가용성 관리
가용성 관리
가용성 점검 및 테스트
가용성 시나리오 테스트
온프레미스에서는 작은 규모의 테스트 환경을 구성하여 테스트를 수행하지만, 클라우드에서는 실제 배포되는 프로덕션 규모의 테스트 환경을 구성하여 테스트를 수행할 수 있습니다.
사용자에게 영향을 주지 않고 별도 환경에서 테스트를 진행함으로써 서비스나 데이터의 손상 없이 정상적으로 서비스가 작동하는지 확인할 수 있습니다.
- 테스트 시나리오를 구성하여 단위 기능 테스트와 통합 테스트를 수행합니다.
- 문서화된 서비스 수준 목표(Service Level Object, SLO), 서비스 수준 계약(Service Level Agreeement, SLA) 등에 따라 측정 지표를 점검하고 목표에 따라 서비스가 가동하는지 측정합니다.
- 부하 테스트 시행 시 자원 조정을 통해 요구 부하량을 처리하는지 확인합니다.
- 병목 지점을 확인하고 개선을 수행합니다.
지금부터 가용성 목표에 따라 아키텍처 설계와 테스트를 점검해보겠습니다.
다음은 Samsung Cloud Platform의 주요 서비스별 가용성 현황입니다.
| 서비스 | 최대 월 가용률 | 정지 시간 |
|---|---|---|
| Virtual Server (단일) | 99.9% | 43.8분 |
| Virtual Server(이중화) | 99.99% | 4.3분 |
| Database(HA) | 99.95% | 21.9분 |
| Load Balancer | 99.95% | 21.9분 |
가용성 목표가 월 가용률 99%일 경우, 월 730시간 기준으로 평균 복구 시간(Mean Time To Repair, MTTR)은 43.8분입니다.
이러한 가용성 목표를 달성하기 위한 3계층 아키텍처는 다음과 같습니다.
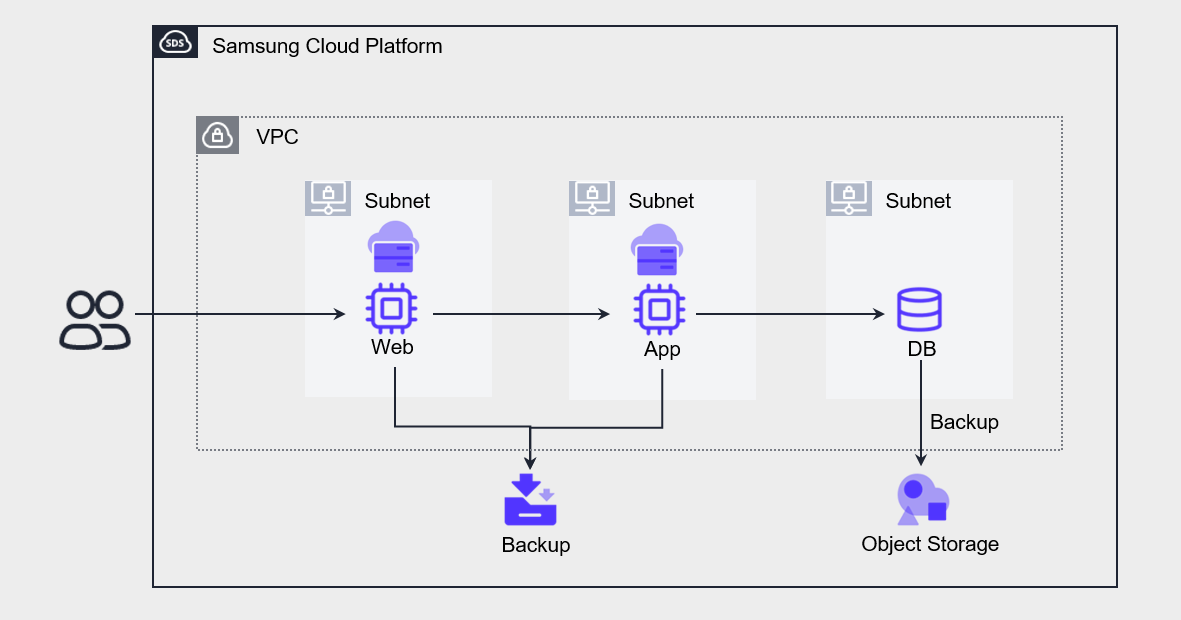
Web, App, DB 모두 단일 구성이며, VM은 Backup으로 사본을 저장하고, DB는 Database 서비스에서 제공하는 백업 기능으로 사본을 저장합니다.
