Service Overview
Data Flow is a data processing flow tool that visually creates processing flows for extracting large volumes of data from various data sources and for transforming/transferring stream or batch data, and provides the open-source Apache NiFi. Data Flow can be used independently in the Kubernetes Engine cluster environment of Samsung Cloud Platform, or together with other application software.
Provided Features
Data Flow provides the following features.
- Convenient Installation and Management: Data Flow can be easily installed in a standard Kubernetes cluster environment via the web-based Samsung Cloud Platform Console. * Automatically configure the architecture required for scalable clustering based on the open-source Apache NiFi, and automatically install ZooKeeper, Registry, and management modules. * Through Data Flow, you can configure and deploy the configuration files, NiFi templates, etc., needed for service connections.
- Easy Data Flow Management: You can easily create processing flows for stream/batch data in a GUI tailored to the user environment, and with GUI-based data processing flow creation, you can efficiently extract, transfer, and process data between systems.
- NiFi Template Gallery: You can share/distribute reference NiFi templates. * Data Flow provides work files for data processing flows commonly used in the field as a gallery, and users can share the data processing flow tasks they have created.
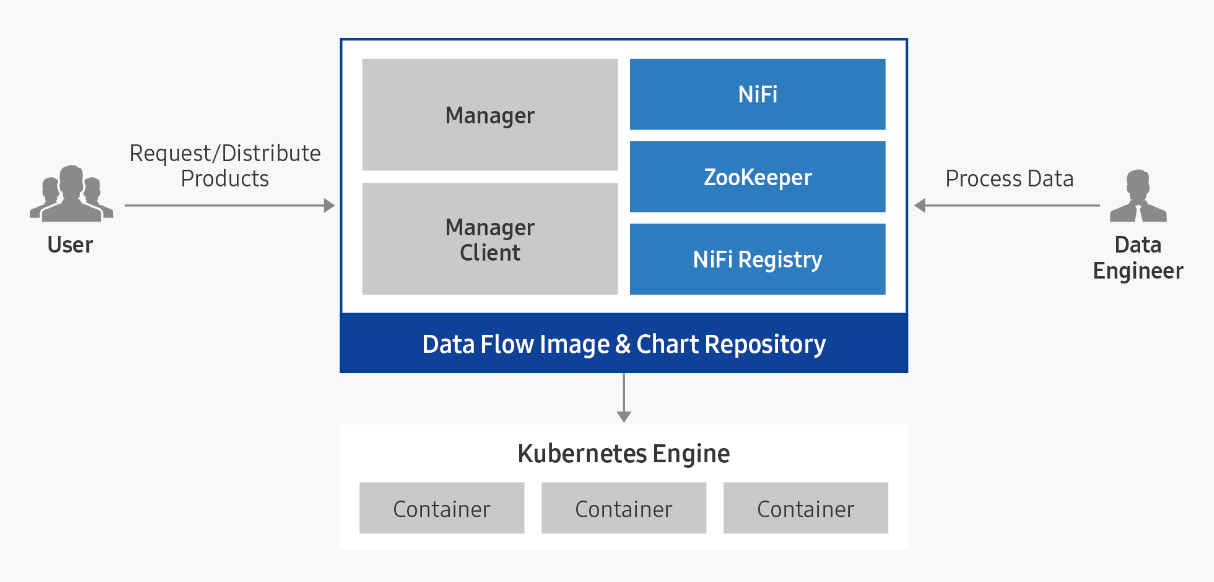
Component
Data Flow consists of Manager and Service modules, and is provided packaged with Apache NiFi.
Data Flow Manager
Data Flow Manager provides various managing features to enable more efficient use of NiFi.
- Through Data Flow Manager, you can upload the Nar File created by the customer for use in the Processor, and upload configuration files to share them.
- Frequently used NiFi templates are packaged as assets and offered in the Gallery, ready for use with a single click.
- Provides real-time monitoring of multiple services configured for the native NiFi service and resource status monitoring.
- You can easily provision configuration information for NiFi components within the cluster.
Data Flow Service
- We provide a data flow management service based on Apache NiFi.
- Automatically configures the architecture required for scalable clustering based on Apache NiFi, and automatically installs the Nifi, ZooKeeper, and Nifi Registry modules.
- When providing Nifi, you can set the Description, required resource size, connection ID/PW, and Host Alias.
- After creating the service, you can modify the Description, required resource size, connection password, Host Alias, and other settings, and apply the changes to the service.
Server spec type
When creating a Data Flow service, check the following.
- Recommended service installation specifications: CPU 21 core, Memory 57 GB, storage 100 GB or more
Provision status by region
Data Flow is available in the environments below.
| Region | Provision status |
|---|---|
| Korea West (kr-west1) | Provide |
| Korea East (kr-east1) | Provide |
| South Korea South 1 (kr-south1) | Not provided |
| South Korea South 2 (kr-south2) | Not provided |
| South Korea South 3 (kr-south3) | Not provided |
Preliminary Service
This is a list of services that must be pre-configured before creating the service. Please refer to the guide provided for each service and prepare in advance.
| Service Category | Service | Details |
|---|---|---|
| Storage | File Storage | Storage where multiple client servers share files via a network connection |
| Container | Kubernetes Engine | Kubernetes container orchestration service |