to unused.
Load Balancer Draining Timeout Edit
You can set the Load Balancer Draining Timeout of an Auto-Scaling Group.
Reference
Draining Timeout is the time to wait before removing a server from the Load Balancer.
- Because sessions may remain connected to the server, setting a Draining Timeout and waiting can clean up sessions more safely.
- If the Load Balancer is unused, the Draining Timeout cannot be set.
- The default is 300 seconds, and it can be set from a minimum of 1 second up to a maximum of 3,600 seconds.
To set the Load Balancer Draining Timeout for an Auto-Scaling Group, follow these steps.
- All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to configure the Load Balancer Draining Timeout. 3. Auto-Scaling Group Details Navigate to the page.
- Load Balancer Click the tab. 4. Load Balancer Navigate to the list page.
- Click the Edit button of Draining Timeout. 5. Draining Timeout Edit A popup window opens.
- Edit Draining Timeout In the popup window, select whether to use Draining Timeout, and enter the Draining Timeout duration (seconds).
- Draining Timeout Edit After checking the input value in the popup window, click the Confirm button. 7. Draining Timeout Modification Notification A popup window opens. 7. Check the message in the notification popup and click the Confirm button.
Using Load Balancer
You can modify the Load Balancer of an Auto-Scaling Group. To configure the Load Balancer of an Auto-Scaling Group, follow these steps.
Reference
- When a server in the Auto-Scaling Group is created, it is automatically added as a member of the selected Load Balancer’s LB server group, and when the server is terminated, it is removed from the LB server group’s members.
- If Draining Timeout is in use, after waiting for the Draining Timeout (seconds), the server is removed from the LB server group’s members.
- In the case of Member separation due to Load Balancer modification, it waits in Detach from LB state, and in the case of Member separation due to Scale In, it waits in Scale In state.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Navigate to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to use with Load Balancer. 3. Go to the Auto-Scaling Group Details page.
- Load Balancer Click the tab. 3. Load Balancer Navigate to the list page.
- Click the Edit button of the Load Balancer. 4. Load Balancer Edit The popup window opens.
- Edit Load Balancer Please select whether to use it in the popup window. 5. If you select Use, you can select a Load Balancer.
Category Detailed description LB server group LB server group name - Select the LB server group that is created in the selected VPC
- LB server groups that use Weighted Round Robin or Weighted Least Connection load balancing cannot be selected
Port Port information of the LB server group - When registering as a member of the LB server group, enter the required port information in the registration details.
- Enter a value between 1 and 65,534
Table. Load Balancer list items- Click the + button to add an LB server group. * A maximum of three is allowed. * You can remove the Load Balancer you added by clicking the X button.
- Check the Load Balancer list and click the Confirm button. 6. Load Balancer Modification Notification A popup window opens. 6. Check the message in the notification popup and click the Confirm button.
Caution
- Please be aware that separating or connecting servers from the Load Balancer may impact the service.
- If the Draining Timeout is in use, setting the Load Balancer to unused or removing some of the connected Load Balancers with the X button will not disconnect them immediately. * After waiting for the Draining Timeout (seconds), the server is detached from the Load Balancer. * At this point, the Auto-Scaling Group waits in the Detach from LB state.
Reference
- The LB server group member information set in the Auto-Scaling Group can also be checked in LB 서버 그룹 연결된 자원.
- If manual connection/disconnection between the server and Load Balancer is required, refer to LB 서버 그룹 Member 등록하기.
Load Balancer Not Used
You can modify the Auto-Scaling Group’s Load Balancer to be disabled. To configure an Auto-Scaling Group without using a Load Balancer, follow these steps.
Caution
- Please be aware that separating or connecting servers from the Load Balancer may impact the service.
- If the Draining Timeout is in use, setting the Load Balancer to not used or removing some of the connected Load Balancers with the X button will not detach them immediately. * After waiting for Draining Timeout(seconds), the server is detached from the Load Balancer. * At this point, the Auto-Scaling Group waits in the Detach from LB state.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Auto-Scaling Group List Navigate to the page.
- On the Auto-Scaling Group List page, click the resource to set the Load Balancer to unused. 3. Auto-Scaling Group Details page.
- Load Balancer Click the tab. 4. Load Balancer Navigate to the list page.
- Click the Edit button of Load Balancer. 5. Load Balancer Edit The popup window opens.
- Edit Load Balancer Select whether to use it in the popup window. 6. If you deselect 사용, you will no longer use the Load Balancer.
- Uncheck the Use option and click the Confirm button. 7. Load Balancer Modification Notification A popup window opens. 7. Check the notification popup message and click the Confirm button.
Delete Auto-Scaling Group
Deleting unused Auto-Scaling Groups can reduce operating costs. However, if you terminate the Auto-Scaling Group, the running service may be stopped immediately, so you should proceed with the termination only after fully considering the impact of service interruption.
Caution
Please be aware that data cannot be recovered after deleting the service.
To terminate the Auto-Scaling Group, follow these steps.
- All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Auto-Scaling Group menu. 2. Go to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource to terminate. 3. Go to the Auto-Scaling Group Details page.
- Click the Auto-Scaling Group Delete button.
- After the deletion is complete, verify on the Auto-Scaling Group List page that the resource has been deleted.
2.2.1 - Launch Configuration
To create an Auto-Scaling Group, a Launch Configuration must be created in advance.
Create Launch Configuration
You can create and use the Launch Configuration service in the Samsung Cloud Platform Console.
To create a Launch Configuration, follow these steps.
All Services > Compute > Virtual Server menu, please click. 1. Navigate to the Service Home page of the Virtual Server.
Click the Launch Configuration menu. 2. Go to the Launch Configuration List page.
On the Launch Configuration List page, click the Create Launch Configuration button. 3. Go to the Launch Configuration creation page.
On the Launch Configuration creation page, in the Image and version selection area, select the required information and click the Next button.
Reference- Refer to the Virtual Server OS Image 제공 버전 for the images selectable in the Launch Configuration.
- In Custom Image, you can select Image-Based and Snapshot-Based images.
- Snapshot-Based type Image does not support future features such as distributed disk deployment, so for a stable Auto-Scaling configuration, we recommend using Image-Based type Image.
- Image-Based type Image generation details can be found in Image-Based 유형의 Image 생성하기.
Enter the required information in the Service Information Input area of the Launch Configurationp creation page.
Category Required statusDetailed description Launch Configuration name Essential Launch Configuration name - a name to distinguish the Launch Configuration
Service Type > Server Type Essential Server type of Launch Configuration - Standard: Standard specification commonly used
- High Capacity: Large‑capacity server specification above Standard
- Refer to Virtual Server 서버 타입 for selectable server types
- Since supported Availability Zones may differ by server type, verification is required via Support Center > Contact Us
Block Storage Required Configure Block Storage according to the purpose of the Launch Configuration - Basic OS: The area where the OS is installed and used
- Enter the size in Units; the minimum size varies depending on the OS Image type
- Alma Linux: Enter a value between 2 and 1,536
- Oracle Linux: Enter a value between 5 and 1,536
- RHEL: Enter a value between 2 and 1,536
- Rocky Linux: Enter a value between 2 and 1,536
- Ubuntu: Enter a value between 1 and 1,536
- Windows: Enter a value between 4 and 1,536
- SSD: High‑performance general volume
- HDD: General volume
- SSD/HDD_KMS: Additional encrypted volume using Samsung Cloud Platform KMS (Key Management System) encryption keys
- Encryption can be applied only at initial creation and cannot be changed afterward
- Using the SSD_KMS disk type may result in performance degradation
- Enter the size in Units; the minimum size varies depending on the OS Image type
- Additional: Use when extra space beyond the OS area is needed
- After selecting Use, enter the storage type and size
- Click the + button to add storage, or the x button to delete (up to 25 can be added)
- Enter the size in Units, with a value between 1 and 1,536
- Since 1 Unit equals 8 GB, this creates 8 ~ 12,288 GB
- SSD: High‑performance general volume
- HDD: General volume
- SSD/HDD_KMS: Additional encrypted volume using Samsung Cloud Platform KMS (Key Management System) encryption keys
- Encryption can be applied only at initial creation and cannot be changed afterward
- Using the SSD_KMS disk type may result in performance degradation
- SSD_MultiAttach: Volume that can be attached to more than one server
- For details on each Block Storage type, refer to Create Block Storage ___HTML_MARKER***
Keypair Essential Select the user authentication method for the Launch Configuration - Server authentication information for accessing the servers created by generating an Auto-Scaling Group with a Launch Configuration
- New creation: Create a new one if a new Keypair is needed
- Refer to Keypair 생성하기 for how to create a new Keypair
- Default login account list by OS
- Alma Linux: almalinux
- RHEL: cloud-user
- Rocky Linux: rocky
- Ubuntu: ubuntu
- Windows: sysadmin
File Storage Settings Selection When performing Scale-out/Scale-in, you can configure File Storage to be automatically attached - Volume: After clicking the Select button, choose the Volume to use in the File Storage selection popup
- You can select up to a maximum of 5
- Only Volumes intended as source that can be attached to a Virtual Server can be selected
- High‑performance SSDs are disabled because they cannot be attached to a Virtual Server
- The selected Volume can be removed by clicking the X button
Table. Launch Configuration service information input itemsOn the Launch Configuration Creation page, after entering information in the Additional Information Input area, click the Next button.
Category required statusDetailed description Init Script Selection The script that runs when a server in an Auto-Scaling Group using a Launch Configuration starts - Enter within 45,000 bytes
- The Init Script must be a batch script for Windows, a shell script for Linux, or cloud‑init, depending on the selected image.
tag Selection Add Tag - Up to 50 per resource can be added
- Add Tag After clicking the Add Tag button, enter or select Key, Value values
Table. Launch Configuration additional information entry fieldsOn the Check Creation Information page, verify the entered information and the estimated amount, then click the Create button.
- When creation is complete, verify the created Launch Configuration on the Launch Configuration list page.
Launch Configuration View detailed information
The Launch Configuration service lets you view and edit the complete list of resources and their detailed information. On the Launch Configuration Details page, it consists of Detailed Information, Tags, Operation History tabs.
To view the detailed information of the Launch Configuration, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Launch Configuration menu. 2. Go to the Launch Configuration list page.
- Launch Configuration List On the page, click the resource to view detailed information. 3. Launch Configuration Details Navigate to the page.
- Launch Configuration Details At the top of the page, status information and additional feature information are displayed, and it consists of Details, Tags, Activity History tabs.
Category Detailed description Launch Configuration status The status of the user-created Launch Configuration - Active: available
Delete Launch Configuration Delete Launch Configuration button Table. Launch Configuration status information and additional features
- Launch Configuration Details At the top of the page, status information and additional feature information are displayed, and it consists of Details, Tags, Activity History tabs.
Detailed Information
Launch Configuration List page allows you to view detailed information of the selected resource and, if necessary, modify the information.
| Category | Detailed description |
|---|---|
| service | Service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation Date/Time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Launch Configuration name | Launch Configuration name |
| Image | When creating a Launch Configuration, the selected Image name
|
| Auto-Scaling Group count | Number of Auto-Scaling Groups using a Launch Configuration |
| Server type | Server type set in the Launch Configuration |
| Block Storage | Block Storage information per server set in the Launch Configuration
|
| Keypair | Server authentication information set in the Launch Configuration
|
| Init Script | Init Script set in the Launch Configuration
|
| File Storage Settings | File Storage Volume name set in the Launch Configuration
|
Table. Launch Configuration detailed information tab items
Tag
On the Launch Configuration list page, you can view the tag information of the selected resource, and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Launch Configuration tag tab items
Operation History
Launch Configuration List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource change history
|
Table. Launch Configuration Job History Tab Detailed Information Items
Launch Configuration Resource Management
Explains the resource management function of Launch Configuration.
Generate Image-Based type Image
To create an Image of the Image-Based type, follow the steps below.
information
- If the image type is Snapshot-Based, it does not support future features such as distributed disk deployment. * We recommend using an Image with Image type set to Image-Based for a stable Auto-scaling configuration.
- When generating an Image of the Image-Based type, only one OS area disk volume is included in the target. * Note that additionally attached data volumes are not included in the Image.
- An Image can be created as an Image-Based type only if its Visibility is private and it has snapshot information.
- If the OS disk size is 500 GB or more, you cannot create an Image of the Image-Based type.
- Object Storage fees for Image storage will be billed.
To create an Image of the Image-Based type, follow the steps below.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- On the Service Home page, click the Image menu. 2. Go to the Image list page.
- On the Image List page, click the Image to create an Image of the Image-Based type. 3. Image Details go to the page.
- Create Image for Sharing button, click it. 4. A popup window opens to notify the creation of a shared Image. 4. The popup’s ‘Share to another Account’ content will not be processed. 4. If you only proceed with ‘Create Image for sharing’, an Image-Based type Image will be generated.
- After reviewing the contents of the popup window, click the Confirm button.
Delete Launch Configuration
Deleting unused Launch Configurations can reduce operating costs. However, terminating the Launch Configuration may cause the running service to stop immediately, so you should proceed with the termination only after fully considering the impact of service interruption.
Caution
Please be careful, as data cannot be recovered after deletion.
To delete a Launch Configuration, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Launch Configuration menu. 2. Go to the Launch Configuration List page.
- Launch Configuration List On the page, click the resource to be terminated. 3. Navigate to the Launch Configuration Details page.
- Click the Delete Launch Configuration button.
- After the deletion is complete, verify on the Launch Configuration list page that the resource has been deleted.
Caution
The Launch Configuration applied to the Auto-Scaling Group cannot be deleted.
Please delete the Auto-Scaling Group first, then delete the Launch Configuration.
2.2.2 - Manage Policy
You can dynamically adjust the number of servers in an Auto-Scaling Group based on monitoring metrics. When the metric exceeds the threshold you set, the server count is adjusted. At that time, you can choose one of three methods to adjust the server count: increase or decrease by a specified number, increase or decrease by a specified percentage, or fix the server count to a given value. When servers are launched or terminated due to a policy, the monitoring metric, such as CPU utilization, may temporarily exceed the threshold registered in the policy. However, because this is a brief moment, a cooldown period is set to avoid treating it as an abnormal condition. You can add and manage policies for an Auto-Scaling Group created in the Samsung Cloud Platform Console.
Add Policy
You can add policies to an Auto-Scaling Group. To add a policy to an Auto-Scaling Group, follow these steps.
Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
Click the Auto-Scaling Group menu. You will be taken to the Auto-Scaling Group List page.
Auto-Scaling Group List page, click the resource you want to view detailed information for. You will be taken to the Auto-Scaling Group Details page.
Click the Policy Tab. You will be taken to the Policy Tab page.
Click the Add Policy button. The Add Policy popup window opens.
Category RequiredDetailed description Category Required Policy Category - Scale In: return server count
- Scale Out: increase server count
Policy Name Required Name for policy-specific categorization Execution conditions Required Conditions to execute the policy - Statistic: How to calculate the Metric Type
- Average: Average of servers in the Auto-Scaling Group
- Min: Minimum value among servers in the Auto-Scaling Group
- Max: Maximum value among servers in the Auto-Scaling Group
- Metric Type: CPU Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- Operator:
>=><=<
- Threshold: Threshold corresponding to the Metric Type
- Period: Continuous duration required to trigger the condition (the condition must be continuously satisfied for N minutes for the policy to execute)
execution unit Required Policy execution method - Policy Type: Select the type of policy to execute.
- Increase or decrease the number of servers by a specified count: Increase or decrease the server count to the Target Value
- Increase or decrease the number of servers by a specified ratio: Increase or decrease by the Target Value ratio
- Fix the number of servers to the entered value: Fix the server count according to the Target Value
- Target Value: The number or ratio to apply for the selected Policy Type
cooldown Required The waiting time (seconds) when a server is started or terminated due to a policy - The default is 300 seconds, and it can be set between a minimum of 60 seconds and a maximum of 3,600 seconds.
Table. Add Policy Popup ItemsReferencePolicy > Cooldown Settings
- When a server is started or terminated due to a policy, it waits for the configured cooldown period. Temporarily, the monitoring metric CPU utilization may exceed the threshold defined in the policy. However, because this is a transient moment rather than a condition for adjusting the number of servers, it is not considered an abnormal situation, and the system waits by applying the cooldown time.
guidePolicy execution operates within the configured Min/Max server count range.
- Even if you input values outside the Min/Max server count range—such as increasing, returning, or fixing the number of servers—it operates within the configured Min/Max server count.
- Example: When the minimum number of servers is 3, even if you set the server count fixed to 1, the server count does not drop to 1 and remains at the minimum of 3.
Add Policy After entering the required values in the popup window, click the Confirm button. The added policy can be viewed in the Policy List.
Policy creation example
The following is an explanation of the policy example. Please refer to it when creating a policy.
Policy example description 1
| Category | Execution Conditions | execution unit | cooldown |
|---|---|---|---|
| Scale Out | Average CPU Usage >= 60% occurs for 1 minute | Increase the server count by the specified number, incrementing by one unit. | 300 seconds |
Table. Auto-Scaling Group policy example 1
- If the average CPU usage of the servers in the Auto-Scaling Group exceeds 60% for one minute, a server is added one at a time.
- When a server is added, the cooldown period is 300 seconds, and during this time, no server addition or removal due to policy occurs.
- After the cooldown period ends, the policy execution conditions are checked again.
Policy example description 2
| Category | Execution Conditions | execution unit | cooldown |
|---|---|---|---|
| Scale In | Min CPU Usage <= 5% occurs for 1 minute | Scale the number of servers up or down by the specified ratio, returning 50%. | 300 seconds |
Table. Auto-Scaling Group policy example 2
- If the minimum CPU usage of servers in the Auto-Scaling Group remains below 5% for 1 minute, 50% of the current servers will be terminated.
- When a server is terminated, the cooldown period is 300 seconds, and during this time, no server additions or removals occur due to policy.
- After the cooldown period ends, the policy execution conditions are checked again.
Policy example description 3
| Category | Execution Conditions | Execution Unit | cooldown |
|---|---|---|---|
| Scale Out | Max CPU Usage >= 90% occurs for 1 minute | Fix the number of servers to 5 based on the entered value | 300 seconds |
Table. Auto-Scaling Group policy example 3
- If the maximum CPU usage among the servers in the Auto-Scaling Group exceeds 90% for 1 minute and the current number of servers is less than 5, servers will be created up to a total of 5.
- During server creation, the cooldown period is 300 seconds, and no server additions or removals due to policy occur during the cooldown period.
- After the cooldown period ends, the policy execution conditions are checked again.
Edit Policy
You can modify the policies of an Auto-Scaling Group. To modify the policies of an Auto-Scaling Group, follow these steps.
Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
Click the Auto-Scaling Group menu. Navigate to the Auto-Scaling Group List page.
Auto-Scaling Group List page, click the resource to view detailed information. You will be taken to the Auto-Scaling Group Details page.
Click the Policy Tab. You will be taken to the Policy Tab page.
Click the More > Edit button for the policy you want to modify. The Policy Edit Popup opens.
Category RequiredDetailed description Category Required Policy Classification - Scale In: Return server count
- Scale Out: Increase server count
Policy Name Required Name for policy-specific categorization Execution conditions Required Conditions to execute the policy - Statistic: Method to calculate the Metric Type
- Average: Average of servers in the Auto-Scaling Group
- Min: Minimum value among servers in the Auto-Scaling Group
- Max: Maximum value among servers in the Auto-Scaling Group
- Metric Type: CPU Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- Operator:
>=><=<
- Threshold: Threshold corresponding to the Metric Type
- Period: Continuous duration (in minutes) that triggers the execution condition
execution unit Required Policy execution method - Policy Type: Select the type of policy to execute.
- Increase or decrease the number of servers by a specified count: Increase or reduce the server count to the Target Value
- Increase or decrease the number of servers by a specified ratio: Increase or reduce by the Target Value ratio
- Fix the number of servers to the entered value: Fix the server count according to the Target Value
- Target Value: The number or ratio to execute the selected Policy Type
Cool down Required The waiting time (seconds) when a server is started or terminated due to a policy - The default is 300 seconds, and it can be set from a minimum of 1 second up to a maximum of 3,600 seconds
Table. Policy edit popup itemsEdit Policy In the popup window, after entering the required values, click the Confirm button.
Policy addition and modification constraints
When adding or modifying a policy, constraints exist based on the policy classification, execution conditions, and the scope of those conditions. Below is an example of constraints for the policy. Refer to the constraint examples to add or modify the policy.
Example 1 - Need to check for duplicate registration of policy classification/execution conditions
Policy classification (Scale Out or Scale In) and execution condition (Metric type) cannot be registered redundantly with the same values.
| Policy classification | Policy Name | Execution Condition(Statistic) | Execution condition(Metric type) | Execution condition range |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
Table. Policy Constraint Example 1 - Pre-registration Policy
If a policy is registered as above, you cannot add a policy with the category (Scale Out) execution condition (Metric type=CPU Usage) or modify it to that condition.
Example 2 - Need to verify the execution condition range for execution conditions (Metric type) and execution conditions (Statistic) according to policy classification
When the policy type (Scale Out or Scale In) differs, duplicate registration of the execution condition range (Comparison operator + Threshold) is not allowed for the same execution condition (Metric type) and execution condition (Statistic).
| Policy classification | Policy Name | Execution condition(Statistic) | Execution condition(Metric type) | Execution condition range |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
Table. Policy Constraint Example 2 - Pre-registration Policy
If a policy is registered as shown above, you cannot add a policy as below or modify it under the following conditions.
If the average CPU Usage is 60% or higher, a Scale Out policy is already registered; therefore, registering a Scale In policy when the average CPU Usage is 60% or lower would duplicate the 60% execution condition and cannot be added.
| Policy Classification | Policy Name | Execution Condition(Statistic) | Execution condition(Metric type) | Execution condition range |
|---|---|---|---|---|
Scale In | AddUpdatePolicy | Average | CPU Usage | <= 60% |
Table. Policy Constraint Example 2 - Non-Addable Policy
Example 3 - Need to verify the execution condition range for execution conditions (Metric type) and execution conditions (Statistic) according to policy classification
When the policy classification (Scale Out or Scale In) differs, duplicate registration of the execution condition range (Comparison operator + Threshold) is not allowed for the same execution condition (Metric type) and execution condition (Statistic).
| Policy classification | Policy Name | Execution condition(Statistic) | Execution condition (Metric type) | Execution condition range |
|---|---|---|---|---|
Scale In | ScaleInPolicy | Average | CPU Usage | <= 10% |
Table. Policy Constraint Example 3 - Pre-registration Policy
If a policy is registered as shown above, you cannot add a policy as below or modify it under the following conditions.
When the average CPU Usage is 10% or less, a Scale In policy is already registered; therefore, if the average CPU Usage is less than 60% / 60% or less / 10% or more / exceeds 9%, you cannot register a Scale Out policy because the execution condition ranges would overlap.
| Policy classification | Policy Name | Execution Condition(Statistic) | Execution condition(Metric type) | Execution condition range |
|---|---|---|---|---|
Scale Out | AddUpdatePolicy1 | Average | CPU Usage | < 60% |
Scale Out | AddUpdatePolicy2 | Average | CPU Usage | <= 60% |
Scale Out | AddUpdatePolicy3 | Average | CPU Usage | >= 10% |
Scale Out | AddUpdatePolicy4 | Average | CPU Usage | > 9% |
Table. Policy constraint example 3 – non‑addable policy
Example 4 - Execution conditions (Metric type) and execution conditions (Statistic) can be registered according to the execution condition range based on policy classification
If the policy type (Scale Out or Scale In) differs, you can register when the execution condition (Metric type) is the same but the execution condition (Statistic) is different, or when the execution condition range (Comparison operator + Threshold) does not overlap.
| Policy classification | Policy Name | Execution Condition(Statistic) | Execution condition (Metric type) | Execution Condition Range |
|---|---|---|---|---|
Scale Out | ScaleOutPolicy | Average | CPU Usage | >= 60% |
Table. Policy Constraint Example 4 - Pre-registration Policy
If a policy is already registered as shown above, you can add a policy as below or modify it with the following conditions. Registration is possible when the execution condition ranges do not overlap, or when the execution condition (Statistic) differs.
| Policy classification | Policy Name | Execution Condition(Statistic) | Execution condition (Metric type) | Execution condition range |
|---|---|---|---|---|
Scale In | AddUpdatePolicy1 | Average | CPU Usage | <= 10% |
Scale In | AddUpdatePolicy2 | Min | CPU Usage | <= 60% |
Table. Policy constraint example 4 – Addable policy
Delete Policy
You can delete a policy of an Auto-Scaling Group. To delete a policy of an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. Navigate to the Auto-Scaling Group List page.
- Auto-Scaling Group List page: click the resource you want to view details for. You will be taken to the Auto-Scaling Group Details page.
- Click the Policy Tab. You will be taken to the Policy Tab page.
- Select the policy to delete and click the Delete button. The Policy Deletion Confirmation popup opens.
- Policy Deletion Confirmation Check the popup window and click the Confirm button.
2.2.3 - Manage Schedule
You can schedule reservations daily, weekly, monthly, or one-time, and set the desired number of servers at the specified time. This is useful when you can predict when you need to decrease or increase the number of servers.
Add schedule
You can add a schedule to an Auto-Scaling Group. To add a schedule to an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. Navigate to the Auto-Scaling Group List page.
- Auto-Scaling Group List page, click the resource you want to view detailed information for. You will be taken to the Auto-Scaling Group Details page.
- Click the Schedule Tab. You will be taken to the Schedule Tab page.
- Click the Add Schedule button. The Add Schedule popup window opens.
Category requiredDetailed description Schedule name Required Name to distinguish by schedule Select server count Required Select the number of servers to adjust when executing the schedule - Min: The minimum number of servers the Auto-Scailg Group should maintain
- Desired: The target number of servers within the Auto-Scailg Group
- Max: The maximum number of servers the Auto-Scailg Group can maintain
Enter the number of servers Required Enter the value for the selected number of servers - Min value: Enter a value between 0 and 50. (Min≤Desired≤Max)
- Desired value: Enter a value between 0 and 50. (Min≤Desired≤Max)
- Max value: Enter a value between 0 and 50. (Min≤Desired≤Max)
Period Required Schedule execution frequency - Daily: You can set the Start date, End date, and Permanent options for a daily schedule. You can also set the Time and Time zone
- Weekly: You can set the Start date, End date, Permanent options, and the Time and Time zone. You can also select the Day of week on which the weekly schedule will run.
- Monthly: You can set the Start date, End date, Permanent options, and the Time and Time zone. You can also enter the Date on which the monthly schedule will run
- One-time: You can set the Time and Time zone. You can also set the Date on which the one-time schedule will run
Start date Selection Set schedule start date - Cannot set a date earlier than the current date. The default is the current date.
End date Selection Set schedule end date - Cannot set a date earlier than the current date. The default is the current date plus 7 days.
permanent Selection When configuring permanently, set the schedule end date to 9999-12-31 time Required Schedule execution time setting - Can be set in 30‑minute increments. Times earlier than the current date or current time cannot be set
time zone Required Schedule execution time zone (example: Asia/Seoul (GMT +09:00)) day of the week Required When Period is set to Weekly, select the Day of the week to execute the schedule Date Required - When Period is set to Monthly, enter the Date on which the schedule will run
- Enter one or more values from -31 to 31, excluding 0. (Example: 3,4,5)
- When Period is set to Once, set the Date on which the schedule will run
- Setting a date earlier than the current date is not allowed. The default is the current date.
Table. Schedule addition popup items - Add Schedule After entering the required values in the popup window, click the Confirm button.
- Add Schedule Confirmation After checking the message in the popup window, click the Confirm button.
Reference
If you select the schedule frequency as monthly, you must enter the schedule execution date, Date. Refer to the information below to register the schedule.
- If you input a number greater than 0, it represents the day of the month.
- Example: If you enter 1, you get August 1, September 1, …, December 1
- If you enter a number less than 0, the calculation starts from the end of each month.
- Entering -1 means the last day of each month.
- Example: August 31, September 30, …, December 31
- If you enter -2, it means the day before the last day of each month.
- Example: August 30, September 29, …, December 30
- Since the last day of each month varies—31, 30, 29, or 28 days—we allow calculation from the end of the month using negative numbers, as shown above, to handle schedules that need to run on the month’s final day.
- Entering -1 means the last day of each month.
Information
- When the schedule runs, if the Min server count set in the schedule is greater than the Desired server count, or if the Max server count is less than the Desired server count, the Desired server count is also adjusted.
- If there are schedules with overlapping execution times, they may not run correctly. Please try to avoid overlapping execution times as much as possible.
Modify schedule
You can modify the schedule of an Auto-Scaling Group. To modify the schedule of an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. Navigate to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource for which you want to view detailed information. You will be taken to the Auto-Scaling Group Details page.
- Click the Schedule Tab. You will be taken to the Schedule Tab page.
- Click the More > Edit button of the schedule you want to modify. The Edit Schedule popup window will open.
Category requiredDetailed description Schedule name Required Name to distinguish by schedule Select number of servers Required Select the number of servers to adjust when executing the schedule - Min: The minimum number of servers the Auto-Scailg Group should maintain
- Desired: The target number of servers within the Auto-Scailg Group
- Max: The maximum number of servers the Auto-Scailg Group can maintain
Enter number of servers Required Enter the value for the selected number of servers - Min value: Enter a value between 0 and 50. (Min≤Desired≤Max)
- Desired value: Enter a value between 0 and 50. (Min≤Desired≤Max)
- Max value: Enter a value between 0 and 50. (Min≤Desired≤Max)
period Required Schedule execution frequency - Daily: You can set the Start Date and End Date, and Permanent setting for the daily schedule. You can also set the Time and Time Zone
- Weekly: You can set the Start Date and End Date, Permanent setting, and the Time and Time Zone. You can also select the Day of Week for the Weekly schedule to run.
- Monthly: You can set the Start Date and End Date, Permanent setting, and the Time and Time Zone. You can also enter the Date for the Monthly schedule to run.
- Once: You can set the Time and Time Zone. You can also set the Date for the Once schedule to run
Start date Selection Set schedule start date - Cannot set a date earlier than the current date. The default is the current date.
End date Selection Set schedule end date - Cannot set a date earlier than the current date. The default is the current date plus 7 days.
Permanent Selection When configuring permanently, set the schedule end date to 9999-12-31. time Required Schedule execution time setting - Can be set in 30‑minute increments. Times earlier than the current date or current time cannot be set
time zone Required Schedule execution time zone (example: Asia/Seoul (GMT +09:00)) day of the week Required When Period is weekly, select the day of the week to run the schedule. Date Required - When Period is set to Monthly, enter the Date on which the schedule will run
- Enter one or more values from -31 to 31, excluding 0. (Example: 3,4,5)
- When Period is set to Once, set the Date on which the schedule will run
- Cannot set a date earlier than the current date. The default is the current date.
Table. Schedule edit popup items - Schedule Edit After entering the required values in the popup window, click the Confirm button.
- Schedule Modification Confirmation After checking the message in the popup window, click the Confirm button.
Delete schedule
You can delete the schedule of an Auto-Scaling Group. To delete the schedule of an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. You will be taken to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource for which you want to view detailed information. You will be taken to the Auto-Scaling Group Details page.
- Click the Schedule Tab. You will be taken to the Schedule Tab page.
- Select the schedule to delete and click the Delete button. Schedule Deletion Confirmation popup will open.
- Schedule Deletion Confirmation Check the popup window and click the Confirm button.
2.2.4 - Manage Notification
You can designate a notification recipient and send alert messages via E‑mail or SMS for specific situations.
Reference
- The notification method (E-mail or SMS) can be set on the Notification Settings page by selecting Notification Target as Service > Virtual Server Auto-Scaling.
- For details on editing notification settings, refer to Edit Notification Settings.
Add notification
You can add notifications to an Auto-Scaling Group. To add notifications to an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. You will be taken to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource to which you want to add notification information. You will be taken to the Auto-Scaling Group Details page.
- Click the Notification Tab. You will be taken to the Notification Tab page.
- Click the Add Notification button. The Add Notification popup opens.
- Add Notification After entering the required values in the popup window, click the Confirm button.
Category Detailed description Notification timing Notification timing when an Auto-Scaling Group alert occurs - Server creation, Server termination, Server creation failure, Server termination failure, When policy execution conditions are met
- Multiple selection allowed
Notification recipient User who will receive the notification when an alert occurs - Click the Add Notification Recipient button to select a user
- Only Samsung Cloud Platform users can be selected as recipients
Table. Notification items
Caution
When adding a notification recipient, verify that an email address exists and add it. Only users with login history (users who have registered an email or mobile phone number) can receive notifications.
- Add Notification Confirmation After checking the message in the popup window, click the Confirm button.
Edit Notification
You can modify the notification settings of an Auto-Scaling Group. To modify the notification settings of an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. Navigate to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource to edit the notification information. You will be taken to the Auto-Scaling Group Details page.
- Click the Notification Tab. You will be taken to the Notification Tab page.
- In the notification list, click the More > Edit button for the notification you want to modify. The Edit Notification popup window will open.
- Edit Notification After editing the notification information in the popup window, click the Confirm button.
Category Detailed description Notification timing Notification timing when an Auto-Scaling Group alert occurs - Server creation, Server termination, Server creation failure, Server termination failure, When policy execution conditions are met
- Multiple selection allowed
Table. Notification edit items - Edit Notification Confirmation After checking the message in the popup window, click the Confirm button.
Delete Notification
You can delete notifications for an Auto-Scaling Group. To delete notifications for an Auto-Scaling Group, follow these steps.
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Auto-Scaling Group menu. You will be taken to the Auto-Scaling Group List page.
- On the Auto-Scaling Group List page, click the resource to edit the notification information. You will be taken to the Auto-Scaling Group Details page.
- Click the Notification Tab. You will be taken to the Notification Tab page.
- In the notification list, select the notification you want to delete, then click the Delete button. The Delete Notification Confirmation popup will open.
- Delete Notification Confirmation Review the popup window and click the Confirm button.
2.3 - API Reference
API Reference
2.4 - CLI Reference
CLI Reference
2.5 - Release Note
Virtual Server Auto-Scaling
2026.03.19
FEATURE
Virtual Server and Load Balancer status check feature and other feature additions- Virtual Server and Load Balancer status check functionality has been added.
- Check the status of Virtual Server and Load Balancer and automatically replace servers that are in an Unhealthy state.
- You can attach File Storage to a Launch Configuration.
- When creating a Launch Configuration, you can attach up to five File Storage Volumes.
- You can monitor data by integrating with the ServiceWatch service.
- When setting the execution conditions of the policy, Memory Usage was excluded from the Metric Type.
2025.10.23
FEATURE
Virtual Server termination feature improvement- The termination functionality for Virtual Servers created by the Auto-Scaling Group has been improved.
- When a Virtual Server is terminated, the Load Balancer is automatically detached.
- The desired number of servers remains unchanged, and scale-out is performed according to the desired check batch.
2025.07.01
FEATURE
Add new feature- Added a notification feature to Virtual Server Auto-Scaling.
- You can add notification settings in the creation or detail screen of an Auto-Scaling Group.
- You can set scaling policies when creating an Auto-Scaling Group.
- Added the Metric Type to the Auto-Scaling Group policy.
- Additional: Memory Usage, Network In(bytes), Network Out(bytes), Network In(Packets), Network Out(Packets)
- You can set the Draining Timeout when connecting to a Load Balancer.
- An Auto-Scaling Group can connect up to 50 Virtual Servers, and up to three LB server groups and ports.
2025.02.27
FEATURE
Virtual Server Auto Scaling-Load Balancer Release of service integration and addition of NAT configuration feature- Virtual Server Auto-Scaling feature change
- It will be released in conjunction with the Load Balancer service launching in February 2025.
- NAT configuration functionality has been added to Auto-Scaling Group.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, Service Home, tags, etc., have been updated to reflect common CX changes.
2024.11.19
NEW
Virtual Server Auto Scaling Service Official Version Launch- Virtual Server Auto-Scaling creates an Auto-Scaling Group through a Launch Configuration and monitors and manages the servers.
- Provides a scheduling method that allows setting the desired number of servers at a specified time, and a policy method that adjusts the number of servers based on CPU utilization.
3 - GPU Server
3.1 - Overview
Service Overview
GPU Server is a virtualized computing service that lets you freely allocate and use infrastructure resources such as CPU, GPU, and memory provided by the server, without having to purchase them individually, and allocate as much as needed at the required time. It is suitable for tasks that require fast computation speed, such as AI model experiments, predictions, and inference in a cloud environment, and you can flexibly select and use resources with optimized performance according to the type and scale of the work. The GPU Server provides the following features.
Provided features
- GPU Server Management: Through a web-based console, users can directly Self Service create, delete, and modify GPU servers from provisioning to monitoring and billing.
- Product offering by GPU quantity: Depending on the project’s purpose and scale, you can freely select the number of H100/A100 GPUs to configure a virtual server.
- High‑Performance GPU Provision: We provide high‑performance GPU servers at physical‑server level using a pass‑through method.
- Storage Connection: Provides additional attached storage besides the OS disk. * Block Storage, File Storage, Object Storage can be connected and used.
- Strong Security Enforcement: Through the Security Group service, control inbound/outbound traffic exchanged with the external Internet or other VPC (Virtual Private Cloud) to securely protect the server.
- Monitoring: You can view monitoring information such as the status of CPU, Memory, Disk, and GPU, which are computing resources, through the Cloud Monitoring service.
- Network Configuration Management: The server’s subnet/IP can be conveniently changed from the values set at initial creation. * NAT IP provides a management feature that lets you enable or disable it as needed.
- Key Pair method: To ensure a secure OS access method, we provide a Key Pair method instead of ID/PW login.
- Image Management: You can create and manage Custom Images, and it provides sharing functionality between projects.
- ServiceWatch Service Integration: You can monitor data through the ServiceWatch service.
Components
GPU Server provides GPUs, NVSwitch, and NVLink on top of virtualized computing resources.
caution
- NVSwitch can be enabled and used only for instance types that allocate eight GPUs on a single GPU server.
Specifications by GPU Type
GPU (Graphic Processing Unit) performs the calculations required to generate the images that compose a computer screen, and because it is specialized for parallel processing, it can handle large amounts of data quickly, processing large‑scale parallel operations such as artificial intelligence (AI) and data analysis. The specifications of the GPU Types provided by the GPU Server service are as follows.
| Category | A100 Type | H100 Type | B300 Type |
|---|---|---|---|
| GPU Architecture | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Blackwell Ultra |
| GPU Memory | 80 GiB | 80 GiB | 268 GiB |
| GPU Transistors | 54 billion 7N TSMC | 80 billion 4N TSMC | 208 billion 4NP TSMC |
| FP16 Tensor Core (Dense) | 312 TFLOPs | 989 TFLOPs | 2.25 PFLOPs |
| FP8 Tensor Core (Dense) | Unsupported | 1,979 TFLOPs | 4.5 PFLOPs |
| FP4 Tensor Core (Dense) | Unsupported | Unsupported | 13.5 PFLOPs |
| GPU Memory Bandwidth | 2,039 GB/s HBM2e | 3,352 GB/s HBM3 | 8 TB/s HBM3e |
| NVLink performance | NVLink 3 | NVLink 4 | NVLink 5 |
| NVLink Signaling Rate | 25 GB/s (x12) | 25 GB/s (x18) | 50 GB/s (x18) |
| NVSwitch GPU-to-GPU bandwidth | 600 GB/s | 900 GB/s | 1.8 TB/s |
| Total NVSwitch aggregate bandwidth | 4.8 TB/s | 7.2 TB/s | 14.4 TB/s |
Table. Specifications by GPU Type
NPU Type Specifications
The NPU (Network Processing Unit) is a processor specialized for AI inference operations, performing generative AI and various AI inference workloads based on high throughput and power efficiency. The specifications of the NPU Type provided by the GPU Server service are as follows.
| Category | Furiosa RNGD |
|---|---|
| Architecture | Tensor Contraction Processer |
| BF16 | 256 TFLOPS |
| FP8 | 512 TFLOPS |
| Memory Bandwidth | HBM3 1.5 TB/s |
| Memory Capacity | HBM3 48 GB |
| Interconnect Interface | PCIe Gen5 x16 |
Table. Specifications by NPU Type
Server type
The server types offered by the GPU Server are as follows. For detailed information about the server types provided by GPU Server, see GPU Server 서버 타입.
| Category | Server type | CPU vCore | Memory(GB) | GPU/NPU quantity |
|---|---|---|---|---|
| GPU-A100-1 | g1v16a1 | 16 | 234 | 1 |
| GPU-A100-1 | g1v32a2 | 32 | 468 | 2 |
| GPU-A100-1 | g1v64a4 | 64 | 936 | 4 |
| GPU-A100-1 | g1v128a8 | 128 | 1,872 | 8 |
| GPU-H100-2 | g2v12h1 | 12 | 234 | 1 |
| GPU-H100-2 | g2v24h2 | 24 | 468 | 2 |
| GPU-H100-2 | g2v48h4 | 48 | 936 | 4 |
| GPU-H100-2 | g2v96h8 | 96 | 1,872 | 8 |
| GPU-B300-3 | g3v16b1 | 16 | 480 | 1 |
| GPU-B300-3 | g3v32b2 | 32 | 960 | 2 |
| GPU-B300-3 | g3v64b4 | 64 | 1,920 | 4 |
| GPU-B300-3 | g3v128b8 | 128 | 3,840 | 8 |
| NPU-RNGD-1 | n1v8r1 | 8 | 106 | 1 |
| NPU-RNGD-1 | n1v16r2 | 16 | 212 | 2 |
| NPU-RNGD-1 | n1v32r4 | 32 | 424 | 4 |
| NPU-RNGD-1 | n1v64r8 | 64 | 848 | 8 |
Table. GPU Server server type
OS and driver version
The operating systems (OS) supported by the GPU Server are as follows. Please be aware that B300-type GPUs are supported only from a certain GPU version onward, so choose your image accordingly.
| OS | OS version | Driver version | Server type classification |
|---|---|---|---|
| Ubuntu | 24.04 | ND 580.126.20 | GPU-B300-3, GPU-H100-2, GPU-A100-1 |
| Ubuntu | 24.04 | ND 570.195.03 | GPU-H100-2, GPU-A100-1 |
| Ubuntu | 24.04 | FRD 2026.2.0 | NPU-RNGD-1 |
| Ubuntu | 22.04 | ND 535.183.06 | GPU-H100-2, GPU-A100-1 |
| RHEL | 9.6 | ND 580.126.20 | GPU-B300-3, GPU-H100-2, GPU-A100-1 |
| RHEL | 8.1 | ND 580.126.20 | GPU-B300-3, GPU-H100-2, GPU-A100-1 |
| RHEL | 8.1 | ND 535.183.06 | GPU-H100-2, GPU-A100-1 |
Table. GPU Server OS and driver version
Constraints
The GPU Server has the following constraints.
- We are providing Ubuntu22.04 as the current OS version.
- GPU is provided via Pass-through.
- Physical GPU cards are created in units of 1, 2, 4, or 8 cards each. * –>
Preceding Service
This service must be installed in advance before creating it. Please prepare by referring to the user guide provided in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
| Networking | Security Group | Virtual firewall that controls server traffic |
Table. GPU Server Preliminary Service
3.1.1 - Server type
GPU Server server type
GPU servers are categorized by the GPU type they offer, and the GPU used in a GPU server is determined by the server type selected when creating the GPU server. Please select the server type based on the specifications of the application you want to run on the GPU server.
The server types supported by the GPU Server are as follows.
GPU-H100-2 g2v12h1
Category | Example | Detailed description |
|---|---|---|
| Server type | GPU-H100-2 | Provided server type classification
|
| Server specifications | g2 | 제공되는 서버 타입 구분 및 세대
|
| 서버 사양 | v12 | vCore 개수
|
| 서버 사양 | h1 | GPU 종류와 수량
|
Table. GPU Server server type format
g1 server type
The g1 server type is a GPU Server that uses the NVIDIA A100 Tensor Core GPU, making it suitable for high‑performance applications.
- Up to 8 NVIDIA A100 Tensor Core GPUs provided
- Equipped with 6,912 CUDA cores and 432 Tensor cores per GPU.
- Supports up to 128 vCPUs and 1,920 GB of memory
- Maximum networking speed of 40 Gbps
- 600 GB/s GPU and NVIDIA NVSwitch P2P communication
- Additional AMD CPU-based server type provided (GPU-A100-1-A)
| 구분 | 서버 타입 | GPU | CPU | Memory | GPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| GPU-A100-1 | g1v16a1 | 1 | 16 vCore | 234 GB | 80 GiB | 최대 20 Gbps |
| GPU-A100-1 | g1v32a2 | 2 | 32 vCore | 468 GB | 160 GiB | Maximum 20 Gbps |
| GPU-A100-1 | g1v64a4 | 4 | 64 vCore | 936 GB | 320 GiB | Up to 40 Gbps |
| GPU-A100-1 | g1v128a8 | 8 | 128 vCore | 1,872 GB | 640 GiB | Maximum 40 Gbps |
| GPU-A100-1-A | g1av16a1 | 1 | 16 vCore | 234 GB | 80 GiB | Maximum 20 Gbps |
| GPU-A100-1-A | g1av32a2 | 2 | 32 vCore | 468 GB | 160 GiB | Maximum 20 Gbps |
| GPU-A100-1-A | g1av64a4 | 4 | 64 vCore | 936 GB | 320 GiB | 최대 40 Gbps |
| GPU-A100-1-A | g1av128a8 | 8 | 128 vCore | 1,872 GB | 640 GiB | 최대 40 Gbps |
Table. GPU Server server type > GPU-A100-1 server type
g2 server type
The g2 server type is a GPU Server that uses the NVIDIA H100 Tensor Core GPU, making it suitable for high-performance applications.