각 구성 요소에 장애가 발생했을 때 허용되는 서비스 중단 시간은 SLA 기준으로 44분입니다.
가용성 테스트를 수행하는 단계는 아래와 같이 구성할 수 있습니다.
| 항목 | 테스트 항목 | 예상 시간 |
|---|---|---|
| 장애 탐지 테스트 | Cloud Monitoring Event 알림 설정 | 관리자 분석/대응시간 |
| 장애 대응 테스트 | Backup에서 Virtual Server복원 Public IP 전환 | 최대 20분 |
| 복원력 테스트 | 신규 Database 생성 Backup에서 Database 복구 백업 이후 장애시점까지 데이터 변경 분 반영 | 최대 60분 |
| 부하 테스트 | Virtual Server 서버 타입 변경 Database 서버 타입 변경 | 작업 당 최대 15분 |
장애 발생 후 단계별 복구를 수행했을 때, 복구 예상 시간은 최대 90분으로 예상됩니다.
복구 작업을 Console이 아닌 CLI 스크립트를 준비하여 진행하고, 테스트 환경을 통한 데이터 작업을 수행할 경우, 작업 시간은 더욱 단축될 수 있습니다.
그러나 전체 복구 프로세스에서 가장 불확실한 구간은 장애 발생부터 이를 탐지하고 관리자에게 통지하여 실제로 복구 작업을 개시하기까지의 시간입니다.
이 시간을 얼마나 단축할 수 있는지는 테스트 과정에서 검토해야 할 사항입니다.
다음은 월 가용률 99.9%를 목표로 한 아키텍처로, 월 730시간 기준으로 MTTR(평균 복구 시간)은 약 44분입니다.
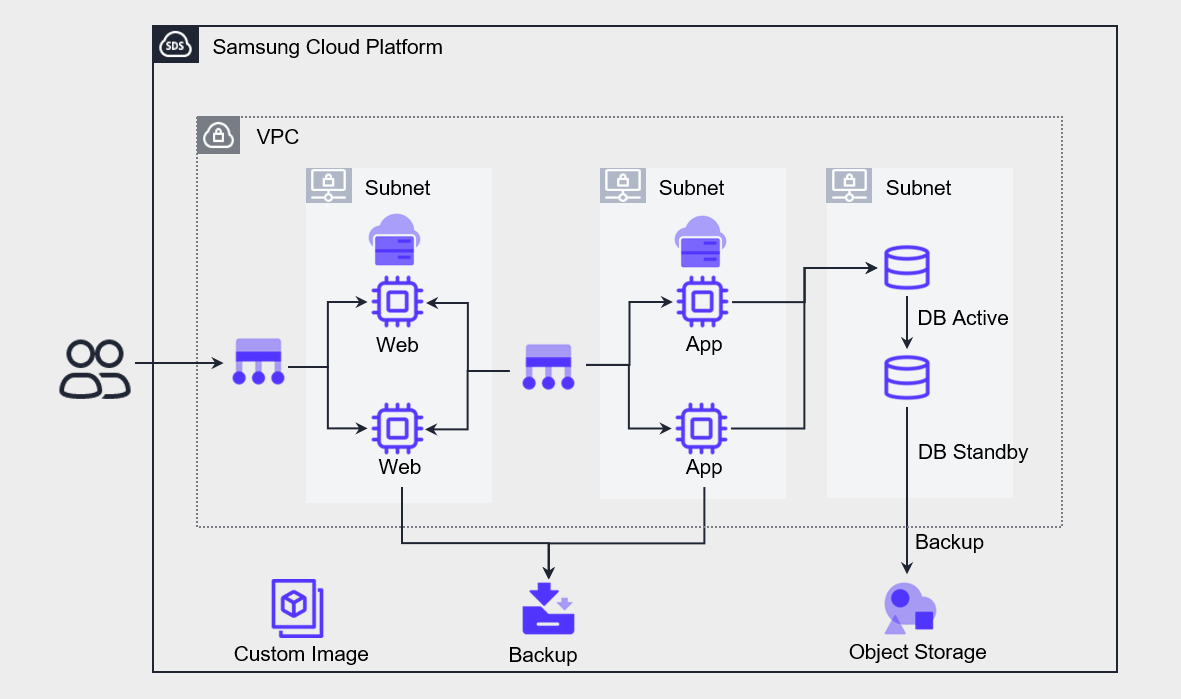
Web, App, DB 모두 고가용성을 위해 이중화 구성되어 있습니다.
