컴퓨팅 설계
컴퓨팅 설계
컴퓨팅 서비스, 서버 타입 및 사이징
워크로드에 적합한 컴퓨팅 서비스 선택
Samsung Cloud Platform에서 제공하는 컴퓨팅 서비스 사양은 아래와 같습니다.
| Product | Type | CPU | Memory | Option | Option |
|---|---|---|---|---|---|
| Virtual Server | Standard | 1/2/4/6/8/10 vCore | 2~160GB | Max Network Bandwidth | 10Gbps |
| Virtual Server | Standard | 12/14/16 vCore | 24~256GB | Max Network Bandwidth | 12.5Gbps |
| Virtual Server | High Capacity | 24/32/48/64/72/96/128 vCore | 48~1,536GB | Max Network Bandwidth | 25Gbps |
| GPU Server | A100(80G) | 16/32/64/128 vCore | 240~1,920GB | GPU | 1~8 |
| GPU Server | H100(80G) | 12/24/48/96 vCore | 240~1,920GB | GPU | 1~8 |
| Bare Metal Sever(3thGen) | 16/32/64/96/128 vCore | 64~2,048GB | Physical CPU | 8~64 |
※ 아래 사이트를 방문하면 최신 서버 타입을 확인할 수 있습니다.
Virtual Server : https://cloud.samsungsds.com/serviceportal/services/compute/virtualServer.html
GPU Server : https://cloud.samsungsds.com/serviceportal/services/compute/gpuServer.html
Bare Metal Server : https://cloud.samsungsds.com/serviceportal/services/compute/baremetal.html
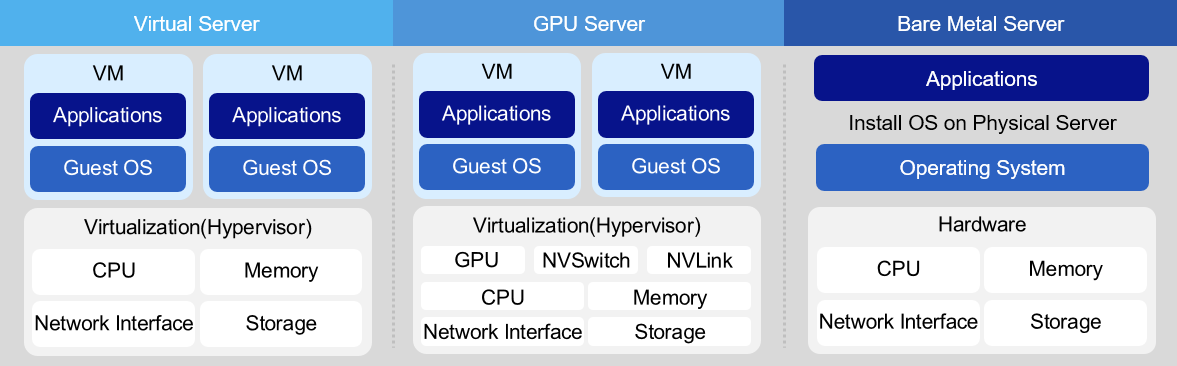
Virtual Server
Virtual Server는 16vCore 이하의 Standard(s1) 타입과 24vCore 이상의 High Capacity(h2) 타입이 제공됩니다. Standard 타입은 Intel Ice Lake CPU를 사용하며, 1vCore/2GB가 최소 사양입니다.
2vCore부터 16vCore까지는 1:2, 1:4, 1:8, 1:16 비율의 CPU:Memory 조합으로 제공됩니다.
High Capacity 타입은 Intel Sapphire Rapids CPU를 사용하며, 24vCore부터 128vCore까지 1:2, 1:4, 1:8, 1:12 비율의 CPU:Memory 조합으로 제공됩니다.
운영 체제는 RHEL, Ubuntu, Alma, Rocky, Oracle Linux 및 Windows Server를 제공하며, Kubernetes 이미지, Data Service Console 이미지 등을 구성할 수 있습니다.
Virtual Server는 개발, 테스트, Application 실행 등 사용자의 컴퓨팅 활용 목적에 따라 다양한 용도로 활용할 수 있습니다.Bare Metal Server
Bare Metal Server는 가상화 기술을 사용하지 않고, 물리적으로 분리된 CPU, 메모리 등의 컴퓨팅 자원을 단독으로 할당받아 사용하는 고성능 클라우드 컴퓨팅 서비스입니다.
현재 Intel Sapphire Rapids를 사용하는 3세대 서비스가 제공되고 있습니다.
제공되는 서버 타입의 CPU:Memory 조합은 1:4, 1:8, 1:16으로 제공됩니다.
기본 제공되는 OS용 Internal Disk는 16 vCore는 480GB2개, 32 vCore는 960GB2개, 96/128 vCore는 1.92TB*2개입니다.
Bare Metal Server는 실시간(Real-Time) 시스템, HPC(High Performance Computing), 과도한 I/O 사용이 요구되는 서버 등 고용량, 고성능을 요구하는 워크로드에 적합합니다.
또한, Multi-Attach 기능을 활용하여 Active-Active 고가용성이 필요한 데이터베이스를 구성하는 데 활용할 수 있습니다.
서버 사이징
워크로드에 적합한 컴퓨팅 서비스를 선택한 후에는, 가용성과 성능 요구 사항에 따라 서버의 사양과 수량을 결정해야 합니다.
온프레미스 환경에서는 서버 사양과 수량을 정하는 과정이 매우 중요했지만, 클라우드 환경에서는 언제든지 변경 가능한 유연한 작업이 될 수 있습니다.
초기 설정한 사양과 실제 필요한 사양 사이에 차이가 있더라도 추후에 조정 가능하기 때문입니다.
그럼에도 불구하고 서버 사이징이 중요한 이유는 클라우드에서 워크로드 운영 비용(월 사용료)을 산정하고, 이를 기반으로 온프레미스 구축 대비 TCO(Total Cost of Ownership)를 도출해야 하기 때문입니다.