- Up to 8 NVIDIA H100 Tensor Core GPUs provided
- Equipped with 16,896 CUDA cores and 528 Tensor cores per GPU
- Supports up to 96 vCPUs and 1,920 GB of memory
- Maximum networking speed of 40 Gbps
- 900 GB/s GPU and NVIDIA NVSwitch P2P communication
| 구분 | 서버 타입 | GPU | CPU | Memory | GPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| GPU-H100-2 | g2v12h1 | 1 | 12 vCore | 234 GB | 80 GiB | Maximum 20 Gbps |
| GPU-H100-2 | g2v24h2 | 2 | 24 vCore | 468 GB | 160 GiB | Maximum 20 Gbps |
| GPU-H100-2 | g2v48h4 | 4 | 48 vCore | 936 GB | 320 GiB | Maximum 40 Gbps |
| GPU-H100-2 | g2v96h8 | 8 | 96 vCore | 1,872 GB | 640 GiB | Maximum 40 Gbps |
Table. GPU Server server type > GPU-H100-2 server type
g3 server type
The g3 server type is a GPU Server that uses the NVIDIA B300 Tensor Core GPU, making it suitable for high-performance applications.
- Provides up to 8 NVIDIA B300 Tensor Core GPUs
- Equipped with 20,480 CUDA cores and 640 Tensor cores per GPU.
- Supports up to 128 vCPUs and 3,840 GB of memory.
- Up to 40 Gbps networking speed
- 1.8 TB/s GPU and NVIDIA NVSwitch P2P communication
| Category | Server type | GPU | CPU | Memory | GPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| GPU-B300-3 | g3v16b1 | 1 | 16 vCore | 480 GB | 268 GiB | Maximum 20 Gbps |
| GPU-B300-3 | g3v32b2 | 2 | 32 vCore | 960 GB | 536 GiB | Maximum 20 Gbps |
| GPU-B300-3 | g3v64b4 | 4 | 64 vCore | 1,920 GB | 1,072 GiB | Up to 40 Gbps |
| GPU-B300-3 | g3v128b8 | 8 | 128 vCore | 3,840 GB | 2,144 GiB | 최대 40 Gbps |
Table. GPU Server server type > GPU-B300-3 server type
n1 server type
The n1 server type is an NPU Server that uses the Furiosa RNGD NPU, making it suitable for AI inference workloads.
- Provides up to 8 Furiosa RNGD NPUs
- Supports 256 TFLOPS and 512 TFLOPS per NPU
- Supports up to 64 vCPUs and 848 GB of memory
- Maximum networking speed of 40 Gbps
- PCIe Gen5 x16 interface support
| 구분 | 서버타입 | NPU | CPU | Memory | NPU Memory | Network Bandwidth |
|---|---|---|---|---|---|---|
| NPU-RNGD-1 | n1v8r1 | 1 | 8 vCore | 106 GB | 48 GiB | Maximum 20 Gbps |
| NPU-RNGD-1 | n1v16r2 | 2 | 16 vCore | 212 GB | 96 GiB | Maximum 20 Gbps |
| NPU-RNGD-1 | n1v32r4 | 4 | 32 vCore | 424 GB | 192 GiB | Up to 40 Gbps |
| NPU-RNGD-1 | n1v64r8 | 8 | 64 vCore | 848 GB | 384 GiB | Maximum 40 Gbps |
Table. GPU Server server type > NPU-RNGD-1 server type
3.1.2 - Monitoring Metrics
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Accordingly, after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With the new alternative service, you can continuously perform resource monitoring by leveraging ServiceWatch released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a seamless monitoring environment.
If you are collecting metrics and logs through the Cloud Monitoring Agent, you need to switch to the ServiceWatch Agent.
For detailed information about ServiceWatch, please refer to ServiceWatch Overview.
Detailed information about ServiceWatch Agent can be found in the ServiceWatch Agent.
GPU Server Monitoring Metrics
The table below shows the monitoring metrics of the GPU server that can be viewed through Cloud Monitoring.
Even without installing the Agent, it provides basic monitoring metrics and the table below. Please check the GPU Server monitoring metrics (provided by default). Additionally, the metrics that can be viewed by installing the Agent are in the table. Please refer to the additional monitoring metrics for GPU Server (Agent installation required).
For detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
| Performance Item Name | Explanation | unit |
|---|---|---|
| Memory Total [Basic] | bytes of usable memory | bytes |
| Memory Used [Basic] | bytes of currently used memory | bytes |
| Memory Swap In [Basic] | bytes of the replaced memory | bytes |
| Memory Swap Out [Basic] | bytes of the replaced memory | bytes |
| Memory Free [Basic] | bytes of unused memory | bytes |
| Disk Read Bytes [Basic] | Read bytes | bytes |
| Disk Read Requests [Basic] | Number of read requests | cnt |
| Disk Write Bytes [Basic] | write bytes | bytes |
| Disk Write Requests [Basic] | Number of write requests | cnt |
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Instance State [Basic] | Instance status | state |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Dropped [Basic] | Incoming packet drop | cnt |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Dropped [Basic] | Transmit packet drop | cnt |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. GPU Server Basic Monitoring Metrics (Provided by Default)
| Performance Item Name | Explanation | unit |
|---|---|---|
| GPU Count | Number of GPUs | cnt |
| GPU Memory Usage | Memory usage rate | % |
| GPU Memory Used | Memory usage | MB |
| GPU Temperature | GPU temperature | ℃ |
| GPU Usage | utilization | % |
| GPU Usage [Avg] | Overall average GPU utilization (%) | % |
| GPU Power Cap | Maximum power capacity of the GPU | W |
| GPU Power Usage | Current GPU power usage | W |
| GPU Memory Usage [Avg] | GPU Memory Uti. AVG | % |
| GPU Count in use | Number of GPUs in use by jobs on the node | cnt |
| Execution Status for nvidia-smi | Result of running the nvidia-smi command | status |
| Core Usage [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| Core Usage [System] | Proportion of CPU time spent in kernel space | % |
| Core Usage [User] | Proportion of CPU time spent in user space | % |
| CPU Cores | Number of CPU cores on the host | cnt |
| CPU Usage [Active] | Percentage of CPU time used, excluding Idle and IOWait states | % |
| CPU Usage [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage [IO Wait] | The proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage [User] | Percentage of CPU time used in user space. | % |
| CPU Usage/Core [Active] | Percentage of CPU time used other than Idle and IOWait states | % |
| CPU Usage/Core [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage/Core [IO Wait] | This is the proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage/Core [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage/Core [User] | Percentage of CPU time used in user space. | % |
| Disk CPU Usage [IO Request] | Proportion of CPU time during which I/O requests to the device were executed | % |
| Disk Queue Size [Avg] | The average queue length of requests executed for the device. | num |
| Disk Read Bytes | The number of bytes read per second from the device. | bytes |
| Disk Read Bytes [Delta Avg] | Average of system.diskio.read.bytes_delta for individual disks | bytes |
| Disk Read Bytes [Delta Max] | Maximum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Min] | Minimum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Sum] | Sum of the system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta] | Delta of the system.diskio.read.bytes value for each disk | bytes |
| Disk Read Bytes [Success] | Total number of bytes successfully read. | bytes |
| Disk Read Requests | Number of read requests to the disk device per second | cnt |
| Disk Read Requests [Delta Avg] | Average of the system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Max] | Maximum system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Min] | Minimum of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Sum] | Sum of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Success Delta] | Delta of system.diskio.read.count for each disk | cnt |
| Disk Read Requests [Success] | Total number of successful reads | cnt |
| Disk Request Size [Avg] | The average size of requests executed on the device (unit: sectors). | num |
| Disk Service Time [Avg] | Average service time (milliseconds) of input requests executed on the device. | ms |
| Disk Wait Time [Avg] | Average time taken for requests executed on the supported device. | ms |
| Disk Wait Time [Read] | Average disk wait time | ms |
| Disk Wait Time [Write] | Average disk wait time | ms |
| Disk Write Bytes [Delta Avg] | Average of system.diskio.write.bytes_delta for each disk | bytes |
| Disk Write Bytes [Delta Max] | Maximum system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta Min] | Minimum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta Sum] | Sum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta] | Delta of the system.diskio.write.bytes value for each disk | bytes |
| Disk Write Bytes [Success] | Total number of bytes successfully written. | bytes |
| Disk Write Requests | Number of write requests to the disk device per second | cnt |
| Disk Write Requests [Delta Avg] | Average of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Max] | Maximum system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Min] | Minimum of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Sum] | Sum of the system.diskio.write.count_delta of individual disks | cnt |
| Disk Write Requests [Success Delta] | Delta of system.diskio.write.count for each disk | cnt |
| Disk Write Requests [Success] | Total number of successful writes | cnt |
| Disk Writes Bytes | It is the number of bytes per second written to the device. | bytes |
| Filesystem Hang Check | filesystem (local/NFS) hang check (normal:1, abnormal:0) | status |
| Filesystem Nodes | It is the total number of file nodes in the file system. | cnt |
| Filesystem Nodes [Free] | It is the total number of available file nodes in the file system. | cnt |
| Filesystem Size [Available] | Disk space (bytes) available to unauthorized users | bytes |
| Filesystem Size [Free] | Available disk space (bytes) | bytes |
| Filesystem Size [Total] | Total disk space (bytes) | bytes |
| Filesystem Usage | Used disk space percentage | % |
| Filesystem Usage [Avg] | Average of individual filesystem.used.pct values | % |
| Filesystem Usage [Inode] | inode usage | % |
| Filesystem Usage [Max] | Maximum among individual filesystem.used.pct | % |
| Filesystem Usage [Min] | minimum among individual filesystem.used.pct | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | Used disk space (bytes) | bytes |
| Filesystem Used [Inode] | inode usage | bytes |
| Memory Free | Total amount of available memory (bytes). | bytes |
| Memory Free [Actual] | Actual usable memory (bytes). | bytes |
| Memory Free [Swap] | Available swap memory. | bytes |
| Memory Total | total memory | bytes |
| Memory Total [Swap] | Total swap memory. | bytes |
| Memory Usage | Percentage of used memory | % |
| Memory Usage [Actual] | Percentage of memory actually used | % |
| Memory Usage [Cache Swap] | cached swap usage rate | % |
| Memory Usage [Swap] | Percentage of used swap memory | % |
| Memory Used | used memory | bytes |
| Memory Used [Actual] | Actual memory used (bytes). | bytes |
| Memory Used [Swap] | Swap memory used. | bytes |
| Collisions | Network collision | cnt |
| Network In Bytes | Number of received bytes | bytes |
| Network In Bytes [Delta Avg] | Average of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta Max] | Maximum of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Min] | Minimum system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Sum] | Sum of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta] | Delta of received byte count | bytes |
| Network In Dropped | Number of deleted packets among incoming packets | cnt |
| Network In Errors | Number of errors during reception | cnt |
| Network In Packets | Number of received packets | cnt |
| Network In Packets [Delta Avg] | Average of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Max] | Maximum of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Min] | Minimum of system.network.in.packets_delta for individual networks | cnt |
| Network In Packets [Delta Sum] | Sum of system.network.in.packets_delta for individual networks | cnt |
| Network In Packets [Delta] | Delta of received packet count | cnt |
| Network Out Bytes | Number of transmitted bytes | bytes |
| Network Out Bytes [Delta Avg] | Average of system.network.out.bytes_delta for each network | bytes |
| Network Out Bytes [Delta Max] | Maximum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Min] | Minimum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Sum] | Sum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta] | Delta of transmitted byte count | bytes |
| Network Out Dropped | Number of deleted packets among outgoing packets. | cnt |
| Network Out Errors | Number of errors during transmission | cnt |
| Network Out Packets | Number of transmitted packets | cnt |
| Network Out Packets [Delta Avg] | Average of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Max] | Maximum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Min] | Minimum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Sum] | Sum of system.network.out.packets_delta for individual networks | cnt |
| Network Out Packets [Delta] | Delta of transmitted packet count | cnt |
| Open Connections [TCP] | All open TCP connections | cnt |
| Open Connections [UDP] | All open UDP connections | cnt |
| Port Usage | Available port usage rate | % |
| SYN Sent Sockets | Number of sockets in SYN_SENT state (when connecting from local to remote) | cnt |
| Kernel PID Max | kernel.pid_max value | cnt |
| Kernel Thread Max | kernel.threads-max value | cnt |
| Process CPU Usage | Percentage of CPU time consumed by the process since the last update. | % |
| Process CPU Usage/Core | Percentage of CPU time used by the process since the last event. | % |
| Process Memory Usage | Proportion of main memory (RAM) occupied by a process | % |
| Process Memory Used | Resident Set size. The amount of memory a process occupies in RAM. | bytes |
| Process PID | process pid | PID |
| Process PPID | parent process PID | PID |
| Processes [Dead] | Number of dead processes | cnt |
| Processes [Idle] | Number of idle processes | cnt |
| Processes [Running] | Number of running processes | cnt |
| Processes [Sleeping] | Number of sleeping processes | cnt |
| Processes [Stopped] | stopped processes count | cnt |
| Processes [Total] | Total number of processes | cnt |
| Processes [Unknown] | Number of processes with an unsearchable or unknown status | cnt |
| Processes [Zombie] | Zombie processes count | cnt |
| Running Process Usage | process usage rate | % |
| Running Processes | Number of running processes | cnt |
| Running Thread Usage | Thread usage rate | % |
| Running Threads | Total number of threads running in running processes | cnt |
| Context Switches | context switch count (per second) | cnt |
| Load/Core [1 min] | The load over the last 1 minute divided by the number of cores | cnt |
| Load/Core [15 min] | The load over the last 15 minutes divided by the number of cores | cnt |
| Load/Core [5 min] | The load over the last 5 minutes divided by the number of cores | cnt |
| Multipaths [Active] | External storage connection path status = active count | cnt |
| Multipaths [Failed] | External storage connection path status = failed count | cnt |
| Multipaths [Faulty] | External storage connection path status = faulty count | cnt |
| NTP Offset | measured offset of the last sample (the time difference between the NTP server and the local environment) | num |
| Run Queue Length | Execution queue length | num |
| Uptime | OS uptime (milliseconds). | ms |
| Context Switchies | CPU context switch count (per second) | cnt |
| Disk Read Bytes [Sec] | Number of bytes read from a Windows logical disk in 1 second | cnt |
| Disk Read Time [Avg] | Average data read time (seconds) | sec |
| Disk Transfer Time [Avg] | Disk average wait time | sec |
| Disk Usage | Disk usage | % |
| Disk Write Bytes [Sec] | Number of bytes written in one second on a Windows logical disk | cnt |
| Disk Write Time [Avg] | Average data write time (seconds) | sec |
| Pagingfile Usage | Paging file usage | % |
| Pool Used [Non Paged] | Nonpaged Pool usage in kernel memory | bytes |
| Pool Used [Paged] | Paged Pool usage in kernel memory | bytes |
| Process [Running] | Number of currently running processes | cnt |
| Threads [Running] | Number of currently running threads | cnt |
| Threads [Waiting] | Number of threads waiting for processor time | cnt |
Table. Additional monitoring metrics for GPU Server (Agent installation required)
3.1.3 - ServiceWatch Metrics
The GPU Server sends metrics to ServiceWatch. The metrics provided by default monitoring are data collected at 5‑minute intervals. If detailed monitoring is enabled, you can view data collected at 1‑minute intervals.
information
- The basic and detailed monitoring of the GPU Server are provided with the same metrics as the Virtual Server, and the namespace is also provided as Virtual Server.
- GPU-related metrics are provided through ServiceWatch Agent, and for instructions on collecting metrics using ServiceWatch Agent, refer to the ServiceWatch Agent guide.
Reference
For how to view metrics in ServiceWatch, refer to the ServiceWatch guide.
Refer to How-to guides > ServiceWatch Detailed Monitoring Activation for how to enable detailed monitoring of the GPU Server.
Basic Metrics
The following are the basic metrics for the Virtual Server namespace.
The indicators whose names are displayed in bold below are the key indicators selected among the basic indicators provided by Virtual Server. The key metrics are used to build service dashboards that are automatically created for each service in ServiceWatch.
Each metric indicates through the user guide which statistical value is meaningful to view for that metric, and among the meaningful statistics, the statistical values shown in bold text are the primary statistics. In the service dashboard, you can view primary metrics using the primary statistical values.
| Performance items | Detailed description | unit | meaningful statistics |
|---|---|---|---|
| Instance State | Instance status display
| None |
|
| CPU Usage | CPU usage | Percent |
|
| Disk Read Bytes | Bytes read from block device (bytes) | Bytes |
|
| Disk Read Requests | Number of read requests on a block device | Count |
|
| Disk Write Bytes | Write capacity (bytes) on block device | Bytes |
|
| Disk Write Requests | Number of write requests on block device | Count |
|
| Network In Bytes | Received bytes (capacity) on the network interface | Bytes |
|
| Network In Dropped | Number of packet drops received on the network interface | Count |
|
| Network In Packets | Number of packets received on the network interface | Count |
|
| Network Out Bytes | Data transmitted on the network interface (bytes) | Bytes |
|
| Network Out Dropped | Number of packet drops transmitted from the network interface | Count |
|
| Network Out Packets | Number of packets transmitted on the network interface | Count |
|
Table. Virtual Server Basic Metrics
3.2 - How-to guides
Users can create the service by entering the required GPU Server information and selecting detailed options through the Samsung Cloud Platform Console.
Create GPU Server
You can create and use a GPU Server service from the Samsung Cloud Platform Console.
To create a GPU Server, follow these steps.
Click the All Services > Compute > GPU Server menu. 1. Navigate to the Service Home page of the GPU Server.
On the Service Home page, click the Create GPU Server button. 2. GPU Server Creation Go to the page.
GPU Server Creation page, input the information required to create the service, and select detailed options.
- Select the required information in the Image and Version Selection area.
Category required statusDetailed description Image Required Select the provided Image type - Standard: Samsung Cloud Platform standard Image
- RHEL, Ubuntu
- Custom: User-created Image
- Kubernetes: Kubernetes Image
- Ubuntu
Image version Required Select the version of the chosen Image - Provide a list of versions for the offered server Image
- For detailed information about the provided server image, refer to OS 및 GPU 드라이버 버전
Table. GPU Server image and version selection input fields - Standard: Samsung Cloud Platform standard Image
- Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Number of servers Required Number of GPU Server instances to create concurrently - only numeric input allowed, enter a value between 1 ~ 100
Service Type > Server Type Required GPU Server server type - Indicates the specifications of a GPU-type server, and select a server that includes 1, 2, 4, or 8 GPUs
- For detailed information about the server types offered by GPU Server, refer to GPU Server 서버 타입
Service Type > Planned Compute Selection Status of resources with Planned Compute configured - In Use: Number of resources with Planned Compute that are currently in use
- Configured: Number of resources with Planned Compute configured
- Coverage preview: Amount applied per resource by Planned Compute
- Apply for Planned Compute service: Navigate to the Planned Compute service application page
- For more details, see Planned Compute 신청하기
Block Storage Required Set the Block Storage used by the GPU Server according to its purpose - Default: Area where the OS is installed and used
- Capacity can be entered in Unit increments (minimum capacity varies by OS image type)
- RHEL: values between 3 and 1,536 are allowed
- Ubuntu: values between 3 and 1,536 are allowed
- SSD: high‑performance general volume
- HDD: general volume
- SSD/HDD_KMS: additional encrypted volume that uses Samsung Cloud Platform KMS (Key Management System) encryption keys
- Encryption can be applied only at initial creation (cannot be changed after creation)
- Performance degradation may occur when using the SSD_KMS disk type
- SSD_Provisioned: SSD volume with configurable IOPS and Throughput
- Capacity can be entered in Unit increments (minimum capacity varies by OS image type)
- Additional: used when extra space beyond the OS area is needed
- After selecting Use, enter the storage type and capacity
- To add storage, click the + button (up to 25 can be added); to delete, click the x button
- Capacity can be entered as a value between 1 and 1,536 in Unit increments
- Since 1 Unit equals 8 GB, 8 ~ 12,288 GB can be created
- SSD: high‑performance general volume
- HDD: general volume
- SSD/HDD_KMS: additional encrypted volume that uses Samsung Cloud Platform KMS (Key Management System) encryption keys
- Encryption can be applied only at initial creation (cannot be changed after creation)
- Performance degradation may occur when using the SSD_KMS disk type
- HDD/SSD_MultiAttach: volume that can be attached to two or more servers
- SSD_Provisioned: SSD volume with configurable IOPS and Throughput
- For details on each Block Storage type, see Block Storage 생성하기
- Delete on termination: If Delete on Termination is set to Use, the volume will be terminated together with the server
- Volumes that have snapshots are not deleted even when Delete on termination is set to Use
- A multi‑attach volume can be deleted only when the server being removed is the last remaining server attached to the volume
Max IOPS Required Enter the maximum IOPS value between 5,000 and 20,000 - Disk type can be set only if it is SSD_Provisioned
Max Throughput Required Enter the maximum Throughput value between 250~1,000 - Can be set only when the disk type is SSD_Provisioned
Table. GPU Server Service Configuration Items - In the Required Information Input area, enter or select the required information.
Category required statusDetailed description Server name Required If the number of selected servers is 1, enter a name to distinguish the server - Set the hostname to the entered server name
- Enter within 63 characters using English letters, numbers, spaces, and special characters (
-_)
Server name Prefix Required Enter a Prefix to distinguish each server generated when the selected number of servers is 2 or more - Automatically generated as the user input value (prefix) + ‘
-#’ format
- Enter within 59 characters using English letters, numbers, spaces, and special characters (
-,_)
Network Settings > Create New Network Port Required Set the network where the GPU Server will be installed - Select a pre-created VPC.
- General Subnet: Select a pre-created general Subnet
- IP can be set to auto-generate or user input, and if input is selected, the user can directly enter the IP
- NAT: Available only when there is a single server and the VPC is connected to an Internet Gateway. Checking Use allows selection of a NAT IP
- NAT IP: Select a NAT IP
- If there is no NAT IP to select, click the Create New button to generate a Public IP
- Refresh button to view and select the created Public IP
- Creating a Public IP incurs charges according to the Public IP pricing policy
- Local Subnet (optional): Select Use for the local Subnet
- It is not a required element for creating the service
- A pre-created local Subnet must be selected
- IP can be set to auto-generate or user input, and selecting Input allows the user to directly enter the IP
Network Settings > Assign Existing Network Port Required Set the network where the GPU Server will be installed - Select a pre‑created VPC
- General Subnet: Select a pre‑created general Subnet and Port
- NAT: Available only when there is a single server and the VPC is connected to an Internet Gateway; checking the option allows you to select a NAT IP.
- NAT IP: Select a NAT IP
- If no NAT IP is available to select, click the Create New button to generate a Public IP
- Refresh button to view and select the created Public IP
- Local Subnet (Optional): Select Use for the local Subnet
- Select a pre‑created local Subnet and Port
Security Group Selection Settings required to connect to the server - Selection: You can select up to 5 pre‑created Security Groups
- Create New: If there is no Security Group to apply, create one separately in the Security Group service
- If you do not configure a Security Group, all connections will be blocked, so you must set it to allow required access
Keypair Required User authentication method to use when connecting to the server - New creation: Create a new one when a new Keypair is required
- Refer to Keypair 생성하기
- Default login account list by OS
- RHEL: cloud-user
- Ubuntu: ubuntu
Table. GPU Server required information input items - Additional Information Input area, enter or select the required information.
Category required statusDetailed description Lock Selection Lock usage setting - When using Lock, it prevents actions such as server termination, start, and stop from being executed, thereby avoiding malfunctions caused by mistakes
Init script Selection Script executed when the server starts - The init script must be written as a Batch script for Windows, a Shell script for Linux, or cloud‑init, depending on the image type.
- Up to 45,000 bytes can be entered
tag Selection Add Tag - Up to 50 per resource can be added
- After clicking the Add Tag button, enter or select Key, Value values
Table. GPU Server Additional Information Input Items
- Select the required information in the Image and Version Selection area.
Summary Check the detailed information and estimated charges generated in the panel, and click the Create button.
When the popup notifying creation opens, click the Confirm button.
- Once creation is complete, check the created resources on the GPU Server List page.
Check GPU Server detailed information
The GPU Server service allows you to view and edit the full resource list and detailed information. The GPU Server Details page consists of Details, Tags, Activity Log tabs. To view detailed information about the GPU Server service, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- GPU Server List page, click the resource to view detailed information. 3. Navigate to the GPU Server Details page.
- GPU Server Details page displays status information and additional feature information, and consists of Details, Tags, Activity History tabs.
- For detailed information about GPU Server Additional Features, please refer to GPU Server 관리 부가 기능.
Category Detailed description GPU Server status Status of the GPU Server created by the user - Build: State where the Build command has been received
- Building: Build in progress
- Networking: Server creation process in progress
- Scheduling: Server creation process in progress
- Block_Device_Mapping: Connecting Block Storage during server creation
- Spawning: State where the server creation process is ongoing
- Active: Available state
- Powering_off: State when a stop request is made
- Deleting: Server deletion in progress
- Reboot_Started: Reboot in progress state
- Error: Error state
- Migrating: State where the server is migrating to another host
- Reboot: State where the Reboot command has been received
- Rebooting: Reboot in progress
- Rebuild: State where the Rebuild command has been received
- Rebuilding: State when a Rebuild request is made
- Rebuild_Spawning: State where the Rebuild process is ongoing
- Shutoff: State when Powering off is completed
Server control Buttons to change server status - Start: Start a stopped server
- Stop: Stop a running server
- Restart: Restart a running server
Image generation Create a user custom image from the current server’s image Console log View the console log of the current server - You can view the console logs output by the current server. For more details, see 콘솔 로그 확인하기.
Create dump Create a dump of the current server - The dump file is created inside the GPU Server
- For detailed dump creation instructions, see Dump 생성하기
Rebuild All data and settings of the existing server are deleted, and a new server is set up - For details, see Rebuild 수행하기.
Service cancellation Cancel service button Table. GPU Server status information and additional features
Notice
When using the mig feature, you must recheck the mig settings after the GPU Server’s Rebooting state has finished.
Detailed Information
GPU Server List page allows you to view detailed information of the selected resource and, if needed, modify the information.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Server name | server name |
| Server type | Display vCPU, memory, GPU information
|
| Image name | OS image and version of the service |
| Lock | Display lock usage status
|
| Keypair name | User-configured server authentication information |
| Planned Compute | Resource status with Planned Compute configured
|
| LLM Endpoint | URL for using LLM |
| ServiceWatch detailed monitoring | When enabled, data monitoring is available in the ServiceWatch service
|
| Network | Network information of the GPU Server
|
| Local Subnet | Local Subnet information of GPU Server
|
| Block Storage | Information of Block Storage attached to the server
|
Table. GPU Server Detailed Information Tab Items
Caution
When using ServiceWatch Detailed Monitoring, additional charges will apply.
Tag
GPU Server list page allows you to view the tag information of the selected resource, and to add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. GPU Server tag tab items
Job History
GPU Server List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource change history
|
Table. Work History Tab Detailed Information Items
Control GPU Server Operation
If you need to control the operation of the created GPU Server resources, you can perform the task from the GPU Server List or GPU Server Details page. You can start, stop, or restart a running server.
Getting Started with GPU Server
You can start a GPU server that is shut off. To start the GPU Server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- GPU Server List page, click the resource to start among the shutoff servers, and navigate to the GPU Server Details page.
- On the GPU Server list page, you can start each resource via the right More button.
- After selecting multiple servers with the checkboxes, you can control multiple servers simultaneously using the Start button at the top.
- On the GPU Server Details page, click the Start button at the top to start the server. 4. In the Status Indicator item, check the status of the changed server.
- When the GPU Server startup is complete, the server status changes from Shutoff to Active.
- For detailed information about the GPU Server status, please refer to GPU Server 상세 정보 확인하기.
Stop GPU Server
You can stop a GPU Server that is running (Active). To stop the GPU Server, follow the steps below.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server List page, click the resource to stop among the servers that are active (Active), and go to the GPU Server Details page.
- On the GPU Server List page, you can stop each resource using the right More button.
- After selecting multiple servers with the checkboxes, you can control multiple servers simultaneously using the Stop button at the top.
- On the GPU Server Details page, click the Stop button at the top to start the server. 4. Check the status of the changed server in the Status Indicator item.
- When the GPU Server shutdown is complete, the server status changes from Active to Shutoff.
- For detailed information about the GPU Server status, refer to GPU Server 상세 정보 확인하기.
Restart GPU Server
You can restart the created GPU Server. To restart the GPU server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- GPU Server List page, click the resource to restart, and navigate to the GPU Server Details page.
- On the GPU Server List page, you can restart each resource through the right More button.
- After selecting multiple servers with the checkboxes, you can control multiple servers simultaneously using the Restart button at the top.
- On the GPU Server Details page, click the Restart button at the top to start the server. 4. Check the status of the changed server in the Status Indicator item.
- During a GPU Server restart, the server status goes through Rebooting and finally changes to Active.
- For detailed information about the GPU Server status, please refer to GPU Server 상세 정보 확인하기.
GPU Server Resource Management
If you need server control and management functions for the created GPU Server resources, you can perform tasks on the GPU Server Resource List or GPU Server Details page.
Create Image
You can create an image of a running GPU server.
Reference
This document provides instructions on how to create a user custom image from the image of a running GPU server.
- GPU Server List or GPU Server Details page, click the Create Image button to generate a user Custom Image.
To create an Image of the GPU Server, follow the steps below.
All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
On the GPU Server List page, click the resource to create an Image. 3. Navigate to the GPU Server Details page.
On the GPU Server Details page, click the Create Image button. 4. Navigate to the Image creation page.
- Enter the required information in the Service Information Input area.
Category required statusDetailed description Image name Required Name of the image to be created - English letters, numbers, spaces, and special characters(
-_) using them, enter within 200 characters
Table. Image service information input items - English letters, numbers, spaces, and special characters(
- Enter the required information in the Service Information Input area.
Check the input information and click the Generate button.
- Once creation is complete, check the created resources on the All Services > Compute > GPU Server > Image List page.
Notice
- When an Image is created, the generated Image is stored in the Object Storage used as internal storage. * Therefore, a Object Storage usage fee is charged for Image storage.
- Since the file system of an image generated from an active GPU server cannot be guaranteed to be intact, it is recommended to stop the server before creating the image.
Enable detailed monitoring for ServiceWatch
By default, the GPU Server is linked to the basic monitoring of the ServiceWatch and Virtual Server namespaces. You can enable detailed monitoring as needed to more quickly identify operational issues and take action. For detailed information about ServiceWatch, refer to the ServiceWatch 개요.
Reference
GPU Server provides basic and detailed monitoring in the same namespace as Virtual Server.
GPU Server’s GPU metrics will be provided by the ServiceWatch Agent. (Scheduled for December 2025)
Caution
Basic monitoring is provided for free, but enabling detailed monitoring incurs additional charges. Please note the usage.
To enable detailed ServiceWatch monitoring on the GPU Server, follow these steps.
- All Services > Compute > GPU Server menu, click it. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server list page, click the resource to enable detailed ServiceWatch monitoring. 3. Navigate to the GPU Server Details page.
- On the GPU Server Details page, click the Edit button for ServiceWatch detailed monitoring. 4. ServiceWatch Detailed Monitoring Edit Navigate to the popup window.
- ServiceWatch Detailed Monitoring Edit In the popup window, after selecting Enable, review the instructions and click the Confirm button.
- Check the ServiceWatch detailed monitoring items on the GPU Server Details page.
Disable detailed monitoring of ServiceWatch
Caution
Disabling detailed monitoring is required for cost efficiency. Maintain detailed monitoring only when absolutely necessary, and disable detailed monitoring otherwise.
To disable detailed monitoring of ServiceWatch on the GPU Server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Go to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server List page, click the resource to disable ServiceWatch detailed monitoring. 3. Navigate to the GPU Server Details page.
- GPU Server Details page, click the Edit button for ServiceWatch detailed monitoring. 4. ServiceWatch Detailed Monitoring Edit Navigate to the popup window.
- ServiceWatch Detailed Monitoring Edit In the popup window, after deselecting Enable, review the guidance message and click the Confirm button.
- Check the detailed ServiceWatch monitoring items on the GPU Server Details page.
GPU Server management additional features
For managing the GPU Server, you can view Console logs, generate Dumps, and perform Rebuilds. To view the Console logs, create a Dump, and perform a Rebuild on the GPU Server, follow these steps.
Check console log
You can view the current console log of the GPU Server.
To check the console log of the GPU Server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server List page, click the resource to view the console log. 3. Navigate to the GPU Server Details page.
- On the GPU Server Details page, click the Console Log button. 4. Console Log navigates to the popup window.
- Console Log Check the console log displayed in the popup window.
Create Dump
To create a dump file on the GPU Server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- GPU Server List page, click the resource to view detailed information. 3. Navigate to the GPU Server Details page.
- On the GPU Server Details page, click the Generate Dump button.
- The dump file is created inside the GPU server.
Execute Rebuild
You can delete all data and settings of the existing GPU Server and rebuild it on a new server.
To perform a Rebuild of the GPU Server, follow these steps.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server List page, click the resource to perform Rebuild. 3. Navigate to the GPU Server Details page.
- On the GPU Server Details page, click the Rebuild button.
- During a GPU Server Rebuild, the server status changes to Rebuilding, and when the Rebuild is complete, it returns to the state it was in before the Rebuild.
- For detailed information about the GPU Server status, please refer to GPU Server 상세 정보 확인하기.
Terminate GPU Server
If you terminate an unused GPU server, you can reduce operating costs. However, if you terminate the GPU server, the running service may be stopped immediately, so you should proceed with the termination only after fully considering the impact of service interruption.
Caution
Please be aware that data cannot be recovered after terminating the service.
To cancel the GPU Server, follow the steps below.
- All Services > Compute > GPU Server Click the menu. 1. Navigate to the Service Home page of the GPU Server.
- Click the GPU Server menu on the Service Home page. 2. GPU Server List Go to the page.
- On the GPU Server List page, select the resource to cancel, and click the Cancel Service button.
- The termination of attached storage depends on the Delete on termination setting, so refer to 해지 제약 사항.
- When termination is complete, check on the GPU Server List page whether the resources have been terminated.
Termination constraints
When a GPU Server termination request cannot be processed, a popup will provide guidance. Please refer to the case below.
Cancellation not possible
- When an LB server group is attached: Terminate the attached LB server group first.
- If Lock is set: Please change the Lock setting to disabled and try again.
The termination of attached storage depends on the Delete on termination setting.
Delete on termination per setting
- Whether the volume is deleted also varies depending on the Delete on termination setting.
- Delete on termination When not set: Even if you terminate the GPU Server, the volume will not be deleted.
- Delete on termination When enabled: terminating the GPU Server will delete the associated volume.
- Volumes that have a snapshot will not be deleted even if Delete on termination is set.
- A multi-attach volume can be deleted only when the server being deleted is the last remaining server attached to the volume.
3.2.1 - Manage Image
Users can create the service by entering the required information for the Image service within the GPU Server service and selecting detailed options through the Samsung Cloud Platform Console.
Create Image
You can create an image of a running GPU Server. To create an image of a GPU Server, please refer to Image Creation.
Check Image detailed information
Image service allows you to view and edit the full resource list and detailed information. The Image Details page consists of Detailed Information, Tags, Operation History tabs.
To view detailed information of the Image service, follow these steps.
- Click the All Services > Compute > GPU Server menu. You will be taken to the Service Home page of GPU Server.
- On the Service Home page, click the Image menu. You will be taken to the Image list page.
- On the Image List page, click the resource to view detailed information. You will be taken to the Image Detail page.
- Image Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Category Detailed description Image status Status of user-created Image - Active: Available state
- Queued: Image has been uploaded and is waiting for processing after creation
- Importing: Image has been uploaded and is currently being processed after creation
Share with another account Image can be shared with another Account - The Image’s Visibility must be set to Shared in order to be shared with another Account
Delete image Button to delete the Image - Once the Image is deleted, it cannot be restored
Table. GPU Server Image status information and additional features
- Image Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Detailed Information
Image list page lets you view detailed information of the selected resource and modify it if necessary.
| Category | Detailed description |
|---|---|
| service | Service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Image name |
| Resource ID | Image ID |
| constructor | User who created the Image |
| Creation date and time | Image creation timestamp |
| editor | User who edited the Image |
| Modification date | Image modification timestamp |
| image name | Image name |
| Minimum disk | Minimum disk capacity (GB) of the Image
|
| Minimum RAM | Minimum RAM size (GB) of the Image |
| OS type | OS type of the image |
| OS hash algorithm | OS hash algorithm method |
| Visibility | Display access permissions for the image
|
| Protected | Select whether image deletion is prohibited
|
| image file URL | Image file URL uploaded when generating an image
|
| Sharing status | Current status of sharing images with another Account
|
Table. Image detailed information tab items
tag
On the Image List page, you can view the tag information of the selected resource and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Image tag tab items
Job History
You can view the operation history of the selected resource on the Image List page.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. GPU Server Image Job History Tab Detailed Information Items
Image Resource Management
Describes the control and management functions of the generated Image.
Share to another Account
To share an Image with another Account, follow the steps below.
- Log in to the account to be shared and click the All Services > Compute > GPU Server menu. Go to the GPU Server’s Service Home page.
- On the Service Home page, click the Image menu. You will be taken to the Image List page.
- On the Image List page, click the Image you want to control. You will be taken to the Image Details page.
- Click the Share to another Account button. Navigate to the Share image to another Account page.
- Share with another Account feature allows you to share an Image with another Account. To share an Image with another Account, the Image’s Visibility must be Shared.
- Share image to another Account page, enter the required information, and click the Done button.
Category RequiredDetailed description image name - Name of the image to share - Input not allowed
Image ID - Shareable image ID - Input not allowed
Shared Account ID Required Enter another Account ID to share - English letters, numbers, special characters
-within 64 characters
Table. Required input fields for sharing images to another Account - You can view the information in the sharing status of the Image Details page.
- When the request is first made, the status is Pending, and it changes to Accepted once approval is completed by the account receiving the share.
Notice
Only images created by uploading an image file from the current user can be shared with another Account. If you create a Custom Image from the image of a running GPU Server, it cannot be shared with another Account, and this feature will be provided in the future, so please note.
Receive sharing from another Account
To receive an Image shared from another Account, follow these steps.
- Log in to the account to be shared and click the All Services > Compute > GPU Server menu. Navigate to the GPU Server’s Service Home page.
- On the Service Home page, click the Image menu. You will be taken to the Image List page.
- On the Image List page, click the Receive Image Share button. You will be taken to the Receive Image Share popup.
- Receive Image Sharing In the popup window, enter the Image’s resource ID you want to receive, and click the Confirm button.
- When image sharing is complete, you can view the shared Image in the Image list.
Delete Image
You can delete unused Images. However, since an Image cannot be recovered after deletion, you should carefully consider the impact before performing the deletion.
Caution
Please note that data cannot be recovered after deleting the service.
To delete the Image, follow these steps.
- Click the All Services > Compute > GPU Server menu. Go to the GPU Server’s Service Home page.
- On the Service Home page, click the Image menu. You will be taken to the Image List page.
- Image list page, select the resource to delete, and click the Delete button.
- On the Image List page, select multiple Image check boxes and click the Delete button at the top of the resource list.
- After deletion is complete, verify on the Image list page that the resource has been removed.
3.2.2 - Manage Keypair
Users can create the service by entering the required Keypair information within the GPU Server service and selecting detailed options through the Samsung Cloud Platform Console.
Create a Keypair
You can create and use the Keypair service while using the GPU Server service in the Samsung Cloud Platform Console.
To create a keypair, follow these steps.
- Click the All Services > Compute > GPU Server menu. You will be taken to the Service Home page of GPU Server.
- On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
- On the Keypair List page, click the Keypair Create button. You will be taken to the Keypair Create page.
- Enter the required information in the Service Information Input area.
Category RequiredDetailed description Keypair name Required Enter the name of the Keypair to create - using English letters, numbers, spaces, and special characters (
-,_) within 255 characters
Keypair type Required ssh Table. Keypair service information input fields - using English letters, numbers, spaces, and special characters (
- Additional Information Input area, please enter or select the required information.
Category Required statusDetailed description tag Selection Add Tag - Up to 50 can be added per resource
- After clicking the Add Tag button, enter or select Key, Value values
Table. Keypair additional information input fieldsCaution- After creation is complete, you can download the Key only once. Since reissuance is not possible, make sure it has been downloaded.
- Store the downloaded Private Key in a safe place.
- Enter the required information in the Service Information Input area.
- Check the input information and click the Create button.
- After creation is complete, check the created resources on the Keypair List page.
View detailed information of the Keypair
The Keypair service allows you to view and edit the full resource list and detailed information. Keypair Details page consists of Details, Tags, Activity Log tabs.
To view detailed information about a keypair, follow these steps.
- Click the All Services > Compute > GPU Server menu. You will be taken to the Service Home page of GPU Server.
- On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
- On the Keypair List page, click the resource to view its details. You will be taken to the Keypair Details page.
- Keypair Details page displays status information and additional feature information, and consists of Details, Tags, Activity Log tabs.
Detailed Information
Keypair List page allows you to view detailed information of the selected resource and edit the information if needed.
| Category | Detailed description |
|---|---|
| service | Service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Keypair name |
| Resource ID | Keypair’s unique resource ID |
| constructor | User who created the keypair |
| Creation date and time | Keypair creation timestamp |
| editor | User who modified the keypair information |
| Modification date | Date and time the keypair information was modified |
| Keypair name | Keypair name |
| Fingerprint | A unique value for identifying the key |
| User ID | User ID of the keypair creator |
| public key | Public key information |
Table. Keypair detailed information tab items
tag
On the Keypair List page, you can view the tag information of the selected resource, and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Keypair Tag Tab Items
Job History
On the Keypair List page, you can view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Keypair operation history tab detailed information items
Keypair Resource Management
Describes the control and management functions of a keypair.
Get public key
To retrieve the public key, follow these steps.
Click the All Services > Compute > GPU Server menu. You will be taken to the Service Home page of GPU Server.
On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
On the Keypair List page, click the More button at the top and then click the Import Public Key button. You will be taken to the Import Public Key page.
- Enter or select the required information in the Required Information Input area.
Category RequiredDetailed description Keypair name Required Name of the Keypair to create Keypair type Required ssh public key Required Enter public key - Load file: Select the Attach file button to attach the public key file
- Only files with the following extension (.pem) can be attached
- Enter public key: Paste the copied public key value
- The public key value can be copied from the Keypair Details page
Table. Required input fields for retrieving the public key - Load file: Select the Attach file button to attach the public key file
- Enter or select the required information in the Required Information Input area.
Review the entered information and click the Complete button.
- Once creation is complete, check the created resources on the Keypair List page.
Delete Keypair
You can delete unused Keypairs. However, once a Keypair is deleted it cannot be recovered, so please review the impact thoroughly beforehand before proceeding with deletion.
Caution
Please note that data cannot be recovered after deleting the service.
To delete a keypair, follow these steps.
- Click the All Services > Compute > GPU Server menu. Go to the Service Home page of GPU Server.
- On the Service Home page, click the Keypair menu. You will be taken to the Keypair List page.
- On the Keypair List page, select the resource to delete, and click the Delete button.
- On the Keypair List page, select multiple Keypair check boxes and click the Delete button at the top of the resource list.
- After deletion is complete, check the Keypair List page to confirm that the resource has been removed.
3.2.3 - Use Multi-instance GPU on GPU Server
After creating a GPU Server, you can enable the MIG (Multi-instance GPU) feature on the GPU Server’s VM (Guest OS) and create an instance for use.
NVIDIA Multi-instance GPU Introduction
NVIDIA Multi-instance GPU (hereafter referred to as MIG) supports safely partitioning a GPU into GPU instances and running CUDA applications starting with the NVIDIA Ampere architecture. Through this, multiple users can each utilize different GPU resources to achieve optimal GPU utilization. This feature is especially useful for workloads that do not fully utilize the GPU’s computing capacity, and users can run multiple workloads in parallel to maximize utilization.
Using Multi-instance GPU feature
To use the MIG feature, create an NVIDIA GPU Server on the Samsung Cloud Platform, then enable and disable MIG. The order of applying and removing MIG is as follows.
MIG application order
Enable MIG → Create GPU Instance → Create Compute Instance → Use MIG
MIG release order
Delete Compute Instance → Delete GPU Instance → Disable MIG feature (deactivate)
Reference
- MIG can be used on Samsung Cloud Platform’s next-generation GPU Server or MNGC (Multi-node GPU Cluster).
- For system requirements to use MIG, refer to the NVIDIA Multi-Instance GPU User Guide.
Applying and Using MIG
After activating the MIG and creating an Instance to assign tasks, the tasks proceed in the following order.
MIG application order
Enable MIG → Create GPU Instance → Create Compute Instance → Use MIG
Note
The example of applying MIG is explained based on an A100 GPU server.
Activate MIG
Check the GPU status on the VM Instance (GuestOS) before applying MIG.
- Check whether MIG mode is Disabled.Color mode
$ nvidia-smi Mon Sep 27 08:37:08 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 08:37:08 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+Code block. nvidia-smi command - Check GPU disabled status (1) Color mode$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)Code block. nvidia-smi command - Check GPU disabled status (2)
- Check whether MIG mode is Disabled.
Enable MIG (Enable) for each GPU on the VM Instance (GuestOS) and reboot the VM Instance.
Color mode$ nvidia-smi –I 0 –mig 1 Enabled MIG mode for GPU 00000000:05:00.0 All done. # reboot$ nvidia-smi –I 0 –mig 1 Enabled MIG mode for GPU 00000000:05:00.0 All done. # rebootCode block. nvidia-smi command - enable MIG
Reference
When using a GPU and configuring MIG, you may encounter the following warning message. If the warning appears, check whether any programs are running on the GPU.
Warning: MIG mode is in pending enable state for GPU 00000000:05:00.0: In use by another client. 00000000:05:00.0 is currently being used by one or more other processes (e.g. CUDA application or a monitoring application such as another instance of nvidia-smi).
- Check the GPU status after applying MIG on the VM Instance(GuestOS).
- Check whether MIG mode is Enabled.Color mode
$ nvidia-smi Mon Sep 27 09:44:33 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 09:44:33 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 59W / 400W | 0MiB / 81251MiB | 0% Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+Code block. nvidia-smi command - Check GPU activation status (1) Color mode$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0)Code block. nvidia-smi command - Check GPU activation status (2)
- Check whether MIG mode is Enabled.
GPU Instance creation
If you have enabled MIG and verified its status, you can create a GPU Instance.
