Elasticsearch 성능 최적화
Elasticsearch 성능 최적화
개요
Elasticsearch는 Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진입니다. Elasticsearch는 Lucene 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다. 이 문서에서는 Elasticsearch 아키텍처를 이해하고, Elasticsearch를 최적화 해서 사용하기 위한 방법을 설명합니다.
Elasticsearch 아키텍처
Elasticsearch에서는 단일 데이터 단위를 Document라고 합니다. RDBMS와 비교하면 하나의 Row와 동일한 개념입니다. 그리고 Document를 모아 놓은 집합을 Index(인덱스)라고 부릅니다. 버전 7부터 Index의 개념을 RDBMS에서의 테이블로 보면 보다 이해하기가 쉽습니다. 그리고 Index는 Shard(샤드) 단위로 파티션되어 각 노드에 데이터(Document)를 분산해서 저장합니다.
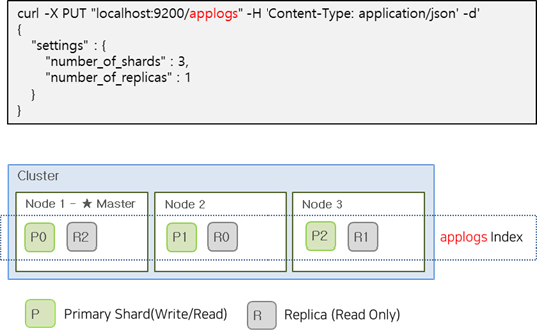
Elasticsearch Cluster의 서비스 연속성 유지를 위해 Shard를 Primary 와 Replica로 나눠서 관리 합니다. Replica Shard는 Primary Shard와 동일한 데이터를 가지고 있기 때문에 사용자의 검색 요청에도 응답할 수 있습니다. Primay Shard에 장애가 발생하면 Replica Shard는 Primary Shard로 승격하여 서비스가 지속됩니다. Primary Shard는 Read/Write 모두 가능하지만 Replica Shard는 Read Only만 가능합니다.
| 구분 | 역할 |
|---|---|
| Primary Shard | CRUD를 제공하는 Shard |
| Replica Shard | 장애 복구를 위한 Primary Shard의 복제본. |
아래 이미지는 applogs index를 Primay Shard 3, Replica Shard 1로 생성한 예시입니다.
Shard 적정 사이즈 및 배치
Index의 Primary Shard 수는 Index 생성 시점에 고정되어 수정이 불가능 하지만, Replica Shard 수는 쿼리 작업을 중단하지 않고 언제든지 변경할 수 있습니다. 따라서 Index 생성 전에 Primary Shard 개수와 사이즈에 대한 고민을 해야합니다.
Shard Size
클러스터에 존재하는 모든 Shard는 마스터 노드에서 관리됩니다. 따라서 Shard가 많아질 수록 마스터 노드의 부하도 증가합니다. 마스터 노드의 부하로 인해 색인과 검색 작업이 느려질 수도 있고, 메모리 문제를 일으킬 가능성도 커집니다. 또한 Shard Size가 너무 클 경우에는 장애 발생시 Shard 단위로 데이터가 이동하기 때문에 복구 작업에 부정적인 영향을 미칠 수 있습니다.
일반적으로 Primary Shard의 개수가 많으면 검색 성능이 좋아집니다. 검색은 각 Shard에서 독립적으로 수행하고 하나의 결과로 합쳐서 제공됨으로, 다수의 Shard로 분산될수록 성능이 빨라집니다. 그렇다고 무한정 Shard가 많다고 다 좋은 것은 아닙니다. Elasticsearch 검색은 1개의 쿼리는 1개의 Shard에서 1개의 Thread를 사용해서 동작합니다. 문제는 Thread 개수가 한정 되어 있기 때문에 Shard가 너무 많은 경우 Thread 할당을 받지 못하고 대기가 발생 할 수 있습니다. 따라서 사전에 테스트를 통해 적절한 Shard Size를 찾아야 합니다.
아래 이미지를 보면, Shard가 12개인 Index를 생성한 경우 각 노드별 4개의 Shard를 할당 받게 됩니다. 만약 노드 별 Thread가 4개인 상황에서 사용자가 거의 동시에 Query #1, #2를 수행하게 되면 먼저 요청된 Query #1이 모든 thread를 점유하게 됩니다. (Query #1을 처리하기 위해 12개 Thread 모두 사용) 이 경우 Query #2는 Query #1이 끝날때까지 대기 해야 합니다.
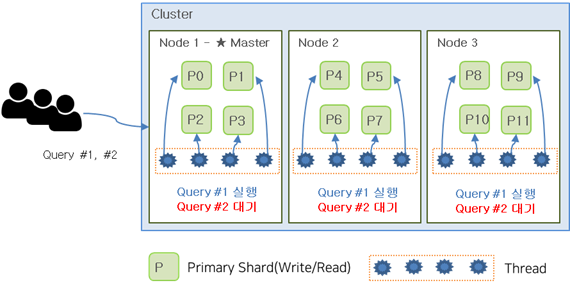
Shard가 6개였다면 아래 이미지 처럼Query #1, #2가 동시에 수행될 수 있었을겁니다. 이처럼 Shard 개수가 너무 많아도 문제가 발생합니다.

