Computing Design
Computing Design
Computing Service, Server Type, and Sizing
Selecting Computing Services Suitable for Workloads
The specifications of the computing services provided by Samsung Cloud Platform are as follows.
| Product | Type | CPU | Memory | Option | Option |
|---|---|---|---|---|---|
| Virtual Server | Standard | 1/2/4/6/8/10 vCore | 2~160GB | Max Network Bandwidth | 10Gbps |
| Virtual Server | Standard | 12/14/16 vCore | 24~256GB | Max Network Bandwidth | 12.5Gbps |
| Virtual Server | High Capacity | 24/32/48/64/72/96/128 vCore | 48~1,536GB | Max Network Bandwidth | 25Gbps |
| GPU Server | A100(80G) | 16/32/64/128 vCore | 240~1,920GB | GPU | 1~8 |
| GPU Server | H100(80G) | 12/24/48/96 vCore | 240~1,920GB | GPU | 1~8 |
| Bare Metal Sever(3thGen) | 16/32/64/96/128 vCore | 64~2,048GB | Physical CPU | 8~64 |
※ You can check the latest server type by visiting the site below. Virtual Server : https://cloud.samsungsds.com/serviceportal/services/compute/virtualServer.html GPU Server : https://cloud.samsungsds.com/serviceportal/services/compute/gpuServer.html Bare Metal Server : https://cloud.samsungsds.com/serviceportal/services/compute/baremetal.html
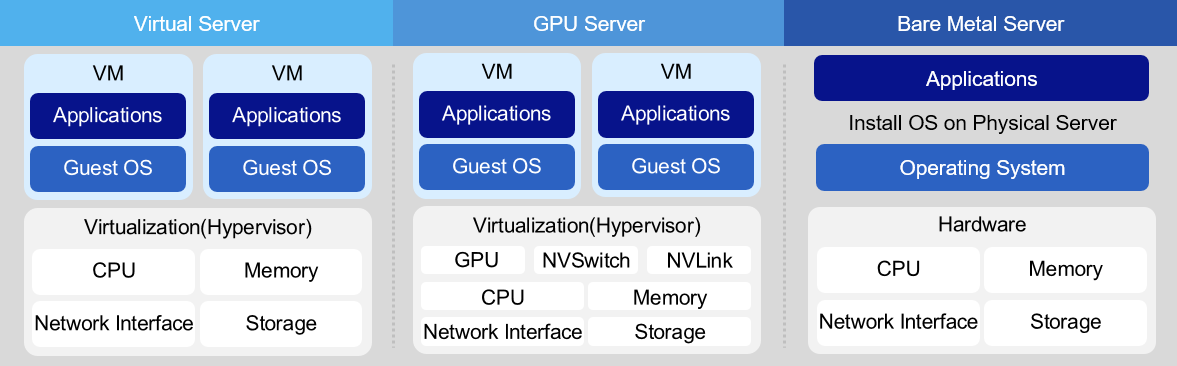
Virtual Server
Virtual Server is offered in Standard (s1) type of up to 16 vCore and High Capacity (h2) type of 24 vCore or more. Standard type uses Intel Ice Lake CPU, and 1vCore/2GB is the minimum specification. From 2 vCore to 16 vCore, it is offered in CPU:Memory combinations of ratios 1:2, 1:4, 1:8, 1:16. High Capacity type uses Intel Sapphire Rapids CPU and is offered as a CPU:Memory combination with ratios of 1:2, 1:4, 1:8, 1:12 from 24 vCore to 128 vCore. The operating systems include RHEL, Ubuntu, Alma, Rocky, Oracle Linux, and Windows Server, and can configure Kubernetes images, Data Service Console images, etc. Virtual Server can be used for various purposes such as development, testing, Application execution, depending on the user’s computing usage purpose.Bare Metal Server Bare Metal Server is a high‑performance cloud computing service that does not use virtualization technology and is allocated dedicated, physically separated computing resources such as CPU and memory. The third-generation service using Intel Sapphire Rapids is currently being offered. The CPU:Memory combinations of the provided server types are offered as 1:4, 1:8, and 1:16. The default OS Internal Disk is 480GB2 for 16 vCore, 960GB2 for 32 vCore, and 1.92TB*2 for 96/128 vCore. Bare Metal Server is suitable for workloads that require high capacity and high performance, such as real-time (Real-Time) systems, HPC (High Performance Computing), and servers that require excessive I/O usage. Also, you can use the Multi-Attach feature to configure databases that require Active-Active high availability.
