Operation Plan
Operation Plan
Identify and define operational requirements
Operational excellence refers to continuous improvement activities aimed at running applications stably with minimal downtime to maximize business value and increase system efficiency.
The operations team is responsible for managing the application’s infrastructure and security, as well as handling all software-related issues, to ensure the application operates stably.
Especially in the case of enterprise applications, because availability must be clearly defined through a Service Level Agreement (SLA), the operations team must fully understand business requirements and be able to respond quickly to various events that may arise accordingly.
First, it is necessary to evaluate the elements that can affect operations among the laws or institutional regulations required according to the industry and tasks the organization belongs to.
It is advisable to check the compliance items of the security design principles (Security Design Principles > I. Security Requirements Analysis and Design Principles > 1. Compliance and Security Requirements).
Among various compliance items, the Information Security Management System (ISMS) is a certification that companies or organizations conducting business of a certain scale must obtain when providing services to end users or consumers, and it can be said to be the most common and essential compliance requirement.
The table below summarizes the contents that correspond to the operational management area among ISMS control items.
When establishing operational excellence design principles, it is important to closely review especially the parts concerning change management, performance management, and fault management among these items.
Information System Implementation and Development Security
| Control Item | Description |
|---|---|
| Separation of test and production environments | Development and test systems should be separated in principle to reduce the risk of unauthorized access and changes to the production system. |
| Source Program Management | Source programs should be managed so that only authorized users can access them, and it should be a principle not to store them in the production environment. |
| Transfer to Operational Environment | When transferring newly introduced, developed, or modified systems to the operational environment, a controlled procedure must be followed, and the executable code must be run in accordance with testing and user acceptance procedures. |
System and Service Operations Management
| Control Item | Description |
|---|---|
| Change Management | Procedures must be established and implemented to manage all change records of information system-related assets, and the impact on system performance and security before changes must be analyzed. |
| Performance and Incident Management | To ensure the availability of information systems, performance and capacity requirements must be defined and the status continuously monitored, and procedures such as detection, recording, analysis, recovery, and reporting for effective response to incidents must be established and managed. |
Among various management systems, IT Service Management (ITSM, IT Service Management) is a process-based approach to effectively design, build, deliver, operate, and manage IT services in line with business requirements, and frameworks such as the IT Infrastructure Library (ITIL: Information Technology Infrastructure Library) represent this.
ITSM approaches from the perspective of the entire service lifecycle rather than being technology-centric, and can be said to be the most common and essential operational management framework adopted by organizations to provide stable and efficient services to end users.
Service transition
| Control Item | Description |
|---|---|
| Change Management | Manage all changes to IT services and infrastructure according to controlled procedures, minimizing service interruptions and business risks caused by changes. |
| Release and Deployment Management | Plan and control the entire lifecycle of safely and successfully deploying and transferring approved changes to the actual production environment. |
Service operation
| Control Item | Description |
|---|---|
| Incident Management | When unexpected service interruptions or quality degradation (incidents) occur, we quickly detect, record, analyze, and restore the service to minimize business impact. |
| Problem Management | Identify the root cause (Root Cause) of failures and establish measures to prevent recurrence, thereby preventing failures in advance and securing long-term stability. |
| Service Level Management | Continuously monitor, measure, report, and perform improvement activities to ensure that the service level objectives defined in the SLA (availability, performance, etc.) are being achieved. |
| Capacity Management | Secure and manage IT resources and performance required for current and future business needs cost-effectively, and monitor to prevent performance degradation. |
Separation of test environment and production environment
Development and test environments must be configured separately from the production system by logically/physically separating them at the VPC and account (Account) level.
Also, it is advisable to strictly restrict developers from directly accessing the operating system via IAM (Identity and Access Management) policies.
If the organization is small or lacks human resources, making it difficult to separate development and operations tasks, it can be compensated through mutual review among staff, monitoring by superiors, and review and approval procedures for changes.
Source Program Management
Access rights to the source program should be granted only to authorized developers, and it is necessary to prepare for emergencies through regular backups.
Also, the change history of the source program must be systematically recorded, and any changes must go through a review and approval process.
Generally, source code is managed using configuration management tools such as Git and SVN, and these tools provide functions such as access permission settings, version control, and change history tracking.
Transfer to production environment
When transferring a system that has completed development to the production environment, a separate person, not the developer, must perform the transfer work.
When transferring, you must review in advance whether testing is complete, the transfer strategy, rollback plans in case of problems, etc., and through this you can reduce the risk of operational transition.
