Evaluation and Improvement
Evaluation and Improvement
Definition of Process for Continuous Improvement
When creating a process for continuous improvement, the first thing to define is the role.
It is necessary to designate who among the members has authority and will perform the required tasks, and to ensure visibility of the improvement flow.
The following figure is an example of a DevOps Pipeline for the improvement process.
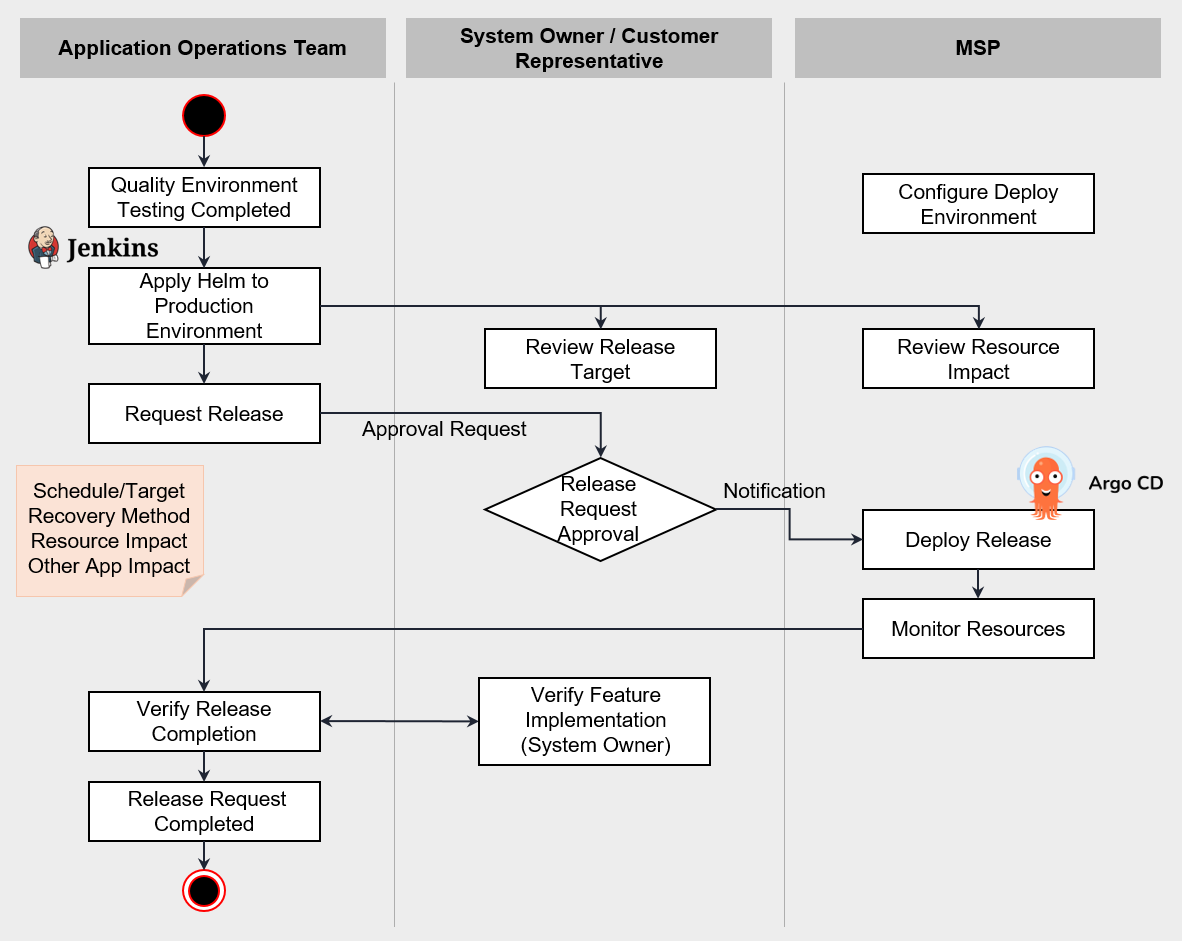
The tasks to be performed at each stage are as follows.