Server Sizing
After selecting a computing service suitable for the workload, you need to determine the server specifications and quantity based on availability and performance requirements.
In on-premises environments, the process of determining server specifications and quantity was very important, but in cloud environments, it can become a flexible task that can be changed at any time.
Because it can be adjusted later even if there is a difference between the initially set specifications and the actually needed specifications.
Nevertheless, the reason server sizing is important is because you need to calculate the workload operating cost (monthly usage fee) in the cloud, and based on that derive the TCO (Total Cost of Ownership) compared to on-premises deployment.
To estimate the scale of information system hardware, the following three methodologies can be considered.
| Category | Concept | Advantage | Disadvantage |
|---|---|---|---|
| Formula calculation method | Method of calculating capacity figures based on factors such as number of users for scale estimation, and applying correction factors | Can clearly present the basis for scale estimation and can be estimated more simply compared to other methods | If the correction factor is incorrect, there can be a large discrepancy from the desired value, and it is difficult to present accurate supporting data for the correction factor |
| Reference method | Based on the workload (number of users, DB size), estimate a similar scale by comparing the approximate system size using basic data | Since it can be compared with existing built business systems, a relatively safe scale estimation is possible | Since it is based on comparison rather than calculation, the justification is weak |
| Simulation method | Model the workload of the target task and simulate it to estimate the scale | Can obtain relatively accurate values | Time and cost are high |
The formula calculation method and reference method extract various indicators to estimate the resource usage of servers built on the cloud.
Generally, cloud capacity estimation finds the capacity balance point by adjusting through simulation methods or operation.
However, there are many cases where sizing is needed for reasons such as establishing a usage fee budget or proposals.
The formula calculation method can provide an objective capacity design standard because it estimates server capacity using various indicators.
Web/WAS CPU sizing by formula calculation method
First, we calculate the CPU capacity of the Web/WAS server using a formula.
| Calculation Item | Calculation Basis | Scope of Application | Default Value |
|---|---|---|---|
| Concurrent Users | Users who use software or systems simultaneously over a network | - | Calculated Value |
| Number of operations per user | Number of business logic operations generated per second by a single user | 3 ~ 6 | 5 |
| Basic OPS correction | Correction factor to apply the OPS (Operations Per Second) measured in the experimental environment to a complex real environment (Basic OPS correction uses 3) | - | 3 |
| Business Use Adjustment | Adjustment factor according to applicable system type (0.7: Web server, 2: WAS server) | - | Web: 0.7 WAS: 2 |
| Interface Load Compensation | Compensation factor considering the load generated at the interface when communicating between servers (generally applied value 1.1) | 1.1 ~ 1.2 | 1.1 |
| Peak time load correction | Correction factor to solve load generated by sudden many connections | 1.2 ~ 1.5 | 1.3 |
| Link Load Compensation | Compensation considering the workload generated from integration with other systems | 1 ~ 1.3 | 1 |
| Cluster correction | Correction factor for preparing for failures in a cluster environment (applied according to number of nodes) | 2Node : 1.4~1.5 3Node : 1.3 | 2Node : 1.4~1.5 3Node : 1.3 |
| System margin rate | Adjustment for stable operation of the system ※ Additional margin considering unexpected increase in work, etc. | 1.3 | - |
| System Target Utilization | Maximum CPU utilization target based on stable system operation | 0.7 | - |
| Unit correction | Conversion factor for converting the calculation result to max-OPS units | 24~31 | - |
| Formula | CPU(max-jOPS) = (number of concurrent users * operations per user * basic OPS correction * business usage correction * interface load correction * peak time load correction * integration load correction * cluster correction * system margin) / (system target utilization * unit correction) | ||
| Core estimation | Estimated jOPS / baseline performance per core jOPS * baseline performance per core jOPS varies from 1,000 to 3,000 depending on hardware. If, according to the above calculation, jOPS is 5,000 and baseline performance per core jOPS is 1,500, then the estimated cores are 5,000/1,500 ≈ 3.3 cores, and when selecting the Virtual Server server type, choose 4 cores. |
- Number of concurrent users
A concurrent user refers to a user who uses software or a system simultaneously over a network, and is generally defined based on a session (from the request for a business service to the termination of the service). Generally, the estimation of concurrent users for an existing web system in operation can be obtained relatively easily based on operational data. On the other hand, the new system must derive the number of concurrent users through estimation. First, calculate the total number of users of the system. The total number of users usually refers to the total users registered in the system, generally meaning users with access rights. However, in the case of the web, an unspecified many can access, so estimation is needed. Then, calculate the number of connected users as a certain proportion of the total number of users. The connected user is a user who is online, and may generate transactions or operations, or may just be connected. Finally, you can estimate the number of concurrent users by multiplying this number of connected users by a certain ratio. In a 3-tier web application, the number of users of the Web server, WAS server, and DB server have a close relationship. The number of concurrent users on the WAS server will not be greater than the number of concurrent users on the Web server, and the number of concurrent users on the DB server will not be greater than the number of concurrent users on the WAS server. Considering these relationships, you can estimate the number of concurrent users at each layer. The table below shows the estimated number of concurrent users in a typical information system.
