평가 및 개선
평가 및 개선
지속적 개선을 위한 프로세스 정의
지속적인 개선을 위한 프로세스를 만들 때 우선적으로 정의해야 할 사항은 역할입니다.
구성원들 중 누가 권한을 갖고 필요한 작업을 수행할지 지정하고, 개선 흐름에 대한 가시성을 확보하는 것이 필요합니다.
다음 그림은 개선 프로세스에 대한 DevOps Pipeline의 예시입니다.
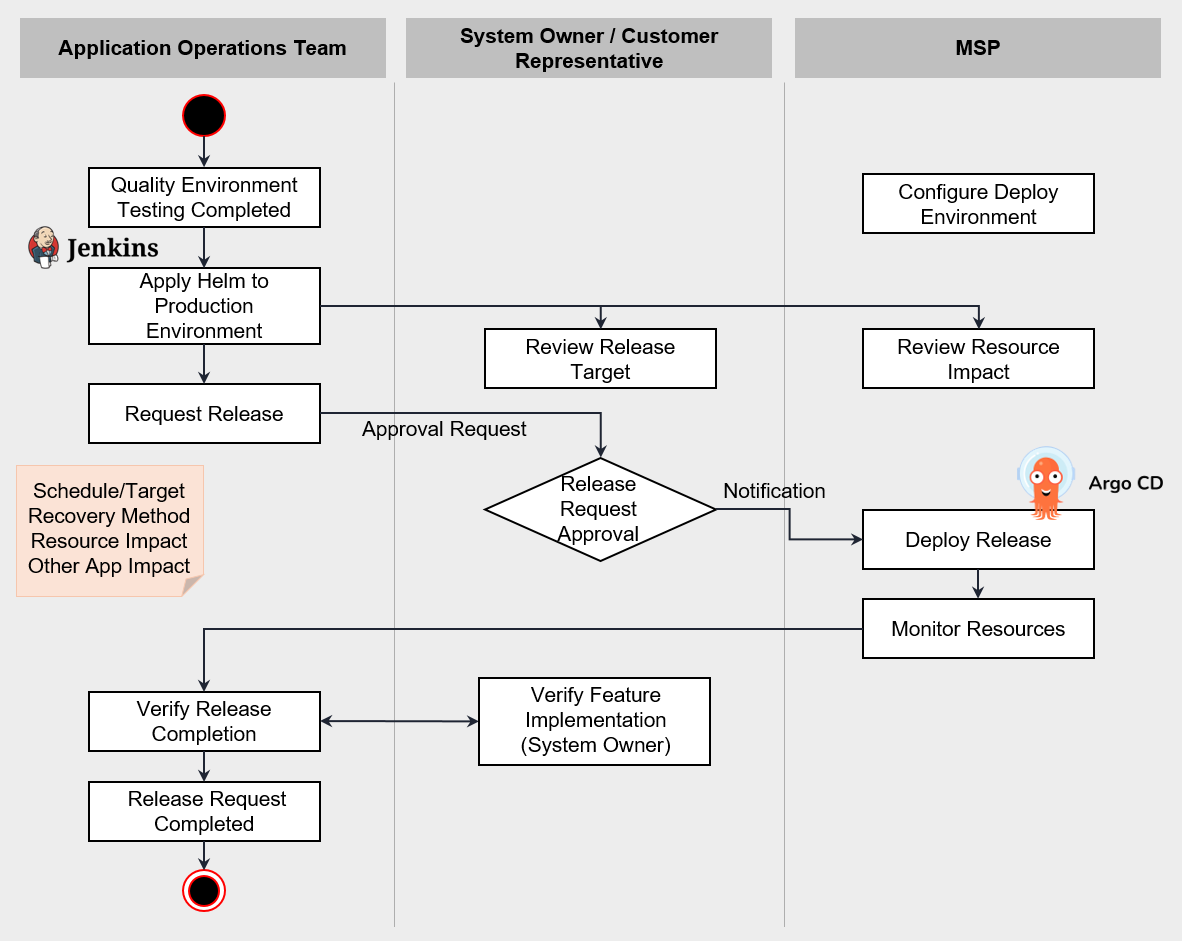
각 단계에서 수행할 작업은 아래와 같습니다.
| 단계 | 설명 |
|---|---|
| 프로젝트 생성/사용자 추가 | Samsung Cloud Platform에서 DevOps 프로젝트를 생성하고 사용자를 추가합니다. |
| 역할 정의 | 사용자 중 업무에 따른 담당자를 지정하고, 권한을 부여합니다. |
| 변경 사항 Commit | 신규 또는 개선된 인프라 구성 템플릿이나 Application 코드를 코드 Repository에 Commit합니다. |
| 변경 사항 빌드 및 테스트 | 테스트 환경에서 변경된 코드를 빌드하고 배포하여 테스트합니다. 앞서 오류 또는 개선 사항에서 제시된 환경을 고려하여 필요한 테스트 환경을 재현하여 테스트를 수행합니다. |
| 운영 환경으로 코드 배포 | 테스트 완료된 Application 및 인프라 구성을 Staging을 거쳐 운영 환경에 배포합니다. |
| 모니터링 | 오류, 개선 사항 단계에서 도출된 개선 사항을 모니터링 지표에 반영합니다. 측정 지표에 대한 성능을 모니터링합니다. |
| 오류, 개선 사항 | 모니터링 과정에서 도출된 오류 및 개선 사항을 정리합니다. |
위와 같이 지속적 개선을 위한 프로세스를 구성할 때는 아래 표와 같은 작업 요소를 고려해야 합니다.