Web과 App의 전방에는 Load Balancer를 구현하여 이중화된 서버에 요청을 분산 처리합니다.
DB는 Database 서비스를 고가용성으로 배포하여 Active-Standby로 구성되었습니다.
이중화된 각 구성 요소의 최대 가용률은 서비스 가용률인 99.9% 이내입니다.
가용성 테스트를 수행하는 단계는 아래의 표와 같이 구성할 수 있습니다.
| 항목 | 테스트 항목 | 예상 시간 |
|---|---|---|
| Virtual Server 장애 탐지 및 조치 테스트 | Load Balancer Health Check 장애 탐지 및 전환 | 30초 (기본 설정) |
| Database 장애 탐지 및 조치 테스트 | Active DB 정지 후 Standby DB로 전환 | 수초 ~ 수분 |
| 복원력 테스트 | Backup에서 Virtual Server복원 신규 Database 생성 Backup에서 Database 복구 백업 이후 장애시점까지 데이터 변경 분 반영 | 최대 60분 |
| 부하 테스트 | Custom Image로 새로운 VM 생성 후 Load Balancer에 등록 Database 서버 타입 변경 | 작업 당 최대 15분 |
각 단계별로 이중화된 서버 중 하나를 정지하고 Fail-over가 이뤄지는지 점검하는 테스트를 수행합니다.
Web과 App에 각각 구성된 Load Balancer는 전방의 요청을 각 VM에 전달함과 동시에 Health Check를 수행합니다.
Health Check를 구성할 때 체크 주기, 대기 시간, 탐지 횟수를 지정할 수 있습니다.
기본값으로는 주기 5초, 대기시간 5초, 탐지 횟수 3회로 설정되어 있으며, 장애를 감지하고 Fail-over를 수행하는데, 30초 [(주기 5초 + 대기시간 5초) * 탐지 횟수 3회]가 소요됩니다.
사용자는 항목별로 값을 수정할 수 있는데, 1~2, 147, 483, 647초의 값을 설정할 수 있으며, 만약 최소 값으로 설정할 경우 장애 탐지 시간을 6초까지 줄일 수 있습니다.
앞의 시나리오와는 달리 Fail-over가 자동화 조치로 전환되기 때문에 단순 장애가 발생할 경우 가용률 범위 안에서 서비스를 재개할 수 있습니다.
단, VM이나 데이터베이스가 손실된 경우에는 여전히 데이터를 복구하는 시간이 소요됩니다.
그리고 부하 테스트를 진행할 때는 Image로부터 신규 VM을 생성하여 Load Balancer의 서버 그룹에 직접 등록해야 합니다.
Database의 경우는 서버 타입을 변경하여 부하에 대응합니다.
다음은 월 가용률 99.99%를 목표로 한 아키텍처로, 월 730시간 기준으로 MTTR은 약 4분입니다.