| Category | Concept | |
|---|---|---|
| Web server | external service | Estimate the number of connected users as about 1% ~ 10% of the total number of users, and estimate the number of concurrent users as 5% ~ 30% of the connected users |
| Web server | large content service | Estimate 30% ~ 50% of the total number of users as the number of connected users, and estimate 40% ~ 70% of the connected users as the number of concurrent users. |
| WAS 서버 | Calculated within the range of 50% ~ 100% of the estimated concurrent Web server users, typically around 75% | |
| DB server | Calculated based on 50% ~ 100% of the estimated concurrent users of WAS, generally at 75% level |
- Number of operations per user
The number of operations per user is the number of business logic operations generated by a single user per second, and is assumed to be about 3 to 6 depending on the type of work.
| Applied Value | Description |
|---|---|
| 3 | Web service-focused tasks (refers to tasks centered on retrieval rather than complex application logic) |
| 4 | Web service and application logic are mixed, but the work is mainly web service |
| 5 | Web services and application logic |
| 6 | Application logic-focused work |
Basic OPS correction
The OPS figures provided by SPEC (Standard Performance Evaluation Corporation) are measured in optimal conditions and differ from actual operating environments. Therefore, the OPS values measured in the experimental environment need to be calibrated to apply to the complex real environment, which is called the basic OPS calibration. The default OPS correction applies a fixed value of 3.Work purpose correction
There is a relative difference in workload between the Web server and the WAS server. Considering these differences, we apply different correction factors depending on the system type, which is called business-use correction. Business purpose correction is applied differently depending on whether the calculation target is a Web server or a WAS server. When it is a Web server, apply a correction factor of 0.7, and when it is a WAS server, apply a correction factor of 2.
| Applied Value | Description |
|---|---|
| 0.7 | Web server |
| 2 | WAS |
Peak time load correction
To increase work efficiency and obtain accurate and immediate results, the system must operate stably during the peak times when work is most concentrated. Therefore, when estimating system size, you should base it on peak time. Generally, the system receives about 20%~50% more load during peak times compared to normal times. Considering this, we adjust the system capacity by applying a weighting factor of 1.2~1.5 times to the calculated capacity. Category Applied Value Description High 1.5 When an extremely excessive load occurs at a specific time or specific day Mid 1.4 When excessive load occurs on a specific deadline ha 1.3 When there is a peak time daily or weekly in a specific time zone Other 1.2 When peak time exists but there is no load difference Table. Peak Time Load CorrectionCluster correction
Cluster correction is applied when two systems are configured as one cluster (One-to-one form). If a failure occurs on one server, the remaining servers must all bear the load that the application has to perform. In this case, if there is no system reserve ratio, overload makes normal operation difficult, so an additional reserve ratio must be set. These preliminary rates vary depending on the cluster’s configuration type. In an Active-Active architecture, each counterpart system should be set to a 100% reserve rate, but this is uneconomical and inefficient, so a value of 1.3 to 1.5 is applied. The application of the value varies depending on the number of Nodes; apply 1.4 ~ 1.5 for a 2-Node configuration and 1.3 for a 3-Node configuration. In an Active-Standby architecture, the actual service is operated on one device while the other is used as a standby system for fault tolerance. If a failure occurs, the entire function of the equipment is transferred to another standby device, and the function is performed on the standby device. In this Active-Standby architecture, you do not need to apply a separate cluster correction factor.