- Check the list of MIG GPU Instance profiles that can be created.Color mode
$ nvidia-smi mig -i [GPU ID] -lgip$ nvidia-smi mig -i [GPU ID] -lgipCode block. nvidia-smi command - view MIG GPU Instance profile list
Color mode
$ nvidia-smi mig -i 0 -lgip
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
| ============================================================================= |
| 0 MIG 1g.10gb 19 7/7 9.50 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.10gb+me 20 1/1 9.50 No 14 0 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.20gb 14 3/3 19.50 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.40gb 9 2/2 39.50 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.40gb 5 1/1 39.50 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.80gb 0 1/1 79.25 No 98 0 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+$ nvidia-smi mig -i 0 -lgip
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
| ============================================================================= |
| 0 MIG 1g.10gb 19 7/7 9.50 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.10gb+me 20 1/1 9.50 No 14 0 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.20gb 14 3/3 19.50 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.40gb 9 2/2 39.50 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.40gb 5 1/1 39.50 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.80gb 0 1/1 79.25 No 98 0 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+Reference
Refer to the NVIDIA Multi-Instance GPU User Guide for GPU Instance profiles.
- After creating a MIG GPU Instance, check it.
Create GPU Instance
Color mode$ nvidia-smi mig -i [GPU ID] -cgi [Profile ID]$ nvidia-smi mig -i [GPU ID] -cgi [Profile ID]code block. nvidia-smi command - GPU Instance creation Color mode$ nvidia-smi mig -i 0 -cgi 0 Successfully created GPU instance ID 0 on GPU 0 using profile MIG 7g.80gb (ID 0)$ nvidia-smi mig -i 0 -cgi 0 Successfully created GPU instance ID 0 on GPU 0 using profile MIG 7g.80gb (ID 0)Code block. nvidia-smi command - Example of creating a GPU Instance Check GPU Instance
Color mode$ nvidia-smi mig -i [GPU ID] -lgi$ nvidia-smi mig -i [GPU ID] -lgicode block. nvidia-smi command - check GPU Instance Color mode$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | | ======================================================== | | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | | ======================================================== | | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+Code block. nvidia-smi command - example of checking GPU Instance
Compute Instance creation
If you have created a GPU Instance, you can create a Compute Instance.
Check the MIG Compute Instance profiles you can create.
Color mode$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcipCode block. nvidia-smi command - Check MIG Compute Instance profile Color mode$ nvidia-smi mig -i 0 -gi 0 -lcip +---------------------------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Exclusive Shared | | GPU Instance ID Free/Total SM DEC ENC OFA | | ID CE JPEG | | ================================================================================= | | 0 0 MIG 1c.7g.80gb 0 7/5 14 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 2c.7g.80gb 1 3/3 28 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 3c.7g.80gb 2 2/2 42 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 4c.7g.80gb 3 1/1 56 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 7g.80gb 4* 1/1 98 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 -lcip +---------------------------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Exclusive Shared | | GPU Instance ID Free/Total SM DEC ENC OFA | | ID CE JPEG | | ================================================================================= | | 0 0 MIG 1c.7g.80gb 0 7/5 14 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 2c.7g.80gb 1 3/3 28 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 3c.7g.80gb 2 2/2 42 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 4c.7g.80gb 3 1/1 56 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+ | 0 0 MIG 7g.80gb 4* 1/1 98 5 0 1 | | 7 1 | +---------------------------------------------------------------------------------+Code block. Example of MIG Compute Instance profile list Create and verify a MIG Compute Instance.
- MIG Compute Instance creationColor mode
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -cci [Compute Profile ID]$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -cci [Compute Profile ID]code block. nvidia-smi command - Create MIG Compute Instance Color mode$ nvidia-smi mig -i 0 -gi 0 -cci 4 Successfully created compute instance ID 0 on GPU instance ID 0 using profile MIG 7g.80gb(ID 4)$ nvidia-smi mig -i 0 -gi 0 -cci 4 Successfully created compute instance ID 0 on GPU instance ID 0 using profile MIG 7g.80gb(ID 4)Code block. nvidia-smi command - Example of creating a MIG Compute Instance - Check MIG Compute InstanceColor mode
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –lci$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –lcicode block. nvidia-smi command - check MIG Compute Instance Color mode$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | | ================================================================= | | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | | ================================================================= | | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+Code block. Example of checking MIG Compute Instance Color mode$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0) MIG 7g.80gb Device 0: (UUID: MIG-53e20040-758b-5ecb-948e-c626d03a9a32)$ nvidia-smi –L GPU 0: NVIDIA A100-SXM-80GB (UUID: GPU-c956838f-494a-92b2-6818-56eb28fe25e0) MIG 7g.80gb Device 0: (UUID: MIG-53e20040-758b-5ecb-948e-c626d03a9a32)Code block. nvidia-smi command - Check GPU status (1) Color mode$ nvidia-smi Mon Sep 27 09:52:17 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 49W / 400W | 0MiB / 81251MiB | N/A Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | 0 0 0 0 | 0MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 1MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 27 09:52:17 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | On | | N/A 32C P0 49W / 400W | 0MiB / 81251MiB | N/A Default | | | | Enabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | 0 0 0 0 | 0MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 1MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+Code block. nvidia-smi command - Check GPU status (2)
- MIG Compute Instance creation
Using MIG
- Use the MIG Instance to perform the Job.
- Example of task executionColor mode
$ docker run --gpus '"device=[GPU ID]:[MIG ID]"' -rm nvcr.io/nvidia/cuda nvidia-smi$ docker run --gpus '"device=[GPU ID]:[MIG ID]"' -rm nvcr.io/nvidia/cuda nvidia-smiCode block. Task execution example - You can see an example of the work performed as follows.Color mode
$ docker run --gpus '"device=0:0"' -rm -it --network=host --shm-size=1g --ipc=host -v /root/.ssh/:/root/.ssh ================ == TensorFlow == ================ NVIDIA Release 21.08-tf1 (build 26012104) TensorFlow Version 1.15.5 Container image Copyright (c) 2021, NVIDIA CORPORATION. All right reserved. ... # Run Python process root@d622a93c9281:/workspace# python /workspace/nvidia-examples/cnn/resnet.py --num_iter 100 ... PY 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] TF 1.15.5 ...$ docker run --gpus '"device=0:0"' -rm -it --network=host --shm-size=1g --ipc=host -v /root/.ssh/:/root/.ssh ================ == TensorFlow == ================ NVIDIA Release 21.08-tf1 (build 26012104) TensorFlow Version 1.15.5 Container image Copyright (c) 2021, NVIDIA CORPORATION. All right reserved. ... # Run Python process root@d622a93c9281:/workspace# python /workspace/nvidia-examples/cnn/resnet.py --num_iter 100 ... PY 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] TF 1.15.5 ...Code block. Operation result
- Example of task execution
- Check the GPU usage. (Create JOB process)
- When the job runs, you can see that a process is allocated to the MIG device and its utilization increases.Color mode
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcip$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -lcipcode block. nvidia-smi command - check GPU utilization - You can check the GPU usage as shown below.Color mode
+-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | 0 0 0 0 | 66562MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 5MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | 0 0 0 17483 C python 66559MiB | +-----------------------------------------------------------------------------++-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | 0 0 0 0 | 66562MiB / 81251MiB | 98 0 | 7 0 5 1 1 | | | 5MiB / 13107... | | | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | 0 0 0 17483 C python 66559MiB | +-----------------------------------------------------------------------------+Code block. Example of checking GPU utilization.
- When the job runs, you can see that a process is allocated to the MIG device and its utilization increases.
Delete and release MIG Instance
Follow these steps to delete the MIG instance and detach the MIG.
MIG release order
Delete Compute Instance → Delete GPU Instance → Disable MIG feature (deactivate)
Compute Instance Delete
- Delete the Compute Instance.Color mode
$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dci $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -ci [Compute Instance] –dci$ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dci $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] -ci [Compute Instance] –dciCode block. nvidia-smi command - Delete Compute Instance Color mode$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | | ================================================================= | | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+$ nvidia-smi mig -i 0 -gi 0 –lci +-----------------------------------------------------------------+ | Compute instance profiles: | | GPU GPU Name Profile Instances Placement | | GPU Instance ID ID Start:Size | | ID | | ================================================================= | | 0 0 MIG 7g.80gb 4 0 0:7 | +-----------------------------------------------------------------+code block. Example of checking MIG Compute Instance Color mode$ nvidia-smi mig -i 0 -gi 0 –dci Successfully destroyed compute instance ID 0 from GPU instance ID 0$ nvidia-smi mig -i 0 -gi 0 –dci Successfully destroyed compute instance ID 0 from GPU instance ID 0Code block. Compute Instance deletion example Color mode$ nvidia-smi mig -i 0 -gi 0 –lci No compute instances found: Not found$ nvidia-smi mig -i 0 -gi 0 –lci No compute instances found: Not foundCode block. Confirm Compute Instance deletion
Delete GPU Instance
- Delete the GPU Instance.Color mode
$ nvidia-smi mig -i [GPU ID] –dgi $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dgi$ nvidia-smi mig -i [GPU ID] –dgi $ nvidia-smi mig -i [GPU ID] -gi [GPU Instance ID] –dgiCode block. nvidia-smi command - Delete GPU Instance Color mode$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | | ======================================================== | | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+$ nvidia-smi mig -i 0 -lgi +--------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | | ======================================================== | | 0 MIG 7g.80gb 0 0 0:8 | +--------------------------------------------------------+Code block. nvidia-smi command - Example of checking GPU Instance Color mode$ nvidia-smi mig -i 0 -dgi Successfully destroyed GPU instance ID 0 from GPU 0$ nvidia-smi mig -i 0 -dgi Successfully destroyed GPU instance ID 0 from GPU 0Code block. nvidia-smi command - GPU Instance deletion example Color mode$ nvidia-smi mig -i 0 -lgi No GPU instances found: Not found$ nvidia-smi mig -i 0 -lgi No GPU instances found: Not foundcode block. nvidia-smi command - example of deleting a GPU Instance
Disable MIG feature (deactivation)
- After disabling MIG (Disable), reboot.Color mode
$ nvidia-smi -mig 0 Disabled MIG Mode for GPU 00000000:05:00.0 All done.$ nvidia-smi -mig 0 Disabled MIG Mode for GPU 00000000:05:00.0 All done.Code block. nvidia-smi command - disable MIG Color mode$ nvidia-smi Mon Sep 30 05:18:28 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 33C P0 60W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+$ nvidia-smi Mon Sep 30 05:18:28 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 | | -------------------------------+----------------------+---------------------- | | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | ===============================+======================+====================== | | 0 NVDIA A100-SXM... Off | 00000000:05:00.0 Off | 0 | | N/A 33C P0 60W / 400W | 0MiB / 81251MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | MIG devices: | +-----------------------------------------------------------------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ============================================================================= | | No MIG devices found | +-----------------------------------------------------------------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ============================================================================= | | No running processes found | +-----------------------------------------------------------------------------+Code block. nvidia-smi command - check GPU status
3.2.4 - Use NVSwitch on GPU Server
After creating a GPU Server, you can enable the NVSwitch feature on the GPU Server’s VM (Guest OS) and use fast GPU-to-GPU P2P communication.
Caution
Only the GPU Server (8 GPU) and Multi-node GPU Cluster of Samsung Cloud Platform are connected with NVSwitch and NVLink.
Exploring NVIDIA NVSwitch for Multi GPU
NVLink expands I/O by directly connecting multiple GPUs within a server both bidirectionally and GPU-to-GPU. Using NVSwitch, you can connect all GPUs in a server with full NVLink bandwidth.
Checking NVSwitch operation
Check the NVIDIA Fabric Manager, NVIDIA NVLink topology, and NVIDIA NVLink Status on the GPU server.
Reference
The example for checking NVSwitch operation is explained using the A100 GPU Server (g1v128a8) as a reference.
NVIDIA Fabric Manager operating status
Verify that active (running) is displayed when operating normally.
~$ systemctl status nvidia-fabricmanager
Color mode
nvidia-fabricmanager.service - NVIDIA fabric manager service
Loaded: loaded (/lib/systemd/system/nvidia-fabricmanager.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2026-02-02 16:23:27 KST; 32min ago
Main PID: 2191 (nv-fabricmanage)
Tasks: 18 (limit: 629145)
Memory: 18.0M
CPU: 33.461s
CGroup: /system.slice/nvidia-fabricmanager.service
└─2191 /usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfgnvidia-fabricmanager.service - NVIDIA fabric manager service
Loaded: loaded (/lib/systemd/system/nvidia-fabricmanager.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2026-02-02 16:23:27 KST; 32min ago
Main PID: 2191 (nv-fabricmanage)
Tasks: 18 (limit: 629145)
Memory: 18.0M
CPU: 33.461s
CGroup: /system.slice/nvidia-fabricmanager.service
└─2191 /usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfgCheck NVIDIA NVLink topology
Check the NVIDIA NVLink topology.
~$ nvidia-smi topo -m
Color mode
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 0-127 0-7 N/A
GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 0-127 0-7 N/A
GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 0-127 0-7 N/A
GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X 0-127 0-7 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinksnvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 0-127 0-7 N/A
GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 0-127 0-7 N/A
GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 0-127 0-7 N/A
GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 0-127 0-7 N/A
GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X 0-127 0-7 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinksCheck NVIDIA NVLink Status
Check the NVIDIA NVLink Status.
~$ nvidia-smi topo -m
Color mode
GPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-64a2f685-bb12-c4af-105c-0726ece9c8d7)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2269851b-71cd-f6c7-50c5-ba1525cf3ce8)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-4c397bbf-95fc-5c29-918a-a429cbe45a7a)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-0e350204-9fb6-2cbe-538e-8f7849658eb8)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-45f0c453-4760-edd4-3af9-25c5ea7473a5)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-38409794-bb34-430e-3c50-90b42cb2bb72)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-3fb478aa-801b-eb64-55c2-0ffc3f2ce404)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/sGPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-64a2f685-bb12-c4af-105c-0726ece9c8d7)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2269851b-71cd-f6c7-50c5-ba1525cf3ce8)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-4c397bbf-95fc-5c29-918a-a429cbe45a7a)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-0e350204-9fb6-2cbe-538e-8f7849658eb8)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-45f0c453-4760-edd4-3af9-25c5ea7473a5)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-38409794-bb34-430e-3c50-90b42cb2bb72)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s
GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-3fb478aa-801b-eb64-55c2-0ffc3f2ce404)
Link 0: 25 GB/s
Link 1: 25 GB/s
Link 2: 25 GB/s
Link 3: 25 GB/s
Link 4: 25 GB/s
Link 5: 25 GB/s
Link 6: 25 GB/s
Link 7: 25 GB/s
Link 8: 25 GB/s
Link 9: 25 GB/s
Link 10: 25 GB/s
Link 11: 25 GB/s3.2.5 - Install ServiceWatch Agent
Users can install the ServiceWatch Agent on a GPU server to collect custom metrics and logs.
Reference
Custom metric/log collection via the ServiceWatch Agent is currently available only on Samsung Cloud Platform For Enterprise. It will also be available in other offerings in the future.
Caution
Metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges, unlike the default metrics collected from each service; therefore, we recommend removing or disabling any unnecessary metric collection settings.
ServiceWatch Agent
There are two main types of agents that need to be installed on a GPU server to collect custom metrics and logs for ServiceWatch. It is the Prometheus Exporter and Open Telemetry Collector.
| Category | Detailed description | |
|---|---|---|
| Prometheus Exporter | Provide metrics of a specific application or service in a format that Prometheus can scrape
| |
| Open Telemetry Collector | Acts as a centralized collector that gathers telemetry data such as metrics and logs from distributed systems, processes (filtering, sampling, etc.) it, and exports it to various backends (e.g., Prometheus, Jaeger, Elasticsearch, etc.)
|
Table. Explanation of Prometheus Exporter and Open Telemetry Collector
Caution
If you have configured a Kubernetes Engine on a GPU server, please view the GPU metrics using the metrics provided by the Kubernetes Engine.
- If you install the DCGM Exporter on a GPU server configured with Kubernetes Engine, it may not operate correctly.
Pre-configuration for using ServiceWatch Agent
To use the ServiceWatch Agent, please refer to ServiceWatch Agent를 위한 사전 환경 설정 and prepare the prerequisite configuration.
Install Prometheus Exporter for GPU metrics (for Ubuntu)
Install the Prometheus Exporter for collecting metrics from the GPU server according to the steps below.
Verify NVDIA Driver Installation
- Check the installed NVDIA driver.Color mode
nvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csvCode block. NVDIA Driver version check command Color modedriver_version 535.183.06 535.183.06driver_version 535.183.06 535.183.06code block. Example of checking NVDIA Driver version.
NVSwitch Configuration and Query (NSCQ) Library Installation
Reference
The NVSwitch Configuration and Query (NSCQ) Library is required for Hopper or earlier generation GPUs.
information
The following installation commands are applicable in environments with internet access.
If you are in an environment without internet access, you must download libnvdia-nscq from https://developer.download.nvidia.com/compute/cuda/repos/ and upload it.
Install cuda-keyring.
Color modewget https://developer.download.nvidia.com/compute/cuda/repos/<distro>/<arch>/cuda-keyring_1.1-1_all.debwget https://developer.download.nvidia.com/compute/cuda/repos/<distro>/<arch>/cuda-keyring_1.1-1_all.debcode block. NSCQ library download command Color modesudo dpkg -i cuda-keyring_1.1-1_all.deb apt updatesudo dpkg -i cuda-keyring_1.1-1_all.deb apt updateCode block. NSCQ library installation command Color modenvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csvCode block. NVDIA Driver version check command Color modedriver_version 535.183.06 ... 535.183.06driver_version 535.183.06 ... 535.183.06Code block. NVDIA Driver version check example Install libnvidia-nscq.
Color modeapt-cache policy libnvidia-nscq-535apt-cache policy libnvidia-nscq-535Code block. NSCQ library apt-cache command Color modelibnvidia-nscq-535: Installed: (none) Candidate: 535.247.01-1 Version table: 535.247.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.216.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.06-1 600 # Install the version that matches the Driver 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.01-1 600 ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.54.03-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvidia-nscq-535: Installed: (none) Candidate: 535.247.01-1 Version table: 535.247.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.216.01-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.06-1 600 # Install the version that matches the Driver 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.183.01-1 600 ... 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 535.54.03-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packagescode block. NSCQ library apt-cache command result Color modeapt install libnvidia-nscq-535=535.183.06-1apt install libnvidia-nscq-535=535.183.06-1Code block. NSCQ library installation command
information
It must be installed with the same version as the NVDIA driver.
- Example) driver version: 535.183.06, libnvdia-nscq version: 535.183.06-1
NVSwitch Device Monitoring API(NVSDM) Library Installation
Reference
After Blackwell, GPU architectures require the NVSDM Library to be installed. NVDIA Driver version 560 or lower does not provide the NVSDM Library.
- Install the NVSDM library.Color mode
apt-cache policy libnvsdmapt-cache policy libnvsdmcode block. NVSDM library apt-cache command Color modelibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 PackagesCode block. NVSDM library apt-cache command result Color modeapt install libnvsdm=580.105.08-1apt install libnvsdm=580.105.08-1Code block. Install NVSDM library
NVIDIA DCGM installation (for Ubuntu)
Install the DCGM Exporter according to the steps below.
- DCGM(datacenter-gpu-manager) Installation
- datacenter-gpu-manager-exporter Installation
- DCGM Service Activation and Start
DCGM(datacenter-gpu-manager) Installation
refers to a specific version of NVIDIA’s Data Center GPU Manager (DCGM) tool, which is a package for managing and monitoring NVIDIA data center GPUs. In particular, cuda12 indicates that this management tool is installed for the CUDA 12 version, and datacenter-gpu-manager-4 refers to the 4.x version of DCGM. This tool provides various features, including GPU status monitoring, diagnostics, alert system, and power/clock management.
- Check the CUDA version.Color mode
nvidia-smi | grep CUDAnvidia-smi | grep CUDACode block. Check CUDA version Color mode| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |Code block. Example of CUDA version check result Color modeCUDA_VERSION=12CUDA_VERSION=12Code block. CUDA version setting command - Install datacenter-gpu-manager-cuda.Color mode
apt install datacenter-gpu-manager-4-cuda${CUDA_VERSION}apt install datacenter-gpu-manager-4-cuda${CUDA_VERSION}code block. datacenter-gpu-manager-cuda installation command
datacenter-gpu-manager-exporter installation
It is a tool that, based on NVIDIA Data Center GPU Manager (DCGM), collects various GPU metrics such as GPU usage, memory usage, temperature, and power consumption, and exposes them for use in monitoring systems like Prometheus.
- Install datacenter-gpu-manager-exporter.Color mode
apt install datacenter-gpu-manager-exporterapt install datacenter-gpu-manager-exporterCode block. datacenter-gpu-manager-exporter installation command - Check the DCGM Exporter configuration file.Color mode
cat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartcat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartCode block. Command to check the datacenter-gpu-manager-exporter configuration file. Color modeExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvCode block. Example of checking the datacenter-gpu-manager-exporter configuration file. - When installing the DCGM Exporter, review the provided settings and remove
#for required metrics, and add#for unnecessary metrics.Color modevi /etc/dcgm-exporter/default-counters.csv ## Example ## DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active.vi /etc/dcgm-exporter/default-counters.csv ## Example ## DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active.Code block. datacenter-gpu-manager-exporter metric configuration example
Reference
For the metrics that can be collected with the GPU DCGM Exporter and how to configure them, see DCGM Exporter 지표.
Caution
Since metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges unlike the default metrics, unnecessary metric collection must be removed or disabled to prevent excessive fees.
Enable and start DCGM service
Enable and start the nvdia-dcgm service.
Color modesystemctl enable --now nvidia-dcgmsystemctl enable --now nvidia-dcgmCode block. nvdia-dcgm service activation and start command Enable and start the nvdia-dcgm-exporter service.
Color modesystemctl enable --now nvidia-dcgm-exportersystemctl enable --now nvidia-dcgm-exporterCode block. Command to enable and start the nvdia-dcgm-exporter service
Information
If you have completed the DCGM Exporter setup, you must install the OpenTelemetry Collector provided by ServiceWatch to finish configuring the ServiceWatch Agent.
For more details, refer to ServiceWatch > ServiceWatch Agent 사용하기.
For more details, refer to ServiceWatch > ServiceWatch Agent 사용하기.
Installation of Prometheus Exporter for GPU metrics (for RHEL)
Install the ServiceWatch Agent according to the steps below to collect metrics from the GPU server.
NVDIA Driver Installation Check (for RHEL)
- Check the installed NVDIA Driver.Color mode
nvidia-smi --query-gpu driver_version --format csvnvidia-smi --query-gpu driver_version --format csvCode block. NVDIA Driver version check command Color modedriver_version 535.183.06 ... 535.183.06driver_version 535.183.06 ... 535.183.06Code block. Example of checking NVDIA Driver version
NVSwitch Configuration and Query (NSCQ) Library Installation (for RHEL)
Reference
NVSwitch Configuration and Query (NSCQ) Library is required for Hopper or earlier generation GPUs.
- For RHEL, verify that libnvdia-nscq is installed and install it if necessary.
guide
The following installation commands are applicable in environments with internet access.
If you are in an environment without internet access, you need to download libnvdia-nscq from https://developer.download.nvidia.com/compute/cuda/repos/ and upload it.
Checking the libnvdia-nscq package.
Color moderpm -qa | grep libnvidia-nscq libnvidia-nscq-535-535.183.06-1.x86_64rpm -qa | grep libnvidia-nscq libnvidia-nscq-535-535.183.06-1.x86_64Code block. Check NSCQ library package Add the CUDA Repository to DNF.
Color modednf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repoCode block. Add DNF Repository NVDIA Driver state reset
Color modednf module reset nvidia-driverdnf module reset nvidia-driverCode block. Initialize the state of the NVIDIA Driver DNF module Color modeUpdating Subscription Management repositories. Last metadata expiration check: 0:03:15 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Disabling module profiles: nvidia-driver/default nvidia-driver/fm Resetting modules: nvidia-driver Transaction Summary ============================================= Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:03:15 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Disabling module profiles: nvidia-driver/default nvidia-driver/fm Resetting modules: nvidia-driver Transaction Summary ============================================= Is this ok [y/N]: yCode block. Example of the status reset result of the NVIDIA Driver DNF module. Activate the NVDIA Driver module.
Color modednf module enable nvidia-driver:535-opendnf module enable nvidia-driver:535-openCode block. Enable NVDIA Driver module Color modeUpdating Subscription Management repositories. Last metadata expiration check: 0:04:22 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Enabling module streams: nvidia-driver 535-open Transaction Summary ============================================= Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:04:22 ago on Wed 19 Nov 2025 01:23:48 AM EST. Dependencies resolved. ============================================= Package Architecture Version Repository Size ============================================= Enabling module streams: nvidia-driver 535-open Transaction Summary ============================================= Is this ok [y/N]: ycode block. NVDIA Driver module activation result example Check the libnvdia-nscq module list.
Color modednf list libnvidia-nscq-535 --showduplicatesdnf list libnvidia-nscq-535 --showduplicatesCode block. Check libnvdia-nscq module list Install libnvdia-nscq.
Color modednf install libnvidia-nscq-535-535.183.06-1dnf install libnvidia-nscq-535-535.183.06-1code block. libnvdia-nscq installation command
NVSwitch Device Monitoring API(NVSDM) Library Installation (for RHEL)
Reference
After Blackwell, GPU architectures require the installation of the NVSDM Library. NVDIA Driver versions 560 and below do not provide the NVSDM Library.
Check the NVSDM library module list.
Color modednf list libnvsdm --showduplicatesdnf list libnvsdm --showduplicatesCode block. Check NVSDM library module list Color modelibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packageslibnvsdm: Installed: (none) Candidate: 580.105.08-1 Version table: 580.105.08-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.95.05-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.82.07-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packages 580.65.06-1 600 600 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64 Packagescode block. Example of NVSDM library module list verification results Install libnvsdm.
Color modednf install libnvsdm-580.105.08-1dnf install libnvsdm-580.105.08-1code block. Install NVSDM library Color modeUpdating Subscription Management repositories. Last metadata expiration check: 0:08:18 ago on Wed 19 Nov 2025 01:05:28 AM EST. Dependencies resolved. ========================================================================= Package Architecture Version Repository Size ========================================================================= Installing: libnvsdm x86_64 580.105.08-1 cuda-rhel8-x86_64 675 k Installing dependencies: infiniband-diags x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 323 k libibumad x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 34 k Transaction Summary ========================================================================= Install 3 Packages Total download size: 1.0 M Installed size: 3.2 M Is this ok [y/N]: yUpdating Subscription Management repositories. Last metadata expiration check: 0:08:18 ago on Wed 19 Nov 2025 01:05:28 AM EST. Dependencies resolved. ========================================================================= Package Architecture Version Repository Size ========================================================================= Installing: libnvsdm x86_64 580.105.08-1 cuda-rhel8-x86_64 675 k Installing dependencies: infiniband-diags x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 323 k libibumad x86_64 48.0-1.el8 rhel-8-for-x86_64-baseos-rpms 34 k Transaction Summary ========================================================================= Install 3 Packages Total download size: 1.0 M Installed size: 3.2 M Is this ok [y/N]: yCode block. Example of NVSDM library installation command output
NVIDIA DCGM installation (for RHEL)
Install Node Exporter according to the steps below.
- DCGM(datacenter-gpu-manager) Installation
- datacenter-gpu-manager-exporter installation
- DCGM Service Activation and Start
DCGM(datacenter-gpu-manager) Installation (for RHEL)
Refers to a specific version of NVIDIA’s Data Center GPU Manager (DCGM) tool, which is a package for managing and monitoring NVIDIA data center GPUs. In particular, cuda12 indicates that this management tool is installed for the CUDA 12 version, and datacenter-gpu-manager-4 refers to the 4.x version of DCGM. This tool provides various features, including GPU status monitoring, diagnostics, alert system, and power/clock management.
- Add the CUDA Repository to DNF.Color mode
dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repocode block. Add DNF Repository - Check the CUDA version.Color mode
nvidia-smi | grep CUDAnvidia-smi | grep CUDACode block. Check CUDA version Color mode| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |Code block. Example of CUDA version check result Color modeCUDA_VERSION=12CUDA_VERSION=12Code block. CUDA version setting command - Check the list of datacenter-gpu-manager-cuda modules.Color mode
dnf list datacenter-gpu-manager-4-cuda${CUDA_VERSION} --showduplicatesdnf list datacenter-gpu-manager-4-cuda${CUDA_VERSION} --showduplicatesCode block. Check the datacenter-gpu-manager-cuda module list. Color modeUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:00:34 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-4-cuda12.x86_64 1:4.0.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-2 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.2-1 cuda-rhel8-x86_64Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:00:34 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-4-cuda12.x86_64 1:4.0.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.2.3-2 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.3.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-4-cuda12.x86_64 1:4.4.2-1 cuda-rhel8-x86_64code block. Example of checking the module list of datacenter-gpu-manager-cuda - Install datacenter-gpu-manager-cuda.Color mode
dnf install datacenter-gpu-manager-4-cuda${CUDA_VERSION}dnf install datacenter-gpu-manager-4-cuda${CUDA_VERSION}code block. Install datacenter-gpu-manager-cuda Color modeUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. =================================================================================================== Package Architecture Version Repository Size =================================================================================================== Installing: datacenter-gpu-manager-4-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 554 M Installing dependencies: datacenter-gpu-manager-4-core x86_64 1:4.4.2-1 cuda-rhel8-x86_64 9.9 M Installing weak dependencies: datacenter-gpu-manager-4-proprietary x86_64 1:4.4.2-1 cuda-rhel8-x86_64 5.3 M datacenter-gpu-manager-4-proprietary-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 289 M Transaction Summary ==================================================================================================== Install 4 Packages ... Is this ok [y/N]: yUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. =================================================================================================== Package Architecture Version Repository Size =================================================================================================== Installing: datacenter-gpu-manager-4-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 554 M Installing dependencies: datacenter-gpu-manager-4-core x86_64 1:4.4.2-1 cuda-rhel8-x86_64 9.9 M Installing weak dependencies: datacenter-gpu-manager-4-proprietary x86_64 1:4.4.2-1 cuda-rhel8-x86_64 5.3 M datacenter-gpu-manager-4-proprietary-cuda12 x86_64 1:4.4.2-1 cuda-rhel8-x86_64 289 M Transaction Summary ==================================================================================================== Install 4 Packages ... Is this ok [y/N]: yCode block. Example of datacenter-gpu-manager-cuda installation result
datacenter-gpu-manager-exporter installation (for RHEL)
It is a tool that, based on NVIDIA Data Center GPU Manager (DCGM), collects various GPU metrics such as GPU usage, memory usage, temperature, and power consumption, and exposes them for use in monitoring systems like Prometheus.
Add the CUDA Repository to DNF. 1. (If you have already performed this command, proceed to the next step.)
Color modednf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repodnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repocode block. Add DNF Repository Check the CUDA version. 2. (If you have already performed this command, proceed to the next step.)
Color modenvidia-smi | grep CUDAnvidia-smi | grep CUDACode block. Check CUDA version Color mode| NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 || NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 |Code block. Example of CUDA version check result Color modeCUDA_VERSION=12CUDA_VERSION=12Code block. CUDA version setting command Check the list of datacenter-gpu-manager-exporter modules.
Color modednf list datacenter-gpu-manager-exporter --showduplicatesdnf list datacenter-gpu-manager-exporter --showduplicatesCode block. Check the list of datacenter-gpu-manager-exporter modules Color modeUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:02:11 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-exporter.x86_64 4.0.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.6.0-1 cuda-rhel8-x86_64Updating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:02:11 ago on Wed 19 Nov 2025 12:26:56 AM EST. Available Packages datacenter-gpu-manager-exporter.x86_64 4.0.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.1.3-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.0-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.1-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.5.2-1 cuda-rhel8-x86_64 datacenter-gpu-manager-exporter.x86_64 4.6.0-1 cuda-rhel8-x86_64code block. Example of checking the module list of datacenter-gpu-manager-exporter Install datacenter-gpu-manager-cuda. dcgm-exporter 4.5.X requires glibc 2.34 or newer, but since RHEL9 provides glibc 2.34, we specify the version as 4.1.3-1 for installation.
Color modednf install datacenter-gpu-manager-exporter-4.1.3-1dnf install datacenter-gpu-manager-exporter-4.1.3-1code block. datacenter-gpu-manager-cuda installation Color modeUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. ==================================================================================================== Package Architecture Version Repository Size ==================================================================================================== Installing: datacenter-gpu-manager-exporter x86_64 4.1.3-1 cuda-rhel8-x86_64 26 M Is this ok [y/N]: yUpdating Subscription Management repositories. Unable to read consumer identity This system is not registered with an entitlement server. You can use subscription-manager to register. Last metadata expiration check: 0:07:12 ago on Wed 19 Nov 2025 12:26:56 AM EST. Dependencies resolved. ==================================================================================================== Package Architecture Version Repository Size ==================================================================================================== Installing: datacenter-gpu-manager-exporter x86_64 4.1.3-1 cuda-rhel8-x86_64 26 M Is this ok [y/N]: yCode block. Example of datacenter-gpu-manager-cuda installation result Color modecat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartcat /usr/lib/systemd/system/nvidia-dcgm-exporter.service | grep ExecStartcode block. datacenter-gpu-manager-exporter configuration file Color modeExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvExecStart=/usr/bin/dcgm-exporter -f /etc/dcgm-exporter/default-counters.csvcode block. Example of checking the datacenter-gpu-manager-exporter configuration file. When installing the DCGM Exporter, review the provided settings and remove
#for required metrics, and add#for unnecessary metrics.Color modevi /etc/dcgm-exporter/default-counters.csv ## Example ## DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active.vi /etc/dcgm-exporter/default-counters.csv ## Example ## DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active. DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data. # DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active. # DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active.Code block. datacenter-gpu-manager-exporter metric configuration example
Reference
For the metrics that can be collected with the GPU DCGM Exporter and how to configure them, see DCGM Exporter 지표.
Caution
Since metric collection through the ServiceWatch Agent is classified as custom metrics and incurs charges unlike the default metrics, unnecessary metric collection must be removed or disabled to prevent excessive fees.
Enable and start DCGM service (for RHEL)
Enable and start the nvdia-dcgm service.
Color modesystemctl enable --now nvidia-dcgmsystemctl enable --now nvidia-dcgmcode block. nvdia-dcgm service enable and start command Enable and start the nvdia-dcgm-exporter service.
Color modesystemctl enable --now nvidia-dcgm-exportersystemctl enable --now nvidia-dcgm-exportercode block. nvdia-dcgm-exporter service enable and start command
Info
If you have completed the DCGM Exporter setup, you must install the OpenTelemetry Collector provided by ServiceWatch to finish configuring the ServiceWatch Agent.
For more details, refer to ServiceWatch > ServiceWatch Agent 사용하기.
For more details, refer to ServiceWatch > ServiceWatch Agent 사용하기.
DCGM Exporter metrics
DCGM Exporter Key Metrics
Among the metrics provided by the DCGM Exporter, the main GPU metrics are listed below.
| Category | DCGM Field | Prometheus Metric Type | Summary | |
|---|---|---|---|---|
| Clocks | DCGM_FI_DEV_SM_CLOCK | gauge | SM clock frequency (in MHz) | |
| Clocks | DCGM_FI_DEV_MEM_CLOCK | gauge | Memory clock frequency (in MHz) | |
| Temperature | DCGM_FI_DEV_GPU_TEMP | gauge | GPU temperature (in C) | |
| Power | DCGM_FI_DEV_POWER_USAGE | gauge | Power draw (in W) | |
| Utilization | DCGM_FI_DEV_GPU_UTIL | gauge | GPU utilization (in %) | |
| Utilization | DCGM_FI_DEV_MEM_COPY_UTIL | gauge | Memory utilization (in %) | |
| Memory Usage | DCGM_FI_DEV_FB_FREE | gauge | Frame buffer memory free (in MiB) | |
| Memory Usage | DCGM_FI_DEV_FB_USED | gauge | Frame buffer memory used (in MiB) | |
| Nvlink | DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL(8 GPU only) | counter | Total number of NVLink bandwidth counters for all lanes |
Table. Main GPU metrics provided by the DCGM Exporter
DCGM Exporter metric collection configuration
Refer to the default metrics configured for DCGM Exporter at DCGM Exporter > 기본 지표.
- In addition to the default settings, remove
#from default-counters.csv for the additional metrics to be configured. - For default metrics you do not wish to collect, add
#or delete the corresponding item.
Color mode
# Format
# If line starts with a '#' it is considered a comment
# DCGM FIELD, Prometheus metric type, help message
# Clocks
DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz).
DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz).
# Temperature
DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C).
DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C).
# Power
DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W).
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ).
# PCIE
# DCGM_FI_PROF_PCIE_TX_BYTES, counter, Total number of bytes transmitted through PCIe TX via NVML.
# DCGM_FI_PROF_PCIE_RX_BYTES, counter, Total number of bytes received through PCIe RX via NVML.
...# Format
# If line starts with a '#' it is considered a comment
# DCGM FIELD, Prometheus metric type, help message
# Clocks
DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz).
DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz).
# Temperature
DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C).
DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C).
# Power
DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W).
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ).
# PCIE
# DCGM_FI_PROF_PCIE_TX_BYTES, counter, Total number of bytes transmitted through PCIe TX via NVML.
# DCGM_FI_PROF_PCIE_RX_BYTES, counter, Total number of bytes received through PCIe RX via NVML.
...3.3 - API Reference
API Reference
3.4 - CLI Reference
CLI Reference
3.5 - Release Note
GPU Server
2026.07.16
FEATURE
Add new server type and other feature changes- We provide NPU server types to diversify AI accelerators.
- You can select and use an OS image for the NPU.
- The n1 server type and the A100 HPE server type have been added.
- For detailed specifications, refer to 서버 타입.
- Even if the Backup service is connected, you can delete the server.
- When a server is deleted, the schedule of the associated backup is removed, but the backup itself remains intact and can be restored and utilized.
2026.03.19
FEATURE
Add Kubernetes image and SSD_Provisioned disk type- Add Kubernetes image
- When creating a GPU server, you can select the Kubernetes image (Ubuntu).
- An SSD volume with configurable IOPS and Throughput has been added.
- When creating Block Storage, you can select the SSD_Provisioned disk type.
- You can set the maximum IOPS and Throughput.
2025.10.23
FEATURE
Add new features and provide ServiceWatch service integration functionality- ServiceWatch service integration provision
- You can monitor data through the ServiceWatch service.
- When creating a GPU Server, you can select a RHEL image.
- Keypair management feature has been added.
- You can create a keypair for use or retrieve a public key and apply it.
2025.07.01
FEATURE
Add GPU Server feature, change Image sharing method, and add GPU Server usage guide- Add GPU Server feature
- IP, Public NAT IP, Private NAT IP configuration feature has been added.
- An LLM Endpoint is provided for LLM usage.
- The method for sharing images between accounts has changed.
- You can create a new Image for sharing.
- Add GPU Server usage guide
- Using Multi-instance GPU on GPU Server and Using NVSwitch on GPU Server added the guides.
2025.04.28
FEATURE
Add OS image- GPU Server RHEL OS and GPU driver versions have been added.
2025.02.27
FEATURE
Common feature change- Add GPU Server feature
- NAT configuration functionality has been added to the GPU Server.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, and Service Home, tags, etc., have been updated to reflect common CX changes.
2024.10.01
NEW
GPU Server Service Official Version Release- We have officially launched the GPU Server service.
- We have launched a virtualization computing service that lets you allocate and use infrastructure resources such as CPU, GPU, and memory provided by the server as needed, without having to purchase them individually.
4 - Bare Metal Server
4.1 - Overview
Service Overview
Bare Metal Server does not use virtualization technology and is a high-performance cloud computing service that can allocate and use physically separated computing resources such as CPU and memory exclusively. It is not affected by other cloud users, allowing you to reliably operate performance-sensitive services.
Features
Easy and convenient computing environment setup: Through the web-based Console, you can easily handle everything from Bare Metal Server provisioning to resource management and cost management. You can receive a server with standard specs (CPU, Memory, Disk) allocated exclusively and use it immediately.
Providing High-Performance Computing Environment: We provide servers suitable for workloads that require large capacity and high performance—such as real-time (Real-Time) systems, HPC (High Performance Computing), and servers that demand excessive I/O usage—in a physically isolated environment.
Efficient Service Delivery: Ensure performance and stability through optimal server selection and in-house testing. Customers can choose the optimal resources that fit their service environment from the various specifications of Bare Metal Servers offered by Samsung Cloud Platform.
Service Architecture Diagram
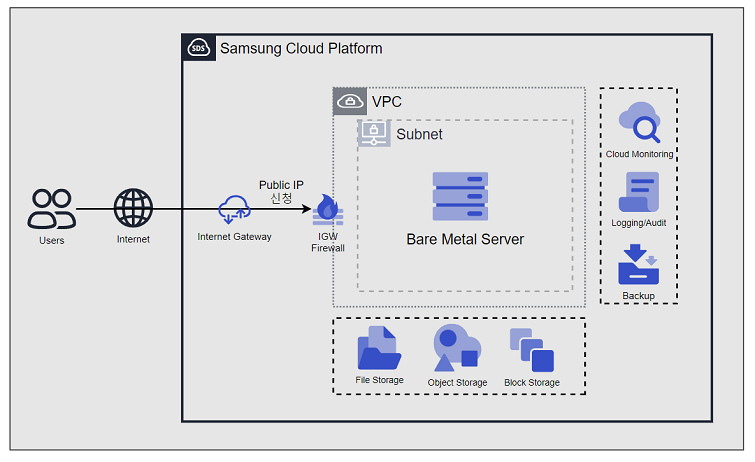
Provided features
Bare Metal Server provides the following features.
- Auto Provisioning (Auto Provisioning) and Management: Through the web-based Console, you can easily provision Bare Metal Servers, manage resources, and control costs.
- Providing various types of server types and OS images: Provides CPU, Memory, and Disk resources of standard server types, and offers a variety of standard OS images.
- Storage Connection: Provides additional attached storage beyond the OS disk. You can connect and use Block Storage, File Storage, and Object Storage.
- Network Connection: You can connect the standard subnet/IP settings of a Bare Metal Server and a Public NAT IP. Provides a local subnet connection for inter-server communication. This can be modified on the detail page.
- Monitoring: You can view monitoring information such as CPU, Memory, and Disk, which are computing resources, through Cloud Monitoring. To use the Cloud Monitoring service for Bare Metal Server, you must install the Agent. Please be sure to install the Agent for stable Bare Metal Server service usage. For more details, see Bare Metal Server Monitoring Metrics.
- Backup and Recovery: You can back up and restore the Bare Metal Server’s filesystem using the Backup service.
- Efficient Cost Management: You can easily create or terminate servers as needed, and because billing is based on actual usage time, you can use it cost‑effectively in various unpredictable situations.
- Local disk partition creation You can create and use up to 10 local disk partitions.
- Terraform Provisioning: Provides an IaC environment using Terraform.
Components
Bare Metal Server provides various standard OS images and standard server types. Users can select and use them according to the scale of the service they want to configure.
OS Image provided version
The OS images supported by Bare Metal Server are as follows
| OS Image version | EoS Date |
|---|---|
| Oracle Linux 9.6 | 2032-06-30 |
| RHEL 8.10 | 2029-05-31 |
| RHEL 9.4 | 2026-04-30 |
| RHEL 9.6 | 2027-05-31 |
| Rocky Linux 8.10 | 2029-05-31 |
| Rocky Linux 9.6 | 2025-11-30 |
| Ubuntu 22.04 | 2027-06-30 |
| Ubuntu 24.04 | 2029-06-30 |
| Windows 2019 | 2029-01-09 |
| Windows 2022 | 2031-10-14 |
Table. Bare Metal Server provided OS Image version
Reference
- Oracle Linux, RHEL, and Rocky Linux only provide even-numbered minor versions. Check the OS Image’s EOS (End of Support)/EOL (End of Life) Date.
- To ensure stable OS operation, apply new or additional individual packages yourself.
Server type
The server types supported by Bare Metal Server are as follows. For detailed information about the server types supported by Bare Metal Server, see Bare Metal Server Server Types.
s3v16m64_metal
| Category | example | Detailed description |
|---|---|---|
| Server generation | s3 | Provided server categories and generations
|
| CPU vCore | v16 | Number of vCores
|
| Memory | m64 | Memory capacity
|
Table. Bare Metal Server server type
Preceding Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
Table. Bare Metal Server Pre-service
4.1.1 - Server type
Bare Metal Server provides server types tailored to the intended use. Server types consist of various combinations such as CPU and Memory, and the server used for a Bare Metal Server is determined by the server type selected when creating the Bare Metal Server. Please select the server type based on the specifications of the application you want to run on the Bare Metal Server.
안내
- Support for the server type varies depending on the OS image provided by the Bare Metal Server. * When creating a service, refer to OS Image별 지원 서버 타입 and select the OS Image and server type.
- s3/h3, s2/h2 server types are no longer accepting new service applications. * There is no impact on the services currently in use.
Bare Metal Server server type
The server types supported by Bare Metal Server are as follows.
s3v16m64_metal
Category | example | Detailed description |
|---|---|---|
| Server generation | s3 | Provided server categories and generations
|
| CPU vCore | v16 | Number of vCores
|
| Memory | m64 | 메모리 용량
|
표. Bare Metal Server 서버 타입 형식
s4/h4 server type
The Bare Metal Server s4 server type is offered with standard specifications (vCPU, Memory) and, because it receives physically isolated resources, it is suitable for high-performance applications. Additionally, the Bare Metal Server h4 server type is offered with high-capacity specifications and is suitable for high-performance applications for large-scale data processing.
- Supports a total of five vCPU options (16, 32, 64, 96, 128 vCore)
- Intel 6th Generation (Granite Rapids) Processor
- Supports up to 64 physical cores, 128 vCPUs, and 2,048 GB of memory.