In a DevOps environment, the development and deployment of applications are automated, and there are cases where developers perform the deployment themselves.
Even in such cases, rather than granting deployment permissions to all developers, it is more effective to delegate authority only to specific personnel and to control the process by setting up an approval procedure in the automated deployment workflow.
Change Management
If asset changes such as operating system upgrades, commercial software installations, improvements to running applications, network configuration changes, or server specification changes are required, a clear procedure must be established and strictly followed.
Even in the Samsung Cloud Platform environment, systematic management of matters related to architecture management, virtual server changes, image upgrades, etc., is required.
To this end, you must use IaC (Infrastructure as Code) tools to template changes and thoroughly document each change.
Also, you should review by comparing the before-and-after states of the changes to minimize unexpected impacts.
In particular, for large-scale changes, it is important to conduct impact analysis according to the importance of the change and to prepare recovery measures in advance (e.g., rolling back to a previous version of IaC code) in case of change failure.
Through this, you can protect the system from unexpected problems that may occur during change operations and quickly restore it to normal.
Additionally, in a cloud environment, it is necessary to automate change tasks using automation tools, and to monitor the application status of changes in real time through monitoring and alert systems.
Through this, you can increase the stability and efficiency of change operations.
Also, through regular reviews and audits, you must continuously improve the quality of IaC code and processes, and ensure that security and compliance requirements are met.
Through this systematic approach, you can efficiently perform operational change management in a cloud environment and maintain system stability and reliability.
Performance and Fault Management
To ensure the availability of information systems, procedures must be established that include identification criteria for performance and capacity management targets, definition of performance and capacity requirements (thresholds), monitoring methods, recording and analysis of results, and response measures when thresholds are exceeded.
To manage the performance of servers, networks, databases, applications, etc., it is advisable to define performance management components such as CPU usage, memory usage, disk usage, and performance metrics such as response time and throughput, and to use tools that can monitor them in real time.
To detect and respond to failures, you must define the types and severity of failures, and clearly specify the reporting procedures, detection methods, and responsibilities and roles for response and recovery.
Also, it is necessary to have a response system that includes customer guidance procedures and an emergency contact system when a failure occurs.
The incident response history must be documented, including the time of occurrence, severity, responsible personnel and manager, incident details and cause, actions and recovery details, and measures to prevent recurrence, and it should be managed in the form of an incident handling report.
In addition to the mandatory operational management activities required by these compliance requirements, resource operation management items in the cloud environment must also be reviewed together.
The following table is a document that organizes the management items of Managed Service as an example of management items for cloud operations.
| Item | Description |
|---|---|
| Billing/Report | - Cloud monthly usage fee billing - CSP technical support level management - Management of billing deduction elements such as credits |
| Service Support | - Service request receipt - Service work execution time (24h X 365d, 9h X 5d etc.) - Sharing service processing results |
| Resource Management | - Cloud Resource Management (resource creation/modification/deletion) - Data Migration - Backup & Recovery |
| OS operation | - System update and patch management - Performance optimization - System configuration management |
| Incident Response | - Incident Notification (Notification List Management, Notification Delivery, Notification Method, Notification Time) - Response Time for Incident Occurrence (based on SLA) - Incident Analysis Report - Incident Reproduction Test |
| Technical Support | - Issue response - Architecture establishment/improvement support - Cost optimization support - Resource usage review |
| Security | - System security diagnosis and action - Regular inspection of user and permission management - Security policy management and implementation - Security notice |
| Monitoring | - Monitoring configuration - Threshold application and management - Monitoring agent management |
| Report | - Regular report (Monthly operation report, Annual plan) - Irregular report (Audit response, Usage risk report, Service interruption notice and tasks, etc.) |
| |
Cloud Operations Organization Structure
To achieve true operational excellence in a cloud environment, beyond adopting advanced technologies, a collaboration-focused organizational culture that can effectively support it is essential.
This is because the core goal of cloud operation excellence is to achieve both of the two values—business speed (Agility) and service reliability (Reliability)—simultaneously and in a balanced manner, which were once considered conflicting in the past.
The past traditional IT organization was based on a structure where development and operations teams were clearly separated. In this structure, the development team prioritized rapid release of new features, while the operations team prioritized faultless, uninterrupted stability.
These fundamental differences in goals inevitably caused interdepartmental goal conflicts, and changes from the development team caused bottlenecks in the operations team’s stability review stage, becoming the main cause that hinders business agility.
The DevOps culture emerged to solve these chronic traditional operational problems and achieve the shared goal of speed and stability.