| Clustering | Node | Applied Value |
|---|---|---|
| Active-Active | 2-Node | 1.4 ~ 1.5 |
| Active-Active | 3-Node | 1.3 |
| Active-Standby | Active-Standby | 1 |
- Link load correction It is a correction factor that takes into account the workload generated from integration with other systems, rather than the load caused by the number of concurrent users. Generally, system integration is linked to the WAS server rather than the Web server, so considering this, a correction factor of 1 is applied to the Web server. On the other hand, for the WAS server, a separate correction factor can be applied as follows depending on the frequency and processing complexity of the linked transactions.
| Category | Applied Value | Description |
|---|---|---|
| Web server | 1 | In the case of Web server |
| WAS | 1 | When there is no linked work among all WAS tasks (0%) |
| WAS | 1.1 | When the linked tasks among all WAS tasks are only simple query tasks (10% of total load) |
| WAS | 1.2 | When among all WAS tasks, the linked tasks are only internal renewal tasks (20% of total load) |
| WAS | 1.3 | If there is internal/external renewal work in linked tasks among the total WAS tasks (30% of total load) |
System utilization rate
System margin is a correction factor for stable operation even in cases of unexpected workload increase or abnormal traffic conditions. Construction-type systems generally apply an additional margin of 30%, i.e., a correction factor of 1.3.System Goal Utilization Rate
Generally, information systems are designed based on a target utilization rate of 100%, but for stable operation of the system, the actual utilization is operated so that it does not reach 100%. As such, the maximum CPU utilization for stable system operation is called the system target utilization, and generally a maximum of 70% (coefficient 0.7) is applied.Unit correction
Unit correction is a correction factor applied depending on the server’s type. When applying max-jOPS in composite form, X86 servers can use 29, Unix servers can use 31, and the default value can be 30. When applying max-jOPS in MultiJVM form, X86 server can use 24, Unix server can use 26, and the default value can be 25.
| Category | Applied Value | Description |
|---|---|---|
| Composite SPECjbb2015 | 29 | X86 server |
| Composite SPECjbb2015 | 30 | Server type unspecified (default value) |
| Composite SPECjbb2015 | 31 | Unix server |
| MultiJVM SPECjbb2015 | 24 | X86 server |
| MultiJVM SPECjbb2015 | 25 | Server type unspecified (default value) |
| MultiJVM SPECjbb2015 | 26 | Unix server |
DB server CPU sizing by formula calculation method
Now we calculate the CPU capacity of the DB server using the formula method.
Unlike the Web/WAS server, the DB server derives and calculates tpmC based on the number of transactions per minute.
| Calculation Item | Calculation Basis | Application | Calculation Item |
|---|---|---|---|
| Transactions per minute | Sum of estimated transactions per minute occurring on servers subject to calculation | - | Number of tasks: 2 Transactions per task: 4~6 |
| Basic tpmC correction | Correction factor to apply the tpmC values measured in the experimental environment to a complex real environment | - | 5 |
| Peak Time Load Compensation | Adjustment factor considering peak time to ensure smooth system operation during periods of heavy workload | 1.2 ~1.5 | 1.3 |
| Database size correction | Correction factor considering the number of records in the database table and the total database volume | 1.5 ~ 2.0 | 1.7 |
| Application structure correction | Correction factor considering performance differences based on the Application’s structure and required response time | 1.1 ~ 1.5 | 1.2 |
| Application load correction | Correction factor considering cases where batch jobs, etc., occur simultaneously during peak times when online tasks are performed | 1.3 ~ 2.2 | 1.7 |
| Linkage Load correction | Correction factor considering the workload generated from linkage with other systems | 1 ~ 1.2 | 1 |
| Cluster Calibration | Adjustment value prepared for failures in a cluster environment | 2 Node : 1.4~1.5 3 Node : 1.3 | 2 Node : 1.4~1.5 3 Node : 1.3 |
| System slack rate | Additional margin considering unexpected increase in tasks, etc. | 1.3 | - |
| System Target Utilization | Maximum CPU utilization target based on stable system operation | 0.7 | |
| Formula | CPU (in tpmC units) = (transactions per minute * base tpmC correction * peak time load correction * DB size correction * application architecture correction * application load correction * integration load correction * cluster correction * system margin) / system target utilization | ||
| Core estimation | estimation tpmC / performance per reference core tpmC * Performance per reference core tpmC varies from 70,000 to 400,000 depending on hardware. If, according to the above calculation, tpmC is 800,000 and performance per reference core tpmC is 190,000, the estimated cores are 700,000/190,000 = about 3.7 cores, and when selecting a server type, choose 4 cores. |