- Provides two internal disks up to 1.92 TB (for OS use)
| 서버 타입 | 물리 CPU | vCPU | Memory | CPU Type | 소켓수 | Internal Disk (OS) |
|---|---|---|---|---|---|---|
| s4v16m64_metal | 8 Core | 16 vCore | 64 GB | Intel Xeon 6507P with a maximum frequency of 4.3 GHz | 1 | 480 GB * 2 EA |
| s4v16m128_metal | 8 Core | 16 vCore | 128 GB | Intel Xeon 6507P with a maximum of 4.3 GHz | 1 | 480 GB * 2 EA |
| s4v16m256_metal | 8 Core | 16 vCore | 256 GB | Intel Xeon 6507P up to 4.3 GHz | 1 | 480 GB * 2 EA |
| h4v32m128_metal | 16 Core | 32 vCore | 128 GB | Intel Xeon 6517P up to 4.0 GHz | 1 | 960 GB * 2 EA |
| h4v32m256_metal | 16 Core | 32 vCore | 256 GB | Intel Xeon 6517P up to 4.0 GHz | 1 | 960 B * 2 EA |
| h4v32m512_metal | 16 Core | 32 vCore | 512 GB | Intel Xeon 6517P with a maximum of 4.0 GHz | 1 | 960 GB * 2 EA |
| h4v64m256_metal | 32 Core | 64 vCore | 256 GB | Intel Xeon 6737P up to 4.0 GHz | 1 | 1.92 TB * 2 EA |
| h4v64m512_metal | 32 Core | 64 vCore | 512 GB | Intel Xeon 6737P up to 4.0 GHz | 1 | 1.92 TB * 2 EA |
| h4v64m1024_metal | 32 Core | 64 vCore | 1,024 GB | 최대 4.0 GHz의 Intel Xeon 6737P | 1 | 1.92 TB * 2 EA |
| h4v96m512_metal | 48 Core | 96 vCore | 512 GB | Intel Xeon 6520P with a maximum of 3.4 GHz | 2 | 1.92 TB * 2 EA |
| h4v96m768_metal | 48 Core | 96 vCore | 768 GB | Intel Xeon 6520P with a maximum of 3.4 GHz | 2 | 1.92 TB * 2 EA |
| h4v96m2048_metal | 48 Core | 96 vCore | 2,048 GB | Intel Xeon 6520P with a maximum of 3.4 GHz | 2 | 1.92 TB * 2 EA |
| h4v128m512_metal | 64 Core | 128 vCore | 512 GB | Intel Xeon 6737P up to 4.0 GHz | 2 | 1.92 TB * 2 EA |
| h4v128m1024_metal | 64 Core | 128 vCore | 1,024 GB | Intel Xeon 6737P up to 4.0 GHz | 2 | 1.92 TB * 2 EA |
| h4v128m2048_metal | 64 Core | 128 vCore | 2,048 GB | Intel Xeon 6737P with a maximum of 4.0 GHz | 2 | 1.92 TB * 2 EA |
표. Bare Metal Server 서버 타입 사양 > s4/h4 서버 타입
s3/h3 server type
안내
s3/h3 서버 타입은 신규 신청 서비스가 종료되었습니다. 기존에 사용 중인 서비스에는 영향이 없습니다.
The Bare Metal Server s3 server type is offered with standard specifications (vCPU, Memory) and, because it receives physically isolated resources, it is suitable for high-performance applications. Additionally, the Bare Metal Server h3 server type is offered with high-capacity specifications and is suitable for high-performance applications for large-scale data processing.
- Supports a total of five vCPU options (16, 32, 64, 96, 128 vCore)
- Intel 4th Generation (Sapphire Rapids) Processor
- Supports up to 64 physical cores, 128 vCPUs, and 2,048 GB of memory.
- Provides two internal disks up to 1.92 TB (for OS use)
| Server type | Physical CPU | vCPU | Memory | CPU Type | socket count | Internal Disk (OS) |
|---|---|---|---|---|---|---|
| s3v16m64_metal | 8 Core | 16 vCore | 64 GB | Intel Xeon Gold 6434 with a maximum of 4.1 GHz | 1 | 480 GB * 2 EA |
| s3v16m128_metal | 8 Core | 16 vCore | 128 GB | Intel Xeon Gold 6434 with a maximum of 4.1 GHz | 1 | 480 GB * 2 EA |
| s3v16m256_metal | 8 Core | 16 vCore | 256 GB | Intel Xeon Gold 6434 with a maximum of 4.1 GHz | 1 | 480 GB * 2 EA |
| h3v32m128_metal | 16 Core | 32 vCore | 128 GB | Intel Xeon Gold 6444Y up to 4.0 GHz | 1 | 960 GB * 2 EA |
| h3v32m256_metal | 16 Core | 32 vCore | 256 GB | Intel Xeon Gold 6444Y up to 4.0 GHz | 1 | 960 GB * 2 EA |
| h3v32m512_metal | 16 Core | 32 vCore | 512 GB | Intel Xeon Gold 6444Y up to 4.0 GHz | 1 | 960 GB * 2 EA |
| h3v64m256_metal | 32 Core | 64 vCore | 256 GB | Intel Xeon Gold 6448H up to 3.2 GHz | 1 | 1.92 TB * 2 EA |
| h3v64m512_metal | 32 Core | 64 vCore | 512 GB | Intel Xeon Gold 6448H with a maximum of 3.2 GHz | 1 | 1.92 TB * 2 EA |
| h3v64m1024_metal | 32 Core | 64 vCore | 1,024 GB | Intel Xeon Gold 6448H up to 3.2 GHz | 1 | 1.92 TB * 2 EA |
| h3v96m384_metal | 48 Core | 96 vCore | 384 GB | Intel Xeon Gold 6442Y up to 3.3 GHz | 2 | 1.92 TB * 2 EA |
| h3v96m768_metal | 48 Core | 96 vCore | 768 GB | Intel Xeon Gold 6442Y up to 3.3 GHz | 2 | 1.92 TB * 2 EA |
| h3v96m1536_metal | 48 Core | 96 vCore | 1,536 GB | Intel Xeon Gold 6442Y up to 3.3 GHz | 2 | 1.92 TB * 2 EA |
| h3v128m512_metal | 64 Core | 128 vCore | 512 GB | Intel Xeon Gold 6448H up to 3.2 GHz | 2 | 1.92 TB * 2 EA |
| h3v128m1024_metal | 64 Core | 128 vCore | 1,024 GB | Intel Xeon Gold 6448H up to 3.2 GHz | 2 | 1.92 TB * 2 EA |
| h3v128m2048_metal | 64 Core | 128 vCore | 2,048 GB | Intel Xeon Gold 6448H up to 3.2 GHz | 2 | 1.92 TB * 2 EA |
표. Bare Metal Server 서버 타입 사양 > s3/h3 서버 타입
s2/h2 server type
안내
s2/h2 서버 타입은 신규 신청 서비스가 종료되었습니다. 기존에 사용 중인 서비스에는 영향이 없습니다.
The Bare Metal Server s2 server type is offered with standard specifications (vCPU, Memory) and, because it receives physically isolated resources, it is suitable for high-performance applications. Additionally, the Bare Metal Server h2 server type is offered with high-capacity specifications and is suitable for high-performance applications that require large-scale data processing.
- Supports a total of five vCPU options (16, 24, 32, 72, 96 vCore)
- Intel 3rd Generation (Ice Lake) Processor
- Supports up to 48 physical cores, 96 vCPUs, and 1,024 GB of memory
- Provides two internal disks up to 1.92 TB (for OS use)
| Server type | Physical CPU | vCPU | Memory | CPU Type | socket count | Internal Disk (OS) |
|---|---|---|---|---|---|---|
| s2v16m64_metal | 8 Core | 16 vCore | 64 GB | Intel Xeon Gold 6334 up to 3.6 GHz | 1 | 480 GB * 2 EA |
| s2v16m128_metal | 8 Core | 16 vCore | 128 GB | Intel Xeon Gold 6334 up to 3.6 GHz | 1 | 480 GB * 2 EA |
| s2v16m256_metal | 8 Core | 16 vCore | 256 GB | Intel Xeon Gold 6334 up to 3.6 GHz | 1 | 480 GB * 2 EA |
| h2v24m96_metal | 12 Core | 24 vCore | 96 GB | Intel Xeon Gold 5317 with a maximum of 3.4 GHz | 1 | 960 GB * 2 EA |
| h2v24m192_metal | 12 Core | 24 vCore | 192 GB | Intel Xeon Gold 5317 up to 3.4 GHz | 1 | 960 GB * 2 EA |
| h2v24m384_metal | 12 Core | 24 vCore | 384 GB | Intel Xeon Gold 5317 up to 3.4 GHz | 1 | 960 GB * 2 EA |
| h2v32m128_metal | 16 Core | 32 vCore | 128 GB | Intel Xeon Gold 6346 up to 3.6 GHz | 1 | 960 GB * 2 EA |
| h2v32m256_metal | 16 Core | 32 vCore | 256 GB | Intel Xeon Gold 6346 up to 3.6 GHz | 1 | 960 GB * 2 EA |
| h2v32m512_metal | 16 Core | 32 vCore | 512 GB | Intel Xeon Gold 6346 with up to 3.6 GHz | 1 | 960 GB * 2 EA |
| h2v72m256_metal | 36 Core | 72 vCore | 256 GB | Intel Xeon Gold 6354 up to 3.6 GHz | 2 | 1.92 TB * 2 EA |
| h2v72m512_metal | 36 Core | 72 vCore | 512 GB | Intel Xeon Gold 6354 up to 3.6 GHz | 2 | 1.92 TB * 2 EA |
| h2v72m1024_metal | 36 Core | 72 vCore | 1,024 GB | Intel Xeon Gold 6354 up to 3.6 GHz | 2 | 1.92 TB * 2 EA |
| h2v96m384_metal | 48 Core | 96 vCore | 384 GB | Intel Xeon Gold 6342 up to 3.3 GHz | 2 | 1.92 TB * 2 EA |
| h2v96m768_metal | 48 Core | 96 vCore | 768 GB | Intel Xeon Gold 6342 up to 3.3 GHz | 2 | 1.92 TB * 2 EA |
| h2v96m1536_metal | 48 Core | 96 vCore | 1,536 GB | Intel Xeon Gold 6342 with a maximum of 3.3 GHz | 2 | 1.92 TB * 2 EA |
표. Bare Metal Server 서버 타입 사양 > s2/h2 서버 타입
Supported server types by OS Image
The server type varies depending on the OS image provided by the Bare Metal Server. The supported server types for each OS image are as follows.
| OS Image version | s4/h4 support status | Whether s3/h3 is supported | Whether s2/h2 is supported |
|---|---|---|---|
| Oracle Linux 9.6 | O | O | O |
| RHEL 8.10 | X | O | O |
| RHEL 9.4 | O | O | O |
| RHEL 9.6 | O | O | O |
| Rocky Linux 8.10 | X | O | O |
| Rocky Linux 9.6 | O | O | O |
| Ubuntu 22.04 | Verification needed | O | O |
| Ubuntu 24.04 | O | O | Verification required |
| Windows 2019 | X | O | O |
| Windows 2022 | O | O | O |
표. OS Image별 지원 서버 타입
참고
- s3/h3, s2/h2 server types have closed new service applications. * There is no impact on the services currently in use.
- For Ubuntu, the server types you can request may vary depending on resource availability. * Please verify before applying for the service.
4.1.2 - Monitoring Metrics
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Accordingly, after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With the new alternative service, you can continuously perform resource monitoring by leveraging ServiceWatch released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a seamless monitoring environment.
If you are collecting metrics and logs through the Cloud Monitoring Agent, you need to switch to the ServiceWatch Agent.
For detailed information about ServiceWatch, please refer to ServiceWatch Overview.
Detailed information about ServiceWatch Agent can be found in the ServiceWatch Agent.
Bare Metal Server Monitoring Metrics
The table below shows the monitoring metrics of Bare Metal Server that can be viewed through Cloud Monitoring.
Guide
Bare Metal Server requires the user to install the Agent through the guide in order to view monitoring metrics. Before using the reliable Bare Metal Server service, please be sure to install the Agent. For instructions on installing the Agent and detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
| Performance items | Detailed description | unit |
|---|---|---|
| Core Usage [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| Core Usage [System] | Proportion of CPU time spent in kernel space | % |
| Core Usage [User] | Proportion of CPU time spent in user space | % |
| CPU Cores | Number of CPU cores on the host | cnt |
| CPU Usage [Active] | Percentage of CPU time used, excluding Idle and IOWait states | % |
| CPU Usage [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| CPU Usage [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage [User] | Percentage of CPU time used in user space | % |
| CPU Usage/Core [Active] | Percentage of CPU time used other than Idle and IOWait states | % |
| CPU Usage/Core [Idle] | Ratio of CPU time spent in idle state | % |
| CPU Usage/Core [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| CPU Usage/Core [System] | Percentage of CPU time used by the kernel | % |
| CPU Usage/Core [User] | Percentage of CPU time used in user space | % |
| Disk CPU Usage [IO Request] | Proportion of CPU time during which I/O requests to the device were executed | % |
| Disk Queue Size [Avg] | Average queue length of requests executed for the device | num |
| Disk Read Bytes | Bytes per second read from the device | bytes |
| Disk Read Bytes [Delta Avg] | Average of system.diskio.read.bytes_delta for individual disks | bytes |
| Disk Read Bytes [Delta Max] | Maximum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Min] | minimum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Sum] | Sum of system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta] | Delta of the system.diskio.read.bytes value for each Disk | bytes |
| Disk Read Bytes [Success] | Total bytes successfully read | bytes |
| Disk Read Requests | Number of read requests to the disk device per second | cnt |
| Disk Read Requests [Delta Avg] | Average of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Max] | Maximum system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Min] | Minimum of individual Disks’ system.diskio.read.count_delta | cnt |
| Disk Read Requests [Delta Sum] | Sum of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Success Delta] | Delta of system.diskio.read.count for each Disk | cnt |
| Disk Read Requests [Success] | Total number of successful reads | cnt |
| Disk Request Size [Avg] | Average size of requests executed on the device (unit: sectors) | num |
| Disk Service Time [Avg] | Average service time (ms) of input requests executed on the device | ms |
| Disk Wait Time [Avg] | Average time taken for requests executed on the device to be supported | ms |
| Disk Wait Time [Read] | Average disk wait time | ms |
| Disk Wait Time [Write] | Disk average wait time | ms |
| Disk Write Bytes [Delta Avg] | Average of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta Max] | Maximum system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta Min] | Minimum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta Sum] | Sum of system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta] | individual Disk’s system.diskio.write.bytes value delta | bytes |
| Disk Write Bytes [Success] | Total bytes successfully written | bytes |
| Disk Write Requests | Number of write requests to the disk device per second | cnt |
| Disk Write Requests [Delta Avg] | Average of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Max] | Maximum system.diskio.write.count_delta of individual disks | cnt |
| Disk Write Requests [Delta Min] | Minimum of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Sum] | Sum of system.diskio.write.count_delta of individual disks | cnt |
| Disk Write Requests [Success Delta] | Delta of system.diskio.write.count for each Disk | cnt |
| Disk Write Requests [Success] | Total number of successful writes | cnt |
| Disk Writes Bytes | Bytes per second written to the device | bytes |
| Filesystem Hang Check | filesystem(local/NFS) hang check (normal:1, abnormal:0) | status |
| Filesystem Nodes | Total number of file nodes in the file system | cnt |
| Filesystem Nodes [Free] | Total number of available file nodes in the file system | cnt |
| Filesystem Size [Available] | Disk space (bytes) available to unauthorized users | bytes |
| Filesystem Size [Free] | Available disk space (bytes) | bytes |
| Filesystem Size [Total] | Total disk space (bytes) | bytes |
| Filesystem Usage | Used disk space percentage | % |
| Filesystem Usage [Avg] | Average of individual filesystem.used.pct | % |
| Filesystem Usage [Inode] | inode usage | % |
| Filesystem Usage [Max] | Maximum among individual filesystem.used.pct | % |
| Filesystem Usage [Min] | minimum among individual filesystem.used.pct | % |
| Filesystem Usage [Total] | Total filesystem usage | % |
| Filesystem Used | Used disk space (bytes) | bytes |
| Filesystem Used [Inode] | inode usage | bytes |
| Memory Free | Total amount of available memory (bytes). Memory used by system cache and buffers is not included. | bytes |
| Memory Free [Actual] | Actual usable memory (bytes). | bytes |
| Memory Free [Swap] | Available swap memory. | bytes |
| Memory Total | total memory | bytes |
| Memory Total [Swap] | Total swap memory. | bytes |
| Memory Usage | Percentage of used memory | % |
| Memory Usage [Actual] | Percentage of memory actually used | % |
| Memory Usage [Cache Swap] | cached swap usage | % |
| Memory Usage [Swap] | Percentage of used swap memory | % |
| Memory Used | used memory | bytes |
| Memory Used [Actual] | Actual used memory (bytes). The value obtained by subtracting used memory from total memory. | bytes |
| Memory Used [Swap] | Used swap memory | bytes |
| Collisions | Network collision | cnt |
| Network In Bytes | Number of received bytes | bytes |
| Network In Bytes [Delta Avg] | Average of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Max] | Maximum of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Min] | Minimum of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Sum] | Sum of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta] | Delta of received byte count | bytes |
| Network In Dropped | Number of deleted packets among incoming packets | cnt |
| Network In Errors | Number of errors during reception | cnt |
| Network In Packets | Number of received packets | cnt |
| Network In Packets [Delta Avg] | Average of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Max] | Maximum of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Min] | Minimum of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Sum] | Sum of system.network.in.packets_delta for individual networks | cnt |
| Network In Packets [Delta] | Delta of received packet count | cnt |
| Network Out Bytes | Number of transmitted bytes | bytes |
| Network Out Bytes [Delta Avg] | Average of system.network.out.bytes_delta for each network | bytes |
| Network Out Bytes [Delta Max] | Maximum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Min] | Minimum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Sum] | Sum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta] | Delta of transmitted byte count | bytes |
| Network Out Dropped | Number of deleted packets among outgoing packets | cnt |
| Network Out Errors | Number of errors during transmission | cnt |
| Network Out Packets | Number of transmitted packets | cnt |
| Network Out Packets [Delta Avg] | Average of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Max] | Maximum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Min] | Minimum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Sum] | Sum of system.network.out.packets_delta for individual networks | cnt |
| Network Out Packets [Delta] | Delta of transmitted packet count | cnt |
| Open Connections [TCP] | All open TCP connections | cnt |
| Open Connections [UDP] | All open UDP connections | cnt |
| Port Usage | Available port usage rate | % |
| SYN Sent Sockets | Number of sockets in SYN_SENT state (when connecting from local to remote) | cnt |
| Kernel PID Max | kernel.pid_max value | cnt |
| Kernel Thread Max | kernel.threads-max value | cnt |
| Process CPU Usage | Percentage of CPU time consumed by the process since the last update | % |
| Process CPU Usage/Core | Percentage of CPU time used by the process since the last event | % |
| Process Memory Usage | The proportion of main memory (RAM) occupied by a process | % |
| Process Memory Used | Resident Set size. The amount of memory a process occupies in RAM. | bytes |
| Process PID | process pid | pid |
| Process PPID | Parent process PID | pid |
| Processes [Dead] | Number of dead processes | cnt |
| Processes [Idle] | Number of idle processes | cnt |
| Processes [Running] | Number of running processes | cnt |
| Processes [Sleeping] | sleeping processes count | cnt |
| Processes [Stopped] | number of stopped processes | cnt |
| Processes [Total] | Total number of processes | cnt |
| Processes [Unknown] | Number of processes with an unknown or unsearchable status | cnt |
| Processes [Zombie] | zombie processes count | cnt |
| Running Process Usage | process usage | % |
| Running Processes | Number of running processes | cnt |
| Running Thread Usage | Thread usage | % |
| Running Threads | Total number of threads running in running processes | cnt |
| Context Switches | context switch count (per second) | cnt |
| Load/Core [1 min] | The load over the last 1 minute divided by the number of cores | cnt |
| Load/Core [15 min] | The load over the last 15 minutes divided by the number of cores | cnt |
| Load/Core [5 min] | The load over the last 5 minutes divided by the number of cores | cnt |
| Multipaths [Active] | External storage connection path status = active count | cnt |
| Multipaths [Failed] | External storage connection path status = failed count | cnt |
| Multipaths [Faulty] | External storage connection path status = faulty count | cnt |
| NTP Offset | measured offset of the last sample (the time difference between the NTP server and the local environment) | num |
| Run Queue Length | Execution queue length | num |
| Uptime | OS uptime (uptime). (milliseconds) | ms |
| Context Switchies | CPU context switch count (per second) | cnt |
| Disk Read Bytes [Sec] | Bytes read per second from the Windows logical disk | cnt |
| Disk Read Time [Avg] | Average data read time (seconds) | sec |
| Disk Transfer Time [Avg] | Disk average wait time | sec |
| Disk Usage | Disk usage | % |
| Disk Write Bytes [Sec] | Number of bytes written in one second on a Windows logical disk | cnt |
| Disk Write Time [Avg] | Average data write time (seconds) | sec |
| Pagingfile Usage | Paging file usage | % |
| Pool Used [Non Paged] | Nonpaged Pool usage in kernel memory | bytes |
| Pool Used [Paged] | Paged Pool usage in kernel memory | bytes |
| Process [Running] | Number of currently running processes | cnt |
| Threads [Running] | Current number of running threads | cnt |
| Threads [Waiting] | Number of threads waiting for processor time | cnt |
Table. Bare Metal Server monitoring metrics (available when the Agent is installed)
4.2 - How-to guides
Users can create the service by entering the required information for a Bare Metal Server and selecting detailed options through the Samsung Cloud Platform Console.
Create Bare Metal Server
You can create and use the Bare Metal Server service from the Samsung Cloud Platform Console.
To create a Bare Metal Server, follow these steps.
- All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
- On the Service Home page, click the Create Bare Metal Server button. 2. Go to the Bare Metal Server Creation page.
- Bare Metal Server Creation page, enter the information required to create the service and select detailed options.
- Select the required information in the Image and version selection area.
Category required statusDetailed description Image Required Select the type of Image provided - RHEL, Rocky Linux, Ubuntu, Windows
- Refer to the caution information below for the server types available for each OS Image
Image version Required Select version of the selected Image - Provide a version list of the provided server Image
Table. Bare Metal Server Image and version input itemsCautionThe server types that can be requested vary by OS image as follows.
OS Image version s4/h4 server type s3/h3 server type s2/h2 server type Oracle Linux 9.6 O O O RHEL 8.10 X O O RHEL 9.4 O O O RHEL 9.6 O O O Rocky Linux 8.10 X O O Rocky Linux 9.6 O O O Ubuntu 22.04 Confirmation needed O O Ubuntu 24.04 O O Confirmation needed Windows 2019 X O O Windows 2022 O O O - s3/h3, s2/h2 server types are no longer accepting new service applications. * There is no impact on the services currently in use.
- For Ubuntu, the server types you can request may vary depending on resource availability. * Please confirm before applying for the service.
- Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Number of servers Required Number of Bare Metal Servers to create simultaneously - Only numeric input is allowed, and up to 20 servers of the same type can be created simultaneously
Service Type > Server Type Required Bare Metal Server server type - Select the desired vCPU, Memory, and Disk specifications
- For detailed information about the server types provided by Bare Metal Server, refer to Bare Metal Server 서버 타입
Service Type > Planned Compute Required Status of resources with Planned Compute configured - In Use: Number of resources with Planned Compute that are currently in use
- Configured: Number of resources with Planned Compute configured
- Coverage Preview: Amount applied per resource by Planned Compute
- Create Planned Compute Service: Go to the Planned Compute application page
- For more details, see Planned Compute 신청하기
Table. Bare Metal Server Service Information Input Items - In the Required Information Input area, enter or select the required information.
Category required statusDetailed description Administrator account Required Set the administrator account and password to be used when connecting to the server - RHEL and Ubuntu OS are provided with a fixed root account
- For Windows OS, enter 5 to 20 characters using lowercase letters and numbers
AdministratorNot allowed
Server name Required When the selected number of servers is 1, enter a name to distinguish the Bare Metal Server - It must start with a lowercase English letter and be entered using lowercase letters, numbers, and special characters (
-) within 3 to 15 characters
- It must not end with a special character (
-)
- Set the hostname to the entered server name
Server name (auto-generated number) Required It is enabled when the number of selected servers is 2 or more, and you must enter a name for distinguishing the Bare Metal Server in the format name-###(e.g., test-001)- It must start with a lowercase English letter and be entered using lowercase letters, numbers, and special characters (
-) within 3 to 15 characters
- It must not end with a special character (
-)
- Set the hostname to the entered server name
- Automatically generate by incrementing from the entered number by 1 (excluding numbers already in use)
Network Settings Required Set the network where the Bare Metal Server will be installed - Select a pre-created VPC
- General Subnet: Select a pre-created general Subnet
- IP can be auto-generated or user-provided, and if input is selected, the user enters the IP manually
- NAT: Available only when there is one server and the VPC is connected to an Internet Gateway
- When checked, a NAT IP can be selected
- NAT IP: Select a NAT IP
- If no NAT IP is available to select, click the Create New button to generate a Public IP
- Click the Refresh button to view and select the generated Public IP
- Creating a Public IP incurs charges according to the Public IP pricing policy
- Local Subnet (optional): Choose to use a local Subnet
- It is not a required element for creating the service
- Select a pre-created local Subnet
- IP can be auto-generated or user-provided, and if input is selected, the user enters the IP manually
Table. Bare Metal Server required information entry items
- Select the required information in the Image and version selection area.
Caution
Please use a firewall, etc., to control traffic access for the Bare Metal Server. Security Group is not provided.
The firewall of a Bare Metal Server can only be used to control traffic between the Bare Metal Server and Virtual Server. To use the Firewall of a Bare Metal Server, follow the steps below.
- Separate the VPC of Bare Metal Server: Separate them so that the Bare Metal Server and Virtual Server do not use the same VPC.
- Transit Gateway Creation: Create a Transit Gateway.
- The integration between the VPC of a Virtual Server and the VPC of a Bare Metal Server uses a Transit Gateway.
- When creating a Transit Gateway integration in the VPC of a Bare Metal Server, you must also create the Bare Metal Server’s firewall.
- Firewall Rule Registration: Register the rule in the Firewall of the Bare Metal Server.
On the Bare Metal Server Creation page, in the Additional Information Input area, enter or select the required information.
Category required statusDetailed description Local disk partition Selection Set whether to use the local disk partition - Up to 10 partitions can be created, including the root partition
- Can use up to 90% of the total capacity
- After checking Use, you can configure partition information
- Configure root partition information
- Partition type: flat, lvm selectable
- Partition name: enter partition name
- Can be entered only when partition type is lvm
- Enter up to 15 characters starting with a letter and containing letters, numbers, and special characters (
-_)
- Partition size: enter at least 50 GB
- Filesystem type: select according to the used image
- For RHEL, Rocky Linux: xfs, ext4
- For Ubuntu: ext4, xfs, btrfs
- For SLES: btrfs, xfs, ext4
- Mount point: start with special character
/and include letters, numbers, and special characters (-_) up to 15 characters- Cannot be entered when Filesystem type is swap
- Available capacity: 90% of the default disk capacity provided when selecting a server
- When setting partition size, the remaining capacity is automatically calculated and displayed
- The total partition disk size cannot exceed the available capacity
- Configure additional partition information
- Partition type: flat, lvm selectable
- Partition name: enter partition name
- Partition type can be entered only when it is lvm
- Enter up to 15 characters starting with a letter and containing letters, numbers, and special characters (
-_) up to 15 characters
- Partition size: enter at least 1 GB
- Filesystem type: select according to the used image>
- For RHEL, Rocky Linux: xfs, ext4, swap
- For Ubuntu: ext4, xfs, btrfs, swap
- For SLES: btrfs, xfs, ext4, swap
- Mount point: start with special character
/and include letters, numbers, and special characters (-_) up to 15 characters- Cannot be entered when Filesystem type is swap
- Available capacity: 90% of the default disk capacity provided when selecting a server
- When setting partition size, the remaining capacity is automatically calculated and displayed
- The total partition disk size cannot exceed the available capacity
Placement Group Selection Servers belonging to the same Placement group are distributed across different racks - Provides distributed placement for up to two servers belonging to the same Placement group
- For distributed placement of three or more servers, add additional Placement groups
- Applicable only at initial creation and cannot be modified afterward
- If you terminate the last server in a Placement group, that Placement group is automatically deleted
Lock Selection Using a lock prevents actions caused by mistakes, such as terminating, starting, or stopping the server. Init Script Selection Script to run when the server starts - The Init Script must be selected differently depending on the Image type
- For Windows: Select Batch Script
- For Linux: Shell Script
Table. Bare Metal Server Additional Information Input ItemsSummary Check the detailed information and estimated charges generated in the panel, and click the Create button.
- Once creation is complete, check the created resources on the Bare Metal Server List page.
Check detailed information of Bare Metal Server
The Bare Metal Server service allows you to view and edit the complete resource list and detailed information. The Bare Metal Server Details page consists of Details, Tags, Activity History tabs.
To view detailed information about the Bare Metal Server, follow these steps.
- All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
- On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
- On the Bare Metal Server List page, click the resource to view detailed information. 3. Go to the Bare Metal Server Details page.
- Bare Metal Server Details page displays status information and additional feature information, and consists of Details, Tags, Operation History tabs.
Category Detailed description Bare Metal Server status Status of the Bare Metal Server created by the user - Creating: State while the server is being created
- Running:: State when creation is complete and the server is usable
- Editing:: State while the IP is being changed
- Unknown: Error state
- Starting: State while the server is starting
- Stopping: State while the server is stopping
- Stopped: State when the server has stopped
- Terminating: State while terminating
- Terminated: State when termination is complete
Server operation control button Button to change server status - Start: Start a stopped server
- Stop: Stop a running server
Service cancellation Cancel service button Table. Bare Metal Server status information and additional functions
- Bare Metal Server Details page displays status information and additional feature information, and consists of Details, Tags, Operation History tabs.
Detailed Information
On the Bare Metal Server List page, you can view the detailed information of the selected resource and, if needed, modify the information.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Server name | server name |
| Image/Version | Server OS image and version |
| Server type | Display vCPU and memory information |
| Planned Compute | Resource status with Planned Compute configured
|
| Lock | Indicates whether Lock is enabled/disabled
|
| CPU settings | When configuring the CPU, CPU specification information and current status
|
| Placement Group | Placement Group name |
| Network | Network information of the Bare Metal Server
|
| Local Subnet | Local Subnet information of the Bare Metal Server
|
| Block Storage | Block Storage information connected to the server
|
| Init Script | View the Init Script content entered during server creation |
Table. Bare Metal Server detailed information tab items
Tag
Bare Metal Server list page lets you view the tag information of the selected resource, and you can add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Bare Metal Server Tag tab items
Job History
Bare Metal Server List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource change history
|
Table. Bare Metal Server Work History Tab Detailed Information Items
Bare Metal Server Resource Management
If you need server control and management functions for the created Bare Metal Server resources, you can perform tasks on the Bare Metal Server List or Bare Metal Server Details page.
Bare Metal Server Control Operation
You can start, stop, and restart a running Bare Metal Server.
Notice
- When a Bare Metal Server is stopped, the server’s power is turned off.
- Since stopping may affect applications or storage in use, it is recommended to shut down the OS before stopping the Bare Metal Server.
- After shutting down the OS, be sure to also stop the console.
Caution
When starting a Bare Metal Server, be sure to start it from the Console.
To control the operation of a Bare Metal Server, follow these steps.
- All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
- On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
- Bare Metal Server List page, after selecting multiple servers, you can control multiple servers simultaneously using the Start and Stop buttons at the top of the table.
- Bare Metal Server Details The page also allows you to start and stop the server.
- On the Bare Metal Server List page, click the resource to control its operation and navigate to the Bare Metal Server Detail page.
- Check the server status and click the server operation control button to complete the change.
- Start: Start the stopped server.
- Stop: Stops the running server.
Operation control not possible
- If a Bare Metal Server cannot be started when a start request is made, refer to the following.
- When Lock is enabled: Change the Lock setting to disabled, then try again.
- If the Bare Metal Server’s status is not Stopped: Change the Bare Metal Server’s status to Stopped, then try again.
- If a stop request for a Bare Metal Server cannot be performed, refer to the following.
- If Lock is set: Change the Lock setting to disabled, then try again.
- If the Bare Metal Server’s status is not Running: Change the Bare Metal Server’s status to Running, then try again.
Add Block Storage
You can add Block Storage to a Bare Metal Server.
To add Block Storage, follow the steps below.
- All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
- On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
- Bare Metal Server List page, click the server to which you want to add Block Storage. 3. Go to the Bare Metal Server Details page.
- On the Bare Metal Server Details page, click the Add button in the Block Storage section.
- When the popup confirming Block Storage addition opens, click the Confirm button. 5. Block Storage (BM) Creation Navigate to the page.
- On the Block Storage(BM) Creation page, enter the information required to create the service and create a Block Storage.
- For detailed information on creating Block Storage (BM), see Block Storage(BM) 생성하기-create).
- Navigate to the Bare Metal Server Details page where Block Storage was added and confirm that Block Storage has been added.
Caution
After creating a Block Storage, you cannot increase its capacity.
Configure CPU
You can configure the CPU of a Bare Metal Server. To configure the CPU, follow these steps.
All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
On the Bare Metal Server List page, click the resource to configure the CPU. 3. Go to the Bare Metal Server Details page.
On the Bare Metal Server Details page, click the Edit button in the CPU Settings item. 4. Edit CPU Settings A popup window opens.
After entering whether to use the CPU settings and the configuration information, click the Confirm button.
Category required statusDetailed description Use status Required Select whether to enable the CPU setting - When Use is set, Thread per core and core count are required inputs
Threads per core Required Set Hyper threading usage - To disable Hyper threading, set Thread per core to 1
Number of cores Required Set the number of vCPUs to activate - Changing the number of cores does not affect the price.
Total vCPU count - The final number of vCPUs to be activated on the server - Automatically calculate and display the value obtained by multiplying Thread per core by number of cores
Table. CPU configuration information itemsWhen the pop-up notifying CPU setting changes opens, click the Confirm button.
Check that the CPU settings have been correctly modified on the Bare Metal Server Details page.
Caution
- If you modify the CPU settings, they are reflected in the Console immediately, but they take effect on the actual server only after a reboot.
- After modifying the settings, be sure to reboot (stop/start in the console) the server directly.
- If you modify the CPU settings again before rebooting, an error occurs.
- The number of configurable cores may vary depending on the server environment.
- By default, it provides the option to select 25%, 50%, or 75% of the total cores.
- Since the number of cores that can be configured when requesting a server may vary depending on the server environment, if you need any additional settings, be sure to inquire before applying for a Bare Metal Server and then proceed with the application.
Terminate Bare Metal Server
If you terminate an unused Bare Metal Server, you can reduce operating costs. However, if you terminate a Bare Metal Server, the running service may be stopped immediately, so you should proceed with the termination only after fully considering the impact of service interruption.
Caution
Please be aware that data cannot be recovered after terminating the service.
Caution
If you terminate servers one by one that have Block Storage (BM) attached, the servers will be terminated but the attached Block Storage (BM) will not be terminated, so terminate the Block Storage (BM) directly.
To cancel a Bare Metal Server, follow the steps below.
- All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
- On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
- On the Bare Metal Server List page, select the resource to terminate, and click the Terminate Service button.
- You can select multiple resources and delete them simultaneously.
- You can also delete the resource by clicking the Cancel Service button on the Bare metal Server Details page.
- Once the termination is complete, check the Bare Metal Server List page to see if the resource has been terminated.
Termination constraints
If a Bare Metal Server termination request cannot be completed, a popup will provide guidance. Please refer to the case below.
Cancellation not possible
When Block Storage(BM) is connected (simultaneous termination of two or more servers): Please disconnect the Block Storage(BM) first.
- For detailed information on how to cancel, please refer to Block Storage(BM) 해지하기.
If File Storage is connected: First, disconnect the File Storage.
- For detailed information on how to cancel, please refer to File Storage 해지하기.
If Lock is set: Change the Lock setting to disabled, then try again.
If there are resources connected to Backup Agent or Load Balancer: First disconnect the connections of those resources.
If resource management tasks for Bare Metal Server are in progress on the same account: After the Bare Metal Server resource management tasks are completed, please try again.
If the Bare Metal Server’s status is not Running or Stopped: Change the Bare Metal Server’s status to Running or Stopped, then try again.
If the selection includes a server that cannot be terminated simultaneously: Select only resources that can be terminated, then try again.
Configure local Subnet
After completing the creation of a Bare Metal Server, when adding a local Subnet on the Bare Metal Server Details page, the user must manually configure the network settings of the local Subnet.
First connection (kr-west)
If there is no local subnet connected to the Bare Metal Server and you are adding the first connection, follow the guide below.
Caution
This guide applies to kr-west(Korea West) when adding the first local Subnet connection to the server.
- The guide corresponding to kr-south(South Korea) can be found in the First connection (kr-south) chapter.
Linux - Setting up Subnet on Ubuntu
To add a local Subnet and configure the network on an Ubuntu operating system, follow these steps.
On the Bare Metal Server Details page, check the Interface Name.
Retrieve the network configuration information.
Color mode[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1Code block. View network configuration file After adding a new VLAN, set the IP for the bonding configuration.
- Replace the example code’s ID and IP with the assigned ID and IP.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 // **Bare Metal Server Details** Enter the Interface Name displayed on the page. - ens4f1 // **Bare Metal Server Details** Enter the Interface Name shown on the page. mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: // Enter the Vlan ID you verified in the SCP Console instead of 20. addresses: - 192.168.0.10/24 // Set it to the local Subnet IP confirmed in the SCP Console. id: 20 // Set to the Vlan ID verified in the SCP Console. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 // **Bare Metal Server Details** Enter the Interface Name displayed on the page. - ens4f1 // **Bare Metal Server Details** Enter the Interface Name shown on the page. mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: // Enter the Vlan ID you verified in the SCP Console instead of 20. addresses: - 192.168.0.10/24 // Set it to the local Subnet IP confirmed in the SCP Console. id: 20 // Set to the Vlan ID verified in the SCP Console. link: bond-mgt mtu: 1500Code block. IP configuration
- Replace the example code’s ID and IP with the assigned ID and IP.
Apply the changes to the system.
Color mode# netplan apply# netplan applyCode block. Apply changes Check the interface status.
Color mode# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Linux – Configuring Subnet on CentOS/Red Hat
After adding a local Subnet on a CentOS/Red Hat operating system, follow these steps to configure the network.
Caution
Be careful, as setting the interface name incorrectly may delete the IP information currently in use.
On the Bare Metal Server Details page, check the Interface Name.
Modify the following command and execute it.
Color mode#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" BOND_IF_name1="ens2f1" // Enter the Interface Name as found on the **Bare Metal Server Detailed** page. BOND_IF_name2="ens4f0" // **Bare Metal Server Details** page, enter the Interface Name you verified. # Delete Connection nmcli con down "Bond ${BOND_NAME}" nmcli con del "Bond ${BOND_NAME}" nmcli con down "System ${BOND_IF_name1}" nmcli con down "System ${BOND_IF_name2}" nmcli con del "System ${BOND_IF_name1}" nmcli con del "System ${BOND_IF_name2}" # Create Bonding nmcli con add con-name ${BOND_NAME} type bond ifname ${BOND_NAME} nmcli conn mod ${BOND_NAME} con-name "Bond ${BOND_NAME}" nmcli conn mod "Bond ${BOND_NAME}" ipv4.method disabled nmcli conn mod "Bond ${BOND_NAME}" ipv6.method ignore nmcli conn mod "Bond ${BOND_NAME}" connect.autoconnect yes nmcli conn mod "Bond ${BOND_NAME}" +bond.options mode=active-backup \ +bond.options xmit_hash_policy=layer2 +bond.options miimon=100 \ +bond.options num_grat_arp=1 \ +bond.options downdelay=0 +bond.options updelay=0 # Assign bond-slave nmcli conn add type bond-slave ifname ${BOND_IF_name1} con-name "${BOND_IF_name1}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name1} con-name "System ${BOND_IF_name1}" nmcli conn add type bond-slave ifname ${BOND_IF_name2} con-name "${BOND_IF_name2}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name2} con-name "System ${BOND_IF_name2}" # Connection UP nmcli conn up "Bond ${BOND_NAME}" # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" BOND_IF_name1="ens2f1" // Enter the Interface Name as found on the **Bare Metal Server Detailed** page. BOND_IF_name2="ens4f0" // **Bare Metal Server Details** page, enter the Interface Name you verified. # Delete Connection nmcli con down "Bond ${BOND_NAME}" nmcli con del "Bond ${BOND_NAME}" nmcli con down "System ${BOND_IF_name1}" nmcli con down "System ${BOND_IF_name2}" nmcli con del "System ${BOND_IF_name1}" nmcli con del "System ${BOND_IF_name2}" # Create Bonding nmcli con add con-name ${BOND_NAME} type bond ifname ${BOND_NAME} nmcli conn mod ${BOND_NAME} con-name "Bond ${BOND_NAME}" nmcli conn mod "Bond ${BOND_NAME}" ipv4.method disabled nmcli conn mod "Bond ${BOND_NAME}" ipv6.method ignore nmcli conn mod "Bond ${BOND_NAME}" connect.autoconnect yes nmcli conn mod "Bond ${BOND_NAME}" +bond.options mode=active-backup \ +bond.options xmit_hash_policy=layer2 +bond.options miimon=100 \ +bond.options num_grat_arp=1 \ +bond.options downdelay=0 +bond.options updelay=0 # Assign bond-slave nmcli conn add type bond-slave ifname ${BOND_IF_name1} con-name "${BOND_IF_name1}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name1} con-name "System ${BOND_IF_name1}" nmcli conn add type bond-slave ifname ${BOND_IF_name2} con-name "${BOND_IF_name2}" master ${BOND_NAME} nmcli conn mod ${BOND_IF_name2} con-name "System ${BOND_IF_name2}" # Connection UP nmcli conn up "Bond ${BOND_NAME}" # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}Code block. IP configuration script Check the interface status.
Color mode# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Setting up Subnet in Windows
After adding a local Subnet on the Windows operating system, follow these steps to configure the network.
Windows Start icon, right-click it, then run the Windows PowerShell(Administrator) program.
On the Bare Metal Server Details page, check the Interface Name.
Run ncpa.cpl from the Windows Run menu.

Check whether the interface is enabled, and enable it if necessary.
- Activate the Interface Name identified on the Bare Metal Server Details page.

- Activate the Interface Name identified on the Bare Metal Server Details page.
Create a Teaming.
Color modePS C:\> New-NetLbfoTeam –Name “bond-mgt” –TeamMembers ens2f1,ens4f1 PS C:\> Set-NetLbfoTeam –Name “bond-mgt” –LoadBalancingAlgorithm DynamicPS C:\> New-NetLbfoTeam –Name “bond-mgt” –TeamMembers ens2f1,ens4f1 PS C:\> Set-NetLbfoTeam –Name “bond-mgt” –LoadBalancingAlgorithm DynamicCode block. Create Teaming 
After adding a new VLAN, configure the IP.
- Enter the VLAN ID and local Subnet IP confirmed on the Bare Metal Server Details page.Color mode
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”Code block. Windows IP configuration
- Enter the VLAN ID and local Subnet IP confirmed on the Bare Metal Server Details page.
In the Windows Run menu, execute ncpa.cpl to check the interface status.
First connection(kr-south)
If there is no local subnet connected to the Bare Metal Server and you are adding the first connection, follow the guide below.
Caution
This guide applies to kr-south(Korea region) when adding the first local Subnet connection to the server.
- For kr-west(Korea West), refer to the First Connection (kr-west) chapter.
Linux - Setting up Subnet on Ubuntu
To add a local Subnet and configure the network on an Ubuntu operating system, follow these steps.
After adding a new VLAN, set the IP.
- Replace the example code’s ID and IP with the assigned ID and IP.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Enter the VLAN ID you verified on the console instead of 21. addresses: - 192.168.0.20/24 // Set it to the local Subnet IP verified in the console. id: 21 // Set to the VLAN ID verified in the console. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Enter the VLAN ID you verified on the console instead of 21. addresses: - 192.168.0.20/24 // Set it to the local Subnet IP verified in the console. id: 21 // Set to the VLAN ID verified in the console. link: bond-mgt mtu: 1500code block. Add Vlan and set IP
- Replace the example code’s ID and IP with the assigned ID and IP.
Apply the changes to the system.
Color mode# netplan apply# netplan applyCode block. Reflect changes Check the interface status.
Color mode# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Linux – Configuring Subnet on CentOS/Red Hat
CentOS/Red Hat operating system, after adding a local Subnet, follow these steps to configure the network.
Caution
When adding a local Subnet or configuring the network incorrectly, be careful as the IP information in use may be deleted.
- Check the Bond Name for the local Subnet.Color mode
# sh /usr/local/bin/ip.sh# sh /usr/local/bin/ip.shcode block. Verify bonding - Modify the following command and execute it.Color mode
#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" // 1. Set the Bond Name you confirmed. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" // 1. Set the Bond Name you confirmed. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}Code block. IP configuration script - Check the interface status.Color mode
# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Configuring Subnet on Windows
After adding a local Subnet on the Windows operating system, follow these steps to configure the network.
Windows Start icon, right-click it, then run the Windows PowerShell(Administrator) program.
Check the Teaming name for the local Subnet.
Color modePS C:\> Get-NetAdapterPS C:\> Get-NetAdaptercode block. Check Windows interface After adding a new VLAN, set the IP.
- Enter the Teaming name confirmed in step 2, and the Vlan ID and local Subnet IP confirmed in the Console.Color mode
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”Code block. Create Teaming
- Enter the Teaming name confirmed in step 2, and the Vlan ID and local Subnet IP confirmed in the Console.
In the Windows Run menu, execute ncpa.cpl to check the interface status.
Add second connection (kr-west, kr-south)
If there is a local subnet connected to the Bare Metal Server, the guide for the second additional connection is below.
Because a Bonding was already created when connecting the first local Subnet, there is no procedure to create Bonding when connecting the second local Subnet.
Please refer to the details below.