정보시스템 하드웨어 규모를 산정하기 위해 다음의 3가지 방법론을 고려할 수 있습니다.
| 구분 | 개념 | 장점 | 단점 |
|---|---|---|---|
| 수식 계산법 | 사용자 수 등 규모 산정을 위한 요소를 토대로 용량 수치를 계산하고, 보정치를 적용하는 방법 | 규모 산정의 근거를 명확하게 제시할 수 있으며, 다른 방법에 비해 간단하게 산정할 수 있음 | 보정치가 잘못되었을 경우 원하는 값과 많은 차이가 발생하며, 보정치에 대한 정확한 근거 자료 제시가 어려움 |
| 참조법 | 업무량(사용자 수, DB 크기)에 따라, 기본 데이터를 토대로 대략적인 시스템 규모를 비교하여 비슷한 규모를 산정 | 기존 구축되어 있는 업무 시스템과 비교가 가능하므로 비교적 안전한 규모 산정 가능 | 계산에 의한 방법이 아닌 비교에 의한 것이므로 근거 제시 미약 |
| 시뮬레이션법 | 대상 업무에 대한 워크로드를 모델링하고 이를 시뮬레이션하여 규모를 산정 | 상대적으로 정확한 값을 얻을 수 있음 | 시간과 비용이 많이 소요 |
수식 계산법과 참조법은 여러 지표를 추출하여 클라우드 상에 구축하는 서버의 자원 사용량을 추정합니다.
일반적으로 클라우드의 용량 산정은 시뮬레이션법이나 운영을 통해 조정함으로써 용량 균형점을 찾습니다.
하지만, 사용 요금 예산 수립이나 제안 등의 이유로 사이징이 필요한 경우가 많습니다.
수식 계산법은 여러 지표를 이용하여 서버의 용량을 산정하기 때문에 객관적인 용량 설계 기준을 제공할 수 있습니다.
수식 계산법에 의한 Web/WAS CPU 사이징
우선 수식 계산법을 통해 Web/WAS 서버의 CPU 용량을 산정합니다.
| 산정 항목 | 산정 근거 | 적용범위 | 일반값 |
|---|---|---|---|
| 동시 사용자 수 | 소프트웨어나 시스템을 네트워크상에서 동시에 사용하는 사용자 | - | 산정값 |
| 사용자별 오퍼레이션 수 | 사용자 한 사람이 초당 발생시키는 비즈니스 로직 오퍼레이션 수 | 3 ~ 6 | 5 |
| 기본 OPS보정 | 실험 환경에서 측정한 OPS(Operation Per Second) 수치를 복잡한 실제 환경에 맞게 적용하기 위한 보정치 (기본 OPS 보정은 3 적용) | - | 3 |
| 업무용도 보정 | 적용 대상 시스템 유형에 따른 보정치 (0.7: 웹서버, 2: WAS서버) | - | Web: 0.7 WAS: 2 |
| 인터페이스 부하 보정 | 서버 간에 통신하게 될 때 인터페이스에서 발생하는 부하를 고려한 보정치 (일반 값으로 1.1 적용) | 1.1 ~ 1.2 | 1.1 |
| 피크타임 부하 보정 | 갑자기 많은 접속으로 인해 부하가 발생하는 것을 해결하기 위한 보정치 | 1.2 ~ 1.5 | 1.3 |
| 연계 부하 보정 | 타 시스템과의 연계로부터 발생하는 작업부하를 고려한 보정 | 1 ~ 1.3 | 1 |
| 클러스터 보정 | 클러스터 환경에서 장애 발생 시를 대비한 보정치 (Node 수에 따른 적용) | 2Node : 1.4~1.5 3Node : 1.3 | 2Node : 1.4~1.5 3Node : 1.3 |
| 시스템 여유율 | 시스템의 안정된 운영을 위한 보정 ※ 예기치 못한 업무의 증가 등을 고려한 추가적인 여유 정도 | 1.3 | - |
| 시스템 목표 활용률 | 시스템의 안정적인 운영을 전제로 한 최대 CPU활용 목표 | 0.7 | - |
| 단위 보정 | 산정결과를 max-OPS 단위로 변환하기 위한 환산치 | 24~31 | - |
| 산정식 | CPU(max-jOPS) = (동시 사용자 수 * 사용자당 오퍼레이션 수 * 기본 OPS보정 * 업무용도 보정 * 인터페이스 부하 보정 * 피크타임 부하 보정 * 연계 부하 보정 * 클러스터 보정 * 시스템 여유율) / (시스템 목표 활용률 * 단위보정) | ||
| 코어 산정 | 산정 jOPS / 기준 코어당 성능 jOPS * 기준 코어당 성능 jOPS는 하드웨어마다 1,000 ~ 3,000으로 편차를 보인다. 만약 위의 계산에 의해 jOPS가 5,000이고, 기준 코어당 성능 jOPS가 1,500이라면 산정 코어는 5,000/1,500= 약 3.3코어이며, Virtual Server 서버 타입을 선정할 때 4코어를 선택합니다. |
- 동시 사용자 수
동시 사용자는 네트워크상에서 소프트웨어나 시스템을 동시에 사용하는 사용자를 의미하며, 일반적으로 세션(업무 서비스 요청부터 서비스 종료까지)을 기준으로 정의합니다.
일반적으로 기존에 운영 중인 웹 시스템은 동시 사용자 수의 산정은 운영 자료를 바탕으로 비교적 쉽게 구할 수 있습니다.
반면, 신규 시스템은 동시 사용자 수를 추정을 통해 도출해야 합니다.
먼저, 시스템의 전체 사용자 수를 산정합니다.
전체 사용자 수는 보통 시스템에 등록된 총 사용자를 의미하는데, 일반적으로 접속 권한을 가진 사용자를 말합니다. 그러나 웹의 경우, 불특정 다수가 접속할 수 있어 추정이 필요합니다.
그 다음, 전체 사용자 수에서 일정 비율의 접속 사용자 수를 구합니다.
접속 사용자는 온라인에 접속되어 있는 사용자로, 트랜잭션이나 오퍼레이션을 발생시킬 수도 있고 접속만 하고 있을 수도 있습니다.