DevOps organization composition means not simply separating development (Dev) and operations (Ops) into separate teams, but a collaborative system that aligns the goals of the two organizations and shares responsibilities across the entire service lifecycle (planning, development, deployment, operation).
Based on this DevOps culture, the role of modern cloud operations organizations is fundamentally redefined.
No longer staying in the traditional role of controlling and managing changes to ensure stability.
Instead, to support both business speed and stability, we build and provide an automated CI/CD pipeline, IaC templates, and a platform with built-in monitoring and security, enabling development teams to deploy quickly and safely on their own.
| Category | Traditional IT Operations Organization | Cloud Operations Organization |
|---|---|---|
| Operational priority | Departmental goal optimization (e.g., development is functionality, operations is stability) | Shared business goals (fast deployment and stable service) |
| Role distinction | Clear technical domain distinction (Server, Network, DB, Security) | Emphasizing automation and efficiency, Performing multiple technical fields comprehensively based on various technology stacks |
| Main Roles | System Administrator, Network Administrator, Database Administrator, Security Administrator, etc. | SRE, DevOps Engineer, Cloud Architect, Security Administrator, etc. |
| Operation method and process | Operates focusing on tasks such as system updates and maintenance, Development and operation are separated | Performs automated updates and management tasks, Development and operation tasks are connected or integrated |
The operating model in a cloud environment can vary depending on how the workload is configured.
Cloud operation within the existing organizational structure
In the process of migrating existing IT infrastructure to the cloud, especially when converting using the Lift & Shift method or moving only some workloads to the cloud while keeping the rest in an on‑premises environment, this is often the case.
In such situations, when designing a cloud operating model, you can consider two main approaches: adding a separate cloud operations team within the existing IT operations organization, or integrating cloud operations tasks into the roles of the existing organization.
The first method is to add a separate cloud operations organization.
This is a method of forming a specialized team tailored to the characteristics and requirements of the cloud environment, to be responsible for managing, monitoring, securing, and optimizing cloud infrastructure.
This approach strengthens expertise in cloud environments, and through role separation from the existing on-premises operations organization, allows focused management of each environment.
However, this method has the drawback that role duplication or communication costs may arise within the organization.
The second method is to integrate cloud operation tasks into the role of the existing organization.
This method enables the existing IT operations organization to manage both cloud and on-premises environments, thereby establishing an integrated operating model between the two environments.
This method strengthens collaboration within the organization and is advantageous for maintaining consistent policies and processes between cloud and on-premises environments.
Also, while efficient utilization of resources within the organization is possible, operational efficiency may decline if there is a lack of expertise in cloud environments.
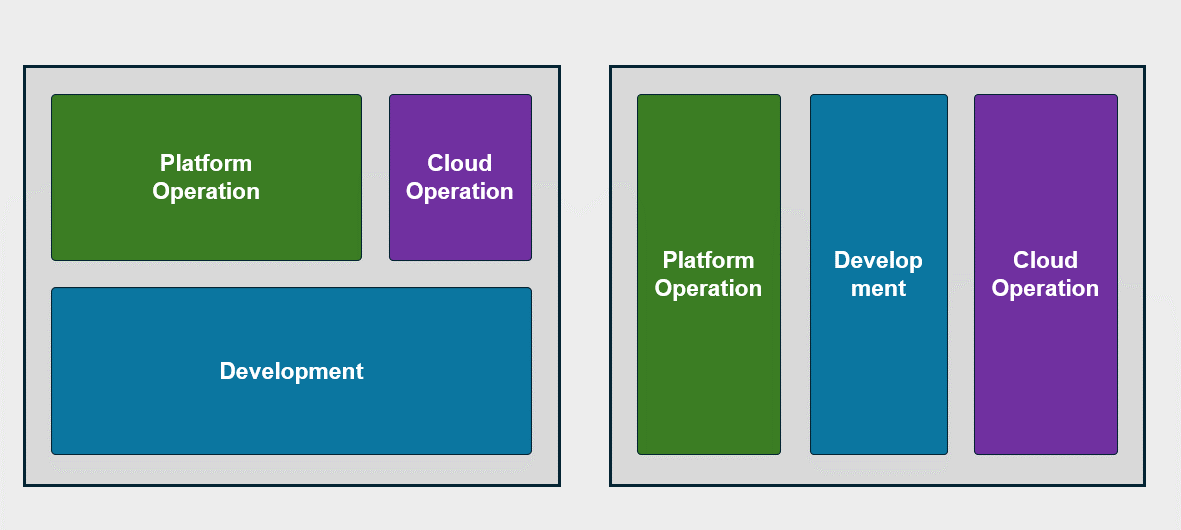
Infrastructure operation after cloud migration
The role of cloud infrastructure operations and development teams undergoes significant changes when an organization’s major workloads have been migrated to the cloud or newly built on a cloud basis.