Notice
This guide can be applied commonly to kr-west and kr-south.
Linux - Setting up Subnet on Ubuntu
To add a local Subnet and configure the network on an Ubuntu operating system, follow these steps.
After adding a new VLAN, set the IP.
- Replace the example code’s ID and IP with the assigned ID and IP.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Enter the VLAN ID you verified on the console instead of 21. addresses: - 192.168.0.20/24 // Set it to the local Subnet IP verified in the console. id: 21 // Set to the VLAN ID verified in the console. link: bond-mgt mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: bond-mgt: interfaces: - ens2f1 - ens4f1 mtu: 1500 parameters: mii-monitor-interval: 100 mode: active-backup transmit-hash-policy: layer2 ethernets: ens2f1: match: macaddress: 68:05:ca:d4:09:91 mtu: 1500 set-name: ens2f1 ens4f1: match: macaddress: 68:05:ca:d4:09:01 mtu: 1500 set-name: ens4f1 vlans: bond-mgt.20: addresses: - 192.168.0.10/24 id: 20 link: bond-mgt mtu: 1500 vlans: bond-mgt.21: // Enter the VLAN ID you verified on the console instead of 21. addresses: - 192.168.0.20/24 // Set it to the local Subnet IP verified in the console. id: 21 // Set to the VLAN ID verified in the console. link: bond-mgt mtu: 1500code block. Add Vlan and set IP
- Replace the example code’s ID and IP with the assigned ID and IP.
Apply the changes to the system.
Color mode# netplan apply# netplan applyCode block. Reflect changes Check the interface status.
Color mode# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Linux – Configuring Subnet on CentOS/Red Hat
After adding a local Subnet on CentOS/Red Hat operating systems, follow the steps below to configure the network.
Caution
When adding a local Subnet or configuring the network incorrectly, be careful as the IP information in use may be deleted.
- Check the Bond Name for the local Subnet.Color mode
# sh /usr/local/bin/ip.sh# sh /usr/local/bin/ip.shcode block. Verify bonding - Modify the following command and execute it.Color mode
#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" // 1. Set the Bond Name you confirmed. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}#!/usr/bin/bash IP_ADDR="10.1.1.3/24" // Set the local Subnet IP as observed in the Console. VLAN_ID="7" // Set the Vlan ID as observed in the console. BOND_NAME="bond-mgt" // 1. Set the Bond Name you confirmed. # add vlan nmcli conn add type vlan ifname "${BOND_NAME}.${VLAN_ID}" con-name "${BOND_NAME}.${VLAN_ID}" id ${VLAN_ID} dev ${BOND_NAME} nmcli con mod ${BOND_NAME}.${VLAN_ID} con-name "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.addresses ${IP_ADDR} nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv4.method manual nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" ipv6.method "ignore" nmcli con mod "Vlan ${BOND_NAME}.${VLAN_ID}" connect.autoconnect yes nmcli con up "Vlan ${BOND_NAME}.${VLAN_ID}" nmcli device reapply ${BOND_NAME}.${VLAN_ID}Code block. IP configuration script - Check the interface status.Color mode
# ip a or # bash /usr/local/bin/ip.sh# ip a or # bash /usr/local/bin/ip.shCode block. Interface lookup
Configuring Subnet on Windows
After adding a local Subnet on the Windows operating system, follow these steps to configure the network.
Windows Start icon, right-click it, then run the Windows PowerShell(Administrator) program.
Check the Teaming name for the local Subnet.
Color modePS C:\> Get-NetAdapterPS C:\> Get-NetAdaptercode block. Check Windows interface After adding a new VLAN, configure the IP.
- Enter the Teaming name confirmed in step 2, the Vlan ID confirmed in the Console, and the local Subnet IP.Color mode
PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-mgt -VlanID 20 -Name bond-mgt.20 PS C:\> Get-NetAdapter PS C:\> netsh interface ip set address bond-mgt.20 static “192.168.0.10/24”Code block. Create Teaming
- Enter the Teaming name confirmed in step 2, the Vlan ID confirmed in the Console, and the local Subnet IP.
In the Windows Run menu, execute ncpa.cpl to check the interface status.
Change IP
The IP can be changed to carry out migration, server replacement, and similar tasks.
Caution
- If you proceed with changing the IP, you will no longer be able to communicate using that IP, and you cannot cancel the IP change while it is in progress.
- If the server is running the Load Balancer service, you must delete the old IP from the LB server group and directly add the new IP as a member of the LB server group.
- Servers using Public NAT, Privat NAT must disable and reconfigure Public NAT, Privat NAT after an IP change.
- If you are using Public NAT and Privat NAT, first disable the use of Public NAT and Privat NAT, complete the IP change, and then reconfigure.
- Whether to use Public NAT and Privat NAT can be changed by clicking the Edit button for Public NAT IP and Privat NAT on the Bare Metal Server Details page.
Follow these steps to change the IP.
All Services > Compute > Bare Metal Server Click the menu. 1. Go to the Service Home page of the Bare Metal Server.
On the Service Home page, click the Bare Metal Server menu. 2. Go to the Bare Metal Server List page.
Bare Metal Server List page, click the server whose IP you want to change. Navigate to the Bare Metal Server Detail page.
On the Bare Metal Server Details page, click the Edit button next to the IP field.
When the popup notifying IP modification opens, click the Confirm button. 5. IP Change The popup window opens.
IP Change popup window’s Step 1, Step 2, Step 3 tasks should be performed sequentially.
Notice- When changing the IP, the detailed configuration method for the IP change step varies depending on the subnet of the IP to be changed. * Be sure to refer to the following example and proceed with the tasks step by step.
- When changing to an IP that uses the same subnet: Change to an IP of the same Subnet Reference
- When changing to an IP that uses a different subnet: Change to IP of a different Subnet See
- When each step is completed successfully, the task status in the upper right corner is displayed as Completed, and you can proceed to the next step.
- When performing the final check of Step 3, it is recommended to restart the server before proceeding with the inspection.
- When changing the IP, the detailed configuration method for the IP change step varies depending on the subnet of the IP to be changed. * Be sure to refer to the following example and proceed with the tasks step by step.
After confirming that all tasks have completed successfully, click the Confirm button.
Change to an IP in the same Subnet
This explains how to configure IP settings per operating system when the IP to be changed uses the same subnet.
Linux – centos/redhat operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When a pop-up notifying you of an IP change opens, click the Confirm button.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Enter the assigned IP from Step 1 and set the new IP on the server.
- In the following example, replace
172.17.34.150with the assigned IP address. - After checking the information of the Interface you want to change on the server, replace it with
bond-srv.9in the following example.Color mode# nmcli con mod "Vlan bond-srv.9" ipv4.addresses 172.17.34.150/24 # nmcli con mod "Vlan bond-srv.9" ipv4.method manual # nmcli device reapply bond-srv.9# nmcli con mod "Vlan bond-srv.9" ipv4.addresses 172.17.34.150/24 # nmcli con mod "Vlan bond-srv.9" ipv4.method manual # nmcli device reapply bond-srv.9Code block. IP settings to modify Notice- Setting the IP disconnects the terminal session.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
- In the following example, replace
When all tasks are completed, select the task completion checkbox for Step 2 in the IP 변경 popup window.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still have issues with terminal access, go to the All Services > Management > Support Center Contact Us menu and contact us.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.Color mode
# bash /usr/local/bin/ip.sh# bash /usr/local/bin/ip.shCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.
After all tasks are completed, restart the server and then perform a final check.
ReferenceIt is recommended to perform the final check after restarting the server.If the final inspection shows no issues, select the work‑completion checkbox for Step 3 in the IP change popup.
Linux – Ubuntu operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When a pop-up notifying you of an IP change opens, click the Confirm button.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Enter the assigned IP from Step 1 and set the new IP on the server.
- In the following example, replace
172.17.34.150/24with the assigned IP address. - After checking the information of the Interface you want to change on the server, replace it with
bond-srv.9in the following example.Color mode[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 # Enter the IP assigned in Step1. gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 # Enter the IP assigned in Step1. gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srvCode block. IP settings to modify
- In the following example, replace
Use the Netplan apply command to apply the changes to the system.
Color mode[root@localhost ~]# netplan apply[root@localhost ~]# netplan applyCode block. Run Netplan apply Notice- Setting the IP disconnects the terminal session.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
When all tasks are completed, select the task completion checkbox for Step 2 in the IP Change popup.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still have issues with terminal access, go to the All Services > Management > Support Center Contact Us menu and submit an inquiry.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the new IP is operating normally.Color mode
# bash /usr/local/bin/ip.sh# bash /usr/local/bin/ip.shCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the new IP is operating normally.
After all tasks are completed, restart the server and then perform a final check.
ReferenceIt is recommended to perform the final check after restarting the server.If there are no issues in the final inspection results, select the work completion checkbox for Step 3 in the IP Change popup window.
Windows operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When the popup notifying IP change verification opens, click the Confirm button.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Windows Start icon, right‑click it, then run Windows PowerShell(Administrator).
Enter the assigned IP from Step 1 and set the new IP on the server.
- In the following example, replace
172.17.34.150with the assigned IP address.Color modePS C:\> netsh interface ip set address "bond-srv.20" static 172.17.34.150 255.255.255.0PS C:\> netsh interface ip set address "bond-srv.20" static 172.17.34.150 255.255.255.0Code block. IP settings to modify Notice- Setting the IP disconnects the terminal session.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
- In the following example, replace
When all tasks are completed, select the task completion checkbox for Step 2 in the IP 변경 popup window.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still have issues with terminal access, go to the All Services > Management > Support Center Contact Us menu and contact us.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.Color mode
PS C:\> Get-NetIPAddress | Format-TablePS C:\> Get-NetIPAddress | Format-TableCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.
After all tasks are completed, restart the server and then perform a final check.
ReferenceIt is recommended to perform the final check after restarting the server.If there are no issues in the final inspection results, select the work completion checkbox for Step 3 in the IP Change popup window.
Change to IP of another Subnet
This explains how to configure IP settings for each operating system when the IP to be changed uses a different subnet.
Linux – centos/redhat operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When the popup notifying IP change verification opens, click the Confirm button.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Add a new VLAN and configure the IP to add the IP to the server.
- Add VLAN: Create the interface of the Vlan ID identified in Step 1. * In the following example, enter the assigned ID instead of
20. - IP configuration: Enter the IP assigned in Step 1. * In the following example, replace
192.168.0.10/24with the assigned IP address.Color mode# nmcli conn add type vlan ifname "bond-srv.20" con-name "bond-srv.20" id 20 dev bond-srv # nmcli con mod bond-srv.20 con-name "Vlan bond-srv.20" # nmcli con mod "Vlan bond-srv.20" ipv4.addresses 192.168.0.10/24 # nmcli con mod "Vlan bond-srv.20" ipv4.method manual # nmcli con mod "Vlan bond-srv.20" ipv6.method "ignore" # nmcli con up "Vlan bond-srv.20"# nmcli conn add type vlan ifname "bond-srv.20" con-name "bond-srv.20" id 20 dev bond-srv # nmcli con mod bond-srv.20 con-name "Vlan bond-srv.20" # nmcli con mod "Vlan bond-srv.20" ipv4.addresses 192.168.0.10/24 # nmcli con mod "Vlan bond-srv.20" ipv4.method manual # nmcli con mod "Vlan bond-srv.20" ipv6.method "ignore" # nmcli con up "Vlan bond-srv.20"Code block. IP settings to modify
- Add VLAN: Create the interface of the Vlan ID identified in Step 1. * In the following example, enter the assigned ID instead of
Set the default gateway for the new VLAN.
- Default gateway configuration: Enter the Default gateway IP assigned in Step 1. * In the following example, replace
192.168.0.1with the assigned Default gateway IP.Color mode# nmcli con mod "Vlan bond-srv.20" ipv4.gateway 192.168.0.1 # nmcli device reapply bond-srv.20# nmcli con mod "Vlan bond-srv.20" ipv4.gateway 192.168.0.1 # nmcli device reapply bond-srv.20Code block. IP settings to modify Notice- If you set a Default Gateway on a new VLAN, the terminal session gets disconnected.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
- Default gateway configuration: Enter the Default gateway IP assigned in Step 1. * In the following example, replace
When all tasks are completed, select the task completion checkbox for Step 2 in the IP 변경 popup window.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still experience problems with terminal access, navigate to the All Services > Management > Support Center Contact Us menu and submit an inquiry.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server subject to IP change using a NAT IP.
Verify the Default Gateway IP of the existing (pre-change) interface, then delete it.
- In the following example, replace
192.168.10.1with the IP you verified.Color mode# ip route del default via 192.168.10.1# ip route del default via 192.168.10.1Code block. Delete the Default Gateway IP of the existing interface
- In the following example, replace
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the changes were applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.Color mode
# netstat –nr # bash /usr/local/bin/ip.sh# netstat –nr # bash /usr/local/bin/ip.shCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the changes were applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.
Check the VLAN information of the existing IP and then delete it from the server.
- Enter the verified ID in place of
30in the following example.Color mode# nmcli con delete "Vlan bond-srv.30"# nmcli con delete "Vlan bond-srv.30"Code block. Delete the VLAN information of the existing IP.
- Enter the verified ID in place of
After all tasks are completed, restart the server and then perform a final check.
ReferenceIt is recommended to perform the final check after restarting the server.If the final inspection results show no issues, select the work‑completion checkbox for Step 3 in the IP Change popup window.
Linux – Ubuntu operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When a popup that notifies IP change verification opens, click the Confirm button.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Add a new VLAN and set the IP and Default Gateway to add the IP to the server.
- In the following example, this is the part where content is added at the bottom of the Step 1 task description.
- In the following example, enter the assigned ID and IP instead of ID and IP.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv # Create the interface for the Vlan ID identified in Step1. # Enter the IP assigned in Step1. # Enter the Default gateway IP assigned in Step1. bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv # Create the interface for the Vlan ID identified in Step1. # Enter the IP assigned in Step1. # Enter the Default gateway IP assigned in Step1. bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500Code block. IP settings to modify
Use the Netplan apply command to apply the changes to the system.
Color mode[root@localhost ~]# netplan apply[root@localhost ~]# netplan applyCode block. Run Netplan apply Notice- If you set a new Default Gateway, the terminal session will be disconnected.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
When all tasks are completed, select the task completion checkbox for Step 2 in the IP 변경 popup window.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still experience problems with terminal access, navigate to the All Services > Management > Support Center Contact Us menu and submit an inquiry.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server subject to IP change using a NAT IP.
Verify the Default Gateway IP of the existing (pre-change) interface, then delete it.
- In the following example, the Delete this line row is the part that gets deleted.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 #Delete this line id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: addresses: - 172.17.34.150/24 gateway4: 172.17.34.2 #Delete this line id: 9 link: bond-srv mtu: 1500 bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1500Code block. Delete the Default Gateway IP of the existing interface
- In the following example, the Delete this line row is the part that gets deleted.
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.Color mode
# netstat –nr # bash /usr/local/bin/ip.sh# netstat –nr # bash /usr/local/bin/ip.shCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.
Delete the existing IP.
- In the following example, the Delete this line row is the part that gets deleted.Color mode
[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: #Delete this line addresses: #Delete this line - 172.17.34.150/24 # Delete this line gateway4: 172.17.34.2 #Delete this line id: 9 # Delete this line link: bond-srv #Delete this line mtu: 1500 #Delete this line bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1[root@localhost ~]# vi /etc/netplan/50-cloud-init.yaml network: bonds: ...................... Omitted ethernets: ...................... Omitted vlans: bond-srv.9: #Delete this line addresses: #Delete this line - 172.17.34.150/24 # Delete this line gateway4: 172.17.34.2 #Delete this line id: 9 # Delete this line link: bond-srv #Delete this line mtu: 1500 #Delete this line bond-srv.350: addresses: - 172.16.87.150/24 routes: - to: 172.17.87.0/24 via: 172.16.87.1 - to: 172.17.87.0/24 via: 172.16.87.1 id: 350 link: bond-srv bond-srv.20: addresses: - 192.168.0.10/24 gateway4: 192.168.0.1 id: 20 link: bond-srv mtu: 1Code block. Delete existing IP
- In the following example, the Delete this line row is the part that gets deleted.
Apply the changes to the system.
Color mode[root@localhost ~]# netplan apply [root@localhost ~]# ip link delete bond-srv.9 # Additional steps when deleting VLAN[root@localhost ~]# netplan apply [root@localhost ~]# ip link delete bond-srv.9 # Additional steps when deleting VLANCode block. Apply changes After all tasks are completed, restart the server and then perform a final check.
Reference
It is recommended to perform the final check after restarting the server.
- If the final inspection results show no issues, select the work‑completion checkbox for Step 3 in the IP Change popup window.
Windows operating system
Step 1
Follow the steps below and proceed with Step 1.
- Select the Subnet to modify.
- Enter the IP to change.
- Click the IP Allocation Request button.
- When the popup indicating IP change verification opens, click the Confirm button.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.CautionIf you proceed with the IP allocation request of Step 1, you cannot cancel or restore the IP change.
- When the operation completes successfully, Vlan ID check, Default Gateway check information is displayed, and the operation status in the upper right corner shows Completed.
Step 2
Follow the steps below to perform Step 2.
For the IP change operation, connect to the target server using the NAT IP.
NoticeTo prevent communication failures during operation, it is recommended to connect through another Virtual Server or Bare Metal Server created in the same subnet.Windows Start icon, right-click, then run Windows PowerShell(Administrator).
Add a VLAN and configure the IP and default gateway.
- Add VLAN: Create the interface of the Vlan ID identified in Step 1. * In the following example, enter the assigned ID instead of
20. - IP configuration: Enter the IP assigned in Step 1. * In the following example, replace
46with the ifindex obtained using Get‑NetAdapter, and replace 192.168.0.10 with the assigned IP address. - Default gateway configuration: Enter the Default gateway IP assigned in Step 1. * In the following example, replace
192.168.0.1with the assigned Default gateway IP.Color modePS C:\> Add-NetLbfoTeamNIC -Team bond_bond-srv -VlanID 20 -Name bond-srv.20 -Confirm:$false PS C:\> Get-NetAdapter PS C:\> New-NetIPAddress -InterfaceIndex 46 -IPAddress 192.168.0.10 -PrefixLength 24 –defaultgateway 192.168.0.1PS C:\> Add-NetLbfoTeamNIC -Team bond_bond-srv -VlanID 20 -Name bond-srv.20 -Confirm:$false PS C:\> Get-NetAdapter PS C:\> New-NetIPAddress -InterfaceIndex 46 -IPAddress 192.168.0.10 -PrefixLength 24 –defaultgateway 192.168.0.1Code block. IP settings to modify Notice- If you set a new Default Gateway, the terminal session will be disconnected.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
- Add VLAN: Create the interface of the Vlan ID identified in Step 1. * In the following example, enter the assigned ID instead of
When all tasks are completed, select the task completion checkbox for Step 2 in the IP 변경 popup window.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.Notice
- If the task status of Step 2 has changed to Completed but you still experience problems with terminal access, navigate to the All Services > Management > Support Center Contact Us menu and submit an inquiry.
- When the task completes successfully, the task status in the upper right corner will be displayed as Completed.
Step 3
Proceed with Step 3 according to the following procedure.
Connect to the server subject to IP change using a NAT IP.
Run the interface index (ifindex) to check the existing Default Gateway IP.
Color modePS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. OmittedPS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. Omittedcode block. Run Get-NetAdapter Color modePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.35.0/24 172.17.35.1 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStore 30 0.0.0.0/0 172.17.34.1 1 ActiveStorePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.35.0/24 172.17.35.1 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStore 30 0.0.0.0/0 172.17.34.1 1 ActiveStoreCode block. Execute -ifindex Delete the existing Default Gateway IP.
- In the following example, replace
30with the ifindex obtained via Get-NetAdapter, and replace172.17.34.1with the IP you obtained.Color modePS C:\> Remove-NetRoute -ifIndex 30 -DestinationPrefix 0.0.0.0/0 -NextHop 172.17.34.1 -Confirm:$falsePS C:\> Remove-NetRoute -ifIndex 30 -DestinationPrefix 0.0.0.0/0 -NextHop 172.17.34.1 -Confirm:$falseCode block. Delete Default Gateway IP Color modePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStorePS C:\> get-netroute -ifindex 30 ifIndex DestinationPrefix NextHop RouteMetric PolicyStore ------- ----------------- ------- ----------- ----------- 30 255.255.255.255/32 0.0.0.0 256 ActiveStore 30 224.0.0.0/4 0.0.0.0 256 ActiveStore 30 172.17.34.255/32 0.0.0.0 256 ActiveStore 30 172.17.34.14/32 0.0.0.0 256 ActiveStore 30 172.17.34.0/24 0.0.0.0 256 ActiveStoreCode block. Execute -ifindex Notice- If you delete the existing Default Gateway, the terminal session will be disconnected.
- Step 2 After completing the task, if the task status changes to Completed, you can reconnect to the terminal.
- In the following example, replace
Connect to the server to be changed using the NAT IP and check its communication status.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.Color mode
PS C:\> netstat –nr | findstr Default PS C:\> Get-NetIPAddress | Format-TablePS C:\> netstat –nr | findstr Default PS C:\> Get-NetIPAddress | Format-TableCode block. Communication status check ReferenceThe NAT IP does not change.
- Use the following command to verify whether any pre‑change configuration information remains and whether the change was applied correctly. * If you can successfully connect to the server targeted for IP change, the changed IP is in normal communication state.
Check the VLAN information of the existing IP in the Team information.
Color modePS C:\> Get-NetLbfoTeam Name : bond_bond-srv Members : {ens6f1, ens3f1} TeamNics : {bond-srv, bond-srv.9} Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-iscsi Members : {ens6f0, ens3f0} TeamNics : bond-iscsi Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-backup Members : {ens2f0, ens4f1} TeamNics : bond-backup Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. OmittedPS C:\> Get-NetLbfoTeam Name : bond_bond-srv Members : {ens6f1, ens3f1} TeamNics : {bond-srv, bond-srv.9} Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-iscsi Members : {ens6f0, ens3f0} TeamNics : bond-iscsi Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up Name : bond_bond-backup Members : {ens2f0, ens4f1} TeamNics : bond-backup Team ingMode : SwitchIndependent LoadBalancingAlgorithm : Dynamic Status : Up PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv.9 Microsoft Network Adapter Multiple...#4 30 Up 40-A6-B7-27-96-D5 50 Gbps bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. Omittedcode block. Run Get-NetLbfoTeam Delete the Vlan information of the existing IP from the server.
- Enter the verified ID in place of
30in the following example.Color modePS C:\> Remove-NetLbfoTeamNic -Team bond_bond-srv -VlanID 30 -Confirm:$false PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. OmittedPS C:\> Remove-NetLbfoTeamNic -Team bond_bond-srv -VlanID 30 -Confirm:$false PS C:\> Get-NetAdapter Name InterfaceDescription ifIndex Status MacAddress LinkSpeed ---- -------------------- ------- ------ ---------- --------- bond-srv Microsoft Network Adapter Multiple...#3 19 Up 40-A6-B7-27-96-D5 50 Gbps bond-iscsi Microsoft Network Adapter Multiple...#2 18 Up 40-A6-B7-27-96-D4 50 Gbps bond-backup Microsoft Network Adapter Multiplexo... 22 Up 68-05-CA-C9-EB-88 20 Gbps eno2 Intel(R) Ethernet Connection X722 fo... 12 Disabled 38-68-DD-36-A0-59 1 Gbps ens3f0 Intel(R) Ethernet Network Adapter XX... 11 Up 40-A6-B7-27-96-D4 25 Gbps ………………………………………….. Omittedcode block. Run Get-NetLbfoTeam
- Enter the verified ID in place of
After all tasks are completed, restart the server and then perform a final check.
ReferenceIt is recommended to perform the final check after restarting the server.If the final inspection results show no issues, select the work‑completion checkbox for Step 3 in the IP Change popup window.
Setting up RHEL Repository
The Samsung Cloud Platform Console provides the SCP RHEL Repository to support user environments where external access is restricted, such as VPC Private Subnet.
You can use the RHEL Repository to install and download the same packages as the official RHEL Repository.
To configure the RHEL Repository, refer to the RHEL Repository 설정 가이드.
안내
- If a user created RHEL before August 2025 through the Samsung Cloud Platform Console, they must modify the RHEL Repository settings.
- Since the SCP RHEL Repository synchronizes with each region’s local repository according to an internal schedule, it is recommended to switch to an external public mirror site to apply the latest patches quickly.
- Samsung Cloud Platform provides the latest version repository for the given major version.
4.2.1 - Install ServiceWatch Agent
Users can install the ServiceWatch Agent on a Bare Metal Server to collect custom metrics and logs.
Reference
Collecting custom metrics/logs via the ServiceWatch Agent is currently available only on Samsung Cloud Platform For Enterprise. It will also be available in other offerings in the future.
Caution
Collecting metrics through the ServiceWatch Agent is classified as custom metrics and, unlike the default collected metrics, incurs charges; therefore, it is recommended to remove or disable unnecessary metric collection settings.
ServiceWatch Agent
On a Bare Metal Server, the agents that need to be installed to collect ServiceWatch’s custom metrics and logs can be divided into two main types. It is a Prometheus Exporter and Open Telemetry Collector.
| Category | Detailed description | |
|---|---|---|
| Prometheus Exporter | Provide metrics of a specific application or service in a format that Prometheus can scrape
| |
| Open Telemetry Collector | Acts as a centralized collector that gathers telemetry data such as metrics and logs from distributed systems, processes (filtering, sampling, etc.) it, and exports it to multiple backends (e.g., Prometheus, Jaeger, Elasticsearch, etc.)
|
Table. Explanation of Prometheus Exporter and Open Telemetry Collector
Reference
The ServiceWatch Agent guide can be used in the same way as Virtual Server.
For more details, see Virtual Server > ServiceWatch Agent.
Pre-configuration for Using ServiceWatch Agent
To use the ServiceWatch Agent, please refer to Prerequisite Settings for ServiceWatch Agent and prepare the prerequisite settings.
4.2.2 - Setting up RHEL Repo and WKMS
The Samsung Cloud Platform Console provides the SCP RHEL Repository to support user environments where external access is restricted, such as VPC Private Subnet. You can use the SCP RHEL Repository to install and download the same packages as the official RHEL Repository.
guide
- If a user created RHEL before August 2025 through the Samsung Cloud Platform Console, they must modify the RHEL Repository settings.
- Since the SCP RHEL Repository synchronizes with each Region Local Repository according to an internal schedule, it is recommended to switch to an external public mirror site to apply the latest patches quickly.
- Samsung Cloud Platform provides the latest repository for the specified major version.
RHEL Repository Configuration Guide
When using RHEL, you can configure the SCP RHEL Repository to install and download the same packages as the official RHEL Repository. To set up the RHEL Repository, follow these steps.
On the Virtual Server, as the OS root user, use the cat command to check the
/etc/yum.repos.d/scp.rhel8.repoor/etc/yum.repos.d/scp.rhel9.repoconfiguration.Color modecat /etc/yum.repos.d/scp.rhel8.repocat /etc/yum.repos.d/scp.rhel8.repoCode block. Verify repo configuration (RHEL8) Color modecat /etc/yum.repos.d/scp.rhel9.repocat /etc/yum.repos.d/scp.rhel9.repoCode block. Verify repo configuration (RHEL9) - When checking the configuration file, the following result is displayed.Color mode
[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstream[rhel-8-baseos] name=rhel-8-baseos gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos [rhel-8-baseos-debug] name=rhel-8-baseos-debug gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/baseos-debug [rhel-8-appstream] name=rhel-8-appstream gpgcheck=0 enabled=1 baseurl=http://scp-rhel8-ip/rhel/8/appstreamCode block. Check repo configuration (RHEL8) Color mode[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1[rhel-9-for-x86_64-baseos-rpms] name=rhel-9-for-x86_64-baseos-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/baseos gpgcheck=0 enabled=1 [rhel-9-for-x86_64-appstream-rpms] name=rhel-9-for-x86_64-appstream-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/appstream gpgcheck=0 enabled=1 [codeready-builder-for-rhel-9-x86_64-rpms] name=codeready-builder-for-rhel-9-x86_64-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/codeready-builder gpgcheck=0 enabled=1 [rhel-9-for-x86_64-highavailability-rpms] name=rhel-9-for-x86_64-highavailability-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/ha gpgcheck=0 enabled=1 [rhel-9-for-x86_64-supplementary-rpms] name=rhel-9-for-x86_64-supplementary-rpms baseurl=http://scp-rhel9-ip/rhel/$releasever/x86_64/supplementary gpgcheck=0 enabled=1Code block. Verify repo configuration (RHEL9)
- When checking the configuration file, the following result is displayed.
Use a text editor (e.g., vim) to open the
/etc/hostsfile.Modify the
/etc/hostsfile with the following content and save it.Color mode198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ip198.19.2.13 scp-rhel8-ip scp-rhel9-ip scp-rhel-ipcode block. Change /etc/hosts file settings Use the yum command to verify the RHEL Repository connection configured on the server.
Color modeyum repolist –vyum repolist –vCode block. Verify repository connection settings - If the RHEL repository is successfully connected, you can view the repository list.Color mode
Repo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repoRepo-id : rhel-8-appstream Repo-name : rhel-8-appstream Repo-revision : 1718903734 Repo-updated : Fri 21 Jun 2024 02:15:34 AM KST Repo-pkgs : 38,260 Repo-available-pkgs: 25,799 Repo-size : 122 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/appstream Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos Repo-name : rhel-8-baseos Repo-revision : 1718029433 Repo-updated : Mon 10 Jun 2024 11:23:52 PM KST Repo-pkgs : 17,487 Repo-available-pkgs: 17,487 Repo-size : 32 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repo Repo-id : rhel-8-baseos-debug Repo-name : rhel-8-baseos-debug Repo-revision : 1717662461 Repo-updated : Thu 06 Jun 2024 05:27:41 PM KST Repo-pkgs : 17,078 Repo-available-pkgs: 17,078 Repo-size : 100 G Repo-baseurl : http://scp-rhel8-ip/rhel/8/baseos-debug Repo-expire : 172,800 second(s) (last: Thu 08 Aug 2024 07:27:57 AM KST) Repo-filename : /etc/yum.repos.d/scp.rhel8.repoCode block. Check repository list
- If the RHEL repository is successfully connected, you can view the repository list.
Windows Key Management Service Configuration Guide
When using Windows Server on Samsung Cloud Platform, you can authenticate genuine licenses by utilizing the Key Management Service provided by Samsung Cloud Platform. To authenticate genuine copies using the Key Management Service, follow these steps.
Right-click the Windows Start icon, then run cmd from Windows PowerShell (Administrator) or the Windows Run menu.
Run the following command in Windows PowerShell(Administrator) or cmd to register the KMS Server.
Color modeslmgr /skms 198.19.2.23:1688slmgr /skms 198.19.2.23:1688code block. WKMS configuration Run the KMS Server registration command, verify the notification popup indicating successful registration, and then click the OK button.

Run the following command in Windows PowerShell(Administrator) or cmd to activate Windows.
Color modeslmgr /atoslmgr /atoCode block. Windows Server activation settings After confirming the notification popup indicating that activation was successful, click the OK button.

In Windows PowerShell(Administrator) or cmd, run the following command to verify that the product is properly activated.
Color modeslmgr /dlvslmgr /dlvCode block. Verify Windows Server activation After confirming the notification popup indicating that product activation was successful, click the OK button.

4.3 - API Reference
API Reference
4.4 - CLI Reference
CLI Reference
4.5 - Release Note
Bare Metal Server
2026.07.16
FEATURE
CPU configuration option support and other feature changes- CPU configuration options are supported.
- Through the CPU setting options, you can activate only the desired number of CPU cores and adjust the number of threads per core.
- Even if you change the number of cores, the usage fee remains the same.
- When creating a Bare Metal Server, up to 20 can be created simultaneously.
- When creating two or more servers, you can automatically generate names in the format server name + creation number.
2026.03.19
FEATURE
Add new server type- The 4th generation BM based on the Intel 6th generation (Granite Rapids) Processor has been released.
- Bare Metal Server s4 and h4 server types have been added.
- Detailed information about the s4/h4 server type can be found in the s3/h3 server type.
2025.10.23
FEATURE
Add Local disk partition feature- Provides local disk partition functionality
- Now you can create and use up to 10 Local disk partitions.
2025.07.01
FEATURE
Add new features and provide additional OS Image- You can terminate multiple resources simultaneously from the Bare Metal Server list.
- You can change the IP of a regular Subnet.
- OS Image has been added.
- RHEL 8.10, Ubuntu 24.04
2025.02.27
FEATURE
Placement Group functionality and addition of OS Image, server type- Add Bare Metal Server feature
- Distribute servers belonging to the same Placement group across different racks.
- Additional OS images provided (RHEL 9.4, Rocky Linux 8.6, Rocky Linux 9.4)
- Add 3rd‑generation (s3/h3) server type based on Intel 4th‑generation (Sapphire Rapids) Processor. * For detailed information, refer to Bare Metal Server 서버 타입.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, and Service Home, tags, etc., have been updated to reflect common CX changes.
2024.10.01
NEW
Bare Metal Server Service Official Version Release- We have officially launched the Bare Metal Server service.
- We have launched a Bare Metal Server service that lets customers use a physical server without virtualization, exclusively for themselves.
5 - Multi-node GPU Cluster
5.1 - Overview
Service Overview
Multi-node GPU Cluster is a service that provides physical GPU servers without virtualization for large-scale high-performance AI computation. You can use two or more Bare Metal Servers equipped with GPUs to cluster multiple GPUs, and conveniently operate GPU servers in conjunction with Samsung Cloud Platform’s high‑performance storage and networking services.
Provided Features
The Multi-node GPU Cluster provides the following features.
- Auto Provisioning and Management: Through the web-based Console, you can easily provision servers of the standard GPU Bare Metal model equipped with 8 GPUs and manage resources and costs.
- Network Connection: You can cluster multiple GPUs on two or more Bare Metal Servers via high‑speed interconnects, and by configuring a GPU Direct RDMA (Remote Direct Memory Access) environment, you can directly process data I/O between GPU memories, enabling high‑speed AI/Machine Learning computation.
- Storage Connection: Provides various additional attached storage besides the OS disk. * High-performance SSD NAS File Storage, Block Storage, and Object Storage directly integrated with a high-speed network can also be used together.
- Network Configuration Management: The server’s subnet/IP can be easily changed from the values set at initial creation. * NAT IP provides a management feature that allows you to enable or disable it as needed.
- Monitoring: You can view monitoring information for computing resources such as CPU, GPU, Memory, and Disk through Cloud Monitoring. * To use the Cloud Monitoring service of a Multi-node GPU Cluster, you need to install the Agent. * Please install the Agent to ensure stable service. * For more details, please refer to Multi-node GPU Cluster Monitoring Metrics.
- Terraform Provision: Provides an IaC environment via Terraform.
Component
Multi-node GPU Cluster provides GPUs as a Bare Metal Sever type with standard images and server types. NVSwitch and NVLink are provided.
Specifications by GPU Type
GPU (Graphic Processing Unit) is specialized for parallel operations that process large amounts of data quickly, enabling large-scale parallel computation in fields such as artificial intelligence (AI) and data analysis.
The following are the specifications of GPU types offered by the Multi-node GPU Cluster service.
| Category | H100 Type | B300 Type |
|---|---|---|
| GPU Architecture | NVIDIA Hopper | NVIDIA Blackwell Ultra |
| GPU Memory | 80 GiB | 268 GiB |
| GPU Transistors | 80 billion 4N TSMC | 208 billion 4NP TSMC |
| FP16 Tensor Core (Dense) | 989 TFLOPs | 2.25 PFLOPs |
| FP8 Tensor Core (Dense) | 1979 TFLOPs | 4.5 PFLOPs |
| FP4 Tensor Core (Dense) | Not supported | 13.5 PFLOPs |
| GPU Memory Bandwidth | 3,352 GB/s HBM3 | 8 TB/s HBM3e |
| NVLink performance | NVLink 4 | NVLink 5 |
| NVLink Signaling Rate | 25 GB/s (x18) | 50 GB/s (x18) |
| NVSwitch GPU-to-GPU bandwidth | 900 GB/s | 1.8 TB/s |
| Total NVSwitch aggregate bandwidth | 7.2 TB/s | 14.4 TB/s |
Table. GPU Type specifications
OS and GPU driver version
The operating systems (OS) supported by the Multi-node GPU Cluster are as follows.
| OS | OS version | GPU driver version |
|---|---|---|
| Ubuntu | 22.04 | 535.86.10, 535.183.06 |
| Ubuntu | 24.04 | 580.105.08 |
Table. Multi-node GPU Cluster OS and GPU driver version
Server type
The format of server types provided by the Multi-node GPU Cluster is as follows.
- Example: when the server type is g2c96h8_metal
| Category | example | Detailed description |
|---|---|---|
| Server generation | g2 | Provided server generation
|
| CPU | c96 | Number of cores
|
| GPU | h8 | GPU type and quantity
|
Table. Multi-node GPU Cluster server type format
Reference
For detailed information about the server types provided by Multi-node GPU Cluster, refer to Multi-node GPU Cluster Server Types.
Preceding Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
Table. Multi-node GPU Cluster preliminary service
5.1.1 - Server type
Multi-node GPU Cluster server type
Multi-node GPU Cluster is categorized based on the GPU Type it provides, and the GPU used in a Multi-node GPU Cluster is determined by the server type selected when creating a GPU Node. Select the server type based on the specifications of the application you want to run on a multi-node GPU cluster.
The server types supported by the Multi-node GPU Cluster are as follows.
- Example: when the server type is g2c96h8_metal.
Category example Detailed description Server generation g2 Provided server generation - g2
- g means GPU server specification
- 2 means generation
CPU c96 Number of cores - c96: Allocated cores are physical cores
GPU h8 GPU type and quantity - h8: h means GPU type, and 8 means GPU quantity
Table. Multi-node GPU Cluster server type format - g2
g2 server type
The g2 server type is a GPU Bare Metal Server that uses NVIDIA H100 SXM GPUs, suitable for large-scale high-performance AI computation.
- 8 NVIDIA Hopper Architecture-based H100 GPUs provided
- Provides 1,979 TFLOPS FP8 Tensor Core performance per GPU, 989 TFLOPS FP16 Tensor Core performance.
- Supports up to 96 vCPUs and 2,048 GB of memory
- Supports up to 1,600 Gb/s NVIDIA InfiniBand RDMA network.
- Service network up to 100 Gbps
- 900 GB/s GPU P2P communication via NVSwitch within a node
| Server type | GPU | GPU Memory | CPU(Core) | Memory | Disk | GPU P2P |
|---|---|---|---|---|---|---|
| g2c96h8_metal | H100 | 640 GiB | 96 vCore | 2 TB | SSD (OS) 960 GB * 2, NVMeSSD 3.84 TB * 4 | 900 GB/s NVSwitch |
Table. Multi-node GPU Cluster server type specifications > H100 server type
g3 server type
The g3 server type is a GPU Bare Metal Server that uses NVIDIA B300 SXM GPUs, suitable not only for large-scale high-performance AI computation but also for LLM inference and AI deployment for generative AI.
- 8 NVIDIA Blackwell Ultra Architecture-based B300 GPUs provided
- Provides 13.5 PFLOPS FP4 Tensor Core and 4.5 PFLOPS FP8 Tensor Core performance per GPU.
- Supports up to 128 vCPUs and 4,096 GB of memory
- Supports up to 6,400 Gb/s NVIDIA InfiniBand RDMA network
- Service network up to 100 Gbps
- 1.8 TB/s GPU P2P communication via NVSwitch within a node
| Server type | GPU | GPU Memory | CPU(Core) | Memory | Disk | GPU P2P |
|---|---|---|---|---|---|---|
| g3c128b8_metal | B300 | 2.1 TiB | 128 vCore | 4 TB | SSD (OS) 960 GB * 2, NVMeSSD 3.84 TB * 4 | 1.8 TB/s NVSwitch |
Table. Multi-node GPU Cluster server type specifications > B300 server type
5.1.2 - Monitoring Metrics
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Accordingly, from after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With a new alternative service, you can continuously perform resource monitoring by leveraging ServiceWatch released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a seamless monitoring environment.
If you are collecting metrics and logs through the Cloud Monitoring Agent, you need to switch to the ServiceWatch Agent.
For more details about ServiceWatch, please refer to ServiceWatch Overview.
Detailed information about ServiceWatch Agent: please refer to the ServiceWatch Agent
Multi-node GPU Cluster Monitoring Metrics
The table below shows the monitoring metrics of a Multi-node GPU Cluster that can be viewed through Cloud Monitoring.