마지막으로, 이 접속 사용자 수에 일정 비율을 곱해 동시 사용자 수를 추정할 수 있습니다.
3계층 웹 Application에서는 Web 서버, WAS 서버, DB 서버의 사용자 수가 밀접한 연관성을 갖습니다.
WAS 서버의 동시 접속 사용자 수는 Web 서버의 동시 접속 사용자 수보다 많지 않을 것이며, DB 서버의 동시 접속 사용자 수는 WAS 서버의 동시 접속 사용자 수보다 많지 않을 것입니다.
이러한 연관 관계를 고려하여 각 계층의 동시 접속 사용자 수를 추정할 수 있습니다.
아래 표는 일반적인 정보시스템에서의 동시 접속 사용자 수의 추정치를 나타냅니다.
| 구분 | 개념 | |
|---|---|---|
| Web 서버 | 대외용 서비스 | 전체 사용자 수의 1% ~ 10% 정도를 접속 사용자 수로 산정하고, 접속 사용자 수의 5% ~ 30%를 동시 사용자 수로 산정 |
| Web 서버 | 대내용 서비스 | 전체 사용자 수의 30% ~ 50% 정도를 접속 사용자 수로 산정하고, 접속 사용자 수의 40% ~ 70%를 동시 사용자 수로 산정 |
| WAS 서버 | 산정된 Web 서버 동시 사용자 수의 50% ~ 100%의 범위에서 산정하며, 일반 값으로 75% 수준 | |
| DB 서버 | 산정된 WAS의 동시 사용자 수의 50% ~ 100%의 범위에서 산정하며, 일반 값으로 75% 수준 |
- 사용자별 오퍼레이션 수
사용자당 오퍼레이션 수는 한 사용자가 초당 발생시키는 비즈니스 로직 오퍼레이션(Business logic operation) 수로서, 업무 유형에 따라 다음과 같이 3개 ~ 6개 정도로 가정합니다.
| 적용 값 | 설명 |
|---|---|
| 3 | 웹 서비스 위주 업무(복잡한 응용 로직이 아닌 조회 위주의 업무를 의미함) |
| 4 | 웹 서비스와 응용 로직 혼합되어 있으나 웹 서비스 위주 업무 |
| 5 | 웹 서비스와 응용 로직 |
| 6 | 응용 로직 위주의 업무 |
기본 OPS 보정
SPEC(Standard Performance Evaluation Corporation)에서 제공하는 OPS 수치는 최적의 환경에서 측정된 것으로, 실제 운영 환경과는 차이가 있습니다.
따라서 실험 환경에서 측정한 OPS 수치를 복잡한 실제 환경에 맞게 적용하기 위한 보정을 해야 하는데, 이를 기본 OPS 보정이라고 합니다.
기본 OPS 보정은 고정값으로 3을 적용합니다.업무 용도 보정
Web 서버와 WAS 서버의 업무 부하에는 상대적인 차이가 있습니다.
이러한 차이를 고려하여, 시스템 유형에 따라 다른 보정치를 적용하는데, 이를 업무 용도 보정이라고 합니다.
업무 용도 보정은 산정 대상이 Web 서버인지 또는 WAS 서버인지에 따라 다르게 적용됩니다.
Web 서버인 경우 0.7의 보정치를 적용하고, WAS 서버인 경우에는 2의 보정치를 적용합니다.
| 적용 값 | 설명 |
|---|---|
| 0.7 | Web 서버 |
| 2 | WAS |
- 피크 타임 부하 보정
업무의 효율성을 높이고 정확하고 즉각적인 결과를 얻기 위해서는 업무가 가장 집중되는 피크 타임에 시스템이 안정적으로 운영되어야 합니다.
따라서 시스템 규모를 산정할 때는 피크 타임을 기준으로 해야 합니다.
일반적으로 시스템은 평상시에 비해 피크 타임에 약 20%~50% 정도 더 많은 부하를 받게 됩니다.
이를 고려하여 산정된 용량에 1.2~1.5배의 가중치를 적용하여 시스템 용량을 조정합니다.
| 구분 | 적용 값 | 설명 |
|---|---|---|
| 상 | 1.5 | 특정 시간이나 특정일에 매우 과도한 부하가 걸리는 경우 |
| 중 | 1.4 | 특정한 마감일에 과도한 부하가 걸리는 경우 |
| 하 | 1.3 | 특정 시간대에 매일 혹은 매주 피크타임이 있는 경우 |
| 기타 | 1.2 | 피크타임이 존재하나 부하 차이가 존재하지 않는 경우 |
- 클러스터 보정
클러스터 보정은 2대의 시스템이 하나의 클러스터(One-to-one 형태)로 구성될 때 적용됩니다.
하나의 서버에 장애가 발생하면 Application이 수행해야 하는 부하를 남아있는 서버가 모두 감당해야 합니다.
이 경우 시스템의 예비율이 없으면 과부하로 정상적인 운영이 어렵게 되므로 추가적인 예비율을 두어야 합니다.
이러한 예비율은 클러스터의 구성 형태에 따라 달라집니다.
Active-Active 구조에서는 각 상대 시스템의 100%를 예비율로 두어야 하지만, 이는 비경제적이고 비효율적이므로 1.3 ~ 1.5의 값을 적용합니다.
값의 적용은 Node 수에 따라 달라지며, 2-Node 구성에는 1.4 ~ 1.5, 3-Node 구성에는 1.3을 적용합니다.
Active-Standby 구조에서는 실제 서비스는 한 장비에서 운용하고 다른 한 대는 장애 대비용 시스템으로 사용합니다.
만약 장애 발생 시, 해당 장비의 기능 전체가 대기 중인 다른 장비로 이전되어, 대기 중인 장비에서 기능이 수행되는 구조입니다.
