Data Analytics Migration
Data Analytics Migration
개요
Samsung Cloud Platform 환경에 구성된 Search Engine을 Samsung Cloud Platform v2 환경으로 마이그레이션 하는 방법은 2가지가 있습니다. 백업/복구 하는 Snapshot 기능과 실시간 복제하는 CCR(Crosss Cluster Replication) 기능을 이용해서 마이그레이션 할 수 있습니다. 각각 장/단점 및 제약사항이 있음으로 프로젝트 요구사항에 맞는 방법을 이용하면 됩니다.
Elasticsearch 버전 별로 마이그레이션 가능한 방법을 우선 확인하세요.
| vmware | nuri | 마이그레이션방법 |
|---|---|---|
| Elasticsearch 7.9.3 | Opensearch 2.17.1 | snapshot |
| Elasticsearch 7.9.3 | Elasticsearch 8.15.0 | snapshot |
| Elasticsearch 8.7.1 | Elasticsearch 8.15.0 | snapshot or CCR |
| Elasticsearch 8.10.4 | Elasticsearch 8.15.0 | snapshot or CCR |
| Elasticsearch 8.15.0 | Elasticsearch 8.15.0 | snapshot or CCR |
마이그레이션 절차
CCR(Cross Cluster Replication)
CCR은 클러스터 간 인덱스 단위의 복제를 통해 DR(Disaster Recovery), HA(High Availability)을 제공하는 기술을 의미합니다, 6.7 버전부터 기능이 릴리즈 되었으며, 현재는 플래티넘 라이센스에서 이용 가능합니다. CCR을 사용하면 특정 인덱스를 하나의 Elasticsearch 클러스터에서 하나 이상의 Elasticsearch 클러스터로 복제할 수 있습니다.
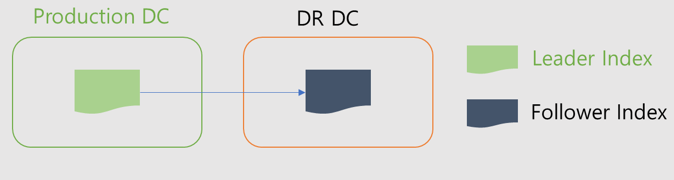
CCR은 액티브-패시브 모델을 사용합니다. 리더 인덱스에 인덱싱하면 데이터가 하나 이상의 읽기 전용 팔로워 인덱스에 복제됩니다.
CCR 동작
- 원본 Index를 Leader Index라고하며, 복사된 Index를 Follower Index라고함
- Index 단위로 복제 설정하며, 복제된 Follow Index는 Read Only 상태임
- Follower Index를 일반 Index로 변경하기 위해 unfollow api를 호출 해야함
- 데이터 복제는 샤드 수준에서 복제됨으로 복제된 Index도 원본과 동일한 샤드수를 가짐
- Leader Index가 삭제 되어도 Follow Index는 삭제 안됨
제약사항
클러스터 간 복제는 사용자 생성 인덱스만 대상으로 설계되었으며, 다음의 인덱스는 적용되지 않습니다
- 시스템 인덱스
- 인덱스 템플릿
- ILM, SLM 정책
- 클러스터 설정
- 사용자 권한 및 매핑
- 스냅샷
CCR 설정 사전 준비
1. Network 연결 요청
CCR 설정을 위해서 Cluster간 보안연결 설정이 필요합니다. 현재 SCP Search Engine 상품은 이부분이 자동화 되어있지 않기 때문에 SCP 1:1 문의 하기를 통해 보안연결 설정 요청이 필요합니다.
2. Network 연결 확인
Network이 연결 후 Kibana Stack Management > Remote Cluster 메뉴에서 “mig_ccr” Remote Cluster가 등록되어 있는지 확인 하세요
데이터 동기화 설정
데이터 실시간 복제를 위해서 Index를 Follower Index로 설정을 해야합니다.
Follower Index를 설정하는 방법은 두가지가 있습니다. Index명을 명시적으로 등록 하거나 Pattern을 이용해서 등록할 수 있습니다. 일반적으로 * 패턴을 먼저 설정 해서, 신규로 생성되는 Index를 자동 동기화 설정합니다. 기존에 생성되어 있는 Index는 Index명으로 명시적으로 follower Index로 설정합니다.
| 구분 | Index Name (Add follower Index) | Pattern (Auto-follow patterns) |
|---|---|---|
| 등록방법 | leader Index 명으로 등록 | leader Index 패턴으로 등록 ex. log* |
| 참고사항 | leader Index가 사전에 존재해야함 | Pattern 생성 이후 생성되는 leader Index만 복제됨 |
1. ILM, 인덱스템플릿 생성
ILM, 인덱스템플릿 등 CCR을 통해 복제되지 않는 Object는 수작업으로 생성하시기 바랍니다. 복제 설정하기 전에 생성해야합니다.