Guide
In a Multi-node GPU Cluster, users must install the Agent themselves via the guide to view monitoring metrics. Before using the stable service, please be sure to install the Agent. For instructions on installing the Agent and detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
Multi-node GPU Cluster [Cluster]
| Performance items | Detailed description | unit |
|---|---|---|
| Memory Total [Basic] | bytes of usable memory | bytes |
| Memory Used [Basic] | Current memory usage in bytes | bytes |
| Memory Swap In [Basic] | bytes of the replaced memory | bytes |
| Memory Swap Out [Basic] | bytes of the replaced memory | bytes |
| Memory Free [Basic] | bytes of unused memory | bytes |
| Disk Read Bytes [Basic] | Read bytes | bytes |
| Disk Read Requests [Basic] | Number of read requests | cnt |
| Disk Write Bytes [Basic] | write bytes | bytes |
| Disk Write Requests [Basic] | Number of write requests | cnt |
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Instance State [Basic] | Instance status | state |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Dropped [Basic] | Incoming packet drop | cnt |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Dropped [Basic] | Transmit packet drop | cnt |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. Multi-node GPU Cluster [Cluster] Monitoring Metrics (default)
| Performance items | Detailed description | unit |
|---|---|---|
| Cluster GPU Count | GPU Count SUM in Cluster
| cnt |
| Cluster GPU Count In Use | Number of GPUs being used by jobs within the cluster
| cnt |
| Cluster GPU Usage | GPU Utilization AVG within the cluster
| % |
| Cluster GPU Memory Usage [Avg] | Cluster GPU Memory Utilization AVG
| % |
Table. Multi-node GPU Cluster [Cluster] Additional monitoring metrics (Agent installation required)
Multi-node GPU Cluster [Node]
| Performance items | Detailed description | unit |
|---|---|---|
| Memory Total [Basic] | bytes of usable memory | bytes |
| Memory Used [Basic] | Current memory usage in bytes | bytes |
| Memory Swap In [Basic] | bytes of the replaced memory | bytes |
| Memory Swap Out [Basic] | bytes of the replaced memory | bytes |
| Memory Free [Basic] | bytes of unused memory | bytes |
| Disk Read Bytes [Basic] | Read bytes | bytes |
| Disk Read Requests [Basic] | Number of read requests | cnt |
| Disk Write Bytes [Basic] | write bytes | bytes |
| Disk Write Requests [Basic] | Number of write requests | cnt |
| CPU Usage [Basic] | Average system CPU usage over 1 minute | % |
| Instance State [Basic] | Instance status | state |
| Network In Bytes [Basic] | Received bytes | bytes |
| Network In Dropped [Basic] | Incoming packet drop | cnt |
| Network In Packets [Basic] | Number of received packets | cnt |
| Network Out Bytes [Basic] | sent bytes | bytes |
| Network Out Dropped [Basic] | Transmit packet drop | cnt |
| Network Out Packets [Basic] | Number of transmitted packets | cnt |
Table. Multi-node GPU Cluster [Node] Monitoring Metrics (provided by default)
| Performance items | Detailed description | unit |
|---|---|---|
| GPU Count | Number of GPUs | cnt |
| GPU Temperature | GPU temperature | ℃ |
| GPU Usage | utilization | % |
| GPU Usage [Avg] | Overall average GPU utilization (%) | % |
| GPU Power Cap | Maximum power capacity of the GPU | W |
| GPU Power Usage | Current GPU power usage | W |
| GPU Memory Usage [Avg] | GPU Memory Uti. AVG | % |
| GPU Count in use | Number of GPUs in use by jobs on the node | cnt |
| Execution Status for nvidia-smi | Result of running the nvidia-smi command | status |
| Core Usage [IO Wait] | Ratio of CPU time spent in wait state (disk wait) | % |
| Core Usage [System] | Proportion of CPU time spent in kernel space | % |
| Core Usage [User] | Proportion of CPU time spent in user space | % |
| CPU Cores | The number of CPU cores on the host. The maximum value of the unnormalized ratio is 100%* of a core. The unnormalized ratio already incorporates this value, and its maximum is 100%* of a core. | cnt |
| CPU Usage [Active] | Percentage of CPU time used excluding Idle and IOWait states (when all 4 cores are used at 100%: 400%) | % |
| CPU Usage [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage [IO Wait] | This is the proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage [System] | Percentage of CPU time used by the kernel (when all 4 cores are used at 100%: 400%) | % |
| CPU Usage [User] | Percentage of CPU time used in user space. (If all 4 cores are used at 100%, it is 400%) | % |
| CPU Usage/Core [Active] | Percentage of CPU time used excluding Idle and IOWait states (value normalized by the number of cores; 100% when all four cores are fully utilized) | % |
| CPU Usage/Core [Idle] | It is the proportion of CPU time spent in idle state. | % |
| CPU Usage/Core [IO Wait] | This is the proportion of CPU time spent in a waiting state (disk wait). | % |
| CPU Usage/Core [System] | Percentage of CPU time used by the kernel (value normalized by the number of cores; 100% when all 4 cores are fully utilized) | % |
| CPU Usage/Core [User] | Percentage of CPU time used in user space. (Value normalized by the number of cores; 100% when all 4 cores are fully utilized) | % |
| Disk CPU Usage [IO Request] | It is the proportion of CPU time during which I/O requests for the device were executed (device bandwidth utilization). If this value approaches 100%, the device becomes saturated. | % |
| Disk Queue Size [Avg] | The average queue length of requests executed for the device. | num |
| Disk Read Bytes | The number of bytes read per second from the device. | bytes |
| Disk Read Bytes [Delta Avg] | Average of system.diskio.read.bytes_delta for individual disks | bytes |
| Disk Read Bytes [Delta Max] | Maximum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Min] | Minimum system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta Sum] | Sum of the system.diskio.read.bytes_delta of individual disks | bytes |
| Disk Read Bytes [Delta] | Delta of the system.diskio.read.bytes value for each disk | bytes |
| Disk Read Bytes [Success] | Total number of bytes successfully read. On Linux, assuming a sector size of 512, it is the number of sectors read multiplied by 512. | bytes |
| Disk Read Requests | Number of read requests to the disk device per second | cnt |
| Disk Read Requests [Delta Avg] | Average of the system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Max] | Maximum system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Min] | Minimum of system.diskio.read.count_delta for individual disks | cnt |
| Disk Read Requests [Delta Sum] | Sum of system.diskio.read.count_delta of individual disks | cnt |
| Disk Read Requests [Success Delta] | Delta of system.diskio.read.count for each disk | cnt |
| Disk Read Requests [Success] | Total number of successful reads | cnt |
| Disk Request Size [Avg] | Average size of requests executed on the device (unit: sectors). | num |
| Disk Service Time [Avg] | Average service time (ms) of input requests executed on the device. | ms |
| Disk Wait Time [Avg] | Average time taken for requests executed on the supported device. | ms |
| Disk Wait Time [Read] | Average disk wait time | ms |
| Disk Wait Time [Write] | Average disk wait time | ms |
| Disk Write Bytes [Delta Avg] | Average of system.diskio.write.bytes_delta for each disk | bytes |
| Disk Write Bytes [Delta Max] | Maximum system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta Min] | Minimum of system.diskio.write.bytes_delta for individual disks | bytes |
| Disk Write Bytes [Delta Sum] | Sum of the system.diskio.write.bytes_delta of individual disks | bytes |
| Disk Write Bytes [Delta] | Delta of the system.diskio.write.bytes value for each disk | bytes |
| Disk Write Bytes [Success] | Total number of bytes successfully written. On Linux, assuming a sector size of 512, it is the number of sectors written multiplied by 512. | bytes |
| Disk Write Requests | Number of write requests to the disk device per second | cnt |
| Disk Write Requests [Delta Avg] | Average of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Max] | Maximum system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Min] | Minimum of system.diskio.write.count_delta for individual disks | cnt |
| Disk Write Requests [Delta Sum] | Sum of the system.diskio.write.count_delta of individual disks | cnt |
| Disk Write Requests [Success Delta] | Delta of system.diskio.write.count for each disk | cnt |
| Disk Write Requests [Success] | Total number of successful writes | cnt |
| Disk Writes Bytes | It is the number of bytes per second written to the device. | bytes |
| Filesystem Hang Check | filesystem (local/NFS) hang check (normal:1, abnormal:0) | status |
| Filesystem Nodes | It is the total number of file nodes in the file system. | cnt |
| Filesystem Nodes [Free] | It is the total number of available file nodes in the file system. | cnt |
| Filesystem Size [Available] | Disk space (bytes) that unauthorized users can use. | bytes |
| Filesystem Size [Free] | Available disk space (bytes) | bytes |
| Filesystem Size [Total] | Total disk space (bytes) | bytes |
| Filesystem Usage | Used disk space percentage | % |
| Filesystem Usage [Avg] | Average of individual filesystem.used.pct | % |
| Filesystem Usage [Inode] | inode usage | % |
| Filesystem Usage [Max] | Maximum among individual filesystem.used.pct | % |
| Filesystem Usage [Min] | minimum of individual filesystem.used.pct | % |
| Filesystem Usage [Total] | - | % |
| Filesystem Used | Used disk space (bytes) | bytes |
| Filesystem Used [Inode] | inode usage | bytes |
| Memory Free | Total amount of available memory (bytes). Memory used by system cache and buffers is not included (see system.memory.actual.free). | bytes |
| Memory Free [Actual] | Actual usable memory (bytes). The calculation method varies by OS: on Linux, it is MemAvailable from /proc/meminfo, or if meminfo cannot be used, it is calculated from available memory plus cache and buffers. On OSX, it is the sum of usable memory and inactive memory. On Windows, it corresponds to a value such as system.memory.free. | bytes |
| Memory Free [Swap] | Available swap memory. | bytes |
| Memory Total | total memory | bytes |
| Memory Total [Swap] | Total swap memory. | bytes |
| Memory Usage | Percentage of used memory
| % |
| Memory Usage [Actual] | Percentage of memory actually used
| % |
| Memory Usage [Cache Swap] | Cached swap usage rate | % |
| Memory Usage [Swap] | Percentage of used swap memory | % |
| Memory Used | used memory | bytes |
| Memory Used [Actual] | Actual used memory (bytes). The value obtained by subtracting used memory from total memory. Available memory is calculated differently for each OS (see system.actual.free). | bytes |
| Memory Used [Swap] | Used swap memory. | bytes |
| Collisions | Network collision | cnt |
| Network In Bytes | Number of received bytes | bytes |
| Network In Bytes [Delta Avg] | Average of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Max] | Maximum of system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Min] | Minimum system.network.in.bytes_delta for each network | bytes |
| Network In Bytes [Delta Sum] | Sum of system.network.in.bytes_delta for individual networks | bytes |
| Network In Bytes [Delta] | Delta of received byte count | bytes |
| Network In Dropped | Number of deleted packets among incoming packets | cnt |
| Network In Errors | Number of errors during reception | cnt |
| Network In Packets | Number of received packets | cnt |
| Network In Packets [Delta Avg] | Average of system.network.in.packets_delta for individual networks | cnt |
| Network In Packets [Delta Max] | Maximum of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Min] | Minimum of system.network.in.packets_delta for each network | cnt |
| Network In Packets [Delta Sum] | Sum of system.network.in.packets_delta for individual networks | cnt |
| Network In Packets [Delta] | Delta of received packet count | cnt |
| Network Out Bytes | Number of transmitted bytes | bytes |
| Network Out Bytes [Delta Avg] | Average of system.network.out.bytes_delta for each network | bytes |
| Network Out Bytes [Delta Max] | Maximum system.network.out.bytes_delta of individual networks | bytes |
| Network Out Bytes [Delta Min] | Minimum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta Sum] | Sum of system.network.out.bytes_delta for individual networks | bytes |
| Network Out Bytes [Delta] | Delta of transmitted byte count | bytes |
| Network Out Dropped | Number of deleted packets among outgoing packets. This value is not reported by the operating system, so it is always 0 on Darwin and BSD. | cnt |
| Network Out Errors | Number of errors during transmission | cnt |
| Network Out Packets | Number of transmitted packets | cnt |
| Network Out Packets [Delta Avg] | Average of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Max] | Maximum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Min] | Minimum of system.network.out.packets_delta for each network | cnt |
| Network Out Packets [Delta Sum] | Sum of system.network.out.packets_delta for individual networks | cnt |
| Network Out Packets [Delta] | Delta of transmitted packet count | cnt |
| Open Connections [TCP] | All open TCP connections | cnt |
| Open Connections [UDP] | All open UDP connections | cnt |
| Port Usage | Available port usage rate | % |
| SYN Sent Sockets | Number of sockets in SYN_SENT state (when connecting from local to remote) | cnt |
| Kernel PID Max | kernel.pid_max value | cnt |
| Kernel Thread Max | kernel.threads-max value | cnt |
| Process CPU Usage | Percentage of CPU time consumed by the process since the last update. This value is similar to the %CPU value shown for the process by the top command on Unix systems. | % |
| Process CPU Usage/Core | The percentage of CPU time used by the process since the last event. Normalized by the number of cores, with values ranging from 0 to 100%. | % |
| Process Memory Usage | Proportion of main memory (RAM) occupied by a process | % |
| Process Memory Used | Resident Set size. The amount of memory a process occupies in RAM. In Windows, the current working set size. | bytes |
| Process PID | process pid | PID |
| Process PPID | parent process PID | PID |
| Processes [Dead] | Number of dead processes | cnt |
| Processes [Idle] | Number of idle processes | cnt |
| Processes [Running] | Number of running processes | cnt |
| Processes [Sleeping] | Number of sleeping processes | cnt |
| Processes [Stopped] | stopped processes count | cnt |
| Processes [Total] | Total number of processes | cnt |
| Processes [Unknown] | Number of processes with an unknown or unsearchable status | cnt |
| Processes [Zombie] | Number of zombie processes | cnt |
| Running Process Usage | process usage | % |
| Running Processes | Number of running processes | cnt |
| Running Thread Usage | Thread usage rate | % |
| Running Threads | Total number of threads running in running processes | cnt |
| Instance Status | Instance status | state |
| Context Switches | context switch count (per second) | cnt |
| Load/Core [1 min] | The load over the last 1 minute divided by the number of cores | cnt |
| Load/Core [15 min] | The load over the last 15 minutes divided by the number of cores | cnt |
| Load/Core [5 min] | The load over the last 5 minutes divided by the number of cores | cnt |
| Multipaths [Active] | External storage connection path status = active count | cnt |
| Multipaths [Failed] | External storage connection path status = failed count | cnt |
| Multipaths [Faulty] | External storage connection path status = faulty count | cnt |
| NTP Offset | measured offset of the last sample (the time difference between the NTP server and the local environment) | num |
| Run Queue Length | Execution queue length | num |
| Uptime | OS uptime(uptime). (milliseconds) | ms |
| Context Switchies | CPU context switch count (per second) | cnt |
| Disk Read Bytes [Sec] | Number of bytes read from a Windows logical disk in 1 second | cnt |
| Disk Read Time [Avg] | Average data read time (seconds) | sec |
| Disk Transfer Time [Avg] | Disk average wait time | sec |
| Disk Usage | Disk usage | % |
| Disk Write Bytes [Sec] | Number of bytes written in one second on a Windows logical disk | cnt |
| Disk Write Time [Avg] | Average data write time (seconds) | sec |
| Pagingfile Usage | Paging file usage | % |
| Pool Used [Non Paged] | Nonpaged Pool usage in kernel memory | bytes |
| Pool Used [Paged] | Paged Pool usage in kernel memory | bytes |
| Process [Running] | Number of currently running processes | cnt |
| Threads [Running] | Number of currently running threads | cnt |
| Threads [Waiting] | Number of threads waiting for processor time | cnt |
Table. Multi-node GPU Cluster [Node] Additional monitoring metrics (Agent installation required)
5.2 - How-to guides
Users can create the service by entering the required information for the Multi-node GPU Cluster service and selecting detailed options through the Samsung Cloud Platform Console.
Multi-node GPU Cluster Getting Started
You can create and use a Multi-node GPU Cluster service from the Samsung Cloud Platform Console.
This service consists of a GPU Node and a Cluster Fabric service.
Create GPU Node
Follow the steps below to create a Multi-node GPU Cluster.
All Services > Compute > Multi-node GPU Cluster Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
On the Service Home page, click the Create GPU Node button. 2. Navigate to the GPU Node Creation page.
On the GPU Node creation page, enter the information required to create the service, and select detailed options.
- Select the required information in the Image and Version Selection area.
Category required statusDetailed description image Required Select the type of image provided - Ubuntu
Image version Required Select version of the selected image - Provide version list of the provided server image
Table. GPU Node image and version selection options - Enter or select the required information in the Service Information Input area.
Category required statusDetailed description Number of servers Required Number of GPU Node servers to create simultaneously - Only numeric input is allowed, and the minimum number of servers to create is 2.
- When initially configuring, you must create at least 2, and expansions can be done one at a time.
Service Type > Server Type Required GPU Node server type - Select the desired CPU, Memory, GPU, and Disk specifications
- For detailed information about the server types provided by GPU Node, refer to Multi-node GPU Cluster server type
Service Type > Planned Compute Required Planned Compute가 설정된 자원 현황 - In Use: Number of resources with Planned Compute that are currently in use
- Configured: Number of resources with Planned Compute set
- Coverage Preview: Amount applied per resource by Planned Compute
- Apply for Planned Compute Service: Go to the Planned Compute service application page
- For more details, see Planned Compute 신청하기
Table. GPU Node Service Information Input Items - In the Required Information Input area, enter or select the required information.
Category required statusDetailed description Administrator account Required Set the administrator account and password to be used when connecting to the server - Ubuntu OS is provided with a fixed root account
Server name Prefix Required Enter a prefix to distinguish each GPU Node generated when the selected number of servers is 2 or more - Automatically generated in the form of user input value (prefix) + ‘
-###’
- Must start with a lowercase English letter and be entered using lowercase letters, numbers, and special characters (
-) within 3 to 11 characters
- Must not end with a special character (
-)
Network Settings Required Set the network where the GPU Node will be installed - VPC Name: Select a pre‑created VPC
- General Subnet Name: Select a pre‑created standard Subnet
- IP can be Auto‑generated or Manual Input; if Manual Input is selected, the user enters the IP directly
- NAT: Available only when there is a single server and the VPC is attached to an Internet Gateway. Checking the option allows selection of a NAT IP. (Initially, only configurations with two or more servers can be created, so modify on the resource detail page)
- NAT IP: Select a NAT IP
- If no NAT IP is available to select, click the Create New button to generate a Public IP
- Refresh button to view and select the created Public IP
- Creating a Public IP incurs charges according to the Public IP pricing policy
Table. GPU Node required information input items - In the Cluster Selection area, create or select a Cluster Fabric.
Category required statusDetailed description Cluster Fabric Required Configuration of GPU Node server groups that can apply GPU Direct RDMA together - Optimal GPU performance and speed can be secured only within the same Cluster Fabric
- When creating a new Cluster Fabric, *New Input > select Node pool, then enter the name of the Cluster Fabric to be created
- To add to an existing Cluster Fabric, Existing Input > select Node pool, then choose the previously created Cluster Fabric
Table. GPU Node Cluster Fabric options - In the Additional Information Input area, enter or select the required information.
Category required statusDetailed description Lock Selection Using a lock prevents actions caused by mistakes, such as terminating, starting, or stopping the server. Init Script Selection Script to run at server startup - The Init Script must be selected differently depending on the image type
- For Linux: Choose Shell Script or cloud-init
tag Selection Add Tag - You can add up to 50 per resource
- After clicking the Add Tag button, enter or select Key, Value values
Table. GPU Node additional information input fields - The Init Script must be selected differently depending on the image type
- Select the required information in the Image and Version Selection area.
Summary Check the detailed information and estimated billing amount generated in the panel, and click the Create button.
When the popup notifying creation opens, click the Confirm button.
- When creation is complete, check the created resources on the GPU Node List page.
Caution
- When creating a service, the GPU MIG/ECC settings are reset. * However, to apply the correct settings, perform an initial reboot, verify that the settings have been applied, and then use it.
- For detailed information on resetting GPU MIG/ECC settings, refer to the GPU MIG/ECC 설정 초기화 점검 가이드.
Check GPU Node detailed information
The Multi-node GPU Cluster service can view and modify the full list of GPU Node resources and detailed information.
GPU Node Details page consists of Details, Tags, Job History tabs.
To view detailed information about the GPU Node, follow these steps.
Click the All Services > Compute > Multi-node GPU Cluster > GPU Node menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
On the Service Home page, click the GPU Node menu. 2. Go to the GPU Node list page.
- Resource items other than the required columns can be added through the Settings button.
Category required statusDetailed description Resource ID Selection User-created GPU Node ID Cluster Fabric name Required User-created Cluster Fabric name Server name Required User-created GPU Node name Server type Required Server type of GPU Node - The user can view the number of cores, memory capacity, and GPU type and count of the created resources
image Required User-generated GPU Node image version IP Required IP of the GPU node created by the user status Required Status of the GPU Node created by the user Creation date and time Selection GPU Node creation timestamp Table. GPU Node resource list items
- Resource items other than the required columns can be added through the Settings button.
GPU Node List page, click the resource to view detailed information. 3. Go to the GPU Node Details page.
- GPU Server Details At the top of the page, status information and descriptions of additional features are displayed.
Category Detailed description GPU Node status Status of the GPU Node created by the user - Creating: State while the server is being created
- Running:: State when creation is complete and the server is available for use
- Editing:: State while the IP is being changed
- Unknown: Error state
- Starting: State while the server is starting
- Stopping: State while the server is stopping
- Stopped: State when the server has stopped
- Terminating: State while terminating
- Terminated: State when termination is complete
Server control Button to change server status - Start: Start a stopped server
- Stop: Stop a running server
Service cancellation Cancel service button Table. GPU Node status information and additional features
- GPU Server Details At the top of the page, status information and descriptions of additional features are displayed.
Detailed Information
On the GPU Node List page’s Details Tab, you can view the detailed information of the selected resource and edit the information if needed.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | Resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Server name | server name |
| Node pool | A collection of nodes that can be grouped into the same Cluster Fabric |
| Cluster Fabric name | User-created Cluster Fabric name |
| Image/Version | Server OS image and version |
| Server type | CPU, memory, GPU, information display |
| Planned Compute | Resource status with Planned Compute configured
|
| Lock | Indicates whether Lock is enabled/disabled
|
| Network | GPU Node network information
|
| Block Storage | Block Storage information connected to the server
|
| Init Script | View the Init Script content entered during server creation |
Table. GPU Node detailed information tab items
note
If the VPC does not have an Internet Gateway attached, you cannot attach a Public NAT IP.
Tag
On the GPU Node List page’s Tag Tab, you can view the selected resource’s tag information, and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. GPU Node Tag Tab Items
Job History
GPU Node List page’s Job History Tab allows you to view the job history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. GPU Node Job History Tab Detailed Information Items
Control GPU Node operation
If you need server control and management functions for the created GPU Node resources, you can perform tasks on the GPU Node List or GPU Node Details page. You can start and stop the running GPU Node resources.
Getting Started with GPU Node
You can start a stopped (Stopped) GPU Node. To start the GPU Node, follow these steps.
- All Services > Compute > Multi-node GPU Cluster Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
- On the Service Home page, click the GPU Node menu. 2. Go to the GPU Node list page.
- GPU Node List page, after selecting individual or multiple servers with the checkbox, you can Start via the More button at the top.
- GPU Node List page, click Resources. 3. Go to the GPU Node Details page.
- On the GPU Node Details page, click the Start button at the top to start the server.
- Check the server status and complete the status change.
Stop GPU Node
You can stop a GPU node that is (Active). To stop the GPU Node, follow the steps below.
- All Services > Compute > Multi-node GPU Cluster Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
- On the Service Home page, click the GPU Node menu. 2. Go to the GPU Node list page.
- GPU Node List page, after selecting individual or multiple servers with the checkboxes, you can control them using the Stop button at the top.
- On the GPU Node List page, click Resources. 3. Go to the GPU Node Details page.
- Click the 중지 button at the top of the GPU Node 상세 page to stop the server.
- Check the server status and complete the status change.
Terminate GPU Node
You can terminate unused GPU nodes to reduce operating costs. However, if you terminate the service, the running service may be discontinued immediately, so you should proceed with the termination only after fully considering the impact that may arise from the service interruption.
Caution
Please be aware that data cannot be recovered after terminating the service.
To cancel a GPU Node, follow these steps.
- All Services > Compute > Multi-node GPU Server Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
- On the Service Home page, click the Cluster Fabric menu. 2. Go to the Cluster Fabric List page.
- On the Cluster Fabric List page, select the resources to cancel, and click the Cancel Service button.
- Resources that use the same Cluster Fabric can be terminated simultaneously.
- When termination is complete, check on the GPU Node List page whether the resources have been terminated.
Notice
The cases where a GPU Node cannot be terminated are as follows.
- When Block Storage(BM) is connected: Please disconnect the Block Storage(BM) connection first.
- When File Storage is connected: Please disconnect the File Storage connection first.
- If Lock is set: Please change the Lock setting to disabled and try again.
- If the selection includes a server that cannot be terminated simultaneously: Please re-select only resources that can be terminated.
- If the server you want to decommission has a different Cluster Fabric: Select only resources that use the same Cluster Fabric.
Reference
If all GPU Nodes in the Cluster Fabric are deleted, the Cluster Fabric is automatically deleted.
5.2.1 - Cluster Fabric Management
Cluster Fabric is a service that helps manage the servers (GPU Nodes) included in a GPU Cluster. Using Cluster Fabric, you can move servers between GPU clusters in the same node pool and optimize GPU performance and speed within a single GPU cluster.
Create Cluster Fabric
Cluster Fabric can be created together when a GPU Node is created, and it cannot be created or deleted separately. If all GPU Nodes in the Cluster Fabric are terminated, the Cluster Fabric is automatically deleted.
If you have not created a GPU Node, please create a GPU Node first. For more details, please refer to GPU Node 생성하기.
Check detailed information of Cluster Fabric
guide
- Cluster Fabric can be created together when a GPU node is created, and it cannot be created or deleted independently.
- If all GPU Nodes in the Cluster Fabric are terminated, the Cluster Fabric is automatically deleted.
- If you have not created a GPU Node, please create a GPU Node first. * For more details, refer to GPU Node 생성하기.
On the Cluster Fabric List page and the Cluster Fabric Details page, you can view the generated Cluster Fabric list and details, and move the server.
All Services > Compute > Multi-node GPU Server Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
On the Service Home page, click the Cluster Fabric menu. 2. Go to the Cluster Fabric List page.
- Cluster Fabric List page allows you to view the resource list of the GPU Cluster you created.
- Resource items other than the required columns can be added through the Settings button.
Category required statusDetailed description Resource ID Selection User-generated Cluster Fabric ID Cluster Fabric name Required User-created Cluster Fabric name Node pool Selection A collection of nodes that can be grouped into the same Cluster Fabric Number of servers Selection Number of GPU Nodes Server type Selection Server type of GPU Node - The user can view the number of cores, memory capacity, and GPU type and count of the created resources
status Selection Status of the user-created Cluster Fabric Creation date and time Selection Cluster Fabric creation timestamp Table. Cluster Fabric resource list items
Cluster Fabric List page: click the resource to view detailed information. 3. Navigate to the Cluster Fabric Details page.
- Cluster Fabric Details At the top of the page, status information and descriptions of additional features are displayed.
Category Detailed description Cluster Fabric status Status of the Cluster Fabric created by the user - Creating: State while the cluster is being created
- Active: State when creation is complete and it is usable
- Editing: State while the IP is being changed
- Deleting: State while being terminated
- Deleted: State after termination is complete
Add target server A feature that allows moving a server from another cluster to the target cluster. Table. Cluster Fabric status information and additional functions
- Cluster Fabric Details At the top of the page, status information and descriptions of additional features are displayed.
Detailed Information
On the Cluster Fabric List page’s Details Tab, you can view the detailed information of the selected resource and retrieve servers from another cluster.
| Category | Detailed description |
|---|---|
| service | service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource name | resource name
|
| Resource ID | Unique resource ID in the service |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who edited the service information |
| Modification date and time | Date and time the service information was modified |
| Cluster Fabric name | User-created Cluster Fabric name |
| Node pool | A collection of nodes that can be grouped into the same Cluster Fabric |
| Target server | List of GPU Nodes bound to Cluster Fabric
|
Table. Cluster Fabric detailed information tab items
Import Cluster Fabric server
Using the Add Target Server feature on the Cluster Fabric Details page, you can import servers from another cluster and add them to the selected cluster.
- All Services > Compute > Multi-node GPU Server Click the menu. 1. Go to the Service Home page of the Multi-node GPU Cluster.
- On the Service Home page, click the Cluster Fabric menu. 2. Go to the Cluster Fabric List page.
- Cluster Fabric List page: click the resource to view detailed information. 3. Navigate to the Cluster Fabric Details page.
- Click the right Add button on the target server in the Details tab.
- The popup window for adding a target server opens. *
- Select a cluster in Cluster Fabric.
- GPU nodes associated with the selected cluster are listed; select the GPU node you want to retrieve.
- The selected GPU Node’s name is displayed at the bottom.
- Press the Confirm button to complete.
- Pressing the Cancel button cancels the operation.
- Check whether the added GPU Node is visible on the target server.
- The popup window for adding a target server opens. *
Terminate Cluster Fabric
If all GPU Nodes in the Cluster Fabric are terminated, the Cluster Fabric is automatically deleted. For more details, see GPU Node 해지하기.
5.2.2 - Install ServiceWatch Agent
Users can install the ServiceWatch Agent on the GPU nodes of a Multi-node GPU Cluster to collect custom metrics and logs.
Reference
Custom metric/log collection via the ServiceWatch Agent is currently available only on Samsung Cloud Platform For Enterprise. It will also be available in other offerings in the future.
Caution
Since metric collection through the ServiceWatch Agent is classified as a custom metric and incurs charges unlike the default metrics, it is recommended to remove or disable any unnecessary metric collection settings.
ServiceWatch Agent
In a Multi-node GPU Cluster, the agents that need to be installed on GPU nodes to collect ServiceWatch custom metrics and logs can be divided into two main types. It is the Prometheus Exporter and Open Telemetry Collector.
| Category | Detailed description | |
|---|---|---|
| Prometheus Exporter | Provide metrics of a specific application or service in a format that Prometheus can scrape
| |
| Open Telemetry Collector | Acts as a centralized collector that gathers telemetry data such as metrics and logs from distributed systems, processes (filtering, sampling, etc.) it, and exports it to various backends (e.g., Prometheus, Jaeger, Elasticsearch, etc.)
|
Table. Explanation of Prometheus Exporter and Open Telemetry Collector
information
If you have configured a Kubernetes Engine on a GPU node, please view the GPU metrics using the metrics provided by the Kubernetes Engine.
- If you install the DCGM Exporter on a GPU node configured with Kubernetes Engine, it may not operate correctly.
Reference
The ServiceWatch Agent guide for collecting GPU metrics on a GPU Node can be used the same way as on a GPU Server.
For more details, see GPU Server > ServiceWatch Agent.
Pre-configuration for Using ServiceWatch Agent
To use the ServiceWatch Agent, please refer to ServiceWatch Agent를 위한 사전 환경 설정 and prepare the prerequisite configuration.
5.2.3 - Multi-node GPU Cluster Service Scope and Inspection Guide
Multi-node GPU Cluster Service Scope
If an IaaS hardware-level issue occurs with the Multi-node GPU Cluster service, you can receive technical support through Contact Us in the Support Center. However, the risks associated with changes such as OS kernel updates or application installations are the user’s responsibility, so technical support is limited; please be mindful when performing tasks such as system updates.
IaaS hardware level issue
- HW fault event messages generated within the server by the IPMI hardware monitoring console.
- GPU HW operation error observed in the nvdia-smi command
- HW error messages that occur during inspection of InfiniBand HCA cards or InfiniBand Switches
Caution
Since the Multi-node GPU Cluster is a service sensitive to software version compatibility of Ubuntu OS / NVDIA / Infiniband, official technical support is unavailable after changes such as a user’s OS kernel update or application installation.
IaaS HW Inspection Guide
After applying for the Multi-node GPU Cluster service, it is recommended to check the IaaS HW level according to the inspection guide.
Intel E810 driver update
Check the version of the Intel E810 driver and, if necessary, refer to the following procedure to perform an update.
- Server manufacturer Intel E810 driver minimum recommended version: 1.15.4 or later
- Driver download: Intel Network Adapter Driver for 800 Series Devices under Linux
Caution
Proceed with the update only if the Multi-node GPU Cluster Node has an Intel E810 Device and is simultaneously using a standard image version 535.86.10 or lower.
Reference
You can use the lspci command to verify whether an E810 NIC device is present.
If the E810 NIC is valid, the PCIe device is identified as follows using the E810-C information (if there is no E810 NIC device, this operation is not performed).
<div class="code-block-buttons">
<button class="code-block-download">
<div class="code-block-download-icon">
<svg width="14" height="16" viewBox="0 0 14 16" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M13.999 14.4353v-2.998C13.999 11.0232 13.6602 10.6853 13.2461 10.6853S12.5 11.0232 12.5 11.4373v2.2519H1.5V11.4373C1.5 11.0232 1.16211 10.6853.748047 10.6853.333984 10.6853 976563e-9 11.0232 976562e-9 11.4373v2.998C976562e-9 14.8494.333984 15.1892.748047 15.1892H13.2461c.414099999999999.0.7529-.3398.7529-.7539z" fill="#5135ff"/><path d="M1.41169 6.21654c.25876-.32345.73073-.37589 1.05417-.11713l3.78463 3.0277V1.56104c0-.41422.33578-.750005.75-.750005.41421.0.75.335785.75.750005V9.12208L11.5288 6.09941C11.8523 5.84065 12.3242 5.89309 12.583 6.21654 12.8418 6.53999 12.7893 7.01196 12.4659 7.27071L6.99734 11.6455 1.52882 7.27071c-.32345-.25875-.37589-.73072-.11713-1.05417z" fill="#5135ff"/></svg></div>
Sample Code Download
</button>
<button class="code-block-copy">
<div class="code-block-copy-icon">
<svg width="14" height="14" viewBox="0 0 14 14" fill="none" xmlns="http://www.w3.org/2000/svg"><path fill-rule="evenodd" clip-rule="evenodd" d="M10 4.00012V1c0-.552285-.44772-1-1-1H1C.447715.0.0.447715.0 1V9c0 .55228.447715 1 1 1H3.99988v3.0001C3.99988 13.5515 4.44849 14 4.99988 14H10.0002l3.9997-3.9995V5c0-.55139-.448600000000001-.99988-1-.99988H10zM1.4 1.4V8.6H3.99988V5c0-.55139.44861-.99988 1-.99988H8.6V1.4H1.4zM5.3999 12.6H9.08295V9.78301C9.08295 9.39641 9.39635 9.08301 9.78295 9.08301H12.5999V5.40015h-7.2V12.6zm6.1375-2.117-1.0545 1.0544V10.483h1.0545z" fill="currentcolor"/></svg></div>
Copy Code
</button>
</div>
Color mode
lspci | grep E810
0000:6a:00.0 Ethernet controller: Intel Corporation Ethernet Controller E810-C for QSFP (rev 02) 0000:6a:00.1 Ethernet controller: Intel Corporation Ethernet Controller E810-C for QSFP (rev 02)lspci | grep E810
0000:6a:00.0 Ethernet controller: Intel Corporation Ethernet Controller E810-C for QSFP (rev 02) 0000:6a:00.1 Ethernet controller: Intel Corporation Ethernet Controller E810-C for QSFP (rev 02)</div>
To update the driver, follow the steps below.
Move the base driver tar file to the desired directory.
Color mode/usr/local/src/usr/local/srcDirectory navigation example Untar / unzip the Archiver file.
- x.x.x is the version number of the driver tar file.Color mode
tar zxf ice-x.x.x.tar.gztar zxf ice-x.x.x.tar.gzuntar example
- x.x.x is the version number of the driver tar file.
Change the driver to the src directory.
- x.x.x is the version number of the driver tar file.Color mode
cd ice-x.x.x/src/cd ice-x.x.x/src/Example of changing to the src directory
- x.x.x is the version number of the driver tar file.
Compile the driver module.
Color modemake installmake installDriver module compilation example After the update is complete, check the version.
Color modelsmod | grep ice modinfo ice | grep versionlsmod | grep ice modinfo ice | grep versionVersion check example
Check NVIDIA driver
To check the NVIDIA driver (nvidia-smi topo, IB nv_peer_mem status) and inspect the IaaS hardware level, follow these steps.
Reference
The example of applying MIG is described using an A100 GPU node as the reference.
Check the GPU driver status.
Color mode~$ nvidia-smi~$ nvidia-smiExample code for checking GPU driver status Color modeThu Jan 29 14:48:31 2026 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | =========================================+======================+====================== | | 0 NVIDIA A100-SXM4-80GB On | 00000000:00:05.0 Off | On | | N/A 36C P0 52W / 400W | 0MiB / 81920MiB | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA A100-SXM4-80GB On | 00000000:00:06.0 Off | 0 | | N/A 36C P0 61W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA A100-SXM4-80GB On | 00000000:00:07.0 Off | 0 | | N/A 36C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA A100-SXM4-80GB On | 00000000:00:08.0 Off | 0 | | N/A 40C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA A100-SXM4-80GB On | 00000000:00:09.0 Off | 0 | | N/A 36C P0 63W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA A100-SXM4-80GB On | 00000000:00:0A.0 Off | 0 | | N/A 40C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA A100-SXM4-80GB On | 00000000:00:0B.0 Off | 0 | | N/A 39C P0 65W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA A100-SXM4-80GB On | 00000000:00:0C.0 Off | 0 | | N/A 39C P0 60W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | MIG devices: | +------------------+--------------------------------+-----------+-----------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ==================+================================+===========+======================= | | No MIG devices found | +---------------------------------------------------------------------------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ======================================================================================= | | No running processes found | +---------------------------------------------------------------------------------------+Thu Jan 29 14:48:31 2026 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.183.06 Driver Version: 535.183.06 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | | =========================================+======================+====================== | | 0 NVIDIA A100-SXM4-80GB On | 00000000:00:05.0 Off | On | | N/A 36C P0 52W / 400W | 0MiB / 81920MiB | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA A100-SXM4-80GB On | 00000000:00:06.0 Off | 0 | | N/A 36C P0 61W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA A100-SXM4-80GB On | 00000000:00:07.0 Off | 0 | | N/A 36C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA A100-SXM4-80GB On | 00000000:00:08.0 Off | 0 | | N/A 40C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA A100-SXM4-80GB On | 00000000:00:09.0 Off | 0 | | N/A 36C P0 63W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA A100-SXM4-80GB On | 00000000:00:0A.0 Off | 0 | | N/A 40C P0 64W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA A100-SXM4-80GB On | 00000000:00:0B.0 Off | 0 | | N/A 39C P0 65W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA A100-SXM4-80GB On | 00000000:00:0C.0 Off | 0 | | N/A 39C P0 60W / 400W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | MIG devices: | +------------------+--------------------------------+-----------+-----------------------+ | GPU GI CI MIG | Memory-Usage | Vol | Shared | | ID ID Dev | BAR1-Usage | SM Unc | CE ENC DEC OFA JPG | | | | ECC | | | ==================+================================+===========+======================= | | No MIG devices found | +---------------------------------------------------------------------------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | | ======================================================================================= | | No running processes found | +---------------------------------------------------------------------------------------+GPU driver status example Check the NVSwitch and NVLink hardware status.
Check NVSwitch status
Color mode~$ nvidia-smi nvlink --status~$ nvidia-smi nvlink --statusNVSwitch status check example Color modeGPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-64a2f685-bb12-c4af-105c-0726ece9c8d7) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2269851b-71cd-f6c7-50c5-ba1525cf3ce8) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-4c397bbf-95fc-5c29-918a-a429cbe45a7a) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-0e350204-9fb6-2cbe-538e-8f7849658eb8) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-45f0c453-4760-edd4-3af9-25c5ea7473a5) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-38409794-bb34-430e-3c50-90b42cb2bb72) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-3fb478aa-801b-eb64-55c2-0ffc3f2ce404) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/sGPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-64a2f685-bb12-c4af-105c-0726ece9c8d7) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 2: NVIDIA A100-SXM4-80GB (UUID: GPU-2269851b-71cd-f6c7-50c5-ba1525cf3ce8) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-4c397bbf-95fc-5c29-918a-a429cbe45a7a) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-0e350204-9fb6-2cbe-538e-8f7849658eb8) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-45f0c453-4760-edd4-3af9-25c5ea7473a5) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-38409794-bb34-430e-3c50-90b42cb2bb72) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/s GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-3fb478aa-801b-eb64-55c2-0ffc3f2ce404) Link 0: 25 GB/s Link 1: 25 GB/s Link 2: 25 GB/s Link 3: 25 GB/s Link 4: 25 GB/s Link 5: 25 GB/s Link 6: 25 GB/s Link 7: 25 GB/s Link 8: 25 GB/s Link 9: 25 GB/s Link 10: 25 GB/s Link 11: 25 GB/sNVSwitch status example Check NVLinks hardware status
Color mode~$ nvidia-smi topo -m~$ nvidia-smi topo -mExample code for checking NVLink hardware status Color modeGPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 0-127 0-7 N/A GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 0-127 0-7 N/A GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 0-127 0-7 N/A GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X 0-127 0-7 N/A Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinksGPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 0-127 0-7 N/A GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 0-127 0-7 N/A GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 0-127 0-7 N/A GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 0-127 0-7 N/A GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X 0-127 0-7 N/A Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinksNVLink HW status check code example
Check the InfiniBand (IB) HCA card hardware status and link.
Color modeuser@bm-dev-001:~$ ibdev2netdev -vuser@bm-dev-001:~$ ibdev2netdev -vHW status check command example Color modecat: /sys/class/infiniband/mlx5_0/device/vpd: Permission denied 0000:45:00.0 mlx5_0 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs18 (Down) cat: /sys/class/infiniband/mlx5_1/device/vpd: Permission denied 0000:0e:00.0 mlx5_1 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs17 (Down) cat: /sys/class/infiniband/mlx5_2/device/vpd: Permission denied 0000:c5:00.0 mlx5_2 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs20 (Down) cat: /sys/class/infiniband/mlx5_3/device/vpd: Permission denied 0000:85:00.0 mlx5_3 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs19 (Down) user@bm-dev-001:~$cat: /sys/class/infiniband/mlx5_0/device/vpd: Permission denied 0000:45:00.0 mlx5_0 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs18 (Down) cat: /sys/class/infiniband/mlx5_1/device/vpd: Permission denied 0000:0e:00.0 mlx5_1 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs17 (Down) cat: /sys/class/infiniband/mlx5_2/device/vpd: Permission denied 0000:c5:00.0 mlx5_2 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs20 (Down) cat: /sys/class/infiniband/mlx5_3/device/vpd: Permission denied 0000:85:00.0 mlx5_3 (MT4123 - ) fw 20.29.1016 port 1 (ACTIVE) ==> ibs19 (Down) user@bm-dev-001:~$Example of HW status check result Color moderoot@bm-dev-001:~# ibstatroot@bm-dev-001:~# ibstatExample of link verification command Color modeCA 'mlx5_0' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff5060ac System image GUID: 0x88e9a4ffff5060ac Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 8 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff5060ac Link layer: InfiniBand CA 'mlx5_1' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504080 System image GUID: 0x88e9a4ffff504080 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 5 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504080 Link layer: InfiniBand CA 'mlx5_2' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff505038 System image GUID: 0x88e9a4ffff505038 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 2 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff505038 Link layer: InfiniBand CA 'mlx5_3' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504094 System image GUID: 0x88e9a4ffff504094 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 7 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504094 Link layer: InfiniBandCA 'mlx5_0' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff5060ac System image GUID: 0x88e9a4ffff5060ac Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 8 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff5060ac Link layer: InfiniBand CA 'mlx5_1' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504080 System image GUID: 0x88e9a4ffff504080 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 5 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504080 Link layer: InfiniBand CA 'mlx5_2' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff505038 System image GUID: 0x88e9a4ffff505038 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 2 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff505038 Link layer: InfiniBand CA 'mlx5_3' CA type: MT4123 Number of ports: 1 Firmware version: 20.29.1016 Hardware version: 0 Node GUID: 0x88e9a4ffff504094 System image GUID: 0x88e9a4ffff504094 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 7 LMC: 0 SM lid: 1 Capability mask: 0x2651e848 Port GUID: 0x88e9a4ffff504094 Link layer: InfiniBandLink verification result example
Check IB bandwidth communication
Check the IB bandwidth communication status (ib_send_bw) and follow the steps below to inspect the IaaS hardware level.
Check the name of the IB HCA interface.
- In the following example, IB ports:
mlx5_0,mlx5_4,mlx_5_5,mlx5_8Color mode~$ ibdev2netdev -v~$ ibdev2netdev -vExample of checking IB HCA interface name Color mode0000:1a:00.0 mlx5_0 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp26s0 (Down) 0000:1b:00.0 mlx5_1 (MT4123 - 1028SN ) Mellanox ConnectX-6 Single Port VPI HDR QSFP Adapter fw 20.38.1002 port 1 (ACTIVE) ==> bond-nas (Up) 0000:3c:00.0 mlx5_2 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp60s0 (Down) 0000:4d:00.0 mlx5_3 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp77s0 (Down) 0000:5e:00.0 mlx5_4 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp94s0 (Down) 0000:9c:00.0 mlx5_5 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp156s0 (Down) 0000:9d:00.0 mlx5_6 (MT4123 - 1028SN ) Mellanox ConnectX-6 Single Port VPI HDR QSFP Adapter fw 20.38.1002 port 1 (ACTIVE) ==> bond-nas (Up) 0000:bc:00.0 mlx5_7 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp188s0 (Down) 0000:cc:00.0 mlx5_8 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp204s0 (Down) 0000:dc:00.0 mlx5_9 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp220s0 (Down)0000:1a:00.0 mlx5_0 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp26s0 (Down) 0000:1b:00.0 mlx5_1 (MT4123 - 1028SN ) Mellanox ConnectX-6 Single Port VPI HDR QSFP Adapter fw 20.38.1002 port 1 (ACTIVE) ==> bond-nas (Up) 0000:3c:00.0 mlx5_2 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp60s0 (Down) 0000:4d:00.0 mlx5_3 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp77s0 (Down) 0000:5e:00.0 mlx5_4 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp94s0 (Down) 0000:9c:00.0 mlx5_5 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp156s0 (Down) 0000:9d:00.0 mlx5_6 (MT4123 - 1028SN ) Mellanox ConnectX-6 Single Port VPI HDR QSFP Adapter fw 20.38.1002 port 1 (ACTIVE) ==> bond-nas (Up) 0000:bc:00.0 mlx5_7 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp188s0 (Down) 0000:cc:00.0 mlx5_8 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (ACTIVE) ==> ibp204s0 (Down) 0000:dc:00.0 mlx5_9 (MT4129 - 1028SN ) Nvidia ConnectX-7 Single Port Infiniband NDR OSFP Adapter fw 28.38.1002 port 1 (DOWN ) ==> ibp220s0 (Down)Example of IB HCA interface name verification result
- In the following example, IB ports:
Use the SERVER Side command to check the communication status.
Color mode~$ ib_send_bw -d mlx5_0 -i 1 –F~$ ib_send_bw -d mlx5_0 -i 1 –FSERVER Side command example Color mode************************************ * Waiting for client to connect... * * ************************************ --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 100 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x0f QPN 0x6d95 PSN 0xb974a remote address: LID 0x01 QPN 0x6dd2 PSN 0xc8a18c --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 0.00 19827.40 0.317238 ---------------------------------------------------------------------------------------************************************ * Waiting for client to connect... * * ************************************ --------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 100 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x0f QPN 0x6d95 PSN 0xb974a remote address: LID 0x01 QPN 0x6dd2 PSN 0xc8a18c --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 0.00 19827.40 0.317238 ---------------------------------------------------------------------------------------Example of mutual communication status check result Use the CLIENT Side command to check the communication status.
Color mode~$ ib_send_bw -d mlx5_0 -i 1 -F <SERVER Side IP>~$ ib_send_bw -d mlx5_0 -i 1 -F <SERVER Side IP>CLIENT Side command example Color mode--------------------------------------------------------------------------------------- Send BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON RX depth : 512 CQ Moderation : 100 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x01 QPN 0x6dd2 PSN 0xc8a18c remote address: LID 0x0f QPN 0x6d95 PSN 0xb974a --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 19008.49 19006.37 0.304102 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Send BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON RX depth : 512 CQ Moderation : 100 Mtu : 4096[B] Link type : IB Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0x01 QPN 0x6dd2 PSN 0xc8a18c remote address: LID 0x0f QPN 0x6d95 PSN 0xb974a --------------------------------------------------------------------------------------- #bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps] 65536 1000 19008.49 19006.37 0.304102 ---------------------------------------------------------------------------------------Example of mutual communication status check result
Check IB service related kernel modules
Check the relevant kernel modules for the IB service (lsmod) to inspect the IaaS hardware level.
Check IB service-related kernel module - nvidia_peermem
Color mode~$ lsmod | grep nvidia_peermem~$ lsmod | grep nvidia_peermemExample command to check nvidia_peermem Color modenvidia_peermem 16384 0 ib_core 425984 9 rdma_cm,ib_ipoib,nvidia_peermem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm nvidia 56524800 451 nvidia_uvm,nvidia_peermem,nvidia_modesetnvidia_peermem 16384 0 ib_core 425984 9 rdma_cm,ib_ipoib,nvidia_peermem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm nvidia 56524800 451 nvidia_uvm,nvidia_peermem,nvidia_modesetExample of nvidia_peermem check result Check IB service related kernel modules - IB Card (HCA) driver
Color mode~$ lsmod|egrep 'ib_|_ib|mlx'~$ lsmod|egrep 'ib_|_ib|mlx'Example command to check the IB Card (HCA) driver Color modemlx5_ib 393216 0 ib_uverbs 163840 2 irdma,mlx5_ib ib_core 393216 3 irdma,ib_uverbs,mlx5_ib mlx5_core 1593344 1 mlx5_ib mlxfw 32768 1 mlx5_core psample 20480 1 mlx5_core tls 114688 1 mlx5_core pci_hyperv_intf 16384 1 mlx5_core ib_ipoib 139264 0 ib_cm 131072 2 rdma_cm,ib_ipoib ib_umad 40960 0 mlx5_ib 454656 0 ib_uverbs 135168 2 rdma_ucm,mlx5_ib ib_core 434176 9 rdma_cm,ib_ipoib,nvidia_peermem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm libcrc32c 16384 5 nf_conntrack,nf_nat,btrfs,nf_tables,raid456 mlx5_core 2064384 1 mlx5_ib mlx_compat 69632 11 rdma_cm,ib_ipoib,mlxdevm,iw_cm,ib_umad,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_coremlx5_ib 393216 0 ib_uverbs 163840 2 irdma,mlx5_ib ib_core 393216 3 irdma,ib_uverbs,mlx5_ib mlx5_core 1593344 1 mlx5_ib mlxfw 32768 1 mlx5_core psample 20480 1 mlx5_core tls 114688 1 mlx5_core pci_hyperv_intf 16384 1 mlx5_core ib_ipoib 139264 0 ib_cm 131072 2 rdma_cm,ib_ipoib ib_umad 40960 0 mlx5_ib 454656 0 ib_uverbs 135168 2 rdma_ucm,mlx5_ib ib_core 434176 9 rdma_cm,ib_ipoib,nvidia_peermem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm libcrc32c 16384 5 nf_conntrack,nf_nat,btrfs,nf_tables,raid456 mlx5_core 2064384 1 mlx5_ib mlx_compat 69632 11 rdma_cm,ib_ipoib,mlxdevm,iw_cm,ib_umad,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_coreExample of IB Card (HCA) driver verification result
Check storage physical disk resources and Multi-Path
Verify the storage physical disk resources and Multi-Path to assess the IaaS hardware level.