이러한 Active-Standby 구조에서는 별도의 클러스터 보정치를 적용하지 않아도 됩니다.
| 클러스터링 | Node | 적용 값 |
|---|---|---|
| Active-Active | 2-Node | 1.4 ~ 1.5 |
| Active-Active | 3-Node | 1.3 |
| Active-Standby | Active-Standby | 1 |
- 연계 부하 보정
동시 사용자 수에 의해 발생하는 부하가 아닌 타 시스템과의 연계로부터 발생하는 작업 부하를 고려한 보정치입니다. 일반적으로 시스템 간 연계는 Web 서버가 아닌 WAS 서버에 연계되므로, 이를 고려하여 Web 서버에는 보정치를 1로 적용합니다.
반면, WAS 서버에는 연계 트랜잭션의 빈도나 처리 복잡도에 따라 다음과 같이 별도의 보정 계수를 적용할 수 있습니다.
| 구분 | 적용 값 | 설명 |
|---|---|---|
| Web서버 | 1 | Web서버의 경우 |
| WAS | 1 | WAS 전체 업무 중 연계 업무가 없는 경우 (0%) |
| WAS | 1.1 | WAS 전체 업무 중 연계 업무가 단순 조회 업무만 있는 경우 (전체 부하의 10%) |
| WAS | 1.2 | WAS 전체 업무 중 연계 업무가 대내 갱신 업무만 있는 경우 (전체 부하의 20%) |
| WAS | 1.3 | WAS 전체 업무 중 연계 업무가 대내/대외 갱신 업무가 있는 경우 (전체 부하의 30%) |
시스템 여유율
시스템 여유율은 예기치 못한 업무 증가나 비정상 트래픽 상황에서도 안정적인 운영을 위한 보정치입니다.
구축형 시스템은 일반적으로 30%의 추가적인 여유율, 즉 보정치 1.3을 적용합니다.시스템 목표 활용률
일반적으로 정보시스템은 시스템 목표 활용률 100%를 기준으로 설계되지만, 시스템의 안정적인 운영을 위하여 실제 활용률은 100%에 도달하지 않도록 운영합니다.
이처럼 시스템의 안정적인 운영을 위한 CPU의 최대 활용률을 시스템 목표 활용률이라고 하며, 일반적으로 최대 70%(계수 0.7)를 적용합니다.단위 보정
단위 보정은 서버의 형태에 따라 적용하는 보정치입니다.
Composite 형태의 max-jOPS를 적용하는 경우, X86 서버는 29, Unix 서버는 31, 그리고 일반값은 30을 적용할 수 있습니다.
MultiJVM 형태의 max-jOPS를 적용하는 경우, X86 서버는 24, Unix 서버는 26, 일반값은 25를 적용할 수 있습니다.
| 구분 | 적용 값 | 설명 |
|---|---|---|
| Composite SPECjbb2015 | 29 | X86 서버 |
| Composite SPECjbb2015 | 30 | 서버 형태 미정(일반값) |
| Composite SPECjbb2015 | 31 | Unix 서버 |
| MultiJVM SPECjbb2015 | 24 | X86 서버 |
| MultiJVM SPECjbb2015 | 25 | 서버 형태 미정(일반값) |
| MultiJVM SPECjbb2015 | 26 | Unix 서버 |
수식 계산법에 의한 DB 서버 CPU 사이징
이제 수식 계산법에 의해 DB 서버의 CPU 용량을 산정합니다.
Web/WAS 서버와는 달리 DB 서버는 분당 트랜잭션 수를 기반으로 tpmC를 도출하여 산출합니다.
| 산정 항목 | 산정 근거 | 적용 | 산정 항목 |
|---|---|---|---|
| 분당 트랜잭션 수 | 산정 대상 서버에서의 분당 트랜잭션 발생 추정치의 합 | - | 업무 수: 2 업무당 트랜잭션 수: 4~6개 |
| 기본 tpmC 보정 | 실험 환경에서 측정한 tpmC 수치를 복잡한 실제 환경에 맞게 적용하기 위한 보정치 | - | 5 |
| 피크타임 부하 보정 | 업무가 과중한 시간대에 시스템이 원활하게 운영될 수 있도록 피크타임을 고려한 보정치 | 1.2 ~1.5 | 1.3 |
| 데이터베이스 크기 보정 | 데이터베이스 테이블의 레코드 건수와 전체 데이터베이스 볼륨을 고려한 보정치 | 1.5 ~ 2.0 | 1.7 |
| Application 구조 보정 | Application의 구조와 요구되는 응답 시간에 따른 성능 차이를 고려한 보정치 | 1.1 ~ 1.5 | 1.2 |
| Application 부하 보정 | 온라인 작업을 수행하는 피크타임에 배치 작업 등이 동시에 이루어지는 경우를 고려한 보정치 | 1.3 ~ 2.2 | 1.7 |
| 연계 부하 보정 | 타 시스템과의 연계로부터 발생하는 작업부하를 고려한 보정치 | 1 ~ 1.2 | 1 |
| 클러스터 보정 | 클러스터 환경에서 장애 발생 시를 대비한 보정치 | 2 Node : 1.4~1.5 3 Node : 1.3 | 2 Node : 1.4~1.5 3 Node : 1.3 |
| 시스템 여유율 | 예기치 못한 업무의 증가 등을 고려한 추가적인 여유 정도 | 1.3 | - |
| 시스템 목표 활용률 | 시스템의 안정적인 운영을 전제로 한 최대 CPU활용 목표 | 0.7 | |
| 산정식 | CPU(tpmC 단위) = (분당 트랜잭션 수 * 기본 tpmC 보정 * 피크타임 부하 보정 * DB 크기 보정 * Application 구조 보정 * Application 부하 보정 * 연계 부하 보정 * 클러스터 보정 * 시스템 여유율) / 시스템 목표 활용률 | ||
| 코어 산정 | 산정 tpmC / 기준 코어당 성능 tpmC * 기준 코어당 성능 tpmC는 하드웨어마다 70,000에서 400,000까지 편차를 보입니다. 만약 위의 계산에 의해 tpmC가 800,000이고, 기준 코어당 성능 tpmC가 190,000이라면 산정 코어는 700,000/190,000= 약 3.7코어이며, 서버 타입을 선정할 때 4코어를 선택합니다. |
분당 트랜잭션 수
클라이언트/서버 환경에서는 일반적으로 트랜잭션 단위로 업무가 발생합니다.