2. Auto-follow patterns 등록
복제 할 Index 패턴을 등록합니다. 주의할 사항은 신규로 생성되는 Index에 대해서면 적용됩니다.
Stack Management > Cross-Cluster Replication > Auto -follow patterns
3. Follow Index 설정
복제 할 Index를 명시적으로 등록합니다.
Stack Management > Cross-Cluster Replication > Follower indices
API로 수행 할 수도 있습니다.
PUT /<follower_index>/_ccr/follow
{
"remote_cluster" : "mig_ccr",
"leader_index" : "<leader_index>"
}
4. 데이터 동기화 확인
Kibana에서 정상적으로 데이터 동기화 되는지 확인 할 수 있습니다.
Status가 Active이면 정상입니다.
Stack Management > Cross-Cluster Replication
데이터 동기화 해제
데이터 동기화 설정된 인덱스(follower index)는 read only로 동작 합니다. Samsung Cloud Platform v2의 Search Engine으로 완전히 전환하는 시점에 데이터 동기화 해제(unfollow) 작업이 필요합니다.
1. unfollow index (데이터 동기화 해제)
Kibana 에서 일괄 unfollow 할 수 있습니다.
Stack Management > Cross-Cluster Replication
2. promote datastream
datastream을 사용하는 경우, 데이터 동기화 해제 후 promote api를 이용해서 datastream promotion 작업을 수행해야합니다. 이 작업을 수행하지 않으면, datastream 롤오버 작업을 수행할 수 없습니다.
POST /_data_stream/_promote/my-datastream
promotion 후 아래 api를 통해 “replicated”: false 로 정상적으로 나오는지 확인합니다.
GET /_data_stream/my-datastream
3. alias write 가능하게 변경
alias를 사용하는 경우, 데이터 동기화 해제 후 write 가능한 alias로 변경해야합니다. 이 작업을 수행하지 않으면 alias를 통해 write가 불가능합니다.
POST _aliases
{
"actions": [
{
"add": {
"index": "app-log-000004",
"alias": "app-logs",
"is_write_index": true
}
}
]
}
write 가능한 alias로 변경후 아래 api를 통해 확인합니다.
GET _cat/aliases/app*?v
alias index filter routing.index routing.search is_write_index
app-logs app-log-000003 - - - false
app-logs app-log-000004 - - - true
Snapshot 마이그레이션
Samsung Cloud Platform의 Search Engine은 백업 시 Snapshot 기능을 이용해서 Object Storage Bucket에 저장합니다. 이 Bucket을 Samsung Cloud Platform v2의 Object Storage로 복제하고 Samsung Cloud Platform v2의 Search Engine에서 복구하는 방식으로 데이터 마이그레이션을 진행합니다.
사전 작업
1. Bucket 복제 & Snapshot Repository 생성 요청
- Samsung Cloud Platform 환경의 Search Engine이 백업 설정이 되어 있어야합니다.
- SCP 1:1 문의 하기를 통해 백업 Bucket 복제 요청이 필요합니다.
2. Snapshot Repository 확인
Kibana에서 “scp_migration_repo” repository가 조회되는지 확인합니다.
2.1 Elasticsearch
Stack Management > Snapshot and Restore > Repositories
2.2 Opensearch
Snapshot Management > Repositories
Snapshot 복구 작업
Elasticsearch / Opensearch 공통
1. 복구 할 snapshot 확인
GET _snapshot/scp_migration_repo/*
2. 복구 할 Index 확인
GET _snapshot/scp_migration_repo/snapshot_202504241057
"snapshots": [
{
"snapshot": "snapshot_202504241057",
"uuid": "Xp4Ngd3rTpWPzThxLk0P0g",
"version_id": 7090399,
"version": "7.9.3",
"indices": [
"app-log-002",
".kibana_1",
"app-log-001",
"user-log-001",
"user-log-002"
],
"data_streams": [],
"include_global_state": true,
"state": "SUCCESS",
"start_time": "2025-04-24T01:57:28.728Z",
"start_time_in_millis": 1745459848728,
"end_time": "2025-04-24T01:57:30.528Z",
"end_time_in_millis": 1745459850528,
"duration_in_millis": 1800,
"failures": [],
"shards": {
"total": 5,
"failed": 0,
"successful": 5
}
}
]
3. Index 복구
POST _snapshot/scp_migration_repo/snapshot_202504241057/_restore
{
"indices": "app-log*,user-log*",
"index_settings": {
"index.number_of_replicas": 0
}
}
필요 시 replica 수도 조정 가능합니다.