Storage Physical Disk Resource Check Results
Color moderoot@bm-dev-002:/tmp# fdisk –lroot@bm-dev-002:/tmp# fdisk –lExample of storage physical disk resource check result Multi-Path verification result
Color moderoot@bm-dev-002:/tmp# multipath –llroot@bm-dev-002:/tmp# multipath –llExample of Multi-Path verification result
Check Service Network after new deployment of Multi-node GPU Cluster
Use the following command to verify that the MII Status of Bonding and Slave Interface is up.
Service Network check command
Color mode~$ cat /proc/net/bonding/bond-srv~$ cat /proc/net/bonding/bond-srvExample command to check Service Network Service Network check result
Color modeEthernet Channel Bonding Driver: v5.15.0-25-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens9f0 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 Slave Interface: ens9f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:35:70 Slave queue ID: 0 Slave Interface: ens11f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:2f:e8 Slave queue ID: 0Ethernet Channel Bonding Driver: v5.15.0-25-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens9f0 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 Slave Interface: ens9f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:35:70 Slave queue ID: 0 Slave Interface: ens11f0 MII Status: up Speed: 100000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 30:3e:a7:02:2f:e8 Slave queue ID: 0Example of Service Network verification result
Reference
If some Slave Interface is in a down state, use the Contact of the Support Center to report the abnormal situation and receive a response.
Multi-node GPU Cluster: Verify time synchronization with the Time Server after new deployment
The OS image includes the installation of the chrony daemon and configuration for SCP NTP server synchronization. Use the following command to verify whether a line marked with ^* exists in the MS Name column.
Command to check the chrony daemon source and synchronization status
Color mode~$ chronyc sources -V~$ chronyc sources -VExample of status check command Result of checking chrony daemon status
Color modeMS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 198.19.0.54 4 10 377 1040 -16us[ -37us] +/- 9982usMS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 198.19.0.54 4 10 377 1040 -16us[ -37us] +/- 9982usExample of checking the chrony daemon status
5.3 - Release Note
Multi-node GPU Cluster
2026.03.19
FEATURE
New OS version, server type addition and Terraform integration provided- Ubuntu image version 24.04 has been added.
- B300 GPU server type has been added.
- Provides an IaC environment through Terraform.
2025.07.01
FEATURE
New feature addition and monitoring integration- You can terminate multiple resources simultaneously from the GPU Node list.
- It must be a node that uses the same DataSet and Cluster Fabric.
- Integrated with Cloud Monitoring.
- You can view key performance metrics in real time in Cloud Monitoring.
2025.02.27
NEW
Multi-node GPU Cluster official version launch- Multi-node GPU Cluster service has been launched.
- We provide a service that offers physical GPU servers without virtualization for large-scale high-performance AI computing.
6 - Cloud Functions
6.1 - Overview
Service Overview
Cloud Functions is a serverless computing-based FaaS (Function as a Service) that lets you easily run function‑based applications without provisioning servers. Users don’t have to hassle with managing servers or containers for scaling, and can focus on writing code and deploying applications.
Features
- Easy and Convenient Development Environment: Developers can easily create Function resources that connect to events across multiple environments using a Code Editor suitable for the selected runtime, and can write and invoke code with ease.
- Serverless Computing: You can use a serverless code execution service for development in the Samsung Cloud Platform environment. * The resources required to invoke and run function-based applications are allocated and managed by the Samsung Cloud Platform according to the scale of execution.
- Efficient Cost Management: The invoked Function aggregates usage (total number of calls, total execution time) and is billed for the time actually used to run the application. * Functions with low usage can have the Cloud Functions scaler adjusted to a scale-to-zero state, so they do not consume resources, enabling efficient cost management.
Service diagram
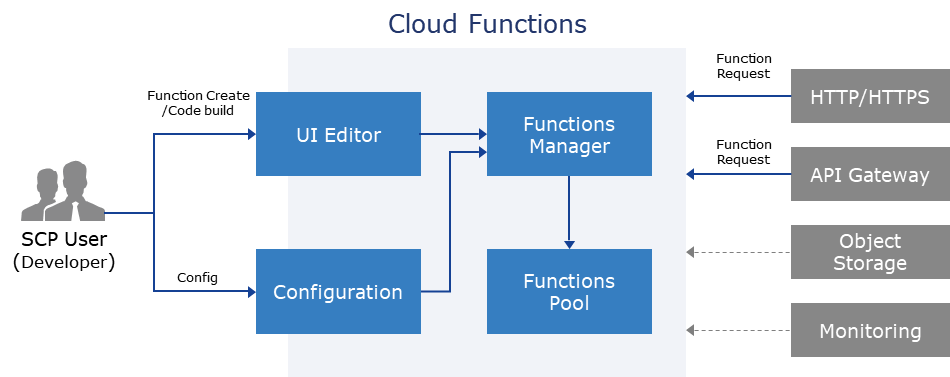
Provided Features
Cloud Functions provides the following features.
- Code Development Environment: Create Runtime-optimized functions, write and edit code
- Refer to 구성 요소 > Runtime for supported runtimes.
- Function execution, environment management, monitoring: endpoint definition, Token management, access control configuration, trigger configuration, etc., runtime environment/variable definition and modification, artifact invocation/testing for Deploy/Test, service deployment, progress status monitoring/logging
- Serverless Computing: All elements required for code writing and deployment are managed by Samsung Cloud Platform, with automatic scaling adjustments based on deployment.
- Sample Code Provided: By providing various sample codes through Blueprint, you can start easily and quickly
Component
Runtime
Cloud Functions currently supports the following runtimes. Additional continuously supported runtimes will also be added.
| Runtime | Version | Deprecation date |
|---|---|---|
| GO | 1.21 | 2026.7.30 |
| GO | 1.23 | 2026.7.30 |
| GO | 1.25 | - |
| java | 17 | - |
| Node.js | 18 | 2026.7.30 |
| Node.js | 20 | 2026.7.30 |
| Node.js | 22 | - |
| Node.js | 24 | - |
| PHP | 8.1 | 2026.7.30 |
| PHP | 8.4 | - |
| PHP | 8.5 | - |
| Python | 3.9 | 2026.7.30 |
| Python | 3.10 | - |
| Python | 3.11 | - |
| Python | 3.14 | - |
Table. Supported Runtime Items
Caution
Runtime scheduled for deprecation
- For Runtime versions slated for deprecation, technical support is expected to end within 60 days (End of Technical Support) (detailed schedule will be announced on the console).
- When technical support for a Runtime version ends, security patches and updates will no longer be applied to that Runtime version.
- Already created functions can be used continuously without a call time limit, but they cannot be modified.
- We do not guarantee bugs, errors, defects, or vulnerabilities that arise in Runtime versions for which technical support has ended.
- We recommend migrating to and using an alternative version of a function that is scheduled for deprecation to ensure safe usage.
Provision status by region
The Cloud Functions service is available in the environments below.
| Region | Whether provided |
|---|---|
| Korea West 1 (kr-west1) | Provide |
| Korea East 1 (kr-east1) | Provided |
| South Korea 1 (kr-south1) | Not provided |
| South Korea South 2 (kr-south2) | Not provided |
| South Korea 3 (kr-south3) | Not provided |
Table. Cloud Functions regional availability status
Preceding Service
This is a list of services that can be configured as optional before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Application Service | API Gateway | A service that easily manages and monitors APIs |
Table. Cloud Functions prerequisite service
6.1.1 - ServiceWatch Metrics
Cloud Functions sends metrics to ServiceWatch. The metrics provided by default monitoring are data collected at a 1‑minute interval.
Reference
For how to view metrics in ServiceWatch, refer to the ServiceWatch guide.
Basic Metrics
The following are the basic metrics for the Cloud Functions namespace.
The metrics whose names are displayed in bold below are the metrics selected as key metrics among the default metrics provided by Cloud Functions. The key metrics are used to build service dashboards that are automatically created per service in ServiceWatch. You can also view the key metrics on the Monitoring tab of the Cloud Functions detail page.
Each metric guides users, through the user guide, on which statistical values are meaningful when querying that metric, and among the meaningful statistics, the values displayed in bold are the primary statistics. In the service dashboard or monitoring tab, you can view key metrics using these primary statistics.
| Performance items | Detailed description | unit | meaningful statistics |
|---|---|---|---|
| Invocations | Average number of times the function is called per unit time | Count |
|
| Success Calls | Average number of times the runtime code operates correctly and returns a response code per unit time during a function call. | Count |
|
| Error Calls | Average number of calls per unit time that encounter errors during function invocation, including runtime errors due to response timeouts and logic errors. | Count |
|
| Memory Usage | Average memory usage per unit time while the function is executing | Kilobytes |
|
| Active Operations | When a function is called multiple times simultaneously, the average number of tasks generated per unit time for concurrent processing. | Count |
|
Table. Cloud Functions Basic Metrics
6.2 - How-to guides
Users can create the service by entering the required information for Cloud Functions and selecting detailed options through the Samsung Cloud Platform Console.
Creating Cloud Functions
All Services > Compute > Cloud Functions Click the menu. 1. Go to the Service Home page of Cloud Functions.
On the Service Home page, click the Create Cloud Functions button. 2. Go to the Create Cloud Functions page.
On the Create Cloud Functions page, enter the information required to create the service.
Category RequiredDetailed description Function name Required Enter the name of the Funtion to create - Start with a lowercase English letter and use lowercase English letters, numbers, and special characters (
-) to enter between 3 and 64 characters
Runtime Required Select Runtime creation method - New: Create a new Runtime
- Start with Blueprint: Write using the Runtime source code provided by the service
Runtime & Vesion Essential Select Runtime and Version - When Create New is selected
- Refer to the Runtime & Version list in Components > Runtime
- For the Java runtime, UI code editing is not supported, but you can import a JAR file from Object Storage and execute it
- When Start with Blueprint is selected
- You can view a source code example by clicking the View Source Code button for that Runtime & Version
- Refer to the Blueprint Detailed Guide for more information on Blueprint settings
- If the Runtime version has reached End of Technical Support (EoTS), it cannot be modified after creation
Table. Cloud Functions service information input fields- Start with a lowercase English letter and use lowercase English letters, numbers, and special characters (
Summary Check the detailed information and estimated charges generated in the panel, and click the Create button.
- When creation is complete, check the created resources on the Cloud Functions list page.
information
After July 2026, you cannot create new functions for runtimes that are no longer supported. Note that already created user functions are not deleted.
View Cloud Functions details
Cloud Functions Details page consists of Details, Monitoring, Logs, Code, Configuration, Triggers, Tags, Job History tabs.
To view detailed information about the Cloud Functions service, follow these steps.
- All Services > Compute > Cloud Functions Click the menu. 1. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. 2. Function list Go to the page.
- On the Function list page, click the resource to view detailed information. 3. Navigate to the Function Details page.
- Function Details page displays status information and additional feature information, and consists of Details, Monitoring, Logs, Code, Configuration, Triggers, Tags, Job History tabs.
Category Detailed description Cloud Functions status Cloud Functions status information - Ready: green icon, a state where normal function invocations are possible
- Not Ready: gray icon, a state where normal function invocations are not possible
- Deploying: yellow icon, a state where the function is being created or updated, which triggers the next action
- Function creation and modification
- Code tab: edit code in the editor
- Code tab: inspect jar file
- Trigger tab: add and modify
- Configuration tab: modify
- Running: blue icon, a state where normal function invocations are possible and a cold‑start prevention policy is applied
Service cancellation Cancel service button Table. Cloud Functions status information and additional features
- Function Details page displays status information and additional feature information, and consists of Details, Monitoring, Logs, Code, Configuration, Triggers, Tags, Job History tabs.
Detailed Information
Function list page allows you to view detailed information of the selected resource and edit the information if needed.
| Category | Detailed description |
|---|---|
| service | Service name |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform |
| Resource name | Resource name
|
| Resource ID | Service’s unique resource ID |
| Constructor | User who created the service |
| Creation date and time | Service creation timestamp |
| Modifier | User who modified the service |
| Modification date | Date and time of service modification |
| Function name | Name of the Cloud Function |
| Runtime | Runtime types and versions
|
Table. Cloud Functions Details – Details Tab Items
Caution
- Even after technical support for the Runtime version ends, functions that have already been created can continue to be used without any call time limit. * However, security patches and updates for that Runtime version will not be applied.
- Bugs, errors, defects, or vulnerabilities that occur in Runtime versions that are no longer supported are not covered.
- If support for a Runtime has ended, the user must create a replacement Runtime version and then manually delete the function of the previous version.
- To use this function safely, create a new instance using the Lastest or Stable version.
Monitoring
Function List page lets you view the Cloud Functions usage information for the selected resource.
| Category | Detailed description |
|---|---|
| Number of calls | Average number of times the function is called per unit time (instances) |
| execution time | Average execution time (seconds) of the function per unit time |
| Memory usage | Average memory usage (KB) during the function execution per unit time |
| Current number of tasks | When the function is called multiple times simultaneously, the average number of tasks (count) generated per unit time for concurrent processing. |
| Successful call count | Average number of times (cases) the runtime code operated correctly and returned a response code per unit time during a function call. |
| Failed call count | Average number of calls with errors per unit time during function invocation
|
Table. Cloud Functions Details – Monitoring Tab Items
log
Function list page allows you to view the Cloud Functions logs of the selected resource.
| Category | Detailed description |
|---|---|
| unit period | Select the period to view Cloud Functions log information
|
| log message | Functions are displayed in order, starting with the most recent occurrence. |
Table. Cloud Functions Details – Log Tab Items
Reference
Log messages can be viewed up to the previous 1,000 entries based on the most recent occurrence.
code
Function List page lets you view and edit the Cloud Functions code of the selected resource.
Reference
The way to view and edit source code varies depending on the runtime used.
- Inline Editor: Node.js, Python, PHP, Go
- Compressed file (.jar/.zip) execution: Java
| Category | Detailed description |
|---|---|
| source code | Inline editor method |
| code information | Display code information |
| Edit | After clicking the Edit button, you can modify the code in the inline editor. |
Table. Cloud Functions Details – Inline Editor Items in the Code Tab
| Category | Detailed description |
|---|---|
| source code | Execution method for compressed files (.jar/.zip) |
| code information | Display compressed file information
|
| Edit | Jar file can be modified
|
Table. Cloud Functions Details - Execution items for compressed files (.jar/.zip) in the Code tab
Reference
- If technical support for the runtime version has ended, you cannot modify the code. * Also, because security patches and updates are not applied, create and use the function anew with the Latest or Stable version to ensure safe usage.
- In the case of Java Runtime, it does not provide a UI code editing feature, and you must select a compressed file (.jar/.zip) from a bucket in the Object Storage service.
- If a user does not have an authentication key generated for the Object Storage service, they cannot execute Import from Object Storage, so they must create an authentication key in advance.
- For detailed information on creating an authentication key, see Creating an Authentication Key.
- The Object Storage bucket for the Cloud Functions service must have its access control set to allow.
- For detailed information on Object Storage access control, see Allowing Cloud Functions Service Access.
Configuration
On the Function list page, you can view the Cloud Functions configuration of the selected resource.
| Category | Detailed description |
|---|---|
| General configuration | Memory and timeout settings of Cloud Function
|
| function URL | Issue an HTTPS URL address that can access the function
|
| environment variable | Set runtime environment variables
|
| Private connection configuration | Can be used in conjunction with PrivateLink Service
|
| Permission | Add and manage resource policies for IAM-based functions
|
Table. Cloud Functions Details - Configuration Tab Items
Caution
- If technical support for the Runtime version has been discontinued, configuration items cannot be modified. * Also, because security patches and updates are not applied, create and use the function anew with the Latest or Stable version to ensure safe usage.
- If access control is disabled, the registered access information is deleted, making function access control impossible, which can expose the system to security attacks such as external scanning, hacking, etc.
Reference
- CPU cores proportional to the memory allocation of General configuration are automatically assigned.
- If the minimum number of executions of General configuration is 1 or more, Cold Start is prevented, but continuous costs are incurred.
Trigger
On the Function List page, you can view and configure the trigger information of the selected resource. By setting a trigger, you can automatically execute the Function when an event occurs.
| Category | Detailed description |
|---|---|
| Cronjob | Use Cronjob as a trigger
|
| API Gateway | Use API Gateway as a trigger
|
Table. Cloud Functions Details – Trigger Tab Items
Caution
- If technical support for the Runtime version has ended, you cannot modify the trigger item. * Also, because security patches and updates are not applied, create and use the function anew with the Latest or Stable version to ensure safe usage.
- If the Cronjob trigger is called before the function’s timeout, the function will execute concurrently, increasing both the execution count and the total time. * Therefore, be cautious because continuous additional costs can lead to high expenses.
Reference
- If the status is Deploying, it cannot be modified.
- Refer to Setting up triggers for trigger configuration.
Tag
In the Tag tab, you can view the resource’s tag information, and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Cloud Functions Details – Tag Tab Items
Job History
Job History page allows you to view the resource’s job history.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Cloud Functions Details – Job History Tab Items
Changing Java Runtime code
If you are using Java Runtime, you cannot modify the code directly, so you must select and replace the archive file (.jar/.zip) in the bucket of the Object Storage service.
Reference
If technical support for the runtime version has ended, you cannot modify the code. Also, because security patches and updates are not applied, create and use the function anew with the Latest or Stable version to ensure safe usage.
To modify a compressed file, follow these steps.
All Services > Compute > Cloud Functions menu, click. 1. Navigate to the Service Home page of Cloud Functions.
On the Service Home page, click the Function menu. 2. Go to the Function list page.
On the Function List page, click the resource to change the compressed file in the code. 3. Go to the Function Details page.
Click the Edit button on the Code tab of the Function Details page. 4. Edit Function code Navigate to the page.
Click the Import from Object Storage button. 5. Import from Object Storage The popup window opens.
Category Detailed description Java Runtime Java Runtime Information Handler information Handler information - Execution Class: Automatically entered when setting the archive file (.jar/.zip)
- Execution Method: Automatically entered when setting the archive file (.jar/.zip)
Compressed file (.jar/.zip) Set the archive file to modify - Archive file name (.jar/.zip): Displays the name of the archive file. Import from Object Storage after configuration, it is entered automatically
- Import from Object Storage: Configure the Object Storage to retrieve the archive file (.jar/.zip)
Table. Cloud Functions Details - Function Code Modification ItemsEnter the URL information of the Object Storage to retrieve the compressed file in Object Storage URL, then click the Confirm button. 6. The notification popup opens.
- URL information can be found in the Folder List tab of the detailed page of the Object Storage to retrieve, under the File Information > Private URL item.
Click the Confirm button. 7. On the Function code edit page, the name of the imported compressed file is displayed in the Compressed file name (.jar/.zip).
Click the Save button.
Caution
- Users without a generated authentication key cannot execute Import from Object Storage.
- If the URL does not exist or the archive file matches any of the following, it cannot be changed.
- When using an unsupported file extension
- If there are harmful files inside the compressed file.
- If the size exceeds the supported limit
Terminate Cloud Functions
To cancel the Cloud Functions service, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. 1. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. 2. Navigate to the Function list page.
- On the Function List page, click the resource you want to terminate and then click the Terminate Service button.
- When the termination is complete, check on the Function list page whether the resource has been terminated.
6.2.1 - Configure Trigger
Configure Trigger
Note
- By default, all triggers can be added in Cloud Functions.
- If it is triggered for a specific product, it should be passed to Cloud Functions.
Setting up Cronjob trigger
To set up a Cronjob trigger, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function list page.
- Function List page, click the resource for which you want to set a trigger. You will be taken to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. Set it. The Add Trigger popup window opens.
- Add Trigger In the popup, select Cronjob from Trigger Type. A required information input area appears at the bottom.
Category Detailed description Cronjob configuration Set the trigger’s repeat frequency - Can be set in minutes, hours, days, months, weekdays
Timezone setting Set the trigger’s reference time zone Table. Cronjob Trigger Required Information Items - After entering the required information, click the Confirm button.
- When the popup notifying an addition opens, click the Confirm button.
Configure API Gateway Trigger
To set up an API Gateway trigger, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Click the resource to set the trigger on the Function List page. Go to the Function Details page.
- Click the Trigger tab, then click the Add Trigger button. Set it. The Add Trigger popup opens.
- In the Add Trigger popup, select API Gateway under Trigger Type. A required information input area appears at the bottom.
Category Detailed description API name Select API - You can select an existing API or create a new one
Stage Select deployment target - You can select an existing stage or create a new one
Table. API Gateway Trigger Required Information Items - After entering the required information, click the Confirm button.
- When the popup notifying the addition opens, click the Confirm button.
Configure Multi-Trigger
You can attach multiple triggers to a single function.
Modify Trigger
To modify the added trigger, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function list page.
- On the Function List page, click the resource to edit the trigger. You will be taken to the Function Details page.
- Click the Trigger tab, then in the trigger list, click the Edit button of the trigger whose settings you want to modify. The Edit Trigger popup window opens.
- Edit Trigger After modifying the settings in the popup window, click the Confirm button.
- The configuration values differ depending on the trigger type (refer to Cronjob Trigger, API Gateway Trigger).
- When the edit notification popup appears, click Confirm.
Delete Trigger
To delete a trigger, follow these steps.
Caution
A trigger linked to a specific product manages only the product delivered at the time of linking, and when the Functions are terminated, it must convey a deletion status to that product.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Function List page, click the resource for which you want to set a trigger. You will be taken to the Function Details page.
- In the Trigger tab’s trigger list, select the trigger you want to delete, then click the Delete button.
- When the popup notifying you of trigger deletion opens, click the Confirm button.
6.2.2 - Blueprint Detailed Guide
Blueprint Overview
When creating Cloud Functions, you can set a Blueprint to utilize the Runtime source code provided by Cloud Functions. Refer to the following for the Blueprint items provided by Cloud Functions.
| Category | Detailed description | Remarks |
|---|---|---|
| Hello World | When the function is invoked, it responds with Hello Serverless World! | |
| Execution after timeout | It outputs code that should run after the function call timeout but does not execute. | PHP, Python not supported |
| HTTP request body | Parse the request body. | PHP not supported |
| Send HTTP requests | The Cloud function sends an HTTP request. | PHP not supported |
| Print logs | Logs the user’s Samsung Cloud Platform Console request. | PHP not supported |
| Throw a custom error | Enter the error logic directly to handle the error. | |
| Using Environment Variable | Configure environment variables within the Cloud function and execute it. |
Table. Blueprint Items
Hello World
Hello World Explains the response-receiving configuration and a function call example (using the function URL).
Hello World Setup
To set up Hello World, follow these steps.
Click the All Services > Compute > Cloud Functions menu. Go to the Service Home page of Cloud Functions.
On the Service Home page, click the Function menu. You will be taken to the Function List page.
Function List page, click the resource to be called via URL. You will be taken to the Function Detail page.
After clicking the Configuration tab, click the Edit button for the Function URL item. The Edit Function URL popup window opens.
In the Function URL Edit popup, set Activation status to Enabled, then click the Confirm button.
Category Detailed description Enable status Configure the use of the function URL Authentication type Select whether to use IAM authentication for requests to the function URL Access control Add accessible IPs to enable management - Set to Use, then you can input and add a public access IP
Table. Required input fields when adding a triggerAfter navigating to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; };Hello World - Node.js source code - Python source codeColor mode
import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps('Hello Serverless World!') }import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps('Hello Serverless World!') }Hello World - Python source code - PHP source codeColor mode
<?php function handle_request() { # User writing area (Function details) $res = array( 'statusCode' => 200, 'body' => 'Hello Serverless World!', ); return $res; } ?><?php function handle_request() { # User writing area (Function details) $res = array( 'statusCode' => 200, 'body' => 'Hello Serverless World!', ); return $res; } ?>Hello World - PHP source code
- Node.js source code
Check function call
On the Function Details page, in the Configuration tab, invoke the function URL and then verify the response.
Hello Serverless World!
Execution after timeout
Describes configuring execution after timeout (Execution after timeout) and provides an example of invoking the function (using the function URL).
Configure execution after timeout
To set Execution after timeout, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- On the Function List page, click the resource for which you want to set a trigger. You will be taken to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- Add Trigger In the popup window, after selecting the Trigger Type item, enter the required information displayed at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency(minute, hour, day, month, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input fields when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ console.log("Hello world 3"); await delay(3000); const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; }; const delay = (ms) => { return new Promise(resolve=>{ setTimeout(resolve,ms) }) }exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ console.log("Hello world 3"); await delay(3000); const response = { statusCode: 200, body: JSON.stringify('Hello Serverless World!'), }; return response; }; const delay = (ms) => { return new Promise(resolve=>{ setTimeout(resolve,ms) }) }Execution after timeout - Node.js source code
- Node.js source code
Check function call
On the Function Detail page’s Configuration tab, invoke the function URL and, after a brief period, check the response.
Hello Serverless World!
HTTP request body
Explains the configuration for parsing the Request Body and an example of calling the function (using the function URL).
Setting HTTP request body
To set the HTTP request body, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Function List page, click the resource to set the trigger. You will be taken to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- Add Trigger In the popup window, select the Trigger Type option, then fill in the required information shown at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency (minutes, hours, day, month, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input fields when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; return response; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; return response; };Execution after timeout - Node.js source code - Python source codeColor mode
import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps(params.json) }import json def handle_request(params): # User writing area (Function details) return { 'statusCode': 200, 'body': json.dumps(params.json) }Execution after timeout - Python source code
- Node.js source code
Check function call
In the Configuration tab of the Function Details page, after calling the Function URL, check the Body data, request Body value, and response Body value.
Request Body value
Color mode{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }Request Body value Response Body value
Color mode{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }{ "testKey" :"cloud-001", "testNames": [ { "name": "Son" }, { "name": "Kim" } ], "testCode":"test" }Response Body value
Send HTTP requests
Explains the HTTP request configuration and an example of calling a function (using the function URL).
Send HTTP requests Configure
To configure Send HTTP requests, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Click the resource to set the trigger on the Function List page. Go to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- Add Trigger In the popup window, after selecting the Trigger Type item, enter the required information displayed at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency (minutes, hours, day, month, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input items when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { // Port 80 and Port 443 are available url = "https://example.com"; // Destination URL const options = { uri: url, method:'GET', json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }const request = require('request'); /** * @description User writing area (Function details) */ exports.handleRequest = async function (params) { return await sendRequest(params); }; async function sendRequest(req) { return new Promise((resolve, reject) => { // Port 80 and Port 443 are available url = "https://example.com"; // Destination URL const options = { uri: url, method:'GET', json: true, strictSSL: false, rejectUnauthorized: false } request(options, (error, response, body) => { if (error) { reject(error); } else { resolve({ statusCode: response.statusCode, body: JSON.stringify(body) }); } }); }); }Send HTTP requests - Node.js source code - Python source codeColor mode
import json import requests def handle_request(params): # User writing area (Function details) # Port 80 and Port 443 are available url = "https://example.com" # Destination URL try: response = requests.get(url, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)import json import requests def handle_request(params): # User writing area (Function details) # Port 80 and Port 443 are available url = "https://example.com" # Destination URL try: response = requests.get(url, verify=True) return { 'statusCode': response.status_code, 'body': json.dumps(response.text) } except requests.exceptions.RequestException as e: return str(e)Send HTTP requests - Python source code
- Node.js source code
Check Function Call
On the Function Details page, after invoking the function URL in the Configuration tab, verify the response.
Color mode
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html><!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>Print logs
This explains how to configure log output and an example of calling a function (using the function URL).
Configure Print logs
Print logs To set up response receiving, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Function List page, click the resource to set the trigger. Function Details page will be displayed.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- In the Add Trigger popup, select the Trigger Type item, then enter the required information displayed at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency(minutes, hours, day, month, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input fields when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
const winston = require('winston'); // Log module setting const logger = winston.createLogger({ format: winston.format.combine( winston.format.timestamp(), winston.format.printf(info => info.timestamp + ' ' + info.level + ': ' + info.message) ), transports: [ new winston.transports.Console() ] }); exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; logger.info(JSON.stringify(response, null, 2)); return response; };const winston = require('winston'); // Log module setting const logger = winston.createLogger({ format: winston.format.combine( winston.format.timestamp(), winston.format.printf(info => info.timestamp + ' ' + info.level + ': ' + info.message) ), transports: [ new winston.transports.Console() ] }); exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ const response = { statusCode: 200, body: JSON.stringify(params.body), }; logger.info(JSON.stringify(response, null, 2)); return response; };Print logs - Node.js source code - Python source codeColor mode
import json import logging # Log module setting logging.basicConfig(level=logging.INFO) def handle_request(params): # User writing area (Function details) response = { 'statusCode': 200, 'body': json.dumps(params.json) } logging.info(response) return responseimport json import logging # Log module setting logging.basicConfig(level=logging.INFO) def handle_request(params): # User writing area (Function details) response = { 'statusCode': 200, 'body': json.dumps(params.json) } logging.info(response) return responsePrint logs - Python source code
- Node.js source code
Check Function Call
After calling the function URL in the Configuration tab of the Function Details page, check the log in the Log tab.
Color mode
[2023-09-07] 12:06:23] "host": "scf-xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-id": "xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-source": "xxxxxxxxxxxxxxxxxxxxx",[2023-09-07] 12:06:23] "host": "scf-xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-id": "xxxxxxxxxxxxxxxxxxxxx",
[2023-09-07] 12:06:23] "ce-source": "xxxxxxxxxxxxxxxxxxxxx",Throw a custom error
Explains setting up a custom error (Throw a custom error) and an example of calling a function (using a function URL).
Configure Throw a custom error
To configure Throw a custom error, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Click the resource to set the trigger on the Function List page. Go to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- Add Trigger In the popup window, after selecting the Trigger Type item, enter the required information displayed at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency (minutes, hours, day, month, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input fields when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
class CustomError extends Error { constructor(message) { super(message); this.name = 'CustomError'; } } exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ throw new CustomError('This is a custom error!'); };class CustomError extends Error { constructor(message) { super(message); this.name = 'CustomError'; } } exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ throw new CustomError('This is a custom error!'); };Throw a custom error - Node.js source code - Python source codeColor mode
class CustomError(Exception): def __init__(self, message): self.message = message def handle_request(parmas): raise CustomError('This is a custom error!')class CustomError(Exception): def __init__(self, message): self.message = message def handle_request(parmas): raise CustomError('This is a custom error!')Throw a custom error - Python source code - PHP source codeColor mode
<?php class CustomError extends Exception { public function __construct($message) { parent::__construct($message); $this->message = $message; } } function handle_request() { throw new CustomError('This is a custom error!'); } ?><?php class CustomError extends Exception { public function __construct($message) { parent::__construct($message); $this->message = $message; } } function handle_request() { throw new CustomError('This is a custom error!'); } ?>Throw a custom error - PHP source code
- Node.js source code
Check Function Call
On the Function Details page, after calling the Function URL in the Configuration tab, verify whether an error occurred in the Log tab.
Using Environment Variable
Explains the use of environment variables (Using Environment Variable) settings and a function call example (using function URL).
Using Environment Variable Configure
To configure Using Environment Variable, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function List page.
- Click the resource to set the trigger on the Function List page. Go to the Function Details page.
- After clicking the Trigger tab, click the Add Trigger button. The Add Trigger popup window opens.
- In the Add Trigger popup, select the Trigger Type item, then enter the required information displayed at the bottom and click the OK button.
- Required information varies depending on the trigger type.
Trigger Types Input field API Gateway - API name: Select an existing API or create a new one
- Stage: Select an existing stage or create a new one
Cronjob - Refer to the example and enter the trigger’s repeat frequency(minutes, hours, days, months, day of week)
- Timezone setting: select the reference time zone to apply
Table. Required input fields when adding a trigger
- Required information varies depending on the trigger type.
- After moving to the Code tab, click the Edit button. You will be taken to the Function Code Edit page.
- After adding the handling logic for success and failure cases, click the Save button.
- Node.js source codeColor mode
exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ return process.env.test; };exports.handleRequest = async function (params) { /** * @description User writing area (Function details) */ return process.env.test; };Using Environment Variable - Node.js source code - Python source codeColor mode
import json import os def handle_request(params): # User writing area (Function details) return os.environ.get("test")import json import os def handle_request(params): # User writing area (Function details) return os.environ.get("test")Using Environment Variable - Python source code - PHP source codeColor mode
import json def handle_request(params): # User writing area (Function details) return os.environ.get("test")import json def handle_request(params): # User writing area (Function details) return os.environ.get("test")Using Environment Variable - PHP source code
- Node.js source code
- After moving to the Configuration tab, click the Edit button in the Environment Variables area. The Edit Environment Variables popup will open.
- After entering the environment variable information, click the Confirm button.
Category Detailed description Name Enter the key value value Enter the value Table. Environment Variable Input Items
Check function call
On the Function Details page, after calling the function URL in the Configuration tab, check the environment variable value in the Log tab.
6.2.3 - Integrate PrivateLink Service
By integrating Cloud Functions with the PrivateLink service, you can connect VPCs within the Samsung Cloud Platform to other VPCs, and VPCs to services, without using the external internet.
The data uses only the internal network, providing high security, and does not require public IP, NAT, VPN, or an internet gateway.
Enable PrivateLink Service
To connect the PrivateLink Service, you must first enable the service.
To enable the PrivateLink service, follow these steps.
- All Services > Compute > Cloud Functions Click the menu. 1. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. 2. Go to the Function list page.
- On the Function List page, click the resource to associate with PrivateLink. 3. Function Details page.
- On the Function Details page, click the Configuration tab.
- In Private connection configuration, click the Edit button of PrivateLink Service. 5. PrivateLink Service Edit The popup window opens.
- PrivateLink Service Edit In the popup window, after checking the Use item of Activation Status, click the Confirm button. 6. Configuration tab’s Private connection configuration displays PrivateLink Service information.
| Category | Detailed description |
|---|---|
| Private URL | PrivateLink Service URL information |
| PrivateLink Service ID | PrivateLink Service ID information |
| Request Endpoint Management | List of PrivateLink Endpoints that requested a PrivateLink Service connection
|
Table. PrivateLink Service detailed information items
Integrating PrivateLink Service
You can expose the function for private access from another VPC by integrating with PrivateLink Service.
information
Activate the PrivateLink Service first, then proceed with the integration work.
To integrate the PrivateLink service, review the following tasks.
- Register the domain for the PrivateLink Endpoint IP address and the Private URL address to invoke the issued Private URL.
192.168.0.13 abc123.scf.private.kr-west1.qa2.samsungsdscloud.com - When invoking the PrivateLink Service, verify IAM authentication based on the credentials of the Endpoint creator required for the Endpoint.
Create PrivateLink Endpoint
Create an entry point to access the PrivateLink Service of the user VPC.
Caution
Additional costs may be incurred when creating an endpoint.
To create a PrivateLink Endpoint, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. 1. Go to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. 2. Go to the Function list page.
- On the Function list page, click the resource to associate with PrivateLink. 3. Function Details Go to the page.
- On the Function Details page, click the Configuration tab.
- Click the Add button in Private connection configuration of PrivateLink Endpoint. 5. Add PrivateLink Endpoint The popup window opens.
- Add PrivateLink Service in the popup window, after entering the PrivateLink Service ID and Alias information, click the Confirm button.
- When the popup indicating creation opens, click the Confirm button. 7. Configuration tab’s Private connection configuration displays PrivateLink Endpoint information.
| Category | Detailed description |
|---|---|
| PrivateLink Endpoint ID | PrivateLink Endpoint ID information |
| PrivateLink Service ID | PrivateLink Service ID information |
| Alias | hostalias information that can be used instead of an IP address for accessing a PrivateLink Endpoint |
| status | Approval status of PrivateLink Endpoint
|
Table. PrivateLink Endpoint detailed information items
Integrating APIGW Private EPS
To connect the SCF Endpoint and the APIGW Private Endpoint, you must specify the Private URL in the SCF Endpoint Alias instead of the APIGW EPS resource path.
- Private URL example:
181b6126ef6d4e4b81370df5.apigw.private.kr-west1.s.samsungsdscloud.com/get/resourcepath
To integrate APIGW Private EPS, refer to the following code.
Color mode
const request = require('request');
/**
* @description User writing area (Function details)
*/
exports.handleRequest = async function (params) {
return await sendRequest(params);
};
async function sendRequest(req) {
return new Promise((resolve, reject) => {
// Port 80 and Port 443 are available
url = "https://{alias}/{resource_path}"; // Destination URL
/**
{alias} is the alias name entered when creating an Endpoint within the function
{resoure_path} is the resource path (/get/resourcepath) specified in the Private URL of APIGW EPS
*/
const options = {
uri: url,
method:'GET',
json: true,
strictSSL: false,
rejectUnauthorized: false
}
request(options, (error, response, body) => {
if (error) {
reject(error);
} else {
resolve({
statusCode: response.statusCode,
body: JSON.stringify(body)
});
}
});
});
}const request = require('request');
/**
* @description User writing area (Function details)
*/
exports.handleRequest = async function (params) {
return await sendRequest(params);
};
async function sendRequest(req) {
return new Promise((resolve, reject) => {
// Port 80 and Port 443 are available
url = "https://{alias}/{resource_path}"; // Destination URL
/**
{alias} is the alias name entered when creating an Endpoint within the function
{resoure_path} is the resource path (/get/resourcepath) specified in the Private URL of APIGW EPS
*/
const options = {
uri: url,
method:'GET',
json: true,
strictSSL: false,
rejectUnauthorized: false
}
request(options, (error, response, body) => {
if (error) {
reject(error);
} else {
resolve({
statusCode: response.statusCode,
body: JSON.stringify(body)
});
}
});
});
}6.2.4 - Resource-based Policy Guide
Resource-based policy overview
The resource-based policy (Resource-based Policy) of Cloud Functions is a policy granted to a resource that can decide to allow or deny (Effect) an action (Action) on a specific resource for a principal (Principal). You can directly define the principal that can invoke a function by using resource-based policies.
Reference
While a typical IAM policy (Identity-based) grants permissions to a user, a resource-based policy is applied to the function itself to allow external access.
You can allow function calls by defining the following in a resource-based policy.
- User of the specified Samsung Cloud Platform account
- Specified source IP address range or CIDR block
A source policy is defined as a JSON policy document attached to the API, which controls whether the specified security principal (typically an IAM role or group) can call the API.
| Category | description | example |
|---|---|---|
| Principal | Specify the caller of the function | Specific object storage bucket, API Gateway, other Samsung Cloud Platform accounts, etc. |
| Task(Action) | Define the allowed functions | Mostly scf:InvokeFunction |
| Condition(Condition) | Restrict to allow only in specific situations | Allow only requests originating from a bucket with a specific SRN. |
Table. Entity that controls API call execution
Reference
- Cloud Functions’ resource-based policies leverage the rules of IAM’s resource-based policies.
- For instructions on creating or modifying policies using JSON, refer to the JSON Mode Utilization Guide.
Resource-based policy usage scenario
The primary use cases for resource-based policies are as follows.
Resource-based policy scenario
The resource-based policy scenarios used when a Cloud Functions function runs are as follows.
| Category | description | Reference example |
|---|---|---|
| Function URL - Authentication Type None | It is required when generating a function URL for invocation.
| Function URL (Auth Type None) Example |
| Function URL - Authentication Type IAM |
| Function URL (authentication type IAM) example |
| API Gateway trigger | It is required when API Gateway calls Lambda to handle external API requests.
| API Gateway Trigger Example |
| PrivateLink connection | You can connect a PrivateLink Service to define the function for private access from another VPC.
| PrivateLink connection example |
Table. Resource-based policy scenario
User addition usage scenario
Although it is not automatically registered as a resource-based policy for Cloud Functions, users can add and use it as needed. The scenarios that users can add and utilize are as follows.
- Cross-Account Access
- If an IAM user in account A wants to invoke a Lambda in account B, register account A in the function policy of account B.
- Hybrid Access Control
- It can be configured so that access is allowed only when both conditions are met—a specific user and a specific IP range—rather than merely restricting by account or IP alone.
Resource-based policy management for Cloud Functions
To view and configure resource-based policies for Cloud Functions, follow these steps.
- Click the All Services > Compute > Cloud Functions menu. Navigate to the Service Home page of Cloud Functions.
- On the Service Home page, click the Function menu. You will be taken to the Function list page.
- On the Function List page, click the resource for which you want to set a policy. You will be taken to the Function Details page.
- Click the Configuration tab on the Function Details page.
- Click the Edit button of the Resource-based policy permission item. The Resource policy edit popup window opens.
- In the Resource Policy edit popup, after selecting the Policy Template, write the policy.
- For policy examples by policy template, refer to Resource-based policy examples.
- When the writing is complete, click the Confirm button.
- Click the Delete button to delete the registered policy.
Example of resource-based policy
Users can define additional resource-based policies as needed or modify existing policies for use.
Reference
- For some features, a resource‑based policy (or credential) must be registered to use them in Cloud Functions.
- In the resource-based policy examples described in this guide, Cloud Functions automatically registers the example resource-based policies when each feature is enabled or linked.
Function URL - Authentication Type None
Principal is /* a policy that allows public calls.
Policy Template
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["NONE"]
}
},
"Effect": "Allow"
"Principal": "*"
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "InvokeFunctionURLAllowPublicAccess"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["NONE"]
}
},
"Effect": "Allow"
"Principal": "*"
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "InvokeFunctionURLAllowPublicAccess"
}
],
"Version": "2024-07-01"
}Policy example
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["NONE"]
}
},
"Effect": "Allow"
"Principal": "*"
"Resource": ["srn:e::accountID:kr-west1::scf:cloud-function/functionsID"],
"Sid": "InvokeFunctionURLAllowPublicAccess"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["NONE"]
}
},
"Effect": "Allow"
"Principal": "*"
"Resource": ["srn:e::accountID:kr-west1::scf:cloud-function/functionsID"],
"Sid": "InvokeFunctionURLAllowPublicAccess"
}
],
"Version": "2024-07-01"
}Function URL - Authentication Type IAM
This policy permits a specific user to invoke a public URL.
Policy Template
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": {
"scp": ["srn:{{Environment}}::{{AccountID}}:::iam:user/{{UserId}}"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": {
"scp": ["srn:{{Environment}}::{{AccountID}}:::iam:user/{{UserId}}"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}Policy Example
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": "*",
"Resource": ["srn:e::accountID:kr-west1::scf:cloud-function/functionsID"],
"Sid": "accountID-iam-invokefunctionurl"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunctionUrl"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": "*",
"Resource": ["srn:e::accountID:kr-west1::scf:cloud-function/functionsID"],
"Sid": "accountID-iam-invokefunctionurl"
}
],
"Version": "2024-07-01"
}API Gateway trigger
Principal is a policy that permits public calls with a * principal.
Policy Template
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunction"],
"Condition": {
"SrnLike": {
"scp:RequestAttribute/body['x-scf-request-obj-srn']": ["{{ApiGatewayMethodSrn}}"]
}
},
"Effect": "Allow",
"Principal": {
"Service": ["apigateway.samsungsdscloud.com"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunction"],
"Condition": {
"SrnLike": {
"scp:RequestAttribute/body['x-scf-request-obj-srn']": ["{{ApiGatewayMethodSrn}}"]
}
},
"Effect": "Allow",
"Principal": {
"Service": ["apigateway.samsungsdscloud.com"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}Policy Example
Color mode
{
"Statement": [
{
"Action": [
scf:InvokeFunction
],
"Condition": {
"SrnLike": {
"scp:RequestAttribute/body['x-scf-request-obj-srn']": [
srn:e::accountID:kr-west1::apigateway:method/MethodID/*/GET/test
]
}
},
"Effect": "Allow"
"Principal": {
"Service": [
"apigateway.samsungsdscloud.com"
]
},
"Resource": [
srn:e::accountID:kr-west1::scf:cloud-function/functionID
],
"Sid": "999e9a9999de4d4683c9e10c74ee999z"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": [
scf:InvokeFunction
],
"Condition": {
"SrnLike": {
"scp:RequestAttribute/body['x-scf-request-obj-srn']": [
srn:e::accountID:kr-west1::apigateway:method/MethodID/*/GET/test
]
}
},
"Effect": "Allow"
"Principal": {
"Service": [
"apigateway.samsungsdscloud.com"
]
},
"Resource": [
srn:e::accountID:kr-west1::scf:cloud-function/functionID
],
"Sid": "999e9a9999de4d4683c9e10c74ee999z"
}
],
"Version": "2024-07-01"
}PrivateLink connection
This is a policy that allows function calls through a Privatelink Endpoint for specific users.
Policy Template
Color mode
{
"Statement": [
{
"Action": ["scf:InvokeFunction"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionPrivatelinkServiceAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": {
"scp": ["srn:{{Environment}}::{{AccountID}}:::iam:user/{{UserId}}"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": ["scf:InvokeFunction"],
"Condition": {
"StringEquals": {
"scf:CloudFunctionPrivatelinkServiceAuthType": ["SCP_IAM"]
}
},
"Effect": "Allow"
"Principal": {
"scp": ["srn:{{Environment}}::{{AccountID}}:::iam:user/{{UserId}}"]
},
"Resource": ["{{CloudFunctionSrn}}"],
"Sid": "Statement1"
}
],
"Version": "2024-07-01"
}Policy Example
Color mode
{
"Statement": [
{
"Action": [
scf:InvokeFunction
],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": [
SCP_IAM
]
}
},
"Effect": "Allow",
"Principal": {
"scp": [
srn:e::accountID:::iam:user/userID
]
},
"Resource": [
srn:e::accountID:kr-west1::scf:cloud-function/functionID
],
"Sid": "rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr-privatelink-invokefunction"
}
],
"Version": "2024-07-01"
}{
"Statement": [
{
"Action": [
scf:InvokeFunction
],
"Condition": {
"StringEquals": {
"scf:CloudFunctionAuthType": [
SCP_IAM
]
}
},
"Effect": "Allow",
"Principal": {
"scp": [
srn:e::accountID:::iam:user/userID
]
},
"Resource": [
srn:e::accountID:kr-west1::scf:cloud-function/functionID
],
"Sid": "rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr-privatelink-invokefunction"
}
],
"Version": "2024-07-01"
}6.3 - API Reference
API Reference
6.4 - CLI Reference
CLI Reference
6.5 - Release Note
Cloud Functions
2026.05.21
CHANGED
Added information on the termination of support for each Runtime version and discontinued AIOS integration- Technical support end-of-life information (EoTS) for the Runtime version is provided.