따라서 OLTP(Online Transaction Processing) 환경에서는 Application당 발생하는 트랜잭션 수를 추정하는 것이 시스템 규모 산정의 핵심 기준이 됩니다.
분당 트랜잭션 수를 구하는 방법에는 기존 시스템의 트랜잭션 조사, 동시 사용자 수 기반 추정, 클라이언트 수 기반 추정의 세 가지 방식이 있습니다.기존 시스템의 트랜잭션 조사
운영 중인 시스템에 대한 트랜잭션을 연간 또는 월간 단위로 조사하고 이를 분당 트랜잭션으로 변환하여 활용하는 방식입니다.
일반적으로 기존 시스템은 이미 Application 사용에 대한 연간 및 월간 트랜잭션 데이터를 보유하고 있으므로, 이 데이터를 기반으로 트랜잭션 발생 일수와 시간을 고려하여 산정을 시작하는 것이 효과적입니다.
이때, 트랜잭션이 한 달 동안 매일 발생하는지, 혹은 주말을 제외한 약 20일 동안만 발생하는지, 하루 중 8시간 동안 또는 24시간 발생하는지 등 발생 패턴에 대한 분석도 함께 수행되어야 합니다.동시 사용자 수 이용
신규 시스템 도입과 같이 기존에 조사된 트랜잭션이 존재하지 않는 경우, 동시 사용자 수 기반 추정 방식을 사용합니다.
즉, 시스템에 대한 예상치와 향후 개발될 Application에 대한 구체적인 내용을 산정하기 어려운 경우에 해당합니다.
이 방법을 적용하기 위해 먼저 총 사용자 수를 예상하여 동시 사용자 수를 산정합니다.
이후 예상되는 업무 유형과 특성을 고려하여 동시 사용자 한 명이 분당 발생시킬 것으로 예상되는 트랜잭션 수를 추정합니다.
이 값은 “업무 수 × 업무당 트랜잭션 수”로 계산하며, 최종적으로 분당 트랜잭션 수 = 동시 사용자 수 × 사용자당 트랜잭션 수로 산출할 수 있습니다.클라이언트 수 이용
클라이언트 수만 확보되어 있는 경우에 사용할 수 있는 방법입니다.
이 경우, 클라이언트가 어떤 방식으로 서버에 접속하고 작업을 요청하는지를 고려해야 하나, 이 내용은 이후 보정 단계에서 반영합니다. 기본적으로는 모든 클라이언트가 동일한 LAN 상에 존재한다고 가정합니다.
그리고 클라이언트의 수에서 동시 사용되는 클라이언트의 수를 추정한 후, 이를 기반으로 앞서 설명한 동시 사용자 수 이용 방식에 따라 분당 트랜잭션 수를 산정합니다.기본 tpmC 보정
TPC에서 제공하는 tpmC 수치는 최적의 환경에서 측정하는 것으로 실제 운영 환경과 차이가 있습니다.
따라서 실험 환경에서 측정한 tpmC 수치를 복잡한 실제 환경에 맞게 적용하기 위한 보정을 해야 하는데, 이를 기본 tpmC 보정이라고 합니다.
기본 tpmC 보정값은 고정값 5를 적용합니다.피크 타임 부하 보정
업무의 효율성을 높이고 정확하고 즉각적인 결과를 얻기 위해서는 업무가 가장 집중되는 피크 타임에 시스템이 안정적으로 운영되어야 합니다.
따라서 시스템 규모를 산정할 때는 피크 타임을 기준으로 해야 합니다.
일반적으로 시스템은 평상시에 비해 피크 타임에 약 20%~50% 정도 더 많은 부하를 받게 됩니다.
이를 고려하여 1.2에서 1.5의 가중치를 적용하여 시스템 용량을 조정합니다.
| 구분 | 적용값 | 설명 |
|---|---|---|
| 상 | 1.5 | 특정 시간이나 특정일에 매우 과도한 부하가 걸리는 경우 |
| 중 | 1.4 | 특정한 마감일에 과도한 부하가 걸리는 경우 |
| 하 | 1.3 | 특정 시간대에 매일 혹은 매주 피크타임이 있는 경우 |
| 기타 | 1.2 | 피크타임이 존재하나 부하 차이가 존재하지 않는 경우 |
- 데이터베이스 크기 보정
데이터베이스 크기에 따른 보정치는 DB에 속한 가장 큰 테이블의 레코드 건수와 전체 DB의 볼륨을 고려하여 결정합니다.
같은 크기의 DB인 경우에는 건수가 많은 쪽이, 같은 건수라면 DB의 볼륨이 큰 쪽이 큰 가중치를 갖게 됩니다.
그러나 실제 업무 시스템에 대한 세부적인 분석을 근거로 정확한 값이 도출되지 않을 경우 가중치의 적용이 어려우므로 일반값인 1.7을 적용합니다.
| 레코드 건수 \ DB 크기 | ~ 8 | ~ 32 | ~ 128 | ~ 256 | 256 이상 |
|---|---|---|---|---|---|
| 50Gbyte 미만 | 1.50 | 1.55 | 1.60 | 1.65 | 1.70 |
| 500Gbyte 미만 | 1.60 | 1.65 | 1.70 | 1.75 | 1.80 |
| 1Tbyte 미만 | 1.70 | 1.75 | 1.80 | 1.85 | 1.90 |
| 2Tbyte 미만 | 1.80 | 1.85 | 1.90 | 1.95 | 1.95 |
| 2Tbyte 이상 | 1.85 | 1.90 | 1.90 | 1.95 | 2.00 |
- Application 구조 보정
Application 구조 보정은 Application 응답 시간에 따른 성능 차이를 감안한 보정치입니다.
응답 시간은 서버의 응답 시간을 의미하는 것이 아니라 사용자의 서비스 응답 시간을 말합니다.