Transactions per minute
In client/server environments, work typically occurs on a transaction basis. Therefore, in an OLTP (Online Transaction Processing) environment, estimating the number of transactions per application becomes the key criterion for sizing the system. There are three methods to calculate transactions per minute: investigation of transactions in the existing system, estimation based on concurrent user count, and estimation based on client count.Investigation of existing system transactions
It is a method of investigating transactions for the operating system on an annual or monthly basis and converting them into per‑minute transactions for use. Generally, existing systems already have annual and monthly transaction data for Application usage, so it is effective to start the calculation based on this data, taking into account the number of days and times transactions occur. At this point, an analysis of the occurrence pattern should also be performed, such as whether transactions occur daily for a month, only for about 20 days excluding weekends, or during 8 hours of the day or 24 hours.Concurrent user count usage
If there is no existing transaction previously investigated, such as when introducing a new system, we use an estimation method based on concurrent user count. In other words, this applies when it is difficult to estimate the expectations for the system and the specific details of the application to be developed in the future. To apply this method, first estimate the total number of users and calculate the concurrent user count. We estimate the number of transactions per minute that a single concurrent user is expected to generate, considering the anticipated task types and characteristics. This value is calculated as “number of tasks × transactions per task”, and ultimately the transactions per minute = concurrent users × transactions per user can be derived.Client count usage
This is a method that can be used when only the number of clients is secured. In this case, we need to consider how the client connects to the server and requests tasks, and this will be reflected in the subsequent correction stage. By default, we assume that all clients exist on the same LAN. And after estimating the number of concurrently used clients from the total number of clients, we calculate the transactions per minute based on the concurrent user count usage method described earlier.Basic tpmC calibration The tpmC figures provided by TPC are measured in optimal conditions, which differ from actual operating environments. Therefore, the tpmC value measured in the experimental environment must be corrected to apply to the complex real environment, which is called the basic tpmC correction. The default tpmC correction value applies a fixed value of 5.
Peak time load correction
To increase work efficiency and obtain accurate and immediate results, the system must operate stably during the peak times when work is most concentrated. Therefore, when estimating system size, you should base it on peak time. Generally, the system experiences about 20% to 50% more load during peak times compared to normal times. Considering this, we adjust the system capacity by applying a weighting factor of 1.2 to 1.5.
| Category | Applied Value | Description |
|---|---|---|
| High | 1.5 | When a very excessive load occurs at a specific time or specific day |
| 중 | 1.4 | When excessive load occurs on a specific deadline |
| 하 | 1.3 | If there is a peak time daily or weekly at a specific time slot |
| Other | 1.2 | When peak time exists but there is no load difference |
- Database size adjustment
The correction factor based on database size is determined by considering the record count of the largest table in the DB and the overall DB volume. In the case of DBs of the same size, the side with a larger number of records gets a higher weight; if the number of records is the same, the side with a larger DB volume gets a higher weight. However, if an accurate value cannot be derived based on a detailed analysis of the actual business system, applying the weight is difficult, so we apply the default value of 1.7.
| Number of records \ DB size | ~ 8 | ~ 32 | ~ 128 | ~ 256 | 256 or more |
|---|---|---|---|---|---|
| less than 50Gbyte | 1.50 | 1.55 | 1.60 | 1.65 | 1.70 |
| less than 500Gbyte | 1.60 | 1.65 | 1.70 | 1.75 | 1.80 |
| less than 1Tbyte | 1.70 | 1.75 | 1.80 | 1.85 | 1.90 |
| less than 2Tbyte | 1.80 | 1.85 | 1.90 | 1.95 | 1.95 |
| 2Tbyte or more | 1.85 | 1.90 | 1.90 | 1.95 | 2.00 |
- Application Structure Correction
Application structure correction is a correction factor that takes into account performance differences based on Application response time. Response time refers not to the server’s response time but to the user’s service response time. The applied values are as shown in the table below, and are not applied if they exceed 5 seconds.