| Stage | Description |
|---|---|
| Project Creation/User Addition | Create a DevOps project and add users on Samsung Cloud Platform. |
| Role Definition | Assign a person in charge according to the task among users, and grant permissions. |
| Change Commit | Commit new or improved infrastructure configuration templates or Application code to the code repository. |
| Build and Test Changes | In the test environment, build and deploy the changed code for testing. Considering the environment presented in the earlier errors or improvements, reproduce the necessary test environment and perform testing. |
| Deploy code to production environment | Deploy the tested Application and infrastructure configuration to the production environment after passing through Staging. |
| Monitoring | Errors, improvements derived from the improvement stage are reflected in the monitoring indicators. The performance of measurement indicators is monitored. |
| Errors, Improvements | Organize the errors and improvements identified during the monitoring process. |
When configuring a process for continuous improvement as above, you need to consider work elements such as those in the table below.
| Improvement work items | Description |
|---|---|
| Number of stages | In CI/CD, development, integration, system, user acceptance, and production may be included. Some organizations also include development, alpha, beta, and release stages. |
| Test Types of Each Stage | Each stage can perform various types of tests such as unit testing, integration testing, system testing, UAT, smoke testing, load testing, and A/B testing in the production stage. |
| Test Order | Test cases are executed in parallel or sequentially. |
| Monitoring and Reporting | Monitor system defects and failures, and send notifications when a failure occurs. |
| Infrastructure provisioning | Defines the infrastructure provisioning method for each stage. |
| Rollback | Define a rollback strategy that reverts to a previous version when needed. |
Perform post-event analysis
If a failure occurs during system operation, you must learn from mistakes and identify the problem.
You must ensure that the same failure does not recur, and if a failure repeats, you must prepare a solution in advance.
One of the improvement measures is to implement a root cause analysis called RCA (Root Cause Analysis), which helps analyze the fundamental cause of a problem and prevent its recurrence.
RCA performs problem analysis through the following five-step questions.
| Step | Question |
|---|---|
| Step 1 Problem Definition | - What happened? - What are the specific symptoms? |
| Step 2 Data Collection | - What evidence proves that there is a problem? - How long has the problem existed? - What is the impact of that problem? |
| Step 3 Cause Element Exploration | - Which events turned into problems? - Under what conditions did the problem arise? - What other issues surround the core problem? |
| Step 4 Root Cause Exploration | - Why do the cause elements exist? - What is the real cause that triggers the problem? |
| Step 5: Propose and Implement Solutions | - What should be done to prevent the problem from recurring? - How can the solution be implemented? - Who is responsible for it? - What are the risks associated with implementing the solution? |
Knowledge Management Execution
The manual provides the method for executing tasks to resolve problems caused by external or internal events. Occasionally, the operations team delays document updates, often leaving outdated manuals neglected.
If the documentation is insufficient, because the work relies on people, the risk of errors increases, so system operation must always be kept separate from people, and a process for documenting all parts must be established.
To enable new team members to quickly resolve similar issues by referring to existing incident cases and solutions, document automation via scripts is needed so that documentation is automatically updated when the system changes.
The documentation should include a Service Level Agreement (SLA) defined with respect to recovery time objective/recovery point objective (RTO/RPO), latency, scalability performance, etc.
The system administrator maintains documentation that includes system start, stop, patch, and update phases, and the operations team must include system test and verification results in the documentation along with event response procedures.
It is desirable for the operations team to automate the process of applying changes to the system, building, and then adding annotations to the documentation, and in this case, annotations can be used to automate tasks and can be easily read as code.
Because business priorities and customer requirements continuously change and evolve over time, maintaining an operational environment that supports this is a core success factor of operations.