적용 값은 아래 표와 같으며, 5초 이상인 경우 적용하지 않습니다.
| 응답 시간 | 1초 | 2초 | 3초 | 4초 |
|---|---|---|---|---|
| 적용 값 | 1.50 | 1.35 | 1.20 | 1.10 |
- Application 부하 보정
Application 부하 보정은 온라인 작업을 수행하는 피크타임에 배치 작업 등이 동시에 이루어지는 경우를 감안하여 고려한 보정치입니다.
정해진 온라인 업무 외에 부가적인 작업이 처리되는 경우(리포팅이나 백업 등과 같은 배치성 업무나 외부 시스템을 사용하는 경우) 그에 필요한 처리 능력을 보정하여야 합니다.
따라서 이러한 Application 부하 보정은 배치 업무의 발생 비중에 따라 적용됩니다.
아래 표와 같이 배치성 작업 등 추가 작업이 많은 경우에는 최대치인 2.2, 온라인 트랜잭션 외에 배치성 작업 등 추가 작업이 없는 경우에는 최소치인 1.3까지 적용할 수 있으며, 일반값으로 1.7을 적용할 수 있습니다.
| 구분 | 적용값 | 설명 |
|---|---|---|
| 상 | 1.9 ~ 2.2 | 배치성 작업 등 추가 작업이 많이 이루어지는 경우 |
| 중 | 1.6 ~ 1.8 | 온라인 트랜잭션에 일부 배치 작업이 이루어지는 경우 |
| 하 | 1.3 ~ 1.5 | 온라인 트랜잭션 외에 배치성 작업 등 추가 작업이 없는 경우 |
- 연계 부하 보정
동시 사용자 수에 의해 발생하는 것이 아니라 타 시스템과의 연계로부터 발생하는 작업부하를 고려한 보정치입니다.
DB서버는 연계 작업 부하의 트랜잭션 등의 수준에 따라 달리 적용할 수 있습니다.
| 적용값 | 설명 |
|---|---|
| 1 | DB서버 전체 업무 중 연계 업무가 없는 경우(미반영) |
| 1.1 | DB서버 연계 업무가 단순 조회 및 데이터 갱신 연계인 경우(전체 부하의 10%) |
| 1.2 | DB서버 연계 업무가 대용량 조회 및 데이터 갱신 연계인 경우(전체 부하의 20%) |
- 클러스터 보정
클러스터 보정은 2대의 시스템이 하나의 클러스터(One-to-one 형태)로 구성될 때 적용됩니다.
하나의 서버에 장애가 발생하면 Application이 수행해야 하는 부하를 남아있는 서버가 모두 감당해야 합니다.
이 경우 시스템의 예비율이 없으면 과부하로 정상적인 운영이 어렵게 되므로 추가적인 예비율을 두어야 합니다.
이러한 예비율은 클러스터의 구성 형태에 따라 달라집니다.
Active-Active 구조에서는 각 상대 시스템의 100%를 예비율로 두어야 하지만, 이는 비경제적이고 비효율적이므로 1.3 ~ 1.5의 값을 적용합니다.
값의 적용은 Node 수에 따라 달라지며, 2-Node 구성에는 1.4 ~ 1.5, 3-Node 구성에는 1.3을 적용합니다.
Active-Standby 구조에서는 실제 서비스는 한 장비에서 운용하고 다른 한 대는 장애 대비용 시스템으로 사용합니다.
만약 장애 발생 시, 해당 장비의 기능 전체가 대기 중인 다른 장비로 이전되어, 대기 중인 장비에서 기능이 수행되는 구조입니다.
이러한 Active-Standby 구조에서는 별도의 클러스터 보정치를 적용하지 않아도 됩니다.
| 클러스터링-Node | 적용 값 |
|---|---|
| Active-Active - 2 Node | 1.3 ~ 1.5 |
| Active-Active - 3 Node | 1.3 |
| Active-Standby | 1 |
시스템 여유율
시스템 여유율은 예기치 못한 업무 증가나 비정상 트래픽 상황에서도 안정적인 운영을 위한 보정치입니다.
구축형 시스템은 일반적으로 30%의 추가적인 여유율, 즉 보정치 1.3을 적용합니다.시스템 목표 활용률
일반적으로 정보시스템은 시스템 목표 활용률 100%를 기준으로 설계되지만, 시스템의 안정적인 운영을 위하여 실제 활용률은 100%에 도달하지 않도록 운영합니다.
이처럼 시스템의 안정적인 운영을 위한 CPU의 최대 활용률을 시스템 목표 활용률이라고 하며, 일반적으로 최대 70%(계수 0.7)를 적용합니다.
참조법을 통한 CPU 사이징
다음은 참조법을 이용한 CPU 사이징입니다.
참조법은 기존에 구축되어 있는 업무 시스템의 자원을 기준으로 구축하려는 시스템의 용량을 산정하는 것입니다.
참조법으로 용량을 산정하기 위한 방식은 아래 표와 같습니다.
| 산정 항목 | 내용 | 적용 범위 | 일반값 |
|---|---|---|---|
| 기존 CPU Core 수 | 기존 정보시스템의 대상 서버 코어 수(CPU * CPU당 코어 수) | - | 산정값 |
| 계층 구성 | 기존 CPU Core 수 대비 계층 보정치 적용 | 0.5~3.0 | |
| 이중화 구성 | 이중화 구성 보정치 적용 | 0.7~2.0 | |
| 서버 형태 | 기존 x86서버에(물리/가상화) 따라 보정치 적용 - 물리: 보정치 1.2 적용(가상화 Overhead 고려) - 가상화: 보정치 미적용 | ||
| CPU 평균 사용률 | 기존 정보시스템의 평균 CPU 사용률(50%일 경우 0.5 적용) | 1%~100% | - |
| CPU 여유 사용률 | 시스템의 안정된 운영을 위한 보정치 | 1.3 | - |
| 산정식 | 용량 산정치 = 기존 CPU Core 수 * 계층 구성 보정치 * 이중화 구성 보정치 * 서버 형태 보정치 * CPU 평균 사용률 * 여유 사용률 보정치 | ||
| 코어 산정 | 기존 CPU 수(4) * 계층 구성 변경 없음(1) * A-A 이중화 구성(0.7) * 서버 형태 물리 → 가상(1.2) * CPU 평균 사용률 30%(0.3) * 여유 사용률 30%(1.3) = 약 1.3 코어 * 서버 타입을 고려하여 2 코어를 산정합니다. |
기존 CPU Core 수
기존 정보시스템 서버에서 사용하고 있는 CPU Core를 기준으로 산정합니다.