| Response Time | 1 second | 2 seconds | 3 seconds | 4 seconds |
|---|---|---|---|---|
| Applied Value | 1.50 | 1.35 | 1.20 | 1.10 |
- Application Load Compensation
Application load correction is a correction factor considered taking into account cases where batch jobs, etc., occur simultaneously during peak times when online tasks are performed. If additional tasks are processed beyond the designated online work (such as batch tasks like reporting or backup, or when using external systems), the required processing capacity must be adjusted accordingly. Therefore, this Application load correction is applied according to the proportion of batch job occurrences. In cases where there are many additional tasks such as batch jobs as shown in the table below, the maximum value of 2.2 can be applied; when there are no additional tasks such as batch jobs besides online transactions, the minimum value of 1.3 can be applied, and a typical value of 1.7 can be used.
| Category | Applied Value | Description |
|---|---|---|
| Upper | 1.9 ~ 2.2 | When batch-type tasks and other additional tasks are performed frequently |
| 중 | 1.6 ~ 1.8 | When some batch work is performed on online transactions |
| Lower | 1.3 ~ 1.5 | If there are no additional tasks such as batch jobs besides online transactions |
- Linked Load Compensation It is a correction factor that considers the workload generated not by the number of concurrent users but by the integration with other systems. The DB server can be applied differently depending on the level of transaction load of linked operations, etc.
| Applied Value | Description |
|---|---|
| 1 | When there is no linked work among all DB server tasks (not reflected) |
| 1.1 | When the DB server linked task is a simple query and data update linkage (10% of total load) |
| 1.2 | When DB server linked tasks involve large-scale queries and data update linking (20% of total load) |
- Cluster correction
Cluster correction is applied when two systems are configured as a single cluster (one-to-one configuration). If a failure occurs on one server, the remaining servers must all handle the load that the application has to perform. In this case, if there is no system reserve ratio, overload makes normal operation difficult, so an additional reserve ratio must be set. This preliminary rate varies depending on the cluster’s configuration. In an Active-Active architecture, each counterpart system should be set at 100% redundancy, but this is uneconomical and inefficient, so a value of 1.3 to 1.5 is applied. The application of the value varies depending on the number of Nodes; apply 1.4 ~ 1.5 for a 2-Node configuration and 1.3 for a 3-Node configuration. In an Active-Standby configuration, the actual service is operated on one device while the other is used as a standby system for fault tolerance. If a failure occurs, the entire function of the device is transferred to another device that is on standby, and the function is performed on the standby device. In this Active-Standby architecture, you do not need to apply a separate cluster correction factor.
| Clustering-Node | Applied Value |
|---|---|
| Active-Active - 2 Node | 1.3 ~ 1.5 |
| Active-Active - 3 Node | 1.3 |
| Active-Standby | 1 |
System utilization rate
System margin is a correction factor for stable operation even in cases of unexpected workload increases or abnormal traffic conditions. Construction-type systems generally apply an additional margin of 30%, i.e., a correction factor of 1.3.System Goal Utilization Rate Generally, information systems are designed based on a target utilization rate of 100%, but to ensure stable operation of the system, the actual utilization is operated so that it does not reach 100%. The maximum CPU utilization for stable system operation is called the system target utilization, and generally a maximum of 70% (coefficient 0.7) is applied.
CPU sizing through reference method
The following is CPU sizing using the reference method.
The reference method calculates the capacity of the system to be built based on the resources of the existing business system.
The method for estimating capacity using the reference method is shown in the table below.
| Calculation Item | Content | Scope of Application | General Value |
|---|---|---|---|
| Existing CPU Core count | Number of cores of target server in existing information system (CPU * cores per CPU) | - | Estimated value |
| Layer Configuration | Apply layer correction factor relative to existing CPU core count | 0.5~3.0 | |
| Redundancy configuration | Apply redundancy configuration correction factor | 0.7~2.0 | |
| Server Type | Apply correction factor according to existing x86 server (physical/virtualized) - Physical: Apply correction factor 1.2 (considering virtualization overhead) - Virtualization: No correction factor applied | ||
| CPU average usage rate | Average CPU usage of the existing information system (apply 0.5 if 50%) | 1%~100% | - |
| CPU idle usage rate | Adjustment factor for stable operation of the system | 1.3 | - |
| Formula | Capacity estimation = Number of existing CPU cores * Layer configuration correction factor * Redundancy configuration correction factor * Server type correction factor * Average CPU utilization * Spare utilization correction factor | ||
| Core calculation | Existing CPU count (4) * No change in tier configuration (1) * A-A redundancy configuration (0.7) * Server type physical → virtual (1.2) * CPU average utilization 30% (0.3) * Spare utilization 30% (1.3) = approx. 1.3 cores * Calculate 2 cores considering server type. |
Existing CPU Core count
It is calculated based on the CPU cores used in the existing information system server. This reference method does not consider the CPU’s own performance, and calculates based on the number of CPUs and the number of cores per CPU.Layered Structure If the existing server’s hierarchical configuration changes, the correction factor is calculated considering load balancing. When the hierarchy increases or decreases, the correction factor is calculated respectively.
