가용성 목표 수립
가용성 목표 수립
가용성이란 사용자가 일정한 기대를 가지고 IT 자원 또는 서비스를 이용하려 할 때, 그 기대에 부합하는 기능과 성능을 안정적으로 제공할 수 있는 능력을 의미합니다.
온프레미스 환경에서 IT 서비스를 설계하거나 구축할 때는 서비스의 가용성 요구사항을 검토한 후, 각 구성 요소의 장애 요인을 분석하여 단일 구성 또는 이중화/다중화 방안을 설계하고 구현합니다.
고가용성 구현 대상 식별
업무 중요도 평가
고가용성 구현 대상 업무를 식별하기 위해, 다음의 항목을 기준으로 업무 중요도를 평가합니다.
| 평가 항목 | 내 용 |
|---|---|
| 업무 영향도 | - 시스템 중단 시 예상 매출 손실 - 고객 이탈 또는 서비스 계약 위반에 따른 비용 |
| 고객 서비스 영향 | - 시스템 중단이 고객 경험에 미치는 영향 - 고객 불만 또는 클레임 발생 가능성 - 고객 서비스 중단 시 대체 서비스 제공 방안 |
| 규정 준수 | - 규정 준수 의무 사항 - 위반 시 법적 문제 발생 여부 |
업무 중요도를 평가하기 위해 업무 영향 분석을 활용하기도 합니다.
업무 영향 분석(Business Impact Analysis)은 안정성 설계 원칙에서 더 자세히 다룹니다.
고가용성 요구 사항 및 대응 방안
고가용성을 구현하기 위해서는 장애 발생 구성 요소 또는 원인에 따라 적절한 장애 조치 방안을 수립할 수 있어야 합니다.
아래 표는 장애 또는 재해 상황에 대한 고가용성 구현 요구사항과, 이를 클라우드 환경에서 어떻게 구현할 수 있는지에 대한 예시입니다.
| 구분 | 요구사항 예시 | 구현 방안 예시 |
|---|---|---|
| 클라우드 데이터센터 장애 또는 재해 | - 클라우드 서비스 제공자의 물리적 데이터센터 장애에도 서비스가 중단하지 않는 아키텍처를 설계합니다. | Multi-AZ 기반 중복 구성 |
| 클라우드 서비스 장애 | - 단일 서버(VM)의 장애 상황에서도 장애 극복(Fault Tolerance)할 수 있는 고가용성 아키텍처를 설계합니다. - 고가용성 데이터베이스 서버를 구성합니다. | Active-Active 또는 Active-Standby 고가용성 구현 |
| 수요량 급증 | - 변화하는 수요량에 대응하여 자원을 동적으로 조정하고, 탄력적으로 부하에 대응할 수 있는 클라우드 아키텍처를 설계합니다. - 사용자가 직접 부하 대응을 설계, 관리하지 않고, 내재적으로 부하 대응 기능을 제공하는 관리형 서비스를 사용합니다. | Auto-Scaling 또는 관리형 서비스 구현 |
| 공격/침해 | - DDoS 공격에도 서비스 정지를 최소화할 수 있는 아키텍처를 설계합니다. | DDoS Protection 구성 Auto-Scaling 구성 |
서비스 수준 지표 및 목표 수립
가용성을 설계할 때 모든 구성요소에 고가용성을 적용하려면 예산이나 운영 인력 등 여러 가지 제약이 따를 수 있습니다.
고객은 중요 시스템의 가용성 요구사항을 제시할 때, 일반적으로 “고가용성” 또는 “이중화” 수준을 요구합니다.
하지만, 이러한 고객 요구가 내포하는 의미는 단순히 구성 요소를 이중화하면 된다는 것에 그치는 것이 아니라, 단일 구성 요소에 장애가 발생하더라도 전체 서비스는 중단되지 않도록 구성해야 한다는 것입니다.
고가용성 요구사항을 분석할 때는 고객의 포괄적인 고가용성 요구를 체계적으로 관리할 수 있도록 객관적 지표를 도출하고, 이를 기반으로 목표를 설정하는 과정이 필요합니다.