이 참조법은 CPU 자체의 성능은 고려하지 않고, CPU 개수와 CPU당 Core 수를 기준으로 산정합니다.계층 구성
기존 서버의 계층 구성이 변경될 경우 서버 부하 분산을 고려하여 보정치를 계산합니다.
계층이 증가하거나 감소할 때 보정치를 각각 산정합니다.
| 계층 변경 | 적용값 | 내용 |
|---|---|---|
| 1→2,2→3 | 0.7 | (Web/WAS/DB)→(Web),(WAS/DB) 또는 (Web/WAS),(DB) (Web),(WAS/DB) 또는 (Web/WAS),(DB)→(Web),(WAS),(DB) |
| 1→3 | 0.5 | (Web/WAS/DB)→(Web),(WAS),(DB) |
| 2→1,3→2 | 2.0 | (Web),(WAS/DB) 또는 (Web/WAS),(DB)→(Web/WAS/DB) (Web),(WAS),(DB)→(Web),(WAS/DB) 또는 (Web/WAS),(DB) |
| 3→1 | 3.0 | (Web),(WAS),(DB)→(Web/WAS/DB) |
- 이중화 구성
기존 서버의 계층 구성이 변경될 경우 서버 부하 분산을 고려하여 보정치를 계산합니다.
계층이 증가하거나 감소할 때 보정치를 각각 산정합니다.
| 계층 변경 | 적용값 | 내용 |
|---|---|---|
| 1→2 | 0.7 | Active–Active 이중화 구성 보정치 |
| 1→2 | 1.0 | Active–Standby 이중화 구성 보정치: 보정 없음 |
| 2→1 | 2.0 | Active–Active 이중화 구성에서 단일 구성으로 변경 |
- 서버 형태
기존 정보시스템 서버가 물리 서버일 경우와 가상 서버일 경우를 고려하여 보정치를 적용합니다.
물리 서버에서 클라우드로 전환할 경우 가상화의 오버헤드를 고려하여 보정치를 적용합니다.
| 기존서버 | 적용값 | 내용 |
|---|---|---|
| 물리서버 | 1.2 | 클라우드의 가상화에 따른 물리-가상화 전환 보정치를 적용 |
| 가상서버 | 1.0 | 가상화–가상화 전환이므로 보정치 적용 없음 |
CPU 평균 사용률
기존 정보시스템 서버의 평균 CPU 사용률을 고려하여 기존 서버의 컴퓨팅 사용량을 측정합니다.CPU 여유 사용률
새로운 서버를 구성할 때 목표 CPU 사용률을 고려한 보정치를 적용합니다.
예를 들어, 목표 평균 CPU 사용률이 70%인 경우, 30%의 여유를 고려하여 보정치 1.3을 적용합니다.
수식 계산법에 의한 서버 메모리 사이징
수식 계산법에 의한 메모리의 규모 산정 방법은 CPU에 비해 훨씬 간단합니다.
구축하는 시스템 별로 프로그래밍 언어나 스레드(thread)를 사용하는 등의 다양한 방법에 의해 메모리 점유를 줄이기 위한 전략을 사용합니다.
이러한 전략에 따라 규모 산정 방법에는 조금씩 차이가 있으며, 시스템에서 구동되는 프로세스의 수와 그 프로세스가 사용하는 메모리 양이 메모리 산정에 큰 영향을 미칩니다.
그러나 본 지침에서는 프로그래밍 언어나 스레드 사용, 특정 시스템에 대한 메모리 구성 특성의 반영 등을 고려하지 않고 일반적인 시스템의 용도와 구조를 바탕으로 하여 메모리 규모를 산정합니다.
| 산정 항목 | 산정 근거 | 적용 범위 | 일반값 |
|---|---|---|---|
| 시스템 영역 | OS, DBMS 엔진, 미들웨어 엔진, 기타 유틸리티 등의 소요 공간 | - | 산정값 |
| 사용자당 필요 메모리 | Application, 미들웨어, DBMS의 사용에 필요한 사용자당 메모리 | 1MB~3MB | 2MB |
| 동시 사용자 수 | 소프트웨어나 시스템을 네트워크상에서 동시에 사용하는 사용자 | - | 산정값 |
| OS 버퍼 캐시 보정 | 처리 속도를 향상시키기 위해 일정량의 데이터를 임시로 모아 놓은 기억 장소를 위한 보정치 | 1.1~1.3 | 1.15 |
| Application 필요 메모리 | DBMS의 공유메모리, WAS의 heap size 등 미들웨어에서 사용하는 캐시 영역 | - | 산정값 |
| 시스템 여유율 | 시스템의 안정된 운영을 위한 보정치 | 1.3 | - |
| 산정식 | 메모리(MB단위) = {시스템 영역 + (사용자당 필요 메모리 * 사용자 수) + Application 필요 메모리} * 버퍼 캐시 보정 * 시스템 여유율 | ||
| 메모리 산정 예시 | {시스템 영역 256MB + (사용자당 필요 메모리 64KB * 사용자 수 3,000) + Application 필요 메모리 300MB} * 버퍼 캐시 보정 1.15 * 시스템 여유율 30% (1.3) * 위 수식의 결과는 991.54MB입니다. 서버 타입에 따라 메모리를 산정할 수 있습니다. |
시스템 영역
시스템 영역은 운영 중인 소프트웨어(운영체제, 네트워크 데몬(Daemon), 데이터베이스 엔진, 미들웨어, 유틸리티 등)의 실행에 필요한 메모리 공간을 의미하며, 각 소프트웨어가 구동 시 요구하는 메모리를 기준으로 산정합니다.