| Layer Change | Applied Value | Content |
|---|---|---|
| 1→2,2→3 | 0.7 | (Web/WAS/DB)→(Web),(WAS/DB) or (Web/WAS),(DB) (Web),(WAS/DB) or (Web/WAS),(DB)→(Web),(WAS),(DB) |
| 1→3 | 0.5 | (Web/WAS/DB)→(Web),(WAS),(DB) |
| 2→1,3→2 | 2.0 | (Web),(WAS/DB) or (Web/WAS),(DB)→(Web/WAS/DB) (Web),(WAS),(DB)→(Web),(WAS/DB) or (Web/WAS),(DB) |
| 3→1 | 3.0 | (Web),(WAS),(DB)→(Web/WAS/DB) |
- Redundancy configuration If the hierarchical configuration of the existing server changes, the correction factor is calculated considering server load balancing. When the hierarchy increases or decreases, the correction factor is calculated respectively.
| Layer change | Applied value | Content |
|---|---|---|
| 1→2 | 0.7 | Active–Active redundancy configuration correction factor |
| 1→2 | 1.0 | Active–Standby redundancy configuration correction factor: no correction |
| 2→1 | 2.0 | Active–Active change from dual configuration to single configuration |
- Server type
Apply correction factors considering whether the existing information system server is a physical server or a virtual server. When transitioning from a physical server to the cloud, a correction factor is applied considering the overhead of virtualization.
| Existing Server | Applied Value | Content |
|---|---|---|
| Physical Server | 1.2 | Apply physical-virtual conversion correction factor according to cloud virtualization |
| Virtual Server | 1.0 | Virtualization – No correction applied because it is a virtualization transition |
CPU average usage rate We measure the computing usage of the existing server, taking into account the average CPU usage of the existing information system server.
CPU idle usage rate
Apply a correction factor that takes into account the target CPU utilization when configuring a new server. For example, if the target average CPU usage is 70%, a correction factor of 1.3 is applied considering a 30% margin.
Server memory sizing by formula calculation method
The method of estimating memory size by formula calculation is much simpler compared to the CPU.
We use strategies to reduce memory usage by various methods such as programming languages or using threads for each built system.
According to this strategy, there are slight differences in the scaling estimation methods, and the number of processes running in the system and the amount of memory those processes use have a significant impact on memory estimation.
However, in these guidelines, the memory size is estimated based on the purpose and structure of a general system, without considering programming languages, thread usage, or reflecting memory configuration characteristics of specific systems.
| Calculation Item | Calculation Basis | Scope of Application | Default Value |
|---|---|---|---|
| System Area | OS, DBMS engine, middleware engine, other utilities etc. required space | - | Estimated value |
| Memory required per user | Memory required per user for using Application, middleware, DBMS | 1MB~3MB | 2MB |
| Concurrent Users | Users who use software or system simultaneously on a network | - | Calculated Value |
| OS buffer cache correction | Correction factor for a memory location that temporarily stores a certain amount of data to improve processing speed | 1.1~1.3 | 1.15 |
| Application required memory | Cache area used by middleware such as DBMS shared memory, WAS heap size, etc. | - | Calculated value |
| System margin | Adjustment factor for stable operation of the system | 1.3 | - |
| Formula | Memory (in MB) = {system area + (memory required per user * number of users) + Application required memory} * buffer cache correction * system margin | ||
| Memory estimation example | {System area 256MB + (Memory needed per user 64KB * Number of users 3,000) + Application needed memory 300MB} * Buffer cache correction 1.15 * System margin 30% (1.3) * The result of the above formula is 991.54MB. Memory can be estimated according to server type. |
System Area
The system area refers to the memory space required for the execution of operating software (operating system, network daemon (Daemon), database engine, middleware, utilities, etc.), and it is calculated based on the memory required by each software when it runs. In particular, this area must be applied differently depending on the number of licenses for the software, such as databases, and is generally calculated by reflecting the required memory recommended by each software manufacturer.Memory required per user
The required memory per user refers to the amount of memory required per user depending on the use of applications, middleware, DBMS, etc. This value is calculated considering various factors. For example, the required memory per user can vary depending on the implementation method of the application, the middleware application method, the I/O structure of the user process, the architecture of the DBMS vendor, etc. However, if calculation is impossible, a value between 1MB and 3MB can be applied arbitrarily.Number of concurrent users A concurrent user refers to a user who uses software or a system simultaneously over a network. In terms of memory, the number of concurrent users is not calculated separately, and the estimated concurrent user count based on CPU from the previous step is applied identically.