- When technical support ends, security patches and updates will no longer be applied to that Runtime version.
- Already created functions can be used continuously without any call time limit. * However, we do not guarantee bugs, errors, defects, or vulnerabilities that arise in Runtime versions for which support has ended.
- End of technical support scheduled The Runtime versions are as follows (For the full list of supported Runtime versions, see Rutime)
- GO: 1.21, 1.23
- Node.js: 18, 20
- PHP 8.1
- Python: 3.9
- Including runtime of additionally excluded functions
- The AIOS service integration has been stopped.
- Since the AIOS service has been discontinued, the AIOS integration service has been removed from Cloud Functions.
2026.03.19
FEATURE
Add resource-based policy feature- You can set a resource-based policy on the function.
- Resource-based policies are policies applied directly to the function that permit external access.
- You can use resource-based policies to allow or deny actions on specific resources to specific principals.
2025.12.16
FEATURE
AIOS, PrivateLink service integration- You can use functions in conjunction with the AIOS service.
- You can integrate Cloud Functions with AIOS to utilize LLMs.
- You can use the function in conjunction with the PrivateLink service.
- Through a Private connection (PrivateLink), you can establish internal connections between VPCs and between a VPC and a service on the Samsung Cloud Platform without traversing the Internet.
2025.10.23
FEATURE
Add Java Runtime executable file upload feature- The feature to upload Java Runtime executable files has been added.
- You can import and configure a Java Runtime executable archive file (.jar/.zip) in Object Storage.
2025.07.01
NEW
Cloud Functions official version launch- We have officially launched the Cloud Functions service.
- It is a serverless computing‑based FaaS (Function as a Service) that lets you easily run function‑style applications without server provisioning.
7 - Virtual Server DR
When the system is disrupted due to various disaster situations and risk factors, you can replicate the Block Storage attached to a Virtual Server in another region to restore normal operation quickly.
7.1 - Overview
Service Overview
Virtual Server DR is a service that quickly restores the system by replicating the Virtual Server and its attached Block Storage to a region different from the one currently in use. Even if the system is disrupted due to various disaster situations or unexpected events, you can quickly restore normal operation by using Virtual Server DR.
Notice
- The Virtual Server DR service can be configured using partner solutions sold on the Samsung Cloud Platform Marketplace.
- For detailed information on using the Marketplace, please refer to Marketplace.
Caution
- When you purchase and use a service sold on the Marketplace, a delegated tax invoice is issued in accordance with a separate agreement with the Marketplace software supplier.
- If you request a partner solution product for Virtual Server DR from the Marketplace, the request information will be emailed to the responsible person. Coordinate product details and schedule with the person in charge. Software installation and charges will be billed based on the confirmed date.
- The services sold in the Marketplace of Samsung Cloud Platform are offered by individual sellers, and Samsung SDS serves as an e‑commerce intermediary, not a party to the sales. Accordingly, Samsung SDS does not guarantee or assume responsibility for the service information or transactions conducted by individual sellers.
Features
- Easy DR Environment Setup: You can easily configure a Virtual Server for DR setup through partner solutions in the Marketplace of Samsung Cloud Platform.
- Various Environment Configurations: Using partner solutions, you can configure various environments such as physical to virtual (P2V) and virtual to virtual (V2V) environments, and it supports multiple operating systems (Windows, Linux).
Service Architecture Diagram
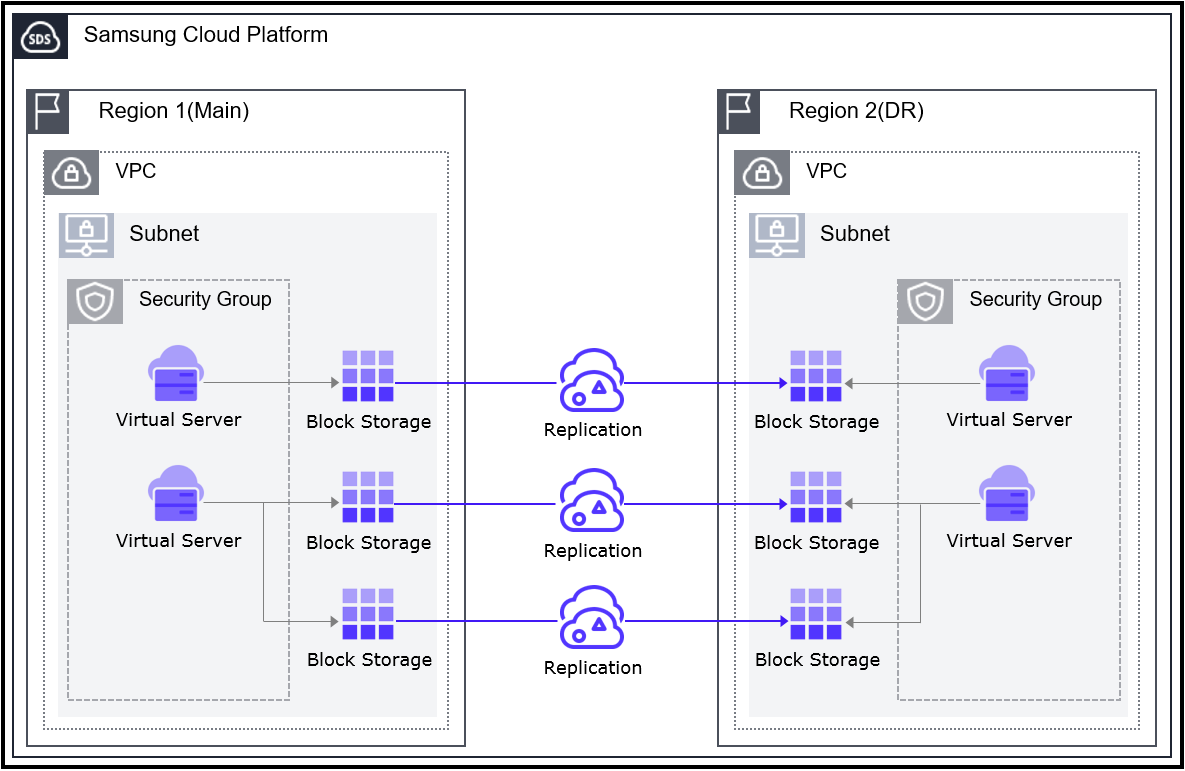
Provided features
For the main features, please refer to the Product Catalog Details page of the partner solution sold on the Samsung Cloud Platform Marketplace.
Note
For detailed information on using the Marketplace, see Marketplace.
Preliminary Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare accordingly.
| Service Category | service | Detailed description |
|---|---|---|
| Networking | VPC | A service that provides an isolated virtual network in a cloud environment |
| Networking | Security Group | Virtual firewall that controls server traffic |
| Compute | Virtual Server | Virtual server optimized for cloud computing |
Table. Virtual Server DR Preliminary Service
7.2 - Release Note
Virtual Server DR
2025.07.01
NEW
Official launch of Virtual Server DR service- We have officially launched the Virtual Server DR service.
- When the system is interrupted by various disaster scenarios and risk factors, it can be restored to normal operation in a short time.
8 - Block Storage
8.1 - Overview
Service Overview
Block Storage is a high-performance storage that stores data in block units arranged in a fixed size and order.
Suitable for large-scale, high-performance requirements such as databases and mail servers, and users can directly allocate volumes to the server.
Features
- Large Volume Provisioning: OS configuration volumes are created with at least the minimum size per image and can be expanded up to 12TB, and data storage volumes outside the OS can be created and expanded from a minimum of 8GB to a maximum of 12TB. * Capacity expansion is carried out reliably while online.
- Full SSD-based high performance: Provides high durability and availability based on redundant Controllers and Disk Array RAID. * Full SSD disks are provided by default, making them suitable for high‑speed data processing tasks such as database workloads.
- Snapshot Backup: Image snapshot functionality allows recovery of changed and deleted data. * The user selects the snapshot created at the desired recovery point from the list and performs the recovery.
Service architecture diagram
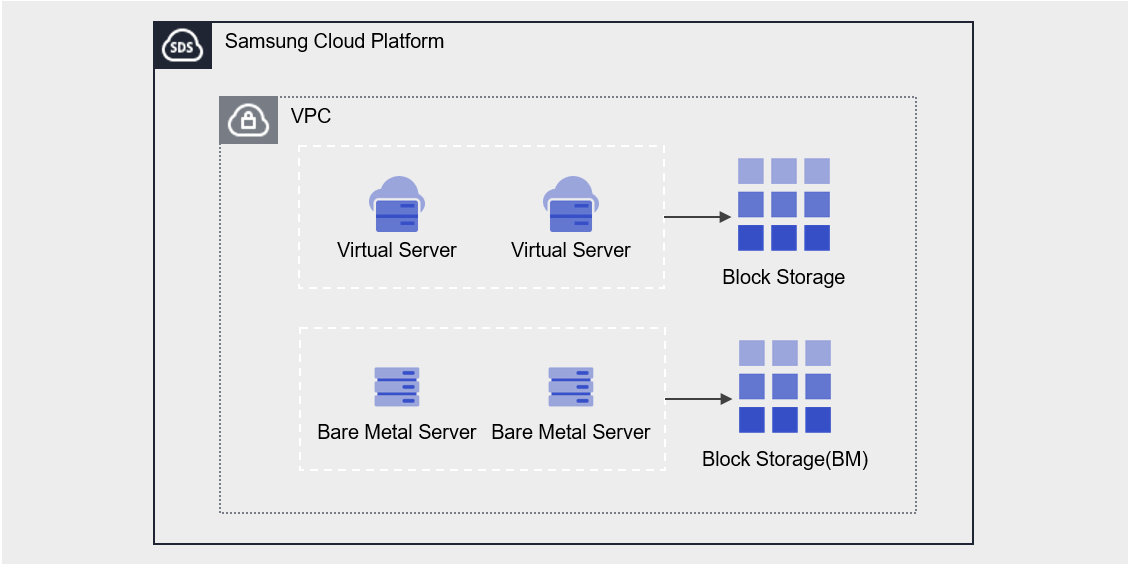
Provided features
Block Storage provides the following features.
- Volume Name: Users can set or edit the name for each volume.
- Capacity: Volumes can be created with capacities ranging from a minimum of 8 GB up to a maximum of 12 TB, and can be expanded while in use. * The default OS volume can be created with a size no less than the minimum required for each image.
- Connection Server: You can select a Virtual Server to connect or disconnect.
- Multi-Server Connection (Multi Attach): Connects to two or more servers, with no limit on the number of servers per volume, and a Virtual Server can connect up to 26 volumes
- Encryption: All volumes of Block Storage have AES-256 algorithm encryption applied by default, and when a volume is of HDD/SSD_KMS disk type, additional in‑transit encryption is provided for the Block Storage segment connected to the instance.
- snapshot: Through the image snapshot feature, recovery of modified and deleted data is possible. * The user selects a snapshot created at the desired recovery point from the list and restores it.
- Volume Transfer: Using the volume transfer feature, you can transfer a volume to another Account.
- Monitoring: IOPS, Latency, Throughput, etc. monitoring information can be viewed through the ServiceWatch service.
Components
You can create a volume by entering the capacity and selecting the disk type according to the user’s service scale and performance requirements. When using the snapshot feature, you can restore data to the desired point in time.
Volume
A volume (Volume) is the basic creation unit of the Block Storage service and is used as data storage space. The user selects a name, size, and disk type to create a volume, then attaches it to a Virtual Server for use.
The volume name creation rules are as follows.
Reference
Use English letters, numbers, spaces, and special characters(
-, _) within 255 characters.Snapshot
A snapshot (Snapshot) is an image backup of a volume at a specific point in time. The user can view the snapshot name and creation time in the snapshot list, select the snapshot they wish to restore, and recover data that was modified or deleted using that snapshot.
The following are considerations when using snapshots.
Reference
- The snapshot creation time is based on Asia/Seoul (GMT +09:00).
- Select the snapshot recovery button to restore the Block Storage volume to the latest snapshot.
- If you select a specific snapshot from the snapshot list, you can recover by creating a new volume based on that snapshot.
- Snapshots are billed based on the size of the original Block Storage, so please delete any unnecessary snapshots.
Preceding Service
This is a list of services that must be pre-configured before creating the service. Refer to the guide provided for each service for detailed information and prepare in advance.
| Service Category | service | Detailed description |
|---|---|---|
| Compute | Virtual Server | Virtual server optimized for cloud computing |
Table. Block Storage pre-service
8.1.1 - Monitoring Metrics
Cloud Monitoring service termination notice
According to Samsung Cloud Platform’s policy, the Cloud Monitoring service is scheduled to be discontinued in September 2026.
Accordingly, after the September 2026 release, resource monitoring of the Samsung Cloud Platform via Cloud Monitoring will no longer be possible.
With the new alternative service, you can continuously perform resource monitoring by leveraging ServiceWatch released in October 2025.
ServiceWatch provides more modern and powerful features, replacing Cloud Monitoring to deliver a seamless monitoring environment.
Block Storage planned to be integrated with ServiceWatch from the July 2026 release onward is.
Detailed information about ServiceWatch is available in the ServiceWatch Overview.
Block Storage Monitoring Metrics
The table below shows the monitoring metrics for Block Storage that can be viewed in Cloud Monitoring. For detailed usage of Cloud Monitoring, refer to the Cloud Monitoring guide.
| Performance Item Name | Explanation | unit |
|---|---|---|
| Volume Total | Total byte count | bytes |
| IOPS [Read] | iops(read) | iops |
| IOPS [Write] | iops(write) | iops |
| Latency Time [Read] | Read latency | usec |
| Latency Time [write] | Latency (write) | usec |
| Throughput [Read] | Throughput (read) | bytes/s |
| Throughput [Write] | Throughput (write) | bytes/s |
Table. Block Storage Monitoring Metrics
8.1.2 - ServiceWatch metric
Block Storage VM sends metrics to ServiceWatch. The metrics provided by basic monitoring are data collected at 1‑minute intervals.
Reference
For how to view metrics in ServiceWatch, refer to the ServiceWatch guide.
basic metrics
The following are the basic metrics for the Block Storage VM namespace.
The indicators whose names are displayed in bold below are the key indicators selected from the basic metrics provided by Block Storage VM. The key metrics are used to configure service dashboards that are automatically built for each service in ServiceWatch.
Each metric offers guidance in the user guide on which statistical value is meaningful when viewing it, and the service dashboard allows you to view key metrics using their primary statistical values.
| Indicator name | Detailed description | unit | meaningful statistics |
|---|---|---|---|
| Volume Total | Block Storage size | Gigabytes | - |
| IOPS [Read] | Block Storage volume IOPS (read) | - |
|
| IOPS [Write] | Block Storage volume IOPS (write) | - |
|
| Latency Time [Read] | Block Storage volume latency (read) | Milliseconds |
|
| Latency Time [write] | Block Storage volume latency (write) | Millisecond |
|
| Throughput [Read] | Block Storage volume throughput (read) | Megabytes/Second |
|
| Throughput [Write] | Block Storage volume throughput (write) | Megabytes/Second |
|
Table. Block Storage VM basic metrics
8.2 - How-to guides
Users can create the service by entering the required Block Storage information and selecting detailed options through the Samsung Cloud Platform Console.
Create Block Storage
You can create and use the Block Storage service from the Samsung Cloud Platform Console. To create Block Storage, follow these steps.
All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
Click the Block Storage menu. 2. Go to the Block Storage List page.
Block Storage on the page, click the Create Service button. 3. Go to the Create Block Storage page.
On the Block Storage Creation page, enter the information required to create the service and select detailed options.
구분 Required statusDetailed description Volume name Required Volume name - English letters, numbers, spaces, and special characters (
-,_) up to 255 characters
Disk type Required Select Disk Type - SSD_Provisioned: SSD volume with configurable IOPS and throughput
- SSD/HDD: Standard SSD/HDD volume
- SSD/HDD_KMS: Additional encrypted volume
- SSD/HDD_MultiAttach: Volume that can be attached to more than one server
- Cannot be modified after service creation
- When creating the service via snapshot restore volume creation, it is set identical to the original and cannot be modified
capacity Selection Capacity setting - Can be created within 8~12,228 GB
- Enter the number of units provided in 8 GB increments
- When creating a service via snapshot recovery volume creation, input a capacity that is equal to or larger than the original
Max IOPS Required Enter the maximum IOPS value between 5,000 and 20,000 - disk type can be set only when it is SSD_Provisioned
Max Throughput Required Enter the maximum Throughput value between 250 and 1,000 - disk type can be set only when it is SSD_Provisioned
Availability Zone Required Select the Availability Zone to create resources within the region Snapshot Selection Select the snapshot to use when creating a volume from a snapshot - Use item after checking, snapshot selection is possible
- When creating a service via snapshot recovery volume creation, provide the recovery snapshot name
- If not selected, an empty volume is created
Table. Block Storage service information input items- English letters, numbers, spaces, and special characters (
Summary Verify the detailed information and estimated charges generated in the panel, then click the Create button.
- When creation is complete, verify the created resource on the Block Storage List page.
Reference
- You can only attach a volume to a Virtual Server in the same Availability Zone.
- The performance metrics (IOPS, Throughput) of the configured storage are based on maximum values and do not guarantee consistent values.
- All volumes of Block Storage are encrypted by default using the AES-256 algorithm.
- Virtual Servers based on Windows cannot use MultiAttach disks. * Use a separate replication method or solution.
- If the volume is of the HDD/SSD_KMS disk type, additional in‑transit encryption is provided for the instance and the Block Storage segment attached to the instance.
Caution
HDD/SSD_KMS Using this disk type may result in approximately 60% performance degradation.
Check Block Storage detailed information
You can view and edit the full resource list and detailed information of the Block Storage service. Block Storage Details page consists of Detailed Information, Snapshot List, Tags, Operation History tabs.
To view detailed information about the Block Storage service, follow these steps.
- All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Navigate to the Block Storage List page.
- Block Storage List page, click the resource to view detailed information. 3. Block Storage Details Navigate to the page.
- Block Storage Details page displays status information and additional feature information, and consists of Details, Snapshot List, Tags, Activity Log tabs.
Category Detailed description Volume status Volume status - Creating: Creating
- Downloading: Creating (applying OS image)
- Available: Created, server connection available
- Reserved: Server connection pending
- Attaching: Connecting to server
- Detaching: Detaching from server
- In Use: Server connection established
- Deleting: Terminating service
- Awaiting Transfer: Waiting for volume transfer
- Extending: Extending capacity
- Error Extending: Abnormal state during capacity extension
- Backing Up: Backing up volume
- Restoring Backup: Restoring volume backup
- Error Backing Up: Abnormal state during volume backup
- Error Restoring: Error restoring volume backup
- Error Deleting: Error deleting
- Error Managing: Abnormal state
- Error: Abnormal state
- Maintenance: Temporary maintenance
- Reverting: Reverting snapshot
Volume Transfer Move the volume to another Account - For details on volume migration, see 볼륨 이전
Create snapshot Immediately create a snapshot at the time of creation - For detailed information on snapshot creation, see 스냅샷 생성하기
Snapshot recovery Recover the volume using the latest snapshot in Available state - For detailed information on snapshot recovery, see 스냅샷 복구하기
Delete Block Storage Button to delete the service Table. Status information and additional features
- Block Storage Details page displays status information and additional feature information, and consists of Details, Snapshot List, Tags, Activity Log tabs.
Detailed Information
Block Storage List page lets you view detailed information of the selected resource and modify it if needed.
| Category | Detailed description |
|---|---|
| service | service group |
| Resource Type | Resource Type |
| SRN | Unique resource ID in Samsung Cloud Platform
|
| Resource Name | Resource name
|
| Resource ID | Service’s unique resource ID |
| Constructor | User who created the service |
| Creation date and time | Service creation date and time |
| Modifier | User who modified the service |
| Modification date and time | Service modification date and time |
| Volume name | Volume name
|
| Volume ID | Volume unique ID |
| Availability Zone | Availability Zone information |
| Disk type | Disk type |
| type | Classification by volume creation method and usage |
| capacity | Volume capacity
|
| Max IOPS | Required |
| Max Throughput | Required |
| Connection server | Connected Virtual Server
|
Table. Block Storage detailed information items
Snapshot List
Block Storage List page allows you to view the snapshot of the selected resource.
| Category | Detailed description |
|---|---|
| Snapshot name | Snapshot name |
| Explanation | Snapshot description |
| Volume capacity | Capacity of the original Block Storage volume for the snapshot target
|
| Creation date and time | Snapshot creation time |
| Status | Snapshot status
|
| Additional features > More | Snapshot management button
|
| Delete | Select the snapshots to delete from the snapshot list and delete them all at once. |
Table. Snapshot list tab detailed information items
Caution
- Snapshots can affect volume capacity management. * Delete unnecessary snapshots after use.
- Snapshot recovery can be performed while the server is not connected.
Reference
- The snapshot creation time is based on Asia/Seoul (GMT +09:00).
- When you click the snapshot recovery button, the volume is restored to the latest snapshot in the Available state.
- When you select to create a recovery volume on the snapshot list page, a new volume based on the snapshot is created without modifying the existing volume.
Tag
On the Block Storage list page, you can view the tag information of the selected resource and add, modify, or delete it.
| Category | Detailed description |
|---|---|
| Tag list | Tag list
|
Table. Block Storage tag tab item
Operation History
Block Storage List page allows you to view the operation history of the selected resource.
| Category | Detailed description |
|---|---|
| Task History List | Resource Change History
|
Table. Work History tab detailed information items
Block Storage Resource Management
If you need to modify the settings of a created Block Storage or add or remove a connected server, you can perform the operation on the Block Storage Details page.
Edit volume name
You can edit the volume name. To modify the volume name, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Go to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the resource whose volume name you want to edit. 3. Go to the Block Storage Details page.
- Click the Edit button of the Volume Name. 4. Edit Volume Name The popup window opens.
- Enter the volume name and click the Confirm button.
Reference
Use English letters, numbers, spaces, and special characters (
-, _) within 255 characters.Expand Capacity
You can expand the volume capacity. To increase capacity, follow the steps below.
- All Services > Compute > Virtual Server menu, click it. 1. Go to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the resource to increase capacity. 3. Block Storage Details page.
- Click the Edit button of Capacity. 4. Capacity Modification popup window opens.
- Enter the capacity and click the Confirm button.
Caution
용량 축소는 제공하지 않습니다.
용량 증설 후에는 증설 전의 스냅샷으로 복구되지 않습니다.
용량 증설 이전에 생성한 스냅샷으로는 신규 볼륨 생성 방식의 복구만 가능합니다.
Reference
8~12,228GB 이내에서 기존 용량보다 큰 용량으로 증설 가능합니다.
8GB 단위로 제공되는 Unit 개수를 입력하세요.
연결 서버 수정하기 {#update-1} 서버를 연결하거나 연결 해제할 수 있습니다. 연결 서버를 수정 하려면 다음 절차를 따르세요. 모든 서비스 > Compute > Virtual Server 메뉴를 클릭하세요. Virtual Server의 Service Home 페이지로 이동합니다. Block Storage 메뉴를 클릭하세요. Block Storage 목록 페이지로 이동합니다. Block Storage 목록 페이지에서 연결 서버를 수정할 자원을 클릭하세요. 3. Block Storage Details Navigate to the page. 4. When adding a Virtual Server connection, click the Add button in the Connection Server item. 4. Add Connection Server The popup window opens. 5. After selecting the Virtual Server you want to connect to, click the Confirm button. 6. If you disconnect the Virtual Server, click the Disconnect button in the Connection Server item. * Be sure to perform the disconnect operation (Umount, Disk Offline) on the server before proceeding with the disconnection.
Caution
Log in to the server, be sure to perform the disconnect operations (Umount, Disk Offline), and then detach the connected server. Releasing without OS actions may cause a status error (Hang) on the connected server. For detailed information about server disconnection, see 서버 연결 해제하기.
Reference
- You can connect a Virtual Server created in the same location as the Block Storage.
- Virtual servers that use a Partition with a Server Group policy cannot be connected.
- For HDD/SSD_MultiAttach disk types, they can be attached to two or more Virtual Servers, and there is no limit on the number of connections.
- Virtual Servers based on Windows cannot use MultiAttach disks and must use a separate replication method or solution.
- Virtual Server can connect up to 26 volumes, including the OS default.
- The OS default volume cannot be modified on the connected server, nor can its service be deleted.
- When adding a connected server, it can be used after performing the connection tasks (Mount, Disk Online) on the server. * For detailed information about server connections, refer to 서버 연결하기.
Delete Block Storage
You can reduce operating costs by deleting unused Block Storage. Note that deleting a service may cause the running service to stop immediately, so you should proceed with the deletion only after fully considering the impact of service interruption.
Caution
- Be careful, as the data cannot be recovered after deletion.
- In the following case, the Block Storage volume cannot be deleted.
- Connecting to server
- OS default volume
- Connect to the Virtual Server’s custom image
- When the volume status is not Available, Error, Error Extending, Error Restoring, or Error Managing.
- When selecting and deleting two or more volumes, only the deletable volumes will be deleted.
To delete Block Storage, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, select the resource to delete, and click the Delete button.
- After navigating to the detailed page of the resource to be deleted, you can click the Block Storage Delete button to delete it individually.
- When the deletion notification pop-up appears, type Delete and click the Confirm button.
- After the deletion is complete, verify on the Block Storage List page that the resource has been removed.
8.2.1 - Connect to Server
When using a volume on the server, a connect or disconnect operation is required.
On the Block Storage Details page, add a connected server, then access the server to perform connection operations (Mount, Disk Online). After use, perform disconnection operations (Umount, Disk Offline) and then remove the connected server.
Connect to Server (Mount, Disk Online)
To use the volume added to the connected server, you must log into the server and perform the connection tasks (Mount, Disk Online). Follow the steps below.
Linux operating system
Example configuration for server connection
- Server OS: LINUX
- Mount location: /data
- Volume size: 24 GB
- File system: ext3, ext4, xfs etc
- Additional allocated disk: /dev/vdb
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Block Storage menu. Go to the Block Storage List page.
- On the Block Storage List page, click the resource to be used on the connected server. Navigate to the Block Storage Details page.
- After verifying the server in the Connection Server item, connect.
- Refer to the steps below to mount the volume (Mount).
Switch to root privileges
$ sudo -iCheck Disk
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 diskCreate partition
# fdisk /dev/vdb Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): p Partition number (1-4, default 1): 1 First sector (2048-50331646, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-50331646, default 50331646): Created a new partition 1 of type 'Linux' and of size 24 GiB. Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.Partition format setting (example: ext4)
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 disk └─vdb1 252:17 0 24G 0 part # mkfs.ext4 /dev/vdb1 mke2fs 1.46.5 (30-Dec-2021) ... Writing superblocks and filesystem accounting information: doneVolume Mount
# mkdir /data # mount /dev/vdb1 /data # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 24G 0 disk ├─vda1 252:1 0 23.9G 0 part [SWAP] └─vda14 252:14 0 4M 0 part / └─vda15 252:15 0 106M 0 part /boot/efi vdb 252:16 0 24G 0 disk └─vdb1 252:17 0 24G 0 part /data # vi /etc/fstab (추가) /dev/vdb1 /data ext4 defaults 0 0
| Item | Explanation |
|---|---|
| cat /etc/fstab | File system information file
|
| df -h | Check the total disk usage of mounted disks |
| fdisk -l | Check partition information
|
Table. Mount command reference
| command | Explanation |
|---|---|
| m | Check the usage of the fdisk command |
| n | Create a new partition |
| p | Verify the updated partition information |
| t | Change the system ID of the partition |
| w | Save partition information and exit fdisk. |
Table. Partition creation command (fdisk) reference
Windows operating system
- Click the All Services > Compute > Virtual Server menu. Navigate to the Virtual Server Service Home page.
- Click the Block Storage menu. You will be taken to the Block Storage List page.
- On the Block Storage List page, click the resource to be used on the connected server. You will be taken to the Block Storage Details page.
- Connection Server item, verify the server and then connect.
- Refer to the steps below to connect the volume (Disk Online).
After right-clicking the Windows Start icon, run
Computer Management.In the Computer Management tree structure, select
Storage > Disk ManagementCheck Disk
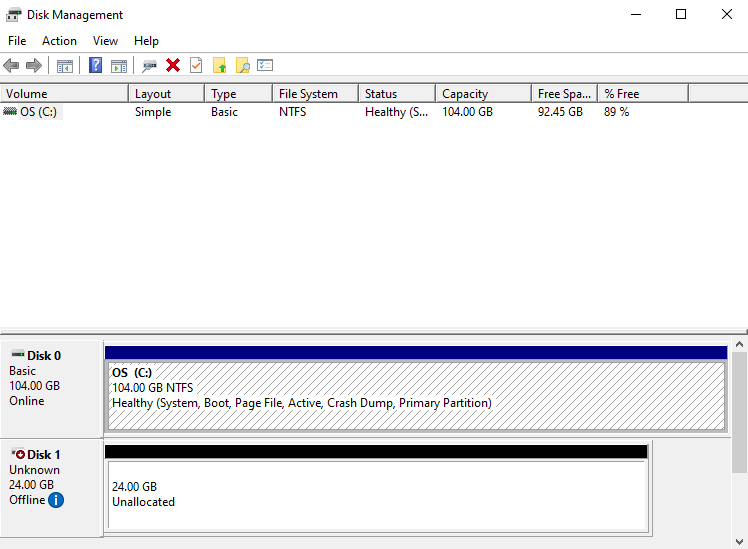
Disk Online
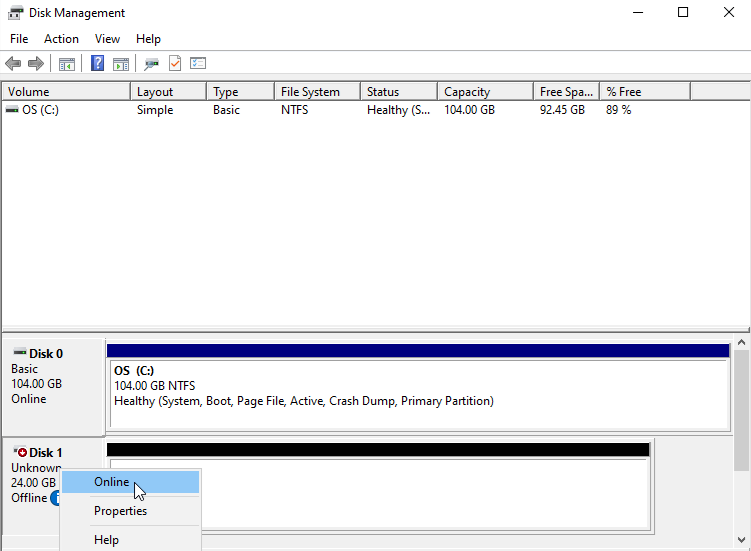
Disk initialization
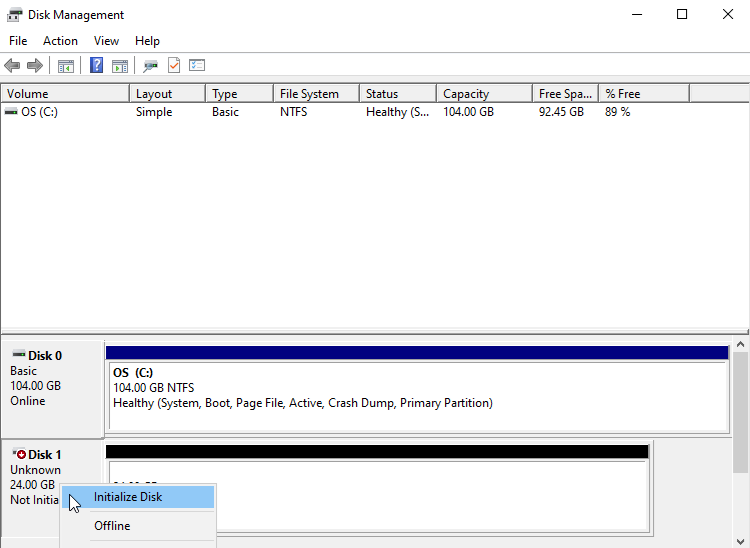
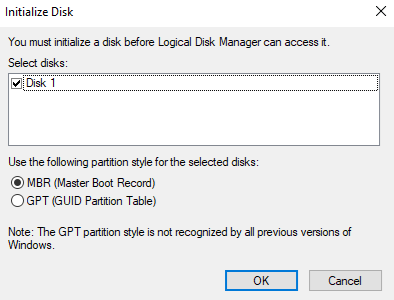
Partition format
Check volume
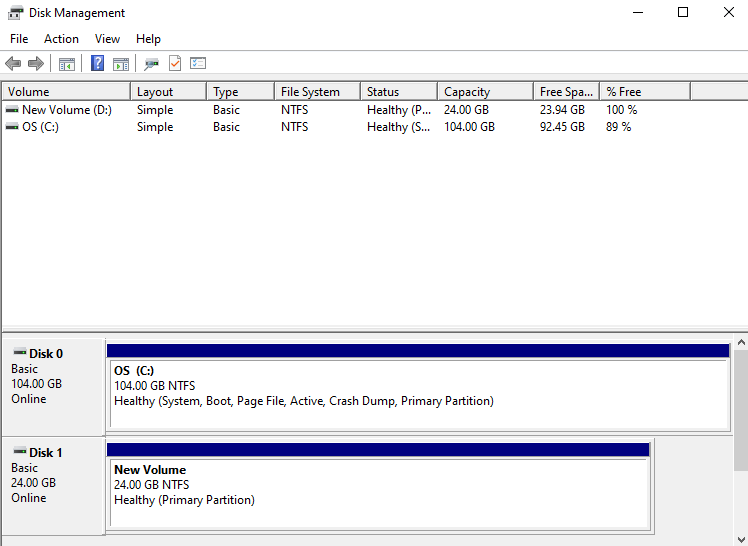
Disconnect server (Umount, Disk Offline)
Access the server, perform the disconnect operations (Umount, Disk Offline), and then disconnect the server from the Console.
Follow the next procedure.
Caution
- If you disconnect the server from the console without performing the disconnect operations (Umount, Disk Offlline) on the server, a server state error (Hang) may occur.
- Be sure to perform the OS tasks first.
- For the OS default volume, you cannot modify the connected server or cancel the service.
Linux operating system
- Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
- Click the Block Storage menu. Navigate to the Block Storage List page.
- On the Block Storage List page, click the resource to detach the attached server. You will be taken to the Block Storage Details page.
- After verifying the server in the Connection Server item, connect.
- Refer to the steps below to unmount the volume(Umount).
- Volume Umount
# umount /dev/vdb1 /data
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 24G 0 disk
├─vda1 252:1 0 23.9G 0 part [SWAP]
└─vda14 252:14 0 4M 0 part /
└─vda15 252:15 0 106M 0 part /boot/efi
vdb 252:16 0 24G 0 disk
└─vdb1 252:17 0 24G 0 part
# vi /etc/fstab
(삭제) /dev/vdb1 /data ext4 defaults 0 0
Windows operating system
Click the All Services > Compute > Virtual Server menu. Navigate to the Service Home page of Virtual Server.
Click the Block Storage menu. Go to the Block Storage List page.
Block Storage List page, click the resource to detach the connected server. Navigate to the Block Storage Details page.
In the Connection Server field, verify the server before connecting.
Unmount the mounted file system.
Please follow the procedure below to detach the volume (Disk Offline).
Right-click the Windows Start icon, then run
Computer Management.In the Computer Management tree structure, select
Storage > Disk ManagementRight-click the disk to be removed, then run
Offline
Check disk status
8.2.2 - Using Snapshots
You can create a snapshot of the created Block Storage, delete it, or recover using the snapshot. You can perform actions on the Block Storage Details page and the Snapshot List page.
Create Snapshot
You can create a snapshot of the current point in time. To create a snapshot, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- Block Storage Click the menu. 2. Block Storage List navigate to the page.
- On the Block Storage List page, click the resource to create a snapshot. 3. Block Storage Details Navigate to the page.
- Click the Create Snapshot button. 4. Create Snapshot The popup window opens.
- Enter the Snapshot Name and Description, then click the Create button.
- When the popup notifying snapshot creation opens, click the Confirm button. 6. Creates a snapshot of the current point in time.
- Click the Snapshot List button. 7. Navigate to the Block Storage Snapshot List page.
- Check the generated snapshot.
Caution
Snapshots are billed based on the size of the original Block Storage, so please delete any unnecessary snapshots.
Reference
The snapshot creation time is based on Asia/Seoul (GMT +09:00).
Edit Snapshot
You can modify snapshot information. To modify the snapshot name or description, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the resource to edit the snapshot information. 3. Block Storage Details Navigate to the page.
- Click the Snapshot List button. 4. Navigate to the Block Storage Snapshot List page.
- After confirming the snapshot to edit, click the More button.
- Edit Click the button. 6. Snapshot Edit The popup window opens.
- Enter the Snapshot name or Description, then click the Confirm button.
Restore Snapshot
You can restore a Block Storage volume to the latest snapshot in the Available state. To restore a snapshot, follow these steps.
- All Services > Compute > Virtual Server menu, please click. 1. Navigate to the Service Home page of the Virtual Server.
- Block Storage Click the menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the resource you want to restore from a snapshot. 3. Navigate to the Block Storage Details page.
- If there is a server added in the Connection Server item, after connecting to the server, perform the disconnect operations (Umount, Disk Offline).
- For detailed information about disconnecting the server, please refer to 서버 연결 해제하기.
- On the Block Storage Details page, click the Disconnect button in the Connected Server item to remove the server. 5. The connection server will be removed.
- For detailed information on disconnecting the server, see 연결 서버 수정하기.
- Click the Snapshot List button. 6. Block Storage Snapshot List Navigate to the page.
- Check the latest snapshot in the Available state. 7. The volume will be restored from this snapshot.
- Click the Snapshot Recovery button. 8. Snapshot Recovery popup window opens.
- After checking the snapshot name and creation timestamp, click the Confirm button.
- When recovery starts, it becomes Reverting, and when completed, it becomes Available.
- Click the Details page button. 10. Go to the Block Storage Detail Page.
- Click the Add button of the Connection Server. 11. Reconnect the Virtual Server.
- For detailed information on adding a connection server, see 연결 서버 수정하기.
- After connecting to the added server, perform the connection tasks (Mount, Disk Online) according to the operating system.
- For detailed information about server connections, refer to 서버 연결하기.
Caution
- Snapshot recovery can be performed while the server is not connected.
- If you need to restore from a snapshot that is not the latest, you can recover by creating a recovery volume.
- Recovery is not possible in the following situations.
- When a Block Storage volume is not in the Available state
- If a server is attached to the Block Storage volume
- If there are no recoverable snapshots.
- If the latest snapshot changes while creating a recovery.
- If the latest snapshot is not in the Available state.
- When the snapshot’s volume size differs from the Block Storage volume size (in case the volume was expanded)
Create a snapshot recovery volume
You can create a volume using a snapshot. To create a snapshot recovery volume, follow these steps.
All Services > Compute > Virtual Server Click the menu. 1. Navigate to the Service Home page of the Virtual Server.
Click the Block Storage menu. 2. Go to the Block Storage List page.
On the Block Storage List page, click the resource to create a snapshot recovery volume. 3. Navigate to the Block Storage Details page.
Click the Snapshot List button. 4. Navigate to the Block Storage Snapshot List page.
After verifying the snapshot name, description and creation date and time, click the More button of the snapshot you wish to restore.
Click Create recovery volume. 6. Create snapshot recovery volume A popup window opens.
Click the Create button. 7. Go to the Create Block Storage page.
On the Block Storage Creation page, enter the information required to create the service and select detailed options.
- Enter the volume name and capacity. * You can input a capacity that is greater than or equal to the original volume.
- The disk type is set to match the original and cannot be modified.
Category Required상세 설명 볼륨명 필수 볼륨 이름 - 영문, 숫자, 공백과 특수문자(
-,_) 사용하여 255자 입력
디스크 유형 필수 디스크 유형 선택 - SSD_Provisioned: IOPS, Throughput 설정이 가능한 SSD 볼륨
- SSD/HDD: 일반 SSD/HDD 볼륨
- SSD/HDD_KMS: 추가 암호화 볼륨
- SSD/HDD_MultiAttach: 2개 이상의 서버 연결이 가능한 볼륨
- 서비스 생성 후 수정 불가
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본과 동일하게 설정되며 수정이 불가함
용량 선택 용량 설정 - 8~12,228GB 이내로 생성 가능
- 8GB 단위로 제공되는 Unit 개수 입력
- 스냅샷 복구 볼륨 생성을 통해 서비스 생성 시 원본보다 크거나 같은 용량으로 입력
Max IOPS 필수 Enter the maximum IOPS value between 5,000 and 20,000 - Disk type can be set only when it is SSD_Provisioned
Max Throughput Required Enter the maximum Throughput value between 250 and 1,000 - Can be set only when Disk type is SSD_Provisioned
Recovery snapshot name Selection Name of the recovery snapshot used when creating the volume - Provide the recovery snapshot name when creating a service via snapshot recovery volume creation
Table. Block Storage service information entry items - 영문, 숫자, 공백과 특수문자(
Summary Verify the detailed information and estimated charges generated in the panel, then click the Create button.
- When creation is complete, check the created resources on the Block Storage List page.
Delete Snapshot
You can select a snapshot and delete it. To delete a snapshot, follow these steps.
- All Services > Compute > Virtual Server Click the menu. 1. Go to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the resource to delete the snapshot. 3. Block Storage Details Navigate to the page.
- Click the Snapshot List button. 4. Navigate to the Block Storage Snapshot List page.
- After verifying the snapshot name, description and creation date and time, click the More button of the snapshot you wish to delete.
- Click the Delete button. 6. Snapshot List page removes snapshots.
8.2.3 - Transfer volume
You can transfer the volume to another account, and when you do so, the volume is removed from its original location. You can perform volume migration on the Block Storage List or Block Storage Details page.
Previous volume
You can transfer the volume to another Account. To migrate the volume, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of Virtual Server.
- Click the Block Storage menu. 2. Block Storage List Navigate to the page.
- On the Block Storage List page, after selecting the resource to migrate, click the More > Migrate Volume button at the top left of the list.
- Or click the Volume Transfer button at the top of the Block Storage Details page of the resource to be transferred.
- When the popup notifying volume transfer opens, verify the volume name you want to transfer, then click the Confirm button.
- When the previous completion popup opens, click the Confirm button. 5. Volume Transfer ID and Approval Key information will be downloaded as a text file.
- The volume changes to Awaiting Transfer status.
Caution
- You can attach the volume only to a Virtual Server in the same Availability Zone as the migrated volume.
- Volume migration is possible only when the volume is in Available state. * If it is In Use, disconnect all connected servers.
Cancel previous volume
You can cancel after creating a volume transfer. To cancel the volume transfer, follow these steps.
- Click the All Services > Compute > Virtual Server menu. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Navigate to the Block Storage List page.
- On the Block Storage List page, click the resource to cancel the volume migration. 3. Go to the Block Storage Details page.
- If the volume is in Awaiting Transfer status, it can be canceled.
- Click the Cancel previous volume button. 4. Cancel previous volume A popup window opens.
- After confirming the volume name for which you want to cancel the volume transfer, click the Confirm button.
- The volume changes to Available state.
Receive previous volume
You can receive a volume transfer from another Account. To receive a volume transfer, follow the steps below.
- All Services > Compute > Virtual Server menu, click it. 1. Navigate to the Service Home page of the Virtual Server.
- Click the Block Storage menu. 2. Go to the Block Storage List page.
- On the Block Storage List page, click the More > Receive Volume Transfer button at the top left of the list. 3. Receive previous volume A popup window opens.
- Volume Migration Enter the provided Volume Migration ID and Approval Key.
- A volume is created on the Block Storage List page.
information
- It takes time for the changes to take effect.
- In the account that initiated the volume transfer, the transferred volume is removed.
8.3 - API Reference
API Reference
8.4 - CLI Reference
CLI Reference
8.5 - Release Note
Block Storage
2026.07.16
FEATURE
SeviceWatch service integration and other feature additions- ServiceWatch service has been integrated.
- You can view monitoring information such as IOPS, latency, and throughput via the ServiceWatch service.
- You can select an Availability Zone when creating a resource.
- A text input feature has been added when deleting resources.
- To prevent accidentally deleting resources, you must verify the deletion information and enter Delete when deleting to proceed with the deletion operation.
2026.03.19
FEATURE
SSD_Provisioned disk type added- An SSD volume with configurable IOPS and Throughput has been added.
- When creating Block Storage, you can select the SSD_Provisioned disk type.
- You can set the IOPS and Throughput range.
- IOPS: 5,000 ~ 20,000
- Throughput: 250 ~ 1,000
- During the preview period, there is no additional charge; charges will be applied in the future.
2025.07.01
FEATURE
Snapshot fee policy change and monitoring integration- Snapshots are billed based on the size of the original Block Storage.
- Integrated with Cloud Monitoring.
- You can view IOPS, latency, and throughput information in Cloud Monitoring.
2025.02.27
FEATURE
Add Block Storage disk type- Block Storage feature change
- HDD disk types have been added, allowing you to select the added type (HDD, HDD_MultiAttach, HDD_KMS) according to the purpose.
- Samsung Cloud Platform Common Feature Change
- Account, IAM, Service Home, tags, and other common CX changes have been reflected.
2024.10.01
NEW
Block Storage Service Official Version Release- Added SSD_KMS disk type.
- When SSD_KMS is selected, encryption using KMS (Key Management Service) encryption keys is added.
- We have launched a high-performance storage service suitable for handling large-scale data and database workloads.
2024.07.02
NEW
Beta version release- We have launched a high-performance storage service suitable for handling large-scale data and database workloads.