특히, 이 영역은 데이터베이스 등과 같이 해당 소프트웨어의 라이선스 수에 따라 달리 적용되어야 하며, 일반적으로 각각의 소프트웨어 제조사가 권고하는 필요 메모리를 반영하여 산정합니다.사용자당 필요 메모리
사용자당 필요 메모리는 Application, 미들웨어, DBMS 등의 사용에 따라 사용자 당 요구되는 메모리 용량을 의미합니다.
이 값은 다양한 요소를 고려하여 산정됩니다.
예를 들어, Application의 구현 방식, 미들웨어 적용 방식, 사용자 프로세스의 입출력 구조, DBMS 벤더의 아키텍처 등에 따라 사용자당 요구 메모리는 달라질 수 있습니다.
그러나 계산이 불가능한 경우 1MB ~ 3MB 사이의 값을 임의로 적용할 수 있습니다.동시 사용자 수
동시 사용자는 네트워크 상에서 소프트웨어 또는 시스템을 동시에 사용하는 사용자를 의미합니다.
메모리 측면에서의 동시 사용자 수는 별도로 산정하지 않고, 이전 단계에서 산정한 CPU 기준 동시 사용자 수 추정값을 동일하게 적용합니다.OS 버퍼 캐시 보정
컴퓨터는 처리 속도 향상을 위해 일정량의 데이터를 모아 한꺼번에 처리하는데, 이 때 데이터를 모아놓은 기억장소를 버퍼 캐시(buffer cache)라고 합니다.
이를 고려한 보정치를 OS 버퍼 캐시 보정이라 합니다.
OS 버퍼 캐시 보정은 1.1 ~ 1.3의 값을 적용할 수 있으며, 일반값으로는 1.15를 적용합니다.Application 필요 메모리
Application 필요 메모리는 DBMS의 공유 메모리, WAS의 힙 크기(Heap Size) 등 미들웨어에서 사용하는 캐시 영역을 말합니다.
이 메모리의 크기는 DBMS, WAS 등 각 미들웨어의 요구에 따라 결정됩니다.시스템 여유율
예기치 못한 업무의 증가에 따른 시스템의 안정된 운영을 위한 보정치입니다. 구축형 시스템의 경우에는 일반적으로 30%의 추가적인 여유(보정치 1.3)을 고려합니다.
Container 적용 검토
컨테이너는 Application 현대화를 위한 가장 널리 사용되는 도구 중 하나입니다.
Application과 런타임을 컨테이너로 패키징하면, 모든 운영체제 플랫폼에 배포할 수 있으며, 플랫폼 독립적인 기능을 제공함으로써 소프트웨어 개발, 테스트, 배포 프로세스를 단순화하고 자동화를 용이하게 합니다.
컨테이너는 복잡한 멀티 티어(Multi-tier) Application을 구축하는 데 효과적입니다.
예를 들어, Application 서버, 데이터베이스, 메시지 큐를 함께 실행해야 하는 경우, 각각을 별도의 컨테이너 이미지로 병렬 실행하고 이들 간의 통신을 설정할 수 있습니다.
각 계층에서 라이브러리 버전이 다르더라도 컨테이너를 통해 충돌 없이 동일한 컴퓨팅 서버에서 실행이 가능합니다.
Kubernetes는 운영 환경에서 다수의 컨테이너를 효율적으로 관리하고 제어할 수 있는 플랫폼입니다.
Kubernetes는 수평적 확장 기능과 중단 시간을 최소화하는 블루-그린 배포 기능을 제공합니다.
또한 사용자 트래픽 부하를 컨테이너 간에 분산시키고, 다양한 컨테이너에서 공유하는 저장소를 관리할 수 있습니다.
GPU 적용 검토
GPU Server는 프로젝트의 용도 및 규모 등에 따라 GPU 카드 타입과 수량을 선택하여 가상 서버를 구성할 수 있으며, Pass-through 방식을 사용하여 물리 서버 수준의 고성능 GPU 서버를 제공합니다.
제공하는 NVIDIA GPU의 사양은 아래와 같으며, 운영체제는 RHEL, Ubuntu가 제공됩니다.
| 구분 | V100 Type | A100 Type | H100 SXM |
|---|---|---|---|
| 서비스 제공 방식 | Pass-through | Pass-through | Pass-through |
| GPU 성능 | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| · GPU Memory | 32GB | 80GB | 80GB |
| · Transistors | 21.1 billion 12nm TSMC | 54 billion 7nm TSMC | 80 billion 4N TSMC |
| · Tensor 성능(FP16기준) | 125 TFLOPs | 312 TFLOPs | 1,979 TFLOPs |
| · Memory Bandwidth | 900 GB/sec | 2,000 GB/sec | 3.35 TB/sec HBM3 |
| · CUDA Cores | 5,120 Cores | 6,912 Cores | 16,896 Cores |
| · Tensor Cores | 640 (1st Generation) | 1,024 (3세대) | 528 (4세대) |
| NVLink 성능 | NVLink 2 | NVLink 3 | NVLink 4 |
| · 총 NVLink 대역폭 | 300 GB/s | 600 GB/s | 900 GB/s |
| · Signaling Rate | 25 Gbps | 50 Gbps | 25 Gbps (x18) |
| NVSwitch 성능 | - | NVSwitch 2 | NVSwitch 3 |
| · NVSwitch GPU간 대역폭 | - | 600 GB/s | 900 GB/s |
| · 총 집계 대역폭 | - | 9.6 TB/s | 7.2TB/s |
| 연계 스토리지 | Block Storage - SSD | Block Storage - SSD | Block Storage - SSD |
Nvidia V100, A100, H100을 장착한 GPU Server는 가상화 컴퓨팅 자원 위에 1/2/4/8개의 GPU와 NVSwitch 및 NVLink가 장착된 서버 타입으로 제공됩니다.
제공되는 서버 타입의 CPU:Memory 조합은 V100의 경우 1:8, A100의 경우 1:15, H100의 경우 1:20으로 제공됩니다.
GPU Server는 AI모델 실험, 예측, 추론 등 빠른 연산 속도를 필요로 하는 업무에 적합하며, 업무 유형 및 규모에 따라 최적화된 성능의 자원을 유연하게 선택하여 이용할 수 있습니다.