| 개선 작업 요소 | 설명 |
|---|---|
| 단계 수 | CI/CD의 경우에는 개발, 통합, 시스템, 사용자 수용, 프로덕션이 포함될 수 있습니다. 일부 조직에는 개발, 알파, 베타, 릴리스 단계도 포함합니다. |
| 각 단계의 테스트 유형 | 각 단계는 프로덕션 단계에서 단위 테스트, 통합 테스트, 시스템 테스트, UAT, 스모크 테스트, 부하 테스트, A/B 테스트와 같은 다양한 유형의 테스트를 수행할 수 있습니다. |
| 테스트 순서 | 테스트 케이스는 병렬로 실행하거나 순서대로 실행합니다. |
| 모니터링과 레포팅 | 시스템 결함과 장애를 모니터링하고 장애가 발생하면 알림을 전송합니다. |
| 인프라 프로비저닝 | 각 단계에 대한 인프라 프로비저닝 방법을 정의합니다. |
| 롤백 | 필요한 경우 이전 버전으로 되돌아가는 롤백 전략을 정의합니다. |
이벤트 사후 분석 수행
시스템 운영 중 장애가 발생하면 실수로부터 교훈을 얻고 문제를 식별해야 합니다.
동일한 장애가 재발하지 않게 해야 하며, 만약 장애가 반복될 경우를 대비해 해결책을 준비해야 합니다.
개선 방안 중 하나는 RCA(Root Cause Analysis)라고 하는 근본 원인 분석을 실행하는 것인데, 문제가 발생한 근본 원인을 분석하고 문제의 재발을 방지하는 데 도움을 줍니다.
RCA는 다음의 5 단계 질문을 통해 문제 분석을 수행합니다.
| 단계 | 질문 |
|---|---|
| 1단계 문제 정의 | - 무슨 일이 발생했는가? - 구체적인 증상은 무엇인가? |
| 2단계 데이터 수집 | - 문제가 있다는 것을 증명할 증거는 무엇인가? - 얼마나 오랫동안 문제가 있어왔는가? - 그 문제의 영향은 무엇인가? |
| 3단계 원인 요소 탐색 | - 어떤 사건들이 문제로 발전했는가? - 어떤 조건 속에서 문제가 발생했는가? - 핵심적 문제 주변에 어떤 다른 문제들이 있나? |
| 4단계 근본 원인 탐색 | - 왜 원인 요소들이 존재하나? - 무엇이 그 문제를 일으키는 진짜 원인인가? |
| 5단계 해결책 제안 및 실행 | - 그 문제가 다시 발생하지 않으려면 무엇을 해야 하나? - 어떻게 해결책을 실행할 수 있나? - 누가 그에 대한 책임이 있나? - 해결책 실행에 따르는 위험은 무엇인가? |
지식 관리 수행
설명서는 외부 또는 내부 이벤트로 발생한 문제를 해결하기 위한 작업 실행 방법을 제공합니다. 간혹 운영팀이 문서 업데이트를 미루어 오래된 설명서를 방치하는 경우가 종종 있습니다.
문서의 내용이 부족할 경우, 사람에게 의존해 작업이 이뤄지기 때문에 실수로 인한 위험성이 높아지므로, 시스템 운영은 항상 사람과 구분하여 유지하고, 모든 부분을 문서화하는 프로세스를 갖춰야 합니다.
신규 팀원이 기존의 장애 사례와 해결 방법을 참고해 유사한 문제를 신속히 해결할 수 있게 하려면, 시스템 변경 시 설명서가 자동으로 업데이트되도록 스크립트를 통해 문서 자동화가 필요합니다.
설명서에는 복구 목표 시간/복구 목표 시점(RTO/RPO), 지연 시간, 확장성 성능 등과 관련해 정의된 서비스 수준 협약(SLA)이 포함되어야 합니다.
시스템 관리자는 시스템 시작, 중지, 패치, 업데이트 단계가 포함된 설명서를 유지 관리하고, 운영팀은 이벤트 대응 절차와 함께 시스템 테스트와 검증 결과를 설명서에 포함해야 합니다.
운영팀은 시스템에 변경 사항을 적용하고 빌드한 후에 문서에 주석을 추가하는 프로세스를 자동화하는 것이 바람직하며, 이 경우 주석을 사용해 작업을 자동화할 수 있고, 코드로 쉽게 읽을 수 있습니다.
비즈니스 우선순위와 고객 요구 사항은 계속 변경되고 시간이 지남에 따라 진화하기 때문에 이를 지원하도록 운영 환경을 유지하는 것은 운영의 핵심 성공 요소입니다.