이와 연관된 주요 관리 항목 및 지표는 아래 표에서 확인할 수 있습니다.
| 항 목 | 내 용 |
|---|---|
| SLA (Service Level Agreement, 서비스 수준 계약) | -서비스 제공자와 고객 간의 공식적인 계약으로, 제공되는 서비스의 기대 수준을 정의함 - SLA에는 가용성, 성능, 지원 응답 시간 등 구체적인 서비스 수준 목표가 포함됨 - 이 목표를 달성하지 못할 경우 서비스 제공자가 고객에게 보상해야 하는 조건도 명시됨 |
| SLO (Service Level Objective, 서비스 수준 목표) | -SLA 내에서 명시된 특정 서비스 수준 목표를 의미함 -SLO는 측정 가능한 목표로, 예를 들어 “서비스 가용성 99.9% 이상 유지"와 같은 형태로 표현됨 -SLO는 서비스 제공자가 준수해야 할 기준으로, SLA를 충족하기 위한 세부 목표임 |
| SLI (Service Level Indicator, 서비스 수준 지표) | -SLO를 측정하는 데 사용되는 구체적인 지표 -SLI는 서비스 성능이나 가용성을 수치로 표현하며, 예를 들어 “지난 30일 동안의 평균 응답 시간"과 같은 형태로 나타낼 수 있음 -SLI는 SLO 달성 여부를 평가하기 위해 필수적인 데이터를 제공함 |
| MTTD (Mean Time to Detection,평균 탐지 시간) | -고장 발생 시점과 수리 작업 시작 시점 사이의 평균 시간 |
| MTTR (Mean Time to Repair,평균 복구 시간) | -기기 또는 시스템의 장애가 발생한 시점부터 장애가 발생한 곳의 수리가 끝나 가동이 가능하게 된 시점까지의 평균 시간 - MTTR = (F1 + F2 …Fn)/n [F: 고장 중인 시간, n: 고장 횟수] |
| MTTF (Mean Time To Failure, 평균 고장 간격) | -수리 완료로부터 다음 고장까지 무고장으로 작동하는 시간의 평균값 -MTTF = (T1 + T2…Tn)/n [T: 가동 중인 시간, n: 고장 횟수] |
MTTD, MTTR, MTTF의 관계는 아래의 그림으로 이해할 수 있습니다.
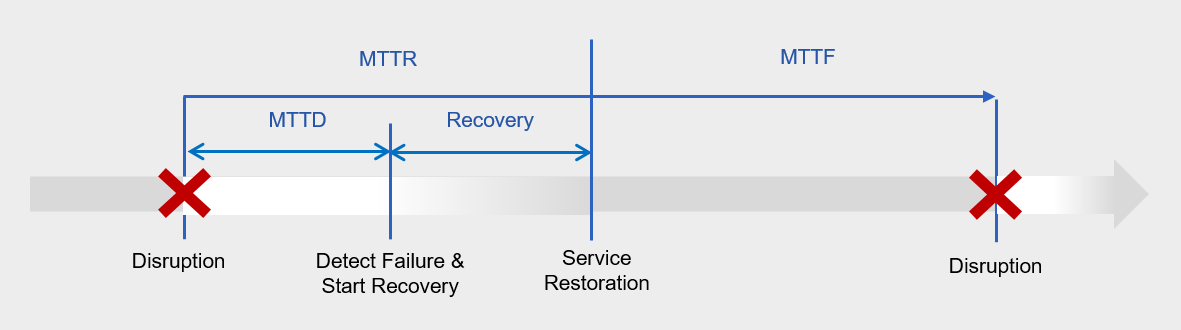
앞서 가용성의 지표인 가용률을 1 - {장애 시간(분) 합}/{서비스 이용 총 시간(분)의 합} 으로 표현하였습니다.
위의 지표를 통해 가용성을 표현한다면, MTTF/(MTTF + MTTR) 으로 표현할 수 있을 것입니다.
가용성을 높이기 위해서 MTTR, 즉 평균 복구 시간을 최소화하는 것이 핵심입니다.
MTTR은 MTTD와 복구 시간으로 구성되는데, 이때 MTTD는 장애가 발생한 이후, 이를 탐지하여 복구 조치를 시작하기까지 걸리는 시간을 의미합니다.
고가용성은 MTTD와 복구조치가 사람의 개입 없이 자동화되어 수행되는 것을 의미하며, 이는 본 가용성 설계 원칙의 주요 검토 대상입니다.
가용성을 향상시키기 위해서는 모니터링, 알림 및 응답 자동화를 통해 장애를 감지하고 자동 조치할 수 있도록 구성하여 MTTD를 최소화해야 합니다.
또한, 자원의 중복 구성 및 자원 확장 자동화를 통해 장애 대응을 자동화함으로써 MTTR을 최소화하여 가용성을 향상시킬 수 있습니다.
Samsung Cloud Platform 가용성
클라우드 환경에서도 서비스 가용성 요구사항에 따라 단일 구성 또는 이중화/다중화를 설계하고 구현합니다. 다만, 장애 요소 분석은 클라우드 사업자가 제시하는 서비스 수준 협약(Service Level Agreement,SLA)의 가용률을 기준으로 수행됩니다.
Samsung Cloud Platform에서는 SLA를 통해 서비스별 월간 가용률(%)을 제시하고 있습니다.
아래 표는 Samsung Cloud Platform에서 제공하는 서비스별 월 가용률 산정식과 용어 정의를 보여주고 있습니다.