Previously, there was an on-premises operations organization composed by function, but after the cloud transition, as many personnel began managing cloud-based workloads, the role of the operations organization is also being reorganized to focus on cloud infrastructure.
In this structure, application-related tasks are still handled by the development team, and the platform operation is designed as an operating model that is restructured to fit the cloud environment.
The cloud infrastructure operations organization is designed considering the characteristics of the cloud environment, and operates focusing on cloud resource management, monitoring, security, and optimization tasks.
This organization utilizes the platform of a cloud service provider (CSP) to efficiently manage infrastructure and simplifies repetitive tasks through automation tools and scripts.
Additionally, it provides flexibility to quickly respond to business demands by leveraging the elasticity and scalability of the cloud environment.
The development team continues to handle tasks related to application development and optimizes the development process in a cloud environment.
To this end, the development team designs a cloud-native architecture and builds microservice-based applications to maximize the advantages of the cloud environment.
Also, it supports fast and stable software deployment through the CI/CD pipeline, and smoothly performs integration between cloud infrastructure and applications.
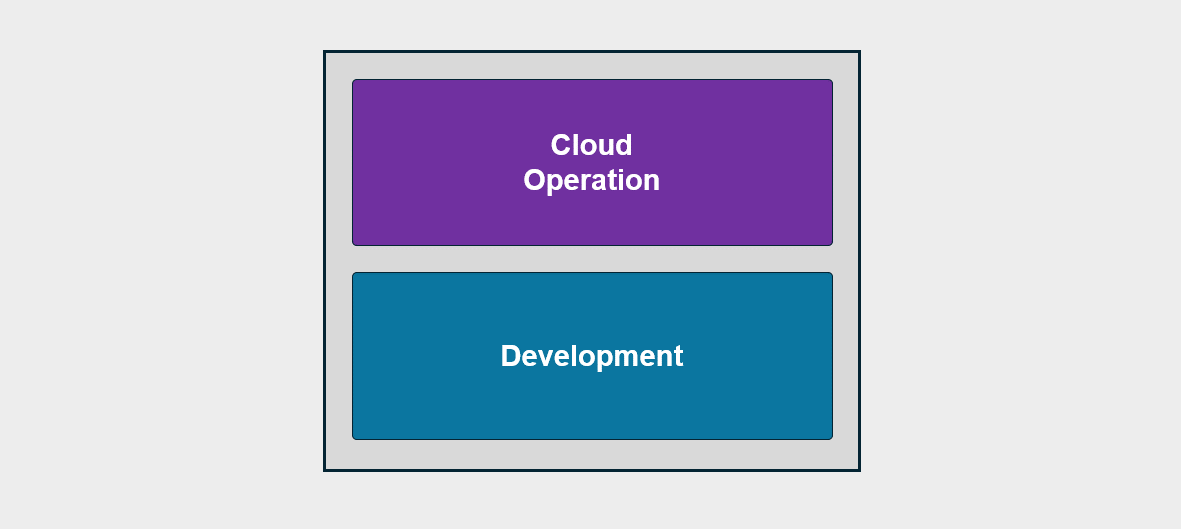
DevOps System Operation
If an organization decides to rebuild its core systems as cloud-based CI/CD applications, the operating model will also change to an optimized cloud One Team structure accordingly.
In this case, the cloud operations team and the development team are integrated into a DevOps team, and their roles are redefined as a unit responsible for continuous integration and deployment processes.
Through this, collaboration between development and operations becomes tighter, and rapid deployment and stable operation in a cloud environment can be achieved simultaneously.
Also, for enhanced security, operations may be integrated in a DevSecOps manner.
This means a structure where security, development, and operations organically cooperate as one team, and supports integrating security elements into the development and operation processes to build a safe application from the start.
This integrated operating model maximizes efficiency and stability in cloud environments, and provides a foundation for effectively achieving the organization’s business goals.
Optimized cloud one-team operation breaks down boundaries between teams and fosters a culture of collaboration toward common goals.
Through this, organizations can respond quickly and flexibly even in cloud environments, and can lay the foundation for continuous innovation and maintaining competitiveness.