OS buffer cache correction Computers collect a certain amount of data and process it all at once to improve processing speed, and the storage location where the data is gathered is called a buffer cache. The correction factor that takes this into account is called OS buffer cache correction. OS buffer cache correction can apply values from 1.1 to 1.3, and the default value is 1.15.
Application required memory Application required memory refers to the cache area used by middleware such as DBMS shared memory and WAS heap size (Heap Size). The size of this memory is determined by the requirements of each middleware such as DBMS, WAS, etc.
System utilization rate
This is a correction factor for stable operation of the system due to an unexpected increase in workload. For on-premise systems, a typical additional margin of 30% (correction factor 1.3) is considered.
Container Application Review
Containers are one of the most widely used tools for application modernization.
If you package the application and runtime into a container, you can deploy to all operating system platforms, and by providing platform‑independent functionality, it simplifies software development, testing, and deployment processes and facilitates automation.
Containers are effective for building complex multi-tier applications.
For example, when you need to run the Application server, database, and message queue together, you can run each as a separate container image in parallel and set up communication between them.
Even if library versions differ at each layer, they can be run on the same computing server without conflicts through containers.
Kubernetes is a platform that can efficiently manage and control multiple containers in an operational environment.
Kubernetes provides horizontal scaling capabilities and blue-green deployment features that minimize downtime.
It can also distribute user traffic load across containers and manage storage shared among various containers.
GPU Application Review
GPU Server can configure a virtual server by selecting GPU card type and quantity according to the project’s purpose and scale, and provides a high-performance GPU server at the physical server level using the Pass-through method.
The specifications of the provided NVIDIA GPU are as follows, and the operating systems RHEL and Ubuntu are provided.
| Category | V100 Type | A100 Type | H100 SXM |
|---|---|---|---|
| Service Provision Method | Pass-through | Pass-through | Pass-through |
| GPU Performance | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| · GPU Memory | 32GB | 80GB | 80GB |
| · Transistors | 21.1 billion 12nm TSMC | 54 billion 7nm TSMC | 80 billion 4N TSMC |
| · Tensor performance (based on FP16) | 125 TFLOPs | 312 TFLOPs | 1,979 TFLOPs |
| · Memory Bandwidth | 900 GB/sec | 2,000 GB/sec | 3.35 TB/sec HBM3 |
| · CUDA Cores | 5,120 Cores | 6,912 Cores | 16,896 Cores |
| · Tensor Cores | 640 (1st Generation) | 1,024 (3rd Generation) | 528 (4th Generation) |
| NVLink Performance | NVLink 2 | NVLink 3 | NVLink 4 |
| · Total NVLink bandwidth | 300 GB/s | 600 GB/s | 900 GB/s |
| · Signaling Rate | 25 Gbps | 50 Gbps | 25 Gbps (x18) |
| NVSwitch Performance | - | NVSwitch 2 | NVSwitch 3 |
| · NVSwitch inter-GPU bandwidth | - | 600 GB/s | 900 GB/s |
| · Total aggregated bandwidth | - | 9.6 TB/s | 7.2TB/s |
| Linked Storage | Block Storage - SSD | Block Storage - SSD | Block Storage - SSD |
GPU servers equipped with Nvidia V100, A100, and H100 are offered as server types mounted on virtualized computing resources with 1, 2, 4, or 8 GPUs, NVSwitch, and NVLink.
The CPU:Memory combinations for the provided server types are offered as 1:8 for V100, 1:15 for A100, and 1:20 for H100.
GPU Server is suitable for tasks that require fast computation speed such as AI model experiments, predictions, and inference, and you can flexibly select and use resources with optimized performance according to the type and scale of the work.