가동 시간을 기준으로 가용률을 산정하는 서비스도 있고 요청 건수 또는 장애 건수를 기준으로 가용률을 산정하는 서비스도 있습니다.
| 서비스 | 장애 정의 | 월 가용률(%) | 장애 시간 정의 |
|---|---|---|---|
| 공통* | 가동 중인 고객의 인스턴스 또는 개별 서비스가 모두 외부 연결 및 접속을 확보하지 못하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Virtual Server DR | DR Recovery Plan에서 모의 훈련 또는 재해 전환 수행이 완료된 후 고객 서비스 접속이 불가하거나, 요청에 따른 전환이 이루어지지 않는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| DBaaS, Event Streams, Search Engine | 가동 중인 멀티 인스턴스 또는 개별 서비스가 모두 외부 연결 및 접속을 5분 이상 확보하지 못하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Kubernetes Engine | 컨트롤 플레인에 외부연결 및 접속을 5분 이상 확보하지 못하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Container Registry | Container Registry Endpoint에 대한 모든 연결 요청이 5분 동안 실패하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| DDoS Protection, Secured VPN, Secured Firewall, WAF, IPS, SASE | 회사가 제공하는 보안 장비의 미작동, 오작동으로 인하여 고객 서비스에 대한 모니터링, 탐지에 실패하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| File Storage, Block Storage | Compute에서 Storage로 15초 이상 Timeout이 발생한 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Transit Gateway, Direct Connect | 포트가 Down되거나, 연결 구간의 네트워크 오류로 인해 120초 이상 정보 송수신 불가 상태 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Edge Server | Edge Manager 접속 불가 또는 Edge Server 장애로 고객 서비스 실패 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Private Cloud | 가동 중인 고객의 인스턴스 또는 개별 서비스가 모두 CMP 접속을 확보하지 못하는 경우 | [1 - {장애 시간(분)합 / 서비스 이용 월 총 시간(분)의 합}] * 100 | 회사(SDS)의 사유로 해당 월에 발생한 장애 시간의 합 |
| Cloud Functions | 요청에 대해 500 또는 503 오류 코드 반환 (사용자 지정 오류 제외) | [1 - (장애 시간 및 건수의 합)/(서비스 이용 월 총 시간 및 건수의 합)] * 100 | 매 5분 동안 장애 발생한 시간 및 건수의 합 |
| Object Storage, Archive Storage | Storage 요청에 대해 500 오류 반환 장애율: 장애 요청 비율 평균 장애율: 월 평균 장애율 | 100% - 평균 장애율 | - |
| API Gateway | 요청에 대해 500 또는 503 오류 코드 반환 | [1 - (장애 건수의 합)/(서비스 이용 월 총 건수의 합)] * 100 | 매 5분 동안 오류 발생한 요청 건수의 합 |
| Quick Query | SQL 쿼리 요청이 외부 연결 및 접속을 5분 이상 확보하지 못하는 경우 장애시간: | [1 - (장애 건수의 합)/(서비스 이용 월 총 건수의 합)] * 100 | 회사의 사유로 해당 월에 발생한 장애건수의 합 |
| Backup | 고객 요청 백업 실패 (재수행 성공 시 제외) | [1 - (장애 건수의 합)/(서비스 이용 월 총 건수의 합)] * 100 | 회사의 사유로 해당 월에 발생한 장애건수의 합 |
*공통의 대표적인 서비스는 Virtual Server, Bare Metal Server, Load Balancer, GSLB, VPN, SingleID, DevOps Service,AIOS 등입니다.
Samsung Cloud Platform의 Well-Architected 설계 원칙은 장애 및 복원력 측면에서 가용성(Availability)과 안정성(Reliability)에 관한 설계 원칙을 제시하고 있습니다.
가용성 설계 원칙은 특정 구성 요소의 장애 발생이나 예기치 못한 부하 급증 상황에서도 서비스가 중단되지 않도록, 자동화된 대응 조치를 중심으로 아키텍처를 설계하는 데 초점을 둡니다.
안정성 설계 원칙은 계획되지 않은 장애나 재해 발생 시 데이터 손실을 최소화하고, 서비스를 신속하게 복구할 수 있는 방안을 중심으로 합니다.
가용성 설계의 핵심은 서비스를 중복 배치하여 하나의 구성 요소에 장애가 발생하더라도 다른 요소가 정상적으로 작동하게 함으로써 서비스 중단을 방지하는 고가용성(High Availability) 구현하는 데 있습니다.
또한, 수요 증가로 인해 특정 구성 요소에서 병목 현상이 발생해 서비스 응답이 지연되거나 중단되는 상황을 방지하기 위한 확장성(Scalability)을 확보하는 것도 가용성 설계의 중요한 목표입니다.