일반적으로 Shard Size는 20~40GB를 권장 하고, 최대 50GB를 넘지 않아야 합니다. 또한, Shard 개수는 하나의 노드에 설정한 힙 1GB당 20개 미만으로 유지하는 것이 좋습니다. 따라서 힙이 30GB인 노드는 최대 600개의 샤드를 가질 수 있지만 이보다 훨씬 더 적게 유지하는 것이 더 좋습니다.
Replica Shard
Primary Shard와 달리 Replica Shard 수는 운영 중에 변경이 가능합니다. 일반적으로 장애 대응을 위해 최소 한개 이상의 Replica Shard를 두는 것이 좋습니다. Replica Shard개수에는 trade-off 관계가 있습니다. Replica가 많아질수록 색인 성능은 떨어지고, 읽기 성능은 좋아집니다. 반면에 Replica가 적으면 색인 성능은 좋지만, 읽기 성능은 떨어집니다. 위와 같은 관계가 발생하는 이유는 Replica Shard가 생성될 때도 색인 데이터를 전송하고 파일에 Write하는 과정을 거쳐야 하기 때문입니다. 이 때문에 많은 수의 Replica는 색인 성능을 떨어뜨릴 수 있는 것이고, 대신 더 많은 분산 처리를 가능하게 함으로 읽기 성능은 올라갈 수 있습니다.
기본적으로는 최소 한개 이상의 Replica Shard를 권장하며, 읽기 성능이 중요한 경우 추가적으로 늘려가는 것이 좋습니다.
Shard 배치
노드가 3개이고, Shard가 4개이면 아래와 같이 배치됩니다. Shard 배치는 Master 노드가 알아서 수행하고, 최대한 고르게 배치됩니다. 아래와 같이 배치되면 Node1이 더 많은 Disk를 사용하고, Client 요청도 더 많이 받게 됩니다. 따라서 Shard 생성 시 노드수를 고려하는게 좋습니다. 일반적으로는 Index 별 Shard 개수는 노드 수의 N배로 시작하는 것이 좋습니다. 만약 노드 추가가 계획이 있다면, 현재 노드수와 노드가 추가되었을 때 전체 노드수의 최소 공배수로 하면, 향후 전체 노드에 Shard가 고르게 분배 될 수 있습니다.

노드 별 Disk Size
데이터소스가 로그데이터이고 HOT노드로 사용할 경우 노드 별 최대 3TB 디스크에 70~75% 사용율을 권장드립니다. 만약 Disk가 부족한 경우 Disk Size를 더 늘리지 않고 노드 추가를 통해 저장공간을 확보해야 합니다. 또한 노드 장애가 발생한 경우 해당 노드가 할당 받은 Shard를 나머지 노드에 분산하게 됩니다. 이 용량 또한 고려해서 Disk Size를 결정 해야 합니다.
Master Node 분리
Elasticsearch Node 역할을 Master와 Data로 구분 할 수 있습니다.
Master Node Index Metadata, Shard 할당, Cluster의 상태정보를 관리합니다. 분리 설치 했을 경우 Data노드에 비해 상대적으로 낮은 사양의 CPU, RAM, Disk사용이 가능합니다.
- Cluster의 1개 node는 항상 Master node 역할을 수행
- Master node는 Cluster 전체의 설정 및 변경을 담당 . indices creating/deleting . adding/removing nodes . allocating shards to nodes
- Heatbeat 체크로 Cluster의 모든 node 상태 모니터링
Data Node Disk I/O 가 중요하며, 분리 설치 시 Master노드에 비해 상대적으로 높은 사양의 CPU, RAM, Disk를 사용하는 것이 좋습니다. 특히 Disk는 SSD사용을 권장합니다.
- Index를 생성한 documents가 속한 shards를 Data node에 저장
- CRUD, 검색 및 집계와 같은 데이터 관련 작업을 실행
- I/O, CPU, memory-intensive → resource 모니터링으로 Data node를 확장하는 것이 중요
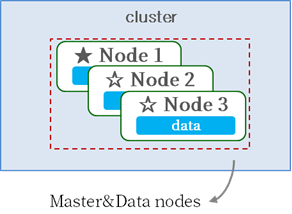
Master / Data를 각각 노드에 구성 할 수도 있고, 하나의 노드에 Master / Data 역할을 같이 할 수 있도록 구성 할 수도 있습니다.
[Master/Data 통합 구성]
[Master/Data 분리 구성]
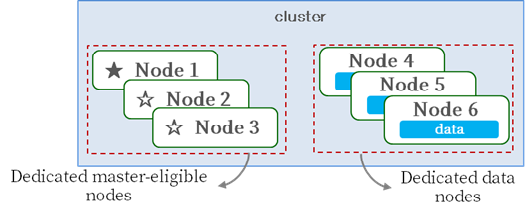
Master노드는 Index의 메타데이터, Shard의 할당, Cluster 상태 정보를 관리하고, Master 역할을 잘 수행할 수 있도록 충분한 리소스가 확보가 필요합니다. Maste가 다른 작업으로 과부하 되는 것을 방지하는 가장 안정적인 방법은 Master 전용 노드를 구성하는 것입니다.
클러스트가 아주 작은수의 노드로 구성 되었거나 로드가 적은 경우 Master 전용 노드를 구성하지 않아도 잘 작동할 수 있지만 클러스터가 소수(handful of nodes) 이상의 노드로 구성되고 부하가 높다면 Master 전용 노드를 구성하는 것이 좋습니다.