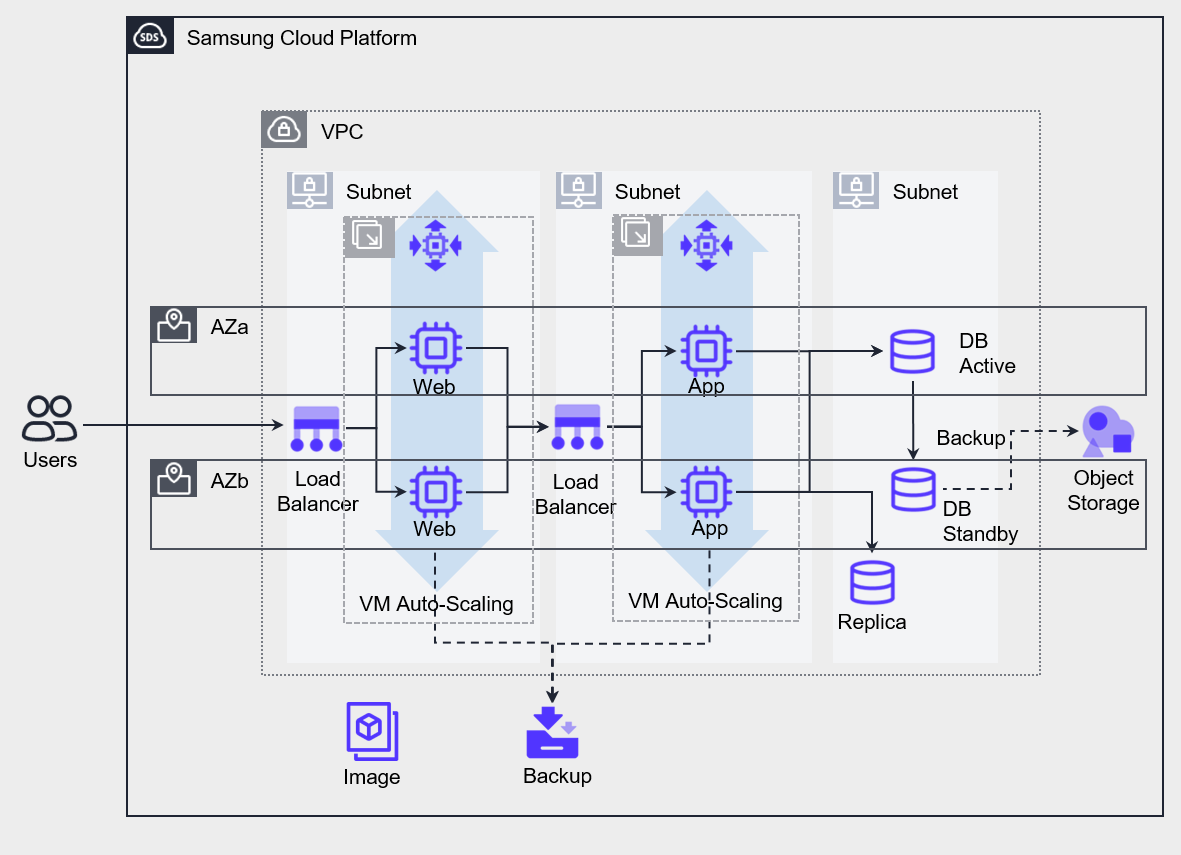
VPC와 각 서비스를 Multi-AZ 기반에 구현하였습니다.
Web과 App의 VM은 지표 기반 Auto-Scaling을 기반으로 배포하였고, Database 읽기 작업 부하 오프로드를 위해 Replica를 추가하여 서버를 구성했습니다.
Multi-AZ에 배포한 각 구성요소의 가용률은 서비스가 요구하는 수준인 월 가용률 99.99%를 충족하도록 설계되었습니다.
가용성 테스트를 수행하는 단계는 아래의 표와 같이 구성할 수 있습니다.
| 항목 | 테스트 항목 | 예상 시간 |
|---|---|---|
| Virtual Server 장애 탐지 및 조치 테스트 | Load Balancer Health Check 장애 탐지 및 전환 | 30초 (기본 설정) |
| Database 장애 탐지 및 조치 테스트 | Active DB 정지 후 Standby DB로 전환 | 수초 ~ 수분 |
| 복원력 테스트 | Backup에서 Virtual Server복원 신규 Database 생성 Backup에서 Database 복구 백업 이후 장애시점까지 데이터 변경 분 반영 | 최대 60분 |
| 부하 테스트 | Auto-Scaling 신규 서버 생성 Database 서버 타입 변경 데이터베이스 읽기 부하에 따라 Replica추가 생성 | 최대 5분 |
앞선 시나리오와 달라진 점은 Multi-AZ에 자원을 배포하고, 부하의 증감에 따라 서버를 자동으로 수평 확장/축소할 수 있는 Auto-Scaling을 구현한 점입니다.
각 이중화 구성 요소 중 하나를 정지하여 전환 테스트를 하고, 단계별로 부하를 증가시키며 서버 생성 속도와 부하 증가 속도를 비교합니다.
부하 증가 속도가 서버 생성 속도보다 빠를 경우, Scale-out 정책의 임계치를 낮추어 더 이른 시점에 확장되도록 하고, 생성 서버 수를 증가시키는 조정 작업을 수행합니다.
데이터베이스의 읽기 부하는 사전에 Replica에서 수행하도록 구성합니다.
부하 테스트 시에 단계별로 데이터베이스 지연 속도를 측정하고, 테스트 사후에 적절한 용량으로 서버 타입을 조정합니다.
정기적 검토 시행
Planned Maintenance
구성 요소에 대해 업데이트하거나 보안 패치를 수행하는 정기 점검(Maintenance) 기간 동안 구성 요소 및 서비스 흐름을 테스트합니다.
구성 요소 변경에 대한 테스트를 수행하고, 전체적인 서비스의 흐름 상 새로운 병목 현상이 발생하는지 여부를 점검합니다.Unplanned Failure
예기치 않은 서비스 중단이 발생한 경우, 장애 발생을 확인한 후 복구 가능 시간을 판단하여 사전에 정해놓은 우선순위에 따라 복구를 진행해야 합니다.
그 다음 서비스 중단의 근본 원인을 확인하고 이를 해결합니다.
원인 분석이 완료되면, 근본 원인과 해결 방안, 그리고 재발 방지를 위한 사전 조치를 문서화합니다.
문제 해결을 위해 장시간 서비스를 정지해야 하는 경우, 계획된 정기 점검 기간에 맞춰 조치를 수행하고, 정기 점검 전까지 사전에 준비한 비상 조치 방안을 수행합니다.
아울러 해결 조치를 수행하기 위한 로그를 수집합니다.
문제 해결 후에는 단위 기능 및 통합 테스트를 수행하여 전체 가용성을 유지하도록 합니다.
모니터링 및 알림
모니터링 및 로그 수집
모든 구성 요소로부터 핵심적인 지표를 선정하고 수집한 후, 분석 결과를 알림과 연계함으로써 워크로드 안정성과 최적의 사용자 경험을 보장합니다.
가용성 요구사항에 부합하는 지표에 따라 실시간 모니터링을 수행하고, 시계열 로그를 수집하여 분석한 결과를 알림과 연동함으로써 장애를 사전에 감지하고 이에 대비합니다.
모든 계층의 구성 요소에 대해 모니터링하며, 필요 시 주요 지표를 정의하고 로그 데이터를 기반으로 해당 지표를 추출하도록 합니다.
- 가용성을 유지하기 위한 지표 및 목표를 설정합니다.
- 가능한 모든 서비스에 모니터링을 활성화하고 대시보드를 구성합니다.
- 가능한 모든 서비스에 로깅을 활성화하고, 수집된 로그는 중앙 저장소에서 관리합니다.
가용성 목표에 미달하는 지표가 나타나면 필요한 조치를 수행합니다.
예를 들어, 특정 Virtual Server의 평균 CPU 사용률이 90%를 초과하는 경우, 해당 서버의 장애 발생 확률이 높아집니다.
단일 서버일 경우 용량을 증설한 서버로 대체하고, Load Balancer로 구성한 서버 군일 경우에는 새로운 서버를 추가하여 전체 부하를 낮춰야 합니다.
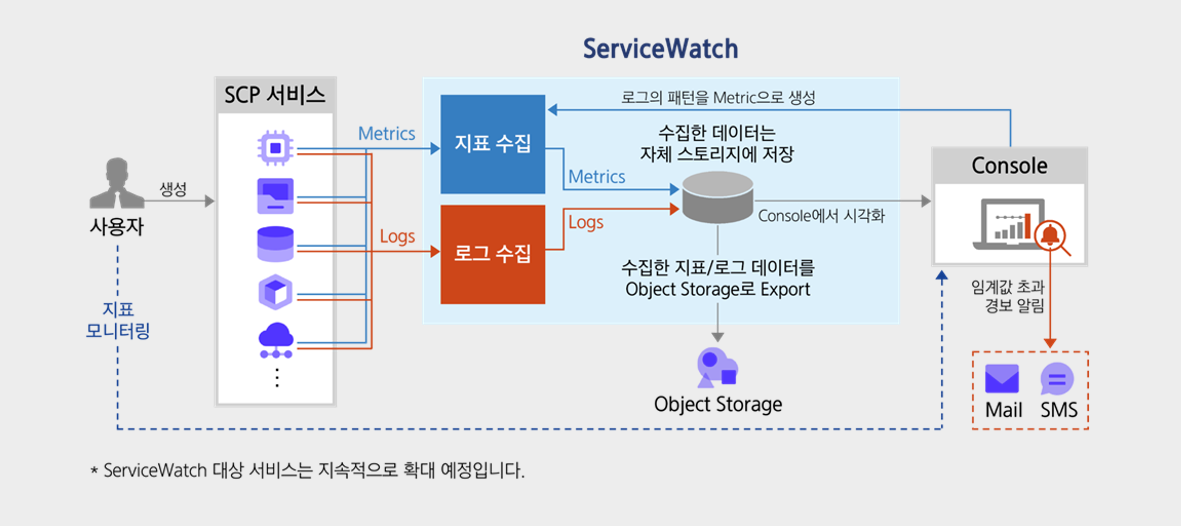
알림 및 응답 자동화
장애는 업무 중인 근무시간 뿐만 아니라 언제든지 발생할 수 있습니다.
지표가 가용성 목표를 만족하지 못하고 있음이 감지되면, 장애 상황임을 신속하게 알리고 복구를 수행할 수 있도록 합니다.
- 임계값에 지표가 도달하면 Event를 설정하여 자동으로 알림을 전송합니다.
- 각 Event에 해당하는 필요 조치를 사전에 준비하고, 알림을 수신한 즉시 조치를 수행합니다.
- 자동으로 구현할 수 있는 대응 조치를 구성하여 필요한 대응이 수행되도록 합니다.
Event의 위험도는 3가지로 나눌 수 있습니다.
| 위험도 | 설명 |
|---|---|
| Fatal | 가장 높은 수준의 위험도입니다. 일반적으로 매우 위험한 상황일 경우 이 수준으로 설정합니다. |
| Warning | 중간 단계의 위험도입니다. 일반적으로 시스템에 문제를 일으켜 해결이 필요한 상황일 경우, 이 수준으로 설정합니다. |
| Information | 가장 낮은 단계의 위험도입니다. 단순한 알림 수준의 정보도 포함하며, 일반적으로 참고 또는 확인이 필요한 상황일 경우, 이 수준으로 설정합니다. |